深度实践KVM笔记
libvirt(virt-install,API,服务,virsh)-》qemu(qemu-kvm进程,qemu-img)-》KVM虚拟机-》kvm.ko 内核模块 P7
/etc/init.d/libvirtd
virsh
腾讯云一样要自己手动进入虚拟机扩容
第3章 CPU,内存虚拟化技术
CPU 的嵌套技术nested特性,使用kvm虚拟机在理论上可以无限嵌套下去,只要物理机性能足够 P23
numastat P25
node0
numa_hit 4309388
numa_miss 0
numa_foreign 0
interleave_hit 18480
local_node 4309388
other_node 0
numactl --hardware
available: 1 nodes (0)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
node 0 size: 4095 MB
node 0 free: 3034 MB
node distances:
node 0
0: 10
Linux系统默认是打开自动numa平衡策略,关闭Linux系统的自动numa平衡 P25
echo 0 >/proc/sys/kernel/numa_balancing #关闭
echo 1 >/proc/sys/kernel/numa_balancing #开启
virsh numatune设置虚拟机的numa配置
CPU热添加是centos7的一个新特性,物理机和虚拟机都必须是centos7,windows虚拟机必须是windows2012标准版或数据中心版 P32
cat /proc/interrupts 在虚拟机里面查看当前系统有多少个cpu P33
cat /proc/cpuinfo
echo 1 > /sys/devices/system/cpu/cpu3/online 在虚拟机里面激活第4个cpu
echo 0 > /sys/devices/system/cpu/cpu3/online 在虚拟机里面关闭第4个cpu
KSM技术 P39
KSM:kernel samepage merging,将相同内存页进行合并
KSM服务
ksmtuned服务
service ksm start
service ksmtuned start
chkconfig ksm on
chkconfig ksmtuned on
cat /sys/kernel/mm/ksm/* 查看ksm的运行情况
巨型页large page技术 P44
X86默认的内存页是4KB,但也可以使用2MB或1GB的巨型页
kvm虚拟机可以通过分配巨型页提升性能,centos5需要手动开启巨型页,centos6有一种透明巨型页面的技术,默认开启巨型页,并可以自动调整
cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never
三个选项
always 总是使用巨型页
madvise 避免改变内存占用
never 不使用巨型页
cat /proc/meminfo|grep -i huge
AnonHugePages: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
cat /proc/sys/vm/nr_hugepages
0
修改巨型页的pagesize,N是巨型页的pagesize
sysctl vm.nr_hugepages=N
挂载巨型页
mount -t hugetlbfs hugetlbfs /dev/hugepages
第4章 网络虚拟化技术
半虚拟化网卡
解决全虚拟化网卡效率低下的一个办法就是使用半虚拟化驱动程序Virtio。
要使用Virtio需要在宿主机和客户机分别安装Virtio驱动。
Linux内核从2.6.24开始支持Virtio,现在的内核版本一般是2.6.32,只需要较新的Linux内核即可,不需要安装
在宿主机和客户机执行下面命令,如果有Virtio字样输出证明支持Virtio,如果是windows,需要安装Virtio驱动
grep -i Virtio /boot/config-2.6.32-504.el6.x86_64
CONFIG_NET_9P_VIRTIO=m
CONFIG_VIRTIO_BLK=m
CONFIG_SCSI_VIRTIO=m
