K8s日志收集 - EFK
K8s 对接 EFK-日志收集
前言
对于任何基础设施或后端服务系统,日志都是极其重要的,借助日志可以分析程序的运行状态、用户的操作行为等。最早常说的日志监控系统是ELK,即ElasticSearch(负责数据检索)、Logstash(负责数据收集)、Kibana(负责数据展示)三个软件的组合,随着技术的发展,又出现了很多新的名词,比如EFK,这个F可以指Filebeat,有时也指Fluentd,其实日志收集软件的原理都是大概相同的,区别是它们的编程语言不同,功能不同,所以在选择时要根据自己的实际情况,比如在K8S及docker环境中,就可以使用更轻量级的fluent-bit, 而在云虚拟机和物理机上,则可以使用功能更强大的fluentd,目前我一直在线上使用fluentd系列的软件来收集日志,而且它们在长期的线上环境上运行良好。
这里使用EFK架构收集kubernetes集群的日志:
kubernetes可以实现efk的快速部署和使用,
通过statefulset控制器部署elasticsearch组件,用来存储日志数据,
通过volumenclaimtemplate动态生成pv实现es数据的持久化;
通过deployment部署kibana组件,实现日志的可视化管理;
通过daemonset控制器部署fluentd组件,来收集各节点和k8s集群的日志。


项目思路
1.首先配置启动一个可扩展的 Elasticsearch 集群,
2.然后在Kubernetes集群中创建一个Kibana应用,
3.通过DaemonSet来运行Fluentd,以便它在每个Kubernetes工作节点上都可以运行一个 Pod,此pod挂载本地的docker日志目录到容器内部(k8s集群的日志都在这个目录下),Fluentd将日志收集处理后推送到elasticsearch
4.最后由kibana进行一个完整的展示。
整体流程:
EFK 利用部署在每个节点上的 Fluentd 采集 Kubernetes 节点服务器的 /var/log 和 /var/lib/docker/container 两个目录下的日志,然后传到 Elasticsearch 中。最后,用户通过访问 Kibana 来查询日志
(如果docker没有使用默认的目录/var/lib/docker/container,请根据实际情况更改)。
具体流程:
创建Fluentd并且将 Kubernetes节点服务器的log目录挂载进容器。
Fluentd 采集节点服务器 log 目录下的 containers 里面的日志文件。
Fluentd 将收集的日志转换成 JSON 格式。
Fluentd 利用 Exception Plugin 检测日志是否为容器抛出的异常日志,如果是就将异常栈的多行日志合并。
Fluentd 将换行多行日志 JSON 合并。
Fluentd 使用 Kubernetes Metadata Plugin 检测出 Kubernetes 的 Metadata 数据进行过滤,如 Namespace、Pod Name 等。
Fluentd 使用 ElasticSearch Plugin 将整理完的 JSON 日志输出到 ElasticSearch 中。
ElasticSearch 建立对应索引,持久化日志信息。
Kibana 检索 ElasticSearch 中 Kubernetes 日志相关信息进行展示
组件介绍
- Elasticsearch
Elasticsearch 是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大量日志数据,也可用于搜索许多不同类型的文档。
- Kibana
Elasticsearch 通常与 Kibana 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 允许你通过 web 界面来浏览 Elasticsearch 日志数据。
- Fluentd
Fluentd是一个流行的开源数据收集器,在 Kubernetes 集群所有节点上安装 Fluentd,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
日志系统部署流程
存储篇-nfs动态存储
适用于1.23版本及以上
由于elasticsearch这个组件是计划部署为一个可扩展的集群,因此,使用了volumenclaimtemplate模板动态生成pv,而volumenclaimtemplate必须要有一个可用的StorageClass,因此,部署一个nfs-client-provisioner插件,然后借由此插件实现一个可用的StorageClass
配置nfs-server
nfs服务端配置
#选择一台主机部署nfs server (master01)
yum -y install nfs-utils rpcbind
#启动nfs-server,并加入开机启动
systemctl enable --now rpcbind.service
systemctl enable --now nfs-server
#查看nfs server是否已经正常启动
systemctl status nfs-server
#编辑配置文件,设置共享目录
mkdir -p /data/kubernetes
cat > /etc/exports <<'EOF'
/data/kubernetes *(rw,no_root_squash)
EOF
exportfs -arv
nfs客户端配置
