FlinkCEP - Flink的复杂事件处理
文章目录
- 本节引导
- 使用场景
- 依赖
- 第一个CEP不完整程序
- 模式(pattern) API
-
- 单个模式
-
- 量词
- 条件
- 组合模式
-
- 循环模式中的连续性
-
- 模式操作 consecutive()
- 模式组
- 匹配后跳过策略
- 检测模式
-
- 从模式中选取
-
- 处理超时的部分匹配
- 便捷的API(旧api迁移到新api)
- CEP库中的时间
-
- 按照事件时间处理迟到事件
- 时间上下文
- 可选的参数设置
- 例子
FlinkCEP是在Flink上层实现的复杂事件处理库。 它可以让你在无限事件流中检测出特定的事件模型,有机会掌握数据中重要的那部分。
本节引导
- 首先讲述模式API,它可以让你指定想在数据流中检测的模式
- 然后讲述如何检测匹配的事件序列并进行处理
- 再然后我们讲述Flink在按照事件时间处理迟到事件时的假设
- 以及如何从旧版本的Flink向1.3之后的版本迁移作业
使用场景
- 实时营销
- 监测用户弹幕行为案例
- 实时反作弊和风控
- 实时网络攻击检测
依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-cepartifactId>
<version>1.15.0version>
dependency>
如果需要其它依赖,请参照案例地址
第一个CEP不完整程序
如果想要了解具体cep程序,请关注下面文章,本篇文章只是把作者学习官网的,做个记录
DataStream中的事件,如果你想在上面进行模式匹配的话,必须实现合适的 equals()和hashCode()方法, 因为FlinkCEP使用它们来比较和匹配事件。
DataStream<Event> input = ...;
Pattern<Event, ?> pattern = Pattern.<Event>begin("start").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
return event.getId() == 42;
}
}
).next("middle").subtype(SubEvent.class).where(
new SimpleCondition<SubEvent>() {
@Override
public boolean filter(SubEvent subEvent) {
return subEvent.getVolume() >= 10.0;
}
}
).followedBy("end").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
return event.getName().equals("end");
}
}
);
PatternStream<Event> patternStream = CEP.pattern(input, pattern);
DataStream<Alert> result = patternStream.process(
new PatternProcessFunction<Event, Alert>() {
@Override
public void processMatch(
Map<String, List<Event>> pattern,
Context ctx,
Collector<Alert> out) throws Exception {
out.collect(createAlertFrom(pattern));
}
});
模式(pattern) API
模式API可以让你定义想从输入流中抽取的复杂模式序列。
每个复杂的模式序列包括多个简单的模式,比如,寻找拥有相同属性事件序列的模式。从现在开始,我们把这些简单的模式称作模式, 把我们在数据流中最终寻找的复杂模式序列称作模式序列,你可以把模式序列看作是这样的模式构成的图, 这些模式基于用户指定的条件从一个转换到另外一个,比如 event.getName().equals(“end”)。 一个匹配是输入事件的一个序列,这些事件通过一系列有效的模式转换,能够访问到复杂模式图中的所有模式。
每个模式必须有一个独一无二的名字,你可以在后面使用它来识别匹配到的事件。
模式的名字不能包含字符":".
