【LeetCode】SQL题单 持续更新......
文章目录
- 说明
- 175 组合两个表
- 176 第二高的薪水
- 177 第N高的薪水
- 178 分数排名
- 180 连续出现的数字
- 181 超过经理收入的员工
- 182 查找重复的电子邮箱
- 183 从不订购的客户
- 184 部门工资最高的员工
- 185 部门工资前三高的所有员工
- 196 删除重复的电子邮箱
- 197 上升的温度
- 595 大的国家
- 596 超过5名学生的课
- 620 有趣的电影
- 626 换座位
- 627 变更性别
- 1322 广告效果
- 1327 列出指定时间段内所有的下单产品
- 1341 电影评分
- 1350 院系无效的学生
- 1369 获取最近第二次的活动
- 1378 使用唯一标识码替换员工ID
- 1384 按年度列出销售总额(困难)
- 1393 股票的资本损益
- 1398 购买了产品A和产品B却没有购买产品C的客户
- 1407 排名靠前的旅行者
- 1440 计算布尔表达式的值
- 1445 苹果和桔子
- 1454 活跃用户
- 1459 矩形面积
- 1484 按日期分组销售产品
- 1501 可以放心投资的国家
- 1527 患某种疾病的患者
- 1532 最近的三笔订单
- 1549 每件商品的最新订单
- 1571 仓库经理
- 1581 进店却为进行交易的顾客
- 1587 银行账户概要II
- 1596 每位顾客最经常订购的商品
- 1607 没有卖出的卖家
- 1613 找到遗失的ID
- 1633 各赛事的用户注册率
- 1667 修复表中的名字
- 1693 每天的领导和合伙人
- 1699 两人之间的通话次数
- 1709 访问日期之间最大的空档期
- 1729 求关注者的数量
- 1731 每位经理的下属员工数量
- 1741 查询每个员工花费的总时间
- 1747 应该被禁止的Leetflex账户
- 1757 可回收且低脂的产品
- 1783 大满贯数量
- 1795 每个产品在不同商店的价格
- 1831 每天的最大交易
- 1867 最大数量高于平均水平的订单
- 1873 计算特殊奖金
- 1890 2020年最后一次登录
- 1949 坚定的友谊
- 1951 查询具有最多共同关注者的所有两两结对组
- 1965 丢失信息的雇员
- 1988 找出每个学校的最低分数要求
说明
其中有一部分题目包括了【LeetCode】精选数据库70题的题目,这里就不在重复写了
175 组合两个表
SELECT firstName,lastName,city,state
FROM Person t1
LEFT JOIN Address t2 ON t1.personId = t2.personId;
176 第二高的薪水
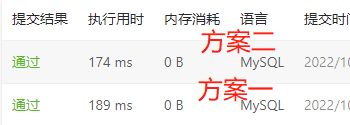
方案一
先按照salary从大到小排序,使用DENSE_RANK()对其进行标号,可能存在多个员工salary一样的情况,所以使用DENSE_RANK(),这一种并列排序,不会跳过重复的序号。将在原有基础上标号的表作为临时表,查找出其中需要序号是2的记录,也可能不止一条,如果没有标号为2的记录,则说明该部门只有一个人,或者该部门有多个人,但是员工的salary都是一样的。如果序号为2的记录的数量大于等于1,则输出salary否则输出null。
WITH salary_rank AS (
SELECT
id,
salary,
DENSE_RANK() OVER(ORDER BY salary DESC) rk
FROM Employee
)
SELECT IF(COUNT(*)>=1,salary,NULL) SecondHighestSalary
FROM salary_rank
WHERE rk = 2;
方案二
和上面的思路一样,不过临时表中的salary已经去重了(用GROUP BY去重),所以,可以用ROW_NUMBER()进行标号。
WITH salary_rank AS (
SELECT
salary,
ROW_NUMBER() OVER(ORDER BY salary DESC) rk
FROM Employee
GROUP BY salary
)
SELECT IF(COUNT(*)=1,salary,NULL) SecondHighestSalary
FROM salary_rank
WHERE rk = 2;
官方思路
将不同的薪资按照降序排序,然后使用LIMIT子句获取第二高的薪资
SELECT DISTINCT
Salary AS SecondHighestSalary
FROM
Employee
ORDER BY salary DESC
LIMIT 1 OFFSET 1
上面的SQL如果没有第二高的薪资,会什么都不输出,并不会输出NULL;为了克服这个问题,可以将其作为临时表。
SELECT (
SELECT DISTINCT salary
FROM Employee
ORDER BY salary DESC
LIMIT 1 OFFSET 1
) SecondHighestSalary ;
使用IFNULL也可以
SELECT IFNULL(
(
SELECT DISTINCT salary SecondHighestSalary
FROM Employee
ORDER BY salary DESC
LIMIT 1 OFFSET 1
),NULL
) SecondHighestSalary ;
177 第N高的薪水
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
SET N = N -1;
RETURN (
SELECT DISTINCT salary
FROM Employee
ORDER BY salary DESC
LIMIT 1 OFFSET N
);
END
178 分数排名
方案一:使用窗口函数DENSE_RANK()
本题需要注意的是rank要加上` `这个符号,不然报错
SELECT
score,