CONFIG_VIRTIO_NET=m
CONFIG_VIRTIO_CONSOLE=m
CONFIG_HW_RANDOM_VIRTIO=m
CONFIG_VIRTIO=m
CONFIG_VIRTIO_RING=m
CONFIG_VIRTIO_PCI=m
CONFIG_VIRTIO_BALLOON=m
配置半虚拟化网卡的方法
在虚拟机的xml配置文件里找到interface节,修改model type为Virtio
步骤:
lspci #修改之前
00:03.0 Ethernet controller: Intel Corporation 82540EM Gigabit Ethernet Controller (rev 03)
00:04.0 USB controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #1 (rev 03)
00:04.1 USB controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #2 (rev 03)
00:04.2 USB controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #3 (rev 03)
00:04.7 USB controller: Intel Corporation 82801I (ICH9 Family) USB2 EHCI Controller #1 (rev 03)
00:05.0 RAM memory: Red Hat, Inc Virtio memory balloon
1、虚拟机关机
2、修改xml配置文件
virsh edit gzxtest01
3、虚拟机开机
virsh start gzxtest01
lspci #修改之后
00:03.0 Ethernet controller: Red Hat, Inc Virtio network device
00:04.0 USB controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #1 (rev 03)
00:04.1 USB controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #2 (rev 03)
00:04.2 USB controller: Intel Corporation 82801I (ICH9 Family) USB UHCI Controller #3 (rev 03)
00:04.7 USB controller: Intel Corporation 82801I (ICH9 Family) USB2 EHCI Controller #1 (rev 03)
00:05.0 RAM memory: Red Hat, Inc Virtio memory balloon
看到这个提示Ethernet controller: Red Hat, Inc Virtio network device表示已经使用Virtio网卡
在virt-install 安装的时候,不能指定model=Virtio网卡
Starting install...
ERROR internal error process exited while connecting to monitor: char device redirected to /dev/pts/4
2016-08-11T02:42:41.500805Z qemu-kvm: -device Virtio,netdev=hostnet0,id=net0,mac=52:54:00:7d:a3:18,bus=pci.0,addr=0x3: Parameter 'driver' expects a driver name
Try with argument '?' for a list.
Windows P63
Virtio驱动网卡在2014年10月之后工作很稳定,没有网络闪断情况,可以在生产环境使用
Linux
Linux内核默认集成Virtio驱动,大部分Linux发行版可以直接使用Virtio驱动网卡。RHEL5.4之后建议使用Virtio网卡
vhost_net技术 P66
运行一台虚拟机是由用户空间的QEMU和内核空间的KVM共同完成,QEMU模拟各种设备提供给虚拟机,KVM负责模拟CPU和内存