- 单个模式
- 复杂模式
单个模式
一个模式可以是一个单例或者循环模式。单例模式只接受一个事件,循环模式可以接受多个事件。 在模式匹配表达式中,模式"a b+ c? d"(或者"a",后面跟着一个或者多个"b",再往后可选择的跟着一个"c",最后跟着一个"d"), a,c?,和 d都是单例模式,b+是一个循环模式。默认情况下,模式都是单例的,你可以通过使用量词把它们转换成循环模式。 每个模式可以有一个或者多个条件来决定它接受哪些事件。
量词
在FlinkCEP中,你可以通过这些方法指定循环模式:pattern.oneOrMore(),指定期望一个给定事件出现一次或者多次的模式(例如前面提到的b+模式); pattern.times(#ofTimes),指定期望一个给定事件出现特定次数的模式,例如出现4次a; pattern.times(#fromTimes, #toTimes),指定期望一个给定事件出现次数在一个最小值和最大值中间的模式,比如出现2-4次a。
你可以使用pattern.greedy()方法让循环模式变成贪心的,但现在还不能让模式组贪心。 你可以使用pattern.optional()方法让所有的模式变成可选的,不管是否是循环模式。
对一个命名为start的模式,以下量词是有效的:
// 期望出现4次
start.times(4);
// 期望出现0或者4次
start.times(4).optional();
// 期望出现2、3或者4次
start.times(2, 4);
// 期望出现2、3或者4次,并且尽可能的重复次数多
start.times(2, 4).greedy();
// 期望出现0、2、3或者4次
start.times(2, 4).optional();
// 期望出现0、2、3或者4次,并且尽可能的重复次数多
start.times(2, 4).optional().greedy();
// 期望出现1到多次
start.oneOrMore();
// 期望出现1到多次,并且尽可能的重复次数多
start.oneOrMore().greedy();
// 期望出现0到多次
start.oneOrMore().optional();
// 期望出现0到多次,并且尽可能的重复次数多
start.oneOrMore().optional().greedy();
// 期望出现2到多次
start.timesOrMore(2);
// 期望出现2到多次,并且尽可能的重复次数多
start.timesOrMore(2).greedy();
// 期望出现0、2或多次
start.timesOrMore(2).optional();
// 期望出现0、2或多次,并且尽可能的重复次数多
start.timesOrMore(2).optional().greedy();
条件
对每个模式你可以指定一个条件来决定一个进来的事件是否被接受进入这个模式,例如,它的value字段应该大于5,或者大于前面接受的事件的平均值。 指定判断事件属性的条件可以通过pattern.where()、pattern.or()或者pattern.until()方法。 这些可以是IterativeCondition或者SimpleCondition。
迭代条件: 这是最普遍的条件类型。使用它可以指定一个基于前面已经被接受的事件的属性或者它们的一个子集的统计数据来决定是否接受时间序列的条件。
下面是一个迭代条件的代码,它接受"middle"模式下一个事件的名称开头是"foo", 并且前面已经匹配到的事件加上这个事件的价格小于5.0。 迭代条件非常强大,尤其是跟循环模式结合使用时。
middle.oneOrMore()
.subtype(SubEvent.class)
.where(new IterativeCondition<SubEvent>() {
@Override
public boolean filter(SubEvent value, Context<SubEvent> ctx) throws Exception {
if (!value.getName().startsWith("foo")) {
return false;
}
double sum = value.getPrice();
for (Event event : ctx.getEventsForPattern("middle")) {
sum += event.getPrice();
}
return Double.compare(sum, 5.0) < 0;
}
});
调用ctx.getEventsForPattern(…)可以获得所有前面已经接受作为可能匹配的事件。 调用这个操作的代价可能很小也可能很大,所以在实现你的条件时,尽量少使用它。
简单条件: 这种类型的条件扩展了前面提到的IterativeCondition类,它决定是否接受一个事件只取决于事件自身的属性。
start.where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) {
return value.getName().startsWith("foo");
}
});
最后,你可以通过pattern.subtype(subClass)方法限制接受的事件类型是初始事件的子类型。
start.subtype(SubEvent.class).where(new SimpleCondition<SubEvent>() {
@Override
public boolean filter(SubEvent value) {
return ...; // 一些判断条件
}
});
组合条件: 如上所示,你可以把subtype条件和其他的条件结合起来使用。这适用于任何条件,你可以通过依次调用where()来组合条件。 最终的结果是每个单一条件的结果的逻辑AND。如果想使用OR来组合条件,你可以像下面这样使用or()方法。
pattern.where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) {
return ...; // 一些判断条件
}
}).or(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) {
return ...; // 一些判断条件
}
});
停止条件: 如果使用循环模式(oneOrMore()和oneOrMore().optional()),你可以指定一个停止条件,例如,接受事件的值大于5直到值的和小于50。
为了更好的理解它,看下面的例子。给定
-
模式如"(a+ until b)" (一个或者更多的"a"直到"b")
-
到来的事件序列"a1" “c” “a2” “b” “a3”
-
输出结果会是: {a1 a2} {a1} {a2} {a3}.
