VPP node-graph编排过程
VPP处理报文时是沿着一个有向图进行处理的,每一个功能单元称之为节点(node)。
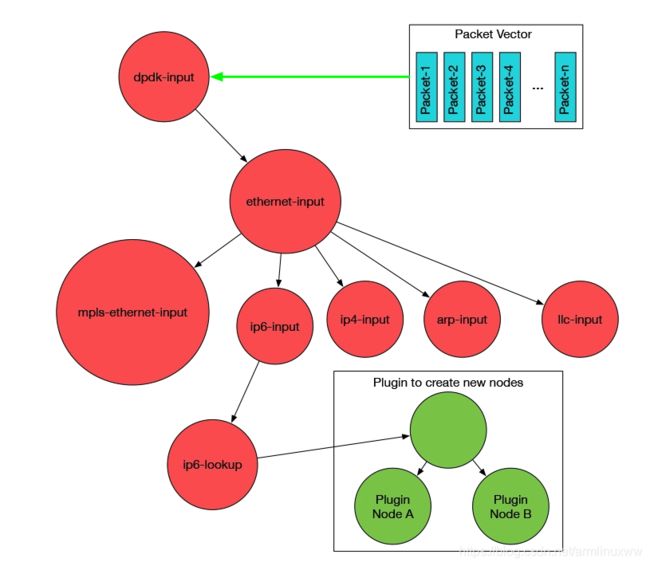
数据结构
静态数据结构
节点全局管理结构vlib_node_main_t
typedef struct
{
/* Public nodes. */
/* 节点指针数组,使用下标作为索引 */
vlib_node_t **nodes;
/* Node index hashed by node name. */
/* 根据节点名字进行hash,可以根据节点名字进行hash表查找
* 只有main线程才会委会该hash表
*/
uword *node_by_name;
u32 flags;
/* 该标志表示Runtime信息已经被初始化过了 */
#define VLIB_NODE_MAIN_RUNTIME_STARTED (1 << 0)
/* Nodes segregated by type for cache locality.
Does not apply to nodes of type VLIB_NODE_TYPE_INTERNAL. */
vlib_node_runtime_t *nodes_by_type[VLIB_N_NODE_TYPE];
/* Node runtime indices for input nodes with pending interrupts. */
u32 *pending_interrupt_node_runtime_indices;
clib_spinlock_t pending_interrupt_lock;
/* Input nodes are switched from/to interrupt to/from polling mode
when average vector length goes above/below polling/interrupt
thresholds.
* 输入节点在中断模式和轮询模式之间进行切换,当向量的平均长度高于轮询长度阈值时
* 将会从中断模式切换到轮询模式(这种情况说明报文非常多),当长度低于中断阈值时,从
* 轮询模式切换到中断模式(压力变小了)
*/
u32 polling_threshold_vector_length;
u32 interrupt_threshold_vector_length;
/* Vector of next frames. */
/* 帧数组,由内部节点组成,其中n1是节点的下一跳个节点的个数,元素是节点运行索引
* node_runtime_index与帧数据索引构成的帧。
*/
/* |----node 1的n1个元素|----node 2的n2个元素|......| ----node n的n个元素| */
/* 只针对内部节点 */
vlib_next_frame_t *next_frames;
/* Vector of internal node's frames waiting to be called.
* 等待被调用的内部节点,通常是上一个节点的报文处理后指向的下一个节点
*/
vlib_pending_frame_t *pending_frames;
/* Timing wheel for scheduling time-based node dispatch. */
void *timing_wheel;
vlib_signal_timed_event_data_t *signal_timed_event_data_pool;
/* Opaque data vector added via timing_wheel_advance. */
u32 *data_from_advancing_timing_wheel;
/* CPU time of next process to be ready on timing wheel. */
f64 time_next_process_ready;
/* Vector of process nodes.
One for each node of type VLIB_NODE_TYPE_PROCESS. */
vlib_process_t **processes;
/* Current running process or ~0 if no process running. */
u32 current_process_index;
/* Pool of pending process frames. */
vlib_pending_frame_t *suspended_process_frames;
/* Vector of event data vectors pending recycle. */
void **recycled_event_data_vectors;
/* Current counts of nodes in each state. */
u32 input_node_counts_by_state[VLIB_N_NODE_STATE];
/* Hash of (scalar_size,vector_size) to frame_sizes index. */
uword *frame_size_hash;
/* Per-size frame allocation information. */
/* 不同大小的帧的分配信息,是一个数组,与上面的hash表是两种索引方式 */
vlib_frame_size_t *frame_sizes;
/* Time of last node runtime stats clear. */
f64 time_last_runtime_stats_clear;
/* Node registrations added by constructors */
vlib_node_registration_t *node_registrations;
} vlib_node_main_t;节点类型
typedef enum
{
/* An internal node on the call graph (could be output). */
VLIB_NODE_TYPE_INTERNAL,
/* Nodes which input data into the processing graph.
Input nodes are called for each iteration of main loop.
输入节点,报文流转入口 */
VLIB_NODE_TYPE_INPUT,
/* Nodes to be called before all input nodes.
Used, for example, to clean out driver TX rings before
processing input.