Virtio的后端处理程序一般有用户空间的QEMU提供,为了进一步减少延迟,比较新的内核中已经增加了一个vhost_net的驱动模块,在内核中
实现了Virtio的后端处理程序
vhost_net配置
虚拟机的xml配置文件默认就是使用vhost_net
数据包从虚拟机到物理机的过程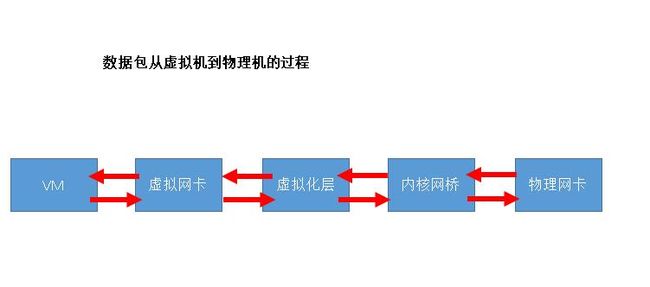
virtio原理 前端
virtio原理 后端
网卡的中断和多队列
中断优化脚本效果测试 P68
mpstat -P ALL 5 2
Linux 2.6.32-504.el6.x86_64 (gzxkvm53) 08/12/2016 _x86_64_ (4 CPU)
10:36:09 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
10:36:09 AM all 0.00 0.00 0.01 0.07 0.00 0.00 0.00 0.03 99.88
10:36:09 AM 0 0.00 0.00 0.01 0.09 0.00 0.00 0.00 0.04 99.86
10:36:09 AM 1 0.01 0.00 0.03 0.08 0.00 0.00 0.00 0.06 99.82
10:36:09 AM 2 0.00 0.00 0.00 0.07 0.00 0.00 0.00 0.02 99.91
10:36:09 AM 3 0.00 0.00 0.00 0.05 0.00 0.00 0.00 0.02 99.92
以上显示机器有四个逻辑CPU
它显示了系统中 CPU 的各种统计信息。–P ALL 选项指示该命令显示所有 CPU 的统计信息,
而不只是特定 CPU 的统计信息。参数 5 2 指示该命令每隔 5 秒运行一次,共运行 2 次。
mpstat 可以显示每个处理器的统计,
而 vmstat 显示所有处理器的统计。因此,编写糟糕的应用程序(不使用多线程体系结构)可能会运行在一个多处理器机器上,
而不使用所有处理器。从而导致一个 CPU 过载,而其他 CPU 却很空闲。通过 mpstat 可以轻松诊断这些类型的问题
针对 Oracle 用户的用法
与 vmstat 相似,mpstat 命令还产生与 CPU 有关的统计信息,因此所有与 CPU 问题有关的讨论也都适用于 mpstat。
当您看到较低的 %idle 数字时,您知道出现了 CPU 不足的问题。当您看到较高的 %iowait 数字时,
您知道在当前负载下 I/O 子系统出现了某些问题。该信息对于解决 Oracle 数据库性能问题非常方便
RSS需要网卡硬件的支持,在使用不支持RSS的网卡时,为了充分利用多核CPU,centos6.1开始提供了RPS和RFS功能 P69
而RSS仅仅是根据hash值确定处理器。
由于RFS/RSS都不能提供irq affinity hint,所以使用irqbalance足够。
网卡PCI Passthrough技术 P71
物理网卡直接给虚拟机使用,性能几乎达到物理网卡一样
PCI Passthrough技术是虚拟化网卡的终极解决方案,能够让虚拟机独占物理网卡,达到最优性能。
对宿主机的物理网卡数量有要求,目前主流服务器都有4块以上的网卡,实际使用的时候,可以将1~2块网卡通过PCI Passthrough技术分给网络
压力大的虚拟机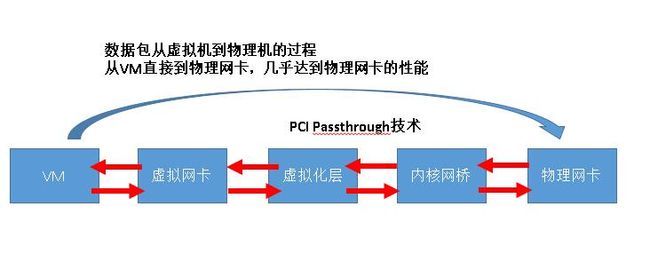
网卡绑定的7种模式 P80
http://www.cnblogs.com/MYSQLZOUQI/p/4255675.html(CentOS工作内容(六)双网卡带宽绑定bind teaming)
mode=0 balance-rr 多端口轮询发送数据包
mode=1 active-backup 主备模式,不需要交换机支持
mode=2 balance-xor 每个接口上传输每个数据包,具有容错功能
mode=3 802.3ad 基于802.3ad IEEE802.3ad dynamic link aggreagtion 动态链路聚合,需要和交换机配合,功能不大,不建议使用
mode=4 balance-tlb 每块网卡根据当前负载根据速度计算,分配外出流量,发送数据包自动负载均衡,接受数据包由current active slave负责,具容错功能,其中一块网卡失效依然可以继续工作,不需要交换机支持