你可以看到{a1 a2 a3}和{a2 a3}由于停止条件没有被输出。
| 模式操作 | 描述 |
|---|---|
| where(condition) | 为当前模式定义一个条件。为了匹配这个模式,一个事件必须满足某些条件。 多个连续的where()语句取与组成判断条件:pattern.where(new IterativeCondition() { @Override public boolean filter(Event value, Context ctx) throws Exception { return ... // 一些判断条件 } }); |
| or(condition) | 增加一个新的判断,和当前的判断取或。一个事件只要满足至少一个判断条件就匹配到模式:pattern.where(new IterativeCondition() { @Override public boolean filter(Event value, Context ctx) throws Exception { return ... // 一些判断条件 } }).or(new IterativeCondition() { @Override public boolean filter(Event value, Context ctx) throws Exception { return ... // 替代条件 } }); |
| until(condition) | 为循环模式指定一个停止条件。意思是满足了给定的条件的事件出现后,就不会再有事件被接受进入模式了。只适用于和oneOrMore()同时使用。NOTE: 在基于事件的条件中,它可用于清理对应模式的状态。pattern.oneOrMore().until(new IterativeCondition() { @Override public boolean filter(Event value, Context ctx) throws Exception { return ... // 替代条件 } }); |
| subtype(subClass) | 为当前模式定义一个子类型条件。一个事件只有是这个子类型的时候才能匹配到模式:pattern.subtype(SubEvent.class); |
| oneOrMore() | 指定模式期望匹配到的事件至少出现一次。默认(在子事件间)使用松散的内部连续性。 关于内部连续性的更多信息可以参考连续性。NOTE: 推荐使用until()或者within()来清理状态。pattern.oneOrMore(); |
| timesOrMore(#times) | 指定模式期望匹配到的事件至少出现#times次。默认(在子事件间)使用松散的内部连续性。 关于内部连续性的更多信息可以参考连续性。pattern.timesOrMore(2); |
| times(#ofTimes) | 指定模式期望匹配到的事件正好出现的次数。默认(在子事件间)使用松散的内部连续性。 关于内部连续性的更多信息可以参考连续性。pattern.times(2); |
| times(#fromTimes, #toTimes) | 指定模式期望匹配到的事件出现次数在#fromTimes和#toTimes之间。默认(在子事件间)使用松散的内部连续性。 关于内部连续性的更多信息可以参考连续性。pattern.times(2, 4); |
| optional() | 指定这个模式是可选的,也就是说,它可能根本不出现。这对所有之前提到的量词都适用。pattern.oneOrMore().optional(); |
| greedy() | 指定这个模式是贪心的,也就是说,它会重复尽可能多的次数。这只对量词适用,现在还不支持模式组。pattern.oneOrMore().greedy(); |
组合模式
现在你已经看到单个的模式是什么样的了,该去看看如何把它们连接起来组成一个完整的模式序列。
模式序列由一个初始模式作为开头,如下所示:
Pattern<Event, ?> start = Pattern.<Event>begin("start");
接下来,你可以增加更多的模式到模式序列中并指定它们之间所需的连续条件。FlinkCEP支持事件之间如下形式的连续策略:
- 严格连续: 期望所有匹配的事件严格的一个接一个出现,中间没有任何不匹配的事件。
- 松散连续: 忽略匹配的事件之间的不匹配的事件。
- 不确定的松散连续: 更进一步的松散连续,允许忽略掉一些匹配事件的附加匹配。
可以使用下面的方法来指定模式之间的连续策略:
- next(),指定严格连续,
- followedBy(),指定松散连续,
- followedByAny(),指定不确定的松散连续。
或者
- notNext(),如果不想后面直接连着一个特定事件
- notFollowedBy(),如果不想一个特定事件发生在两个事件之间的任何地方。
模式序列不能以notFollowedBy()结尾。
一个 NOT 模式前面不能是可选的模式。
// 严格连续
Pattern<Event, ?> strict = start.next("middle").where(...);
// 松散连续
Pattern<Event, ?> relaxed = start.followedBy("middle").where(...);
// 不确定的松散连续
Pattern<Event, ?> nonDetermin = start.followedByAny("middle").where(...);
// 严格连续的NOT模式
Pattern<Event, ?> strictNot = start.notNext("not").where(...);
// 松散连续的NOT模式
Pattern<Event, ?> relaxedNot = start.notFollowedBy("not").where(...);
松散连续意味着跟着的事件中,只有第一个可匹配的事件会被匹配上,而不确定的松散连接情况下,有着同样起始的多个匹配会被输出。 举例来说,模式"a b",给定事件序列"a",“c”,“b1”,“b2”,会产生如下的结果:
- "a"和"b"之间严格连续: {} (没有匹配),"a"之后的"c"导致"a"被丢弃。
“a"和"b"之间松散连续: {a b1},松散连续会"跳过不匹配的事件直到匹配上的事件”。
"a"和"b"之间不确定的松散连续: {a b1}, {a b2},这是最常见的情况。
也可以为模式定义一个有效时间约束。 例如,你可以通过pattern.within()方法指定一个模式应该在10秒内发生。 这种时间模式支持处理时间和事件时间.
