《ClickHouse原理解析与应用实践》读书笔记(1)
开始学习《ClickHouse原理解析与应用实践》,写博客作读书笔记。
本文全部内容都来自于书中内容,个人提炼。
前言和推荐
略过
第1章 ClickHouse的前世今生
跟ck没多大关系,过一遍就行。不看可以直接跳。
1.1 传统BI系统之殇
为了解决数据孤岛的问题,人们提出了数据仓库的概念。即通过引入一个专门用于分析类场景的数据库,将分散的数据统一汇聚到一处。
于20世纪 90年代,有人第一次提出了BI(商业智能)系统的概念。自此以后,人们通常用BI一词指代这类分析系统。相对于联机事务处理系统,我们把这类BI系统称为联机分析(OLAP)系统。
BI缺陷:
- 统对企业的信息化水平要求较高,通常只有中大型企业才有能力实施
- 受众狭小,主要受众是企业中的管理层或决策层
- 研发过程冗长
1.2 现代BI系统的新思潮
现代BI系统在设计思路的变化:
- 轻量化。就算只根据简单的Excel文件也能进行数据分析。
- 受众多元化。人人都能做。
- 虽然依然私有化, 但是使用体验上偏向快速应答,简单易用。
传统BI系统为OLTP型数据库(关系型数据库)。
现代BI 系统的典型应用场景是多维分析,为OLAP型数据库。
1.3 OLAP常见架构分类
OLAP指的是通过多种不同的维度审视数据,进行深层次分析。
对数据的几个分析操作的解释,概念的东西,了解即可:
- 上卷:从低层次向高层次汇聚。例如从“市”汇 聚成“省”,将“武汉”“宜昌”汇聚成“湖北”。
- 下钻:和上卷相反,从高层次向低层次明细数据穿透。例如从“省”下钻到 “市”,从“湖北省”穿透到“武汉”和“宜昌”。
- 切片:观察立方体的一层,将一个或多个维度设为单个固定值,然后观察剩余的维度,例如将商品维度固定为“足球”。
- 切块:与切片类似,只是将单个固定值变成多个值。例如将商 品维度固定成“足球”“篮球”和“乒乓球”。
- 旋转:旋转立方体的一面,如果要将数据映射到一张二维表, 那么就要进行旋转,这就等同于行列置换。
举例如图1-1。

常见的OLAP架构大致分成三类:
- ROLAP(Relational OLAP,关系型OLAP)。直接使用关系模型构建,数据模型常使用星型模型或者雪花模型。最为直接的实现方法。缺点是对数据的实时处理能力要求很高。
- MOLAP(Multidimensional OLAP,多维型 OLAP)。核心思想是借助预先聚合结果,使用空间换取时间 的形式最终提升查询性能。是为了缓解ROLAP性能问题。缺点是维度预处理可能会导致数据的膨胀。
- HOLAP(Hybrid OLAP,混合架构的OLAP)。理解成ROLAP和MOLAP两者的集成。
不考虑性能,单纯从模型角度考虑,ROLAP架构更胜一筹。更简单且容易理解。它直接面向明细数据查询,不需要预处理。
1.4 OLAP实现技术的演进
演进过程简单划分成两个阶段:
- 传统关系型数据库阶段。存在严重的性能问题。
- ROLAP架构下,使用Oracle、MySQL一类数据库作为存储与计算的载体
- MOLAP架构下,则借助物化视图的形式实现数据立方体。
- 大数据技术阶段。
- ROLAP架构下,使用Hive和SparkSQL等分布式系统。
- MOLAP架构下,依托MapReduce,Spark,HBase,依然存在维度爆炸、数据同步实时性不高的问题。
1.5 一匹横空出世的黑马
就是吹黑屁,说ck多牛逼。
ck既使用ROLAP模型,同时又拥有比肩MOLAP的性能。
1.5.1 天下武功唯快不破