输入节点之前处理的节点,用于处理一些在处理输入报文之前的任务。
比如清除发送缓冲区(好像没有注册该功能的节点)。目前只注册了两个该
类型的节点:epoll和session */
VLIB_NODE_TYPE_PRE_INPUT,
/* "Process" nodes which can be suspended and later resumed. */
/* vpp的协程节点,用于处理可以挂起的任务,比如命令行,api等业务 */
VLIB_NODE_TYPE_PROCESS,
VLIB_N_NODE_TYPE,
} vlib_node_type_t;节点功能函数描述结构
typedef struct _vlib_node_fn_registration
{
vlib_node_function_t *function; /* 功能函数 */
int priority; /* 优先级,同一节点可以注册多个处理函数,选择优先级最高的,值越大优先级越高 */
struct _vlib_node_fn_registration *next_registration;/* 形成链表 */
char *name;/* 名字,必须要和其所属的节点一致,否则注册会失败 */
} vlib_node_fn_registration_t;注册节点描述结构,用于表示一个注册节点
typedef struct _vlib_node_registration
{
/* Vector processing function for this node. 节点的功能函数,从下面注册的功能函数链表中选择一个优先级最高的最为该成员的值 */
vlib_node_function_t *function;
/* Node function candidate registration with priority 节点功能函数链表 */
vlib_node_fn_registration_t *node_fn_registrations;
/* Node name. 节点名字 */
char *name;
/* Name of sibling (if applicable). */
/* 兄弟节点名字 */
char *sibling_of;
/* Node index filled in by registration. 节点索引 */
u32 index;
/* Type of this node. 节点类型 */
vlib_node_type_t type;
/* Error strings indexed by error code for this node. 节点错误码映射表 */
char **error_strings;
/* Buffer format/unformat for this node. */
format_function_t *format_buffer;
unformat_function_t *unformat_buffer;
/* Trace format/unformat for this node. */
format_function_t *format_trace;
unformat_function_t *unformat_trace;
/* Function to validate incoming frames. */
u8 *(*validate_frame) (struct vlib_main_t * vm,
struct vlib_node_runtime_t *,
struct vlib_frame_t * f);
/* Per-node runtime data. 节点运行时数据,私有数据存储位置 */
void *runtime_data;
/* Process stack size. */
u16 process_log2_n_stack_bytes;
/* Number of bytes of per-node run time data. */
u8 runtime_data_bytes;
/* State for input nodes. */
u8 state;
/* Node flags. */
u16 flags;
/* protocol at b->data[b->current_data] upon entry to the dispatch fn */
u8 protocol_hint;
/* Size of scalar and vector arguments in bytes. */
u16 scalar_size, vector_size;
/* Number of error codes used by this node. */
u16 n_errors;
/* Number of next node names that follow. 该节点指向的下一个节点个数 */
u16 n_next_nodes;
/* Constructor link-list, don't ask... 所有节点通过该成员形成链表 */
struct _vlib_node_registration *next_registration;
/* Names of next nodes which this node feeds into. 下一个节点数组,存储的是名字、 */
char *next_nodes[];
} vlib_node_registration_t;节点注册相关的宏
#ifndef CLIB_MARCH_VARIANT
#define VLIB_REGISTER_NODE(x,...) \
__VA_ARGS__ vlib_node_registration_t x; \ //声明一个需要注册的节点
static void __vlib_add_node_registration_##x (void) \ //声明一个静态的添加一个节点的函数,有constructor属性,在main函数之前执行
__attribute__((__constructor__)) ; \
static void __vlib_add_node_registration_##x (void) \
{ \ //定义添加节点函数,即将节点x链接到vm->node_main.node_registrations链表中
vlib_main_t * vm = vlib_get_main(); \
x.next_registration = vm->node_main.node_registrations; \
vm->node_main.node_registrations = &x; \
} \
static void __vlib_rm_node_registration_##x (void) \ //从链表中移除节点
__attribute__((__destructor__)) ; \
static void __vlib_rm_node_registration_##x (void) \
{ \
vlib_main_t * vm = vlib_get_main(); \
VLIB_REMOVE_FROM_LINKED_LIST (vm->node_main.node_registrations, \
&x, next_registration); \
} \
__VA_ARGS__ vlib_node_registration_t x // 定义一个需要注册的节点,这里没有分号,是因为使用这个宏的时候有分号,并且初始化该变量。
#else
#define VLIB_REGISTER_NODE(x,...) \
static __clib_unused vlib_node_registration_t __clib_unused_##x
#endifVPP定义的节点样例
我们以DPDK类型的输入节点来进行分析。
/* *INDENT-OFF* */
VLIB_REGISTER_NODE (dpdk_input_node) = {
.type = VLIB_NODE_TYPE_INPUT,
.name = "dpdk-input",
.sibling_of = "device-input",
/* Will be enabled if/when hardware is detected. */
.state = VLIB_NODE_STATE_DISABLED,
.format_buffer = format_ethernet_header_with_length,
.format_trace = format_dpdk_rx_trace,
.n_errors = DPDK_N_ERROR,
.error_strings = dpdk_error_strings,
};节点处理函数
节点处理函数宏
#define VLIB_NODE_FN(node) \
uword CLIB_MARCH_SFX (node##_fn)(); \
static vlib_node_fn_registration_t \
CLIB_MARCH_SFX(node##_fn_registration) = \
{ .function = &CLIB_MARCH_SFX (node##_fn), }; \
\
static void __clib_constructor \
CLIB_MARCH_SFX (node##_multiarch_register) (void) \
{ \
extern vlib_node_registration_t node; \ //这里引用了一个node节点,其名字为宏的输入参数,说明在定义节点和其处理函数的时候要求它们有一样的名字。
vlib_node_fn_registration_t *r; \
r = & CLIB_MARCH_SFX (node##_fn_registration); \
r->priority = CLIB_MARCH_FN_PRIORITY(); \//处理函数优先级,根据优先级选择最高优先级的处理函数
r->name = CLIB_MARCH_VARIANT_STR; \
r->next_registration = node.node_fn_registrations; \//将函数添加到其对应的节点链表中,从这里可以看出一个节点可以有多个处理函数,在函数register_node中会选择一个优先级最高的函数作为节点的最终处理函数。
node.node_fn_registrations = r; \
} \
uword CLIB_CPU_OPTIMIZED CLIB_MARCH_SFX (node##_fn)节点处理函数示例
我们以DPDK输入节点为例。
VLIB_NODE_FN (dpdk_input_node) (vlib_main_t * vm, vlib_node_runtime_t * node,
vlib_frame_t * f)
{
dpdk_main_t *dm = &dpdk_main;
dpdk_device_t *xd;
uword n_rx_packets = 0;
/* 获取输入节点的运行信息,其中的devices_and_queues包含了该线程在该输入节点需要处理的队列信息,动态增加该类设备时,会在修改其中的信息 */
vnet_device_input_runtime_t *rt = (void *) node->runtime_data;
vnet_device_and_queue_t *dq;/* */
u32 thread_index = node->thread_index;
/*
* Poll all devices on this cpu for input/interrupts.
*/
/* *INDENT-OFF* 遍历该线程接管的每一个设备的每一个队列 */
foreach_device_and_queue (dq, rt->devices_and_queues)
{
xd = vec_elt_at_index(dm->devices, dq->dev_instance);
if (PREDICT_FALSE (xd->flags & DPDK_DEVICE_FLAG_BOND_SLAVE))
continue; /* Do not poll slave to a bonded interface */
n_rx_packets += dpdk_device_input (vm, dm, xd, node, thread_index,
dq->queue_id);
}
/* *INDENT-ON* */
return n_rx_packets;
}运行数据
vlib_node_runtime_t
/* 运行时帧索引,这些帧根据节点类型进行分类的 */
typedef struct vlib_node_runtime_t
{
CLIB_CACHE_LINE_ALIGN_MARK (cacheline0); /**< cacheline mark */
/* 运行函数 */
vlib_node_function_t *function; /**< Node function to call. */
vlib_error_t *errors; /**< Vector of errors for this node. */
#if __SIZEOF_POINTER__ == 4
u8 pad[8];
