【大数据】Hive函数➕分区分桶表➕hive文件格式和压缩
目录
- 前言
- 一、函数
- 1. 单行函数
- 1.1. 算数、数值函数
- 1.2. 字符串函数(10种)
- 1.3 日期函数(9点)
- 1.4 流程控制函数(case、if)
- 1.5 集合函数(3大类)
- 2. 高级聚合函数(collect_list、collect_set)
- 3. 炸裂函数(UDTF)
- 3.1. 四种常用的UDTF(拆开集合)
- 3.2. Lateral View(串成一个虚拟表)
- 4. 窗口函数(开窗函数)
- 4.1. 基本概念、语法
- 4.2. 窗口
- 4.3. 常用窗口函数(聚合、跨行取值、排名函数)
- 5. 自定义UDF函数
- 二、分区表和分桶表(存储角度优化)
- 1. 分区表
- 1.2. 基本语法(创建、查看、插入、删除)
- 1.2. 修复分区
- 1.3. 二级分区表
- 1.4. 动态分区
- 2. 分桶表
- 2.1. 基本语法
- 2.2. 分桶排序表
- 三、文件格式和压缩
- 1. Hadoop压缩概述
- 2. Hive文件格式(orc/parquet)
- 2.1. Text File(默认使用)
- 2.2. ORC(用的多)
- 2.3. Parquet(同样用的多)
- 3. 压缩(推荐snappy)
- 3.1. Hive表数据进行压缩(textfile/orc/parquet)
- 3.2. 计算过程中使用压缩(2种)
- 总结
前言
hive打开本地模式sql语句(所有语句都走本地模式):set mapreduce.framework.name=local;
一、函数
Hive会将常用的逻辑封装成函数给用户进行使用,类似于Java中的函数。
- 好处:避免用户反复写逻辑,可以直接拿来使用。
- 重点:用户需要知道函数叫什么,能做什么。
Hive提供了大量的内置函数,按照其特点可大致分为如下几类:单行函数、聚合函数、炸裂函数、窗口函数
查看函数语法:
-- 查看系统内置函数
show functions;
--查看内置函数用法
desc function upper;
-- 查看内置函数详细信息
desc function extended upper;
1. 单行函数
单行函数的特点是一进一出,即输入一行,输出一行。单行函数按照功能可分为如下几类: 日期函数、字符串函数、集合函数、数学函数、流程控制函数等
1.1. 算数、数值函数
算术运算函数
数值函数
-- round:四舍五入
select round(3.3); -- 3
select round(1.123456,2); -- 1.12
select round(-1.5); -- -2
-- ceil:向上取整
select ceil(3.1); -- 4
-- floor:向下取整
select floor(4.8); -- 4
1.2. 字符串函数(10种)
1️⃣ substring:截取字符串
-- 返回字符串A从start位置(从1开始)到结尾的字符串
substring(string A, int start)
-- 返回字符串A从start位置(从1开始)开始,长度为len的字符串
substring(string A, int start, int len)
2️⃣ replace :替换(全局替换)
-- 将字符串A中的子字符串B替换为C
replace(string A, string B, string C)
select replace('atguigu', 'a', 'A9')
-- 输出:
A9tgigu
3️⃣ regexp_replace:正则替换,正则可视化网站点击前往
-- 将字符串A中的符合java正则表达式B的部分替换为C,在有些情况下要使用转义字符
select regexp_replace('114-514', '\\d{1,}', 'homo')
-- 输出:
homo-homo

4️⃣ regexp_replace:正则匹配
-- 若字符串符合正则表达式,则返回true,否则返回false
select 'dfsaaaa' regexp 'dfsb+';
-- 输出:
false
类似于
like能做出判断select "string" like '%str%';不同的是like里面的是通配表达式,这里是正则表达式
5️⃣ repeat:重复字符串,语法:repeat(string A, int n)
-- 将字符串A重复n遍
select repeat('123', 3);
-- 输出:
123123123
6️⃣ split :字符串切割,语法:split(string str, string pat)
-- 按照正则表达式pat匹配到的内容分割str,分割后的字符串,以数组的形式返回
select split('a-b-c-d','-');
-- 输出:
["a","b","c","d"]
7️⃣ nvl :替换null值,语法:nvl(A,B)
select nvl(null,1);
-- 输出:
1
-- 非null值输出第一个数
select nvl(66,99);
select nvl(99,66);
-- 给字段默认值(col为null)
select nvl(col,1);
8️⃣ concat:拼接字符串,语法:concat(string A, string B, string C, ……),特殊符号||也有拼接作用
select concat('beijing','-','shanghai','-','shenzhen');
select 'beijing'||'-'||'shanghai'||'-'||'shenzhen'
-- 输出:
beijing-shanghai-shenzhen
9️⃣ concat_ws:以指定分隔符拼接字符串或者字符串数组,语法:concat_ws(string A, string…| array(string))
select concat_ws('-','beijing','shanghai','shenzhen');
select concat_ws('-',array('beijing','shanghai','shenzhen'));
-- 输出:
beijing-shanghai-shenzhen
get_json_object:解析json字符串,语法:get_json_object(string json_string, string path)
-- 解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NULL
-- 获取数组元素中的信息
select get_json_object('[{"name":"大海海","sex":"男","age":"25"},{"name":"小宋宋","sex":"男","age":"47"}]','$[1].name');
-- 输出:
小宋宋
-- 获取json数组里面的数据
select get_json_object('[{"name":"大海海","sex":"男","age":"25"},{"name":"小宋宋","sex":"男","age":"47"}]','$.[0]');
-- 输出:
{"name":"大海海","sex":"男","age":"25"}
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它有以下一些主要特点和用途:
- 结构清晰和易于理解:JSON采用完全独立于编程语言的文本格式,使得JSON数据在各种系统之间传输变得更简单。
- 语法简单:JSON的语法是JavaScript对象表示法的子集,数据在中括号{}内,采用名称/值对的形式,通过逗号分隔。
- 轻量和高效:相比XML,JSON更小更快,且解析起来没有那么复杂。这使得它更适合在Web环境中传输数据。
- 通用性强:JSON格式 standardized,并得到广泛支持。目前几乎所有编程语言和主流Web框架都提供了对JSON的支持。
主要应用场景:
- 作为数据交换的格式,用于服务端与客户端、后端与前端的通信交互。
- 存储服务端的数据,如配置文件、用户信息、产品数据等。
- 用于NoSQL数据库中存储和表示文档数据。
- 作为参数传递格式,用于AJAX请求或服务请求。
- 用于日志文件或监控指标采集数据。
所以总的来说,JSON是一个轻量级的文本数据格式,由于其简单易用的特点,广泛应用于现代软件系统中的数据存储、传输和交互。它大大提高了系统与系统,服务与客户端之间的数据交换能力。
了解学习json
1.3 日期函数(9点)
1️⃣ unix_timestamp:返回当前或指定时间的时间戳(UTC,0时区为准),语法:unix_timestamp(),返回值:bigint
-- 指定时间(0时区的)
select unix_timestamp('2023/08/30 11-30-08','yyyy/MM/dd HH-mm-ss');
-- 输出:
1693395008
2️⃣ from_unixtime:转化UNIX时间戳(从 1970-01-01 00:00:00 UTC 到指定时间的秒数)到当前时区的时间格式,语法:from_unixtime(bigint unixtime[, string format]),返回值:string
select from_unixtime(1659946088);
-- 输出:
2022-08-08 08:08:08
解决UTC导致的时区不一致问题

