【阅读论文】TimesNet-short term forecast机理
目录
一、遇到的问题
二、short term 数据分析(以M4-quarterly为例)
三、研究代码
Step1 sh文件
Step2 run.py文件
Step3 exp_basic.py文件
Step4 exp_short_term_forecasting.py文件
Step5 完整执行run.py文件
四、回答遇到的问题
一、遇到的问题
现在还在硬磕TimeNet那篇文章,但由于自己电脑跑一小段要1900s+服务器没权限改不了环境,调转方向去分析输入输出和代码了。讲道理,服务器实在是太痛苦了,各种没权限,下不了、删不了,想创建一个新环境也没门。

二、short term 数据分析(以M4-quarterly为例)
以下四张图分别为:train, test, forecast 和 由第一组数据(Q1)绘制出的0.pdf
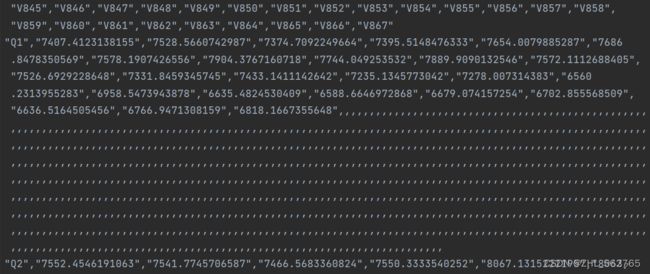

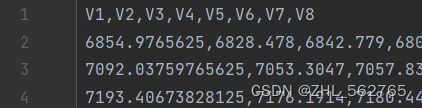

train的数据标号写到了867,但实际上数据只有25个(Q1、Q2、Q3都是25个);test里是V1到V9,但其实Q1占了一个,也是只有8个数据;forecast最简单,只有8个数据;0.pdf中的黄线有24个数据点(转折点),除去蓝色的出发点,黄蓝刚好也是8个点,并且根据下图的红线可以明显看出,蓝线(Ground Truth)是test的数据,黄线(Prediction)是forecast的数据。
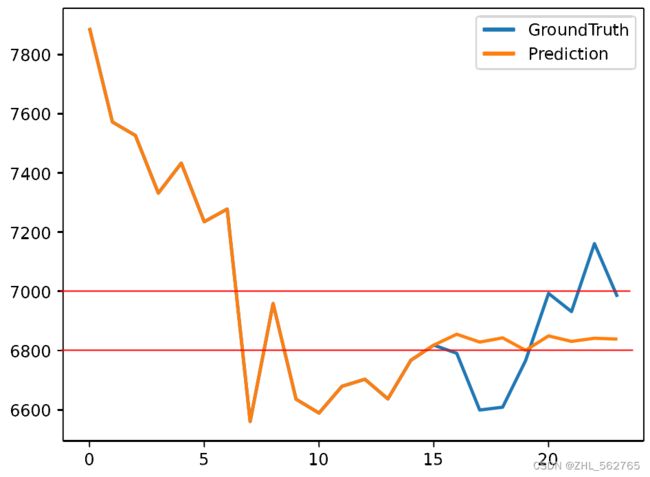
对比数据时,我突然发现了一个问题。Ground Truth(GT)一般是指真值(作为基准的,由已有的、可靠的测量方式得到的测量值,即 经验证据 ),Prediction一般就是根据GT的一部分做训练来预测后一部分,但出现了一个问题“train的数据和黄线数据、test数据不匹配”:train有25个数据,但黄线只有24个数据点;train的开头是7407.4123138155,但黄线目测在7900左右;train的数据在test里也是完全找不到。
于是我觉得研究一下代码,来搞清楚以下几个问题:
1. train的25个数据用在了什么地方?
2. 0.pdf的24个数据点来自什么地方?
3. forecast作为预测值是由什么数据来预测的?
