C语言深度解剖
C语言深度解剖
1. 关键字
标准C语言,c89 中共有32个关键字,c99 又新增了5个。
1.1 auto
auto 一般用来修饰局部变量,被 auto 修饰的局部变量可以自动开辟自动释放,但局部变量本身就是自动开辟和释放的,所以 auto 没什么用。
auto 只能修饰局部变量,不能修饰全局变量。
1.2 register
建议编译器将 register 修饰的变量放到寄存器中。一般高频被读取的、很少被写入的、局部的变量可以被放到寄存器中。
因为放在寄存器,不是在内存中,所以无法取地址。
1.3 extern
定义与声明的区别?
定义变量的本质就是开辟一块空间,以供变量使用。声明是告知编译器存在这样的一个变量。
定义只有一次,而声明可以有多次。
//test.c
int g_val = 1;
//main.c
extern int g_val; // 正确
extern int g_val = 1; // 错误
- extern 声明变量时不能加上赋值或初始化操作。编译器认为是在定义变量,就发生变量重定义。
- 函数可以不 extern 声明,变量一定要声明。
1.4 static
全局变量和函数都是可以跨文件访问的。
- static 修饰全局变量或函数,则该变量或函数只能在本文件内被访问,不能跨文件访问。
- static 限制全局变量或函数只能在本文件中访问,限制了其的作用域,也变相的提供安全保证。
static 修饰局部变量,是另一种作用,不要和上面混淆。
- static 修饰的局部变量只在入作用域时被定义和初始化一次,出作用域不会被销毁。
- 但出作用域不能被访问,作用域不变,只是生命周期变成全局。
- 变量从栈中移到了全局数据区。
1.5 sizeof 及类型关键字
sizeof 是关键字而不是函数,()只是习惯用法。
类型的意义在于对内存使用进行合理的划分,使用场景决定了使用变量的类型,因此存在多种类型。
1.6 signed/unsigned
有符号数和无符号数都是整数,浮点数没有这样的概念。
- 有符号数取二进制序列的最高位为符号位,其他位为数据位。符号为为0表示整数,为1表示负数。
- 无符号数的二进制序列所有位都是数据位。
