Linux系统编程:IO系统总结
stdio标准IO
标准IO都是一些C语言的函数,注意与文件IO的系统调用函数区别开。
fopen
函数描述:

第一个参数填要打开的文件路径,第二个参数填以什么形式打开(读or写or其它)。
在我们学习fopen函数时,查看其返回值可以看到:
![]()
成功时返回FILE类型指针,否则返回errno。
errno
来看errno是什么东西:
errno在被定义的时候,是一个全局变量的概念,就是大家都可以使用就是全局变量的作用嘛,如果某个位置出错了那么出错原因会被放到errno这个全局变量上,换句话说,如果当前进行了某一个操作并且该操作出错了那么我们必须马上打印来进行查看,如果没有马上打印而继续做别的工作去了,那么errno将会被用来存放下一次的错误信息(也就是这一次的错误信息就被覆盖了)。
其位置在:/usr/include/asm-generic/errno目录下:

我们可以打开其中一个error-base.h查看一下:
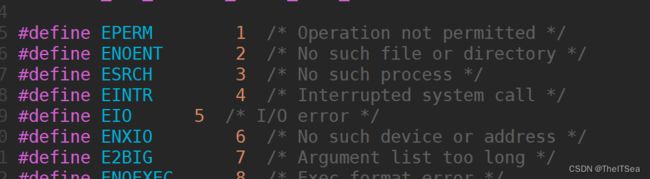
可以看见当errno为2时,表示No such file or directory;
我们可以结合fopen来检验一下:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <errno.h>
4 int main(){
5 //因为fopen函数返回一个FILE*指针,所以我们直接定义一个FILE*
6 FILE* fp;
7 //使用fopen函数来进行文件只读打开,因为我们并没有tmp文件
8 //所以必然报错
9 fp = fopen("tmp","r");
10 //检查报错
11 if(fp == NULL){
12 printf("fopen() error! errno = %d\n",errno);
13 }
14 exit(0);
15 }

对照上面的在usr/include下的文件图片,我们可以知道报错为2意思是没有该文件,这很明显是比较糟糕的体验。
这显然是不友好的,但好在系统还提供了另外两个函数,来强化errno的使用体验:perror和strerror。
perror

可以看到perror是用来打印系统错误消息的,它可以用来打印错误的用法中就包括打印errno,同时其只需要一个参数,就是一个常量字符串,我们来在刚刚的代码中验证:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <errno.h>
4 int main(){
5 //因为fopen函数返回一个FILE*指针,所以我们直接定义一个FILE*
6 FILE* fp;
7 //使用fopen函数来进行文件只读打开,因为我们并没有tmp文件
8 //所以必然报错
9 fp = fopen("tmp","r");
10 //检查报错
11 if(fp == NULL){
12 // printf("fopen() error! errno = %d\n",errno);
13 perror("fopen()");
14 }
15 exit(0);
16 }

可以看见因为error是全局变量,独一份谁报错了都可以使用它来输出报错信息,所以我们只是使用了perror函数传入了我们想要指明的错误位置,该函数就自动替我们打印了errno变量所对应的字符错误描述,非常好用。
strerror

对于strerror函数来说,其只有一个参数,那就是整形的errno值,然后返回一个对应的描述其值所宏定义的错误字符串,来验证一下:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <errno.h>
4 #include <string.h>
5 int main(){
6 //因为fopen函数返回一个FILE*指针,所以我们直接定义一个FILE*
7 FILE* fp;
8 //使用fopen函数来进行文件只读打开,因为我们并没有tmp文件
9 //所以必然报错
10 fp = fopen("tmp","r");
11 //检查报错
12 if(fp == NULL){
13 // printf("fopen() error! errno = %d\n",errno);
14 //perror("fopen()");
15 printf("fopen() error! error = %s\n",strerror(errno));
16 }
17 exit(0);
18 }

