《深入理解计算机系统》(CSAPP)实验七 —— Malloc Lab
文章目录
- 隐式空闲链表
-
- 分离的空闲链表
- 显示空闲链表
-
- 1. 实验目的
- 2. 背景知识
- 3. Implicit list
-
- mm_init
- extend_heap
- mm_malloc
- find_fit
- place
- mm_free
- coalesce
- mm_realloc
- 4. explicit list
-
- mm_init
- allocate_from_heap
- extend_heap
- insert_to_free_list
- mm_malloc
- find_fit
- place
- delete_from_free_list
- mm_free
- coalesce
-
- case1
- case2
- case3
- case4
- 其余 debug 用的函数
- 5. 总结
这个实验太,太,太难了!我自己是写不出来的。看了两位大佬的两篇文章,才搞清楚。直接贴下大佬的两篇文章吧,一个是用隐式链表实现的,一个是用显示链表实现的。
隐式空闲链表
该作业编译成32位程序,我使用的是Windows的WSL子操作系统,不支持32位的程序,可参考这里来修改。
做了两天,一直遇到段错误,好难debug,但是做出了一点结果,不追求满分了,就加强对动态分配器的理解吧。
该实验主要是让我们实现一个动态分配器,实现mm_init、mm_malloc、mm_free和mm_realloc函数。然后提供了两个简单的验证文件short1-bal.rep和short2-bal.rep来测试我们算法的内存利用率和吞吐量。我们可以调用./mdriver -f short1-bal.rep -V来查看单个文件的测试结果。然后github上有人上传了该课程的其他测试数据,可以从这里下载,得到一个trace文件夹,然后调用./mdriver -t ./trace -V来查看测试结果。
首先,我们使用带有脚部的块的数据结构,如下所示。并且设置指向块的指针bp是指向有效载荷的,这样就能通过bp直接访问块中的有效载荷。

基于此,我们可以确定一些宏
//字大小和双字大小
#define WSIZE 4
#define DSIZE 8
//当堆内存不够时,向内核申请的堆空间
#define CHUNKSIZE (1<<12)
//将val放入p开始的4字节中
#define PUT(p,val) (*(unsigned int*)(p) = (val))
//获得头部和脚部的编码
#define PACK(size, alloc) ((size) | (alloc))
//从头部或脚部获得块大小和已分配位
#define GET_SIZE(p) (*(unsigned int*)(p) & ~0x7)
#define GET_ALLO(p) (*(unsigned int*)(p) & 0x1)
//获得块的头部和脚部
#define HDRP(bp) ((char*)(bp) - WSIZE)
#define FTRP(bp) ((char*)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
//获得上一个块和下一个块
#define NEXT_BLKP(bp) ((char*)(bp) + GET_SIZE(HDRP(bp)))
#define PREV_BLKP(bp) ((char*)(bp) - GET_SIZE((char*)(bp) - DSIZE))
#define MAX(x,y) ((x)>(y)?(x):(y))
**注意:**我们传入的bp指针可能是void *类型的,如果对bp进行计算时,要将其强制类型转换为char *,这样加减的值就是字节数目。
//指向隐式空闲链表的序言块的有效载荷
static char *heap_listp;
/*
* mm_init - initialize the malloc package.
*/
int mm_init(void){
if((heap_listp = mem_sbrk(4*WSIZE)) == (void*)-1) //申请4字空间
return -1;
PUT(heap_listp, 0); //填充块
PUT(heap_listp+1*WSIZE, PACK(DSIZE, 1)); //序言块头部
PUT(heap_listp+2*WSIZE, PACK(DSIZE, 1)); //序言块脚部
PUT(heap_listp+3*WSIZE, PACK(0, 1)); //结尾块
heap_listp += DSIZE; //指向序言块有效载荷的指针
if(expend_heap(CHUNKSIZE/WSIZE) == NULL) //申请更多的堆空间
return -1;
return 0;
}
该部分是用来创建初始隐式空闲链表的,我们的隐式空闲链表具有以下结构

首先需要一个包含头部和脚部的已分配序言块,永远不会被释放,大小为8字节,作为隐式空闲链表的开头。后续就是一些我们普通的块,包含已分配块和空闲块,最后是一个块大小为0的已分配结尾块,只包含头部,大小为4字节,作为隐式空闲链表的结尾,为什么结尾块是这么设置的,后面会看到原因。
现在普通块1加上序言块和自己的头部就有3个字,为了保证块的有效载荷都是双字对齐的,就在堆的起始位置填充一个字的块。
然后我们令一个指针heap_listp指向序言块的有效载荷部分,作为隐式空闲链表的起始指针。然后当前隐式空闲链表还没有可以装其他数据的部分,所以调用expend_heap来申请更多的堆空间,这里一次申请固定大小的空间,由CHUNKSIZE定义。
static void *expend_heap(size_t words){
size_t size;
void *bp;
size = words%2 ? (words+1)*WSIZE : words*WSIZE; //对大小双字对对齐
if((bp = mem_sbrk(size)) == (void*)-1) //申请空间
return NULL;
PUT(HDRP(bp), PACK(size, 0)); //设置头部
PUT(FTRP(bp), PACK(size, 0)); //设置脚部
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); //设置新的结尾块
//立即合并
return imme_coalesce(bp);
//return bp;
}
该函数传入字数目,首先要保证字数目是双字对齐的,然后申请对应的堆空间。接下来就将申请的堆空间作为一个空闲块,设置头部和脚部。需要注意,此时的bp指针和隐式空闲链表的关系如下所示
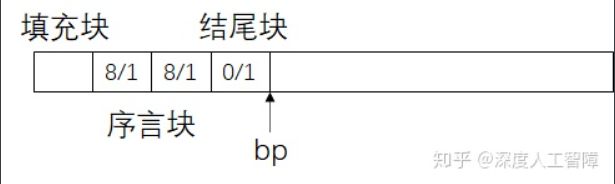
此时我们调用PUT(HDRP(bp),PACK(size,0));来设置新空闲块的头部,可以发现是将之前的结尾块作为当前空闲块的头部,而PUT(HDRP(NEXT_BLKP(bp)),PACK(0,1));是将最终结尾的一个字作为结尾块。这样就充分利用了原来的结尾块空间。
此时该空闲块的前面可能也为空闲块,所以可以调用imme_coalesce(bp)进行立即合并。
static void *imme_coalesce(void *bp){
size_t prev_alloc = GET_ALLO(FTRP(PREV_BLKP(bp))); //获得前面块的已分配位
size_t next_alloc = GET_ALLO(HDRP(NEXT_BLKP(bp))); //获得后面块的已分配位
size_t size = GET_SIZE(HDRP(bp)); //获得当前块的大小
if(prev_alloc && next_alloc){
return bp;
}else if(prev_alloc && !next_alloc){
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}else if(!prev_alloc && next_alloc){
size += GET_SIZE(FTRP(PREV_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
bp = PREV_BLKP(bp);
}else{
size += GET_SIZE(HDRP(NEXT_BLKP(bp))) +
GET_SIZE(FTRP(PREV_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
return bp;
}
该函数会根据bp前面一块和后面一块的已分配位的不同情况,来决定如何进行合并, 如下所示

其实我们这里只需要修改对应块的头部和脚部中的块大小字段就可以了,然后根据需要修改bp使它指向合并后的空闲块。
接下来就能看看我们的mm_malloc函数了
void *mm_malloc(size_t size){
size_t asize;
void *bp;
if(size == 0)
return NULL;
//满足最小块要求和对齐要求,size是有效负载大小
asize = size<=DSIZE ? 2*DSIZE : DSIZE * ((size + (DSIZE) + (DSIZE-1)) / DSIZE);
//首次匹配
if((bp = first_fit(asize)) != NULL){
place(bp, asize);
return bp;
}
//最佳匹配
/*if((bp = best_fit(asize)) != NULL){
place(bp, asize);
return bp;
}*/
//推迟合并
//delay_coalesce();
//最佳匹配
/*if((bp = best_fit(asize)) != NULL){
place(bp, asize);
return bp;
}*/
//首次匹配
/*if((bp = first_fit(asize)) != NULL){
place(bp, asize);
return bp;
}*/
if((bp = expend_heap(MAX(CHUNKSIZE, asize)/WSIZE)) == NULL)
return NULL;
place(bp, asize);
return bp;
}
首先,mm_malloc传进来的大小参数size是指块的有效载荷,当我们对空闲块进行搜索时,空闲块的大小包括了头部、有效载荷和脚部,所以我们需要将size加上这两部分的大小且进行双字对齐,得到进行比较的大小asize。然后我们就可以使用asize来搜索合适的空闲块,这里有两个策略:首次适配和最佳适配。并且如果我们采用延迟合并空闲块的话,如果找不到合适的空闲块,就要进行延迟合并,然后再找一次,如果还是找不到,则说明没有足够的堆空间,此时要再申请堆空间,然后将我们想要的空间大小放入空闲块中。
首先看首次适配
static void *first_fit(size_t asize){
void *bp = heap_listp;
size_t size;
while((size = GET_SIZE(HDRP(bp))) != 0){ //遍历全部块
if(size >= asize && !GET_ALLO(HDRP(bp))) //寻找大小大于asize的空闲块
return bp;
bp = NEXT_BLKP(bp);
}
return NULL;
}
将隐式空闲链表的结尾块作为结尾,依次判断链表中的块,如果有大小大于asize的空闲块,就直接返回。
我们也可以看看最佳适配
static void *best_fit(size_t asize){
void *bp = heap_listp;
size_t size;
void *best = NULL;
size_t min_size = 0;
while((size = GET_SIZE(HDRP(bp))) != 0){
if(size >= asize && !GET_ALLO(HDRP(bp)) && (min_size == 0 || min_size>size)){ //记录最小的合适的空闲块
