第五章 高级查询(二)
本章需要会使用GROUP BY 子句进行分组查询,会使用HAVING子句进行分组筛选,会使用多表连接查询,会使用UNIQUE联合查询结果,会使用SQL语句进行综合查询,本章任务是使用子查询制作学生成绩单,使用连接查询获得学生考试信息,使用UNION完成两校区数据统计,以及SQL语句的综合应用。
5.1 任务1:使用子查询制作学生成绩单啊
任务目标是了解分组查询的应用场景,会使用GROUP BY 进行分组查询,会使用HAVING子句对分组结果进行条件筛选。
5.1.1 使用GROUP BY进行分组查询
在实际应用中,常常需要对数据进行分组查询。例如,学生成绩表中存储了学生各课程的考试成绩,有时需要统计不同课程得到平均成绩,那就需要对成绩表中的记录按照课程来进行分组,然后针对每组计算平均成绩。
这种应用很普遍,例如一个电商平台销售洗衣机、冰箱、电视等,月末需要分类统计洗衣机销售总数、冰箱销售总数、电视销售总数,这就需要将冰箱、洗衣机、电视分成三组,然后每组分别进行汇总和统计,这实际上就是分组查询的实际应用,分组后的统计要利用前面学习过的聚合函数,SUM()、AVG()等
【示例1】
首先向学生成绩表中插入以下数据
INSERT INTO results VALUES(10000,1,'2019-02-17',71),(10001,2,'2019-03-06',60),(10002,1,'2019-02-17',83),(10002,2,'2019-03-06',78),(10004,1,'2019-02-17',60),(10004,2,'2019-03-06',51),(10005,1,'2019-02-17',95),(10006,1,'2019-02-17',95),(10007,1,'2019-02-17',23),(10007,3,'2019-07-04',90),(20000,3,'2019-07-04',78);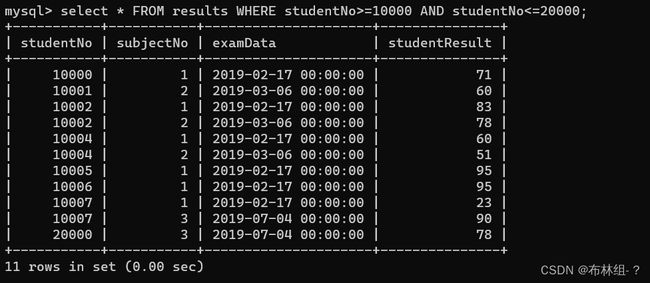 从表中的数据可以看出,该成绩表记录了学生3门课程的成绩,可成编号(subjectNo)分别是1,2,3.此时要统计不同课程的平均成绩,首先把相同的subject都分为一组,这样将数据分成了3组,
从表中的数据可以看出,该成绩表记录了学生3门课程的成绩,可成编号(subjectNo)分别是1,2,3.此时要统计不同课程的平均成绩,首先把相同的subject都分为一组,这样将数据分成了3组, 然后针对每组数据使用聚合函数取平均值,这样就得到了每门课程的平均成绩。
然后针对每组数据使用聚合函数取平均值,这样就得到了每门课程的平均成绩。
在编写SQL语句之前,先想想我们想要的输出结果是什么。我们想要的输出结果首先应该是不同的可成,其次是没门课程的平均成绩。那么我们还能够在查询中输出显示这张表中学生学号的信息吗,答案肯定是不行了。很明显。学生的学号与课程不是一对一的关系,因为课程已经分组了,分组后的组数减少为3组,而学生没有备份组,依然保持原来的个数,以上这种类型的查询,在MySQL中叫做分组查询。分组查询采用GROUP BY子句来实现。实现分组查询的SQL雨具如下:
SELECT subjectNo,AVG(studentResult) AS AVERAGEGRADE
FROM results
GROUP BY subject; 【示例2】查询男、女学生的人数各是多少
【示例2】查询男、女学生的人数各是多少
分析如下:首先按照性别列进行分组:GROUP BY sex;其次对每组的总人数进行统计,用到聚合函数COUNT(),
SELECT COUNT(*) AS 人数,sex FROM student GROUP BY sex; 不难理解,使用GROUP BY关键字时,在SELECT 后面可以指定的列是有限制的,仅允许以下几项
不难理解,使用GROUP BY关键字时,在SELECT 后面可以指定的列是有限制的,仅允许以下几项
(1)GROUP BY子句后的列
(2)聚合函数可以计算的列
被分组的列为每个分组返回一个值的表达式,如聚合函数可以计算的列。
【示例3】查询每个年级的总人数
SELECT gradeId AS GRADE,COUNT(*) from student GROUP BY gradeId;
【示例4】查询每门课程的平均成绩,并且按照从高到低的顺序进行排列显示,分析如下。思路同前面一样,按照课程进行分组。分数由高到低进行排序,需要用到ORDER BY子句子句,问题是这个ORDER BY子句放在哪个位置,问题是这个ORDER BY子句是在GROUP BY子句之后,仔细想一下,进行排序时,应该是对分组后的平均成绩进行排序,因此应该放在GROUP BY子句后面
SELECT subjectNO,AVG(studentResult) AS grade
FROM result GROUP BY subjectNo
ORDER BY AVG(studentResult) DESC;
5.1.2 多列分组查询
前面讲解的示例中,都是按照表中的某一列来进行分组,如性别、年级、可成。除此之外,分组查询有时候肯呢个还要按照多列进行分组,下面看一个具体事例
【示例5】
学生表student中记录了每个学生的信息,包括所属年级和性别等,要求统计每个年级的男、女学生人数。分析如下:理论上先把年级分开,在针对每个年级分别统计男、女学生人数,也就是需要按照所属年级和性别两列进行分组,SQL语句如下
SELECT gradeId AS GRADE,sex AS XB,COUNT(*) AS RS
FROM student GROUP BY gradeId,sex
ORDER BY gradeId;
5.1.3 使用HAVING子句进行分组筛选
通过前面的学习,我们已经基本了解了分组查询的意义和原理,下面再来分析以下几个查询需求。
【示例6】查询年级总人数超过2个人的年级,分析如下,首先可以通过分组查询获取每个年级的总人数,对应的SQL语句如下SELECT gradeId AS NJ,count(*) FROM student GROUP BY gradeId;
