postgresql实现job的六种方法
简介
在postgresql数据库中并没有想oracle那样的job功能,要想实现job调度,就需要借助于第三方。本人更为推荐kettle,pgagent这样的图形化界面,对于开发更为友好
| 优势 | 劣势 | |
| Linux 定时任务(crontab) |
|
|
| pgagent |
|
|
| kettle(也称为 Pentaho Data Integration) |
|
|
| pg_cron |
|
|
| pg_timetable |
|
|
| 编程语句 |
|
|
创建模拟函数
以上文pgbouncer创建过程中由于userlist需要更新为例子,创建一个job,完成userlist的定时更新。
CREATE OR REPLACE FUNCTION export_userlist_to_file(date_param character)
RETURNS character AS
$$
BEGIN
EXECUTE 'COPY (SELECT ''"'' || usename || ''" "'' || passwd ||''"'' FROM pg_shadow) TO ''/home/postgres/pgbouncer/share/doc/pgbouncer/userlist.txt''';
RETURN date_param;
END;
$$
LANGUAGE plpgsql;
select export_userlist_to_file('20231010')Linux 定时任务(crontab)
这个是在linux操作中支持。这里创建一个用户专门用来调度,此用户必须拥有对函数的执行和访问权限,并设免密登录。你也可以使用.pgpass的方式配置用户密码。本问作为job实验,使用postgres用户进行操作,不再累述此类操作。
使用linux创建定时脚本。
vim postgres_job
并在文件中键入以下内容。
#!/bin/bash
#加载环境变量
. /etc/profile
. ~/.bash_profile
# 使用 `date` 命令获取当前日期
current_date=$(date +%Y%m%d)
# 然后你可以将这个变量作为参数传递给你的脚本或其他命令
#shell对换行敏感如果你需要执行多个函数,需要单引号内进行换行
psql -c "select export_userlist_to_file('$current_date')" 在postgres用户下 使用crontab -e 命令,编辑postgres的 crontab 文件

在脚本前方的五个位置,分别代表不同的含义。
* * * * * (EXECUTE) file
- - - - -
| | | | |
| | | | +----- 星期中星期几 (0 - 6) (星期天 为0)
| | | +---------- 月份 (1 - 12)
| | +--------------- 一个月中的第几天 (1 - 31)
| +-------------------- 小时 (0 - 23)
+------------------------- 分钟 (0 - 59)
0 0 * * * /home/postgres/pg_job
便是指定每天的零点执行/home/postgres/pg_job脚本
启动crond服务
systemctl start crond 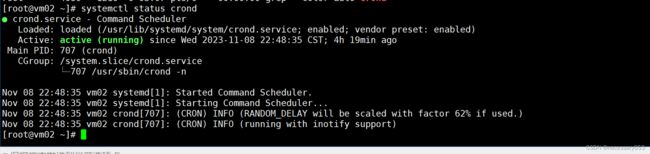 注意:
注意:
在pg_job脚本有增加这样一句加载环境变量
#加载环境变量
. /etc/profile
. ~/.bash_profile