DENSE_RANK() OVER(ORDER BY score DESC) `rank`
FROM Scores
方案二:不使用窗口函数,使用表连接
最后的结果包含两个部分:第一部分是降序排列的分数,第二部分是每个分数对应的排名
第一部分的降序排列可以使用ORDER BY … DESC 排序
第二部分是每个分数对应的排名,可以先提取出大于等于X的所有分数集合H,将H去重后的元素个数就是X的排名。
(我觉得这个比较巧妙的点在于:提取出大于等于X的分数,但是会存在重复的分数,所以需要去重)
不过方案二和方案一的执行时间还是差得有点多…
SELECT t1.score, (SELECT COUNT(DISTINCT t2.score) FROM Scores t2 WHERE t2.score >= t1.score) `rank`
FROM Scores t1
ORDER BY t1.score DESC;
180 连续出现的数字
SELECT
DISTINCT num AS ConsecutiveNums
FROM (
SELECT
id,
num,
LEAD(num,1) OVER() lead_1,
LEAD(num,2) OVER() lead_2
FROM `Logs`
) temp
WHERE num=lead_1 AND num=lead_2;
181 超过经理收入的员工
SELECT t1.name Employee
FROM Employee t1
JOIN Employee t2 ON t1.managerId = t2.id
WHERE t1.salary > t2.salary;
182 查找重复的电子邮箱
SELECT Email
FROM Person
GROUP BY Email
HAVING COUNT(Email)>1;
183 从不订购的客户
SELECT Name Customers
FROM Customers
WHERE Id NOT IN (
SELECT DISTINCT CustomerId
FROM Orders
);
184 部门工资最高的员工
方法一:使用窗口函数
SELECT Department,Employee,salary
FROM (
SELECT
t2.name Department,
t1.name Employee,
salary,
DENSE_RANK() OVER(PARTITION BY t2.name ORDER BY t1.salary DESC) rk
FROM Employee t1
JOIN Department t2 ON t1.departmentId = t2.id
) temp
WHERE rk = 1;
方法二
先查询出每个部门的最高工资,之后将Employee表和Department表连接,取出工资是最高工资的员工,不能直接使用GROUP BY按照部门分组,因为一个部门里可能有多个工资是最高工资的员工
SELECT t2.name Department,t1.name Employee, t1.salary Salary
FROM Employee t1
JOIN Department t2
ON t1.departmentId = t2.id
WHERE (t1.departmentId,t1.salary) IN (
SELECT departmentId,MAX(salary) max_salary
FROM Employee
GROUP BY departmentId
)
185 部门工资前三高的所有员工
SELECT department_name Department,employee_name Employee, salary Salary
FROM(
SELECT
t2.name department_name,
t1.name employee_name,
t1.salary,
DENSE_RANK() OVER(PARTITION BY t2.name ORDER BY t1.salary DESC) rk
FROM Employee t1
JOIN Department t2
ON t1.departmentId = t2.id
) tmp
WHERE rk <= 3;
196 删除重复的电子邮箱
需要注意的是,本题要求写的是DELETE语句
使用窗口函数对表中的数据进行标号,按照email进行分组,对于每个分组中,按照id的升序进行排序,那些序号不为1的,就说明是email重复的,且Id较大的记录,需要删除
DELETE FROM Person
WHERE id IN (
SELECT id
FROM (
SELECT
id,
email,
ROW_NUMBER() OVER(PARTITION BY email ORDER BY id) rk
FROM Person
)temp
WHERE rk != 1
);
197 上升的温度
方法一:表的自连接
SELECT t1.id
FROM Weather t1
JOIN Weather t2
ON DATEDIFF(t1.recordDate,t2.recordDate)=1
AND t1.Temperature > t2.Temperature;
方法二:窗口函数
SELECT id
FROM (
SELECT
id,
recordDate,
temperature,
LAG(recordDate,1) OVER(ORDER BY recordDate) lastDate,
LAG(temperature,1) OVER(ORDER BY recordDate) lastTemperature
FROM Weather
)temp
WHERE TIMESTAMPDIFF(DAY,recordDate,lastDate)=-1 AND temperature > lastTemperature;
595 大的国家
SELECT name, population, area
FROM World
WHERE area >= 3000000 OR population >= 25000000;