但是需求中还有一个条件,即人数超过2个人的年级。这涉及分组统计后的条件限制,限制条件为count(*)>2.这时使用WHERE子句是不能满足查询要求的,因为WHERE子句只能对没有分组的数据进行筛选,对分组后的条件的删选只能使用HAVING子句,简单来说,HAVING子句用来对分组后的数据进行筛选,将组看作列来限定条件,实现以上需求的SQL语句如下
SELECT gradeId AS NJ,count(*) AS 'rs' FROM student GROUP BY gradeId
HAVING COUNT(*)>2;
通过以上代码可以看出,HAVING子句对删选后的数据COUNT(*)进行判断,对于总数大于2的年级人数进行输出显示。
【示例7】查询平均成绩及格的课程信息
分析如下:在查询每个课程平均成绩的基础上,增加了一个条件,即平均成绩及格的可成,这样按照课程进行分组后,使用AVG(studentResult)>=60控制几个条件即可,
SELECT subjectNo AS 'KCBH',AVG(studentResult) AS AVERAGE
FROM results
GROUP BY subjectNo
HAVING AVG(studentResult)>=60
在上面的示例中,通过HAVING子句对分组的数据进行条件限定。事实上,HAVING子句和WHERE子句可以在同一个SELECT语句中一起使用其中必须先使用WHERE,后使用GROUP BY 最后使用HAVING,
【示例8】
查询每门课程及格总人数和学生的平均成绩
分析如下:我们需要对及格成绩进行统计,这样就要首先从数据源中将不及格的学生信息滤除,然后对符合及格要求的数据进行分组处理。完整的SQL语句如下
SELECT subjectNo,COUNT(*),AVG(studentResult) FROM RESULTS WHERE studentResult>=60 GROUP BY ubjectNo;
【示例9】查询每门课程及格总人数和及格平均成绩在80分以上的记录,
示例9查询需求与示例8一致吗,只是加了一个对分组后数据进行筛选的条件,即几个平均成绩在80分以上,因此需要增加HAVING子句:
SELECT subjectNo,count(*),AVG(studentResult) FROM results WHERE studentResult>=60
GROUP BY subjectNo HAVING AVG(studentResult)>=80;
【示例10】
在按照部分分类的员工表中,查询‘有两个及以上员工工资不低于2000元的部门编号’,员工信息表employee如下表所示
| 字段名称 | 说明 |
| deptId | 部门编号 |
| employeeId | 员工编号 |
| salary | 工资 |
分析如下:使用WHERE子句首先滤除工资低于2000元的记录,然后按照部门进行分组,最后对分组后的记录进行条件限定。
SELECT deptId,count(*) FROM employee
WHERE salary>=2000
GROUP BY deptId
HAVING count(*)>1;
上机练习1 使用分组查询学生相关信息
(1)查询每个年级的总学时数,并按照升序排列
(2)查询每个参加考试的学生的你的平均成绩。
(3)查询每门课程的平均成绩,并按照降序排列。
(4)查询每个学生参加的所有考试的总成绩,并按照降序排列。
SELECT gradeId,SUM(classHour) FROM subject GROUP BY gradeId ORDER BY gradeId;
SELECT studentNo,AVG(studentResult) FROM resultsGROUP BY studentNo;
SELECT subjectNo,AVG(studentResult) FROM results; GROUP BY subjectNo ORDER BY AVG(studentResult);
SELECT studentNo SUM(studentResult) FROM RESULTS GROUP BY studentNo ORDER BY SUM(studentResult) DESC;
上机练习2 限定条件的分组查询
(1)查询每个年级学时数超过50的课程
(2)查询每个年级学生的平均年龄。
(3)查询北京地区的每个年级的学生人数。
(4)查询参加考试的学生中平均成绩及格的学生记录,并按照成绩降序排列。
(5)查询考试日期为2019年2月17日的课程的及格平均成绩。
(6)查询至少一次考试不及格的学生学号,以及不及格次数。
SELECT gradeId,COUNT(*) FROM subject WHERE classHour>=50 GROUP BY gradeId;
SELECT gradeId,AVG(YEAR(NOW()-YEAR(birthday))) FROM student GROUP BY gradeId;
SELECT gradeId,count(*) FROM student WHERE address='bj' GROUP BY gradeId;
SELECT studentNo,AVG(studentResult) FROM results GROUP BY studentNO HAVING AVG(studentResult)>=60 ORDER BY AVG(studentResult) DESC;
SELECT subjectNo,AVG(studentResult) FROM results WHERE examData='2019-02-17' GROUP BY subjectNo HAVINF AVG(studentResult)>60
SELECT studentNo,count(*) FROM results WHERE studentNo IN (SELECT studentNo FROM RESULTS WHERE studentResult<60) GROUP BY studentNo;