mode=5 broadcast 所有网卡一起收发网络数据包,有容错功能,其中一个网卡断线依然可以工作,基于hash算法发送数据包
mode=6 balance-alb 针对ipv4做了优化,收发都可以自动负载均衡,有容错功能,其中一个网卡断线也可以工作,网卡驱动需支持setting hardware address功能,不需要交换机支持
第5章 kvm磁盘虚拟化技术和场景
qemu磁盘虚拟化方式 P83
qemu最初是一款软件模拟器,所以qemu的磁盘都是通过软件模拟的,后来qemu和kvm结合
性能有很大提升,磁盘和网卡一样,也有了virtio这样的半虚拟化技术
centos6.x只支持ide和virtio磁盘类型
centos7.x增加支持sata和virtio-scsi磁盘类型
virtio-scsi和virtio是半虚拟化磁盘
磁盘I/O从虚拟机到宿主机流向

虚拟机磁盘的缓存模式 P86
1、默认,不指定缓存模式的情况下,1.2版本qemu-kvm之前是writethough,1.2版本之后qemu-kvm, centos虚拟机默认的缓存模式就是none
2、writethough:使用O_DSYNC语义
3、writeback:不是O_DSYNC语义也不是O_DIRECT语义,虚拟机数据到达宿主机页面缓存page cache就给虚拟机返回写成功报告,页面缓存机制管理数据的合并写入宿主机存储设备
4、none:使用O_DIRECT语义,I/O直接在qemu-kvm用户空间缓存和宿主机存储设备之间发生,要求I/O方式设置为aio=native,不能使用宿主机的page cache,相当于直接访问磁盘,有优越性能
5、unsafe:跟writeback一样,但是不能发出刷盘指令,只有在虚拟机被关闭时候才会将数据刷盘,不安全
6、directsync:同时使用O_DSYNC语义和O_DIRECT语义
缓存模式的数据一致性
writethough、none、directsync
能保证数据一致性,有一些文件系统不兼容none或directsync模式,这些文件系统不支持O_DIRECT语义
writeback
不能保证数据一致性,在数据报告写完成和真正合并写到存储设备上一个时间窗口期,这种模式在宿主机故障时候会丢失数据,因为数据还存在在宿主机的page cache里
unsafe
不保证数据一致性,忽略刷盘指令,只有在虚拟机被关闭时候才会将数据刷盘,不安全
从数据测试来看,none方式的4K随机读写都要比其他的缓存模式高,建虚拟机的时候使用默认缓存模式即可
虚拟机在线迁移支持情况 P89
1、有集群文件系统或共享存储,并且标记为只读模式
所有镜像格式都支持,缓存模式检查会忽略
2、本地盘
只有raw,qcow2,qed镜像格式支持,缓存模式必须是none
一般使用:不使用共享存储和集群文件系统,使用qcow2镜像格式和none缓存模式,所以肯定支持在线迁移
none模式要求I/O方式设置为aio=native(全异步IO,不能使用page cache),如果是其他缓存模式,I/O方式会设置为aio=thread(线程池,同步IO)。
kvm虚拟机可以使用fdatasync()方式实现在宿主机上刷盘
Linux Native Aio 异步AIO的研究
http://www.cnblogs.com/MYSQLZOUQI/p/5792364.html
EXT4文件系统默认的刷盘周期是5秒
http://www.cnblogs.com/MYSQLZOUQI/p/5335649.html
内核缓冲区和磁盘文件同步的系统调用
sync:异步,针对整个块缓冲区,系统的sync命令
fsync:同步阻塞 传入文件描述符针对单个文件
fdatasync:跟fsync一样,只是他只同步data,而不同步inode
msync:mmap方式 需要指定地址空间
QEMU支持的磁盘镜像格式 P89
raw,cloop,cow,qcow,qcow2,vmdk,vdi,vpc vhd,dmg,nbd,parallels
raw:简单二进制镜像文件,一次性会把磁盘空间占用完,ext4和xfs文件系统都支持稀疏文件特性,windows的ntfs也支持稀疏文件
cloop:压缩的loop格式,可直接引导光盘的一种镜像格式
cow:写时复制格式,因为历史兼容问题还保留,这种格式不支持windows虚拟机
qcow:第一代qemu写时复制格式,被qcow2替代,因为历史原因还保留