原反补
整数的有三种二进制序列,分别是原码、反码、补码。正数的原反补码相同,负数的原反补码有如下运算逻辑:
原码 → 符号位不变,其他位安位取反 → 反码 反码 → 加一 (符号位参与运算) → 补码 原码 \rightarrow 符号位不变,其他位安位取反 \rightarrow 反码 \\ 反码 \rightarrow\; 加一 \quad(符号位参与运算) \rightarrow \; 补码 \\ 原码→符号位不变,其他位安位取反→反码反码→加一(符号位参与运算)→补码
原码转补码是取反加一,补码转原码可以是减一取反、也可以是取反加一。
数据的存取
unsigned int ui = -10;
数据-10的类型是signed int,变量赋值就是将内存中的数据拷贝到变量的内存空间,对于整数来说,内存中存储的是补码。
因此,上述赋值操作就是将-10的补码覆盖到变量ui所在的4字节空间中,这4字节空间中存储的二进制序列是:
11111111 11111111 11111111 11110110
又因为ui的类型是unsigned int,故ui默认认为这4字节数据是无符号数,故ui就是一个非常大的数字。
大小端
- 数据按字节为单位,高权值放在高地址处,低权值放在低地址处,就是小端存储。
- 低权值放在高地址处,高权值放在低地址处,就是大端存储。
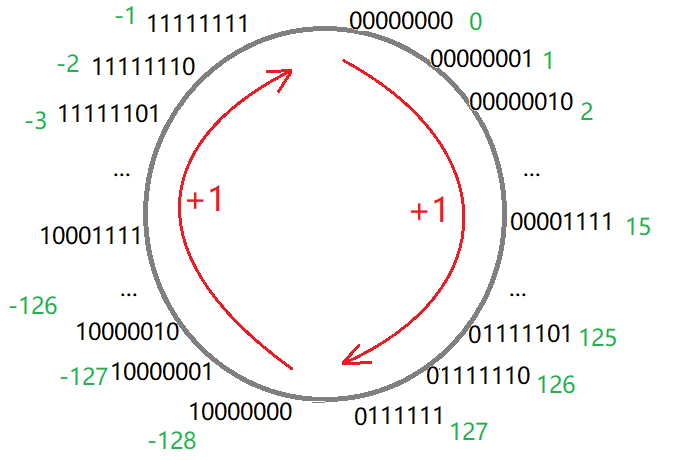
有符号数的最小值
signed char 类型的最小值是 –128,对应的二进制序列是 1000 0000 1000\;0000 10000000 。
1000 0000 原码
1111 1111 反码
1 1000 0000 补码
–128 的补码存入 signed char 8bits 的空间会发生截断,可见 –128 的补码也是 1000 0000 1000\;0000 10000000。
1000 0000 补码
0111 1111 反码
0000 0000 原码
由于发生过截断,取出的时候,补码 1000 0000 1000\;0000 10000000 无法再正确转化回原码。