#endif
u32 clocks_since_last_overflow; /**< Number of clock cycles. */
u32 max_clock; /**< Maximum clock cycle for an
invocation. */
u32 max_clock_n; /**< Number of vectors in the recorded
max_clock. */
u32 calls_since_last_overflow; /**< Number of calls. */
u32 vectors_since_last_overflow; /**< Number of vector elements
processed by this node. */
u32 perf_counter0_ticks_since_last_overflow; /**< Perf counter 0 ticks */
u32 perf_counter1_ticks_since_last_overflow; /**< Perf counter 1 ticks */
u32 perf_counter_vectors_since_last_overflow; /**< Perf counter vectors */
/* 起始的下一帧索引 */
u32 next_frame_index; /**< Start of next frames for this
node. */
/* 节点索引 */
u32 node_index; /**< Node index. */
u32 input_main_loops_per_call; /**< For input nodes: decremented
on each main loop interation until
it reaches zero and function is
called. Allows some input nodes to
be called more than others. */
u32 main_loop_count_last_dispatch; /**< Saved main loop counter of last
** dispatch of this node.
** 上一次进入该节点时,主循环调用次数
*/
u32 main_loop_vector_stats[2];/* 分组报文统计数组,两个元素交替统计 */
u16 flags; /**< Copy of main node flags. */
u16 state; /**< Input node state. */
/* 运行时下一个节点的个数 */
u16 n_next_nodes;/* 多少个下一个节点 */
/* 该节点上一次使用的下一个帧的索引编号,缓存的用于加速 */
u16 cached_next_index; /**< Next frame index that vector
arguments were last enqueued to
last time this node ran. Set to
zero before first run of this
node. */
/* 节点所属线程 */
u16 thread_index; /**< thread this node runs on */
u8 runtime_data[0]; /**< Function dependent
node-runtime data. This data is
thread local, and it is not
cloned from main thread. It needs
to be initialized for each thread
before it is used unless
runtime_data template exists in
vlib_node_t. */
} vlib_node_runtime_t; /* 运行时节点描述结构体 */vlib_next_frame_t
typedef struct
{
/* Frame index. */
/* 帧数据索引*/
u32 frame_index;
/* Node runtime for this next. */
/* 运行节点索引 */
u32 node_runtime_index;
/* Next frame flags. */
u32 flags;
/* Reflects node frame-used flag for this next. */
#define VLIB_FRAME_NO_FREE_AFTER_DISPATCH \
VLIB_NODE_FLAG_FRAME_NO_FREE_AFTER_DISPATCH
/* Don't append this frame */
#define VLIB_FRAME_NO_APPEND (1 << 14)
/* This next frame owns enqueue to node
corresponding to node_runtime_index. */
#define VLIB_FRAME_OWNER (1 << 15)
/* Set when frame has been allocated for this next. */
#define VLIB_FRAME_IS_ALLOCATED VLIB_NODE_FLAG_IS_OUTPUT
/* Set when frame has been added to pending vector. */
#define VLIB_FRAME_PENDING VLIB_NODE_FLAG_IS_DROP
/* Set when frame is to be freed after dispatch. */
#define VLIB_FRAME_FREE_AFTER_DISPATCH VLIB_NODE_FLAG_IS_PUNT
/* Set when frame has traced packets. */
#define VLIB_FRAME_TRACE VLIB_NODE_FLAG_TRACE
/* Number of vectors enqueue to this next since last overflow. */
u32 vectors_since_last_overflow;
} vlib_next_frame_t;vlib_pending_frame_t
/* A frame pending dispatch by main loop. */
typedef struct
{
/* Node and runtime for this frame. */
/* 可以通过该索引在帧数组中找到对应的vlib_node_runtime_t结构 */
u32 node_runtime_index;
/* Frame index (in the heap). */
u32 frame_index;
/* Start of next frames for this node. */
u32 next_frame_index;
/* Special value for next_frame_index when there is no next frame. */
#define VLIB_PENDING_FRAME_NO_NEXT_FRAME ((u32) ~0)
} vlib_pending_frame_t;vlib_frame_t
/* Max number of vector elements to process at once per node. */
#define VLIB_FRAME_SIZE 256
#define VLIB_FRAME_ALIGN CLIB_CACHE_LINE_BYTES
/* Calling frame (think stack frame) for a node.
* 一个节点的调用栈帧
*/
typedef struct vlib_frame_t
{
/* Frame flags. */
u16 frame_flags;
/* User flags. Used for sending hints to the next node. */
u16 flags;
/* 数组arguments中的标量字节数Number of scalar bytes in arguments. */
u8 scalar_size;
/* Number of bytes per vector argument. */
u8 vector_size;
/* Number of vector elements currently in frame. */
/* 在该帧中的向量元素的个数 */
u16 n_vectors;
/* Scalar and vector arguments to next node. */
u8 arguments[0];
} vlib_frame_t;在vlib_main_or_worker_loop函数运行前添加的节点编排过程
vpp节点有两种注册方式,第一种是采用上面的宏进行定义。这些宏带有__constructor__属性,都是在main函数自动执行的,形成相应的链表。还可以动态定义,然后进行加工。下面我们分析一下节点的加工过程。
vlib_main
vlib_main函数调用vlib_node_main_init函数进行node初始化。
/* Main function. */
int
vlib_main (vlib_main_t * volatile vm, unformat_input_t * input)
{
clib_error_t *volatile error;
vlib_node_main_t *nm = &vm->node_main;
......
/* Register static nodes so that init functions may use them. */
/* 注册所有静态节点 */
vlib_register_all_static_nodes (vm);
......
/* Initialize node graph. */
/* 初始化节点图 */
if ((error = vlib_node_main_init (vm)))
{
/* Arrange for graph hook up error to not be fatal when debugging. */
if (CLIB_DEBUG > 0)
clib_error_report (error);
else
goto done;
}
......
vlib_main_loop (vm);
......