-- 先获取当前时间戳
select unix_timestamp();
-- 转化
select from_utc_timestamp(cast(1693367059 as bigint)*1000,'GMT+8');
-- 输出:
2023-08-30 11:44:19.000000000
-- 格式化
select date_format(from_utc_timestamp(cast(1693367059 as bigint)*1000,'GMT+8'),'yyyy/MM/dd HH:mm:ss');
-- 输出:
2023/08/30 11:44:19
3️⃣ current_date:当前日期
select current_date();
-- 输出:
2023-08-30
4️⃣ current_timestamp:当前的日期加时间,并且精确的毫秒
select current_timestamp();
-- 输出:
2023-08-30 12:05:28.636000000
5️⃣year/month/day/hour:获取日期中的年/月/日/时信息
select year('2022-08-08 08:08:08');
select month('2022-08-08 08:08:08');
select day('2022-08-08 08:08:08');
select hour('2022-08-08 08:08:08');
-- 输出:
2022
8
8
8
6️⃣ datediff:两个日期相差的天数(结束日期减去开始日期的天数),语法:datediff(string enddate, string startdate),返回值:int
select datediff('2023-08-30','2003-05-16');
-- 输出:
7411
8️⃣ date_add/sub:日期加/减天数,语法:date_add/sub(string startdate, int days),返回值:string
select date_add('2023-08-30',2);
-- 输出:
2023-09-01
select date_sub('2023-08-30',7);
-- 输出:
2023-08-23
9️⃣ date_format:将标准日期解析成指定格式字符串
select date_format('2022-08-08','yyyy年-MM月-dd日')
-- 输出:
2022年-08月-08日
1.4 流程控制函数(case、if)
1️⃣ case when:条件判断函数
-- 语法一:
case when a then b [when c then d]* [else e] end
-- 语法二:
case a when b then c [when d then e]* [else f] end
举个例子:
select
stu_id,
course_id,
case
when score>=90 then 'A'
when score>=80 then 'B'
when score>=70 then 'C'
when score>=60 then 'D'
else '不及格'
end
from beginner.score_info;
-- 第二种写法(仅限于同一字段):
select
stu_id,
course_id,
case score
when 90 then 'A'
when 80 then 'B'
when 70 then 'C'
when 60 then 'D'
else '不及格'
end
from beginner.score_info;
2️⃣ if: 条件判断,类似于Java中三元运算符,语法:if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if(10>5,'true','false');
1.5 集合函数(3大类)
数组相关
1️⃣ array:声明array集合,语法:array(val1, val2, …)
-- 根据输入参数构建array类
select array('1','1','4','5','1','4');
-- 输出:
["1","1","4","5","1","4"]
2️⃣ array_contains:判断array中是否包含某个元素
select array_contains(array('a','b','c','d'),'a');
-- 输出:
true
3️⃣ sort_array:将array中的元素排序(默认升序)
select sort_array(array('c','d','a'));
-- 输出:
["a","c","d"]
4️⃣ size:集合中元素的个数(数组长度计算)
select size(array(1,4,5,98));
-- 输出:
4
map相关
1️⃣ map:创建map集合,语法:map(key1, value1, key2, value2, …)
select map('xiaohai',1,'dahai',2);
-- 输出:
{"xiaohai":1,"dahai":2}
2️⃣ map_keys/values: 返回map中的key/values
select map_keys(map('xiaohai',1,'dahai',2));
-- 输出:
["xiaohai","dahai"]
select map_values(map('xiaohai',1,'dahai',2));
-- 输出:
[1,2]
结构体相关
1️⃣ struct:声明struct中的各属性,语法:struct(val1, val2, val3, …)
select struct('name','age','weight');
-- 输出:
{"col1":"name","col2":"age","col3":"weight"}
2️⃣ named_struct:声明struct的属性和值
select named_struct('name','xiaosong','age',18,'weight',80);
-- 输出:
{"name":"xiaosong","age":18,"weight":80}
单行函数案例视频讲题,巩固所学
2. 高级聚合函数(collect_list、collect_set)
多进一出 (多行传入,一个行输出)
1️⃣ collect_list:收集并形成list集合,结果不去重
select
sex,
collect_list(job)
from
employee
group by
sex;
-- 输出:
女 ["行政","研发","行政","前台"]
男 ["销售","研发","销售","前台"]