一个模式序列只能有一个时间限制。如果限制了多个时间在不同的单个模式上,会使用最小的那个时间限制。
next.within(Time.seconds(10));
循环模式中的连续性
你可以在循环模式中使用和前面章节讲过的同样的连续性。 连续性会被运用在被接受进入模式的事件之间。 用这个例子来说明上面所说的连续性,一个模式序列"a b+ c"(“a"后面跟着一个或者多个(不确定连续的)“b”,然后跟着一个"c”) 输入为"a",“b1”,“d1”,“b2”,“d2”,“b3”,“c”,输出结果如下:
-
严格连续: {a b3 c} – "b1"之后的"d1"导致"b1"被丢弃,同样"b2"因为"d2"被丢弃。
-
松散连续: {a b1 c},{a b1 b2 c},{a b1 b2 b3 c},{a b2 c},{a b2 b3 c},{a b3 c} - "d"都被忽略了。
-
不确定松散连续: {a b1 c},{a b1 b2 c},{a b1 b3 c},{a b1 b2 b3 c},{a b2 c},{a b2 b3 c},{a b3 c} - 注意{a b1 b3 c},这是因为"b"之间是不确定松散连续产生的。
对于循环模式(例如oneOrMore()和times())),默认是松散连续。如果想使用严格连续,你需要使用consecutive()方法明确指定, 如果想使用不确定松散连续,你可以使用allowCombinations()方法。
模式操作 consecutive()
与oneOrMore()和times()一起使用, 在匹配的事件之间施加严格的连续性, 也就是说,任何不匹配的事件都会终止匹配(和next()一样)。
如果不使用它,那么就是松散连续(和followedBy()一样)。
例如,一个如下的模式:
Pattern.<Event>begin("start").where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.getName().equals("c");
}
})
.followedBy("middle").where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.getName().equals("a");
}
}).oneOrMore().consecutive()
.followedBy("end1").where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.getName().equals("b");
}
});
输入:C D A1 A2 A3 D A4 B,会产生下面的输出:
如果施加严格连续性: {C A1 B},{C A1 A2 B},{C A1 A2 A3 B}
不施加严格连续性: {C A1 B},{C A1 A2 B},{C A1 A2 A3 B},{C A1 A2 A3 A4 B}
与oneOrMore()和times()一起使用, 在匹配的事件中间施加不确定松散连续性(和followedByAny()一样)。
如果不使用,就是松散连续(和followedBy()一样)。
例如,一个如下的模式:
Pattern.<Event>begin("start").where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.getName().equals("c");
}
})
.followedBy("middle").where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.getName().equals("a");
}
}).oneOrMore().allowCombinations()
.followedBy("end1").where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.getName().equals("b");
}
});
输入:C D A1 A2 A3 D A4 B,会产生如下的输出:
如果使用不确定松散连续: {C A1 B},{C A1 A2 B},{C A1 A3 B},{C A1 A4 B},{C A1 A2 A3 B},{C A1 A2 A4 B},{C A1 A3 A4 B},{C A1 A2 A3 A4 B}
如果不使用:{C A1 B},{C A1 A2 B},{C A1 A2 A3 B},{C A1 A2 A3 A4 B}
模式组
也可以定义一个模式序列作为begin,followedBy,followedByAny和next的条件。这个模式序列在逻辑上会被当作匹配的条件, 并且返回一个GroupPattern,可以在GroupPattern上使用oneOrMore(),times(#ofTimes), times(#fromTimes, #toTimes),optional(),consecutive(),allowCombinations()。
Pattern<Event, ?> start = Pattern.begin(
Pattern.<Event>begin("start").where(...).followedBy("start_middle").where(...)