三、研究代码
Step1 sh文件
从执行角度入手,先看sh文件
bash ./scripts/short_term_forecast/TimesNet_M4.sh
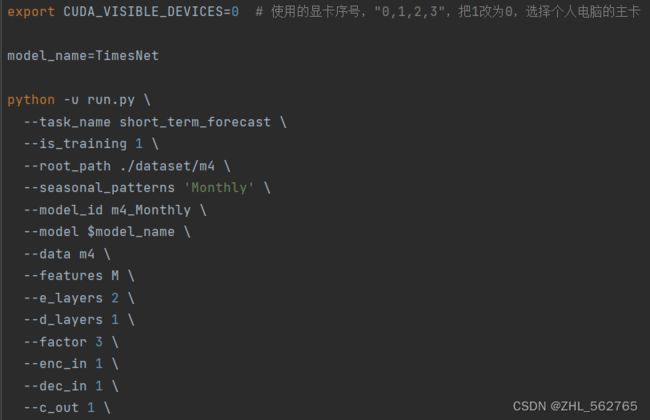
代码很清晰,第一行是我第一篇文章里死活找不到的问题(启用第x块GPU),然后是设定model的名字,再然后是执行Python文件,并引入各项参数。
PS.写到Step4的2时才发现,model的值就是第二行的参数,害得我找了好久。
Step2 run.py文件
那么接下来就来看run.py文件。
1. 引入各种包,设定随机数种子,创建参数字典parser ,然后根据sh文件里的参数进行add参数。
2. 根据文章parse_args()详解_parser.parse_args()_zcy904983的博客-CSDN博客,此处是将属性给与args实例: 把parser中设置的所有"add_argument"给返回到args子类实例当中, 那么parser中增加的属性内容都会在args实例中,使用即可。也就是创建了一个新的参数变量args,并将parser中的各种参数都赋给它。

3. 很单纯,根据task_name决定执行哪一种任务。
4. 终于来到了主函数,先看训练的部分:
setting = '{}_{}_{}_{}_ft{}_sl{}_ll{}_pl{}_dm{}_nh{}_el{}_dl{}_/
df{}_fc{}_eb{}_dt{}_{}_{}'.format(args.参数)
根据文章Python 中 str.format() 方法详解_python str.format_团子大圆帅的博客-CSDN博客,容易理解这是将args的参数值变为一长串的字符串,在后面将会传递给别的函数,而且作为运行结果的图像文件(如0.pdf)就是保存在文件夹“test_results.这个字符串”下。

5. 将args参数交由Exp函数执行,这个Exp在Step4中已经出现了,在本文中就是指Exp_Short_Term_Forecast,接下来根据引入包的这句,来研究exp_short_term_forecasting.py.
from exp.exp_short_term_forecasting import Exp_Short_Term_Forecast
6. 由于train,test等函数都与exp有关,就先把if和else的最后一句说了,torch.cuda.empty_cache(),效果为清空显存缓冲区,在显存比较紧张的情况下可以提高性能。
Step3 exp_basic.py文件
在研究exp_short_term_forecasting.py前,先来认识一下exp_basic.py.主要就是以下三部分:
1. def __init__(self, args):args(参数),model_dict(选择模型),device(GPU的序号/CPU),model(略);
2. def _build_model(self): 有语句raise NotImplementedError,比较复杂,感兴趣的可以看看这篇文章简析 Python 的 `NotImplemented` - 知乎,直接结果就是,告诉device没问题;
3. def _acquire_device(self):调用的设备,输出给device;
其余函数由调用的exp_xxx.py来override(重写)。
Step4 exp_short_term_forecasting.py文件
现在来看exp_short_term_forecasting.py.
1. def __init__(self, args):接收参数。
2. def _build_model(self):感觉应该是重写了exp_basic里的_build_model。
self.args.pred_len = M4Meta.horizons_map[self.args.seasonal_patterns] # Up to M4 config
# args参数里seasonal_patterns的值是Quarterly,因此pred_len=8,即预测8个数据,值为int
self.args.seq_len = 2 * self.args.pred_len # input_len = 2*pred_len
# 时间序列长度为2倍预测长度,即16个数据(这应该就是0.pdf中24的来源),值为int
self.args.label_len = self.args.pred_len# 做标记的也是8个数据(应该是指GT),值为int
self.args.frequency_map = M4Meta.frequency_map[self.args.seasonal_patterns]# args参数里seasonal_patterns的值是Quarterly,因此frequency_map=4,即一年有4个季度,类似于季节性周期,值为int
model = self.model_dict[self.args.model].Model(self.args).float()# args参数里model的值是TimesNet,故使用TimesNet模型,Model(self.args)有点复杂先略过,float()是将输入变为float型,input是数值?