min_size = size;
best = bp;
}
bp = NEXT_BLKP(bp);
}
return best;
}
它将搜索最小的合适的空闲块,这样就能减少碎片的产生,提高内存利用率。
当找到合适的空闲块时,我们就需要将我们需要的空间放入空闲块中
static void place(void *bp, size_t asize){
size_t remain_size;
remain_size = GET_SIZE(HDRP(bp)) - asize; //计算空闲块去掉asize后的剩余空间
if(remain_size >= DSIZE){ //如果剩余空间满足最小块大小,就将其作为一个新的空闲块
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1));
PUT(HDRP(NEXT_BLKP(bp)), PACK(remain_size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(remain_size, 0));
}else{
PUT(HDRP(bp), PACK(GET_SIZE(HDRP(bp)), 1));
PUT(FTRP(bp), PACK(GET_SIZE(HDRP(bp)), 1));
}
}
首先,我们需要计算空闲块去掉asize后的剩余空间,如果剩余空间还能填充头部和脚部构成一个新的空闲块,则对该空闲块进行分割,否则就使用整个空闲块,设置块的已分配位。
然后可以看看延迟合并的代码
static void *delay_coalesce(){
void *bp = heap_listp;
while(GET_SIZE(HDRP(bp)) != 0){
if(!GET_ALLO(HDRP(bp)))
bp = imme_coalesce(bp);
bp = NEXT_BLKP(bp);
}
}
遍历空闲链表的所有块,如果是空闲块,就将其和周围进行合并。
接下来可以看看我们的mm_free
/*
* mm_free - Freeing a block does nothing.
*/
void mm_free(void *ptr){
size_t size = GET_SIZE(HDRP(ptr));
PUT(HDRP(ptr), PACK(size, 0));
PUT(FTRP(ptr), PACK(size, 0));
//立即合并
imme_coalesce(ptr);
}
我们首先设置块的已分配位,将其设置为空闲状态,然后对其立即合并就行。
最终是我们的mm_realloc
/*
* mm_realloc - Implemented simply in terms of mm_malloc and mm_free
*/
void *mm_realloc(void *ptr, size_t size){
size_t asize, ptr_size;
void *new_bp;
if(ptr == NULL)
return mm_malloc(size);
if(size == 0){
mm_free(ptr);
return NULL;
}
asize = size<=DSIZE ? 2*DSIZE : DSIZE * ((size + (DSIZE) + (DSIZE-1)) / DSIZE);
new_bp = imme_coalesce(ptr); //尝试是否有空闲的
ptr_size = GET_SIZE(HDRP(new_bp));
PUT(HDRP(new_bp), PACK(ptr_size, 1));
PUT(FTRP(new_bp), PACK(ptr_size, 1));
if(new_bp != ptr) //如果合并了前面的空闲块,就将原本的内容前移
memcpy(new_bp, ptr, GET_SIZE(HDRP(ptr)) - DSIZE);
if(ptr_size == asize)
return new_bp;
else if(ptr_size > asize){
place(new_bp, asize);
return new_bp;
}else{
ptr = mm_malloc(asize);
if(ptr == NULL)
return NULL;
memcpy(ptr, new_bp, ptr_size - DSIZE);
mm_free(new_bp);
return ptr;
}
}
首先,如果ptr为NULL,则直接分配size大小的空间,如果size为0,则直接释放ptr指向的空间。否则就需要执行mm_realloc。 当我们执行mm_realloc时,ptr指向的是已分配块,它的周围可能有空闲块,而加上空闲块后,可能就会满足asize的大小要求了,所以我们可以先尝试将ptr和周围的空闲块进行合并。
然后下面是实验结果
首次适配+立即合并:
Results for mm malloc:
trace valid util ops secs Kops
0 yes 99% 5694 0.014197 401
1 yes 99% 5848 0.013547 432
2 yes 99% 6648 0.021787 305
3 yes 100% 5380 0.016372 329
4 yes 66% 14400 0.001061 13570
5 yes 92% 4800 0.014609 329
6 yes 92% 4800 0.013454 357
7 yes 55% 12000 0.203199 59
8 yes 51% 24000 0.572411 42
9 yes 44% 14401 0.152757 94
10 yes 45% 14401 0.029385 490
Total 77% 112372 1.052780 107
Perf index = 46 (util) + 7 (thru) = 53/100
首次匹配+延迟合并:
Results for mm malloc:
trace valid util ops secs Kops
0 yes 99% 5694 0.033440 170
1 yes 99% 5848 0.028946 202
2 yes 99% 6648 0.062765 106
3 yes 99% 5380 0.056375 95
4 yes 66% 14400 0.001050 13721
5 yes 92% 4800 0.029646 162
6 yes 90% 4800 0.027486 175
7 yes 60% 12000 0.214382 56
8 yes 53% 24000 0.584505 41
9 yes 35% 14401 0.813350 18
10 yes 45% 14401 0.019537 737
Total 76% 112372 1.871480 60
Perf index = 46 (util) + 4 (thru) = 50/100
最佳匹配+立即合并:
Results for mm malloc:
trace valid util ops secs Kops
0 yes 99% 5694 0.015399 370
1 yes 99% 5848 0.014503 403
2 yes 99% 6648 0.023172 287
3 yes 100% 5380 0.017809 302
4 yes 66% 14400 0.001038 13878
5 yes 96% 4800 0.030279 159
6 yes 95% 4800 0.028814 167
7 yes 55% 12000 0.201558 60
8 yes 51% 24000 0.601187 40
9 yes 40% 14401 0.003348 4302
10 yes 45% 14401 0.002100 6856
Total 77% 112372 0.939206 120
Perf index = 46 (util) + 8 (thru) = 54/100
最佳匹配+延迟合并:
Results for mm malloc:
trace valid util ops secs Kops
0 yes 99% 5694 0.038064 150
1 yes 99% 5848 0.036293 161
2 yes 99% 6648 0.073700 90
3 yes 99% 5380 0.072891 74
4 yes 66% 14400 0.001064 13535
5 yes 95% 4800 0.048523 99
6 yes 94% 4800 0.046162 104
7 yes 60% 12000 0.223058 54
8 yes 53% 24000 0.592458 41
9 yes 65% 14401 0.004285 3361
10 yes 76% 14401 0.001220 11800
Total 82% 112372 1.137718 99
Perf index = 49 (util) + 7 (thru) = 56/100
分离的空闲链表
对于分离的空闲链表,需要首先确定块的数据结构

这里空闲块在第二字和第三字记录了空闲块的前驱和后继的空闲块,由此通过指针的方式将所有空闲块显示链接起来,就能通过该指针直接遍历所有的空闲块了。
我们定义以下的宏
//字大小和双字大小
#define WSIZE 4
#define DSIZE 8
//当堆内存不够时,向内核申请的堆空间
#define CHUNKSIZE (1<<12)
//将val放入p开始的4字节中
#define PUT(p,val) (*(unsigned int*)(p) = (val))
#define GET(p) (*(unsigned int*)(p))
//获得头部和脚部的编码
#define PACK(size, alloc) ((size) | (alloc))
//从头部或脚部获得块大小和已分配位
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLO(p) (GET(p) & 0x1)
//获得块的头部和脚部
#define HDRP(bp) ((char*)(bp) - WSIZE)
#define FTRP(bp) ((char*)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
//获得上一个块和下一个块
#define NEXT_BLKP(bp) ((char*)(bp) + GET_SIZE(HDRP(bp)))
#define PREV_BLKP(bp) ((char*)(bp) - GET_SIZE((char*)(bp) - DSIZE))
//获得块中记录后继和前驱的地址
#define PRED(bp) ((char*)(bp) + WSIZE)
#define SUCC(bp) ((char*)bp)
//获得块的后继和前驱的地址
#define PRED_BLKP(bp) (GET(PRED(bp)))
#define SUCC_BLKP(bp) (GET(SUCC(bp)))
#define MAX(x,y) ((x)>(y)?(x):(y))
这里bp指向的是头部后面一个字的位置,我们将第一个字用来记录空闲块后继的地址,第二个块用来记录前驱的地址。为什么这样后面会有说明。
然后我们需要确定分离的空闲链表的大小类,由于一个空闲块包含头部、后继、前驱和脚部,至少需要16字节,所以空闲块的最小块为16字节,小于16字节就无法记录完整的空闲块内容,所以大小类设置为
{16-31},{32-63},{64-127},{128-255},{256-511},{512-1023},{1024-2047},{2048-4095},{4096-inf}
我们需要在堆的开始包含这些大小类的root节点,指向各自对应的空闲链表,则root需要一个字的空间用来保存地址。其次,还是需要保存序言块和结尾块,用来作为块之间移动的标志。所以mm_init如下所示
static char *heap_listp;
static char *listp;
/*
* mm_init - initialize the malloc package.