上机练习3 制作学生成绩单
为每个学生制作在校期间各门课程的成绩单,要求每个学生参加没门课程的最近一次考试成绩作为该学生本课程的最终成绩,输出哥们课程的成绩,并按照年级顺序和姓名进行排序
(2)成绩单包括以下几个方面
姓名、课程所属年级、课程名称、考试日期、成绩
(1)使用分组查询获得每门课程最近一次考试的日期
(2)使用子查询获得相关小学生姓名。课程所属年级、课程名称、考试日期和成绩
参考解决方案如下
(1)使用分组查询获得每门课程最近一次考试的考试日期,需要按照课程分组:
SELECT MAX(examData),subjectNo FROM results GROUP BY subjectNo;
(2)使用子查询获得相关信息。输出信息的数据来源于学生表、课程表、和年级表,因此需要SELECT查询的SELECT 子句的子查询来实现
SELECT (SELECT studentName FROM student WHERE results.studentNo=student.studentNo) AS XM ,#子查询获得姓名,来源于学生表
(SEELCT (SELECT gradeName FROM grade WHERE subject.gradeId=grade.gradeId) FROM subject WHERE results.subjectNo=subject.subjectNo) AS 课程所属年级 ,#两级嵌套子查询获得年级名
(SELECT subjectName FROM subject WHERE results.subjectNo=subject.subjectNo) AS 课程名称,#子查询获得课程名称
examData AS '考试日期' studentResult AS 成绩
FROM results WHERE examData IN 省略代码
(3)不同课程最近一次考试日期为多条记录,因此使用IN子查询
examData IN (SELECT MAX(examData) FROM results GROUP BY subjectNo);
(4)输出语句要求按照年级顺序和姓名排序,因此如下:
ORDER BY (SELECT gradeID from subject WHERE results.subjectNo=subject,subjectNo),studentNo;
5.2 任务2:使用连接查询获得学生考试信息
任务目标,了解连接查询的用用场景及分类,掌握常用的连接查询的方法
前面章节讲述了子查询的使用,复杂的子查询往往嵌套多层,而且数据来源于多个数据表。对于涉及多个表的数据查询,除了通过子查询来实现,是否还有别的实现方法呢,可以使用多表连接查询。
5.2.1 多表连接查询的分类
在前面介绍的学生成绩查询示例中,通过成绩表可以获取学生的编号信息,因为该表中只存储了学生的编号所以要输出学生姓名,就要借助学生表来实现。像这种需要从多个表中选择获得比较数据项的情况,就可以使用多表连接查询。
多表连接查询实际上是通过各个表之间共同列的关联性来查询数据的,他是关系型数据库查询最主要的特征。以下是集中常用的连接查询方式:内连接查询、外连接查询
(1)内连接查询。内连接查询是最典型、最常用的连接查询,他根据表中共同列进行匹配,特备是两个表存在主外键关系时通常会用到内连接查询。
(2)外连接查询。外连接查询至少返回一个表中的所有记录,根据匹配条件有选择的返回另一个表的记录。外连接分为左外连接、右外连接。
下面一一介绍这几种连接查询的具体含义与用法。
5.2.2 内连接查询
内连接查询通常会使用‘=’或‘<>’等比较运算符来判断两列数据值是否相等,上面所说的根据学生学号来判断学生姓名就是一种内连接。
内连接使用INNER JOIN...ON 关键字或WHERE子句来进行表之间的关联。
【示例11】查询学生姓名和成绩
内连接查询可以通过如下两种方式实现
(1)在WHERE子句中指定连接条件
SELECT student.studentName,results.subjectNo,results.studentResult
FROM student,results
WHERE student.studentNo=results.studentNo;
上面这种形式的查询相当于在FROM后面紧跟了两个表明,在字段列表中用表明.列名来区分列,再在WHERE条件子句中加以判断,要求学生学号信息相等
(2)在FROM子句中使用INNER JOIN...ON
上面的查询语句也可以通过一下INNER JOIN...ON子句来实现。
关键代码:
SELECT S.studentName,R.subjectNO,R,studentRESULT
FROM student AS S
INNER JOIN result AS R ON(S.studentNO=R.studentNo)
在上面的内连接查询中:INNER JOIN 用来连接两个表;INNER可以省略;ON用来设置条件;AS指定表的别名,如果查询的列名在用到的两个或多哥表中不从夫,则对这一列的引用不必用表明来限定。
【示例12】
查询课程编号为1的及格学生的姓名和成绩
使用INNER JOIN内连接查询获得所有学生姓名和成绩;然后通过条件通过WHERE子句来进行筛选
SELECT S.studentName,R.subjectNo,R,studentResult
FROM student AS S
INNER JOIN results AS R ON(S.studentNo=R.studentNo)
WHERE R.studentResult>=60 AND R.subjectNo=1;
内连接不仅仅连接两个表,有时候还会涉及到三个表或者更多的表
查询学生姓名和成绩。要求输出列包括:学生姓名、课程名和成绩
输出的信息来源于三个不同的数据表:学生信息表、课程表和学生成绩表,首先需要通过学生信息表获取小学生姓名,此后通过课程编号来显示课程表中对应的课程名称,并通过学生编号来显示学生表中对应的成绩,因此可以用一下三表连接查询的SQL语句来实现