596 超过5名学生的课
方案一
SELECT class
FROM Courses
GROUP BY class
HAVING COUNT(class) >= 5;
方案二
SELECT class
FROM (
SELECT class,COUNT(class) nums
FROM Courses
GROUP BY class
) temp
WHERE nums >= 5;
分组以后的结果作为,子表,在WHERE中进行过滤,执行用时更短
620 有趣的电影
SELECT id,movie,description,rating
FROM cinema
WHERE description != 'boring' AND id%2=1
ORDER BY rating DESC;
626 换座位
方案一 我的思路
SELECT
id,
IFNULL(
IF(id%2=0,
LAG(student,1) OVER(),
LEAD(student,1) OVER()),student) student
FROM Seat;
方案二 其他解答
SELECT
IF(
id%2=0,
id-1,
IF(
id=(SELECT MAX(id) FROM Seat),
id,
id+1
)
) id,
student
FROM Seat
ORDER BY id ASC;
627 变更性别
UPDATE Salary
SET sex = CASE sex WHEN 'm' THEN 'f' ELSE 'm' END;
通过这一题了解到,原来UPDATE语句中,也能写CASE WHEN …
1322 广告效果
SELECT
ad_id,
ROUND(
IFNULL(SUM(IF(action='Clicked',1,0))*100/SUM(IF(action='Ignored',0,1)),0)
,2)ctr
FROM Ads
GROUP BY ad_id
ORDER BY ctr DESC,ad_id ASC;
会出现NULL的情况,就是题目中所给的例子,ad_id=5的数据只有一条,且action=Ignored,这样用我的计算方法计算,会出现分母为0的情况,所以外面要包一层IFNULL
1327 列出指定时间段内所有的下单产品
SELECT t2.product_name,SUM(t1.unit) unit
FROM Orders t1
JOIN Products t2 ON t1.product_id = t2.product_id
WHERE DATE_FORMAT(t1.order_date,'%Y-%m') = '2020-02'
GROUP BY t1.product_id
HAVING SUM(unit) >= 100;
1341 电影评分
(
SELECT
t2.name results
FROM MovieRating t1 JOIN Users t2 ON t1.user_id = t2.user_id
GROUP BY t1.user_id
ORDER BY COUNT(*) DESC, t2.name ASC
LIMIT 1
)
UNION ALL
(
SELECT
t2.title results
FROM MovieRating t1 JOIN Movies t2 ON t1.movie_id = t2.movie_id
WHERE DATE_FORMAT(t1.created_at,'%Y-%m')='2020-02'
GROUP BY t1.movie_id
ORDER BY AVG(t1.rating) DESC,t2.title
LIMIT 1
);
1350 院系无效的学生
SELECT id,name
FROM Students
WHERE department_id NOT IN (
SELECT id
FROM Departments
);
SELECT
t1.id,
t1.name
FROM Students t1
LEFT JOIN Departments t2
ON t1.department_id = t2.id
WHERE t2.id IS NULL;
1369 获取最近第二次的活动
SELECT username,activity,startDate,endDate
FROM (
SELECT
username,
activity,
startDate,
endDate,
ROW_NUMBER() OVER(PARTITION BY username ORDER BY startDate DESC) rk,
COUNT(*) OVER(PARTITION BY username) cnt
FROM UserActivity
) tmp
WHERE (cnt>1 AND rk=2) OR (cnt=1 AND rk=1);
1378 使用唯一标识码替换员工ID
SELECT t2.unique_id,t1.name
FROM Employees t1
LEFT JOIN EmployeeUNI t2 ON t1.id = t2.id;
1384 按年度列出销售总额(困难)
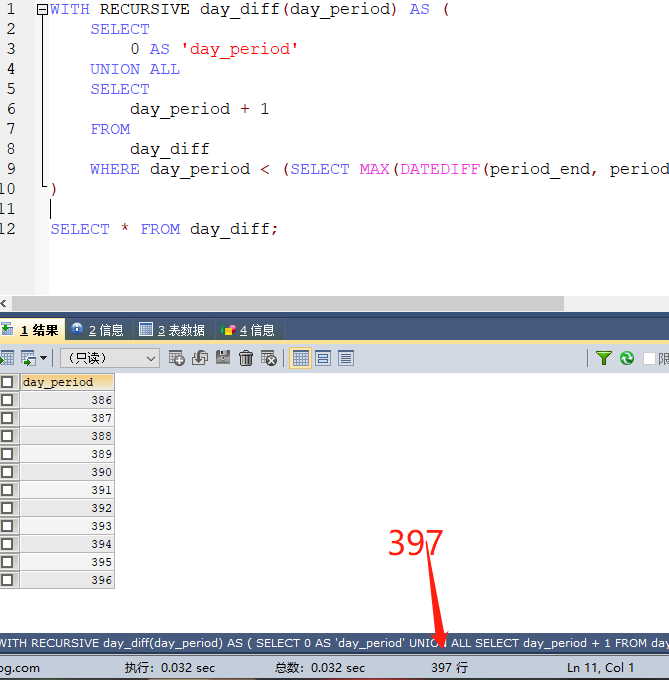
这题的难点在于我们只知道销售的起止日期,需要的是具体的天数
先获取所有的销售天数差,这里需要从0开始直到最大值,使用CTE递归是最简单的解法
WITH RECURSIVE day_diff(day_period) AS (
SELECT
0 AS 'day_period'
UNION ALL
SELECT
day_period + 1
FROM
day_diff
WHERE day_period < (SELECT MAX(DATEDIFF(period_end, period_start)) FROM Sales)
)
在原表上加入我们得到的天数差,这样一来得到的就是每天的日期,再取这些日期的年份就可以按照年份分组了
DATE_FORMAT(DATE_ADD(t1.period_start, INTERVAL t2.day_period DAY), '%Y')
...