*/
int mm_init(void){
if((heap_listp = mem_sbrk(12*WSIZE)) == (void*)-1)
return -1;
//空闲块的最小块包含头部、前驱、后继和脚部,有16字节
PUT(heap_listp+0*WSIZE, NULL); //{16~31}
PUT(heap_listp+1*WSIZE, NULL); //{32~63}
PUT(heap_listp+2*WSIZE, NULL); //{64~127}
PUT(heap_listp+3*WSIZE, NULL); //{128~255}
PUT(heap_listp+4*WSIZE, NULL); //{256~511}
PUT(heap_listp+5*WSIZE, NULL); //{512~1023}
PUT(heap_listp+6*WSIZE, NULL); //{1024~2047}
PUT(heap_listp+7*WSIZE, NULL); //{2048~4095}
PUT(heap_listp+8*WSIZE, NULL); //{4096~inf}
//还是要包含序言块和结尾块
PUT(heap_listp+9*WSIZE, PACK(DSIZE, 1));
PUT(heap_listp+10*WSIZE, PACK(DSIZE, 1));
PUT(heap_listp+11*WSIZE, PACK(0, 1));
listp = heap_listp;
heap_listp += 10*WSIZE;
if(expend_heap(CHUNKSIZE/WSIZE) == NULL)
return -1;
return 0;
}
这里首先申请了12个字的空间,然后接下来的9各自依次保存各个大小类的root指针,初始为NULL。然后后面3个字用来保存序言块和结尾块,让listp指向大小类数组的起始位置,让heap_listp指向序言块的有效载荷,然后调用expend_heap来申请堆空间。**注意:**root指针相当于只有后继的块,所以可以通过SUCC宏来查看后继。
static void *expend_heap(size_t words){
size_t size;
void *bp;
size = words%2 ? (words+1)*WSIZE : words*WSIZE;
if((bp = mem_sbrk(size)) == (void*)-1)
return NULL;
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1));
PUT(PRED(bp), NULL);
PUT(SUCC(bp), NULL);
//立即合并
bp = imme_coalesce(bp);
bp = add_block(bp);
return bp;
}
首先获得对齐的大小size,然后和隐式空闲链表一样设置空闲块的头部、脚部和结尾块。然后由于该空闲块还没插入空闲链表中,所以先设置该空闲块的前驱和后继指针为NULL,然后调用imme_coalesce函数对该空闲块进行立即合并,再调用add_block函数将该空闲块插入合适的大小类的空闲链表中。
static void *imme_coalesce(void *bp){
size_t prev_alloc = GET_ALLO(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLO(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
if(prev_alloc && next_alloc){
return bp;
}else if(prev_alloc && !next_alloc){
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
delete_block(NEXT_BLKP(bp));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}else if(!prev_alloc && next_alloc){
size += GET_SIZE(FTRP(PREV_BLKP(bp)));
delete_block(PREV_BLKP(bp));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
bp = PREV_BLKP(bp);
}else{
size += GET_SIZE(HDRP(NEXT_BLKP(bp))) +
GET_SIZE(FTRP(PREV_BLKP(bp)));
delete_block(NEXT_BLKP(bp));
delete_block(PREV_BLKP(bp));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
return bp;
}
首先查找空闲块bp前后相邻的块的已分配位,根据已分配位的组合分成4种情况。

可以发现,如果有周围有空闲块,则首先需要通过delete_block函数将该空闲块从显示空闲链表中删除对应于图中调整指针的部分,然后再设置对应的头部和脚部,使得空闲块进行合并,并让bp指向新的空闲块的有效载荷部分。
static void delete_block(void *bp){
PUT(SUCC(PRED_BLKP(bp)), SUCC_BLKP(bp));
if(SUCC_BLKP(bp)!=NULL)
PUT(PRED(SUCC_BLKP(bp)), PRED_BLKP(bp));
}
从显示空闲链表中删除指定的空闲块其实很简单,就是调整前驱和后继的指针,使其跳过当前的空闲块就好。
在合并完空闲块后,我们需要将其插入到合适的大小类的显示空闲链表中
static void *add_block(void *bp){
size_t size = GET_SIZE(HDRP(bp));
int index = Index(size);
void *root = listp+index*WSIZE;
//LIFO
return LIFO(bp, root);
//AddressOrder
//return AddressOrder(bp, root);
}
在将空闲块插入显示空闲链表时,首先需要确定该空闲块所在的大小类
static int Index(size_t size){
int ind = 0;
if(size >= 4096)
return 8;
size = size>>5;
while(size){
size = size>>1;
ind++;
}
return ind;
}
由此就能得到对应大小类的显示空闲链表的root指针,此时提供两种在该显示空闲链表插入空闲块的策略:LIFO策略和地址顺序策略。
static void *LIFO(void *bp, void *root){
if(SUCC_BLKP(root)!=NULL){
PUT(PRED(SUCC_BLKP(root)), bp); //SUCC->BP
PUT(SUCC(bp), SUCC_BLKP(root)); //BP->SUCC
}else{
PUT(SUCC(bp), NULL); //缺了这个!!!!