所以,类似 –128 这样,有符号数的最小值的原反补转化,是“半计算半规定”的过程。
故计算机规定,有符号数的补码,符号位为1、数据位为0,就认为其是有符号数的最小值。
有符号数的范围
1.7 _Bool
c99 之前没有布尔类型,c99 新增了一个关键字 _Bool ,被宏定义成一个宏 bool 。类型的大小是 1 1 1 字节。
浮点数本身存在精度丢失,所以不可以用== !=来比较相等,只能判断将两者相减的结果是否小于一定误差。
fabs(x - y) < DBL_EPSILON; // double 精度误差
fabs(x - y) < FLT_EPSILON; // float 精度误差
1.8 continue
break是直接跳出循环,没有异议。
- 对于 while 循环、do while 循环, continue 是跳到下一次循环的条件判断部分。
- 对于 for 循环,continue 是跳到本次循环的条件更新处,再进行下一次循环。
1.9 void
C语言的函数可以不声明返回类型和参数类型,默认的返回类型参数类型是 int。C++ 不允许使用默认 int。
使用 void 修饰返回类型和参数类型,可以避免歧义。
void 更像是一种提示符,没有太大意义。
test0() {}
void test1() {}
void test2(void) {}
int main() {
int a = test(1, 2, 3, 4);
test1(1, 2, 3, 4);
test2(1, 2, 3, 4);
}
void最多是作 void* 类型指针,用来接受任意类型的指针或者赋值给任意类型的指针。
1.10 return
return 返回变量,是通过寄存器拷贝变量的值,调用方接受返回值,是在用另一个变量接受寄存器的值。寄存器中的值是不可更改的,具有常属性。
1.11 const
const 修饰的变量被称为常变量,作用是提醒编译器不能直接修改该变量,但仍可通过指针的方式间接修改。
const void* 是修饰指针所指向的变量不可修改,void* const 修饰的是指针本身不可修改。
const 修饰变量作右值的时候,要注意权限放大的问题。
1.12 volatile
