BEVFusion4D论文阅读
链接
论文:https://arxiv.org/abs/2303.17099
Abstract
将激光雷达和相机信息聚合到鸟瞰图(BEV)中已成为自动驾驶中三维目标检测的一个重要课题。现有的方法大多采用独立的双分支框架来生成激光雷达和相机BEV,然后进行自适应模态融合。由于点云提供了更准确的定位和几何信息,它们可以作为从图像中获取相关语义信息的可靠空间先验。因此,我们设计了一种激光雷达引导的视图变换器 LiDAR-Guided View Transformer(LGVT)来有效地获得相机在BEV空间中的表示,从而有利于整个双分支融合系统。LGVT以相机BEV作为原始语义查询,反复利用激光雷达BEV的空间线索提取多个相机视图的图像特征。此外,我们提出时间可变形对齐 Temporal Deformable Alignment(TDA)模块将我们的框架扩展到时间域,该模块旨在从多个历史帧中聚合BEV特征。有了这两个模块,我们的框架BEVFusion4D在3D目标检测中取得了最先进的结果,在nuScenes验证集上分别达到了72.0%mAP和73.5% NDS,在nuScenes测试集上达到了73.3%mAP和74.7% NDS。
整体框架图如下:

Introduction
三维物体检测的任务多年来引起了广泛的关注,并在自动驾驶方面变得越来越普遍。激光雷达和相机传感器作为两种基本模式,能够以不同的方式获取周围环境。由激光雷达传感器产生的点云通过发射的波长来感知场景。它擅长于描绘物体的精确空间位置并提供可靠的几何信息。与点云相比,图像数据记录了一个高度详细的场景图像,并携带了更密集的语义和纹理信息。因此,它被认为是对前一个传感器的关键补充。尽管存在挑战,整合来自两种不同模式的感知信息被认为是一个具有高价值的研究领域。
由于激光雷达和相机的固有特性,如何有效整合两种模式仍有待研究。基于查询的方法,如TransFusion,提出了一个两阶段的pipeline来顺序关联激光雷达和图像特征。然而,系统的性能在很大程度上取决于查询初始化策略。最近的工作已经证明了双分支融合框架的有效性。如图1(a)所示,来自主干的编码特征被转移并统一在一个中间特征表示,如鸟视图(BEV),虽然这个范式在社会上获得流行,相机感知几何信息的困难还是限制了摄像机分支的作用,阻碍了系统在图像数据中融合语义信息。

为了有效利用摄像机数据并在融合过程中进一步维护语义信息,我们提出了一种简单而有效的解决方案,旨在通过并行激光雷达的显式指导来增强相机的BEV特征。在图1的(c)中,我们设计了一个基于注意力的相机视图转换器,名为LGVT。它学习了通过激光雷达的先验来有效地获取目标的语义信息。由于激光雷达的点云描述了场景相对准确的空间分布,它们可以作为标定目标相关语义的关键先验,从而为融合提供更有价值的信息。在图2中,我们比较了BEVFusion与我们框架中的相机BEV的可视化结果。受益于激光雷达的空间先验,我们的相机BEV特征可以很容易地区分场景轮廓和目标位置,而这在BEVFusion中是不可见的。