);
// 严格连续
Pattern<Event, ?> strict = start.next(
Pattern.<Event>begin("next_start").where(...).followedBy("next_middle").where(...)
).times(3);
// 松散连续
Pattern<Event, ?> relaxed = start.followedBy(
Pattern.<Event>begin("followedby_start").where(...).followedBy("followedby_middle").where(...)
).oneOrMore();
// 不确定松散连续
Pattern<Event, ?> nonDetermin = start.followedByAny(
Pattern.<Event>begin("followedbyany_start").where(...).followedBy("followedbyany_middle").where(...)
).optional();
| 模式操作 | 描述 |
|---|---|
| begin(#name) | 定义一个开始的模式:Pattern start = Pattern.begin("start"); |
| begin(#pattern_sequence) | 定义一个开始的模式:Pattern start = Pattern.begin( Pattern.begin("start").where(...).followedBy("middle").where(...) ); |
| next(#name) | 增加一个新的模式。匹配的事件必须是直接跟在前面匹配到的事件后面(严格连续):Pattern next = start.next("middle"); |
| next(#pattern_sequence) | 增加一个新的模式。匹配的事件序列必须是直接跟在前面匹配到的事件后面(严格连续):java Pattern next = start.next( Pattern.begin("start").where(...).followedBy("middle").where(...) ); |
| followedBy(#name) | 增加一个新的模式。可以有其他事件出现在匹配的事件和之前匹配到的事件中间(松散连续):java Pattern followedBy = start.followedBy("middle"); |
| followedBy(#pattern_sequence) | 增加一个新的模式。可以有其他事件出现在匹配的事件序列和之前匹配到的事件中间(松散连续):java Pattern followedBy = start.followedBy( Pattern.begin("start").where(...).followedBy("middle").where(...) ); |
| followedByAny(#name) | 增加一个新的模式。可以有其他事件出现在匹配的事件和之前匹配到的事件中间, 每个可选的匹配事件都会作为可选的匹配结果输出(不确定的松散连续):java Pattern followedByAny = start.followedByAny("middle"); |
| followedByAny(#pattern_sequence) | 增加一个新的模式。可以有其他事件出现在匹配的事件序列和之前匹配到的事件中间, 每个可选的匹配事件序列都会作为可选的匹配结果输出(不确定的松散连续):java Pattern followedByAny = start.followedByAny( Pattern.begin("start").where(...).followedBy("middle").where(...) ); |
| notNext() | 增加一个新的否定模式。匹配的(否定)事件必须直接跟在前面匹配到的事件之后(严格连续)来丢弃这些部分匹配:java Pattern notNext = start.notNext("not"); |
| notFollowedBy() | 增加一个新的否定模式。即使有其他事件在匹配的(否定)事件和之前匹配的事件之间发生, 部分匹配的事件序列也会被丢弃(松散连续):java Pattern notFollowedBy = start.notFollowedBy("not"); |
| within(time) | 定义匹配模式的事件序列出现的最大时间间隔。如果未完成的事件序列超过了这个事件,就会被丢弃:java pattern.within(Time.seconds(10)); |
匹配后跳过策略
对于一个给定的模式,同一个事件可能会分配到多个成功的匹配上。为了控制一个事件会分配到多少个匹配上,你需要指定跳过策略AfterMatchSkipStrategy。 有五种跳过策略,如下:
- NO_SKIP: 每个成功的匹配都会被输出。
- SKIP_TO_NEXT: 丢弃以相同事件开始的所有部分匹配。
- SKIP_PAST_LAST_EVENT: 丢弃起始在这个匹配的开始和结束之间的所有部分匹配。
- SKIP_TO_FIRST: 丢弃起始在这个匹配的开始和第一个出现的名称为PatternName事件之间的所有部分匹配。
- SKIP_TO_LAST: 丢弃起始在这个匹配的开始和最后一个出现的名称为PatternName事件之间的所有部分匹配。
注意当使用SKIP_TO_FIRST和SKIP_TO_LAST策略时,需要指定一个合法的PatternName.