可以看见效果依然很好。
fopen的FILE是在哪里申请的空间
有三个选项,栈空间、静态区、堆空间。
首先肯定不是栈,因为如果是在栈上的话,那我们岂不是在返回栈上的局部变量地址吗,这是很危险的事情:
//伪代码
FILE* fopen(const char* path, const char* mode){
FILE tmp = ;
// 初始化
tmp. = ;
...
return &tmp;
}
因为当我们的fopen函数调用完毕之后,tmp指针就已经失效了,所以返回局部变量地址是非常糟糕的事情。
其次肯定也不是在静态区,因为静态区的代码会共享(调用fopen十次但其实调用的都是一个空间),这就意味着可能导致一个文件被打开两次的时候那么第二次就会把第一次的FILE给覆盖,那么第一次打开的文件就会不能用了会出错。
所以答案呼之欲出,是放在堆上的:
//伪代码
FILE* fopen(const char* path, const char* mode){
FILE* tmp = NULL;
// 初始化
tmp = malloc(sizeof(FILE));
tmp-> = ;
...
return tmp;
}
为什么能如此断定其在堆上,因为我们还有一个对应的函数fclose,fopen负责申请空间,那么fclose就负责回收这块空间。
也就得出一个比较一般的结论,如果一个函数存在其对应的逆操作构成一对使用,且该函数返回值是指针类型,那么一般都是从堆上申请的内存空间。
fclose

可以看见其是与fopen配套的,其就一个参数,就是fopen申请的FILE*类型,返回值也很好判断,这里注意有宏用宏,比如其失败返回EOF,即使我们知道EOF其实返回的就是-1但也别用数字而是要用宏,这样才好维护,代码健壮性更好。
这样我们可以改变一下刚刚的示例代码来验证:

测试我们最多可以打开多少个文件
这里我们对一个文件进行循环打开,来看最多可以多少:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <errno.h>
4 #include <string.h>
5 int main(){
6 //因为fopen函数返回一个FILE*指针,所以我们直接定义一个FILE*
7 FILE* fp;
8 int cnt = 0;
9 while(1){
10 fp = fopen("tmp","r");
11 if(fp == NULL){
12 perror("fopen()");
13 break;
14 }
15 cnt++;
16 }
17 printf("cnt = %d\n",cnt);
18 exit(0);
19 }

可以看见上面显示的是1021,但其实应该是1024,这是因为在系统启动时自动就有三个文件流:stdin、stdout、stderr。
是谁限制了这个值,是系统,使用uilimit -a可以查看:
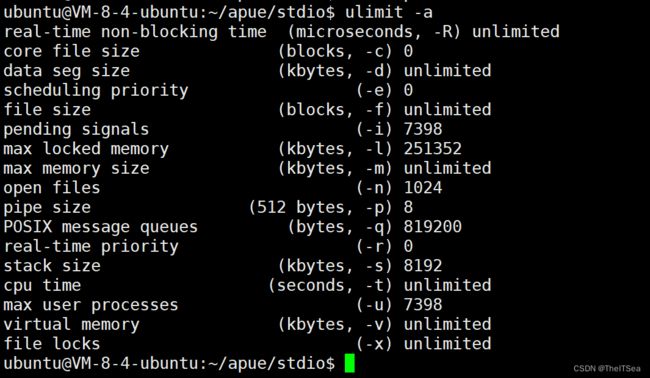
可以看到open files的1024个,1024前面有个-n,这意味着我们可以使用ulimit -n 跟一个数字来修改该值,其余同理。
fgetc、getc、getchar

其实这几个都差不多,从man手册上也是有所体现:

注意一下fgetc和getc俩函数其实几乎一模一样,那为什么还要存在两个?
这是因为getc其实是被定义为宏来使用的,fgetc是被当作函数调用来使用的。
fputc、putc和putchar同理。
作业
1、使用上述函数实现一个copy文件的功能
这是使用getc、putc的方式
#include 2、使用上述函数实现一个计数文件字节数的功能
#include fgets和fputs

fgets的出现是为了解决gets函数本身不安全的问题,这里具体可以看书。
其参数从左到右意思是,s是输入的内容其是一个字符串的地址,能接收size个字节,数据是从一个FILE*文件流来的。
补充一个\0和\n的区别:

fgets正常结束有两种情况:
1、读到size-1个字节(字符数组最后一位需要用’\0’表示结束)
2、读到了’\n’
举个例子:
#define SIZE 5
char buf[SIZE];
fgets(buf,SIZE,stream);现在我们用上述语句来读取该行文本:abcdef
那么读取结果为:a b c d \0 (因为c语言需要占用最后一个数组元素存储’\0’表示字符串的结束)
此时文件指针指向e,这是下一次要读取的内容
再举个例子,加入现在读取的文本为:ab
那么fgets函数也会因为读到\n而正常结束,因为即使是最后一行的内容也会最末尾有一个换行符
哪怕一个文本一个字儿也没有,它也依然有一个换行符,所以ab后面没有字符了那么显然跟的就是一个换行符\n,\n之后字符已经读取结束但依然未超过buf大小,所以读取结束存入\0表示字符数组读取结束,最后一位是随意什么都行的,因为反正\0就表示结束了嘛。
所以读取ab的结果为:a b \n \0 \0
一个小坑:
假设现在要读的是:abcd
我们使用上述的函数要读几次才能读完?
答案是两次:
第一次读取:a b c d ‘\0’
第二次读取:‘\n’ ‘\0’ …
原因很简单,因为abcd此时已经到达了buf的大小5-1了,因为最后一位要填\0表示结束,但是此时还有个换行符没有存,所以换行符还要再单独填一次(换行符必须得读到嗷)。
fputs同理,差球不多,看看man手册或者apue那本书即可。
作业:将之前的作业用fgets和fputs进行改写
#include fread和fwrite
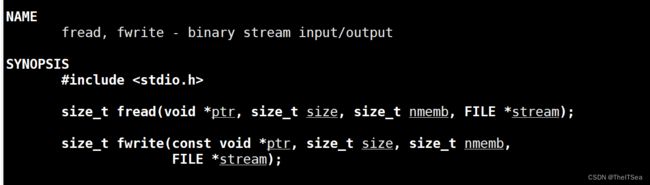
对于fread,其参数从左到右:ptr表示一块内存空间,从stream文件流中读取的数据会被存储到这里面,size表示读取的元素位长或者说元素大小,nmemb表示总共有多少个该size大小的内容,比如我要读学生数据,那么nmemb就表示有多少个学生,而size就表示每个学生的结构体有多大。
fwrite则是从ptr(使用const是告知用户我们只读这片空间内容而并不会改写)这块空间里读取数据写入到文件流stream中,其它参数相同。
其返回值为:

可以看见这俩返回的都是已经读到的或者已经写入的对象数或者说字节数。
这会导致一个问题:

上图中在数据量足够的情况下,二者情况是一样的都是正常的,但是在数据量不足一次size*nmemb的大小之后下面那个就会出现问题返回0。
作业:将之前的作业改成用fread和fwrite来完成
#include printf一族函数:fprintf、sprintf、snprintf
fprintf