INNER JOIN day_diff AS t2 ON DATEDIFF(t1.period_end, t1.period_start) >= t2.day_period
因为我们连接了日期差这张表,所以连接后的表对应的行数其实就是天数,所以,我们此时直接统计每件商品对应的所有的平均日金额就能得到总金额了
最后只需要限制一下日期,写一下分组即可
WITH RECURSIVE day_diff(day_period) AS (
SELECT
0 AS 'day_period'
UNION ALL
SELECT
day_period + 1
FROM
day_diff
WHERE day_period < (SELECT MAX(DATEDIFF(period_end, period_start)) FROM Sales)
)
SELECT
t1.product_id,
t3.product_name,
DATE_FORMAT(DATE_ADD(t1.period_start,INTERVAL t2.day_period DAY),'%Y') report_year,
SUM(t1.average_daily_sales) total_amount
FROM Sales t1
JOIN day_diff t2 ON DATEDIFF(t1.period_end,t1.period_start) >= t2.day_period
JOIN Product t3 ON t1.product_id = t3.product_id
GROUP BY t1.product_id,t3.product_name,report_year
ORDER BY t1.product_id,report_year;
1393 股票的资本损益
SELECT
stock_name,
SUM(IF(operation='buy',-price,price)) capital_gain_loss
FROM
Stocks
GROUP BY
stock_name;
1398 购买了产品A和产品B却没有购买产品C的客户
分组,查出买A的数量>0且买B的数量>0且买C的数量为0的客户Id,然后左连接查出客户的名字即可
SELECT t1.customer_id,t2.customer_name
FROM Orders t1 JOIN Customers t2
ON t1.customer_id = t2.customer_id
GROUP BY t1.customer_id
HAVING
SUM(IF(product_name='A',1,0))>0 AND
SUM(IF(product_name='B',1,0))>0 AND
SUM(IF(product_name='C',1,0))=0
1407 排名靠前的旅行者
SELECT t1.name, IFNULL(SUM(t2.distance),0) travelled_distance
FROM Users t1
LEFT JOIN Rides t2 ON t1.id = t2.user_id
GROUP BY t1.id
ORDER BY travelled_distance DESC, t1.name ASC;
1440 计算布尔表达式的值
SELECT
t1.left_operand,
t1.operator,
t1.right_operand,
CASE
WHEN t1.operator = '>' AND t2.value > t3.value THEN 'true'
WHEN t1.operator = '<' AND t2.value < t3.value THEN 'true'
WHEN t1.operator = '=' AND t2.value = t3.value THEN 'true'
ELSE 'false'
END value
FROM Expressions t1, Variables t2, Variables t3
1445 苹果和桔子
SELECT sale_date, SUM(IF(fruit='apples',sold_num,-sold_num)) diff
FROM Sales
GROUP BY sale_date
ORDER BY sale_date ASC;
1454 活跃用户
方案一
这道题目也是关于找连续日期的,思路是:
- 首先给表中数据去重(根据题目背景,一个用户可能一天之内登陆多次)
- 按照id分组,按照login_date排序
- 找出表中某条记录之后的第四条数据,计算这两个日期之间的差值,如果等于4,说明,已经是连续5天登陆了
SELECT DISTINCT t1.id,t2.`name`
FROM (
SELECT
id,
login_date,
DATEDIFF(lead(login_date, 4) over(PARTITION BY id ORDER BY login_date), login_date) diff
FROM Logins
GROUP BY id, login_date
)t1
LEFT JOIN Accounts t2 ON t1.id = t2.id
WHERE t1.diff=4;
方案二
-
对表中数据去重,因为一个用户可能在一天之内登陆多次

-
使用窗口函数ROW_NUMBER(),按照id分组,组内按照login_date进行排序
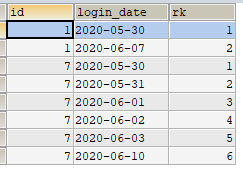
-
计算与login_date相差序号的天数的日期,查出来的是以前的日期,从下图中可以看出来,如果是连续的日期,那么它们的first_login_date字段是一样的(不过真实的首次登陆的日期是first_login_date的后一天,重要的是要用first_login_date这个字段进行分组)
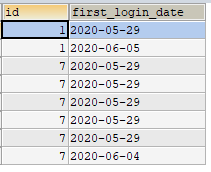
- 把相同的id和first_login_date作为一组,筛选出数量大于5的记录
![]()
5. 与Account表进行连接,得到最终结果
SELECT DISTINCT id,`name`
FROM (
SELECT id,
SUBDATE(login_date,rk) first_login_date
FROM (
SELECT id,login_date,
ROW_NUMBER() OVER(PARTITION BY id ORDER BY login_date) rk
FROM(
SELECT id,login_date
FROM Logins
GROUP BY id,login_date
ORDER BY id,login_date
) t1
)t2
GROUP BY id,first_login_date
HAVING COUNT(*) >= 5
)t3 JOIN Accounts USING(id)
ORDER BY id;
方案三
这个方案也很巧妙
用logins表进行自连接,两个logins表分别记作l1和l2,连接条件是两个logins表的id相同,并且l2中login_date和l1中的login_date的相差的天数在0到4之间
datediff('2022-01-02', '2022-01-02') // 0
datediff('2022-01-03', '2022-01-02') // 1
datediff('2022-01-04', '2022-01-02') // 2
datediff('2022-01-05', '2022-01-02') // 3
datediff('2022-01-06', '2022-01-02') // 4