}
PUT(SUCC(root), bp); //ROOT->BP
PUT(PRED(bp), root); //BP->ROOT
return bp;
}
LIFO策略是直接将空闲块插入称为头结点。注意当root后没后继节点时,说明是直接将bp查到root后面,此时要记得将bp的后继节点置为NULL。
static void *AddressOrder(void *bp, void *root){
void *succ = root;
while(SUCC_BLKP(succ) != NULL){
succ = SUCC_BLKP(succ);
if(succ >= bp){
break;
}
}
if(succ == root){
return LIFO(bp, root);
}else if(SUCC_BLKP(succ) == NULL){
PUT(SUCC(succ), bp);
PUT(PRED(bp), succ);
PUT(SUCC(bp), NULL);
}else{
PUT(SUCC(PRED_BLKP(succ)), bp);
PUT(PRED(bp), PRED_BLKP(succ));
PUT(SUCC(bp), succ);
PUT(PRED(succ), bp);
}
return bp;
}
而地址顺序就是让显示空闲链表中的空闲块地址依次递增。这种策略的首次适配会比LIFO的首次适配有更高的内存利用率。
接下来就可以看看我们的mm_malloc函数了
void *mm_malloc(size_t size){
size_t asize;
void *bp;
if(size == 0)
return NULL;
//满足最小块要求和对齐要求,size是有效负载大小
asize = size<=DSIZE ? 2*DSIZE : DSIZE * ((size + (DSIZE) + (DSIZE-1)) / DSIZE);
//首次匹配
if((bp = first_fit(asize)) != NULL){
place(bp, asize);
return bp;
}
//最佳匹配
/*if((bp = best_fit(asize)) != NULL){
place(bp, asize);
return bp;
}*/
if((bp = expend_heap(MAX(CHUNKSIZE, asize)/WSIZE)) == NULL)
return NULL;
place(bp, asize);
return bp;
}
首先会计算满足最小块和对其要求的空闲块大小asize,**注意:**空闲块需要额外的两个字来保存前驱和后继指针,但是已分配的块不需要,所以这里的asize还是和隐式空闲链表的相同。
这里提供了首次匹配和最佳匹配两种策略
static void *first_fit(size_t asize){
int ind = Index(asize);
void *succ;
while(ind <= 8){
succ = listp+ind*WSIZE;
while((succ = SUCC_BLKP(succ)) != NULL){
if(GET_SIZE(HDRP(succ)) >= asize && !GET_ALLO(HDRP(succ))){
return succ;
}
}
ind+=1;
}
return NULL;
}
在首次匹配中,首先需要确定asize大小的空闲块处于哪个大小类,然后搜索该大小类对应的显示空闲链表,如果找到大小合适的空闲块,则直接返回,如果该显示空闲链表没找到合适的空闲块,就遍历下一个大小类的显示空闲链表,因为下一个大小类的空闲块一定比当前大小类的大。
static void *best_fit(size_t asize){
int ind = Index(asize);
void *best = NULL;
int min_size = 0, size;
void *succ;
while(ind <= 8){
succ = listp+ind*WSIZE;
while((succ = SUCC_BLKP(succ)) != NULL){
size = GET_SIZE(HDRP(succ));
if(size >= asize && !GET_ALLO(HDRP(succ)) && (size<min_size||min_size==0)){
best = succ;
min_size = size;
}
}
if(best != NULL)
return best;
ind+=1;
}
return NULL;
}
而最佳适配就是要找到满足大小要求的最小空闲块。
当找到合适的空闲块后,我们需要调用place函数来使用该空闲块
static void place(void *bp, size_t asize){
size_t remain_size;
remain_size = GET_SIZE(HDRP(bp)) - asize;
delete_block(bp);
if(remain_size >= DSIZE*2){ //分割
PUT(HDRP(bp), PACK(asize, 1));
PUT(FTRP(bp), PACK(asize, 1));
PUT(HDRP(NEXT_BLKP(bp)), PACK(remain_size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(remain_size, 0));
add_block(NEXT_BLKP(bp));
}else{
PUT(HDRP(bp), PACK(GET_SIZE(HDRP(bp)), 1));
PUT(FTRP(bp), PACK(GET_SIZE(HDRP(bp)), 1));
}
}
在place函数中,我们首先要将该空闲块从显示空闲链表中删除,然后判断剩余空间是否满足空闲块的最小要求,如果满足则对空闲块进行分割,然后剩余的空闲块调用add_block函数将其放到合适的大小类的显示空闲链表中,如果剩余空间不足以构成一个空闲块,则直接使用整个空闲块。
接下来可以看看我们的mm_free函数了
/*
* mm_free - Freeing a block does nothing.
*/
void mm_free(void *ptr){
size_t size = GET_SIZE(HDRP(ptr));
PUT(HDRP(ptr), PACK(size, 0));
PUT(FTRP(ptr), PACK(size, 0));
//立即合并
ptr = imme_coalesce(ptr);
add_block(ptr);
}
该函数首先修改已分配块的头部和脚部,将其置为空闲块,然后调用imme_coalesce函数进行立即合并,然后调用add_block函数将其插入合适的大小类的显示空闲链表中的合适位置。
接下来看看我们的mm_realloc函数
/*
* mm_realloc - Implemented simply in terms of mm_malloc and mm_free
*/
void *mm_realloc(void *ptr, size_t size){
size_t asize, ptr_size, remain_size;
void *new_bp;
if(ptr == NULL){
return mm_malloc(size);
}
if(size == 0){
mm_free(ptr);
return NULL;
}
asize = size<=DSIZE ? 2*DSIZE : DSIZE * ((size + (DSIZE) + (DSIZE-1)) / DSIZE);
new_bp = imme_coalesce(ptr); //尝试是否有空闲的
ptr_size = GET_SIZE(HDRP(new_bp));
PUT(HDRP(new_bp), PACK(ptr_size, 1));
PUT(FTRP(new_bp), PACK(ptr_size, 1));
if(new_bp != ptr)
memcpy(new_bp, ptr, GET_SIZE(HDRP(ptr)) - DSIZE);
if(ptr_size == asize){
return new_bp;
}else if(ptr_size > asize){
remain_size = ptr_size - asize;
if(remain_size >= DSIZE*2){ //分割
PUT(HDRP(new_bp), PACK(asize, 1));
PUT(FTRP(new_bp), PACK(asize, 1));
PUT(HDRP(NEXT_BLKP(new_bp)), PACK(remain_size, 0));
PUT(FTRP(NEXT_BLKP(new_bp)), PACK(remain_size, 0));
add_block(NEXT_BLKP(new_bp));
}
return new_bp;
}else{
if((ptr = mm_malloc(asize)) == NULL)
return NULL;
memcpy(ptr, new_bp, ptr_size - DSIZE);
mm_free(new_bp);
return ptr;
}
}
这里和之前介绍的思路是相同的。
其次,离散的空闲链表在指针方面比较容易出错,这里提供一个输出各个大小类的显示空闲链表的代码,用来检测是否有指针出错
static void print_listp(){
int ind;
void *node, *root;
printf("print listp\n");
for(ind=1;ind<=8;ind++){
node = listp+ind*WSIZE;
root = listp+ind*WSIZE;
printf("%d:\n",ind);
while(SUCC_BLKP(node)){
node = SUCC_BLKP(node);
printf("-->%p,%d",node, GET_SIZE(HDRP(node)));
}
printf("-->%p\n",SUCC_BLKP(node));
while(node!=root){
printf("<--%p,%d",node, GET_SIZE(HDRP(node)));
node = PRED_BLKP(node);
}
printf("<--%p\n",node);
}
}
然后下面是实验结果
立即合并+首次适配+LIFO:
trace valid util ops secs Kops
0 yes 98% 5694 0.000925 6158
1 yes 94% 5848 0.001066 5487
2 yes 98% 6648 0.001315 5054
3 yes 99% 5380 0.000914 5887
4 yes 66% 14400 0.001441 9991
5 yes 89% 4800 0.001068 4495
6 yes 85% 4800 0.001189 4037
7 yes 55% 12000 0.001854 6474
8 yes 51% 24000 0.003982 6027
9 yes 48% 14401 0.153353 94
10 yes 45% 14401 0.034466 418
Total 75% 112372 0.201572 557
Perf index = 45 (util) + 37 (thru) = 82/100
立即合并+最佳适配+LIFO:
Results for mm malloc:
trace valid util ops secs Kops
0 yes 99% 5694 0.001026 5548
1 yes 99% 5848 0.001052 5558
2 yes 99% 6648 0.001170 5682
3 yes 100% 5380 0.001103 4878
4 yes 66% 14400 0.001601 8993
5 yes 96% 4800 0.002048 2344
6 yes 95% 4800 0.001930 2487
7 yes 55% 12000 0.001934 6206
8 yes 51% 24000 0.004590 5229
9 yes 40% 14401 0.004290 3357
10 yes 45% 14401 0.003162 4555
Total 77% 112372 0.023907 4700
Perf index = 46 (util) + 40 (thru) = 86/100
立即合并+最佳适配+AddressOrder:
Results for mm malloc:
trace valid util ops secs Kops
0 yes 99% 5694 0.001086 5244
1 yes 99% 5848 0.001069 5473
2 yes 99% 6648 0.001304 5097
3 yes 100% 5380 0.001135 4738
4 yes 66% 14400 0.001509 9544
5 yes 96% 4800 0.003104 1546
6 yes 95% 4800 0.003175 1512
7 yes 55% 12000 0.020766 578
8 yes 51% 24000 0.071639 335
9 yes 40% 14401 0.004262 3379
10 yes 45% 14401 0.003016 4775
Total 77% 112372 0.112065 1003
Perf index = 46 (util) + 40 (thru) = 86/100
立即合并+首次适配+AddressOrder:
Results for mm malloc:
trace valid util ops secs Kops
0 yes 99% 5694 0.000945 6023
1 yes 99% 5848 0.001001 5843
2 yes 99% 6648 0.001177 5649
3 yes 100% 5380 0.000948 5676
4 yes 66% 14400 0.001481 9720
5 yes 93% 4800 0.002984 1608
6 yes 91% 4800 0.002907 1651
7 yes 55% 12000 0.020213 594
8 yes 51% 24000 0.070960 338
9 yes 40% 14401 0.004211 3420
10 yes 45% 14401 0.002934 4908
Total 76% 112372 0.109762 1024
Perf index = 46 (util) + 40 (thru) = 86/100
显示空闲链表
本次 lab,malloclab,自己手写一个内存分配器。
1. 实验目的
malloclab,简单明了的说就是实现一个自己的 malloc,free,realloc 函数。做完这个实验你能够加深对指针的理解,掌握一些内存分配中的核心概念,如:如何组织 heap,如何找到可用 free block,采用 first-fit, next-fit,best-fit? 如何在吞吐量和内存利用率之间做 trade-off 等。
就我个人的感受来说,malloclab 的基础知识不算难,但是代码中充斥了大量的指针运算,为了避免硬编码指针运算,会定义一些宏,而定义宏来操作则会加大 debug 的难度(当然了,诸如 linus 这样的大神会觉得,代码写好了,为什么还用 debug?),debug 基本只能靠 gdb 和 print,所以整体还是有难度了。
2. 背景知识
这里简单说一下要做这个实验需要哪些背景知识。
首先,为了写一个 alloctor, 需要解决哪些问题。csapp 本章的 ppt 中列出了一些关键问题:

第一个问题,free (ptr) 这样的 routine 是如何知道本次释放的 block 的大小的?