可以看到 fprintf 是printf一族的函数,为什么会使用到它,因为我们可以通过该函数将输出信息定向到我们想要的已经打开的文件流中。
其函数参数含义是:将…这些输出项按照format指定格式存放到文件stream中。
补充一点:
stdin标准输入,默认数据来源自键盘;
stdout标注输出,默认数据输出到显示器上;
stderr标准错误,默认数据输出到显示器上。
sprintf
函数参数含义是:将…这些输出项按照format格式存放到一个字符串中。
其作用正好与atoi函数相反,因为atoi是将字符串转换成数字,而sprintf正好可以将数字转换为字符串。
然而该函数有着和gets一样的问题,sprintf也不检查缓冲区的溢出,所以为了解决这样的问题,有了snprintf。
snprintf
参数就不用说了吧,size指定了一下缓冲区大小而已。
scanf一组函数:fscanf、sscanf
fscanf
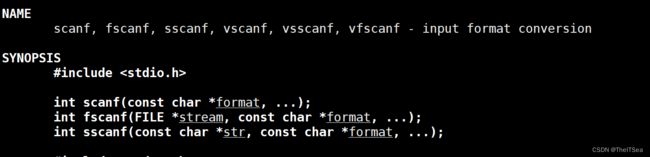
fscanf就是和fprintf一样的,从一个已经打开的文件流中按照format的格式解析进…中的地址格式中去。
sscanf
将字符串str按照format的格式解析进…中的地址格式中去。
操作文件位置指针函数:fseek、ftell、rewind
fseek
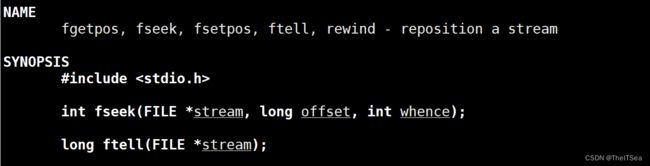
该函数用来定位,之前使用fopen函数时说过不同的打开方式其文件指针的位置是不一样的,有的在文件首部有的在文件尾部。
什么是文件指针?
概括是说文件指针就是我们在读写文件的时候的一个游标,我们总是用眼睛来逐个逐个往后扫的嘛,它用来指示一个位置,它所在的位置就是当前位置,我们文件的读写一定是发生在当前位置的。
举个例子:
fp = fopen(); //打开一个文件流
fputc(fp) * 10; //往里面写十个字符
fgetc() * 10; //从里面读我刚刚写入的十个字符
上面这是绝对行不通的,原因是两次函数使用的是同一个文件流fp,在第一次调用写函数时就文件指针就已经偏移到了第十一位的位置了,此时再进行读取的话只能从第十一位开始读起,这显然不是我们想要的。
为了重新定位文件指针,一种可行的操作是:fp = fopen(); //打开一个文件流
fputc(fp) * 10; //往里面写十个字符
fclose(fp);
fopen(fp);
fgetc() * 10; //从里面读我刚刚写入的十个字符也就是关闭重新打开,将指针重新定位一下即可,但这显然是麻烦的而且限制性是比较强的(如果这段写入的内容是在文件中间部分我们无法定位到该位置)。
而操作文件位置指针的函数就是用来修改这个用的。
fseek的函数参数含义是:stream是指定要操作的文件流,offset指的是偏移量(也就是要偏移多大),whence指的是偏移的相对位置。
对于第三个参数来说,有三种选项:
SEEK_SET:文件首位置
SEEK_CUR:文件指针的当前位置
SEEK_END:文件尾位置
所以对于我们刚刚的例子来说,我们就可以使用fseek来解决:
fseek(fp,-10,SEEK_CUR);
从文件指针的当前位置往前移动十位开始读取(逆向往前走是用负数表示,若是继续往后走则是正数表示)。
feek还有一个非常经典的作用,就是用来制造空洞文件,所谓空洞文件的意思是其文件全部或者一部分充斥着字符0(空字符,该字符是ASC码为0的特殊数值,也就是空字符);空洞文件的典型应用场景就是在文件下载时比如有两个G,那么下载在电脑上时它会直接开辟一个两个G大小的空洞文件空间然后等下完就行了,而这两个G的空间内存的就全是字符0,这就是fseek所创建出来的空洞文件。
ftell
该函数返回文件指针当前所处位置(距离文件首位置多少字节处)。
作业:使用ftell和fseek来统计文件的字节数
#include rewind
这个在man手册中有如下描述:

也就是与offset偏移量为0且是定位在文件首位置时是等价的(注意如果传参的时候对端需要的是long类型的话我们最好是将其常量话也就是加个L,因为比较严格的编译器是会校验这一点的)。
其含义是不管现在文件指针在哪里,我们只要执行了rewind,那么我们当前的文件指针位置一定就seek到了文件首位置开始处。
补充:fseeko和ftello
其实这俩和上面那俩主要的区别就是偏移量的类型不同,上面偏移量为long类型,但long类型我们知道有正有负,但这显然并不是我们希望在描述文件指针位置时想看到的,文件位置不可能为负数不是吗?
所以针对上面这种情况,我们又新创建了这俩函数,这俩函数使用了更加严格的类型定义,但是并不是ISO C标准,属于方言:


fflush

对于该函数的作用,我们可以先来写个小例子来说明:
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 int main(){
5
6 int i ;
7 printf("before while()");
8 while(1);
9 printf("after while()");
10 exit(0);
11 }
这个按照我们的理解,其应该会打印第一句话before while()而不会打印下一句话,因为死循环停住了对吗?
但结果是:

可以看到我们连第一句话都没打印出来,为什么?
因为当前printf一族的函数往标准终端输出的时候,标准终端输出的是典型的行缓冲模式,它是碰到换行的时候才来刷新缓冲区,或者是一行满了的时候才刷新缓冲区。
所以写printf的时候,如果没有特殊格式要求最好加上\n,不然不会被刷新。
我们修改一下再来检测:
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 int main(){
5
6 int i ;
7 printf("before while()\n");
8 while(1);
9 printf("after while()\n");
10 exit(0);
11 }