}vlib_register_all_static_nodes
void
vlib_register_all_static_nodes (vlib_main_t * vm)
{
vlib_node_registration_t *r;
static char *null_node_error_strings[] =
{
"blackholed packets",
};
/* 定义一个null节点,作为第一个节点,其编号为0 */
static vlib_node_registration_t null_node_reg =
{
.function = null_node_fn,
.vector_size = sizeof (u32),
.name = "null-node",
.n_errors = 1,
.error_strings = null_node_error_strings,
};
/* make sure that node index 0 is not used by
real node */
register_node (vm, &null_node_reg);
/* 遍历所有的静态节点,进行注册 */
r = vm->node_main.node_registrations;
while (r)
{
register_node (vm, r);
r = r->next_registration;
}
}register_node
该函数分配一个vlib_node_t结构,用vlib_node_registration_t信息对其进行初始化,让后将其添加到vm->node_main->nodes指针数组中,其在数组中的下标为其节点索引n->index。
static void
register_node (vlib_main_t * vm, vlib_node_registration_t * r)
{
vlib_node_main_t *nm = &vm->node_main;
vlib_node_t *n;
u32 page_size = clib_mem_get_page_size ();
int i;
if (CLIB_DEBUG > 0)
{
/* Default (0) type should match INTERNAL. */
vlib_node_t zero = { 0 };
ASSERT (VLIB_NODE_TYPE_INTERNAL == zero.type);
}
/* 从节点的多个函数中选择一个最高的优先级的函数作为节点的最终处理函数 */
if (r->node_fn_registrations)
{
vlib_node_fn_registration_t *fnr = r->node_fn_registrations;
int priority = -1;
/* to avoid confusion, please remove ".function " statiement from
CLIB_NODE_REGISTRATION() if using function function candidates */
ASSERT (r->function == 0);
while (fnr)
{
if (fnr->priority > priority)
{
priority = fnr->priority;
r->function = fnr->function;
}
fnr = fnr->next_registration;
}
}
ASSERT (r->function != 0);
/* 分配节点内存 */
n = clib_mem_alloc_no_fail (sizeof (n[0]));
clib_memset (n, 0, sizeof (n[0]));
/* 设置索引 */
n->index = vec_len (nm->nodes);
n->node_fn_registrations = r->node_fn_registrations;
n->protocol_hint = r->protocol_hint;
/* 将节点地址添加到数组中 */
vec_add1 (nm->nodes, n);
/* Name is always a vector so it can be formatted with %v. */
if (clib_mem_is_heap_object (vec_header (r->name, 0)))
n->name = vec_dup ((u8 *) r->name);
else
n->name = format (0, "%s", r->name);
/* 构建节点名字与节点索引hash表 */
if (!nm->node_by_name)
nm->node_by_name = hash_create_vec ( /* size */ 32,
sizeof (n->name[0]), sizeof (uword));
/* Node names must be unique. */
{
vlib_node_t *o = vlib_get_node_by_name (vm, n->name);
if (o)
clib_error ("more than one node named `%v'", n->name);
}
hash_set (nm->node_by_name, n->name, n->index);
r->index = n->index; /* save index in registration */
n->function = r->function;
/* Node index of next sibling will be filled in by vlib_node_main_init. */
n->sibling_of = r->sibling_of;
if (r->sibling_of && r->n_next_nodes > 0)
clib_error ("sibling node should not have any next nodes `%v'", n->name);
if (r->type == VLIB_NODE_TYPE_INTERNAL)
ASSERT (r->vector_size > 0);
#define _(f) n->f = r->f
_(type);
_(flags);
_(state);
_(scalar_size);
_(vector_size);
_(format_buffer);
_(unformat_buffer);
_(format_trace);
_(validate_frame);
/* Register error counters. */
vlib_register_errors (vm, n->index, r->n_errors, r->error_strings);
node_elog_init (vm, n->index);
_(runtime_data_bytes);
if (r->runtime_data_bytes > 0)
{
vec_resize (n->runtime_data, r->runtime_data_bytes);
if (r->runtime_data)
clib_memcpy (n->runtime_data, r->runtime_data, r->runtime_data_bytes);
}
/* 初始化节点的下一跳数组 */
vec_resize (n->next_node_names, r->n_next_nodes);
for (i = 0; i < r->n_next_nodes; i++)
n->next_node_names[i] = r->next_nodes[i];
vec_validate_init_empty (n->next_nodes, r->n_next_nodes - 1, ~0);
vec_validate (n->n_vectors_by_next_node, r->n_next_nodes - 1);
n->owner_node_index = n->owner_next_index = ~0;
/* Initialize node runtime. */
/* 初始化节点运行数据,主要是对节点按类型进行分类 */
{
vlib_node_runtime_t *rt;
u32 i;
if (n->type == VLIB_NODE_TYPE_PROCESS)
{
vlib_process_t *p;
uword log2_n_stack_bytes;
log2_n_stack_bytes = clib_max (r->process_log2_n_stack_bytes, 15);
#ifdef CLIB_UNIX
/*
* Bump the stack size if running over a kernel with a large page size,
* and the stack isn't any too big to begin with. Otherwise, we'll
* trip over the stack guard page for sure.
*/
if ((page_size > (4 << 10)) && log2_n_stack_bytes < 19)
{
if ((1 << log2_n_stack_bytes) <= page_size)
log2_n_stack_bytes = min_log2 (page_size) + 1;
else
log2_n_stack_bytes++;
}
#endif
p = clib_mem_alloc_aligned_at_offset
(sizeof (p[0]) + (1 << log2_n_stack_bytes),
STACK_ALIGN, STRUCT_OFFSET_OF (vlib_process_t, stack),
0 /* no, don't call os_out_of_memory */ );
if (p == 0)
clib_panic ("failed to allocate process stack (%d bytes)",
1 << log2_n_stack_bytes);
clib_memset (p, 0, sizeof (p[0]));
p->log2_n_stack_bytes = log2_n_stack_bytes;
/* Process node's runtime index is really index into process
pointer vector. */
n->runtime_index = vec_len (nm->processes);
vec_add1 (nm->processes, p);
/* Paint first stack word with magic number so we can at least
detect process stack overruns. */
p->stack[0] = VLIB_PROCESS_STACK_MAGIC;
/* Node runtime is stored inside of process. */
rt = &p->node_runtime;
#ifdef CLIB_UNIX
/*
* Disallow writes to the bottom page of the stack, to
* catch stack overflows.