然后按照id,name,login_date进行分组,l1中的login_date作为起始日期
然后统计与l1某一日期相连的l2中的login_date的数量有没有大于5个
SELECT DISTINCT
a1.id,
a1.name
FROM accounts a1
JOIN logins l1 USING(id)
JOIN logins l2 ON l1.id = l2.id AND DATEDIFF(l2.login_date, l1.login_date) BETWEEN 0 AND 4
GROUP BY a1.id, a1.name, l1.login_date
HAVING COUNT(DISTINCT l2.login_date) >= 5
ORDER BY l1.id,l1.login_date;
1459 矩形面积
SELECT
t1.id p1,
t2.id p2,
ABS(t1.x_value-t2.x_value)*ABS(t1.y_value-t2.y_value) `area`
FROM Points t1
JOIN Points t2
ON t1.x_value != t2.x_value AND t1.y_value != t2.y_value AND t1.id < t2.id
ORDER BY `area` DESC,p1 ASC,p2 ASC;
1484 按日期分组销售产品
SELECT
sell_date,
COUNT(product) num_sold,
GROUP_CONCAT(product ORDER BY product SEPARATOR ',') products
FROM(
SELECT DISTINCT sell_date,product
FROM Activities
ORDER BY sell_date ASC,product ASC
) temp
GROUP BY sell_date
ORDER BY sell_date;
改进一下
SELECT
sell_date,
COUNT(product) num_sold,
GROUP_CONCAT(product ORDER BY product SEPARATOR ',') products
FROM(
SELECT DISTINCT sell_date,product
FROM Activities
) temp
GROUP BY sell_date
ORDER BY sell_date;
再改进一下,最终版本
SELECT
sell_date,
COUNT(DISTINCT product) num_sold,
GROUP_CONCAT(DISTINCT product ORDER BY product SEPARATOR ',') products
FROM Activities
GROUP BY sell_date
ORDER BY sell_date;
1501 可以放心投资的国家

这道题不算难,就是写起来有点复杂
首先要根据Person表中的phone_number字段的前三个数字,在country表中找到相等的country_code,用country_code进行表连接,得到哪一个人(id)是哪个国家的,作为一张临时表,person_country_info,其中包含id,person_name,country,也就是某一个人的id、姓名,所在国家
再用这张表的id分别与Calls表的caller_id和callee_id进行连接,计算每个国家的通话时长,最后将分别于caller_id连接和callee_id连接的结果UNION ALL,计算总数,在于全球的平均值进行比较即可
(看着代码多,其实很好理解)
WITH person_country_info AS (
SELECT t1.id,t1.name person_name,t2.name country_name
FROM (
SELECT id,name,phone_number,LEFT(phone_number,3) country_code
FROM Person
) t1
JOIN country t2
ON t1.country_code = t2.country_code
)
SELECT country_name country
FROM (
SELECT t1.country_name, SUM(t2.duration) total_duration, COUNT(caller_id) cnt
FROM person_country_info t1
JOIN Calls t2 ON t1.id = t2.caller_id
GROUP BY t1.country_name
UNION ALL
SELECT t1.country_name,SUM(t2.duration) total_duration,COUNT(callee_id) cnt
FROM person_country_info t1
JOIN Calls t2 ON t1.id = t2.callee_id
GROUP BY t1.country_name
) country_avg_duration
GROUP BY country_name
HAVING SUM(total_duration)/SUM(cnt) > (
SELECT AVG(duration)
FROM Calls
);
1527 患某种疾病的患者
SELECT patient_id, patient_name,conditions
FROM Patients
WHERE conditions LIKE 'DIAB1%' OR conditions LIKE '% DIAB1%';
1532 最近的三笔订单
WITH rk_orders AS (
SELECT
customer_id,
order_id,
order_date,
ROW_NUMBER() OVER(PARTITION BY customer_id ORDER BY order_date DESC) rk
FROM Orders
)
SELECT t2.name customer_name, t1.customer_id, t1.order_id, t1.order_date
FROM rk_orders t1
JOIN Customers t2 ON t1.customer_id = t2.customer_id
WHERE t1.rk <= 3
ORDER BY customer_name ASC, customer_id ASC, order_date DESC;
1549 每件商品的最新订单
方案一 窗口函数

WITH rk_orders AS (
SELECT
product_id,
order_id,
order_date,
RANK() OVER(PARTITION BY product_id ORDER BY order_date DESC) rk
FROM Orders
)
SELECT
t2.product_name,
t1.product_id,
t1.order_id,
t1.order_date
FROM rk_orders t1
JOIN Products t2 ON t1.product_id = t2.product_id
WHERE t1.rk = 1
ORDER BY t2.product_name ASC, t1.product_id ASC,t1.order_id ASC;
方案二 子查询
SELECT
t2.product_name,
t1.product_id,