SELECT S.studentName AS '学生姓名',SU.subjectName AS '课程名称',studentResult AS 成绩
FROM student AS S
INNER JOIN subject AS SU ON (SU.subjectNo=R.subjectNo)
INNER JOIN result AS R ON(S.studentNo=R.studentNo);
上机练习4 两表内连接查询信息
以下查询均可使用INNER JOIN ...ON和WHERE两种方式完成
(1)查询学生姓名、所属年级名称及联系电话
(2) 查询参加课程编号为1的考试的学生姓名、成绩、考试日期。
(3)查询学号为10001的考试课程名称、成绩、考试日期
(4)查询参加考试的学生学号、考试课程名称、成绩、考试日期
(1) 该字段分别来自于student、grade、phonelist
SELECT S.studentName,G.gradeName,P.phone FROM student AS S
INNER JOIN grade AS G ON (G.gradeId=S.gradeId)
INNER JOIN phonelist AS P ON (P.studentName=S.studentName);
(2)SELECT S.studentName,R.studentResult,R.examData FROM student AS S INNER JOIN RESULTS AS R ON(S.studentNo=R.studentNo) WHERE R.subjectNo=1;
(3)查询学号为6的学生的考试课程名称,成绩,考试日期
该字段分别来自于subject、results、results,
SELECT subject.subjectName,results.studentResult,results.examData FROM RESULTS INNER JOIN subject on (subject.subjectNo=results.subjectNo) WHERE results.studentNo=1;
(4)查询参加考试的学生学号、考试课程名称、成绩、考试日期
SELECT results.studentNo, subject.subjectName,results.studentResult,results.examData FROM RESULTS INNER JOIN subject on (subject.subjectNo=results.subjectNo);
上机练习5 三表内连接查询信息
以下查询均可以通过INNER JOIN...ON和WHERE两种方式完成
(1)查询学生学号、姓名、考试课程名称和成绩
(2)查询参加Logic Java考试的学生姓名、成绩、考试日期
(3)将SQL语句保存为‘三表内连接查询信息’.sql
SELECT student.studentNo,student.studentName,subject.subjectName,results.studentResult
FROM student
INNER JOIN subject ON(student.gradeId=subject.gradeId)
INNER JOIN results ON(results.subjectNo=subject.subjectNo);
上机练习6 使用内连接查询制作学生课程单
使用内连接查询实现本章上机练习3的需求
(1)使用分组查询获得每门课程最近一次考试的日期
SELECT MAX(examData),subjectNo FROM results GROUP BY subjectNo;
(2)使用内连接查询得到学生姓名、年级、考试课程名称、考试日期和成绩,数据来源于四个不同的表:学生表、课程表、年级表、考试日期和成绩
SELECT studentName AS 姓名,gradeName AS 年级,subjectName AS 考试课程,examData AS 考试日期,studentResult AS 成绩
FROM results R
INNER Join student ST ON R.studentNo=ST.studentNo
INNER JOIN subject SU ON SU.subjectNo=R.subjectNo
INNNER JOIN grade G ON G.gradeId=SU.gradeId
WHERE examDat IN (SELECT MAX(examData) FROM results GROUP BY subjectNo) ORDER BY G.gradeId,studentName;
内连接查询会返回表关联后的所有字段,因此上机练习6中如果使用“*”取代限定的五个字段,运行时将会看到所有表的字段。例如,学生表和成绩表中都有studentNo字段,则输出的数据表中将会出现student和student(1)两个,同样gradeId也会出现两列,因此,ORDER BY子句中必须明确指明G.gradeId否则会出现错误。
5.2.3外连接查询
通过上面的例子可以看出,内连接查询的结果是从两个或两个以上的表的组合中删选出符合连接条件的数据,如果数据无法满足连接条件则将其忽略。在内连接查询中,参与连接的表的地位是平等的。
与内连接查询相对的方式称为外连接。参外连接查询中参与连接的表有主从之分,以主表的每行数据匹配从表的数据列,将符合条件的数据直接返回到结果集中,对那些不符合连接条件的列,将被填上NULL空值后返回结果集中。
1 左连接查询
左外连接查询的结果集包括LEFT JOIN子句中置顶的左表的所有行,而不仅仅是连接列所匹配的行,若左表的某行在由表中没有匹配行,则在相关联的结果集行中右表的所有选择列均为空值。
左连接查询使用LEFT JOIN...ON或LEFT OUTER JOIN ON关键字来进行表之间的关联
【示例14】统计所有学生的考试情况,要求现实所有参加考试学生的每次考试分数,没有参加考试的学生也要显示出来。