def _get_data(self, flag):根据args参数中的task_name和data返回data_set,和data_loader,此处是从m4数据集中获取数据。
_get_data里用到了一个名为data_provider的函数,里面涉及了许多参数和与机器学习相关的知识。
参数:
args.embed:time features encoding,时间特征的编码类型;
args.train_epochs:train epochs,epoch的个数,对所有数据进行一次训练为一个epoch;
args.itr:experiments times,iteration的个数,将所有数据分为若干个batch,对一个batch进行一次训练为一个itr(iteration);
args.batch_size:batch size of train input data,batch的大小,每一次训练时,使用数据的大小/多少,数据总量=batch的个数*batch_size;
args.freq:freq for time features encoding,如果编码类型是timeF,则时间特征编码有对应的频率;
args.num_workers:data loader num workers,数据加载器的个数。
机器学习专有名词:
shuffle:将序列的所有元素随机排序;
drop last:当整个数据长度不能够整除batch_size时,选择是否要丢弃最后一个不完整的batch;collate_fn:自定义数据堆叠过程,自定义batch数据的输出形式,来手动将抽出的样本堆叠起来。
def _select_optimizer(self):optim.Adam里是空的,只能知道输入了model.parameters()和学习率,由train函数重写。
def _select_criterion(self, loss_name='MSE'):选择损失函数/评价标准,默认为MSE,此处为SMAPE(symmetric mean absolute percentage error),即对称平均绝对百分比误差,可从https://www.sciencedirect.com/science/article/pii/S0169207019301128#tbl7这篇文献中了解更多,也是终端里的loss。
def train(self, setting):训练。
train_data:训练集,用于训练参数;
vali_data:验证集,用于在训练时观察训练效果、泛化能力;
EarlyStopping:早停,避免过拟合,提高泛化能力;
args.patience:EarlyStopping的参数,最多能够容忍多少个epoch内没有improvement;
verbose:日志显示,值为0/1,取0/FALSE时,不在标准输出流输出日志信息,取1/TRUE时,输出进度条记录(应该就是终端里每100个iters显示一次的进度)。
def vali(self, train_loader, vali_loader, criterion):验证,略。
def test(self, setting, test=0):测试,最后的提醒“After all 6 tasks are finished, you can calculate the averaged index”,也就是当6种频率的任务都完成后,可以计算一些平均指数,即论文图表中的SMAPE,MASE,OWA三项指标(还有MAPE)。
Step5 完整执行run.py文件
成功获得了yearly,quarterly,monthly,weekly 和 daily的checkpoints文件、m4_results文件和test_results文件。但当执行到hourly时,出了点问题,找不到daily的checkpoints文件了。
super(_open_file, self).__init__(open(name, mode)) FileNotFoundError: [Errno 2] No such file or directory: './checkpoints/short_term_forecast_m4_Daily_TimesNet_m4_ftM_sl96_ll48_pl96_dm32_nh8_el2_dl1_df32_fc3_ebtimeF_dtTrue_Exp_0/checkpoint.pth'
仔细对比了一下文件夹名“short_term_forecast_m4_Daily_TimesNet_m4_ftM_sl96_ll48_pl96_dm16_nh8_el2_dl1_df16_fc3_ebtimeF_dtTrue_Exp_0”。
区别在于:hourly文件想找的是“dm32_nh8_el2_dl1_df32”,而daily文件运行的结果是“dm16_nh8_el2_dl1_df16”,dm和df两个参数出了问题。
在run.py文件中容易发现,dm是d_model,df是d_ff,而TimesNet_M4.sh文件中明确写了:
--d_model 16 --d_ff 16
开始排查问题。
if test:
print('loading model')
self.model.load_state_dict(torch.load(os.path.join('./checkpoints/' + setting, 'checkpoint.pth')))
加载checkpoint文件的是这一段,在这一段前输出setting,看看setting是啥。
short_term_forecast_m4_Daily_TimesNet_m4_ftM_sl96_ll48_pl96_
dm32_nh8_el2_dl1_df32_fc3_ebtimeF_dtTrue_Exp_0
和搜索的文件名是一致的,突然意识到一个问题,明明运行的是hourly部分,找的却是daily文件?回顾了一下TimesNet_M4.sh。
--seasonal_patterns 'Monthly' \ --model_id m4_Monthly