另一方面,在相邻帧中编码的互补视图和运动线索激发了最近的工作,即将时间信息聚合到框架中。作为先驱,LIFT标志着在融合框架中利用时空信息的初步尝试。如图1(b)所示,它将输入的四维数据作为一个集成的实体,通过经典的transformer架构直接聚合顺序的跨传感器数据。然而,由于全局自注意机制,融合系统存在计算过载。相比之下,我们将时空特征融合到两个单独的模块中,以显著降低总体成本,降低时空信息集成的复杂性。此外,为了有效地聚合连续帧的空间融合的BEV特征,我们提出了一个基于可变形注意策略的时间融合模块。利用动态关系建模和稀疏采样的能力,我们提出的模块学习以一种协同有效的方式跨长度地将时间特征关联起来。我们还证明,我们的模块提供了对齐运动物体的时间特征的潜力,而不需显式的运动校准。
在本文中,我们提出了BEVFusion4D和两个时空域的专用模块,以促进多帧跨模态信息聚合。我们将我们的贡献总结为三个方面:
1)我们提出了BEVFusion4D,一个有效的融合框架来学习时空领域的整体特征表示;
2)我们提出的 LGVT 旨在通过空间先验生成高效的相机BEV,促进语义信息的传播,有利于空间域的特征融合。此外,我们还设计了一个时间可变形对齐模块(TDA)来覆盖来自相邻帧的补充信息;
3)我们对nuScenes数据集的检测轨迹进行了广泛的研究,以验证我们方法的性能,并在仅空间情况和时空情况下都得到了领先。
Related Work
1. 3D Object Detection with Single Modality
基于单模态的三维检测的目的是以三维边界盒的形式预测目标信息,给出仅来自一个主要源的传感结果,如激光雷达点云或相机图像。基于激光雷达传感器输入的方法要么直接从一组分散的点回归对象预测,要么将它们转换为一个统一的网格。例如,PointNet等基于点的方法使用点云,并从端到端的网络聚合其特征。另一组工作从柱状编码、体素编码或范围图像编码的角度来处理这个问题,并通过检测器对所编码的特征进行处理。相比之下,基于相机的方法通常通过二维图像主干提取依赖于视图的密集图像特征,并组成统一的三维特征表示(如BEV)进行三维预测。受LSS启发,通过预测每个特征点的离散深度分布,将编码的二维图像特征投影到三维网格中。BEVDepth 进一步使用深度监督,以呈现更好的特征视锥。受DETR启发的其他最近的工作提出通过transformer架构来建模图像特征之间的交互,并通过一组对象查询产生最终的预测。虽然大多数方法在该领域取得了实质性的改进,但从多个传感器源收集信息通常超出了他们的领域。
2. 3D Object Detection with Multi-Modalities
最近的趋势也对基于多模态的三维检测提供了越来越多的认识,并相信来自多个来源的信息将相互补偿,有利于整体检测结果。作为先驱之一,PointPainting开辟了一种点级融合的方法,将从语义分割网络中检索到的图像语义信息附加到输入点中,从而实现模态交互。最近的研究试图将不同概念的相应形态特征联系起来。BEVFusion推导出了一个在BEV空间中进行模态融合的有效框架;而有些方法利用类DETR结构,用注意力机制来加强特征之间的自适应关系。与现有的方法相比,我们的工作受到基于bev的解决方案的启发,保持了整体框架的简单性,但却实现了很好的性能。
3. Temporal Fusion in 3D Object Detection