t1.order_id,
t1.order_date
FROM Orders t1
JOIN Products t2 ON t1.product_id = t2.product_id
WHERE (t1.product_id,t1.order_date) IN (
SELECT product_id,MAX(order_date)
FROM Orders
GROUP BY product_id
)
ORDER BY t2.product_name ASC, t1.product_id ASC, t1.order_id ASC;
1571 仓库经理
SELECT
t1.name WAREHOUSE_NAME,
SUM(t1.units * t2.Width * t2.Length * t2.Height)VOLUME
FROM Warehouse t1
JOIN Products t2 ON t1.product_id = t2.product_id
GROUP BY t1.name;
1581 进店却为进行交易的顾客
SELECT
t1.customer_id,
COUNT(t1.customer_id) count_no_trans
FROM Visits t1
LEFT JOIN Transactions t2 ON t1.visit_id = t2.visit_id
WHERE t2.amount IS NULL
GROUP BY t1.customer_id;
1587 银行账户概要II
SELECT t2.name,SUM(amount) balance
FROM Transactions t1
JOIN Users t2 ON t1.account = t2.account
GROUP BY t1.account
HAVING SUM(amount) > 10000;
1596 每位顾客最经常订购的商品
WITH most_frequent_product AS(
SELECT
customer_id,
product_id,
RANK() OVER(PARTITION BY customer_id ORDER BY COUNT(*) DESC) rk
FROM Orders
GROUP BY customer_id,product_id
ORDER BY customer_id
)
SELECT
t1.customer_id,
t1.product_id,
t2.product_name
FROM most_frequent_product t1
JOIN Products t2 ON t1.product_id = t2.product_id
WHERE t1.rk = 1
1607 没有卖出的卖家
SELECT seller_name
FROM Seller
WHERE seller_id NOT IN (
SELECT DISTINCT seller_id
FROM Orders t1
WHERE YEAR(sale_date) = '2020'
)
ORDER BY seller_name ASC;
1613 找到遗失的ID
本题的关键是创建一个有头有尾的自然序列,这个题之前没有见过,也算是扩展了思路吧
方式一
WITH t1 AS(
SELECT 1 AS a
UNION ALL SELECT 2
UNION ALL SELECT 3
UNION ALL SELECT 4
UNION ALL SELECT 5
UNION ALL SELECT 6
UNION ALL SELECT 7
UNION ALL SELECT 8
UNION ALL SELECT 9
),
t2 AS (
SELECT 0 AS b
UNION ALL SELECT 1
UNION ALL SELECT 2
UNION ALL SELECT 3
UNION ALL SELECT 4
UNION ALL SELECT 5
UNION ALL SELECT 6
UNION ALL SELECT 7
UNION ALL SELECT 8
UNION ALL SELECT 9
),
t3 AS (
SELECT 10*a+b AS numbers FROM t1,t2
UNION ALL SELECT 100
UNION ALL SELECT a FROM t1
)
SELECT numbers ids
FROM t3
WHERE numbers < (
SELECT MAX(customer_id)
FROM Customers
)AND numbers NOT IN (
SELECT customer_id
FROM Customers
)
ORDER BY numbers ASC;
方式二
递归
WITH RECURSIVE tmp AS (
SELECT 1 AS numbers UNION ALL
SELECT numbers+1 FROM tmp WHERE numbers < 100
)
SELECT numbers ids
FROM tmp
WHERE numbers < (
SELECT MAX(customer_id)
FROM Customers
) AND numbers NOT IN (
SELECT customer_id
FROM Customers
);
1633 各赛事的用户注册率
SELECT contest_id, ROUND(COUNT(user_id)*100 / (SELECT COUNT(*) FROM Users),2) percentage
FROM Register
GROUP BY contest_id
ORDER BY percentage DESC,contest_id ASC;
1667 修复表中的名字
SELECT user_id,
CONCAT(UPPER(SUBSTR(name,1,1)),
LOWER(SUBSTR(name,2,CHAR_LENGTH(name)-1))
)name
FROM Users
ORDER BY user_id ASC;
1693 每天的领导和合伙人
SELECT
date_id,
make_name,
COUNT(DISTINCT lead_id) unique_leads,
COUNT(DISTINCT partner_id) unique_partners
FROM DailySales
GROUP BY date_id,make_name;
1699 两人之间的通话次数
通过IF判断,将from_id > to_id 的记录,调换from_id和to_id的位置,这样再使用GROUP BY就很容易了
WITH temp AS (
SELECT
IF(from_id < to_id, from_id, to_id) from_id,
IF(to_id > from_id, to_id, from_id) to_id,
duration
FROM Calls
)
SELECT
from_id person1,
to_id person2,
COUNT(*) call_count,
SUM(duration) total_duration
FROM temp
GROUP BY from_id,to_id;
1709 访问日期之间最大的空档期
方式一
首先是将今天的日期与原来表中数据进行UNION
再对完整的数据按照id分组,visit_date进行排序,对它们进行标号
t1.user_id = t2.user_id AND t1.rk + 1 = t2.rk 使用这个条件筛选出符合条件的记录,计算两天之间的天数,按照user_id分组,返回最大值
WITH temp1 AS (