一般如果一个变量在当前执行流中不会被修改,CPU会将其优化放到寄存器中,不会到内存中取值。
但可能会存在其他执行流修改该变量,如果此时CPU仍不去内存中取值,就会导致程序错误。因此在并发环境下,为避免CPU的这种错误优化,可以对变量加 volatile 修饰。
volatile 就是避免编译器优化,防止内存被覆盖,达到稳定访问内存到目的。
while (flg)
11d8: 8b 05 32 2e 00 00 mov 0x2e32(%rip),%eax # 4010 <flg>
11de: 85 c0 test %eax,%eax
11e0: 75 f6 jne 11d8 <main+0x38>
{}
1.13 union
vs下c语言不支持定义空结构体,gcc允许空结构体且大小为0。
union 内每个成员都从首字节开始存放,相当于每个成员都是第一个成员。union 的大小由最大成员决定,但也要考虑内存对齐。
1.14 typedef
int*连续定义时,只有第一个变量是int*类型,其他都是int类型。- 如果使用 typedef 重定义的 int*,则连续定义的变量都是int*类型。
typedef 的类型,算作一个全新类型,是一个整体。而 #define 是文本替换,编译时和第一种无异。
typedef int* intp;
#define INTP int*
int* a, b; // int*, int
intp a, b; // int*, int*
INTP a, b; // int*, int
C语言的五个存储类型关键字 typedef volatile auto register static,在定义变量时最多只能使用一个。
2. 符号
2.1 char类型大小
char c = '1';
printf("%c\n", c); //1
printf("%c\n", '1'); //4
C99标准规定:'1'这样的字符常量,叫做整型字符常量,实际上是4字节的整型值。截断放入字符型变量c中,所以c占1字节。
上面是C语言对字符常量的处理方式,C++已经遗弃了这一反直觉的设计。