因为crontab的特殊情况,执行用户和权限不一样,读取环境变量也不一样,需要指定变量。
pgAgent的job调度
pgAgent是支持图形化页面的,所以可以通过pgadmin4,为服务器下载pg_agent。安装非常简单



此时在pgadmin4下就可以看到pgagent jobs 了。
远程服务器是10.0.0.199,而此时pgAgent安装在本地,是要在IP互通的情况下同样可以为远程postgres数据库配置job
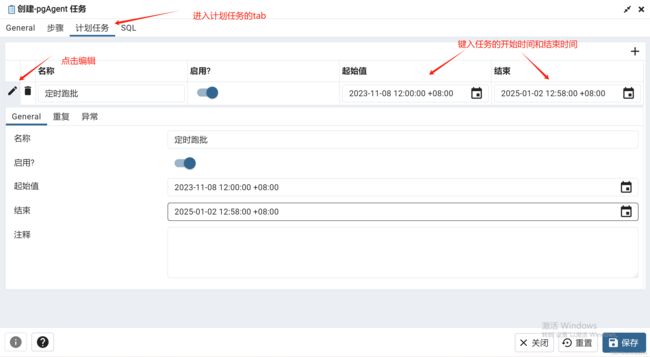
右键pgagent创建一个job,为其命名为zone_task
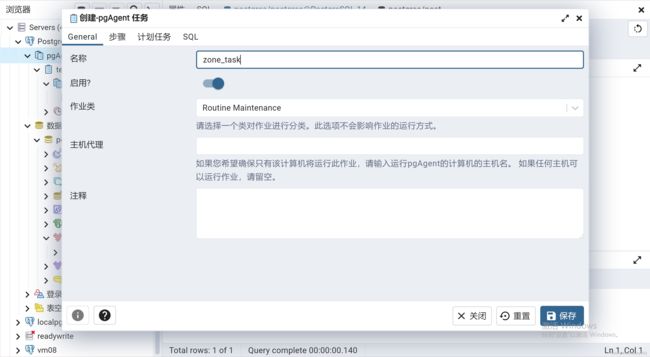
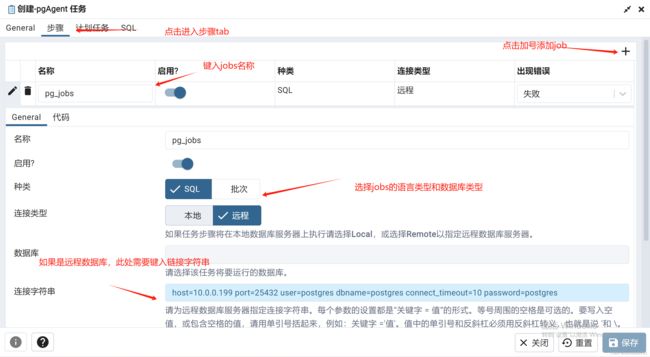
如下所示,编辑连接信息时,会暴露密码,此时可以使用.pgpass的配置方法,本文重要pgagent的使用,不再累述此操作。
host=10.0.0.199 port=25432 user=postgres dbname=postgres connect_timeout=10 password=postgres 这里的种类包含(SQL,批次),就是我们此批次的脚本使用的语言 ,这里批次指的是windows(Batch)或者linux(shell脚本),可以使用SQL意外的语言再去调度一次SQL脚本,本文使用SQL进行编辑。
为该job填入执行代码
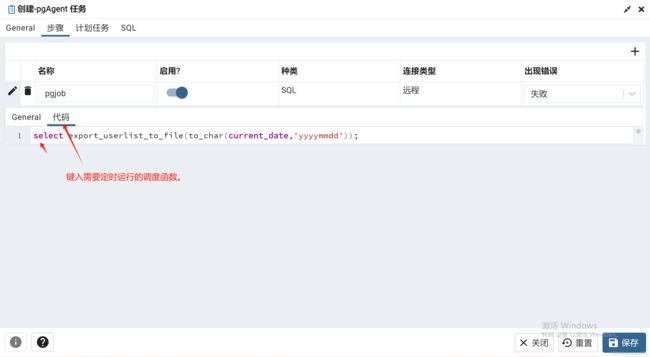

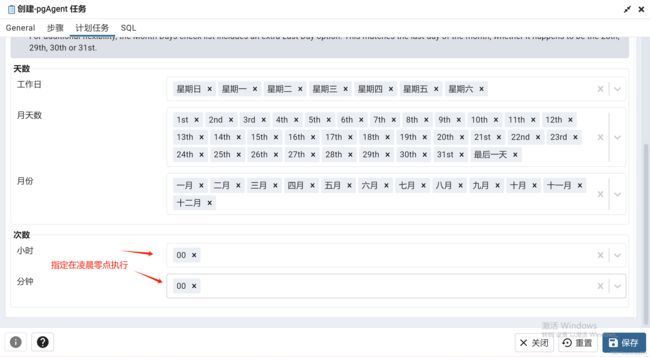
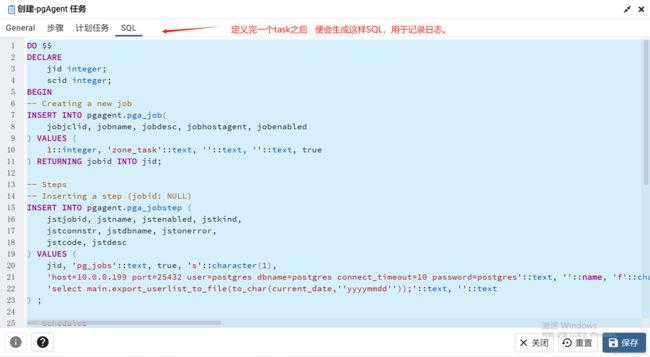
点击保存便可在页面上看到这样一个job,

pgAgent由于支持图形化页面展示,所以功能键展示相对较为完善,理解更为方便。
在安装完pgAgent后会生成一个shcema,名称为pgagent,并在此schema下生成三个函数,三个触发器,八张表
函数
1. pgagent.pga_is_leap_year: 这个函数用于判断一个年份是否是闰年。
2. pgagent.pga_next_schedule: 这个函数用于计算下一个调度时间。
3. pgagent.pgagent_schema_version: 这个函数用于获取pgAgent的模式版本。
表
1. pgagent.pga_exception: 这个表用于存储pgAgent在执行任务时遇到的异常。
2. pgagent.pga_job: 这个表用于存储pgAgent的任务信息。
3. pgagent.pga_jobagent: 这个表用于存储pgAgent的任务代理信息。
4. pgagent.pga_jobclass: 这个表用于存储pgAgent的任务类别信息。
5. pgagent.pga_joblog: 这个表用于存储pgAgent的任务日志。
6. pgagent.pga_jobstep: 这个表用于存储pgAgent的任务步骤信息。
7. pgagent.pga_jobsteplog: 这个表用于存储pgAgent的任务步骤日志。
8. pgagent.pga_schedule: 这个表用于存储pgAgent的调度信息。
触发器
1. pgagent.pga_exception_trigger(): 这个触发器在pga_exception表中插入或更新数据时触发。
2. pgagent.pga_job_trigger(): 这个触发器在pga_job表中插入或更新数据时触发。