分析如下:根据需求,以学生信息表为主表,有时也称为左表、学生成绩表为从表进行左外连接。查询的SQL语句如下:
SELECT S.studentName,R.subjectNo,R.studentResult
FROM student AS S
LEFT OUTER JOIN results AS R ON s.studentNO=R.studentNo;
其中,对学生信息表的每一条记录跟成绩表的记录进行数据匹配(匹配条件是S.studentNo=R.studentNo).若匹配成功,则返回记录集(S.studentName,R.subjectName,R.studentResult的值);若没有找到匹配的值,则返回NULL(空值)填充数据集,所以成绩表中没有相关的考试记录。

思考如下SQL语句返回的结果是什么
SELECT SU.subjectName,R.studentNo,R.studentResult FROM subject AS SU LEFT OUTER JOIN results AS R ON SU.subjectNo=R.subjectNo;
2 右外连接查询
右外连接查询与左外连接查询查询类似,只不过要包含右表中所有匹配的行。若由表中某项在左表中没有匹配项,则以NULL填充。
右连接查询使用RIGHT JOIN...ON或RIGHT OUTER JOIN ...ON关键字来进行两表之间的关联。
【示例15】
在某数据库中,存在书籍表Titles和出版商表Publishers,他们通过pub_id进行外键关联,输出所有的出版商,及其所出版的书籍,分析如下:根据需求,以出版商表为右表与书籍表进行右外连接
SELECT Titles.Title_id,Titles.Title,Publishers.pub_name
FROM Titles
RIGHT OUTER JOIN Publishers ON Titles.Pub_id=Publishers.Pub_id;
可以发现没有书籍的出版商也会被列出来
思考在数据库myschool中,考虑到各表之间的关系,如下两条SQL语句返回的结果是否相同,第一条语句如下:
SELECT SU.subjectName,R.studentNo,R.studentResult FROM subject AS SU RIGHT OUTER JOIN results AS R ON SU.subjectNo=R.subjectNo;
SELECT SU.subjectName,R.studentNo,R.studentResult FROM subject AS SU INNER JOIN results AS R ON SU.subjectNo=R.subjectNo;
上机练习7
(1)查询所有课程的考试信息(某些课程可能还没有被考过)
(2)查询从未考试的课程信息。
(3)查询所有年级对应的学生信息(某些年级可能还没有学生就读)。
解答:
内连接
SELECT subject.subjectName,RESULTS.studentResult FROM subject INNER JOIN RESULTS ON subject.subjectNo=results.subjectNo;
左外连接:SELECT subject.subjectName,RESULTS.studentResult FROM subject LEFT OUTER JOIN RESULTS ON subject.subjectNo=results.subjectNo;
右外连接:SELECT subject.subjectName,RESULTS.studentResult FROM subject RIGHT OUTER JOIN RESULTS ON subject.subjectNo=results.subjectNo;
在右表中所有成绩均在左表中存在的,即每一个成绩studentResult都有一个左表中对应的学科,如果我们向results表中插入一行数据:
INSERT INTO RESULTS (studentNo,subjectNo,examData,studentResult) VALUES(30000,7,'1999-09-09',99);
后进行右连接:SELECT subject.subjectName,RESULTS.studentResult FROM subject RIGHT OUTER JOIN RESULTS ON subject.subjectNo=results.subjectNo;
出现我们的NULL,也就是说A左连接B,输出的行数目=两者均存在匹配的数目+A中有而B中没有的数据。A右连接B,输出的行数目=两者均匹配的数目+B中有而A中没有的数据,若全部都匹配那么外连接=内连接。
(2)在外连接的基础上进行WHERE,因为没有考试的情况下第二行也就是studentResult的值为NULL,从而在1的左外连接的基础上:SELECT subject.subjectName,RESULTS.studentResult FROM subject LEFT OUTER JOIN RESULTS ON subject.subjectNo=results.subjectNo WHERE results.studentResult IS NULL;
(3)分析:有些年级并没有就读,从而年级是右表(首先向grade中添加一些其他的年级:INSERT INTO grade VALUES(4,'FOUTHGRADE'); 然后我们右连接一下
SELECT student.studentName,grade.gradeName from student RIGHT OUTER JOIN grade ON grade.gradeId=student.gradeId;
5.3 任务3:使用UNION完成两校区数据统计
了解UNION的应用场景,掌握UNION的用法
5.3.1 联合查询的应用场景