*/
if (mprotect (p->stack, page_size, PROT_READ) < 0)
clib_unix_warning ("process stack");
#endif
}
else
{
/* 根据类型进行分类 */
vec_add2_aligned (nm->nodes_by_type[n->type], rt, 1,
/* align */ CLIB_CACHE_LINE_BYTES);
n->runtime_index = rt - nm->nodes_by_type[n->type];
}
/* 统计输入节点状态个数 */
if (n->type == VLIB_NODE_TYPE_INPUT)
nm->input_node_counts_by_state[n->state] += 1;
rt->function = n->function;
rt->flags = n->flags;
rt->state = n->state;
rt->node_index = n->index;
rt->n_next_nodes = r->n_next_nodes;
rt->next_frame_index = vec_len (nm->next_frames);
/* 为该节点在nm->next_frames中申请一块rt->n_next_nodes元素的内存
* 该内存用于存储该节点运行的下一帧
*/
vec_resize (nm->next_frames, rt->n_next_nodes);
for (i = 0; i < rt->n_next_nodes; i++)
vlib_next_frame_init (nm->next_frames + rt->next_frame_index + i);
vec_resize (rt->errors, r->n_errors);
for (i = 0; i < vec_len (rt->errors); i++)
rt->errors[i] = vlib_error_set (n->index, i);
STATIC_ASSERT_SIZEOF (vlib_node_runtime_t, 128);
ASSERT (vec_len (n->runtime_data) <= VLIB_NODE_RUNTIME_DATA_SIZE);
if (vec_len (n->runtime_data) > 0)
clib_memcpy (rt->runtime_data, n->runtime_data,
vec_len (n->runtime_data));
vec_free (n->runtime_data);
}
}vlib_node_main_init
clib_error_t *
vlib_node_main_init (vlib_main_t * vm)
{
vlib_node_main_t *nm = &vm->node_main;
clib_error_t *error = 0;
vlib_node_t *n;
uword ni;
/* 创建frame内存分配器 */
nm->frame_sizes = vec_new (vlib_frame_size_t, 1);
#ifdef VLIB_SUPPORTS_ARBITRARY_SCALAR_SIZES
nm->frame_size_hash = hash_create (0, sizeof (uword));
#endif
/* 设置已经初始化标志 */
nm->flags |= VLIB_NODE_MAIN_RUNTIME_STARTED;
/* Generate sibling relationships */
/* 处理所有节点的兄弟关系,比如不同类型的输入节点大多是兄弟节点,他们会指向相同的
* 下一跳节点。比如dpdk-input节点与af-packet-input几点就是互为兄弟节点。兄弟的兄弟
* 也是我兄弟
*/
{
vlib_node_t *n, *sib;
uword si;
/* 遍历每一个节点 */
for (ni = 0; ni < vec_len (nm->nodes); ni++)
{
n = vec_elt (nm->nodes, ni);
if (!n->sibling_of)
continue;
/* 获取兄弟名字 */
sib = vlib_get_node_by_name (vm, (u8 *) n->sibling_of);
if (!sib)
{
error = clib_error_create ("sibling `%s' not found for node `%v'",
n->sibling_of, n->name);
goto done;
}
/* *INDENT-OFF* */
/* 遍历兄弟节点的每一个兄弟掩码,它的兄弟都是我的兄弟 */
clib_bitmap_foreach (si, sib->sibling_bitmap, (
{
/* 获取兄弟的兄弟节点 */
vlib_node_t * m = vec_elt (nm->nodes, si);
/* Connect all of sibling's siblings to us. */
/* 加本节点加入到兄弟的兄的的兄弟掩码图中 */
m->sibling_bitmap = clib_bitmap_ori (m->sibling_bitmap, n->index);
/* Connect us to all of sibling's siblings. */
/* 将兄弟的兄弟加入到自己的掩码图中 */
n->sibling_bitmap = clib_bitmap_ori (n->sibling_bitmap, si);
}));
/* *INDENT-ON* */
/* Connect sibling to us. */
sib->sibling_bitmap = clib_bitmap_ori (sib->sibling_bitmap, n->index);
/* Connect us to sibling. */
/* 将兄弟设置到自己的掩码图中 */
n->sibling_bitmap = clib_bitmap_ori (n->sibling_bitmap, sib->index);
}
}
/* Resolve next names into next indices. */
/* 根据下一跳名字数组构建下一跳掩码数组 */
for (ni = 0; ni < vec_len (nm->nodes); ni++)
{
uword i;
n = vec_elt (nm->nodes, ni);
for (i = 0; i < vec_len (n->next_node_names); i++)
{
char *a = n->next_node_names[i];
if (!a)
continue;
/* 构建下一跳索引数组 */
if (~0 == vlib_node_add_named_next_with_slot (vm, n->index, a, i))
{
error = clib_error_create
("node `%v' refers to unknown node `%s'", n->name, a);
goto done;
}
}
vec_free (n->next_node_names);
}
/* Set previous node pointers. */
/* 将下一跳节点指向自己,即构建前驱关系 */
for (ni = 0; ni < vec_len (nm->nodes); ni++)
{
vlib_node_t *n_next;
uword i;
n = vec_elt (nm->nodes, ni);
for (i = 0; i < vec_len (n->next_nodes); i++)
{
if (n->next_nodes[i] >= vec_len (nm->nodes))
continue;
n_next = vec_elt (nm->nodes, n->next_nodes[i]);
n_next->prev_node_bitmap =
clib_bitmap_ori (n_next->prev_node_bitmap, n->index);
}
}
/* 初始化每一个内部节点,构建起下一跳节点的运行信息 */
{
vlib_next_frame_t *nf;
vlib_node_runtime_t *r;
vlib_node_t *next;
uword i;
vec_foreach (r, nm->nodes_by_type[VLIB_NODE_TYPE_INTERNAL])
{
if (r->n_next_nodes == 0)
continue;
n = vlib_get_node (vm, r->node_index);
/* 根据运行索引获取其在next_frames的起始地址 */
nf = vec_elt_at_index (nm->next_frames, r->next_frame_index);
/* 遍历每一个下一跳 */
for (i = 0; i < vec_len (n->next_nodes); i++)
{
next = vlib_get_node (vm, n->next_nodes[i]);
/* Validate node runtime indices are correctly initialized. */
ASSERT (nf[i].node_runtime_index == next->runtime_index);
nf[i].flags = 0;
if (next->flags & VLIB_NODE_FLAG_FRAME_NO_FREE_AFTER_DISPATCH)
nf[i].flags |= VLIB_FRAME_NO_FREE_AFTER_DISPATCH;
}
}
}
done:
return error;
}vlib_node_add_named_next_with_slot
/* Add named next node to given node in given slot. */
/* 添加一个命名的下一跳到节点node指定的slot中,如果slot没有指定,
* 则分配。
*/
uword
vlib_node_add_named_next_with_slot (vlib_main_t * vm,
uword node, char *name, uword slot)
{
vlib_node_main_t *nm;
vlib_node_t *n, *n_next;
nm = &vm->node_main;
n = vlib_get_node (vm, node);
n_next = vlib_get_node_by_name (vm, (u8 *) name);
if (!n_next)
{
if (nm->flags & VLIB_NODE_MAIN_RUNTIME_STARTED)
return ~0;
if (slot == ~0)
slot = clib_max (vec_len (n->next_node_names),
vec_len (n->next_nodes));
vec_validate (n->next_node_names, slot);
n->next_node_names[slot] = name;
return slot;
}
return vlib_node_add_next_with_slot (vm, node, n_next->index, slot);
}vlib_node_add_next_with_slot