ck具有ROLAP、在线实时查 询、完整的DBMS、列式存储、不需要任何数据预处理、支持批量更 新、拥有非常完善的SQL支持和函数、支持高可用、不依赖Hadoop复杂 生态、开箱即用等许多特点。
1.5.2 社区活跃
ClickHouse是一款开源软件,遵循Apache License 2.0协议。社区更新活跃。
1.6 ClickHouse的发展历程
伴随着 Yandex.Metrica业务的发展,ClickHouse底层架构历经四个阶段:
1.6.1 顺理成章的MySQL时期
流量的数据采集链路是这样的:网站端的应用程序首先通过 Yandex提供的站点SDK实时采集数据并发送到远端的接收系统,再由接收系统将数据写入MySQL集群。导致数据在磁盘中是完全随机存储的,并且会产生大量的磁盘碎片。
1.6.2 另辟蹊径的Metrage时期
Metrage在设计上与MySQL完全不同:
- 在数据模型层面,它使用Key-Value模型(键值 对)代替了关系模型;
- 在索引层面,它使用LSM树代替了B+树;
- 在数据处理层面,由实时查询的方式改为了预处理的方式。
LSM树也是一种非常流行的索引结构,发源于Google的Big Table,现在最具代表性的使用LSM树索引结构的系统是HBase。LSM写入数据流程:
- 在内存保存数据。(预写日志保证不丢)
- 内存数据排序。
- 到达阈值,后台线程刷内存数据到磁盘。
- 字段内数据有序,所以能用稀疏索引优化查询性能。
预处理上,将需要分析的数据预先聚合。将聚合的结果数据按照KeyValue的形式存储。
新的问题是维度组合爆炸,因为需要预先对所有的维度组合进行计算。
1.6.3 自我突破的OLAPServer时期
- 数据模型方面,又换回了关系模型.
- 存储结构上,它与MyISAM表引擎类似,分为了索引文件和数据文件两个部分。
- 索引方面,使用了LSM树的稀疏索引。
- 数据文件设计上,沿用了LSM树数据段,即数据段内数据有序,借助稀疏索引定位数据段。
- 引入了列式存储,每个列字段独立存储。
OLAPServer的定位只是和Metrage形成互补,所以它缺失了 一些基本的功能。比如没有DBMS应有的基本管理功能(DDL查询等)
1.6.4 水到渠成的ClickHouse时代
预聚合的问题:
- 预聚合无法满足自定义分析。
- 维度组合爆炸会导致数据膨胀。
- 流量数据是在线实时接收的,所以预聚合还需要考虑如何及时更新数据。
由于OLAPServer的成功使用经验,选择倾向于实时聚合。

1.7 ClickHouse的名称含义
ClickHouse 的全称是Click Stream,Data WareHouse,简称ClickHouse。
1.8 ClickHouse适用的场景
非常适用于商业智能领域(也就是我们所说的BI领 域),除此之外,它也能够被广泛应用于广告流量、Web、App流量、 电信、金融、电子商务、信息安全、网络游戏、物联网等众多其他领 域。
1.9 ClickHouse不适用的场景
不应该用于任何OLTP事务性操作的场景,原因:
- 不支持事务。
- 不擅长按行粒度查询。
- 不擅长按行删除数据。
1.10 有谁在使用ClickHouse
参考ClickHouse官网的案例介绍(https://clickhouse.yandex/ )。
1.11 本章小结
在BI系统从传统转向现代的过程中的所思所想。
ck的发展历程。
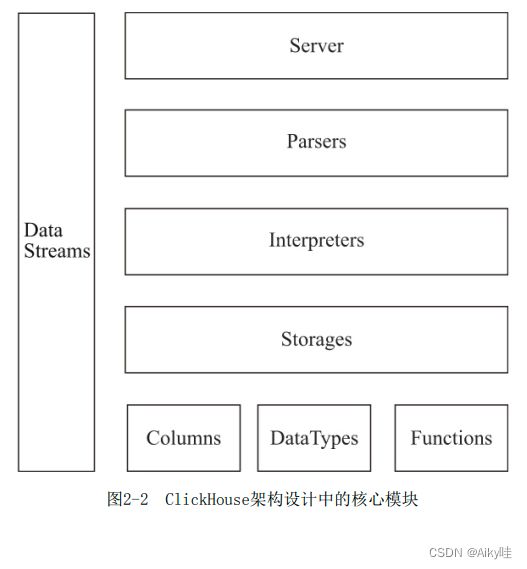
第2章 ClickHouse架构概述
与Hadoop生态的其他数 据库相比,ClickHouse更像一款“传统”MPP架构的数据库,它没有采 用Hadoop生态中常用的主从架构,而是使用了多主对等网络结构,同 时它也是基于关系模型的ROLAP方案。