#集群所有节点安装即可
yum -y install nfs-utils
创建ServiceAccount
cat >sa.yaml<<'EOF'
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
EOF
kubectl apply -f sa.yaml
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>以下为上述资源说明>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
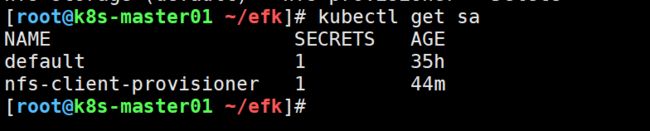
ServiceAccount资源清单是创建了一个服务账号
ClusterRole 集群角色 定义一个集群角色并指定了role规则
ClusterRoleBinding 集群角色绑定,用于把一个角色绑定在一个目标上,可以是User,Group,Service Account,可以为集群范围内授权
RoleBinding 角色绑定,用于把一个角色绑定在一个目标上,可以是User,Group,Service Account,可以为某个命名空间内授权
创建Deployment
cat >deploy-nfs.yaml<<'EOF'
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-client-provisioner
spec:
replicas: 1
selector:
matchLabels:
app: nfs-client-provisioner
strategy:
type: Recreate
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: registry.cn-beijing.aliyuncs.com/mydlq/nfs-subdir-external-provisioner:v4.0.0
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: nfs-provisioner # 和3.Storage中provisioner保持一致便可
- name: NFS_SERVER
value: 10.0.0.180
- name: NFS_PATH
value: /data/kubernetes/logs
volumes:
- name: nfs-client-root
nfs:
server: 10.0.0.180
path: /data/kubernetes/logs
EOF
kubectl apply -f deploy-nfs.yaml
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>以下为上述资源说明>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
- name: PROVISIONER_NAME
value: nfs-provisioner # 和3.Storage中provisioner保持一致便可
- name: NFS_SERVER #这里不修改
value: 10.0.0.201 #nfs服务所在的服务器IP
- name: NFS_PATH #这里不修改
value: /data/kubernetes/logs #nfs服务配置文件里写的路径,也就是/etc/exports文件内定义的路径
volumes:
- name: nfs-client-root #这不修改
nfs:
server: 10.0.0.201 #nfs服务所在的服务器IP
path: /data/kubernetes/logs #nfs服务配置文件里写的路径,也就是/etc/exports文件内定义的路径

创建storageclass
cat >sc.yaml <<'EOF'
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
annotations:
storageclass.kubernetes.io/is-default-class: "true"
name: nfs-storage
provisioner: nfs-provisioner
volumeBindingMode: Immediate
reclaimPolicy: Delete
EOF
kubectl apply -f sc.yaml

创建应用测试动态添加PV
#创建一个nginx应用
cat >nginx-test.yaml<<'EOF'
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "nfs-storage" #使用新建的sc
resources:
requests:
storage: 10Mi
EOF
kubectl apply -f nginx-test.yaml
可以看到nfs-server服务器已经了创建pv持久卷,并且在挂载目录下也有了数据
最后删除测试数据


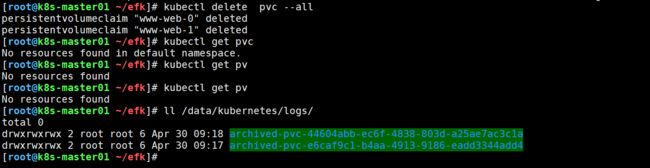
到现在,存储的问题已经解决了,接下来开始重点ELK的 “E”。
ES集群篇
集群service部署清单
cat >es-svc.yaml<<'EOF'
kind: Service
apiVersion: v1
metadata:
name: elasticsearch
namespace: default
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- port: 9200
name: rest
- port: 9300
name: inter-node
EOF
kubectl apply -f es-svc.yaml
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>以下为上述资源说明>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
es-svc.yaml里的headless service:
headless service不具备负载均衡也没有IP,而headless service可以提供一个稳定的域名elasticsearch.kube-logging.svc.cluster.local,而es的部署方式是StateFulSet,是有三个pod的,也就是在默认名称空间定义了一个名为 elasticsearch 的 Service服务,带有app=elasticsearch标签,当我们将 ElasticsearchStatefulSet 与此服务关联时,服务将返回带有标签app=elasticsearch的 Elasticsearch Pods的DNS A记录。最后,我们分别定义端口9200、9300,分别用于与 REST API 交互,以及用于节点间通信(9300是节点之间es集群选举通信用的)
集群deploy部署清单
cat >es-sts-deploy.yaml<<'EOF'
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: es-cluster
namespace: default
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: elasticsearch:7.8.0
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: rest
protocol: TCP
- containerPort: 9300
name: inter-node
protocol: TCP
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
env:
- name: cluster.name
value: k8s-logs
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.seed_hosts
value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch"
- name: cluster.initial_master_nodes
value: "es-cluster-0,es-cluster-1,es-cluster-2"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx512m"
initContainers:
- name: fix-permissions
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
imagePullPolicy: IfNotPresent
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
volumeClaimTemplates:
- metadata:
name: data
labels:
app: elasticsearch
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: managed-nfs-storage
resources:
requests:
storage: 10Gi
EOF
kubectl apply -f es-sts-deploy.yaml
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>以下为上述资源说明>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
在默认名称空间中定义了一个es-cluster的StatefulSet。容器的名字是elasticsearch,镜像是elasticsearch:7.8.0。
使用resources字段来指定容器需要保证至少有0.1个vCPU,并且容器最多可以使用1个vCPU(资源限制)。暴露了9200和9300两个端口,名称要和上面定义的 Service 保持一致,通过volumeMount声明了数据持久化目录,定义了一个data数据卷,通过volumeMount把它挂载到容器里的/usr/share/elasticsearch/data目录。我们将在以后的YAML中为此StatefulSet定义VolumeClaims。
然后,我们使用serviceName 字段与我们之前创建的ElasticSearch服务相关联。这样可以确保可以使用以下DNS地址访问StatefulSet中的每个Pod:,es-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.local,其中[0,1,2]与Pod分配的序号数相对应。我们指定3个replicas(3个Pod副本),将matchLabels selector 设置为app: elasticseach,然后在该.spec.template.metadata中指定pod需要的镜像。该.spec.selector.matchLabels和.spec.template.metadata.labels字段必须匹配。