2️⃣ collect_set:收集并形成set集合,结果去重
select
sex,
collect_set(job)
from
employee
group by
sex;
-- 输出:
女 ["行政","研发","前台"]
男 ["销售","研发","前台"]
3. 炸裂函数(UDTF)
UDTF (Table-Generating Functions),接收一行数据,输出一行或多行数据,也叫做制表函数

3.1. 四种常用的UDTF(拆开集合)
常用UDTF——explode(ARRAY

- 语法:
select explode(array('a','b','c')) as item

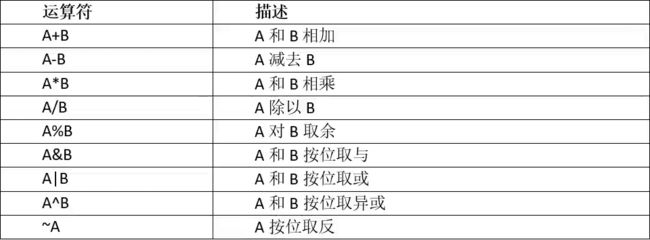
常用UDTF——explode(MAP
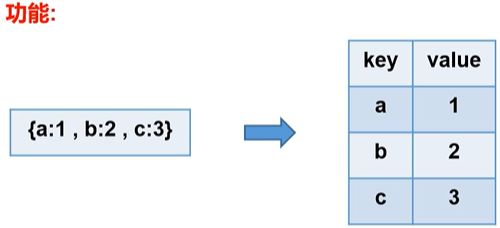
- 语法:
select explode(map('a','1','b',2,'c',3)) as (key,value);

常用UDTF——pseexplode(ARRAY
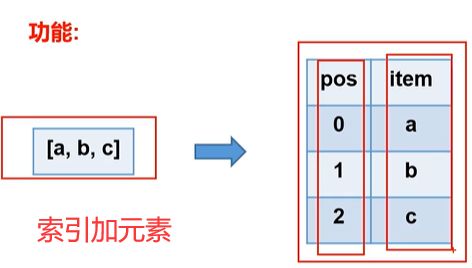
- 语法:
select posexplode(array('a','b','c')) as (pos,item);

常用UDTF——inline(ARRAY

- 语法:
select inline(array(named_struct('id',1,'name','zs'),named_struct('id',2,'name','ls'),named_struct('id',3,'name','ww'))) as (id,name);
3.2. Lateral View(串成一个虚拟表)
定义:Latera View通常与UDTF配合使用。Lateral View可以将UDTF应用到源表的每行数据,将每行数据转换为一行或多行,并将源表中每行的输出结果与该行连接起来,形成一个虚拟表

- 语法(得取别名):
select
id,
name,
hobbies,
hobby
from person
lateral view explode(hobbies) tmp as hobby;
其中tmp是炸出来的数据的别名,穿成一串叫做hobby,多串用逗号分隔,构成一个虚拟表
案例演示:

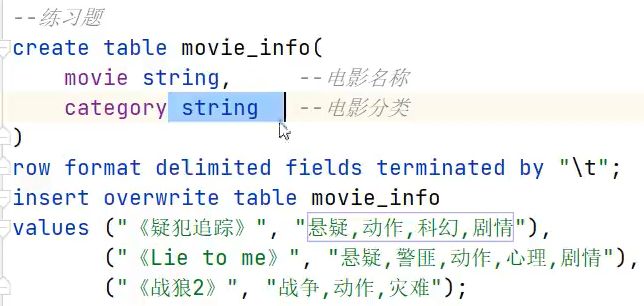
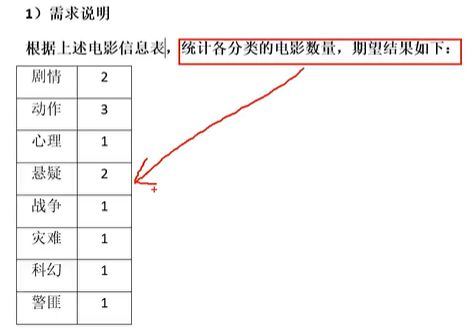
- 实现:
select
cate,
count(*)
from
(
select
movie,
split(category,',') category
from movie_info
) t1 lateral view explode(category) tmp as cate
group by cate;

4. 窗口函数(开窗函数)
4.1. 基本概念、语法
窗口函数,能为每行数据划分一个窗口,然后对窗口范围内的数据进行计算,最后将计算结果返回给该行数据

语法:窗口函数的语法中主要包括“窗口”和“函数”两部分。其中“窗口”用于定义计算范围,“函数”用于定义计算逻辑。
select
order_id,
order_data,
amount,
函数(amount) over (窗口范围) total_amount
from order_info;
4.2. 窗口
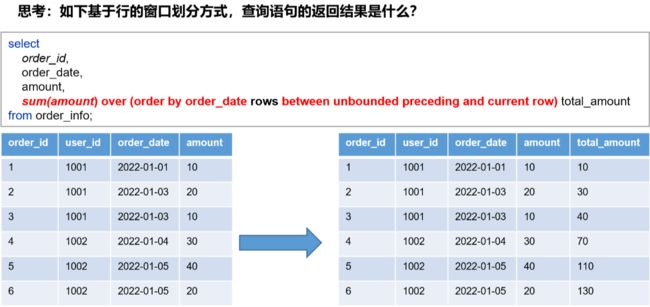
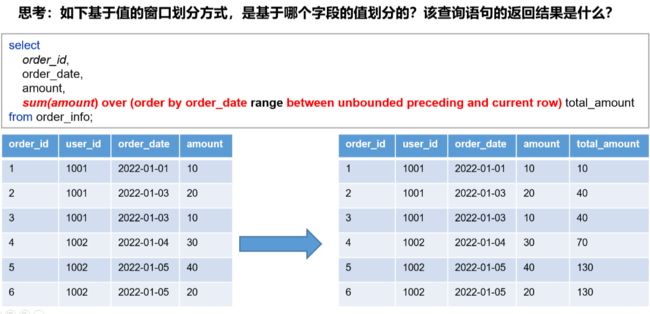
窗口:窗口范围的定义分为两种类型,一种是基于行的(是看计算时的行关系并非看到的表中的,因此必须排序保证字段顺序一致),一种是基于值的。