因此,'123'、'1234'这样的字符常量也是可以编译成功的,小于等于4字节就行。但我们非常不推荐这样。
2.2 溢出和截断
如果变量运算结果超出了变量本身的长度,我们称之为溢出。
变量进行运算,是需要从内存中取出数据放到CPU寄存器中进行运算的。32位机器的寄存器长度为32bits。所以比较小的整型数据放到寄存器中都会发生整形提升到32bits。
如果运算发生溢出,就会将运算结果截取变量大小个长度,放回变量的内存区域,我们称之为截断。
2.3 左移和右移
- 左移:低位补零,高位丢弃。
- 右移:
- 如果是无符号数,低位丢弃,高位补零;
- 如果是有符号数,低位丢弃,高位补符号位。
任何位运算操作的都是内存中的补码,只有涉及存取的时候才会考虑原反补的问题。
左移右移负数位的情况的结果是不可预测的,不推荐这样使用。
2.4 四种小数取整方案
- 浮点数到整数的隐式类型转换,就是零向取整。函数
trunc也是零向取整。 - 函数
floor是负向取整,也就是往小的方向取,也称地板取整。 - 函数
ceil是正向取整,也就是往大的方向取。 - 函数
round是四舍五入取整。
#include 2.5 负数取模
满足 a = q ∗ d + r 且 ( 0 ≤ ∣ r ∣ < ∣ d ∣ ) 则 a / d = q , a % d = r 满足\quad a=q*d+r\quad 且\quad(0≤|r|<|d|)\quad则\quad a/d=q,a\%d=r 满足a=q∗d+r且(0≤∣r∣<∣d∣)则a/d=q,a%d=r
正负余数
不同语言对负数取模运算可能不同,c语言中–10/3=–3,–10%3=–1,而python中–10/3=–4, –10%3=2。我们将两种余数分别称为正余数和负余数。
取模结果不同,根本原因是语言采用的整数除法取整方案不同。c语言采用的是零向取整,python采用的是负向取整。
取余和取模
按照定义,取余和取模并不严格相同,取余是让商零向取整,取模是让商负向取整。区别只有在取模运算的两个操作数不同符号时才体现出来。
c语言是取余,python是取模。
计算方法
我们只要记住自身语言的整数除法是零向取整还是负向取整,然后算出整数除法的结果,再代入公式计算余数即可。