很显然我们需要一些额外的信息来存放 block 的元信息。之类的具体做法是在 block 的前面添加一个 word,存放分配的 size 和是否已分配状态。
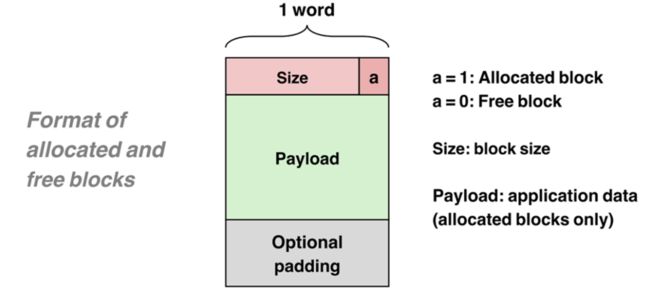
注意:这里只是给出了最简单的情况,实际操作中,额外的元数据不仅只有这些
第二个问题,如何追踪 free blocks?

csapp 一共给出了 4 种方案。其中 implicit list 在书上给出了源码,我个人实现了 implicit list 和 explicit list。segregated free list 感觉利用 OO 思想,把 explicit list 封装一下也是能够实现的,红黑树同理。
第三个问题,拆分策略(详见代码的 place 函数)
第四个问题,一般来说有 first-fit, next-fit 和 best-fit 策略,我这里采用了最简单的 first-fit 策略。(这其实是一个 trade-off 的问题,看你是想要吞吐量高还是内存利用率高了)
ok,下面就来看看 implicit list (书上有)和 explicit list 两种方案是如何实现的。
3. Implicit list
下面是一个 implicit list 的组织方式和一个 block 的具体情况,一个 block 采用了双边 tag,保证可以前向和后向索引。

这种方案的优点:实现简单。缺点:寻找 free block 的开销过大。
现在说说 lab 中给的一些代码把:
- memlib,这个文件中,给出了 heap 扩展的方法,除此之外,我们还可以获取当前可用 heap 的第一个字节,最后一个字节,heap size 等。具体实现是通过一个 sbrk 指针来操作的。
- mdriver, 这个文件不用看,只用它编译出来的可执行文件即可,用于测试我们写的 allocator 是否正确。
- mm.c, 这个就是我们要操作的文件了,主要实现三个函数 mm_malloc,mm_free,mm_realloc,我们再额外定义自己需要的函数。
好的,下面再说说具体代码,因为代码中涉及到很多指针操作,我们对这些操作做一个峰装,用宏定义来操作:
#define WSIZE 4 /* Word and header/footer size (bytes) */
#define DSIZE 8 /* Double word size (bytes) */
#define CHUNKSIZE (1<<12) /* Extend heap by this amount (bytes) */
#define MAX(x, y) ((x) > (y)? (x) : (y))
/* Pack a size and allocated bit into a word */
#define PACK(size, alloc) ((size) | (alloc))
/* Read and write a word at address p */
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val))
/* Read the size and allocated fields from address p */
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
/* Given block ptr bp, compute address of its header and footer */
#define HDRP(bp) ((char *)(bp) - WSIZE)
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
/* Given block ptr bp, compute address of next and previous blocks */
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE)))
注释给出了每个宏的意义。
一些额外的定义:
static void *free_list_head = NULL; // 整个list的头部
static void *extend_heap(size_t words); // heap 不够分配时,用于扩展heap大小
static void *coalesce(void *bp); // free block时,可能存在一些前后也是free block的情况,这时需要做合并,不允许一条list上,同时存在两个连续的free block
static void *find_fit(size_t size); // 在list上找到可满足本次malloc请求的block
static void place(void *bp, size_t size); // 放置当前块,如果size < 本次block size - MIN_BLOCK ,则需要做split操作
mm_init
这个函数对 mm 做初始化,工作包括:
- 分配 4 个字,第 0 个字为 pad,为了后续分配的块 payload 首地址能够是 8 字节对齐。
- 第 1-2 个字为序言块,free_list_head 指向这里,相当于给 list 一个定义,不然我们从哪里开始 search 呢?
- 第 3 个字,结尾块,主要用于确定尾边界。
- extend_heap, 分配一大块 heap,用于后续 malloc 请求时分配。
/*
* mm_init - initialize the malloc package.
*/
int mm_init(void)
{
// Create the inital empty heap
if( (free_list_head = mem_sbrk(4 * WSIZE)) == (void *)-1 ){
return -1;
}
PUT(free_list_head, 0);
PUT(free_list_head + (1 * WSIZE), PACK(DSIZE, 1));
PUT(free_list_head + (2 * WSIZE), PACK(DSIZE, 1));
PUT(free_list_head + (3 * WSIZE), PACK(0, 1));
free_list_head += (2 * WSIZE);
// Extend the empty heap with a free block of CHUNKSIZE bytes
if(extend_heap(CHUNKSIZE/WSIZE) == NULL){
return -1;
}
return 0;
}
extend_heap
工作:
- size 更新,保证 size 为偶数个 word
- 为当前分配的 block 添加元数据,即 header 和 footer 信息
- 更新尾边界
static void *extend_heap(size_t words)
{
char *bp;
size_t size;
/* Allocate an even number of words to maintain alignment */
size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE;
if( (long)(bp = mem_sbrk(size)) == -1 ){
return NULL;
}
// 初始化free block的header/footer和epilogue header
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1));
// Coalesce if the previous block was free
return coalesce(bp);
}
mm_malloc
mm_malloc 也比较简单,首先更改请求 size,满足 8 字节对齐 + 元数据的开销要求。接着尝试找到当前可用 heap 中是否有能够满足本次请求的 block,有则直接 place,无则需要扩展当前可用 heap 的大小,扩展后再 place。
/*
* mm_malloc - Allocate a block by incrementing the brk pointer.
* Always allocate a block whose size is a multiple of the alignment.
*/
void *mm_malloc(size_t size)
{
size_t asize; // Adjusted block size
size_t extendsize; // Amount to extend heap if no fit
char *bp;
if (size == 0)
return NULL;
// Ajust block size to include overhea and alignment reqs;
if (size <= DSIZE)
{
asize = 2 * DSIZE;
}
else
{
asize = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE); // 超过8字节,加上header/footer块开销,向上取整保证是8的倍数
}
// Search the free list for a fit
if ((bp = find_fit(asize)) != NULL)
{
place(bp, asize);
}
else
{
// No fit found. Get more memory and place the block
extendsize = MAX(asize, CHUNKSIZE);
if ((bp = extend_heap(extendsize / WSIZE)) == NULL)
{
return NULL;
}
place(bp, asize);
}
#ifdef DEBUG
printf("malloc\n");
print_allocated_info();
#endif
return bp;
}
find_fit
遍历整个 list,找到还未分配且满足当前请求大小的 block,然后返回该 block 的首地址。
/**
* @brief 使用first-fit policy
*
* @param size
* @return void* 成功,返回可用块的首地址
* 失败,返回NULL
*/
static void *find_fit(size_t size)
{
void *bp ;
for (bp = NEXT_BLKP(free_list_head); GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp))
{
if(GET_ALLOC(HDRP(bp)) == 0 && size <= GET_SIZE(HDRP(bp)))
{
return bp;
}
}
return NULL;
}
place
place 的工作也很简单:
- 最小块大小(2*DSIZE) <= 当前块的大小 - 当前请求的块大小 ,则对当前 block 做 split
- 否则,直接 place 即可。
现在继续看看 free:
/**
* @brief place block
*
* @param bp
* @param size
*/
static void place(void *bp, size_t size)
{
size_t remain_size;
size_t origin_size;
origin_size = GET_SIZE(HDRP(bp));
remain_size = origin_size - size;
if(remain_size >= 2*DSIZE) // 剩下的块,最少需要一个double word (header/footer占用一个double word, pyaload不为空,再加上对齐要求)
{
PUT(HDRP(bp), PACK(size, 1));
PUT(FTRP(bp), PACK(size, 1));
PUT(HDRP(NEXT_BLKP(bp)), PACK(remain_size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(remain_size, 0));
}else{
// 不足一个双字,保留内部碎片
PUT(HDRP(bp), PACK(origin_size, 1));
PUT(FTRP(bp), PACK(origin_size, 1));
}
}
mm_free
可以看到,free 也是相当简单的,将当前 block 的分配状态从 1 更新到 0 即可。然后做 coalesce 操作:
/*
* mm_free - Freeing a block does nothing.