通过前面章节的学习,我们了解到SELECT语句查询会获得一个结果集。如果我们想查询多个SELECT语句,并将每条SELECT语句查询出来的结果合并成一个结果集返回,就需要使用UNION关键字。例如,某公司总部下属多个实体企业,每个企业维护一套独立的人事系统,假设总部有对下属企业数据库的访问权限,总部希望查询上一年各企业新增员工的情况,就需要分别查询不同数据库的人员信息表,然后再将查询结果组合表示。再如,在一些大型项目中,数据经常分布在不同的数据表中,对于复杂业务往往需要将检索的数据组合显示。在这些引用中都需要使用联合查询。
所谓联合查询,就是合并多个相似的SELECT 查询的结果集。等同于将一个表追加到另一个表,从而实现将两个表的查询结果组合在一起的目的,使用关键字UNION或UNION ALL联合实现,下面来讲解UNION的使用方法。
5.3.2 使用UNION实现联合查询
要实现联合查询,需要使用UNION或UNION ALL,他可以将两个或两个以上的SELECT语句的查询结果集合合并成一个结果集显示,即执行联合查询,具体的语法格式如下.
SELECT ...UNION [ALL|DISTINCT] SELECT...[UNION [ALL | DISTINCT]] SELECT...];
从上面的语法可以看出,UNION将多个SELECT语句的结果进行组合,ALL选项表示将所有行合并到结果集中。如果不指定该项,联合查询结果集中的重复行将只保留一行,即UNION默认UNION DISTINCT,例如
| Table1 | |
| 列1 | 列2 |
| a | b |
| a | c |
| a | d |
进行合并
| Table2 | |
| 列1 | 列2 |
| a | d |
| a | c |
| 结果集 | |
| 列1 | 列2 |
| a | b |
| a | c |
| a | d |
| a | d |
| a | c |
使用UNION ALL合并所有行,而UNION合并后去除重复行
| 结果集 | |
| 列1 | 列2 |
| a | b |
| a | c |
| a | d |
| a | d |
在使用UNION进行联合查询时,可以从多个表中查询具有相似结构的数据并返回在一个结果集中.UNION查询返回的列名,以第一个SELECT语句的列名来命名。
【示例16】
某公司有多家分公司,为了方便管理,不同分公司维护各自的销售数据。例如,华南区订单表(order_hn)的部分内容如图,华东区订单表(order_hd)如图所示。年中时,需要汇总华南区和华东区的订单信息进行数据分析,请输出汇总后的数据,包括订单号、交易时间、交易额。
首先需要创建数据库:
CREATE DATABASE COMPANY;
USE COMPANY;
CREATE TABLE order_hn(
order_id VARCHAR(50) PRIMARY KEY,
trade_time DATETime,
status ENUM('0','1'),
transaction_amount INT(4)
);
INSERT INTO order_hn VALUES('HN10909891','2019-01-16 12:11:59','1',5000),
('HN10018938','2019-04-10 12:12:39','1',10000),
('HN29909891','2019-04-11 12:13:59','1',4080),
('HN10909808','2019-06-13 12:11:59','1',8000),
('HN10929822','2019-06-28 12:11:59','1',10000);
CREATE TABLE order_hd(id INT(4) PRIMARY KEY,orderNo INT(4),trans_time DATETIME, trans_amount INT(4),status ENUM('0','1'));
INSERT INTO order_hd VALUES(1,9089100,'2019-01-16 12:11:59',5000,'1'),
(2,9089101,'2019-04-10 12:12:39',10000,'1'),
(3,9089102,'2019-04-11 12:13:59',4080,'1'),
(4,9089103,'2019-06-13 12:11:59',8000,'1'),
(5,9089104,'2019-06-28 12:11:59',10000,'1'),
(6,9089105,'2019-06-28 12:11:59',10000,'1'); 华南地区订单表(order_hn)的部分内容
华南地区订单表(order_hn)的部分内容 从hn和hd两张表可以看出不同区域的订单表中字段并不相同,例如order_hn中,订单号为order_id,而在order_hd中,订单号为orderNo,两表中的其他字段也有类似的情况,但是考虑他们具有相似的结构,因此可以使用UNION执行联合查询,完整的SQL语句如下:
从hn和hd两张表可以看出不同区域的订单表中字段并不相同,例如order_hn中,订单号为order_id,而在order_hd中,订单号为orderNo,两表中的其他字段也有类似的情况,但是考虑他们具有相似的结构,因此可以使用UNION执行联合查询,完整的SQL语句如下:
SELECT order_id AS DDH,trade_time AS JYSJ,transaction_amount AS JE
FROM order_hn
UNION SELECT orderNo,trans_time,trans_amount FROM order_hd; 当UNION检索遇到不一直的列名时,会使用第一条SELECT的查询列名称,或者使用别名来改查询列的的名称,因此,在示例输出的结果集中,可以看到设定地标题信息‘订单号’,‘交易时间’,‘交易金额’,在执行联合查询时,应保证每个查询语句的选择列表中有相同数量的表达式,并且每个查询选择表达式因具有相同的数据类型,或时可以自动将他们转换为相同的数据类型,在自动转换时,对于数值类型,系统会将低精度的数据转换为高精度的数据类型。