3. 预处理
宏在任何地方都可以定义,宏是全局的,定义后都可以使用。
#可以将之后的符号,变成一个字符串。##可以将其左右两侧的符号拼接成一个新的符号文本。
4. 指针和数组
4.1 一维指针和数组
指针就是地址,地址的本质就是一串数字,是可以被保存进变量空间的,保存指针(地址)的变量就是指针变量。
指针的加减运算,就是向前或向后移动一个步长。步长就是指针所指向的类型的大小。
const char* str = "hello world"; // 栈区指针变量保存常量区字符串的地址
char buffer[] = "hello world"; // 栈区数组保存栈区字符串
数组名大部分情况都代表首元素地址,除了在sizeof中和被取地址时。
数组传参自动降维成指针,避免拷贝整个数组,取而代之的是用首元素地址初始化形参指针。
数组元素个数也是数组类型的一部分。
指针是个变量,而数组名会被编译成地址常量,二者寻址方式是不同的。所以指针和数组不同。
4.2 二维指针和数组
任何的 n n n 维数组都可以理解为一维数组, n n n 维数组是元素为 n − 1 n-1 n−1 维数组的一维数组。
二维数组名,除&和sizeof两种情况,都看作是首元素的地址,也就是一维数组的地址。
int a[3][4] = {0};
cout << sizeof(a[0]) << endl; // 第一个元素int[4]
cout << sizeof(a[0] + 1) << endl; // 第一个元素int[4]的第二个元素int的地址
cout << sizeof(&a[0] + 1) << endl; // 第二个元素int[4]的地址
cout << sizeof(*(a[0] + 1)) << endl; // 第二个元素int[4]的第一个元素
cout << sizeof(*(&a[0] + 1)) << endl; // 第二个元素int[4]
cout << sizeof(*a) << endl; // 第一个元素int[4]
cout << sizeof(a[3]) << endl; // 第四个元素int[4]
所有数组传参,都要发生降维,降维成首元素指针。二维数组降维就是一维数组的指针。