*/
void mm_free(void *ptr)
{
size_t size = GET_SIZE(HDRP(ptr));
PUT(HDRP(ptr), PACK(size, 0));
PUT(FTRP(ptr), PACK(size, 0));
coalesce(ptr);
#ifdef DEBUG
printf("free\n");
print_allocated_info();
#endif
}
coalesce
free block 后要考虑前后是否也有 free block, 如果存在 free block 需要进行合并。下面给出了 4 种情况:


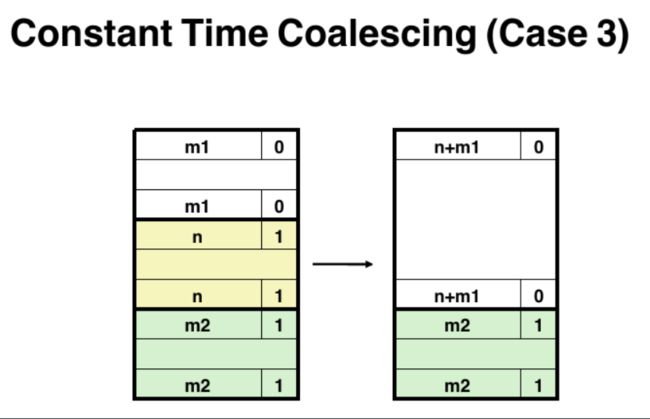

// 由于存在序言块和尾块,避免了一些边界检查。
static void *coalesce(void *bp)
{
size_t pre_alloc = GET_ALLOC(HDRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
size_t size = GET_SIZE(HDRP(bp));
if(pre_alloc && next_alloc){ // case1: 前后都分配
return bp;
}
else if(pre_alloc && !next_alloc){ // case 2: 前分配,后free
void *next_block = NEXT_BLKP(bp);
size += GET_SIZE(HDRP(next_block));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(next_block), PACK(size, 0));
// TODO: 其余两个tag不用清空? 正常情况确实不用清空。
}
else if(!pre_alloc && next_alloc){ // case 3: 前free,后分配
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
else { // 前后两个都是free
size += GET_SIZE(HDRP(PREV_BLKP(bp))) +
GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
return bp;
}
mm_realloc
realloc 函数实现也很简单,重新分配 size 大小的块,然后将旧块内容复制到新块内容上。注意这里也考虑了 block 变小的情况.
/*
* mm_realloc - Implemented simply in terms of mm_malloc and mm_free
*/
void *mm_realloc(void *ptr, size_t size)
{
void *oldptr = ptr;
void *newptr;
size_t copySize;
newptr = mm_malloc(size);
if (newptr == NULL)
return NULL;
copySize = GET_SIZE(HDRP(oldptr));
if (size < copySize)
copySize = size;
memcpy(newptr, oldptr, copySize);
mm_free(oldptr);
return newptr;
}
ok, 以上就是 implicit list 的所有内容,下面我们开始讲解 explicit list 的实现.
4. explicit list
explicit list 和 implicit list 的区别在于前者在 逻辑空间 中维护一个 free list, 里面只保存 free 的 blocks, 而后者则是在 虚拟地址空间中维护整个 list, 里面即包含了 free blocks 也包含了 allocated blocks. 当然了,explicit list 底层也是虚拟地址空间。下面这张图给出了 explicit list 的上层结构:
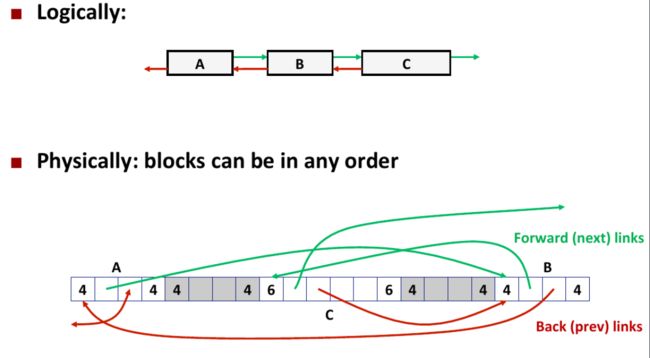
下面给出 implicit 和 explicit 的每一块的具体结构对比:

可以看到,explicit 比较 implicit, 每一个块只是多了两个字段,用于保存下一个 free block 的地址 (next) 和上一个 free block 的地址 (prev).
想一下,explict 的优点:大大提高搜索 free block 的效率。但是实现复杂度比 implicit 难,因为多一个逻辑空间的操作.
首先第一个问题,next 和 prev 占用多大空间?对于 32 位的 os 来说,地址空间的编址大小的 32 位 (4 字节), 64 位的 os 则位 64 位 (8 字节). 为了简单起见,本文中只考虑 32 位的情况 (gcc 编译时加上 - m32 的参数,默认的 makefile 已经给出).
好的现在确定了 next 和 prev 的大小,再来确定一个最小块的大小,最小块应该包含 header+footer+next+prev+payload, 其中 payload 最小为 1 个字节,同时最小块应该保证 8 字节对齐要求,综合以上所述,一个最小块为:
向上取字节对齐,则4+4+4+1+4=17,向上取8字节对齐,则 MINBLOCK=24ok, 现在再说明代码中做的一些规定:
- find 策略,采用 first-fit 策略
- 对于 free 后的 block 应该如何重新插入 free list, 本文采用 LIFO 策略
- 对齐约定,8 字节对齐
有了以上的说明,差不多就可以写代码了,先从定义的宏出发:
/* single word (4) or double word (8) alignment */
#define ALIGNMENT 8
/* rounds up to the nearest multiple of ALIGNMENT */
#define ALIGN(size) (((size) + (ALIGNMENT - 1)) & ~0x7)
#define SIZE_T_SIZE (ALIGN(sizeof(size_t)))
#define WSIZE 4 /* Word and header/footer size (bytes) */
#define DSIZE 8
#define CHUNKSIZE (1 << 12) /* Extend heap by this amount (bytes) */
#define MAX(x, y) ((x) > (y) ? (x) : (y))
/* Pack a size and allocated bit into a word */
#define PACK(size, alloc) ((size) | (alloc))
/* Read and write a word at address p */
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (unsigned int)(val))
/* Read the size and allocated fields from address p */
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) (GET(p) & 0x1)
/* Given block ptr bp, compute address of its header and footer */
#define HDRP(bp) ((char *)(bp)-3 * WSIZE)
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - 4 * WSIZE)
// free block运算:计算当前block的“NEXT"指针域
// bp:当前block的payload首地址
#define NEXT_PTR(bp) ((char *)(bp)-2 * WSIZE)
#define PREV_PTR(bp) ((char *)(bp)-WSIZE)
// free block运算: 计算下一个free block的payload首地址
// bp:当前block的payload首地址
#define NEXT_FREE_BLKP(bp) ((char *)(*(unsigned int *)(NEXT_PTR(bp))))
#define PREV_FREE_BLKP(bp) ((char *)(*(unsigned int *)(PREV_PTR(bp))))
// virtual address计算:计算下一个block的payload首地址
// bp: 当前block的payload首地址
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)))
#define PREV_BLKP(bp) ((char *)(bp)-GET_SIZE(HDRP(bp) - WSIZE))
可以看到,基本上和 implicit 的宏差不多,只是多了 NEXT_FREE_BLKP 这类宏,由于调整了每个 block 的具体 layout (多了 next 和 prev), 所以一些运算,如 HDRP 等需要对应调整.