qcow2:第二代qemu写时复制格式,支持很多特性:例如快照,在不支持稀疏特性的文件系统上也支持精简格式,AES加密,zlib压缩,后备方式
vmdk:vmware产品的镜像格式
vdi:virtual box镜像格式
vpc vhd:微软hyper-v镜像格式
dmg:mac磁盘镜像格式
nbd:网络块设备
parallels:半虚拟化镜像格式
ls命令看到的是分配的大小而不是实际使用大小,du命令看到的是实际使用大小
镜像格式转换主要用于不同虚拟化产品的虚拟机镜像转化,比如将vmware的vmdk转换为kvm专用的qcow2格式 P92
快照 qcow2文件格式才能创建快照 P93
qemu-img snapshot test.qcow2 -c testsnapshop1 创建一个叫testsnapshop1的快照,创建快照之后,test.qcow2镜像文件不能删除,还原快照和查看快照都是基于这个镜像我呢件
qemu-img snapshot test.qcow2 -l 查看test.qcow2镜像文件创建了多少个快照
qemu-img snapshot test.qcow2 -d testsnapshop1 删除test.qcow2镜像文件的名为testsnapshop1的快照
qemu-img snapshot test.qcow2 -a testsnapshop1 还原test.qcow2镜像文件的名为testsnapshop1的快照,注意test.qcow2镜像文件不能删除
快照的原理是利用写时复制技术,所以快照对性能有影响,生产环境建议最多创建一次快照
lvm关闭写缓存的方法 P96
lvm的cache配置
建议将cache关闭,防止主机突然掉电造成数据丢失
默认是1为开启状态
cat lvm.conf |grep write_cache
# Configuration option devices/write_cache_state.
write_cache_state = 1
关闭/etc/lvm/lvm.conf文件中lvm的写缓存
write_cache_state=0
然后清空cache_dir指向的目录内容,默认路径是/etc/lvm/cache
cache_dir="/etc/lvm/cache"
rm -rf /etc/lvm/cache/
clvm P97
clvm是lvm的集群方式,一般用于集群的块设备使用,主要是多了验证功能,抑制两台服务器同时对一个lv进行写操作
块对齐问题 P110
windows2008 server和windows7之后的系统默认都会有1MB的偏移量,解决了块对齐问题
centos6和rhel6之后,和windows一样都有一个1MB的偏移量,解决了块对齐问题
解决块对齐问题建议使用最新操作系统
ll /etc/lvm/
total 80
drwx------. 2 root root 4096 Oct 16 2014 archive
drwx------. 2 root root 4096 Oct 16 2014 backup
drwx------. 2 root root 4096 Oct 16 2014 cache
-rw-r--r--. 1 root root 58444 Oct 16 2014 lvm.conf
drwxr-xr-x. 2 root root 4096 Jul 10 2015 profile
生产环境中SSD使用要点 P123
简单来说,SMART信息就是硬盘内部的一些计数器,这些计数器用来保存硬盘的使用情况,根据这些信息,我们可以预测磁盘的使用寿命以及损坏的情况。
Windows查看ssd硬盘的smart信息
Windows服务器不能用raid卡,因为raid卡会将硬盘的smart信息屏蔽
使用英特尔的专用ssd工具
Linux查看ssd硬盘的smart信息
可以通过raid卡读取硬盘的smart信息
CentOS 系统自带smartmontools软件包,里面有一个smartctl工具,可以很方便的查看SMART相关信息
低端板载raid卡,LSI MPT RAID卡
第一块硬盘
smartctl -a -i /dev/sda1
LSI Mega RAID卡(IBM,联想,华为,浪潮,戴尔)
第一块硬盘
smartctl -a -d megaRAID,0 /dev/sda
惠普服务器RAID卡,需要centos6.3以上
第一块硬盘