稍等几分钟后,es集群基本就部署好了,如下图:


Kibana篇
镜像需和es版本一致,都是7.8.0
kibana-service资源清单
service是暴露节点端口的,如果有安装ingress,那么,此service可以设置为headless service不用设置为NodePort
cat >kibana-svc.yaml<<'EOF'
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: default
labels:
app: kibana
spec:
type: NodePort
ports:
- port: 5601
selector:
app: kibana
EOF
kubectl apply -f kibana-svc.yaml
kibana-deploy资源清单
部署pod的文件,其中的value: http://elasticsearch:9200 是指的headless service的9200端口,此环境变量把kibana和elasticsearch集群联系起来了
cat >kibana-deploy.yaml<<'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: default
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:7.8.0
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_URL
value: http://elasticsearch:9200
ports:
- containerPort: 5601
EOF
kubectl apply -f kibana-deploy.yaml
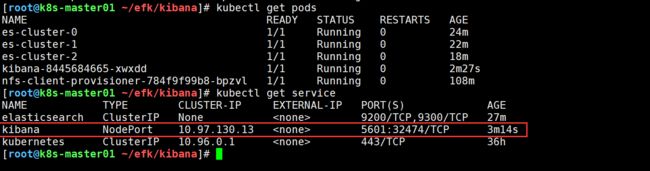
通过查询kibana的NodePort的端口来进行访问,这里访问http://10.0.0.201:32474
结果如上,说明kibana部署完成。
采集器fluentd的部署
ServiceAccount资源清单
cat >fluentd-sa.yaml<<'EOF'
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: default
labels:
app: fluentd
EOF
kubectl apply -f fluentd-sa.yaml
rbac资源清单
cat >fluentd-rbac.yaml<<'EOF'
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
labels:
app: fluentd
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: default
EOF
kubectl apply -f fluentd-rbac.yaml
Deployment资源清单
cat >fluentd-deploy.yaml<<'EOF'
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: default
labels:
app: fluentd
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1
imagePullPolicy: IfNotPresent
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.default.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
resources:
limits:
memory: 512Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
EOF
kubectl apply -f fluentd-deploy.yaml
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>以下为上述资源说明>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
将宿主机Node的/var/log和/var/lib/docker/containers目录挂载到 fluentd容器中,用于读取容器输出到stdout和stderr的日志,以及kubernetes组件的日志。
资源限制根据实际情况进行调整,避免Fluentd占用太多资源。
利用环境变量,设置了elasticsarch服务的访问地址,
此处使用了service名称:elasticsearch.kube-logging.svc.cluster.local
fluent变量的查看需要进入pod里,查看fluent的配置文件
root@fluentd-d58br:/fluentd/etc# cat fluent.conf