当UNION检索遇到不一直的列名时,会使用第一条SELECT的查询列名称,或者使用别名来改查询列的的名称,因此,在示例输出的结果集中,可以看到设定地标题信息‘订单号’,‘交易时间’,‘交易金额’,在执行联合查询时,应保证每个查询语句的选择列表中有相同数量的表达式,并且每个查询选择表达式因具有相同的数据类型,或时可以自动将他们转换为相同的数据类型,在自动转换时,对于数值类型,系统会将低精度的数据转换为高精度的数据类型。
【示例17】
使用示例16的订单表,查询2019年4月的订单数据,并按照交易时间升序排列
分析如下:在执行联合查询前需要对数据进行筛选,在执行联合耗材芯厚再对结果进行排序
(SELECT order_id AS DDH,trade_time AS JYSJ,transaction_amount AS JYJE
FROM order_hn WHERE year(trade_time)='2019' AND MONTH(trade_tine)='4')
UNION
(SELECT orderNo,trans_time,trans_amount FROM order_hd WHERE YEAR(trans_time)='2019') AND MONTH(trans_time)='5')
ORDER BY 'JYSJ';
UNION查询只能对最终的结果集进行排序,因此,order BY必须出现在最后一条SELECT语句之后。注意在包括多个查询的UNION语句中,其执行顺序示从左到右的,通过使用括号可以改变执行顺序,例如:查询 1 UNION(查询2 UNION 查询3);表示查询2和查询3执行联合查询后,在和查询1执行联合查询。
上机练习8 完成两校区的数据统计
学期结束,需要对两校区(本区和天津校区)学生数据进行汇总分析。
(1)查询量校区的学生信息列表。
(2)查询本区和天津校区一年级‘Logic Java课程考试中达到优秀(80分以上)的总人数
提示
首先需要创建result_tj表:CREATE TABLE result_tj LIKE results;
insert into result_tj SELECT * FROM results;
然后使用UNION合并查询两校区符合条件的学生考试信息。这里,为了后面方便做数据分析,可以再查询结果中增加一列schoolZone",用于区分数据来源
SELECT studentNo,R.subjectNo,SU.subjectName,studentResult,'本区' AS schoolZone FROM results R INNER JOIN subject SU ON SU.subjectNo=R.subjectNo WHERE SU.subjectName='Logic Java' AND SU.gradeId=1:
UNION
SELECT studentNo,R.subjectNo,SU.subjectName,studentResult ,'天津校区' AS schoolZone FROM result_tj R inner JOIN subject SU ON SU.subjectNo=R.subjectNo WHERE SU.subjectName='Logic Java' AND SU.gradeId=1;
后使用FROM子句的子查询对联合查询结果按照条件进行筛选
SELECT subjectName AS kemu,count(*) AS '优秀人数总和',schoolZone AS 校区
FROM(联合查询的结果) AS TABLE_TEMP
WHERE studentResult>=80
GROUP BY schoolZone;
5.4 任务4:SQL语句的综合应用
任务目标是掌握子查询,会进行多表连接查询,掌握联合查询。
某公司为方便管理租房信息,聘请某项目组开发名为‘我的租房网’的管理软件。现在该项目组已经完成数据库的设计工作,处于正式编码阶段。‘我的租房网’的数据库house包括客户信息表(sys_user)、区县信息表(hos_district)、街道信息表(hos_street)、房屋类型表(hos_type)和出租房屋信息表(host_house)这5个表:
客户信息表(sys_user)
| 列名称 | 数据类型 | 说明 |
| uid | INT | 客户编号,逐渐,标识列从1开始,递增值为1 |
| uName | VARCHAR | 客户姓名,该列必填 |
| uPassword | VARCHAR | 客户秘密 |
曲线信息表(hos_district)
| 列名称 | 数据类型 | 说明 |
| did | INT | 区县编号,逐渐,标识列从1开始,递增值为1 |
借道信息表(hos_street)
| 列名称 | 数据类型 | 说明 |
| sid | INT | 借道编号,主键,标识列从1开始,递增值为1 |
| streetName | VARCHAR | 街道名称,该列必填 |
| did | INT | 区县编号,该列必填,外键 |
房屋类型表(hos_type)
| 列名称 | 数据类型 | 说明 |
| hTid | INT | 房屋类型编号,主键,标识列从1开始 |
| htName | CARCHAR | 房屋类型名称,该列必填 |
出租房屋信息表(hos_house)
| 列名称 | 数据类型 | 说明 |
| hMid | INT | 出租房屋编号,主键,标识列从1开始,递增值为1 |
| uid | INT | 客户编号,该列必填,外键 |
| sid | INT | 街道编号,该列必填,外键 |
| hTid | INT | 房屋类型编号,该列必填,外键 |
| price | DECIMAL | 每月租金,该列必填,默认值为0 |
| topic | VARCHAR | 标题,该列必填 |
| contents | VARCHA | 描述,该列必填 |