2.1 ClickHouse的核心特性
ClickHouse是一款MPP架构的列式存储数据库。
2.1.1 完备的DBMS功能
ck称得上是一个 DBMS(Database Management System,数据库管理系统)。
具备了一些基本功能:
- DDL(数据定义语言):可以动态地创建、修改或删除数据库、 表和视图,而无须重启服务。
- DML(数据操作语言):可以动态查询、插入、修改或删除数据。
- 权限控制:可以按照用户粒度设置数据库或者表的操作权限, 保障数据的安全性。
- 数据备份与恢复:提供了数据备份导出与导入恢复机制,满足 生产环境的要求。
- 分布式管理:提供集群模式,能够自动管理多个数据库节点。
2.1.2 列式存储与数据压缩
让查询变得更快,最简单且有效的方法是减少数据扫描范围和数据传输时的大小。
列式存储的优点:
- 有效减少查询时所需扫描的数据量。如果只是需要部分列数据,列式存储可以直接返回数据;行式存储需要获取整行数据后筛选。
- 对数据压缩更加友好。压缩的本质是按照一定步长对数据进行匹配扫描,当发现重复部分的时候就进行编码转换。所以重复项越多,压缩越好,包越小,传输越快。
2.1.3 向量化执行引擎
向量化执行是寄存器硬件层面的特性。
需要利用CPU的SIMD(Single Instruction Multiple Data)指令。即用单条指令操作多条数据。
是通过数据并行以提高性能的一种实现方式(其他的还有指令级并行和线程级并行),它的原理是在CPU寄存器层面实现数据的并行操作。
存储媒介距离CPU越近,则访问数据的速度越快。反之越慢。
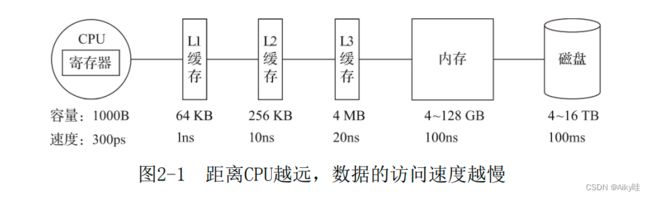
所以利用CPU向量化执行的特 性,对于程序的性能提升意义非凡。
ClickHouse目前利用SSE4.2指令集实现向量化执行。
2.1.4 关系模型与SQL查询
ClickHouse使用关系模型描 述数据并提供了传统数据库的概念(数据库、表、视图和函数等)。所以传统关系型数据库或数据仓库之上的系统迁移到ClickHouse的成本会变得更低。
在SQL解析方面,ClickHouse是大小写敏感的,这意味着SELECT a和SELECT A所代表的语义是不同的。
2.1.5 多样化的表引擎
与MySQL类似,ClickHouse也将存储部分进行了抽象,把存储引擎作为一层独立的接口。通过特定的表引擎支撑特定的场景,十分灵活。
2.1.6 多线程与分布式
多线程处理就是通过线程级并行的方式实现了性能的提升。
由于SIMD不适合用于带有较多分支判断的场景,ClickHouse也大量使用了多线程技术以实现提速,以此和向量化执行形成互补。
在分布式领域,存在一条金科玉律——计算移动比数据移动更加划算。在各服务器之间,通过网络传输数据的成本是高昂的,将数据的计算查询直接下推到数据 所在的服务器更加合适。
ClickHouse在数据存取方面,既支持分区(纵向扩展,利用多线程原理),也支持分片(横向扩展,利用分布式原理),可以说是将多线程和分布式的技术应用到了极致。
2.1.7 多主架构
ClickHouse则采用Multi-Master多主架构,集群中的每个节点角色对等,客户端访问任意一个节点都能得到相同的效果。优点在于系统架构更简单,能规避单点故障。
更适合多数据中心,异地多活。
2.1.8 在线查询
在复杂查询的场景下,它也能够做到极快响应,且无须对数据进行任何预处理加工。
2.1.9 数据分片与分布式查询
数据分片是将数据进行横向切分,使用分治思想。