/* Add next node to given node in given slot. */
uword
vlib_node_add_next_with_slot (vlib_main_t * vm,
uword node_index,
uword next_node_index, uword slot)
{
vlib_node_main_t *nm = &vm->node_main;
vlib_node_t *node, *next;
uword *p;
node = vec_elt (nm->nodes, node_index);
next = vec_elt (nm->nodes, next_node_index);
/* Runtime has to be initialized. */
ASSERT (nm->flags & VLIB_NODE_MAIN_RUNTIME_STARTED);
/* 根据下一跳节点索引快速判断该节点是否在本节点的下一跳数组中 */
if ((p = hash_get (node->next_slot_by_node, next_node_index)))
{
/* Next already exists: slot must match. */
/* 已经存在,返回该slot */
if (slot != ~0)
ASSERT (slot == p[0]);
return p[0];
}
/* 不存在的话,将下一个可用位置分给该next_node_index节点 */
if (slot == ~0)
slot = vec_len (node->next_nodes);
vec_validate_init_empty (node->next_nodes, slot, ~0);
vec_validate (node->n_vectors_by_next_node, slot);
/* 添加一个下一跳索引 */
node->next_nodes[slot] = next_node_index;
hash_set (node->next_slot_by_node, next_node_index, slot);
/* 构建运行信息 */
vlib_node_runtime_update (vm, node_index, slot);
/* 建立反向关系,设置next_node_index节点的位数组prev_node_bitmap中node_index为1 */
next->prev_node_bitmap = clib_bitmap_ori (next->prev_node_bitmap,
node_index);
/* Siblings all get same node structure. */
/* 处理本节点的兄弟节点,兄弟节点都指向该next_node_index节点
* 存在深度的递归调用该函数。最差情况下,一个兄弟节点递归一次。
*/
{
uword sib_node_index, sib_slot;
vlib_node_t *sib_node;
/* *INDENT-OFF* */
clib_bitmap_foreach (sib_node_index, node->sibling_bitmap, (
{
sib_node = vec_elt (nm->nodes, sib_node_index);
if (sib_node != node)
{
sib_slot = vlib_node_add_next_with_slot (vm, sib_node_index, next_node_index, slot);
ASSERT (sib_slot == slot);
}
}));
/* *INDENT-ON* */
}
return slot;
}
vlib_node_runtime_updatevlib_node_runtime_update
/* 增加了节点,需要更新运行时数据,next_index不是节点索引,而是槽位号slot */
static void
vlib_node_runtime_update (vlib_main_t * vm, u32 node_index, u32 next_index)
{
vlib_node_main_t *nm = &vm->node_main;
vlib_node_runtime_t *r, *s;
vlib_node_t *node, *next_node;
vlib_next_frame_t *nf;
vlib_pending_frame_t *pf;
i32 i, j, n_insert;
ASSERT (vlib_get_thread_index () == 0);
/* 开启sync过程 */
vlib_worker_thread_barrier_sync (vm);
node = vec_elt (nm->nodes, node_index);
r = vlib_node_get_runtime (vm, node_index);
/* 新增多少个下一跳节点 */
n_insert = vec_len (node->next_nodes) - r->n_next_nodes;
if (n_insert > 0)
{
i = r->next_frame_index + r->n_next_nodes;
/* 在数组中间插入n_insert个节点 */
vec_insert (nm->next_frames, n_insert, i);
/* Initialize newly inserted next frames. */
for (j = 0; j < n_insert; j++)
vlib_next_frame_init (nm->next_frames + i + j);
/* Relocate other next frames at higher indices. */
for (j = 0; j < vec_len (nm->nodes); j++)
{
s = vlib_node_get_runtime (vm, j);
if (j != node_index && s->next_frame_index >= i)
s->next_frame_index += n_insert;
}
/* Pending frames may need to be relocated also. */
/* 修改正在运行的帧的索引 */
vec_foreach (pf, nm->pending_frames)
{
if (pf->next_frame_index != VLIB_PENDING_FRAME_NO_NEXT_FRAME
&& pf->next_frame_index >= i)
pf->next_frame_index += n_insert;
}
/* *INDENT-OFF* */
pool_foreach (pf, nm->suspended_process_frames, (
{
if (pf->next_frame_index != ~0 && pf->next_frame_index >= i)
pf->next_frame_index += n_insert;
}));
/* *INDENT-ON* */
r->n_next_nodes = vec_len (node->next_nodes);
}
/* Set frame's node runtime index. */
/* 设置节点的运行时索引,next_index是槽位号,不是索引 */
next_node = vlib_get_node (vm, node->next_nodes[next_index]);
nf = nm->next_frames + r->next_frame_index + next_index;
nf->node_runtime_index = next_node->runtime_index;
vlib_worker_thread_node_runtime_update ();
vlib_worker_thread_barrier_release (vm);
}在vlib_main_or_worker_loop函数运行后添加节点
除了使用node注册宏进行节点的注册外,还可以使用如下函数按需注册,注册一个新的VLIB_NODE_TYPE_INTERNAL节点后需要调用vlib_worker_thread_node_runtime_update或者vlib_node_add_next_with_slot开启一轮新的节点编排工作,所有的线程都要进行。注册VLIB_NODE_TYPE_PROCESS节点后,需要调用vlib_start_process函数启动协程。
vlib_register_node
/* Register new packet processing node. */
/* 动态注册一个新的节点 */
u32
vlib_register_node (vlib_main_t * vm, vlib_node_registration_t * r)
{
register_node (vm, r);
return r->index;
}vlib_node_add_next_with_slot
该函数会更新node graph以及runtime 信息,还会通知其它线程进行sync同步来完成消息的变更。
/* Add next node to given node in given slot. */
uword
vlib_node_add_next_with_slot (vlib_main_t * vm,
uword node_index,
uword next_node_index, uword slot)
{
vlib_node_main_t *nm = &vm->node_main;
vlib_node_t *node, *next;
uword *p;
node = vec_elt (nm->nodes, node_index);
next = vec_elt (nm->nodes, next_node_index);
/* Runtime has to be initialized. */
ASSERT (nm->flags & VLIB_NODE_MAIN_RUNTIME_STARTED);
/* 根据下一跳节点索引快速判断该节点是否在本节点的下一跳数组中 */
if ((p = hash_get (node->next_slot_by_node, next_node_index)))
{
/* Next already exists: slot must match. */
/* 已经存在,返回该slot */
if (slot != ~0)
ASSERT (slot == p[0]);
return p[0];
}
/* 不存在的话,将下一个可用位置分给该next_node_index节点 */
if (slot == ~0)
slot = vec_len (node->next_nodes);
vec_validate_init_empty (node->next_nodes, slot, ~0);
vec_validate (node->n_vectors_by_next_node, slot);
/* 添加一个下一跳索引 */
node->next_nodes[slot] = next_node_index;
hash_set (node->next_slot_by_node, next_node_index, slot);
/* 通知其它线程开始进行运行状态重建 */
vlib_node_runtime_update (vm, node_index, slot);