void test(int(*a)[4]) {}
int a[3][4] = {0};
test(a);
4.3 函数指针
函数名和取地址函数名,都是获取函数的地址。因为函数不会写入,不会作左值,函数只关心函数代码的起始位置。
5. 函数
5.1 函数栈帧的创建和销毁
| 常见寄存器 | 作用 |
|---|---|
eax |
通用寄存器,保存临时数据,常用于返回值 |
ebx |
通用寄存器,保存临时数据 |
ebp |
栈底寄存器 |
esp |
栈顶寄存器 |
eip |
指令寄存器,保存下一条指令的地址 |
| 相关汇编指令 | 作用 |
|---|---|
mov |
数据转移指令(开辟空间,数据移入空间) |
push |
数据入栈 |
pop |
数据出栈 |
sub |
减法指令 |
add |
加法指令 |
call |
函数调用(压入返回地址和转入目标函数) |
jump |
转入目标函数(修改eip) |
ret |
恢复返回地址(弹出返回地址和修改eip) |
int Test(int a, int b) {
int c = 0;
c = a + b;
return c;
}
int main() {
int x = 0xA;
int y = 0xB;
int z = Test(x, y);
return 0;
}
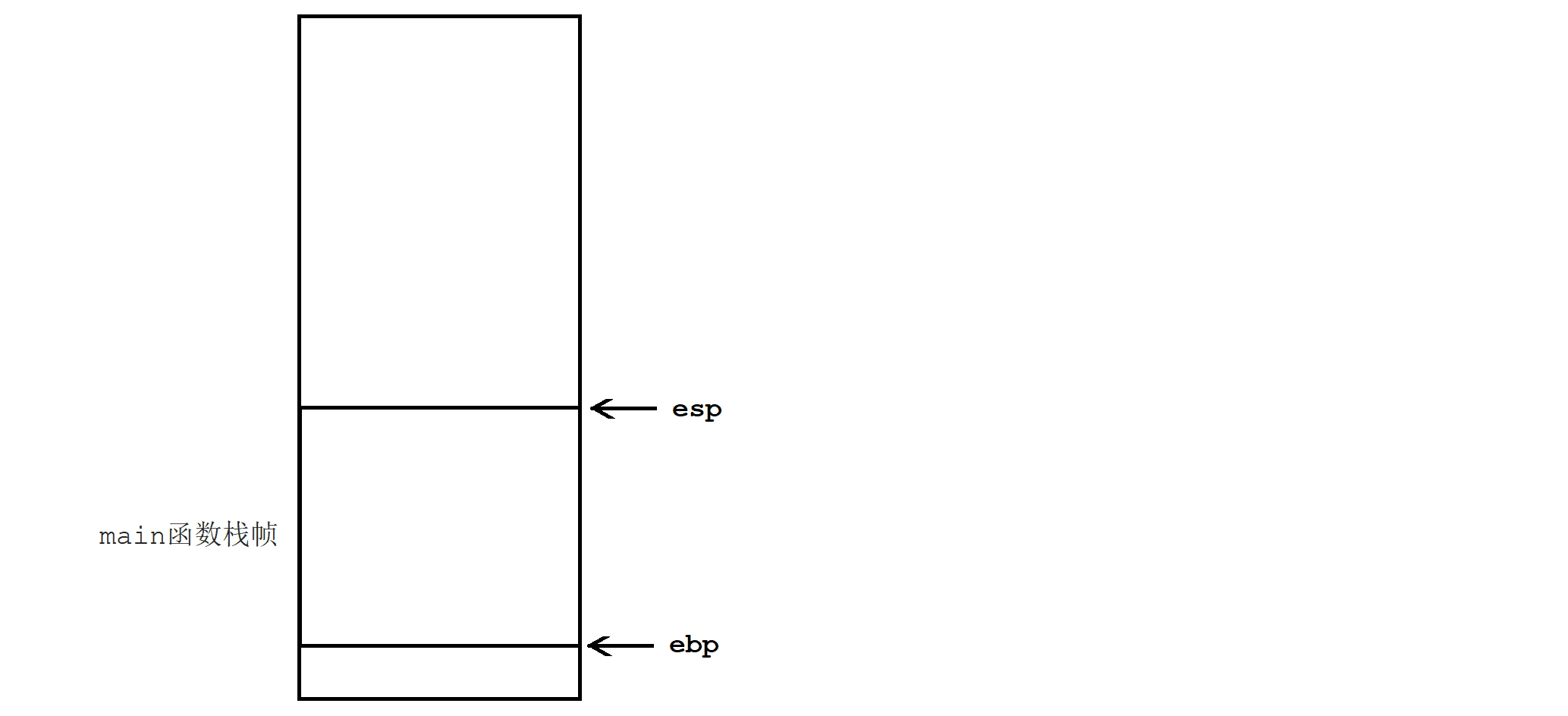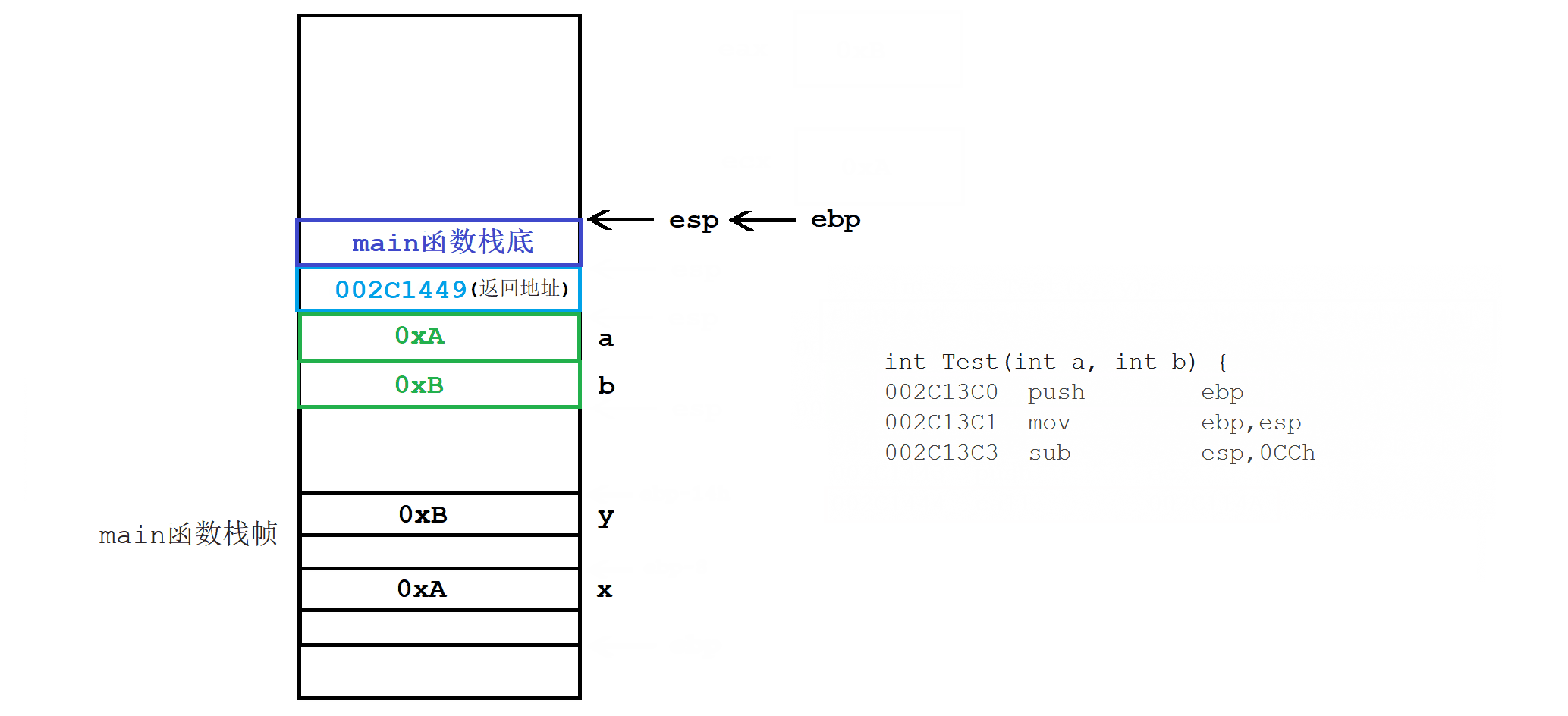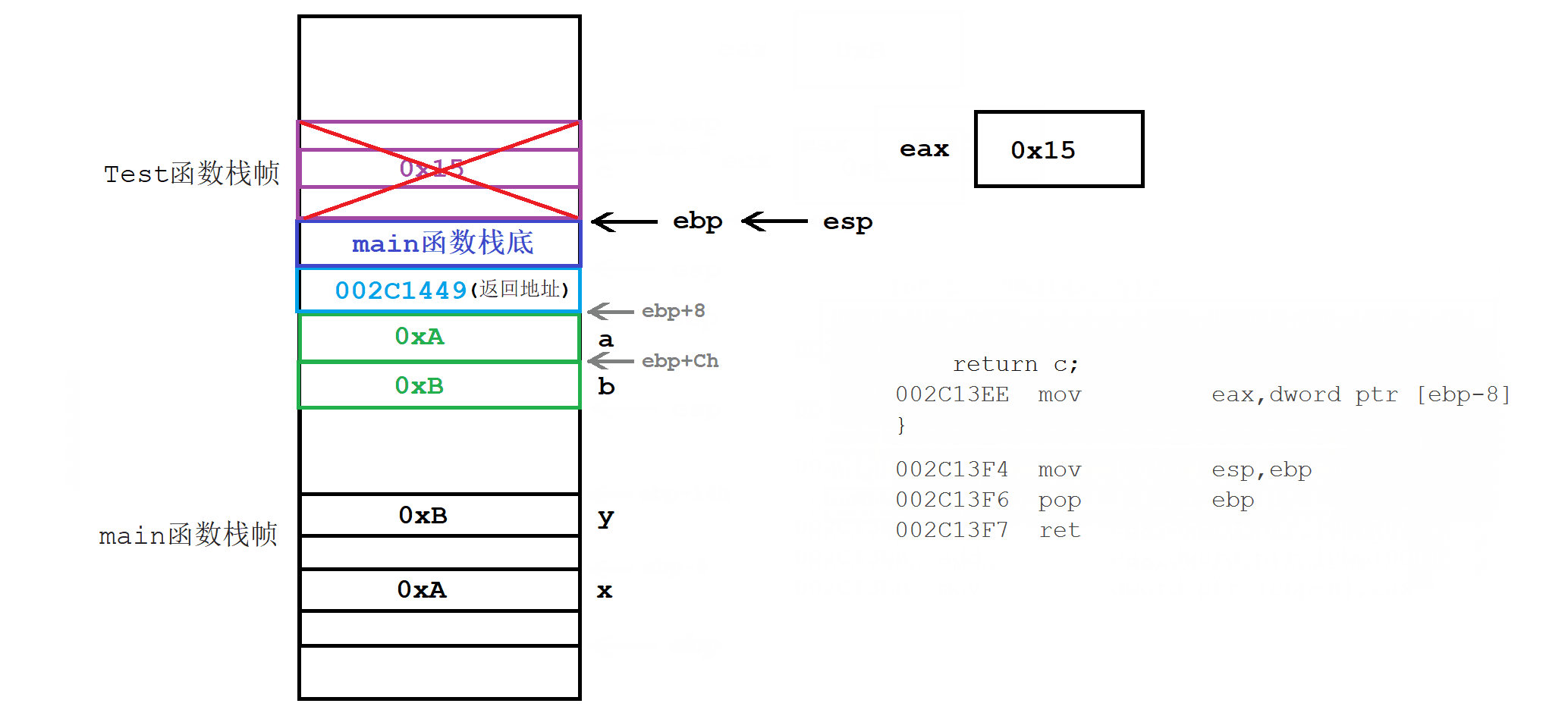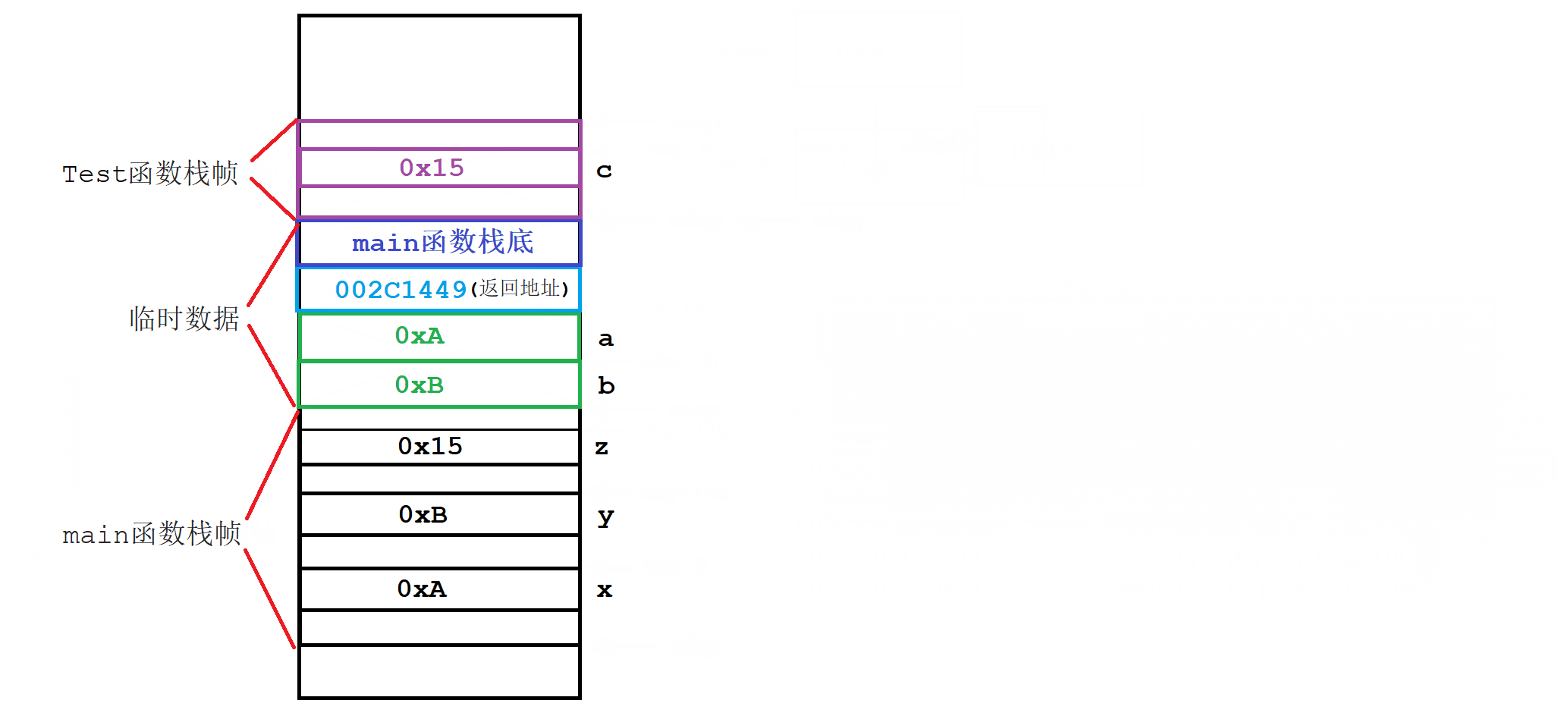
- 函数内临时变量,是在该函数对应栈帧内部开辟的。临时变量的临时性,是因为栈帧会被自动释放。
- 函数调用之前,会提前开辟好指定大小的栈帧。函数调用之后,栈帧会被释放。
- 形参列表的实例化,是按照从右往左的顺序压栈的。且压栈位置是紧挨着的。
- 调用函数的成本,体现在栈帧创建和销毁的消耗上。
5.2 可变参数列表
void Test(int num, ...)