可以看见按照我们正常流程走了。
那么fflsuh的作用是什么呢?其实就是强制刷新缓冲区的内容到指定stream文件流中(比如标准输出流)。
那么我们可以再次修改代码,不加换行符也要让其强制刷新到标准输出中,注意man手册中提到,如果我们传入的参数为NULL,那么就是默认强制刷新所有已经打开的文件流缓冲区的内容:
1 #include <stdio.h>
2 #include <stdlib.h>
3
4 int main(){
5
6 int i ;
7 printf("before while()");
8 fflush(NULL);
9 while(1);
10 printf("after while()\n");
11 exit(0);
12 }
![]()
可以看见依然是正常打印的before while().
缓冲区到底是什么以及缓冲区的作用
对于缓冲区到底是什么可以参考这篇博文:缓冲区到底是什么
其存在大多数时候是好事,合并了系统调用,其被分成以下几种:
行缓冲:换行时候刷新,满了的时候刷新,强制刷新(典型的标准输出就是这样的,因为是终端设备)。
全缓冲:满了的时候刷新,强制刷新(全缓冲其实是默认的,只要不是终端设备就默认是全缓冲的)。
无缓冲:没有刷新条件,就是立即刷新输出内容( 比如stderr,只要出错了就立即输出)。
使用setvbuf函数可以修改缓冲区,这个了解即可(绝大多数情况下我们并不需要修改这些默认的东西,容易出问题)。
getline

之前的函数都无法便捷直接地读取一行,而getline可以做到。
其函数参数含义是:ptr是一个一级char类型指针变量的地址,该函数会将包含了已经读到文本数据的缓冲区存到该地址空间中,size_t*类型的n的意思指的是该函数给该次获读取行字节数预先分配的大小,一开始是120个字节,当读取一行的字节数大于120个字节时其就会动态扩容至240,要还大于这个值就会一直扩下去(传递的是指针很好理解,因为它是动态扩容的嘛),stream则是需要被读取的文件流。
该函数会返回每一一次读取一行的字节数。

getline底层其实是先malloc然后再不停的realloc来实现扩容的(不然怎么装得下未知的一行字符数目)。
作业:通过getline来实现记录一个文件的每行字符个数
#include 临时文件
临时文件概念好理解,主要是要注意临时文件应该有两个问题要注意:
1、文件名如何不起冲突
2、怎么及时销毁临时文件
这就要涉及到两个函数:tmpnam 和 tmpfile。
tmpnam

tmpnam返回一个可用的文件名,但是有一定缺陷(并发环境下这个函数产生的名字可能会产生冲突)。所以我们有更好的系统调用tmpfile来使用。
tmpfile

该函数返回一个匿名文件,即在磁盘上的确上开辟了空间来存储该文件,我们也可以通过其返回的FILE来进行操作该空间,但是我们无法看到它,它在文件系统中无法被看到,即然文件名都没有那么就自然不会产生冲突问题。
另外当没有计数器再指向该文件时,也就是说当我们拿着的这个FILE被回收之后,该空间自然就被释放了,及时销毁的问题自然也就解决了,这是一个可控的内存泄露。
sysio系统调用IO(即文件IO)
之前说标准IO时提到,FILE*类型贯穿始终。
那么在系统调用IO中其实也是这样,只不过是另外一个东西,文件描述符(file description),文件描述符在系统调用IO中贯穿始终。
本章梗概如下:
文件描述符
首先来分析一下之前的标准IO与FILE*之间的联系,我们的标准IO比如fopen其实底层调用的就是系统调用IO函数open,然后系统提供了一个FILE结构体,标准IO通过该结构体来对一个文件进行各种操作。
同样的对于系统级别的系统IO,它操作的可以说是真正的文件,真实的物理磁盘上的文件,每一个文件都有自己的唯一标识叫inode,当我们使用open系统调用来打开文件的时候,系统依然会有一个结构体(类比于FILE结构体)提供一个指向该结构体的指针给该函数进行对应文件的操作,但是遗憾的是系统并不允许这样,这样是不安全的,Linux会将其这个指针和结构体隐藏起来,存放在了一个数组中,我们用户想要操作该文件的时候就得通过这个整形指针数组的下标来进行对该文件的操作。
即文件描述符本身其实就是个整形数,因为它代表的是个数组下标:

所以理当想到,因为我们的fopen底层调用的open,那么FILE结构体中就肯定会有一个属性是指向文件描述符的。
这个可以在FILE的定义中看到。
所以同理,fclose底层调用close,就得关闭释放掉两块空间嗷。
另外还记得之前说的文件描述符最大可以是多少吗,1024,其实这个1024就是指的这个整形指针数组的大小。
文件描述符优先使用当前可用范围内最小的一个。
文件描述符数组存放在一个进程的进程空间里的,每一个进程都会有一个这样的数组(这里其实就是在强调后面fork进程的知识了,意思就是父子进程的文件描述符数组是相同的但是却有两份,父子进程一人一份但是两份之间互不影响毫无关联)。
如果此时我们在一个进程中连续打开同一个文件,那么第二次打开该文件也会占用一个文件描述符,这俩文件描述符指向同一个文件:

即打开多少次就会产生多少个结构体,并且产生同样数量的文件描述符。
还有一种情况,就是多个文件描述符指向了同一个文件对象的结构体(这很容易做到,就是复制嘛),那么其中一个文件描述符被关闭被free掉了那么该结构体还存在吗?显然是存在的,所以每个文件被打开之后都会有一个打开计数器,只有当计数器为0时该结构体才会被关闭释放掉。
文件IO系统调用
open
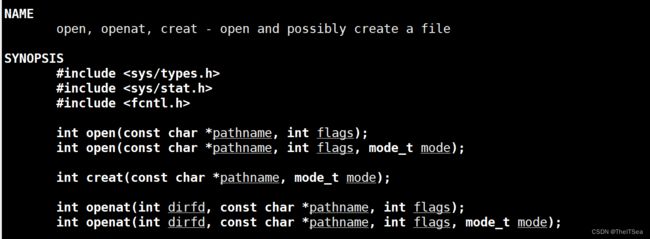
参数比较简单,第一个是文件路径,第二个是flags,具体flags是什么,可以看描述:

也就是这个flags必须包含O_RDONL、O_WRONLY、O_RDWR三者之一,指的是一种读写权限。
除此之外还可以通过 | 运算符来增加一些可选项,具体的可选项也可以看man手册,这里不再罗列。
这也就是说之前我们使用fopen时指定的r呀w呀r+呀之类的,在open这里就成为了:

这具有明显的对应关系。
在man手册中我们可以看到open函数有一个三参数实现和一个两参数实现,这是一种重载形式(但c语言是没有这种机制的,所以实际上是使用变参来实现的),当我们使用open中flags包含create时要用三参数的open,不带create时使用两参数的open实现。
对于三参数的open,第三个参数给的是设置权限,其一样遵循与umask进行取反按位与的机制。
close

read
这里使用man显示不出的时候,使用man 2 read,在man分区2中进行查看即可,因为read是系统调用,所以在分区2中可以找到:
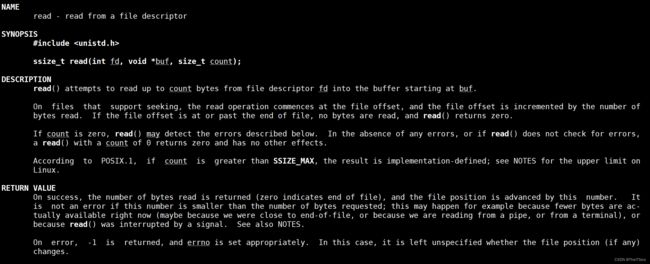
参数含义为:fd表示一个文件描述符,即从该fd中读取数据,放进buf中,读取count个字节进去。
成功的话返回成功读到的字节数,返回0表示读到了文件尾,失败则返回-1;
write