时间信息可以提供物体的运动线索和互补视角,因此很重要。这激发了在目标检测任务中探索时间融合的各种建议。例如,4D-Net开发了一个具有动态连接学习的网络,逐步融合时序激光雷达和RGB图像序列。Huang等人利用LSTM的效果来建模时间特征相关性。PETRV2扩展了3D位置编码,以实现时间对齐,并及时融合图像特征。BEVFormer通过流行的可变形transformer构建时空图像信息的交互。LIFT提出了一种基于全局自注意力机制的多模态传感器融合的时空融合框架。然而,使用这种策略直接融合4D特征将带来不必要的计算成本,并阻碍有效的信息交换。相比之下,我们在空间融合的BEV特征之上实现了时间集成,这大大减少了计算预算。受BEVFormer的启发,我们还采用了可变形transformer,通过时间稀疏采样策略有效地合并特征。
Method
我们首先在Sec 3.1中介绍了特征提取。Sec 3.2提供了空间融合的步骤,并详细解释了我们的LGVT模块。上述两个阶段在每个时间帧上进行相同的操作。此外,我们基于所提出的TDA模块,在Sec 3.3描述了我们的时间融合方法。
1. LiDAR and Camera Features Extraction
在特征提取阶段,我们采用以往工作(北大和MIT的BEVFusion)的双分支范式来处理跨空间数据。具体来说,当前时间的激光雷达点云和多视图图像被输入两个独立的骨干,形成高层次的特征表示。对于激光雷达分支,输入点云P通过体素化转换成一个统一的网格,并进一步用三维稀疏卷积处理形成BEV空间的特征表示![]() 。图像主干采用多视图图像数据生成二维图像特征 I。然后,在接下来的空间融合阶段,对提取的激光雷达与图像特征进行融合。
。图像主干采用多视图图像数据生成二维图像特征 I。然后,在接下来的空间融合阶段,对提取的激光雷达与图像特征进行融合。
2.Spatial BEV Features Fusion
从激光雷达和图像提取的特征分别提供了几何信息和语义信息。为了进一步将这些特征合并到一个统一的BEV空间中,需要进行一个视图转换,将多个二维图像特征投影到相机BEV空间中。以往BEVFusion的方法选择LSS,通过将二维特征提升到具有不同深度概率的三维空间中来实现这一任务。然而,由于该模块缺乏可靠的深度监督,通常会导致性能较差。相比之下,我们依赖于预先训练的激光雷达的相对准确的空间信息来获得相应的语义特征。这使得我们提出的LGVT能够有效地将二维图像特征投影到BEV空间中。
LiDAR-Guided View Transformer Module:
LGVT利用可变形注意力模块,在激光雷达空间先验的指导下,将二维图像特征转换为BEV特征。图4(a)为LGVT模块的体系结构。在第i层,模块将前一层的相机BEV特征和激光雷达的BEV特征融合到查询特征,然后使用2D图像特征 I 执行可变形交叉注意力,来更新相机BEV特征。(这其实就是一层encoder的操作,然后不断重复n次。在encoder的每一层中,LGVT使用了deformable cross attention将2D image features变换为BEV features)。LGVT模块可以用如下方程描述:

其中为第i层的相机BEV特征,f为concat操作。

Camera BEV Feature Initialization:
如图4(b),在第一层,我们为一个空的相机BEV特征预定义了N个高度,并通过将每个BEV网格填充相应的二维图像特征来初始化它。具体来说,对于一个具有坐标(i,j)的空的相机BEV特征网格,我们为其预先定义了N个高度{h1,h2,...,hN },并使用内外参将![]() 投影到2D多视图图像特征。然后对每个高度的最大图像特征进行采样,并计算所有视图中有效图像特征的平均值。最后,利用采样的图像特征对相机BEV进行初始化。该流程可表述如下:
投影到2D多视图图像特征。然后对每个高度的最大图像特征进行采样,并计算所有视图中有效图像特征的平均值。最后,利用采样的图像特征对相机BEV进行初始化。该流程可表述如下:

其中,M为视图数,![]() 为有效采样位置的数量,n = 1,...,N,m = 1,...,M。
为有效采样位置的数量,n = 1,...,N,m = 1,...,M。![]() 是在第m个视图下与
是在第m个视图下与![]() 对应的二维图像特征中的坐标,Project是投影矩阵,Sample是在(x,y)处对二维图像特征进行采样的双线性图像插值过程。
对应的二维图像特征中的坐标,Project是投影矩阵,Sample是在(x,y)处对二维图像特征进行采样的双线性图像插值过程。
LiDAR-Camera BEV Features Fusion:
像BEVFusion中常见的那样,我们只是简单地将激光雷达和相机的BEV特征连接起来,并将结果送入卷积层。融合过程可表述如下:
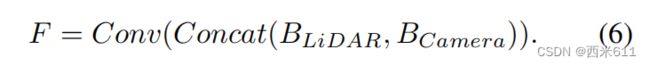
3. Temporal BEV Features Fusion
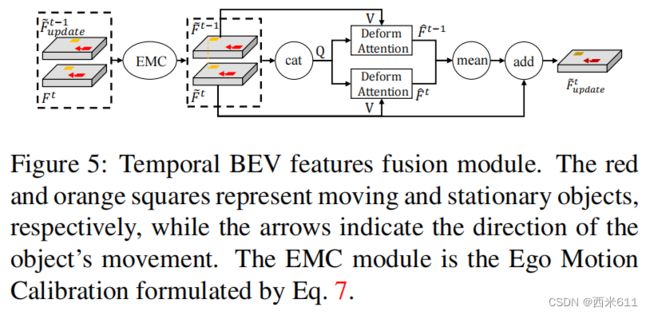
目标的历史位置和方向信息有利于其当前的运动估计。此外,时间信息还可以帮助检测当前时间内的远程、近距离或被遮挡的物体。因此,BEVFusion4D对历史BEV特征采用了时间融合。具体来说,首先根据自车运动信息对过去的BEV特征进行校准,然后在时间可变形对齐模块中进一步对齐两帧之间的移动对象以获得时间融合的BEV特征。(该部分的内存成本和计算预算可忽略)
Ego Motion Calibration:
图5显示了我们的时间BEV特征融合模块的架构。
按时间顺序存储的融合BEV特征记为。BEVFusion4D基于自车的时间运动信息,将每个BEV特征![]() 与下一个BEV特征对齐。此校准过程可用以下公式来描述:
与下一个BEV特征对齐。此校准过程可用以下公式来描述:
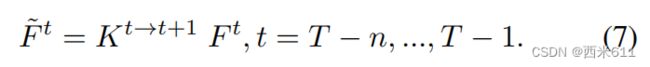
矩阵称为在时刻t与对齐的自车运动变换矩阵。
由等式7所描述的校准过程由于缺乏运动信息,仅限于对齐静止的物体。因此,移动的物体可能在没有任何校准的情况下表现出运动涂抹(exhibit motion smear),并且随着历史BEV特征的增加,运动涂抹效果可能会变得更加明显(图6可视化)。
Temporal Deformable Alignment:
为了缓解这一挑战,我们采用可变形的注意力机制来建立连续帧之间的对应关系。可变形的注意力机制被设计用于自适应地学习感受野,从而能够有效地捕捉到对齐的BEV特征中运动物体的显著特征。利用可变形注意力机制,可以显著减少运动涂抹,提高对齐过程的准确性。我们提出了时间可变形对齐(TDA)来进行特定于移动物体的时间融合。