-
窗口语法——基于行(rows)

-
窗口语法——基于值(range)

-
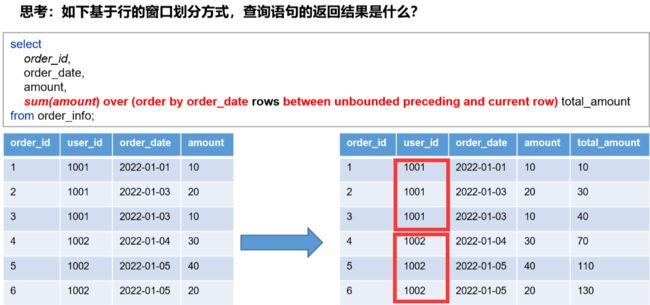
窗口语法——分区

-
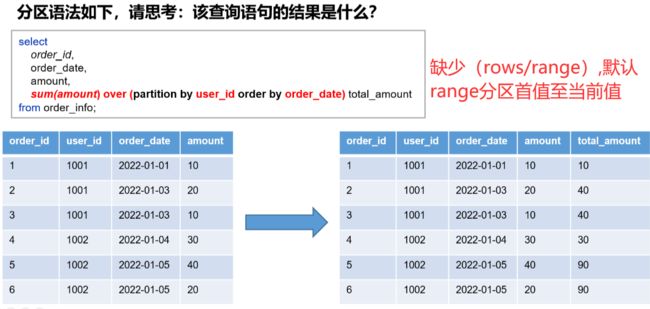
窗口语法——缺省

4.3. 常用窗口函数(聚合、跨行取值、排名函数)
聚合函数:绝大多数的聚合函数都可以配合窗口使用,例max(),min(),sum(),count(),avg()等,因为是多行输入、一行输出
跨行取值函数(2种)
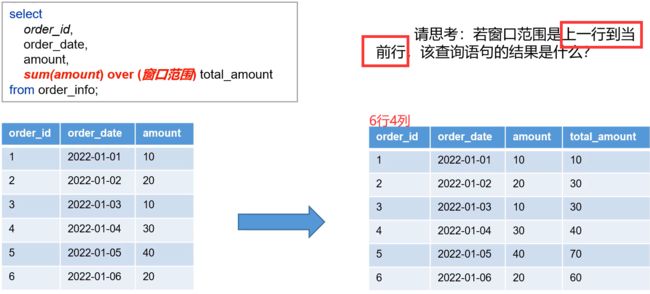
lead和lag
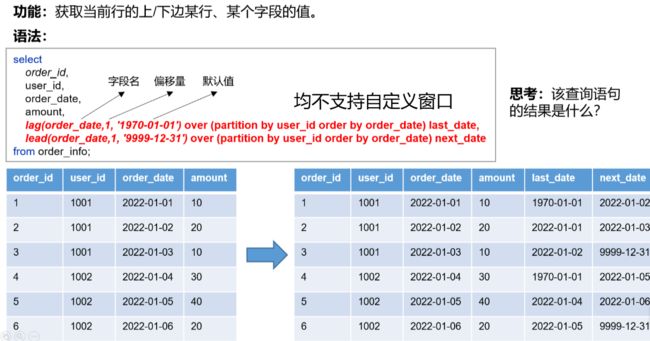
first_value和last_value
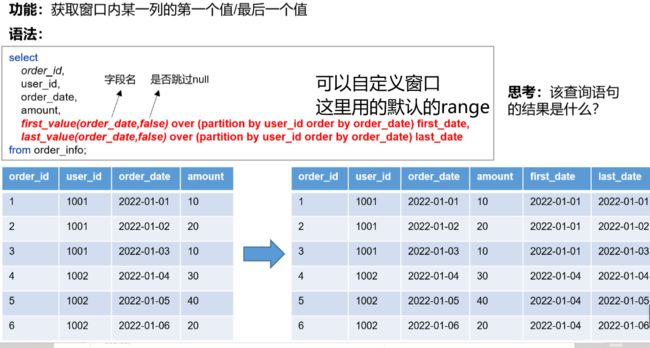
排名函数(rank(113)、dense_rand(112)、row_number(123)均不支持自定义窗口)
窗口函数案例演示视频传送门
别光看啊,快来刷题!!!
5. 自定义UDF函数
Hive自带了一些函数,比如:
max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数UDF:user-defined function参考官方文档
根据用户自定义函数类别分为以下三种:
UDF(User-Defined-Function)
一进一出,单行函数UDAF(User-Defined Aggregation Function)
用户自定义聚合函数,多进一出。类似于:count/max/minUDTF(User-Defined Table-Generating Functions)
用户自定义表生成函数,一进多出。如lateral view explode()
自定义函数编程步骤:
- 继承Hive提供的类
org.apache.hadoop.hive.ql.udf.generic.GenericUDF
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF
- 实现类中的抽象方法
- 在hive的命令行窗口创建函数
-- 添加jar。
add jar linux_jar_path
-- 创建function。
create [temporary] function [dbname.]function_name AS class_name;
-- 在hive的命令行窗口删除函数的命令
drop [temporary] function [if exists] [dbname.]function_name;
需求:自定义一个UDF实现计算给定基本数据类型的长度(hive(default)> select my_len("abcd"); -- 4)点击前往代码视频讲解!
- 在idea中创建一个Maven工程,并导入依赖(hive3.1.3)
<dependencies>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>3.1.3version>
dependency>
dependencies>
- 创建一个类
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class myLength extends GenericUDF {
/**
* 判断传进来的参数类型和长度
* 约定返回的数据类型
* @param objectInspectors
* @return
* @throws UDFArgumentException
*/
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
if(objectInspectors.length != 1){
throw new UDFArgumentException("只接受一个参数");
}
ObjectInspector argument = objectInspectors[0];
if(!argument.getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentException("只接受基本数据类型");
}
PrimitiveObjectInspector primitiveObjectInspector = (PrimitiveObjectInspector) argument;
if(!primitiveObjectInspector.getPrimitiveCategory().equals(PrimitiveObjectInspector.PrimitiveCategory.STRING)){
throw new UDFArgumentException("只接受String类型");
}
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
/**
* 解决具体逻辑
* @param deferredObjects
* @return
* @throws HiveException
*/
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
DeferredObject argument = deferredObjects[0];
Object o = argument.get();
if(o==null)
{
return 0;
}
return o.toString().length();
}
/**
* 用于获取解释的字符串
* @param strings
* @return
*/
@Override
public String getDisplayString(String[] strings) {
return null;
}
}
临时函数和永久函数
- 创建临时函数:临时函数只跟会话有关系,跟库没有关系。只要创建临时函数的会话不断,在当前会话下,任意一个库都可以使用,其他会话全都不能使用
# 打成jar包上传到服务器
/opt/module/datas/hiveTest-1.0-SNAPSHOT.jar
# 将jar包添加到hive的classpath,hive中执行使其临时生效
add jar /opt/module/datas/hiveTest-1.0-SNAPSHOT.jar
# 创建临时函数与开发好的java class关联(找到对应的全类名)
create temporary function my_len as "com.xxxx.hive.udf.myLength";
就可在hive中使用自定义的临时函数
hive> select my_len(1);
FAILED: SemanticException [Error 10014]: Line 1:7 Wrong arguments '1': 只接受String类型
hive> select my_len(1,2);
FAILED: SemanticException [Error 10014]: Line 1:7 Wrong arguments '2': 只接受一个参数