参数含义为:往文件对象fd中写进buf中存放的count个字节的数据。
成功返回写入的字节数,返回值为0表示什么也没写进去,错误返回-1;
lseek
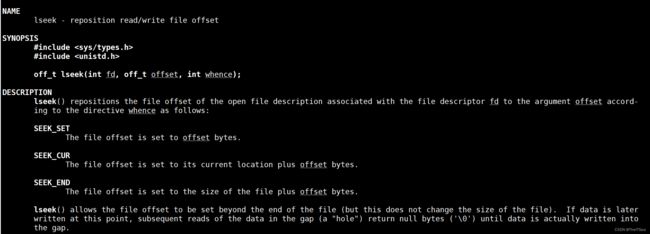
这个函数是不是和我们之前学的fseek很像?它们俩作用是一样的嗷。
参数含义为:对文件对象fd的文件指针位置进行定位,偏移量为offset,相对偏移位置是whence(从哪儿开始偏移)。
比如SEEK_SET文件首位置,SEEK_CUR文件指针当前位置,SEEK_END文件尾位置。
成功则返回从文件开始处到当前文件指针位置所经历的字节个数,相当于综合了fseek和ftell的组合。
作业:使用上述系统IO来完成改写之前的copy作业
#include 文件IO与标准IO区别
1、文件IO响应速度快于标准IO,因为标准IO有缓冲区机制,而文件IO没有
2、标准IO的吞吐量大于文件IO,也是因为有缓冲区机制,标准IO读写一次的数据要多过文件IO
另外:标准IO与文件IO不可以混用。
提到这个我们需要再补充两个函数,这两个函数用来转换文件IO与标准IO:
补充:fileno

作用:本身有个FILE*,我们想把标准IO转换成文件IO操作,其返回值就是其对应的文件描述符。
补充:fdopen

作用:假设现在打开一个文件是用系统调用打开的,那么我们会得到一个文件描述符fd,那么我们再指定一下对该文件的操作方式mode,该函数就会封装一个FILE*返回给我们。
继续刚刚的问题:为什么不能混用标准IO和文件IO
来看这样一个例子:
File* fp;
fputc(fp) //往文件流fp中写入一个字符,此时文件指针pos++
fputc(fp) //往文件流fp中写入一个字符,此时文件指针pos++
经过上面两次put操作,此时pos已经加了两次了,但我们知道,标准IO是自带缓冲区的,也就是说上述两次pos的变化并没有刷新到内核中去,也就是说真正的文件描述符所指向的文件对象(那个结构体)的pos是没有发生改变的,此时如果又要用文件IO来操作真正的物理内存上的文件对象显然数据就不会一致,肯定出错,所以最好不要混用。
我们可以来验证一下混用出错的例子:
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <unistd.h>
4
5 int main(){
6
7
8 //标准IO函数putchar往标准输出中打印a
9 putchar('a');
10 //文件IO函数write往标准输出(文件描述符为1)中打印b
11 write(1,"b",1);
12
13 //标准IO函数putchar往标准输出中打印a
14 putchar('a');
15 //文件IO函数write往标准输出(文件描述符为1)中打印b
16 write(1,"b",1);
17
18 //标准IO函数putchar往标准输出中打印a
19 putchar('a');
20 //文件IO函数write往标准输出(文件描述符为1)中打印b
21 write(1,"b",1);
22
23 exit(0);
24 }
编译运行:

可以看见输出的是bbbaaa。
因为bbb是内核文件IO输出的,因为文件IO没有缓冲区直接写入数据,所以write的数据最先写入,而putchar函数即使在write之前先执行,但因为标准IO具有缓冲区,它会直到exit退出函数时才会被刷新到物理内存中的真正文件内,在这个例子中所谓真正文件指的就是标准输出中。
我们可以使用命令strace ./ab(ab是上面可执行程序的名子)来查看其具体的执行打印的情况:
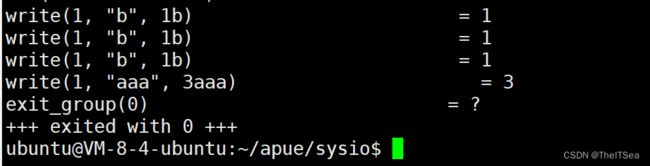
上面可以看到该程序先执行了三次write往标准输出(终端显示器)上写入了三个b,然后是再一次write不过写入的方式不同,是一次性写入了三个a,这是因为所有标准IO函数的写入操作最后都是调用底层调用write来完成数据的真正写入的(从缓冲区写入内核),所以上面的putchar都没有显示,取而代之显示的是write函数。
文件共享
多个任务共同操作一个文件或者协同完成任务,比如下面的作业题目既可以用单文件描述符来完成,也可以使用双文件描述符来完成对一个文件的操作,更高级的可以使用多线程和多进程来完成该任务。
完成该作业之前补充的一个系统调用函数:truncate
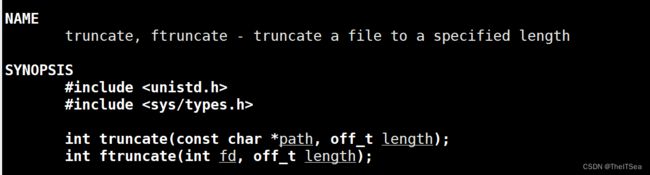
该函数用来对文件大小进行裁剪,其中truncate函数用来将一个未打开的文件path截断到length长度。
ftruncate用来将一个已打开的文件fd截断到length长度。
作业:如何编写程序删除一个文件中的第几行内容
草,目前不会。
原子操作
原子表示不可分割的最小单位。
原子操作就表示不可分割的操作。
其作用是解决并发环境下冲突和竞争的问题。
如之前提到的tmpnam就可能存在并发问题,这个在后面还将总是遇到。
dup和dup2
作业:在一个程序本来就一定会往标准输出输出"hello"的情况下,改写它输出"hello"到指定文件中
#include dup
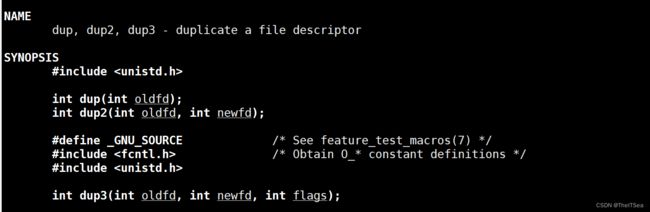
dup意思就是复制的意思,该函数需要的参数是一个文件描述符fd,它将复制该文件描述符到一个当前可用范围内最小的文件描述符位置上去。
dup2
![]()
dup2的作用和dup是一样的,不过它会提供一个原子操作:即复制oldfd到一个新的newfd中,并且关闭oldfd文件描述符,这两个操作是原子关系。
另外如果oldfd和newfd是同一个值的话,那么dup2将什么也不会做,直接返回一个newfd,这就意味着我们就得手动关闭oldfd了,这是个大坑,千万要注意嗷。
同步
这一块内容因为目前并没有涉及到设备或者是大文件的刷新,所以这几个函数了解一下是干嘛用的即可。
sync

该函数的作用是同步buffer和cache的数据,注意是同步内核层面的buffer和cache。
比如我们关机的时候要解除设备挂载了,此时可能还有些数据在buffer或者cache中,我们需要将这些数据刷新到内核的物理内存中,此时就需要使用sync来进行数据的同步。
fsync
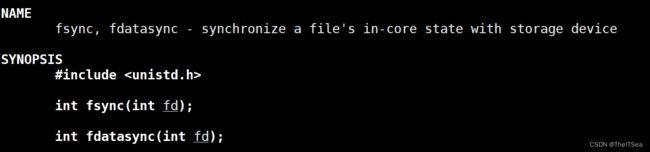
该函数的作用和sync差不多,只不过指向性更强,其会同步一个指定文件的buffer或者cache的数据到实际的物理内存中。
fdatasync
该函数也差不多其实,但是它只同步数据而不同步亚数据,一个文件当中的有效内容我们叫数据,而亚数据是指比如文件最后的修改时间、文件的属性等这种不影响文件内容的数据。
fcntl
有句话是:文件描述符所变的魔术几乎都来源于该函数。
因为该函数的作用是用来管理文件描述符的:

cmd表示要对该文件描述符fd做什么样的事情,而…arg表示的是我们要做的cmd事情是否需要什么参数。
由于命令不同会造成所传的参数不同,其返回值也不同。
ioctl
如果说fcntl是文件管家,那么ioctl就是设备的管家,设备相关的内容都归它来操作。

补充:/dev/fd/目录
这是一个虚目录,显示的是当前进程的文件描述符信息。