我们用![]() 和分别表示在式7中校准过的BEV特征和用TDA进行时序融合的BEV特征。首先,TDA将两个连续的校准后的帧和
和分别表示在式7中校准过的BEV特征和用TDA进行时序融合的BEV特征。首先,TDA将两个连续的校准后的帧和![]() 级联作为
级联作为![]() ,然后利用可变形注意力机制,使用
,然后利用可变形注意力机制,使用![]() 得到
得到![]() 和作为query查询,将和
和作为query查询,将和![]() 作为values值。然后,TDA计算
作为values值。然后,TDA计算![]() 和的平均值,通过将其添加到帧
和的平均值,通过将其添加到帧![]() 来更新帧
来更新帧![]() 。更新过的可以用于后续的BEV特征的融合。该流程可表述如下:
。更新过的可以用于后续的BEV特征的融合。该流程可表述如下:
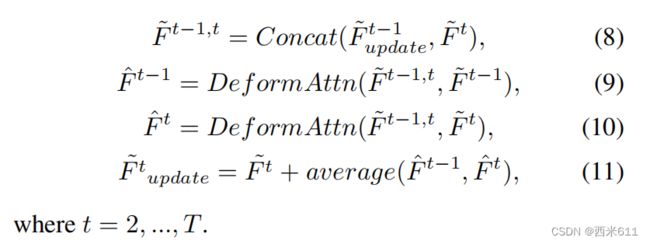
Experiments
在本节中,我们将介绍实验结果来解释我们的框架的原理。在此之外,使用一些消融研究来说明我们的两个模型组件的好处。
1. Experimental Setups
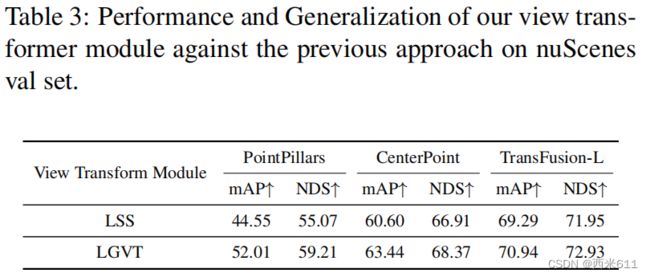
实现细节:在PyTorch中使用开源的MMDetection3D实现我们的网络。对于图像分支,我们使用以FPN [21]为特征提取器的Dual-Swin-Tiny,从在COCO上预训练的实例分割模型Cascade Mask R-CNN中初始化,然后采用了(北大的)BEVFusion使用的nuImage。对于激光雷达分支,选择VoxelNet 作为主干。至于LGVT模块,我们将柱子的高度和层数分别分别设置为4和3。对于时间融合,我们总共使用五帧作为输入。我们将图像大小设置为448×800,体素大小设置为(0.075m,0.075m,0.2m)。我们的训练包括两个阶段: i)我们首先对仅激光雷达的探测器训练20轮;ii)然后对BEVFusion4D进行联合训练6轮。在第二个训练阶段,我们冻结了图像分支的权值,这是以往方法中常用的训练策略。对于数据增强,采用bev空间数据增强。采用AdamW进行优化,学习率为![]() ,权重衰减为
,权重衰减为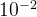 。我们在推理过程中不使用测试时间增强(TTA)或多模型集成。
。我们在推理过程中不使用测试时间增强(TTA)或多模型集成。
2. Comparisons with Previous Results
表1和表2分别列出了我们在验证和测试数据集上与之前的方法的比较结果。我们的无时间融合模型(BEVFusion4D-S)优于以往的方法,在验证集中达到了(70.9% mAP,72.9% NDS),在测试集中达到了(71.9% mAP,73.7% NDS)。此外,我们的方法在大多数检测类别中(验证集中9/10和测试集中7/10)上都超过了以前最先进的。这种整体性能增益可以归因于我们提出的LGVT模块,它强调了激光雷达在产生高效相机BEV方面的空间先验。我们还注意到,我们的方法在很大程度上提高了对某些类别(如卡车)的检测。由于像卡车这样的物体通常跨越多个摄像机帧,但反而在激光雷达中被记录作为一个整体,激光雷达的先验提供了对这种类型的物体的更完整的空间描述。