3. pgagent.pga_schedule_trigger(): 这个触发器在pga_schedule表中插入或更新数据时触发。
functions
SELECT pgagent.pga_is_leap_year('2020') -- 返回 true,因为2020年是闰年
union all
SELECT pgagent.pga_is_leap_year('2021'); -- 返回 false,因为2021年不是闰年
select pgagent.pgagent_schema_version(); --返回pgAgent的版本号,是个固定返回值
pgagent.pga_next_schedule函数用于计算给定调度的下一个运行时间。它接受8个参数:
1. jscid: 调度ID
2. jscstart: 调度的开始时间
3. jscend: 调度的结束时间
4. jscminutes: 表示每个分钟是否有效的布尔数组
5. jschours: 表示每个小时是否有效的布尔数组
6. jscweekdays: 表示每个星期几是否有效的布尔数组
7. jscmonthdays: 表示每个月的哪一天是否有效的布尔数组
8. jscmonths: 表示每个月份是否有效的布尔数组
函数返回一个时间戳,表示下一个运行时间。如果没有下一个运行时间(例如,调度已经过了其结束日期),则返回NULL。
这是一个非常鸡肋的函数pgagent.pga_next_schedule是一个非常鸡肋的函数字,所以没必要关注。 博主也没兴趣举例子。
总的来说:这三个函数都没啥作用。
tables
1. pgagent.pga_exception:这个表用于存储pgAgent在执行任务时遇到的异常。
- jexid: 异常的唯一标识符
- jexscid: 引发异常的调度的ID
- jexdate: 异常发生的日期
- jextime: 异常发生的时间
2. pgagent.pga_job:这个表用于存储pgAgent的任务信息。
- jobid: 任务的唯一标识符
- jobjclid: 任务类别的ID
- jobname: 任务的名称
- jobdesc: 任务的描述
- jobhostagent: 任务的主机代理
- jobenabled: 表示任务是否启用的布尔值
- jobcreated: 任务创建的时间
- jobchanged: 任务最后一次修改的时间
- jobagentid: 任务代理的ID
- jobnextrun: 下一次运行的时间
- joblastrun: 上一次运行的时间
3. pgagent.pga_jobagent:这个表用于存储pgAgent的任务代理信息。
- jagpid: pgagent的进程号
- jaglogintime: 任务代理的登录时间
- jagstation: 任务代理的hostname
4. pgagent.pga_jobclass:这个表用于存储pgAgent的任务类别信息。
- jclid: 任务类别的唯一标识符
- jclname: 任务类别的名称
5. pgagent.pga_joblog:这个表用于存储pgAgent的任务日志。
- jlgid: 任务日志的唯一标识符
- jlgjobid: 任务的ID
- jlgstatus: 任务的状态(s:成功运行,f:运行失败)
- jlgstart: 任务开始的时间
- jlgduration: 任务的持续时间
6. pgagent.pga_jobstep:这个表用于存储pgAgent的任务步骤信息。
- jstid: 任务步骤的唯一标识符
- jstjobid: 任务的ID
- jstname: 任务步骤的名称
- jstdesc: 任务步骤的描述
- jstenabled: 表示任务步骤是否启用的布尔值