ck每个集群由1到多个分片组成,而每个分片则对应了ClickHouse的1个服务节点。
ClickHouse提供了本地表(Local Table)与分布式表 (Distributed Table)的概念。
一张本地表等同于一份数据的分片。 而分布式表本身不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从而实现分布式查询。
类似数据库的分库和分表,十分灵活。
2.2 ClickHouse的架构设计
2.2.1 Column与Field
Column和Field是ClickHouse数据最基础的映射单元。
先说Column
在IColumn接口对象中,定义了对数据进行各种关系运算的方法。
【接口定义在源码中/src/Columns/IColumn.h中】

其中定义了对数据进行各种关系运算的方法,例如插入数据的insertRangeFrom和insertFrom方法、用于分页的cut,以 及用于过滤的filter方法等。
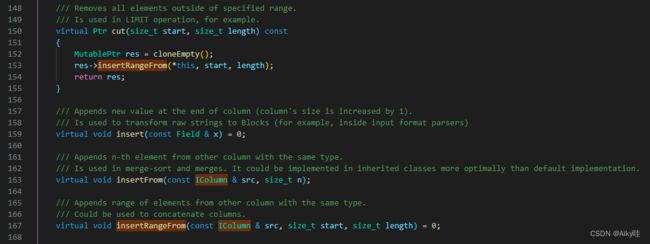
这些方法的具体实现对象则根据数据 类型的不同,由相应的对象实现,例如ColumnString、ColumnArray和 ColumnTuple等。
大多数场合,ClickHouse都会以整列的方式操作数据。
再说Field
如果需要操作单个具体的数值(也就是单列中的一行数据),则需要使用Field对象,Field对象代表一个单值。
与 Column对象的泛化设计思路不同,Field对象使用了聚合的设计模式。 在Field对象内部聚合了Null、UInt64、String和Array等13种数据类型及相应的处理逻辑。
【定义在src/Core/Field.h中】
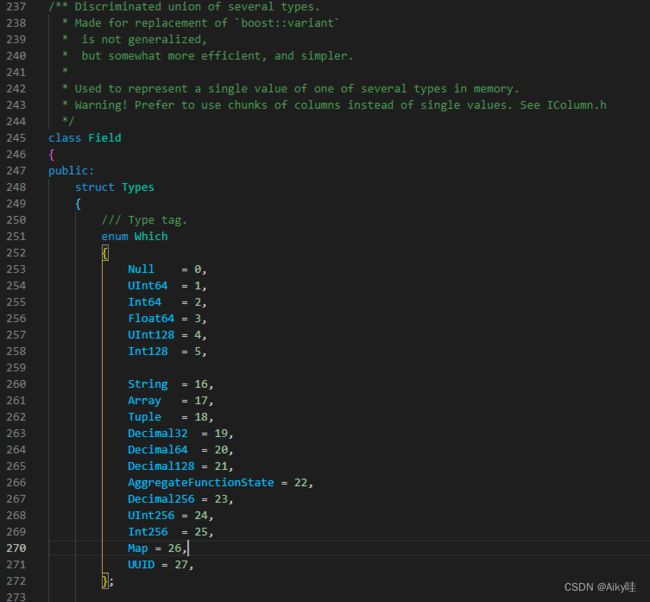
2.2.2 DataType
【现在21.8的版本中序列化这块不在IDateType了,定义在了class ISerialization中,这个不是作者的问题,是ck更新版本太快了,这部分书中的介绍已经落后于版本了】
【IDateType定义在src/DataTypes/IDataType.h】

2.2.3 Block与Block流
ClickHouse内部的数据操作是面向Block对象进行的,并且采用了流的形式。
虽然Column和Filed组成了数据的基本映射单元,但对应到实际操作,它们还缺少了一些必要的信息。数据的类型及列的名称之类的。
Block对象可以看作数据表的子集。本质是由数据对象、数据类型和列名称组成的三元组,即Column、DataType及列名称字符串。
【这里其实和tidb的chunk设计是差不多的,就是一批数据。定义在src/Core/Block.h中】
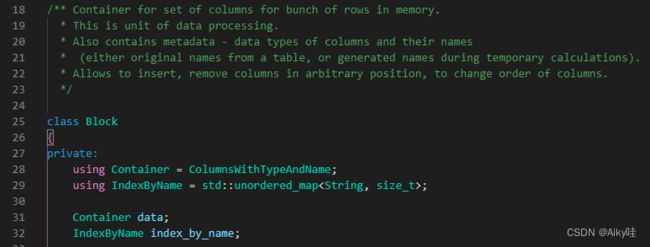
Block流操作有两组顶层接口:
- IBlockInputStream负责数据的读取和关系运算
- 【定义在src/DataStreams/IBlockInputStream.h】
- IBlockOutputStream负责将数据输出到下一环节
- 【定义在src/DataStreams/IBlockOutputStream.h】
Block流也使用了泛化的设计模式,对数据的各种操作最终都会转换成其中一种流的实现。IBlockInputStream接口定义了读取数据的若干个read虚方法,而具体的实现逻辑则交由它的实现类来填充。
IBlockInputStream接口涵盖了 ClickHouse数据摄取的方方面面。这些实现类大致可以分为三类:
- 第一类用于处理数据定义的DDL操作,例如DDLQueryStatusInputStream 等;
- 第二类用于处理关系运算的相关操作,例如LimitBlockInputStream、JoinBlockInputStream及AggregatingBlockInputStream等;
- 第三类则是与表引擎呼应,每一种表引擎都拥有与之对应的 BlockInputStream实现,例如MergeTreeBaseSelectBlockInputStream(MergeTree表引擎)、 TinyLogBlockInputStream(TinyLog表引擎)及 KafkaBlockInputStream(Kafka表引擎)等。
IBlockOutputStream的设计与IBlockInputStream如出一辙。基本用于表引擎的相关处理,负责将数据写入下一环节或者最终目的地,例如MergeTreeBlockOutputStream、 TinyLogBlockOutputStream及StorageFileBlock-OutputStream等。
2.2.4 Table
底层设计中并没有所谓的Table对象,它直接使用 IStorage接口指代数据表。
【定义在src/Storages/IStorage.h】

不同的表引擎由不同的子类实现,例如IStorageSystemOneBlock(系统表)、StorageMergeTree(合并树表引擎)和StorageTinyLog(日志表引擎)等。
IStorage接口定义了DDL(如ALTER、RENAME、OPTIMIZE 和DROP等)、read和write方法,它们分别负责数据的定义、查询与写入。在数据查询时,IStorage负责根据AST查询语句的指示要求,返回指定列的原始数据。
后续对数据的进一步加工、计算和过滤,则会统一交由Interpreter解释器对象处理。
2.2.5 Parser与Interpreter
Parser分析器负责创建AST对象。
【Parser定义在src/Parsers/IParser.h】
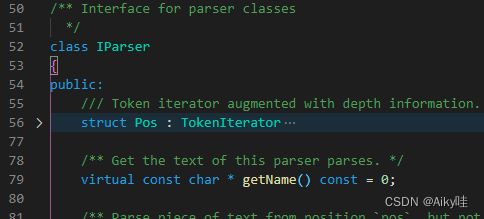
Interpreter解释器则负责解释AST,并进一步创建查询的执行管道。
【Interpreter定义在src/Interpreters/IInterpreter.h】

它们与IStorage一起,串联起了整个数据查询的过程。
不同的SQL语句,会经由不同的Parser实现类解析。例如,有负责解析DDL查询语句的ParserRenameQuery、ParserDropQuery 和ParserAlterQuery解析器,也有负责解析INSERT语句的 ParserInsertQuery解析器,还有负责SELECT语句的 ParserSelectQuery等。
Interpreter解释器的作用就像Service服务层一样,起到串联整 个查询过程的作用,它会根据解释器的类型,聚合它所需要的资源。 首先它会解析AST对象;然后执行“业务逻辑”(例如分支判断、设置 参数、调用接口等);最终返回IBlock对象,以线程的形式建立起一 个查询执行管道。
【其实很好理解,sql的执行流程肯定是先解析成ast解析树,再根据ast解析树生成执行计划。Parser与Interpreter就是干这个的。】
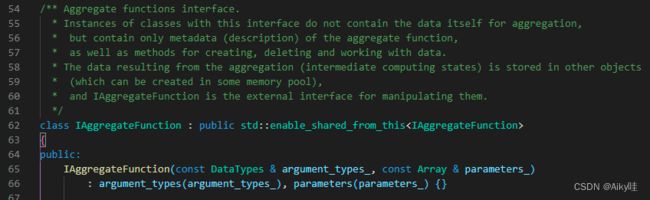
2.2.6 Functions与Aggregate Functions
ck提供普通函数和聚合函数。