/* 建立反向关系,设置next_node_index节点的位数组prev_node_bitmap中node_index为1 */
next->prev_node_bitmap = clib_bitmap_ori (next->prev_node_bitmap,
node_index);
/* Siblings all get same node structure. */
/* 处理本节点的兄弟节点,兄弟节点都指向该next_node_index节点
* 存在深度的递归调用该函数。最差情况下,一个兄弟节点递归一次。
*/
{
uword sib_node_index, sib_slot;
vlib_node_t *sib_node;
/* *INDENT-OFF* */
clib_bitmap_foreach (sib_node_index, node->sibling_bitmap, (
{
sib_node = vec_elt (nm->nodes, sib_node_index);
if (sib_node != node)
{
sib_slot = vlib_node_add_next_with_slot (vm, sib_node_index, next_node_index, slot);
ASSERT (sib_slot == slot);
}
}));
/* *INDENT-ON* */
}
return slot;
}vlib_node_runtime_update
/* 增加了节点,需要更新运行时数据,next_index不是节点索引,而是槽位号slot */
static void
vlib_node_runtime_update (vlib_main_t * vm, u32 node_index, u32 next_index)
{
vlib_node_main_t *nm = &vm->node_main;
vlib_node_runtime_t *r, *s;
vlib_node_t *node, *next_node;
vlib_next_frame_t *nf;
vlib_pending_frame_t *pf;
i32 i, j, n_insert;
ASSERT (vlib_get_thread_index () == 0);
/* 开启sync过程 */
vlib_worker_thread_barrier_sync (vm);
node = vec_elt (nm->nodes, node_index);
r = vlib_node_get_runtime (vm, node_index);
/* 新增多少个下一跳节点 */
n_insert = vec_len (node->next_nodes) - r->n_next_nodes;
if (n_insert > 0)
{
i = r->next_frame_index + r->n_next_nodes;
/* 在数组中间插入n_insert个节点 */
vec_insert (nm->next_frames, n_insert, i);
/* Initialize newly inserted next frames. */
for (j = 0; j < n_insert; j++)
vlib_next_frame_init (nm->next_frames + i + j);
/* Relocate other next frames at higher indices. */
for (j = 0; j < vec_len (nm->nodes); j++)
{
s = vlib_node_get_runtime (vm, j);
if (j != node_index && s->next_frame_index >= i)
s->next_frame_index += n_insert;
}
/* Pending frames may need to be relocated also. */
/* 修改正在运行的帧的索引 */
vec_foreach (pf, nm->pending_frames)
{
if (pf->next_frame_index != VLIB_PENDING_FRAME_NO_NEXT_FRAME
&& pf->next_frame_index >= i)
pf->next_frame_index += n_insert;
}
/* *INDENT-OFF* */
pool_foreach (pf, nm->suspended_process_frames, (
{
if (pf->next_frame_index != ~0 && pf->next_frame_index >= i)
pf->next_frame_index += n_insert;
}));
/* *INDENT-ON* */
r->n_next_nodes = vec_len (node->next_nodes);
}
/* Set frame's node runtime index. */
/* 设置节点的运行时索引,next_index是槽位号,不是索引 */
next_node = vlib_get_node (vm, node->next_nodes[next_index]);
nf = nm->next_frames + r->next_frame_index + next_index;
nf->node_runtime_index = next_node->runtime_index;
vlib_worker_thread_node_runtime_update ();
vlib_worker_thread_barrier_release (vm);
}vlib_worker_thread_node_runtime_update
/* 当有新的节点添加时,需要通知worker线程进行重建运行环境 */
void
vlib_worker_thread_node_runtime_update (void)
{
/*
* Make a note that we need to do a node runtime update
* prior to releasing the barrier.
*/
vlib_global_main.need_vlib_worker_thread_node_runtime_update = 1;
}sync过程中处理节点信息变化同步
node信息发生变化后,main线程会通知其它线程进入sync状态,need_vlib_worker_thread_node_runtime_update标志被设置后,会进行runtime信息重建。
vlib_worker_thread_barrier_release
/* sync过程结束函数*/
void
vlib_worker_thread_barrier_release (vlib_main_t * vm)
{
f64 deadline;
f64 now;
f64 minimum_open;
f64 t_entry;
f64 t_closed_total;
f64 t_update_main = 0.0;
int refork_needed = 0;
if (vec_len (vlib_mains) < 2)
return;
ASSERT (vlib_get_thread_index () == 0);
now = vlib_time_now (vm);
/* 一对sync与release调用时间段 */
t_entry = now - vm->barrier_epoch;
/* 减少递归深度,如果大于0表示sync还没结束 */
if (--vlib_worker_threads[0].recursion_level > 0)
{
barrier_trace_release_rec (t_entry);
return;
}
/* Update (all) node runtimes before releasing the barrier, if needed */
/* 设置了运行数据统计收集标志,将worker线程的运行信息同步到main线程中,同时通知worker线程进行重建 */
if (vm->need_vlib_worker_thread_node_runtime_update)
{
/*
* Lock stat segment here, so we's safe when
* rebuilding the stat segment node clones from the
* stat thread...
*/
vlib_stat_segment_lock ();
/* Do stats elements on main thread */
/* 在mian线程中进行统计信息同步 */
worker_thread_node_runtime_update_internal ();
vm->need_vlib_worker_thread_node_runtime_update = 0;
/* Do per thread rebuilds in parallel */
refork_needed = 1;
/* 设置vlib_worker_threads->node_reforks_required通知 worker线程进行runtime信息重建 */
clib_atomic_fetch_add (vlib_worker_threads->node_reforks_required,
(vec_len (vlib_mains) - 1));
now = vlib_time_now (vm);
t_update_main = now - vm->barrier_epoch;
}
......
/* Wait for reforks before continuing */
/* 等待worker线程重建 */
if (refork_needed)
{
now = vlib_time_now (vm);
deadline = now + BARRIER_SYNC_TIMEOUT;
while (*vlib_worker_threads->node_reforks_required > 0)
{
if ((now = vlib_time_now (vm)) > deadline)
{
fformat (stderr, "%s: worker thread refork deadlock\n",
__FUNCTION__);
os_panic ();
}
}
vlib_stat_segment_unlock ();
}
......
}vlib_worker_thread_barrier_check
worker线程调用函数在sync期间进行runtime信息重建。
static inline void
vlib_worker_thread_barrier_check (void)
{
/* 如果main线程已经启动了sync过程,则本线程需要进入sync状态 */
if (PREDICT_FALSE (*vlib_worker_threads->wait_at_barrier))
{
......
if (PREDICT_FALSE (*vlib_worker_threads->node_reforks_required))
{
......
/* 进行本线程runtime信息重建 */
vlib_worker_thread_node_refork ();
clib_atomic_fetch_add (vlib_worker_threads->node_reforks_required,-1);
while (*vlib_worker_threads->node_reforks_required);
}
......