- jstkind: 任务步骤的类型
- jstcode: 任务步骤的代码
- jstconnstr: 任务步骤的连接字符串
- jstdbname: 任务步骤的数据库名称
- jstonerror: 任务步骤出错时的行为
7. pgagent.pga_jobsteplog:这个表用于存储pgAgent的任务步骤日志。
- jslid: 任务步骤日志的唯一标识符
- jsljlgid: 任务日志的ID
- jsljstid: 任务步骤的ID
- jslstatus: 任务步骤的状态
- jslresult: 任务步骤的结果
- jslstart: 任务步骤开始的时间
- jslduration: 任务步骤的持续时间
- jsloutput: 任务步骤的输出
8. pgagent.pga_schedule:这个表用于存储pgAgent的调度信息。
- jscid: 调度的唯一标识符
- jscjobid: 任务的ID
- jscname: 调度的名称
- jscdesc: 调度的描述
- jscenabled: 表示调度是否启用的布尔值
- jscstart: 调度的开始时间
- jscend: 调度的结束时间
- jscminutes: 表示每个分钟是否有效的布尔数组
- jschours: 表示每个小时是否有效的布尔数组
- jscweekdays: 表示每个星期几是否有效的布尔数组
- jscmonthdays: 表示每个月的哪一天是否有效的布尔数组
- jscmonths: 表示每个月份是否有效的布尔数组
注:重点关注两张表pgagent.pga_joblog,pgagent.pga_jobsteplog。这两张表算是使用频率比较高的了。
kettle(也称为 Pentaho Data Integration)
kettle同样也支持图形化界面,上手较为简单,支持跨库之间的协同。也支持复杂的流控制,有较多控件支持。
新建一个测试函数用于讲解kettle在参数传递过程中的使用
##创建一个测试函数
create or replace function main.text_log(v_date date,v_var varchar)
RETURNS void AS $$
BEGIN
insert into main.log(load_time,name) values(v_date,'测试成功'||v_var);
END;
$$ LANGUAGE plpgsql; 创建一个转换
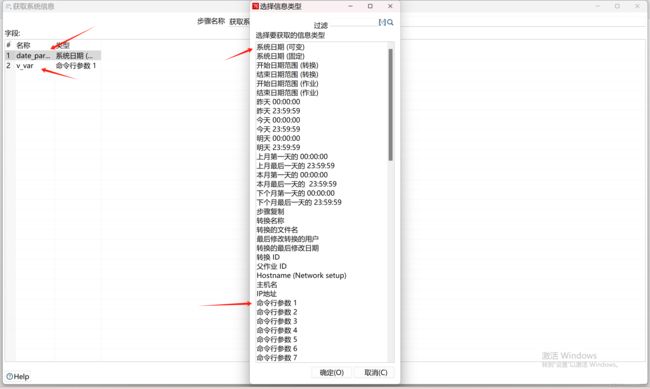
这里的参数传递需要和 函数参数的为的前后顺序对应

测试运行

执行成功后将该转换配置为job
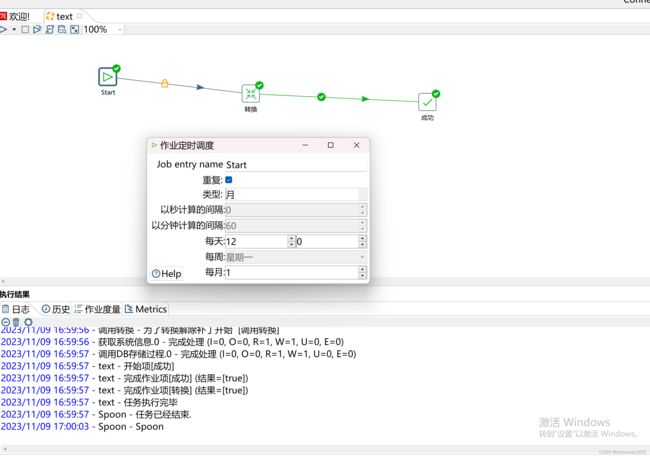
在start控件中可以调整任务调度的间隔信息,同时在kettle中也有很多控件可以满足我们大多数情况的复杂调度的需求。
只要以下该页面一直挂着,start设置的重复频率就有效。

在windows中该页面需要一直打开状态,才可以保持start控件的重复频率有效,也可以使用windows自带的任务计划程序,在linux中可以设置该程序的后台进行。
在windows中将该job设置为任务
使用任务计划程序,start的重复频率便会失效。job在被调用一次,执行一次成功之后便会退出。需要设置触发器,使其job被多次调用。

pg_cron
pg_cron是基于cron的作业调度插件,语法与常规cron相同,但它可以直接从数据库执行PostgreSQL命令。相较于前面得几个例子,安装pg_cron需要重启数据库,其功能性较为轻便化,不支持跨库处理,不支持复杂的控制流处理。