例如,给定一个模式b+ c和一个数据流b1 b2 b3 c,不同跳过策略之间的不同如下:
| 跳过策略 | 结果 | 描述 |
|---|---|---|
| NO_SKIP | b1 b2 b3 c,b2 b3 c,b3 c | 找到匹配b1 b2 b3 c之后,不会丢弃任何结果。 |
| SKIP_TO_NEXT | b1 b2 b3 c,b2 b3 c,b3 c | 找到匹配b1 b2 b3 c之后,不会丢弃任何结果,因为没有以b1开始的其他匹配。 |
| SKIP_PAST_LAST_EVENT | b1 b2 b3 c | 找到匹配b1 b2 b3 c之后,会丢弃其他所有的部分匹配。 |
| SKIP_TO_FIRST[b] | b1 b2 b3 c,b2 b3 c,b3 c | 找到匹配b1 b2 b3 c之后,会尝试丢弃所有在b1之前开始的部分匹配,但没有这样的匹配,所以没有任何匹配被丢弃。 |
| SKIP_TO_LAST[b] | b1 b2 b3 c,b3 c | 找到匹配b1 b2 b3 c之后,会尝试丢弃所有在b3之前开始的部分匹配,有一个这样的b2 b3 c被丢弃。 |
在看另外一个例子来说明NO_SKIP和SKIP_TO_FIRST之间的差别: 模式: (a | b | c) (b | c) c+.greedy d,输入:a b c1 c2 c3 d,结果将会是:
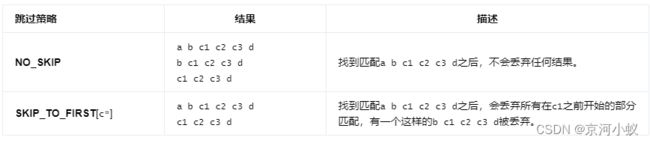
为了更好的理解NO_SKIP和SKIP_TO_NEXT之间的差别,看下面的例子: 模式:a b+,输入:a b1 b2 b3,结果将会是:
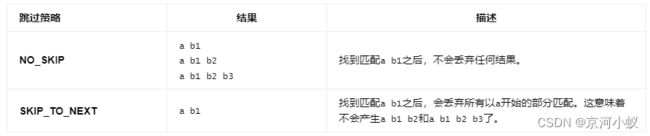
想指定要使用的跳过策略,只需要调用下面的方法创建AfterMatchSkipStrategy:
| 方法 | 描述 |
|---|---|
| AfterMatchSkipStrategy.noSkip() | 创建NO_SKIP策略 |
| AfterMatchSkipStrategy.skipToNext() | 创建SKIP_TO_NEXT策略 |
| AfterMatchSkipStrategy.skipPastLastEvent() | 创建SKIP_PAST_LAST_EVENT策略 |
| AfterMatchSkipStrategy.skipToFirst(patternName) | 创建引用模式名称为patternName的SKIP_TO_FIRST策略 |
| AfterMatchSkipStrategy.skipToLast(patternName) | 创建引用模式名称为patternName的SKIP_TO_LAST策略 |
可以通过调用下面方法将跳过策略应用到模式上:
AfterMatchSkipStrategy skipStrategy = ...;
Pattern.begin("patternName", skipStrategy);
使用SKIP_TO_FIRST/LAST时,有两个选项可以用来处理没有事件可以映射到对应的变量名上的情况。 默认情况下会使用NO_SKIP策略,另外一个选项是抛出异常。 可以使用如下的选项:
AfterMatchSkipStrategy.skipToFirst(patternName).throwExceptionOnMiss();
检测模式
在指定了要寻找的模式后,该把它们应用到输入流上来发现可能的匹配了。为了在事件流上运行你的模式,需要创建一个PatternStream。 给定一个输入流input,一个模式pattern和一个可选的用来对使用事件时间时有同样时间戳或者同时到达的事件进行排序的比较器comparator, 你可以通过调用如下方法来创建PatternStream:
DataStream<Event> input = ...;
Pattern<Event, ?> pattern = ...;
EventComparator<Event> comparator = ...; // 可选的
PatternStream<Event> patternStream = CEP.pattern(input, pattern, comparator);
输入流根据你的使用场景可以是keyed或者non-keyed。
在 non-keyed 流上使用模式将会使你的作业并发度被设为1。
从模式中选取
在获得到一个PatternStream之后,你可以应用各种转换来发现事件序列。推荐使用PatternProcessFunction。
PatternProcessFunction有一个processMatch的方法在每找到一个匹配的事件序列时都会被调用。 它按照Map
class MyPatternProcessFunction<IN, OUT> extends PatternProcessFunction<IN, OUT> {
@Override
public void processMatch(Map<String, List<IN>> match, Context ctx, Collector<OUT> out) throws Exception;
IN startEvent = match.get("start").get(0);
IN endEvent = match.get("end").get(0);
out.collect(OUT(startEvent, endEvent));
}
}
PatternProcessFunction可以访问Context对象。有了它之后,你可以访问时间属性,比如currentProcessingTime或者当前匹配的timestamp (最新分配到匹配上的事件的时间戳)。 更多信息可以看时间上下文。 通过这个上下文也可以将结果输出到侧输出.