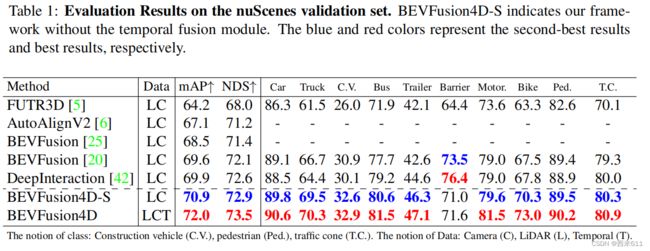
我们还比较了我们的时空框架BEVFusion4D与之前的Sota方法。如表2所示,BEVFusion4D在验证集中实现了72.0%的mAP和73.5%的NDS,并在9/10个类别中实现了持续的性能提高。在测试集中,BEVFusion4D达到了73.3% mAP和74.7% NDS的最新性能,在大多数类别中排名第一。
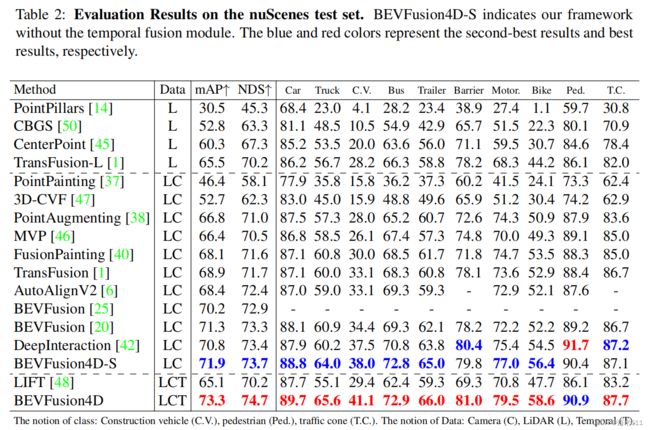
3. Ablation Studies
The performance and generalization of the proposed
LGVT:
显式的Lidar引导提升很大。
Results of the proposed TDA module:
逐渐增加输入帧的长度可以获得1.0%的mAP和0.6%的NDS提升,这意味着我们的方法能够在长时间跨度内聚合历史信息。同时,可变形的注意力机制有助于解决运动物体中的运动涂抹问题(不使用性能会下降,如图6)。


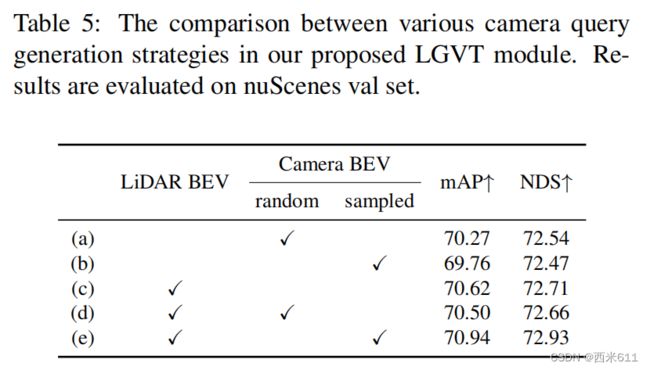
Query strategy in LGVT:
在表5中,我们比较了LGVT中的各种相机查询策略,以验证我们的跨模态查询交互的必要性。我们首先研究了给定单一模态输入的查询生成策略的影响(表5中的(a)-(c))。(a)表示仅使用随机初始化的相机BEV作为查询。(b)表示只使用我们初始化的相机BEV作为查询(即等式3-5) 。在(c)中,查询只是由LiDAR BEV初始化。我们观察到,仅使用激光雷达BEV来初始化的相机查询(c)比基于相机BEV的方法有了性能提高。这可能是由于激光雷达BEV中隐藏了有效的空间信息,为提取相关目标的图像特征提供了更可靠的参考。然后,我们探讨了在查询生成策略中与LiDAR BEV的兼容性(表5中的(d)-(e))。通过在相机查询中强制执行激光雷达BEV,我们发现我们的方法(e)与随机的(d)相比,性能有所提高。这表明激光雷达BEV与我们的采样后的相机BEV更兼容,因为它们都是依赖于输入的。
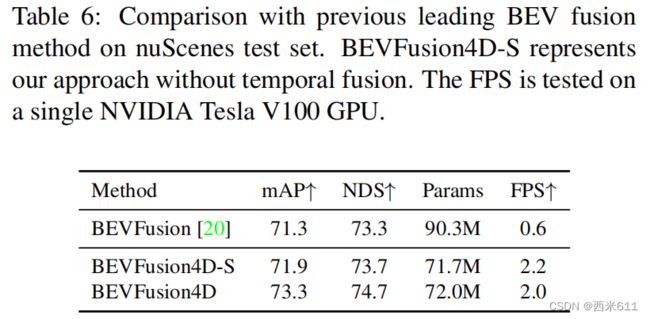
Model Capacity and Efficiency:
Conclusion
在本文中,我们提出了一种新的三维目标检测时空框架BEVFusion4D。在空间融合阶段,我们设计了一种激光雷达引导的视图变换器(LGVT),通过激光雷达先验的引导,帮助在BEV空间中获得更好的图像表示。在时间融合阶段,我们提出了一个时间可变形对齐(TDA)模块,以递归地聚合多个帧,而额外的内存成本和计算预算可以忽略不计。大量的实验证明了我们的两个模块的有效性,我们的方法最终在nuScenes数据集上取得了最先进的性能。我们希望BEVFusion4D可以作为一个强大的基线来启发未来对多传感器融合的研究。
结语
有理解的不对的地方欢迎指正。
PS:感叹一下这个领域更新太快了,一起学习吧,感谢观看:)