--seasonal_patterns 'Yearly' \ --model_id m4_Yearly
--seasonal_patterns 'Quarterly' \ --model_id m4_Quarterly
--seasonal_patterns 'Daily' \ --model_id m4_Daily
--seasonal_patterns 'Weekly' \ --model_id m4_Weekly
--seasonal_patterns 'Hourly' \ --model_id m4_Daily
果然出了问题,model_id明明应该是m4_Hourly,但这里写错了。
改成“m4_Hourly”后又试了一下,还是有问题,果然,明明没有创建过,却直接检索、使用,再改一下吧,先运行一次is_training=1的Hourly.一次性成功了,因为6种结果都有了,直接就输出了6中频率的4种评价。又改回is_training=0后,只是输出了6*4的结果,并无区别。
smape: {'Yearly': 13.478, 'Quarterly': 10.109, 'Monthly': 12.774, 'Others': 5.019, 'Average': 11.908}
mape: {'Yearly': 16.405, 'Quarterly': 11.519, 'Monthly': 14.942, 'Others': 6.696, 'Average': 14.044}
mase: {'Yearly': 2.998, 'Quarterly': 1.184, 'Monthly': 0.946, 'Others': 3.348, 'Average': 1.595}
owa: {'Yearly': 0.79, 'Quarterly': 0.891, 'Monthly': 0.887, 'Others': 1.056, 'Average': 0.856}
smape,mase 和 owa三项指标都比论文表格中的略高,但也算是符合预期,应该没什么问题。
四、回答遇到的问题
回过头一看,这三个问题还是没能很好地回答,所以再来看看数据传递的部分,从train入手。
Q1 train的前两行就是_get_data,但TimesNet_M4.sh中只有root_path,没有data_path,最后是如何确定数据文件的?并且,train和val分别是什么?
A1 train => _get_data => data_provider => data_factory.py => data_dict[args.data]=Dataset_M4 => data_loader.py => class Dataset_M4 => __read_data__ => dataset = M4Dataset.load(返回ids/M4id,groups,frequencies,horizons和training.npz的value,根据seasonal_patterns,把需要的ids和value保存到self中)。也就是说,data_factory.py中的data_provider函数获取的数据,train来源是training.npz,val来源是test.npz。核实了一下,training.npz的前3组数据,和Yearly-train.csv的前三组一致。
A1续 data_path来自m4.py,由flag确定是training.npz还是test.npz,其中train的来源是training.npz,val的来源是test.npz。
Q2 test_results中用于绘制图片的数据来源是哪里?
A2 打印了一下Quarterly-train中的第一个x,发现是Quarterly-train中Q1的后16个数据。
_, train_loader = self._get_data(flag='train') _, test_loader = self._get_data(flag='test') x, _ = train_loader.dataset.last_insample_window()
Q3 TimesNet的具体机制是什么?
A3 outputs = self.model(batch_x, None, dec_inp, None) lf.args),更多内容在models/TimesNet.py中。
最后回答一下最开始的3个问题
1. train的25个数据用在了什么地方?
2. 0.pdf的24个数据点来自什么地方?
3. forecast作为预测值是由什么数据来预测的?
答:
0.pdf的前16个数据点是train的最后16个数据,0.pdf的后8个是test的8个数据和预测出来的8个数据,其中train的后8个是预测的基础。train函数的数据与csv中的完全一致,而test函数中的数据略有加工,比如改为4位小数,但第4位似乎又不是四舍五入获得的,如.1667355648变为.1665。(暂不讨论)test数据只用于test函数中的画图部分,在train函数中几乎没有用到。
总结:
对于M4数据集Quarterly类、TimesNet算法、short term forecast而言,不论数据有多少个,任取连续的16个用于训练数据,都只取最后8个作为预测的基础。
感想:
毕竟阅读论文的经验有限,即使知道哪些方法正确,也还是想按着自己想法来。最开始是想全部认真地看,看到一半就发现实在是太累了,不过这篇还是这样看完吧,也算是有始有终了。(这是最开始几天的)
现在的感想,新人入坑研究算法实在是太累了,花了一周时间都没能搞明白short_term_forecasting的数据选取机理。实在是太过抑郁了,先不搞这个了……而且以后应该也不会这么写CSDN的文章了,又长又累赘,写得累看得也累。
感觉浪费了很多时间,收获不是很大,以后看程序不能再这样了,应当先规划一下总目标和阶段性小目标。而且,虽然这些程序看着很高端、很难懂,但实际上还是那些处理手段,只不过写法还有待学习、理解,以后应该就会好很多。