hive> select my_len("aaa");
OK
3
Time taken: 2.37 seconds, Fetched: 1 row(s)
-- 删除临时函数
drop temporary function my_len;
- 永久函数:我们选择把路径放置到HDFS上,上传好jar包,永久函数跟会话没有关系,创建函数的会话断了以后,其他会话也可以使用。永久函数创建的时候,在函数名之前需要自己加上库名,如果不指定库名的话,会默认把当前库的库名给加上。永久函数使用的时候,需要在指定的库里面操作,或者在其他库里面使用的话加上,库名.函数名。
-- hive中执行
create function my_len
as "com.xxxx.hive.udf.myLength"
using jar "hdfs://hadoop102:8020/udf/hiveTest-1.0-SNAPSHOT.jar";
-- 永久函数名字上会加上数据库名,在那个数据库中不用加也能用
show function like '*my_len*';
select my_len("123");
drop function my_len;
二、分区表和分桶表(存储角度优化)
1. 分区表
Hive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中的表达式选择查询所需要的分区,这样的查询效率会提高很多
1.2. 基本语法(创建、查看、插入、删除)
set mapreduce.framework.name=local;
-- 创建分区表(未指定路径默认在HDFS中/user/hive/warehouse/partition bucket.db路径下)
create table dept_partition
(
deptno int, --部门编号
dname string, --部门名称
loc string --部门位置
)
partitioned by (day string)
row format delimited fields terminated by '\t';
-- 可以将分区字段看作表的伪列,可像使用其他字段一样使用分区字段
select * from dept_patition;
-- 写入数据(load/insert)
-- 1. 数据准备
vim /opt/module/datas/dept_20990401.log
10 行政部 1700000
20 财务部 1800
-- 2. 装载语句
load data local inpath '/opt/module/datas/dept_20990401.log'
into table dept_partition partition(day='20990401');
-- insert+select
insert overwrite table dept_partition partition (day = '20990402') select deptno, dname, loc from dept_partition
where day = '20990401';
-- 查看所有分区信息
show partitions dept_partition;
-- 创建单个分区
alter table dept_partition add partition(day='20220403');
-- 同时创建多个分区(分区之间不能有逗号)
alter table dept_partition add partition(day='20220404') partition(day='20220405');
-- 删除单个分区(HDFS也会删除因为默认是内部表)
alter table dept_partition drop partition (day='20220403');
-- 同时删除多个分区(分区之间必须有逗号)
alter table dept_partition drop partition (day='20220404'), partition(day='20220405');
1.2. 修复分区
Hive将分区表的所有分区信息都保存在了元数据中,只有元数据与HDFS上的分区路径一致时,分区表才能正常读写数据。若用户手动创建/删除分区路径,Hive都是感知不到的,这样就会导致Hive的元数据和HDFS的分区路径不一致。再比如,若分区表为外部表,用户执行drop partition命令后,分区元数据会被删除,而HDFS的分区路径不会被删除,同样会导致Hive的元数据和HDFS的分区路径不一致。可通过如下几种手段进行修复。
add partition:若手动创建HDFS的分区路径,Hive无法识别,可通过alter table dept_partition add partition (day='20220403');命令增加分区元数据信息,从而使元数据和分区路径保持一致。drop partition:若手动删除HDFS的分区路径,Hive无法识别,可通过drop partition命令删除分区元数据信息,从而使元数据和分区路径保持一致。msck:若分区元数据和HDFS的分区路径不一致,还可使用msck命令进行修复,以下是该命令的用法说明。
-- 语法说明
msck repair table table_name [add/drop/sync partitions];
-- 说明:都是增加元数据hive端的信息
msck repair table dept_partition add partitions; --该命令会增加HDFS路径存在但元数据hive部分缺失的分区信息。
msck repair table dept_partition drop partitions; --该命令会删除HDFS路径已经删除但元数据仍然存在的分区信息。
msck repair table dept_partition sync partitions; --该命令会同步HDFS路径和元数据分区信息,相当于同时执行上述的两个命令。
msck repair table table_name; --等价于msck repair table table_name add partitions命令。
1.3. 二级分区表
如果一天内的日志数据量也很大,如何再将数据拆分?答案是二级分区表,例如可以在按天分区的基础上,再对每天的数据按小时进行分区
语法说明:
-- 建表语句
create table dept_partition2(
deptno int, -- 部门编号
dname string, -- 部门名称
loc string -- 部门位置
)
partitioned by (day string, hour string)
row format delimited fields terminated by '\t';
-- 数据装载语句
load data local inpath '/opt/module/hive/datas/dept_20220401.log' into table dept_partition2 partition(day='20220401', hour='12');
-- 查询分区数据