安装pg_cron 这个github上搜索就好了
unzip pg_cron-main
cd pg_cron-main
make && make install
额外得参数配置
#动态链接库
shared_preload_libraries='pg_cron'
#任务运行库
cron.database_name = 'postgres' 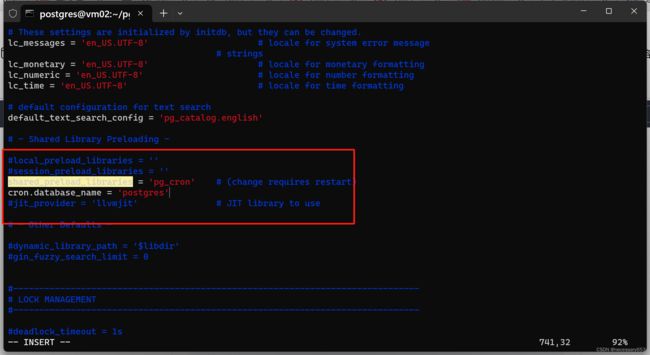
其实重启数据库
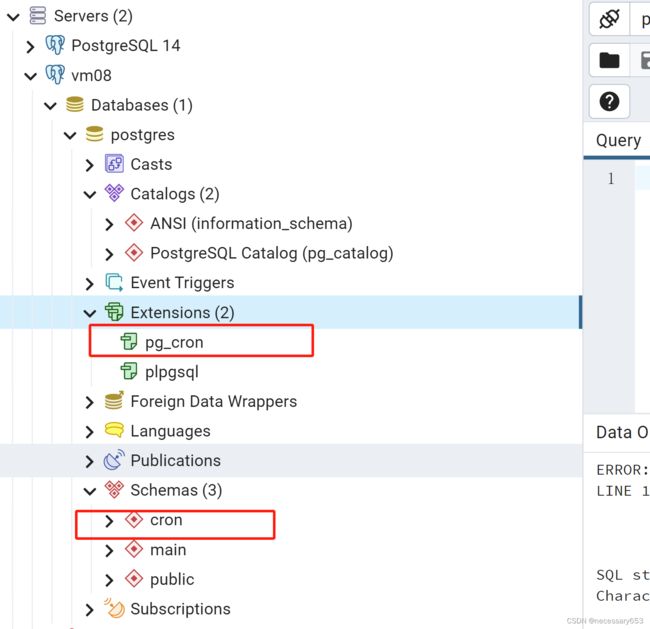
执行创建 extension
create extension pg_cron ;会生成一个cron得schema,并在该schema下生成 六个函数,两张表

function
#创建一个task
cron.schedule(
job_name text,
schedule text,
command text)
#创建一个名为job_namede 作业,每天十点整,执行一次insert 语句
select cron.schedule('job_name','0 10 * * *','insert into main.log(name) values('export_userlist_to_file');')
#在不定义job_name 得情况下也可以创建一个job,会
cron.schedule(
schedule text,
command text)
#用来修改已经存在的定时任务的属性,例如修改任务的执行计划、执行的命令、执行的数据库、执行的用户和是否激活任务。
cron.alter_job(
job_id bigint,
schedule text DEFAULT NULL::text,
command text DEFAULT NULL::text,
database text DEFAULT NULL::text,
username text DEFAULT NULL::text,
active boolean DEFAULT NULL::boolean)
#修改job_id为1得,其执行时间改为每天得十一点整,执行语句不变,执行数据库改为postgres,执行用户改为postgres,任务活跃状态不变。
select cron.alter_job(1,'0 11 * * *','','postgres','postgres','')
#确定一个特定的作业是否应该在当前数据库中调度。
cron.schedule_in_database(
job_name text,
schedule text,
command text,
database text,
username text DEFAULT NULL::text,
active boolean DEFAULT true)
#使得job失效,可以通过job_id,job_Name 进行传参
cron.unschedule(
job_id bigint)
cron.unschedule(
job_name text)
#使job_id 为1 job_name 为'job_name' 得job不再运行
select cron.unschedule(1);
select cron.unschedule('job_name'); tables
1. cron.job:这个表用于存储定时任务的信息。
- jobid: 任务的唯一标识符
- schedule: 任务的调度时间,使用cron语法
- command: 要执行的命令
- nodename: 节点名称,默认为'localhost'
- nodeport: 节点端口,默认为当前服务器的端口