普通函数由IFunction接口定义,拥有数十种函数实现,例如 FunctionFormatDateTime、FunctionSubstring等。在函数具体执行的过程中,并不会一行一行地运算,而是采用向量化的方式直接作用于一整列数据。
【IFunction接口定义在src/Functions/IFunction.h,但是根据代码注释来看,这个接口已经过时了。】

聚合函数由IAggregateFunction接口定义,相比无状态的普通函数,聚合函数是有状态的。以COUNT聚合函数为例,其 AggregateFunctionCount的状态使用整型UInt64记录。
聚合函数的状态支持序列化与反序列化,所以能够在分布式节点之间进行传输,以实现增量计算。
【我没有太理解作者说的这个状态是什么意思,我个人理解应该是聚合过程中产生的中间结果,注释也是这么写的。IAggregateFunction接口定义在src/AggregateFunctions/IAggregateFunction.h】
2.2.7 Cluster与Replication
ClickHouse的集群由分片(Shard)组成,而每个分片又通过副本 (Replica)组成。
【ck的分片是逻辑概念,副本是物理概念,这里很容易弄混。】
ck集群的特性:
- ClickHouse的1个节点只能拥有1个分片,也就是说如果要实现1分片、1副本,则至少需要部署2个服务节点。
- 分片只是一个逻辑概念,其物理承载还是由副本承担的。
举例来说,单分片单副本的配置:

单分片两副本的配置:

2.3 ClickHouse为何如此之快
在设计软件架构的时候,做设计的原则应该是自顶向下地去设计,还是应该自下而上地去设计呢?在传统观念中,或者说在我的观念中,自然是自顶向下的设计,通常我们都被教导要做好顶层设计。
而ClickHouse的设计则采用了自下而上的方式。
2.3.1 着眼硬件,先想后做
基于将硬件功效最大化的目的, ClickHouse会在内存中进行GROUP BY,并且使用HashTable装载数据。同时非常在意CPU L3级别的缓存。
因为一次L3的缓存失效 会带来70~100ns的延迟。这意味着在单核CPU上,它会浪费4000万次/ 秒的运算;而在一个32线程的CPU上,则可能会浪费5亿次/秒的运算。
注意了这些细节,所以ClickHouse在基准查询中能做到 1.75亿次/秒的数据扫描性能。
2.3.2 算法在前,抽象在后
以字符串为例, 有一本专门讲解字符串搜索的书,名为“Handbook of Exact String Matching Algorithms”,列举了35种常见的字符串搜索算法。
各位猜一猜ClickHouse使用了其中的哪一种?答案是一种都没有。这是为什么呢?因为性能不够快。在字符串搜索方面,针对不同的场景, ClickHouse最终选择了这些算法:对于常量,使用Volnitsky算法;对于非常量,使用CPU的向量化执行SIMD,暴力优化;正则匹配使用re2 和hyperscan算法。性能是算法选择的首要考量指标。
【这里属于尬吹了,你拿纯暴力方法跟人家比快么,怎么可能性能会比后缀自动机之类的快,这里我觉得是为了迎合列存,操作能做simd,绝对不是说人家书里的算法不好】
2.3.3 勇于尝鲜,不行就换
如果世面上出现了号称性能强大的新算法, ClickHouse团队会立即将其纳入并进行验证。
如果效果不错,就保留;如果性能不尽人意,就将其抛弃。
2.3.4 特定场景,特殊优化
【没啥好记得】
2.3.5 持续测试,持续改进
【没啥好记得】
2.4 本章小结
展示ck核心特性。
进一步展示ck的底层设计思路。