select
*
from dept_partition2
where day='20220401' and hour='12';
1.4. 动态分区
动态分区是指向分区表insert数据时,被写往的分区不由用户指定,而是由每行数据的最后一个字段的值来动态的决定。使用动态分区,可只用一个insert语句将数据写入多个分区
相关参数:
-- 动态分区功能总开关(默认true,开启)
set hive.exec.dynamic.partition=true
-- 严格模式和非严格模式
-- 动态分区的模式,默认strict(严格模式),要求必须指定至少一个分区为静态分区
-- nonstrict(非严格模式)允许所有的分区字段都使用动态分区
set hive.exec.dynamic.partition.mode=nonstrict
-- 一条insert语句可同时创建的最大的分区个数,默认为1000
set hive.exec.max.dynamic.partitions=1000
-- 单个Mapper或者Reducer可同时创建的最大的分区个数,默认为100
set hive.exec.max.dynamic.partitions.pernode=100
-- 一条insert语句可以创建的最大的文件个数,默认100000
hive.exec.max.created.files=100000
-- 一条insert语句可以创建的最大的文件个数,默认100000
hive.error.on.empty.partition=false
案例实操:将dept表中的数据按照地区(loc字段),插入到目标表dept_partition_dynamic的相应分区中
-- 创建目标分区表
create table dept_partition_dynamic(
id int,
name string
)
partitioned by (loc int)
row format delimited fields terminated by '\t';
-- 设置动态分区
set hive.exec.dynamic.partition.mode = nonstrict;
-- 由于是动态分区只需要声明分区字段即可,select要多写一个字段
insert into table dept_partition_dynamic
partition(loc)
select
deptno,
dname,
loc
from dept;
-- 查看目标分区表的分区情况
show partitions dept_partition_dynamic;
2. 分桶表
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive 可以进一步组织成桶,也就是更为细粒度的数据范围划分,分区针对的是数据的存储路径,分桶针对的是数据文件。分桶表的基本原理是,首先为每行数据计算一个指定字段的数据的
hash值,然后模以一个指定的分桶数,最后将取模运算结果相同的行,写入同一个文件中,这个文件就称为一个分桶(bucket)
2.1. 基本语法
-- 建表语句(分区要指定没有在create中的字段,而分桶表指定在create中的字段)
create table stu_bucket(
id int,
name string
)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\t';
-- 数据准备
vim /opt/module/datas/student.txt
1001 student1
1002 student2
1003 student3
1004 student4
1005 student5
1006 student6
1007 student7
1008 student8
1009 student9
1010 student10
1011 student11
1012 student12
1013 student13
1014 student14
1015 student15
1016 student16
-- 导入数据到分桶表中(4个文件)
load data local inpath '/opt/module/datas/student.txt'
into table stu_bucket;
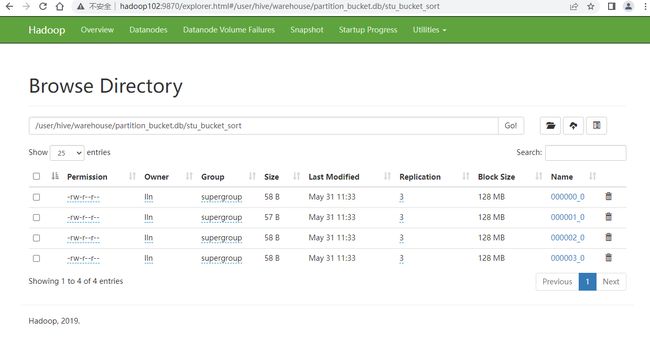
-- File information - 000000_0
1016 student16
1012 student12
1008 student8
1004 student4
-- File information - 000001_0
1009 student9
1005 student5
1001 student1
1013 student13
-- File information - 000002_0
1010 student10
1002 student2
1006 student6
1014 student14
-- File information - 000003_0
1003 student3
1011 student11
1007 student7
1015 student15
2.2. 分桶排序表
-- 分桶字段和排序字段不要求一致
create table stu_bucket_sort(
id int,
name string
)
clustered by(id) sorted by(id) into 4 buckets
row format delimited fields terminated by '\t';
-- 导入数据
load data local inpath '/opt/module/datas/student.txt' into table stu_bucket_sort;
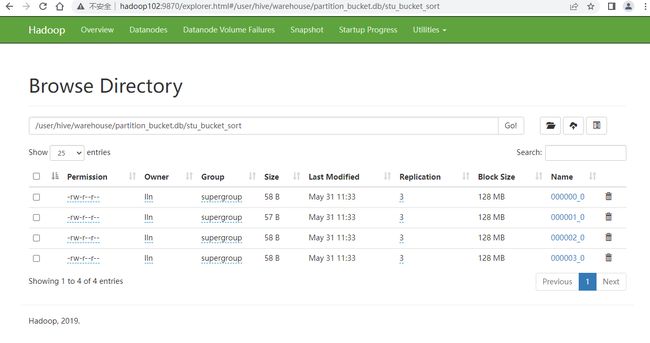
-- File information - 000000_0
1004 student4
1008 student8
1012 student12
1016 student16
-- File information - 000001_0
1001 student1
1005 student5
1009 student9
1013 student13
-- File information - 000002_0
1002 student2
1006 student6
1010 student10
1014 student14
-- File information - 000003_0
1003 student3
1007 student7
1011 student11
1015 student15
三、文件格式和压缩
hive底层是在HDFS上的,HDFS支持哪些压缩算法,hive就支持哪些,跟Hadoop保持一致,当成Hadoop的一个客户端,跟HDFS和YARN打交道
1. Hadoop压缩概述
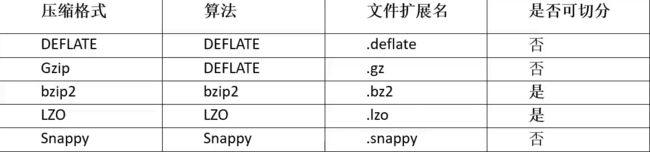
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示:

Hadoop查看支持压缩的方式:hadoop checknative,Hadoop在 driver端可以设置压缩
点击查看Hadoop压缩格式
2. Hive文件格式(orc/parquet)
为Hive表中的数据选择一个合适的文件格式,对提高查询性能的提高是十分有益的。Hive表数据的存储格式,可以选择
text file、orc、parquet、sequence file等
2.1. Text File(默认使用)
文本文件是Hive默认使用的文件格式,文本文件中的一行内容,就对应Hive表中的一行记录。非要显示的话,可通过以下建表语句指定文件格式为文本文件:

2.2. ORC(用的多)
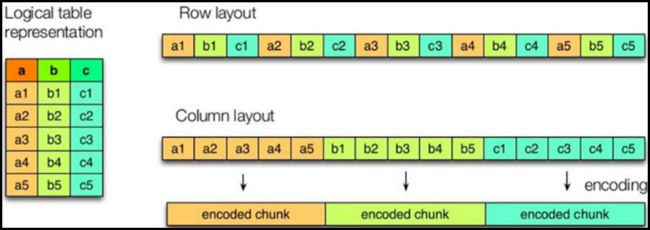
ORC(Optimized Row Columnar)file format是Hive 0.11版里引入的一种列式存储的文件格式。ORC文件能够提高Hive读写数据和处理数据的性能。与列式存储相对的是行式存储,下图是两者的对比:
- 行存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
- 列存储的特点(查得多)
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
前文提到的text file和sequence file都是基于行存储的,orc和parquet是基于列式存储的。
orc文件的具体结构如下图所示:
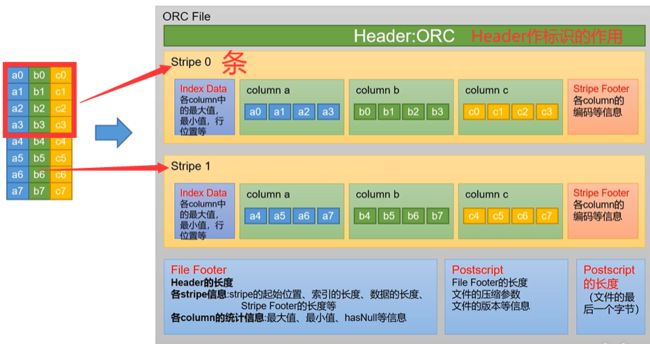
orc文件结构解读:每个Orc文件由Header、Body和Tail三部分组成。
-
其中
Header内容为ORC,用于表示文件类型。 -
Body由1个或多个stripe组成,每个stripe一般为HDFS的块大小,每一个stripe包含多条记录,这些记录按照列进行独立存储,每个stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer。
1️⃣Index Data:一个轻量级的index,默认是为各列每隔1W行做一个索引。每个索引会记录第n万行的位置,和最近一万行的最大值和最小值等信息。
2️⃣Row Data:存的是具体的数据,按列进行存储,并对每个列进行编码,分成多个Stream来存储。
3️⃣Stripe Footer:存放的是各个Stream的位置以及各column的编码信息,用编码存储数据省下了大量空间 -
Tail由File Footer和PostScript组成。File Footer中保存了各Stripe的其实位置、索引长度、数据长度等信息,各Column的统计信息等;PostScript记录了整个文件的压缩类型以及File Footer的长度信息等。
在读取ORC文件时,会先从最后一个字节读取PostScript长度,进而读取到PostScript,从里面解析到File Footer长度,进而读取FileFooter,从中解析到各个Stripe信息,再读各个Stripe拿到编码信息返回数据,即从后往前读,速度非常快!
了解更多点击查看官方orc说明文档
orc建表语法:
create table orc_table
(column_specs)
stored as orc
tblproperties (property_name=property_value, ...);