- database: 要在其中执行命令的数据库,默认为当前数据库
- username: 要执行命令的用户,默认为当前用户
- active: 表示任务是否激活的布尔值,默认为'true'
- jobname: 任务的名称
- job_pkey: 主键约束,基于jobid
- jobname_username_uniq: 唯一约束,基于jobname和username
2. cron.job_run_details:这个表用于存储定时任务的运行详情。
- jobid: 任务的唯一标识符
- runid: 运行的唯一标识符
- job_pid: 任务的进程ID
- database: 在其中执行命令的数据库
- username: 执行命令的用户
- command: 执行的命令
- status: 任务的状态
- return_message: 返回的消息
- start_time: 任务开始的时间
- end_time: 任务结束的时间
- job_run_details_pkey: 主键约束,基于runid每一个定时任务分为两部分:
定时计划
规定使用插件的计划,例如每隔1分钟执行一次该任务。
定时计划使用标准的cron语法,其中*表示任意时间都运行,特定数字表示仅在这个时间时运行。
* * * * * (schedule)
- - - - -
| | | | |
| | | | +----- 星期中星期几 (0 - 6) (星期天 为0)
| | | +---------- 月份 (1 - 12)
| | +--------------- 一个月中的第几天 (1 - 31)
| +-------------------- 小时 (0 - 23)
+------------------------- 分钟 (0 - 59)
测试
创建一个测试函数
CREATE OR REPLACE FUNCTION main.cron_text(v_dt varchar
)
RETURNS void
LANGUAGE 'plpgsql'
COST 100
VOLATILE PARALLEL UNSAFE
AS $BODY$
declare
v_dt1 date ;
BEGIN
v_dt1 :=cast($1 as date);
insert into main.log(load_time,name) values(v_dt1,'cron测试');
END;
$BODY$;
创建一个调度
每天十点执行select main.cron_text(cast(current_date as varchar)) 指令
select cron.schedule('0 10 * * *','select main.cron_text(cast(current_date as varchar))') 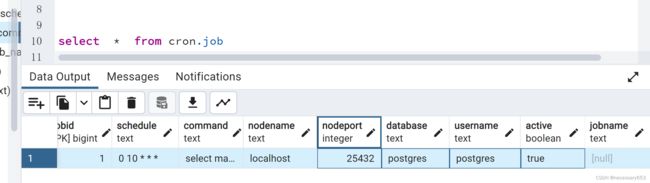
创建完成后可以在cron_job 中看到,此时因为在创建作业得时候并没有设置job_name所以此时job_Name 会是空值,
修改刚刚定义得job 使其每五分钟运行一次
select cron.alter_job(1,'*/5 * * * *');可以看到修改成功,
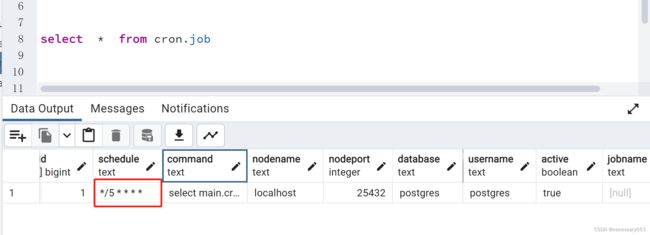
查看job运行状态
select * from cron.job_run_details;

pg_timetable
pg_timetable是一个功能十分全面的job调度工具,支持Windows、Linux 和 macOS 软件包可用。官方给出了
基础作业中支持
- Sleep(延迟睡眠)
- Log(日志记录)
- SendMail(邮件发送)