处理超时的部分匹配
当一个模式上通过within加上窗口长度后,部分匹配的事件序列就可能因为超过窗口长度而被丢弃。可以使用TimedOutPartialMatchHandler接口 来处理超时的部分匹配。这个接口可以和其它的混合使用。也就是说你可以在自己的PatternProcessFunction里另外实现这个接口。 TimedOutPartialMatchHandler提供了另外的processTimedOutMatch方法,这个方法对每个超时的部分匹配都会调用。
class MyPatternProcessFunction<IN, OUT> extends PatternProcessFunction<IN, OUT> implements TimedOutPartialMatchHandler<IN> {
@Override
public void processMatch(Map<String, List<IN>> match, Context ctx, Collector<OUT> out) throws Exception;
...
}
@Override
public void processTimedOutMatch(Map<String, List<IN>> match, Context ctx) throws Exception;
IN startEvent = match.get("start").get(0);
ctx.output(outputTag, T(startEvent));
}
}
注意: processTimedOutMatch不能访问主输出。 但你可以通过Context对象把结果输出到侧输出。
便捷的API(旧api迁移到新api)
前面提到的PatternProcessFunction是在Flink 1.8之后引入的,从那之后推荐使用这个接口来处理匹配到的结果。 用户仍然可以使用像select/flatSelect这样旧格式的API,它们会在内部被转换为PatternProcessFunction。
PatternStream<Event> patternStream = CEP.pattern(input, pattern);
OutputTag<String> outputTag = new OutputTag<String>("side-output"){};
SingleOutputStreamOperator<ComplexEvent> flatResult = patternStream.flatSelect(
outputTag,
new PatternFlatTimeoutFunction<Event, TimeoutEvent>() {
public void timeout(
Map<String, List<Event>> pattern,
long timeoutTimestamp,
Collector<TimeoutEvent> out) throws Exception {
out.collect(new TimeoutEvent());
}
},
new PatternFlatSelectFunction<Event, ComplexEvent>() {
public void flatSelect(Map<String, List<IN>> pattern, Collector<OUT> out) throws Exception {
out.collect(new ComplexEvent());
}
}
);
DataStream<TimeoutEvent> timeoutFlatResult = flatResult.getSideOutput(outputTag);
CEP库中的时间
按照事件时间处理迟到事件
在CEP中,事件的处理顺序很重要。在使用事件时间时,为了保证事件按照正确的顺序被处理,一个事件到来后会先被放到一个缓冲区中, 在缓冲区里事件都按照时间戳从小到大排序,当水位线到达后,缓冲区中所有小于水位线的事件被处理。这意味着水位线之间的数据都按照时间戳被顺序处理。
这个库假定按照事件时间时水位线一定是正确的。
为了保证跨水位线的事件按照事件时间处理,Flink CEP库假定水位线一定是正确的,并且把时间戳小于最新水位线的事件看作是晚到的。 晚到的事件不会被处理。你也可以指定一个侧输出标志来收集比最新水位线晚到的事件,你可以这样做:
PatternStream<Event> patternStream = CEP.pattern(input, pattern);
OutputTag<String> lateDataOutputTag = new OutputTag<String>("late-data"){};
SingleOutputStreamOperator<ComplexEvent> result = patternStream
.sideOutputLateData(lateDataOutputTag)
.select(
new PatternSelectFunction<Event, ComplexEvent>() {...}
);