举个例子:
set hive.exec.mode.local.auto=true;
create database file;
use file;
-- 只需要加上stored as orc即可!!
create table test_org(
id int,
name string
)
stored as orc ;
-- 查看原生建表语句
show create table test_org;
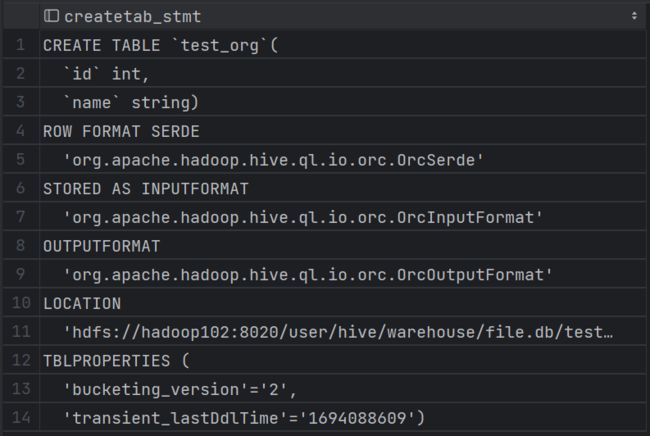
ROW FROMAT行的格式,SERDE序列化和解序列化器(读取、输出时用),INPUTFORMAT/OUTPUTFORMAT执行读写任务时供Mapredude用写读文件
一个文本文件想要进orc表中怎么办!
创建一个临时表,将数据load进临时表(普通文本文件),再用insert+select语句将数据导进orc表中
2.3. Parquet(同样用的多)
Parquet文件是Hadoop生态中的一个通用的文件格式,它也是一个列式存储的文件格式。Parquet文件的格式如下图所示:
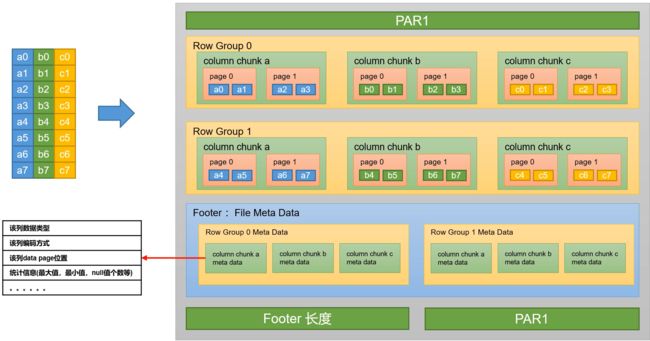
☝上图展示了一个Parquet文件的基本结构,文件的首尾都是该文件的Magic Code,用于校验它是否是一个Parquet文件。
1️⃣首尾中间由若干个Row Group和一个Footer(File Meta Data)组成。
2️⃣每个Row Group包含多个Column Chunk,每个Column Chunk包含多个Page。
3️⃣以下是Row Group、Column Chunk和Page三个概念的说明:
- 行组(
Row Group):一个行组对应逻辑表中的若干行。 - 列块(Column Chunk):一个行组中的一列保存在一个列块中。
- 页(Page):一个列块的数据会划分为若干个页。
4️⃣Footer(File Meta Data)中存储了每个行组(Row Group)中的每个列快(Column Chunk)的元数据信息,元数据信息包含了该列的数据类型、该列的编码方式、该类的Data Page位置等信息。
基本语法(跟orc类似)

3. 压缩(推荐snappy)
在Hive表中和计算过程中,保持数据的压缩,对磁盘空间的有效利用和提高查询性能(降低磁盘IO)都是十分有益的
3.1. Hive表数据进行压缩(textfile/orc/parquet)
在Hive中,不同文件类型的表,声明数据压缩的方式是不同的
TextFile:若一张表的文件类型为TextFile,若需要对该表中的数据进行压缩,多数情况下,无需在建表语句做出声明。直接将压缩后的文件导入到该表即可,Hive在查询表中数据时(select读取操作),可自动识别其压缩格式,进行解压。
需要注意的是,在执行往表中导入数据的SQL语句时(load写入操作),用户需设置以下参数,来保证写入表中的数据是被压缩的
--SQL语句的最终输出结果是否压缩
set hive.exec.compress.output=true;
--输出结果的压缩格式(以下示例为snappy)
set mapreduce.output.fileoutputformat.compress.codec =org.apache.hadoop.io.compress.SnappyCodec;
orc:若一张表的文件类型为ORC,若需要对该表数据进行压缩,需在建表语句中声明压缩格式如下
create table orc_table
(column_specs)
stored as orc
tblproperties ("orc.compress"="snappy");
Parquet:若一张表的文件类型为Parquet,若需要对该表数据进行压缩,需在建表语句中声明压缩格式如下
create table orc_table
(column_specs)
stored as parquet
tblproperties ("parquet.compression"="snappy");
3.2. 计算过程中使用压缩(2种)
1️⃣单个MR的中间结果进行压缩:单个MR的中间结果是指Mapper输出的数据,对其进行压缩可降低shuffle阶段的网络IO,可通过以下参数进行配置
-- 开启MapReduce中间数据压缩功能
set mapreduce.map.output.compress=true;
-- 设置MapReduce中间数据数据的压缩方式(以下示例为snappy)
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
2️⃣单条SQL语句的中间结果进行压缩:单条SQL语句的中间结果是指,两个MR(一条SQL语句可能需要通过多个MR进行计算)之间的临时数据,可通过以下参数进行配置
-- 是否对两个MR之间的临时数据进行压缩
set hive.exec.compress.intermediate=true;
-- 压缩格式(以下示例为snappy)
set hive.intermediate.compression.codec= org.apache.hadoop.io.compress.SnappyCodec;
总结
✍在Hive中,数据可以以行式存储或列式存储的方式进行组织。
- 行式存储:将数据按行存储在文件中,每行包含多个列的数据。
1️⃣优点是适合对整行数据进行查询和读取操作,特别是在需要获取完整记录的情况下效果较好
2️⃣然而,行式存储在处理某些特定的查询时可能会面临性能瓶颈,比如需要聚合大量数据或只需要部分列的查询 - 列式存储:是将数据按列存储在文件中,每个列都被单独存储
1️⃣优点是在需要对部分列进行查询时具有较高的性能,特别是当数据量较大时
2️⃣此外,列式存储还可以更好地支持压缩和列存储索引等技术,以提高查询效率
3️⃣但是,对于需要获取整行数据的查询,列式存储则需要额外的操作和资源。
在Hive中,可以根据数据的特点和查询需求来选择行式存储或列式存储。通常情况下,当数据量较大且查询需要涉及大量列时,使用列式存储可以提供更好的性能。而对于需要获取完整记录或只涉及少量列的查询,则行式存储可能更为适合。同时,Hive还提供了混合存储的方式,将行式和列式存储进行结合,以充分利用它们各自的优势。
✍下一节:hive企业级调优!