- Download(数据加载)
在控制流中支持
- Download files from a server(文件加载)
- Import files(导入文件)
- Run aggregations(聚合运算)
- Commit the transaction(事务提交)
- Remove the files from disk(磁盘文件清理)
个人觉得,功能在以上五个工具中是仅次于kettle的存在。正因为如此在复杂的作业流制定中其运维也是一个十分麻烦的存在。
pg_timetable安装
pg_timetable源码安装,采用go进行构建,需要安装GO在运行的系统中。也可以直接下载pg_timetable_4.5.0_Linux_x86_64.tar.gz 直接解压运行
安装go
wget https://go.dev/dl/go1.21.4.linux-amd64.tar.gzgo支持列表
- go1.21.4.linux-amd64.tar.gz: 这个压缩包适用于 x86_64 架构的 Linux 系统。
- go1.21.4.linux-arm64.tar.gz: 这个压缩包适用于 arm64 架构的 Linux 系统,例如 Raspberry Pi。
- go1.21.4.linux-armv6l.tar.gz: 这个压缩包适用于 armv6l 架构的 Linux 系统。
- go1.21.4.linux-386.tar.gz: 这个压缩包适用于 i386 架构的 Linux 系统。
使用后指令确认计算机系统的架构
uname -m解压
rm -rf /usr/local/go && tar -C /usr/local -xzf go1.21.4.linux-amd64.tar.gz
增加环境变量
export PATH=$PATH:/usr/local/go/bin srouce /etc/profile
##测试安装是否完成
go version
源码安装pg_timetable
下载程序包,并使用go语言进行编译
git clone https://github.com/cybertec-postgresql/pg_timetable.git
cd pg_timetable
go run main.go --dbname=postgres --clientname=timetable --user=postgres --password=postgresdbname: 这是数据库名称,程序需要知道连接到哪个数据库,所以需要预先定义好。clientname: 客户端名字,可以随便定义,一般用于标识不同的客户端实例。在数据库中会生成同名的schemauser: 用户名,需要预先在数据库中创建这个用户,并设置好权限。password: 密码,也需要预先设置好,用于登录数据库。
go build
./pg_timetable --dbname=postgres --clientname=timetable --port=35432 --user=postgres --password=postgres注:在go编译过程中需要下载一些依赖包,会出现connection refused的情况。
tar 安装
wget https://github.com/cybertec-postgresql/pg_timetable/releases/download/v5.6.0/pg_timetable_Linux_x86_64.tar.gz解压
tar -zxvf pg_timetable_Linux_x86_64
sudo mv pg_timetable_Linux_x86_64 /usr/local/pg_timetable