}
}vlib_worker_thread_node_refork
/* 重建所有的worker线程运行信息 */
void
vlib_worker_thread_node_refork (void)
{
vlib_main_t *vm, *vm_clone;
vlib_node_main_t *nm, *nm_clone;
vlib_node_t **old_nodes_clone;
vlib_node_runtime_t *rt, *old_rt;
vlib_node_t *new_n_clone;
int j;
vm = vlib_mains[0];
nm = &vm->node_main;
vm_clone = vlib_get_main ();
nm_clone = &vm_clone->node_main;
/* Re-clone error heap */
u64 *old_counters = vm_clone->error_main.counters;
u64 *old_counters_all_clear = vm_clone->error_main.counters_last_clear;
clib_memcpy_fast (&vm_clone->error_main, &vm->error_main,
sizeof (vm->error_main));
j = vec_len (vm->error_main.counters) - 1;
vec_validate_aligned (old_counters, j, CLIB_CACHE_LINE_BYTES);
vec_validate_aligned (old_counters_all_clear, j, CLIB_CACHE_LINE_BYTES);
vm_clone->error_main.counters = old_counters;
vm_clone->error_main.counters_last_clear = old_counters_all_clear;
nm_clone = &vm_clone->node_main;
/* 删除所有等待运行的帧,重建,一般来说,该向量为空,因为只有处理完所有的帧之后才会进入临界区 */
vec_free (nm_clone->next_frames);
nm_clone->next_frames = vec_dup_aligned (nm->next_frames,
CLIB_CACHE_LINE_BYTES);
for (j = 0; j < vec_len (nm_clone->next_frames); j++)
{
vlib_next_frame_t *nf = &nm_clone->next_frames[j];
u32 save_node_runtime_index;
u32 save_flags;
save_node_runtime_index = nf->node_runtime_index;
save_flags = nf->flags & VLIB_FRAME_NO_FREE_AFTER_DISPATCH;
vlib_next_frame_init (nf);
nf->node_runtime_index = save_node_runtime_index;
nf->flags = save_flags;
}
old_nodes_clone = nm_clone->nodes;
nm_clone->nodes = 0;
/* re-fork nodes */
/* Allocate all nodes in single block for speed */
new_n_clone =
clib_mem_alloc_no_fail (vec_len (nm->nodes) * sizeof (*new_n_clone));
for (j = 0; j < vec_len (nm->nodes); j++)
{
vlib_node_t *old_n_clone;
vlib_node_t *new_n;
new_n = nm->nodes[j];
old_n_clone = old_nodes_clone[j];
clib_memcpy_fast (new_n_clone, new_n, sizeof (*new_n));
/* none of the copied nodes have enqueue rights given out */
new_n_clone->owner_node_index = VLIB_INVALID_NODE_INDEX;
if (j >= vec_len (old_nodes_clone))
{
/* new node, set to zero */
clib_memset (&new_n_clone->stats_total, 0,
sizeof (new_n_clone->stats_total));
clib_memset (&new_n_clone->stats_last_clear, 0,
sizeof (new_n_clone->stats_last_clear));
}
else
{
/* Copy stats if the old data is valid */
clib_memcpy_fast (&new_n_clone->stats_total,
&old_n_clone->stats_total,
sizeof (new_n_clone->stats_total));
clib_memcpy_fast (&new_n_clone->stats_last_clear,
&old_n_clone->stats_last_clear,
sizeof (new_n_clone->stats_last_clear));
/* keep previous node state */
new_n_clone->state = old_n_clone->state;
}
vec_add1 (nm_clone->nodes, new_n_clone);
new_n_clone++;
}
/* Free the old node clones */
clib_mem_free (old_nodes_clone[0]);
vec_free (old_nodes_clone);
/* re-clone internal nodes */
old_rt = nm_clone->nodes_by_type[VLIB_NODE_TYPE_INTERNAL];
nm_clone->nodes_by_type[VLIB_NODE_TYPE_INTERNAL] =
vec_dup_aligned (nm->nodes_by_type[VLIB_NODE_TYPE_INTERNAL],
CLIB_CACHE_LINE_BYTES);
vec_foreach (rt, nm_clone->nodes_by_type[VLIB_NODE_TYPE_INTERNAL])
{
vlib_node_t *n = vlib_get_node (vm, rt->node_index);
rt->thread_index = vm_clone->thread_index;
/* copy runtime_data, will be overwritten later for existing rt */
if (n->runtime_data && n->runtime_data_bytes > 0)
clib_memcpy_fast (rt->runtime_data, n->runtime_data,
clib_min (VLIB_NODE_RUNTIME_DATA_SIZE,
n->runtime_data_bytes));
}
for (j = 0; j < vec_len (old_rt); j++)
{
rt = vlib_node_get_runtime (vm_clone, old_rt[j].node_index);
rt->state = old_rt[j].state;
clib_memcpy_fast (rt->runtime_data, old_rt[j].runtime_data,
VLIB_NODE_RUNTIME_DATA_SIZE);
}
vec_free (old_rt);
/* re-clone input nodes */
old_rt = nm_clone->nodes_by_type[VLIB_NODE_TYPE_INPUT];
nm_clone->nodes_by_type[VLIB_NODE_TYPE_INPUT] =
vec_dup_aligned (nm->nodes_by_type[VLIB_NODE_TYPE_INPUT],
CLIB_CACHE_LINE_BYTES);
vec_foreach (rt, nm_clone->nodes_by_type[VLIB_NODE_TYPE_INPUT])
{
vlib_node_t *n = vlib_get_node (vm, rt->node_index);
rt->thread_index = vm_clone->thread_index;
/* copy runtime_data, will be overwritten later for existing rt */
if (n->runtime_data && n->runtime_data_bytes > 0)
clib_memcpy_fast (rt->runtime_data, n->runtime_data,
clib_min (VLIB_NODE_RUNTIME_DATA_SIZE,
n->runtime_data_bytes));
}
for (j = 0; j < vec_len (old_rt); j++)
{
rt = vlib_node_get_runtime (vm_clone, old_rt[j].node_index);
rt->state = old_rt[j].state;
clib_memcpy_fast (rt->runtime_data, old_rt[j].runtime_data,
VLIB_NODE_RUNTIME_DATA_SIZE);
}
vec_free (old_rt);
/* re-clone pre-input nodes */
old_rt = nm_clone->nodes_by_type[VLIB_NODE_TYPE_PRE_INPUT];
nm_clone->nodes_by_type[VLIB_NODE_TYPE_PRE_INPUT] =
vec_dup_aligned (nm->nodes_by_type[VLIB_NODE_TYPE_PRE_INPUT],
CLIB_CACHE_LINE_BYTES);
vec_foreach (rt, nm_clone->nodes_by_type[VLIB_NODE_TYPE_PRE_INPUT])
{
vlib_node_t *n = vlib_get_node (vm, rt->node_index);
rt->thread_index = vm_clone->thread_index;
/* copy runtime_data, will be overwritten later for existing rt */
if (n->runtime_data && n->runtime_data_bytes > 0)
clib_memcpy_fast (rt->runtime_data, n->runtime_data,
clib_min (VLIB_NODE_RUNTIME_DATA_SIZE,
n->runtime_data_bytes));
}
for (j = 0; j < vec_len (old_rt); j++)
{
rt = vlib_node_get_runtime (vm_clone, old_rt[j].node_index);
rt->state = old_rt[j].state;
clib_memcpy_fast (rt->runtime_data, old_rt[j].runtime_data,
VLIB_NODE_RUNTIME_DATA_SIZE);
}
vec_free (old_rt);
nm_clone->processes = vec_dup_aligned (nm->processes,
CLIB_CACHE_LINE_BYTES);
}