DataStream<String> lateData = result.getSideOutput(lateDataOutputTag);
时间上下文
在PatternProcessFunction中,用户可以和IterativeCondition中 一样按照下面的方法使用实现了TimeContext的上下文:
/**
* 支持获取事件属性比如当前处理事件或当前正处理的事件的时间。
* 用在{@link PatternProcessFunction}和{@link org.apache.flink.cep.pattern.conditions.IterativeCondition}中
*/
@PublicEvolving
public interface TimeContext {
/**
* 当前正处理的事件的时间戳。
*
* 如果是{@link org.apache.flink.streaming.api.TimeCharacteristic#ProcessingTime},这个值会被设置为事件进入CEP算子的时间。
*/
long timestamp();
/** 返回当前的处理时间。 */
long currentProcessingTime();
}
这个上下文让用户可以获取处理的事件(在IterativeCondition时候是进来的记录,在PatternProcessFunction是匹配的结果)的时间属性。 调用TimeContext#currentProcessingTime总是返回当前的处理时间,而且尽量去调用这个函数而不是调用其它的比如说System.currentTimeMillis()。
使用EventTime时,TimeContext#timestamp()返回的值等于分配的时间戳。 使用ProcessingTime时,这个值等于事件进入CEP算子的时间点(在PatternProcessFunction中是匹配产生的时间)。 这意味着多次调用这个方法得到的值是一致的。
可选的参数设置
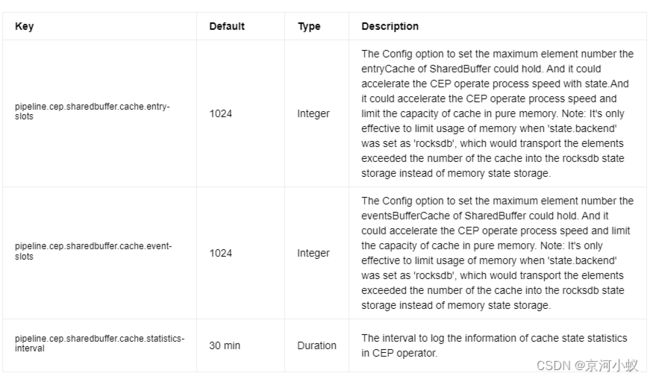
用于配置 Flink CEP 的 SharedBuffer 缓存容量的选项。它可以加快 CEP 算子的处理速度,并限制内存中缓存的元素数量。
注意: 仅当 state.backend 设置为 rocksdb 时限制内存使用才有效,这会将超过缓存数量的元素传输到 rocksdb 状态存储而不是内存状态存储。当 state.backend 设置为 rocksdb 时,这些配置项有助于限制内存。相比之下,当 state.backend 设置为非 rocksdb 时,缓存会导致性能下降。与使用 Map 实现的旧缓存相比,状态部分将包含更多从 guava-cache 换出的元素,这将使得 copy on write 时的状态处理增加一些开销。
例子
下面的例子在一个分片的Events流上检测模式start, middle(name = “error”) -> end(name = “critical”)。 事件按照id分片,一个有效的模式需要发生在10秒内。
StreamExecutionEnvironment env = ...;
DataStream<Event> input = ...;
DataStream<Event> partitionedInput = input.keyBy(new KeySelector<Event, Integer>() {
@Override
public Integer getKey(Event value) throws Exception {
return value.getId();
}
});
Pattern<Event, ?> pattern = Pattern.<Event>begin("start")
.next("middle").where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.getName().equals("error");
}
}).followedBy("end").where(new SimpleCondition<Event>() {
@Override
public boolean filter(Event value) throws Exception {
return value.getName().equals("critical");
}
}).within(Time.seconds(10));
PatternStream<Event> patternStream = CEP.pattern(partitionedInput, pattern);
DataStream<Alert> alerts = patternStream.select(new PatternSelectFunction<Event, Alert>() {
@Override
public Alert select(Map<String, List<Event>> pattern) throws Exception {
return createAlert(pattern);
}
});
``