sudo vim /etc/profile
export PATH=/usr/local/pg_timetable:$PATH
source /etcprofile
#测试
pg_timetbale --help 启动进程
pg_timetable --dbname=postgres --clientname=timetable --user=postgres --password=postgres
[postgres@vm03 contrib]$ pg_timetable --dbname=postgres --clientname=timetable --user=postgres --password=postgres --port=35432
2023-11-12 22:42:57.935 [INFO] [sid:710227833] Starting new session...
2023-11-12 22:42:57.941 [INFO] Database connection established
2023-11-12 22:42:57.949 [INFO] Executing script: Schema Init
2023-11-12 22:42:58.033 [INFO] Schema file executed: Schema Init
2023-11-12 22:42:58.033 [INFO] Executing script: Cron Functions
2023-11-12 22:42:58.072 [INFO] Schema file executed: Cron Functions
2023-11-12 22:42:58.072 [INFO] Executing script: Tables and Views
2023-11-12 22:42:58.125 [INFO] Schema file executed: Tables and Views
2023-11-12 22:42:58.126 [INFO] Executing script: JSON Schema
2023-11-12 22:42:58.146 [INFO] Schema file executed: JSON Schema
2023-11-12 22:42:58.146 [INFO] Executing script: Job Functions
2023-11-12 22:42:58.164 [INFO] Schema file executed: Job Functions
2023-11-12 22:42:58.164 [INFO] Configuration schema created...
2023-11-12 22:42:58.177 [INFO] Accepting asynchronous chains execution requests...
2023-11-12 22:42:58.189 [INFO] [count:0] Retrieve scheduled chains to run @reboot
2023-11-12 22:42:58.210 [INFO] [count:0] Retrieve scheduled chains to run
2023-11-12 22:42:58.211 [INFO] [count:0] Retrieve interval chains to run
此时在数据库中可以看到创建一个timetable的schema
例子
此时在压缩包中自带一些对功能讲解的范例
/usr/local/pg_timetable/samples
自行实操不再累述