| hTime | TIMESTAMP | 发布时间,该列必填,默认值为当前时间 |
| copy | VARCHAR | 备注 |
现在来创建表和插入数据:
创建客户信息表
CREATE DATABASE house;
USE house;
CREATE TABLE sys_user(
uid INT(4) PRIMARY KEY AUTO_INCREMENT,
uName VARCHAR(50) NOT NULL,
uPassword VARCHAR(50)
);
ALTER TABLE sys_user AUTO_INCREMENT=1;
INSERT INTO sys_user (uName,uPassword) VALUES('a','1'),('b','2'),('c','3'),('d','4'),('e','5'),('aa','6'),('bb','7'),('cc','8'),('dd','9'),('ee','10');
创建区县信息表
CREATE TABLE hos_district(did INT(4) PRIMARY KEY AUTO_INCREMENT);
ALTER TABLE hos_district AUTO_INCREMENT=1;
INSERT INTO hos_district VALUES(1),(2),(3),(4),(5),(6),(7),(8),(9),(10);
创建街道信息表
CREATE TABLE hos_street(
sid INT(4) PRIMARY KEY AUTO_INCREMENT,
streetName VARCHAR(50) NOT NULL,
did INT(4)
);
ALTER TABLE hos_street AUTO_INCREMENT=1;
INSERT INTO hos_street(streetName,did) VALUES('q',1),('w',2),('e',3),('r',4),('t',5),('y',6),('u',7),('i',8),('o',9),('p',10);
房屋类型表(hos_type)
CREATE TABLE hos_type(hTid INT(4) PRIMARY KEY AUTO_INCREMENT,
htName VARCHAR(20) NOT NULL);
insert into hos_type (htName) VALUES('YSYT'),('LSYW'),('LSYT'),('YSYT');
出租房屋信息表(hos_house)
CREATE TABLE hos_house(hMid INT(4) PRIMARY KEY AUTO_INCREMENT,
uid INT(4) NOT NULL,
sid INT(4) NOT NULL,
hTid INT(4) NOT NULL,
price DECIMAL DEFAULT 0,
topic VARCHAR(50),
contents VARCHAR(50),
hTime TIMESTAMP DEFAULT NOW(),
copy VARCHAR(50));
INSERT INTO hos_house(uid,sid,hTid,price,topic,contents) VALUES(1,2,1,1000,'11','22'),(2,1,2,1000,'11','22'),(3,3,3,1000,'11','22'),(4,2,1,1000,'11','22'),(5,2,1,2000,'111','232'),(6,4,3,4000,'11','22'),(7,7,1,3000,'11','22'),(8,2,3,400,'11','22'),(9,2,1,1000,'11','22'),(10,2,1,1000,'11','22');
上机练习9 查询出租屋房屋信息并分页显示
查询输出低6-10条出租屋信息,并用临时表保存起来
CREATE TEMPORARY TABLE TMPTABLE (SELECT * FROM hos_house LIMIT 6,4);
临时表只在当前数据库链接课件,当连接关闭后,系统是自动删除临时表,不会占用数据库空间。修改临时表数据不会影响原表数据,因此当希望验证某些修改后的查询,又不想修改原表内容时,我们可以使用临时表。不会占用数据库空间。
上机练习10 查询指定客户发布的出租房屋信息
使用 姓名为a发布的出租房屋信息,并显示房屋分布的街道和区县
SELECT hos_street.streetName,host_type.htName,price,topic,contents,hTime,copy FROM hos_house INNER JOIN hos_street on hos_street.sid=hos_house.sid
INNER JOIN host_type ON host_type.hTid=hos_house.hTid
上机练习11 按区县制作房屋出租清单
SELECT hos_type.htName,sys_user.uName,hos_street.did,hoststreet.streetName FROM hos_house
INNER JOIN hos_street on hos_street.sid=hos_house.sid
INNER JOIN host_type ON host_type.hTid=hos_house.hTid
INNER JOIN sys_user on sys_user.uid=hos_house .sid
WHERE hos_street.did in (SELECT did FROM hos_street WHERE did IN (SELECT sid FROM hos_house group by sid) GROUP BY did HAVING count(*)>1);
上机练习12
按季度统计2019年发布的出租屋数量
(1)按季度统计处各区县、借道、户型出租房屋的数量。
(2)输出2019年的全部出租房屋数量、各区县出租房屋数量以及各街道、各户型房屋数量。