{}
Test(5, 1, 2, 3, 4, 5);
使用可变参数列表,必须至少声明一个明确的参数。
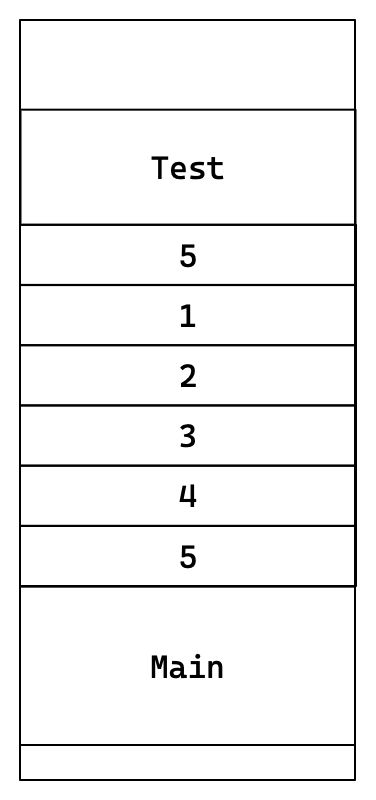
既然我们理解可变参数列表的栈帧结构,我们就可以自行用指针获取每个变量。库中实现也是这个原理。
int Max(int num, ...)
{
va_list arg; // 定义char*类型的指针
va_start(arg, num); // 根据num确定开始位置,并将arg指针指向第一个可变形参
int max = va_arg(arg, int); // arg指针以int长度获取第一个可变形参
for (int i = 1; i < num; i++)
{
int cur = va_arg(arg, int); // 以int长度获取之后的形参
if (cur > max)
max = cur;
}
va_end(arg); // 将arg指针置空
return max;
}
短整型传参一般都会整型提升至4字节整型,所以用 int 处理可变形参长度是合理的。
// va_list va_start va_arg va_end 实现
typedef char * va_list;
#define va_start _crt_va_start
#define va_arg _crt_va_arg
#define va_end _crt_va_end
#define _crt_va_start(ap, v) ( ap = (va_list)_ADDRESSOF(v) + _INTSIZEOF(v) )
#define _crt_va_arg(ap, t) ( *(t *)((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) )
#define _crt_va_end(ap) ( ap = (va_slist)0 )
#define _ADDRESSOF(v) ( &(v) )
#define _INTSIZEOF(n) ( (sizeof(n) + sizeof(int) - 1) & ~(sizeof(int) - 1) ) // 4字节对齐
前面几个宏都很好理解,我们重点看一下最后一个
_INTSIZEOF(n)。
x ≥ n & & x % 4 = = 0 x \ge n \quad \&\& \quad x \% 4 == 0 x≥n&&x%4==0
INTSIZEOF(n)宏的含义就是求出满足上述条件的,最小的 x x x。也就是4字节倍数的向上取整。
5.3 命令行参数
int main(int argc, char* argv[], char* envp[])
{
for (int i = 0; i < argc; i++)
cout << i << "->" << argv[i] << endl;
for (int i = 0; envp[i]; i++)
cout << i << "->" << envp[i] << endl;
}
// argc: 命令行参数的个数
// argv: 命令行参数字符串数组
// envp: 环境变量字符串数组
Linux系统:进程概念