SELECT
user_id,
visit_date
FROM UserVisits
UNION
SELECT DISTINCT user_id,'2021-01-01'
FROM UserVisits
),temp AS(
SELECT
user_id,
visit_date,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY visit_date) rk
FROM temp1
)
SELECT t1.user_id, MAX(DATEDIFF(t2.visit_date,t1.visit_date)) biggest_window
FROM temp t1
JOIN temp t2 ON t1.user_id = t2.user_id AND t1.rk + 1 = t2.rk
GROUP BY t1.user_id
ORDER BY t1.user_id
方式二 LEAD(col,offset,default)
对于一张表而言,在其之上的是Lag,在其之下的是Lead
按照时间排序把下一行的时间找到,然后就可以计算window差了
LEAD(col,offset,default)函数的相关参数:
- col:指你要操作的那一列
- offset:偏移几行,如果是1,就是下一行,以此类推
- default:如果下一行不存在,用什么值填充
SELECT
user_id,
MAX(DATEDIFF(next_visit_date,visit_date)) biggest_window
FROM (
SELECT
user_id,
visit_date,
LEAD(visit_date,1,'2021-01-01') OVER(PARTITION BY user_id ORDER BY visit_date)next_visit_date
FROM UserVisits
) temp
GROUP BY user_id
ORDER BY user_id
1729 求关注者的数量
SELECT user_id,COUNT(follower_id) followers_count
FROM Followers
GROUP BY user_id
ORDER BY user_id;
1731 每位经理的下属员工数量
SELECT
t1.reports_to employee_id,
t2.name,
COUNT(*) reports_count,
ROUND(AVG(t1.age)) average_age
FROM Employees t1
JOIN Employees t2
ON t1.reports_to = t2.employee_id
GROUP BY t1.reports_to
ORDER BY t1.reports_to;
1741 查询每个员工花费的总时间
SELECT
event_day `day`,
emp_id,
SUM(out_time - in_time) total_time
FROM Employees
GROUP BY event_day,emp_id;
1747 应该被禁止的Leetflex账户
SELECT DISTINCT t1.account_id
FROM LogInfo t1
JOIN LogInfo t2
ON t1.account_id = t2.account_id
WHERE t1.ip_address != t2.ip_address
AND t1.login <= t2.logout
AND t2.login <= t1.logout;
1757 可回收且低脂的产品
SELECT product_id
FROM Products
WHERE low_fats = 'Y' AND recyclable = 'Y';
1783 大满贯数量
题目不考虑年份,只考虑总计的得奖数,先将不同比赛的得奖记录汇集在一起,作为一张临时表
再按照id分组计数,最后进行表连接
WITH tmp AS (
SELECT Wimbledon AS id FROM Championships
UNION ALL
SELECT Fr_open FROM Championships
UNION ALL
SELECT US_open FROM Championships
UNION ALL
SELECT Au_open FROM Championships
)
SELECT p.player_id,p.player_name,COUNT(*) grand_slams_count
FROM tmp
JOIN Players p ON tmp.id = p.player_id
GROUP BY id;
1795 每个产品在不同商店的价格
SELECT product_id, 'store1' store, store1 price FROM Products WHERE store1 IS NOT NULL
UNION ALL
SELECT product_id, 'store2' store, store2 price FROM Products WHERE store2 IS NOT NULL
UNION ALL
SELECT product_id, 'store3' store, store3 price FROM Products WHERE store3 IS NOT NULL;
1831 每天的最大交易
方式一
SELECT transaction_id
FROM (
SELECT
transaction_id,
DENSE_RANK() OVER(PARTITION BY DATE(`day`) ORDER BY amount DESC) rk
FROM Transactions
) tmp
WHERE rk = 1
ORDER BY transaction_id;
子查询
SELECT transaction_id
FROM Transactions
WHERE (DATE(`day`),amount) IN (
SELECT
DATE(`day`),
MAX(amount)
FROM Transactions
GROUP BY DATE(`day`)
)
ORDER BY transaction_id;
1867 最大数量高于平均水平的订单
先按照group_id进行分组,求出每份订单的平均数量,找出其中最大的平均数量
再对原表按照group_id分组,找出每个组的最大quantity,如果这个最大quantity大于平均数量的最大值,则输出
SELECT order_id
FROM OrdersDetails
GROUP BY order_id
HAVING MAX(quantity) > (
SELECT MAX(avg_quantity) max_avg_quantity
FROM (
SELECT AVG(quantity) avg_quantity
FROM OrdersDetails
GROUP BY order_id
) tmp
);
1873 计算特殊奖金
SELECT
employee_id,
IF(name NOT LIKE 'M%' AND employee_id%2=1,salary,0) bonus
FROM Employees
ORDER BY employee_id;
1890 2020年最后一次登录
SELECT user_id,MAX(time_stamp) last_stamp
FROM Logins
WHERE YEAR(time_stamp) = 2020
GROUP BY user_id;
1949 坚定的友谊