然后就是各个函数:
NOTE: 再次注意存在逻辑空间和虚拟地址空间两个空间.
mm_init
这个函数的主要工作包括:
- 分配 一个 word+ MIN_BLOCK
- 第一个 word 是做 pad 用,用于保证后续分配的 block 能够 8 字节对齐,和 implicit 一样.
- 后面的 MIN_BLOCK 用于作为 free_list_head, 和 impilicit 的序言块作用相同
- 最后分配一个 CHUNK, 分配函数的内部会将这个 chunk 块插入到 free list 中.
整体来说,explicit 的 mm_init 和 implicit 的 mm_init 作用相同,但是组织方式发生了一些变化.
int mm_init(void)
{
// 申请一个块,用于存放root指针
char *init_block_p;
if ((init_block_p = mem_sbrk(MIN_BLOCK + WSIZE)) == (void *)-1)
{
return -1;
}
init_block_p = (char *)(init_block_p) + WSIZE; // 跳过首个对齐块
free_list_head = init_block_p + 3 * WSIZE;
PUT(PREV_PTR(free_list_head), NULL);
PUT(NEXT_PTR(free_list_head), NULL); // 初始化root指针为NULL(0)
PUT(HDRP(free_list_head), PACK(MIN_BLOCK, 1));
PUT(FTRP(free_list_head), PACK(MIN_BLOCK, 1));
// Extend the empty heap with a free block of CHUNKSIZE bytes
if ((allocate_from_chunk(CHUNKSIZE)) == NULL)
{
return -1;
}
return 0;
}
allocate_from_heap
allocate_from_heap 做的工作很简单,扩展 heap 大小,然后将扩展出来的 block 插入到 free_lilst 中.
/**
* @brief 扩展heap,并分配满足当前需求的块到free_list中
*
* @param size 需求size 字节为单位
* @return void* 成功:当前能够分配的块的首地址
* 失败: NULL, 一般只在run out out memory时才会NULL
*/
static void *allocate_from_heap(size_t size)
{
void *cur_bp = NULL;
size_t extend_size = MAX(size, CHUNKSIZE);
if ((cur_bp = extend_heap(extend_size / WSIZE)) == NULL)
{
return NULL;
}
// 插入到free list中
insert_to_free_list(cur_bp);
return cur_bp;
}
extend_heap
/**
* @brief 扩展当前heap
*
* @param words 需要扩展的words, 字为单位
* @return void* 当前可用块的payload首地址
*/
static void *extend_heap(size_t words)
{
char *bp;
size_t size;
/* Allocate an even number of words to maintain alignment */
size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE;
if ((long)(bp = mem_sbrk(size)) == -1)
{
return NULL;
}
bp = (char *)(bp) + 3 * WSIZE; // point to payload
// set 本块信息
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
return bp;
}
insert_to_free_list
/**
* @brief 将free block插入到free list中
*
* @param bp free block的payload的首个地址
*/
static void insert_to_free_list(void *bp)
{
void *head = free_list_head;
void *p = NEXT_FREE_BLKP(head); // 当前首个有效节点 或者 NULL
if (p == NULL)
{
PUT(NEXT_PTR(head), bp);
PUT(NEXT_PTR(bp), NULL);
PUT(PREV_PTR(bp), head);
}
else
{
// 更新当前要插入的节点
PUT(NEXT_PTR(bp), p);
PUT(PREV_PTR(bp), head);
// 更新head
PUT(NEXT_PTR(head), bp);
// 更新p节点(原首有效节点)
PUT(PREV_PTR(p), bp);
}
}
采用 LIFO 策略,将 bp 所指向的 block 插入到 free_list 中.
mm_malloc
注释中说了本函数的工作。首先从 free_list 中看有没有适合的块,否则从 heap 中分配.
/*
* mm_malloc, 根据 size 返回一个指针,该指针指向这个block的payload首地址
* 主要工作:
* 1. size的round操作,满足最小块需求以及对齐限制
* 2. 首先检查当前free list中是否有可以满足 asize(adjusted size) ,有则place,(place可能需要split),无则第3步
* 3. 从当前heap中分配新的free block, 插入到free list中,然后place
*
*/
void *mm_malloc(size_t size)
{
size_t asize; // Adjusted block size
char *bp;
if (size == 0)
return NULL;
// step1: round size 满足最小块和对齐限制
asize = ALIGN(2 * DSIZE + size); // 2*DSIZE = header+ footer + next + prev
// step2: 从free list 中找free block
if ((bp = find_fit(asize)) != NULL)
{
place(bp, asize);
}
else
{ //free list中找不到
// step3: 从当前heap中分配
if ((bp = allocate_from_heap(asize)) == NULL)
{
return NULL;
}
place(bp, asize);
}
#ifdef DEBUG
printf("malloc\n");
debug();
#endif
return bp;
}
find_fit
从 free list 中找到第一个满足需求 size 的 free block 并返回该 block 的 payload 首地址.
/**
* @brief 使用first-fit policy
*
* @param size
* @return void* 成功,返回可用块的首地址
* 失败,返回NULL
*/
static void *find_fit(size_t size)
{
void *bp;
for (bp = NEXT_FREE_BLKP(free_list_head); bp != NULL && GET_SIZE(HDRP(bp)) > 0; bp = NEXT_FREE_BLKP(bp))
{
if (GET_ALLOC(HDRP(bp)) == 0 && size <= GET_SIZE(HDRP(bp)))
{
return bp;
}
}
return NULL;
}
place
本函数实现,将 bp 所指向的 free block 在可能的情况下做 split. 具体来说,是当当前 free block 的 size >= 请求 size + 最小 block 时会做 split.
/**
* @brief place block
*
* @param bp
* @param size
*/
static void place(void *bp, size_t size)
{
size_t origin_size;
size_t remain_size;
origin_size = GET_SIZE(HDRP(bp));
remain_size = origin_size - size;
if (remain_size >= MIN_BLOCK)
{
// 可拆分
// 设置拆分后剩下的块的size和allocate情况
char *remain_blockp = (char *)(bp) + size;
PUT(HDRP(remain_blockp), PACK(remain_size, 0));
PUT(FTRP(remain_blockp), PACK(remain_size, 0));
// 更新指针,将剩下块加入到free list中
char *prev_blockp = PREV_FREE_BLKP(bp);
char *next_blockp = NEXT_FREE_BLKP(bp);
PUT(NEXT_PTR(remain_blockp), next_blockp);
PUT(PREV_PTR(remain_blockp), prev_blockp);
PUT(NEXT_PTR(prev_blockp), remain_blockp);
if (next_blockp != NULL)
{
PUT(PREV_PTR(next_blockp), remain_blockp);
}
// 设置分配的块
PUT(HDRP(bp), PACK(size, 1));
PUT(FTRP(bp), PACK(size, 1));
// 断开原block与free list的连接
PUT(NEXT_PTR(bp), NULL);
PUT(PREV_PTR(bp), NULL);
}
else
{
// 不可拆分
// 更新header和footer
PUT(HDRP(bp), PACK(origin_size, 1));
PUT(FTRP(bp), PACK(origin_size, 1));
// 移除free block from free list
delete_from_free_list(bp);
}
}
delete_from_free_list
/**
* @brief 从free list中删除 bp 所在节点
*
* @param bp
*/
static void delete_from_free_list(void *bp)
{
void *prev_free_block = PREV_FREE_BLKP(bp);
void *next_free_block = NEXT_FREE_BLKP(bp);
if (next_free_block == NULL)
{
PUT(NEXT_PTR(prev_free_block), NULL);
}
else
{
PUT(NEXT_PTR(prev_free_block), next_free_block);
PUT(PREV_PTR(next_free_block), prev_free_block);
// 断开连接
PUT(NEXT_PTR(bp), NULL);
PUT(PREV_PTR(bp), NULL);
}
}
mm_free
这里的 free 函数和 implicit list 的 free 函数一致,重点在 coalesce 函数.
/*
* mm_free - Freeing a block does nothing.