# AUTOMATICALLY GENERATED
# DO NOT EDIT THIS FILE DIRECTLY, USE /templates/conf/fluent.conf.erb
@include "#{ENV['FLUENTD_SYSTEMD_CONF'] || 'systemd'}.conf"
@include "#{ENV['FLUENTD_PROMETHEUS_CONF'] || 'prometheus'}.conf"
@include kubernetes.conf
@include conf.d/*.conf
<match **>
@type elasticsearch
@id out_es
@log_level info
include_tag_key true
host "#{ENV['FLUENT_ELASTICSEARCH_HOST']}"
port "#{ENV['FLUENT_ELASTICSEARCH_PORT']}"
path "#{ENV['FLUENT_ELASTICSEARCH_PATH']}"
scheme "#{ENV['FLUENT_ELASTICSEARCH_SCHEME'] || 'http'}"
ssl_verify "#{ENV['FLUENT_ELASTICSEARCH_SSL_VERIFY'] || 'true'}"
ssl_version "#{ENV['FLUENT_ELASTICSEARCH_SSL_VERSION'] || 'TLSv1'}"
reload_connections "#{ENV['FLUENT_ELASTICSEARCH_RELOAD_CONNECTIONS'] || 'false'}"
reconnect_on_error "#{ENV['FLUENT_ELASTICSEARCH_RECONNECT_ON_ERROR'] || 'true'}"
reload_on_failure "#{ENV['FLUENT_ELASTICSEARCH_RELOAD_ON_FAILURE'] || 'true'}"
log_es_400_reason "#{ENV['FLUENT_ELASTICSEARCH_LOG_ES_400_REASON'] || 'false'}"
logstash_prefix "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_PREFIX'] || 'logstash'}"
logstash_format "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_FORMAT'] || 'true'}"
index_name "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_INDEX_NAME'] || 'logstash'}"
type_name "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_TYPE_NAME'] || 'fluentd'}"
<buffer>
flush_thread_count "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_FLUSH_THREAD_COUNT'] || '8'}"
flush_interval "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_FLUSH_INTERVAL'] || '5s'}"
chunk_limit_size "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_CHUNK_LIMIT_SIZE'] || '2M'}"
queue_limit_length "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_QUEUE_LIMIT_LENGTH'] || '32'}"
retry_max_interval "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_RETRY_MAX_INTERVAL'] || '30'}"
retry_forever true
</buffer>
</match>

执行完上述操作后,现在可以看到集群每一个node都运行了一个fluentd,接下来访问kibana页面
Kibana页面查看日志
浏览器访问kibana,点击左上角的三横线图标,在弹出的侧边栏选择Discover
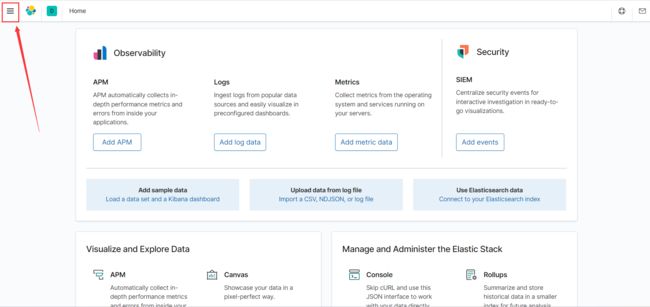
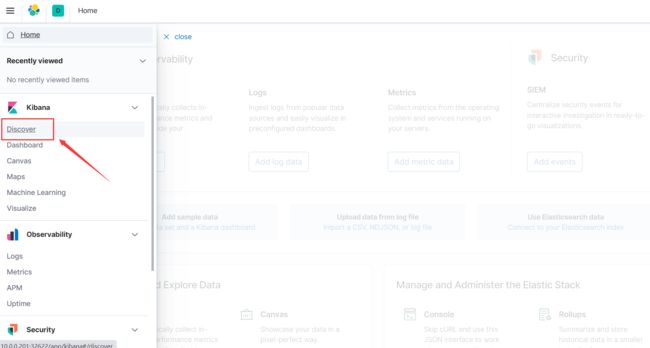
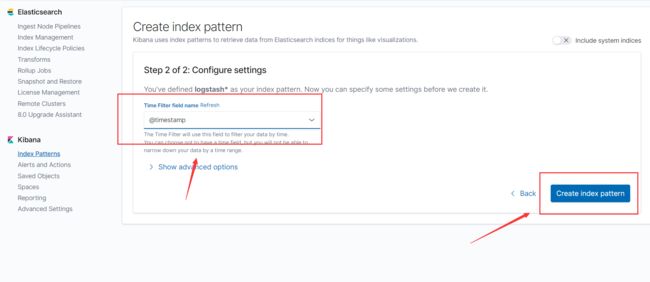
之后可以看到有两个名为logstash+时间日期的日志数据,创建索引名为logstash*,可以将这些数据都匹配,再点击下一步,选择自带的时间戳,下拉框可以选择其他的


最后再点击Discover,进去之后就可以看到日志的数据,可以通过上面的Search对日志进行检索
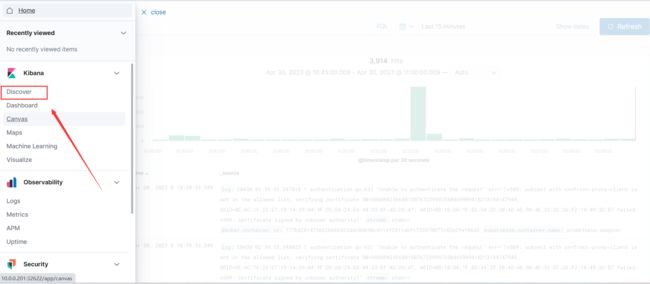

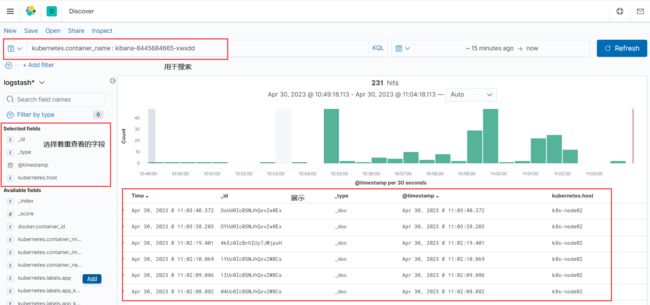
好了,到现在为止,收集kubernetes集群的EFK日志收集系统就已经搭建完成。