方案一
先使用UNION ALL把所有的关系对找出来,作为一张临时表
WITH f AS (
SELECT user1_id,user2_id FROM Friendship
UNION ALL
SELECT user2_id,user1_id FROM Friendship
)
再将临时表 f 进行自连接,找出f表中第二列的user的好友
WITH f AS (
SELECT user1_id,user2_id FROM Friendship
UNION ALL
SELECT user2_id,user1_id FROM Friendship
),
t AS (
SELECT a.user1_id a1, a.user2_id a2, b.user1_id b1, b.user2_id b2
FROM f a LEFT JOIN f b ON a.user2_id=b.user1_id
)
再将临时表 f 与 t 进行连接,找到f表中第一列user的好友,并且连接起来的条件,还得是在 f 表第二列 user 已有好友的基础上,也就是说,再次连接 f 表,找 f 表第一列user的好友一定是第二列user 的好友的子集
WITH f AS (
SELECT user1_id,user2_id FROM Friendship
UNION ALL
SELECT user2_id,user1_id FROM Friendship
),
t AS (
SELECT a.user1_id a1, a.user2_id a2, b.user1_id b1, b.user2_id b2
FROM f a LEFT JOIN f b ON a.user2_id=b.user1_id
),
dat AS (
SELECT a1,a2,COUNT(c.user2_id) common_friend
FROM t LEFT JOIN f c ON t.a1=c.user1_id AND t.b2=c.user2_id
GROUP BY a1,a2
HAVING COUNT(c.user2_id) >= 3
)
SELECT a1 user1_id, a2 user2_id, common_friend
FROM dat
WHERE a1 < a2;
方案二
也是先将所有的关系作为一张临时表
WITH t AS(
SELECT user2_id user1_id,user1_id user2_id
FROM friendship
UNION ALL
SELECT user1_id user1_id,user2_id user2_id
FROM friendship
)
先看前五行(不加where),以user2_id为不变量,t1.user1_id和t2.user1_id都是user2_id的好友
加上where子句,表示t1.user1_id和t2.user1_id也互为好友
SELECT *
FROM t t1
INNER JOIN t t2
ON t1.user2_id=t2.user2_id AND t1.user1_id!=t2.user1_id AND t1.user1_id<t2.user1_id
WHERE (t1.user1_id,t2.user1_id)IN (
SELECT * FROM t
)
在可视化界面对它们进行排序,有助于理解,上面说,t1和t2自连接条件的含义就是:user2_id为不变量,t1.user1_id和t2.user1_id都是user2_id的好友,反过来,t1.user1_id和user2_id是好友,t2.user1_id和user2_id也是好友,那么user2_id就是t1.user1_id和t2.user1_id共同好友,按照t1.user1_id和t2.user1_id分组,计算user2_id的数量,就可以判断t1.user1_id和t2.user1_id的共同好友有没有超过3个
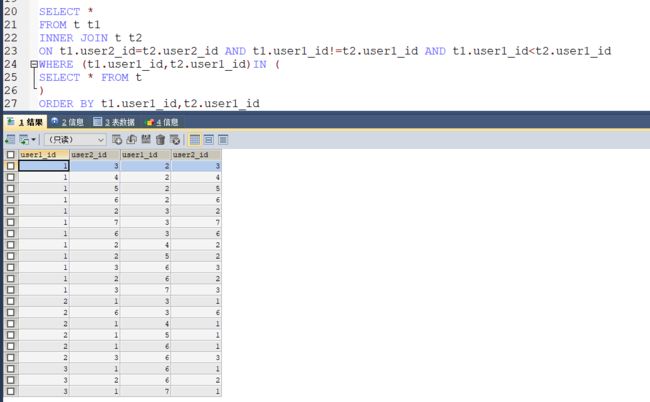
WITH t AS(
SELECT user2_id user1_id,user1_id user2_id
FROM friendship
UNION ALL
SELECT user1_id user1_id,user2_id user2_id
FROM friendship
)
SELECT t1.user1_id, t2.user1_id AS user2_id,COUNT(*)AS common_friend
FROM t t1
INNER JOIN t t2
ON t1.user2_id=t2.user2_id AND t1.user1_id!=t2.user1_id AND t1.user1_id<t2.user1_id
WHERE (t1.user1_id,t2.user1_id)IN (
SELECT * FROM t
)
GROUP BY t1.user1_id,t2.user1_id
HAVING COUNT(*)>=3
1951 查询具有最多共同关注者的所有两两结对组
按照follower_id进行表连接,读懂题目很关键
SELECT user1_id,user2_id
FROM(
SELECT
t1.user_id user1_id,
t2.user_id user2_id,
DENSE_RANK() OVER(ORDER BY COUNT(t1.follower_id) DESC) rk
FROM Relations t1
JOIN Relations t2
ON t1.follower_id = t2.follower_id AND t1.user_id < t2.user_id
GROUP BY t1.user_id,t2.user_id
) tmp
WHERE rk = 1;
1965 丢失信息的雇员
全连接
WITH t AS (
SELECT t1.employee_id, t1.name, t2.salary
FROM Employees t1
LEFT JOIN Salaries t2 ON t1.employee_id = t2.employee_id
UNION ALL
SELECT t1.employee_id,t2.name,t1.salary
FROM Salaries t1
LEFT JOIN Employees t2 ON t1.employee_id = t2.employee_id
)
SELECT employee_id
FROM t
WHERE salary IS NULL OR name IS NULL
ORDER BY employee_id ASC;
1988 找出每个学校的最低分数要求
方案一
SELECT school_id,score
FROM (
SELECT
t1.school_id,
IFNULL(t2.score,-1) score,
ROW_NUMBER() OVER(PARTITION BY t1.school_id ORDER BY t2.student_count DESC,t2.score) rk
FROM Schools t1
LEFT JOIN Exam t2
ON t1.capacity >= t2.student_count
) tmp
WHERE rk = 1;
方案二
SELECT
t1.school_id,
MIN(IFNULL(t2.score,-1)) score
FROM Schools t1
LEFT JOIN Exam t2
ON t1.capacity >= t2.student_count
GROUP BY t1.school_id;