*/
void mm_free(void *ptr)
{
size_t size = GET_SIZE(HDRP(ptr));
PUT(HDRP(ptr), PACK(size, 0));
PUT(FTRP(ptr), PACK(size, 0));
coalesce(ptr);
#ifdef DEBUG
printf("free\n");
debug();
#endif
}
coalesce
coalesce 是每种分配器的重点,需要考虑如何合并在虚拟地址空间中的相邻 blocks 之间的关系,和 implicit 一样,explicit 也有 4 种情况:




/**
* @brief 合并地址空间,并将可用free block插入到free list中
*
* @param bp 当前block的payload首地址
*
*/
static void coalesce(void *bp)
{
char *prev_blockp = PREV_BLKP(bp);
char *next_blockp = NEXT_BLKP(bp);
char *mem_max_addr = (char *)mem_heap_hi() + 1; // heap的上边界
size_t prev_alloc = GET_ALLOC(HDRP(prev_blockp));
size_t next_alloc;
if (next_blockp >= mem_max_addr)
{ // next_block超过heap的上边界,只用考虑prev_blockp
if (!prev_alloc)
{
case3(bp);
}
else
{
case1(bp);
}
}
else
{
next_alloc = GET_ALLOC(HDRP(next_blockp));
if (prev_alloc && next_alloc)
{ // case 1: 前后都已经分配
case1(bp);
}
else if (!prev_alloc && next_alloc)
{ //case 3: 前未分配,后分配
case3(bp);
}
else if (prev_alloc && !next_alloc)
{ // case 2: 前分配,后未分配
case2(bp);
}
else
{ // case 4: 前后都未分配
case4(bp);
}
}
}
case1
/**
* @brief 前后都分配
*
* @param bp
* @return void*
*/
static void *case1(void *bp)
{
insert_to_free_list(bp);
return bp;
}
case2
/**
* @brief 前分配后未分配
*
* @param bp
* @return void*
*/
static void *case2(void *bp)
{
void *next_blockp = NEXT_BLKP(bp);
void *prev_free_blockp;
void *next_free_blockp;
size_t size = GET_SIZE(HDRP(bp)) + GET_SIZE(HDRP(next_blockp));
// 更新块大小
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(next_blockp), PACK(size, 0));
// 更新前后free block指针
prev_free_blockp = PREV_FREE_BLKP(next_blockp);
next_free_blockp = NEXT_FREE_BLKP(next_blockp);
// 边界检查
if (next_free_blockp == NULL)
{
PUT(NEXT_PTR(prev_free_blockp), NULL);
}
else
{
PUT(NEXT_PTR(prev_free_blockp), next_free_blockp);
PUT(PREV_PTR(next_free_blockp), prev_free_blockp);
}
insert_to_free_list(bp);
return bp;
}
case3
/**
* @brief case 3 前一个block未分配,后一个块已分配
*
* @param bp 当前块的payload首地址
* @return void* 合并后的payload首地址
*/
static void *case3(void *bp)
{
char *prev_blockp = PREV_BLKP(bp);
char *prev_free_blockp;
char *next_free_blockp;
size_t size = GET_SIZE(HDRP(bp)) + GET_SIZE(HDRP(prev_blockp));
// 更新块大小
PUT(HDRP(prev_blockp), PACK(size, 0));
PUT(FTRP(prev_blockp), PACK(size, 0));
// 找到前后free块并更新
next_free_blockp = NEXT_FREE_BLKP(prev_blockp);
prev_free_blockp = PREV_FREE_BLKP(prev_blockp);
// 边界检查
if (next_free_blockp == NULL)
{
PUT(NEXT_PTR(prev_free_blockp), NULL);
}
else
{
PUT(NEXT_PTR(prev_free_blockp), next_free_blockp);
PUT(PREV_PTR(next_free_blockp), prev_free_blockp);
}
// LIFO策略,插入到free list的头部
insert_to_free_list(prev_blockp);
return bp;
}
case4
/**
* @brief 前后都未分配
*
* @param bp
* @return void*
*/
static void *case4(void *bp)
{
void *prev_blockp;
void *prev1_free_blockp;
void *next1_free_blockp;
void *next_blockp;
void *prev2_free_blockp;
void *next2_free_blockp;
size_t size;
prev_blockp = PREV_BLKP(bp);
next_blockp = NEXT_BLKP(bp);
// 更新size
size_t size1 = GET_SIZE(HDRP(prev_blockp));
size_t size2 = GET_SIZE(HDRP(bp));
size_t size3 = GET_SIZE(HDRP(next_blockp));
size = size1 + size2 + size3;
PUT(HDRP(prev_blockp), PACK(size, 0));
PUT(FTRP(next_blockp), PACK(size, 0));
bp = prev_blockp;
// 更新前半部 free block指针
prev1_free_blockp = PREV_FREE_BLKP(prev_blockp);
next1_free_blockp = NEXT_FREE_BLKP(prev_blockp);
if (next1_free_blockp == NULL)
{
PUT(NEXT_PTR(prev1_free_blockp), NULL);
}
else
{
PUT(NEXT_PTR(prev1_free_blockp), next1_free_blockp);
PUT(PREV_PTR(next1_free_blockp), prev1_free_blockp);
}
// 更新后半部 free block指针
prev2_free_blockp = PREV_FREE_BLKP(next_blockp);
next2_free_blockp = NEXT_FREE_BLKP(next_blockp);
if (next2_free_blockp == NULL)
{
PUT(NEXT_PTR(prev2_free_blockp), NULL);
}
else
{
PUT(NEXT_PTR(prev2_free_blockp), next2_free_blockp);
PUT(PREV_PTR(next2_free_blockp), prev2_free_blockp);
}
// 根据LIFO策略插入free list
insert_to_free_list(bp);
return bp;
}
其余 debug 用的函数
static void debug()
{
print_allocated_info();
print_free_blocks_info();
consistent_check();
}
/**
* @brief 打印分配情况
*/
static void print_allocated_info()
{
char *bp;
size_t idx = 0;
char *mem_max_addr = mem_heap_hi();
printf("=============start allocated info===========\n");
for (bp = NEXT_BLKP(free_list_head); bp < mem_max_addr && GET_SIZE(HDRP(bp)) > 0; bp = NEXT_BLKP(bp))
{
if (GET_ALLOC(HDRP(bp)) == 1)
{
++idx;
printf("block%d range %p %p size=%d, payload %p %p block size=%d\n", idx, HDRP(bp), FTRP(bp) + WSIZE, FTRP(bp) - HDRP(bp) + WSIZE, (char *)bp, FTRP(bp), FTRP(bp) - (char *)(bp));
}
}
printf("=============end allocated info===========\n\n");
}
static void consistent_check()
{
// 检查free list中的所有block都为free
char *bp;
char *mem_max_heap = mem_heap_hi();
for (bp = NEXT_FREE_BLKP(free_list_head); bp != NULL; bp = NEXT_FREE_BLKP(bp))
{
if (GET_ALLOC(HDRP(bp)))
{
printf("%d free list中存在块已分配\n", __LINE__);
}
}
// 检查是否所有free block都在free list中
for (bp = NEXT_BLKP(free_list_head); bp <= mem_max_heap; bp = NEXT_BLKP(bp))
{
if (!GET_ALLOC(HDRP(bp)) && !is_in_free_list(bp))
{
printf("%d 存在free block %p 不在free list中\n", __LINE__, bp);
}
}
}
static int is_in_free_list(void *bp)
{
void *p;
for (p = NEXT_FREE_BLKP(free_list_head); p != NULL; p = NEXT_FREE_BLKP(p))
{
if (p == bp)
{
return 1;
}
}
return 0;
}
上面就是整个 explicit list 的实现了。最终实现的效果是,跑完所有 trace file, 得分 83/100. 算是个良水平吧。要想实现优秀水平,可以考虑做做 segregated list 或者 red block tree list.
再谈一些优化:
- 空间优化,对于分配的 block, 可以不存储 NEXT 和 PREV 指针,从而扩大 payload 空间,提高空间利用率.
- 封装整个 free list, 然后改用 segregated list.
- 现在 search 策略是从头 search 到尾部,, 比较慢,可以针对每个 free block 建立 index, index 数据结构选择 rbtree, 应该可以大大提高分配吞吐量.
5. 总结
嗯,个人觉得这个 lab 仅次于 cachelab, 但是它的难点不在于思路,而在于如何调试,毕竟像我这样的菜鸡,不 debug 是不可能,这辈子都不可能不 debug 的,而这次 lab 有很多 macros, 就很难在 gdb 中调试,gdb 中也只能通过 exam 命令查看连续的地址内存空间,但是当 trace file 中给定的 malloc size 过大时,exam 命令也很难快速查看,所以个人在做的时候,将 trace file 的 malloc size 手动改小了 (当然后面还是改回去了的), 然后 debug 就会相对轻松一些.
原文链接
https://zhuanlan.zhihu.com/p/126341872
https://www.ravenxrz.ink/archives/36920455.html