smartctl -d sat+cciss,0 -a /dev/sda
ssd的smart信息解读
media_wearout_indicator:使用耗费,100为没有任何耗费,表示ssd上nand的擦写次数程度,初始值为100,随着擦写次数的增加,开始线性递减,一旦这个值降低到1
就不再降了,同时表示ssd上面已经有nand的擦写次数达到了最大次数,这个时候建议备份数据,并更换ssd
reallocated_sector_ct:出厂后产生的坏块个数,初始值为100,如果有坏块,从1开始增加,每4个坏块增加1
第6章 kvm虚拟机的资源限制
CGroups P127
kvm虚拟机的资源限制主要是通过CGroups 去配置,Libvirt在CGroups 上封装了一层,也可以通过修改xml文件去做虚拟机的资源限制
CGroups 是Linux内核提供的一种可以限制,记录,隔离进程组所使用的物理资源的机制,最初由google工程师提出,redhat在rhel6/centos6
中开始正式支持CGroups
CGroups (control groups)是一种机制,它以分组的形式对进程使用系统资源的行为进行管理和控制,用户通过CGroups 对所有进程进行分组,
再对该分组整体进行资源的分配和控制
使用CGroups 最简单的方法是安装libcgroups软件包,该软件包包含大量和CGroups 有关的命令和相关man page,
使用libcgroups提供的工具可以简化过程并扩展功能。
yum install -y libcgroups
Linux生产环境限制网络资源的3种方案 P144
1、通过TC限制虚拟机流量,TC是内核中一套限制网络流量的机制
2、通过Libvirt限制虚拟机流量
3、通过iptables限制虚拟机流量
TC:traffic control,是Linux进行流量控制的工具,可以控制网络接口发送数据速率
每个网络接口都有一个队列,用于管理和调度待发数据,TC的工作原理是通过设置不同类型的网络接口队列从而改变数据包发生速率和优先级
TC只能控制出口流量,入口流量不同通过TC控制
Libvirt实际也是使用TC限制虚拟机流量,因为TC只能限制出流量,不能限制入流量,所以通过Libvirt限制流量也只能限制出流量
iptables不能精确控制网速,只能控制包的个数,具体数据可以用mtu乘以包的个数计算,因为网络协议是双向的,即使配置是单向的,实际对流出和流入都有影响
流入和流出只是一个-s 和一个-d 不同
#限制流入方向 限制流量
# 限定每秒只转发30个到达192.168.0.2的数据包(约每秒45KB 如果一个数据包是1.5KB)
iptables -A FORWARD -d 192.168.0.2 -m limit --limit 30/sec --limit-burst 30 -j ACCEPT
iptables -A FORWARD -d 192.168.0.2 -j DROP #这句作用是超过限制的到达192.168.0.2的数据包不通过)
#限制流出方向 限制流量
# 限定每秒只转发30个离开192.168.0.2的数据包(约每秒45KB 如果一个数据包是1.5KB)
iptables -A FORWARD -s 192.168.0.2 -m limit --limit 30/sec --limit-burst 30 -j ACCEPT
iptables -A FORWARD -s 192.168.0.2 -j DROP #这句作用是超过限制的离开192.168.0.2的数据包不通过)
第7章 物理机转虚拟机实践
P2V方案 物理机转虚拟机 P152
静态方案:关机,克隆软件克隆,在虚拟机上还原,kvm的virt-P2V,vmware esx3.5
动态方案:物理机处于运行状态,使用专用agent将物理机在线复制到虚拟机中,vmware esx4.0以后采用这种方案
V2V方案 P160
最常用是vmware转kvm
低版本的使用virt-P2V工具来操作
对于Hyper-v的虚拟机转换,没有直接转换的工具,需要使用P2V的方法进行转换,侧面说明Hyper-V不是主流
第8章 KVM桌面虚拟化实践
centos6.5磁盘调度算法调整 P167
centos6.5默认的磁盘调度算法是CFQ 完全公平排队算法 ,并不适合于SSD固态硬盘,工作原理是为IO请求进行排序和对邻近IO请求进行合并
机械盘在响应IO请求时最大的耗时发生在机械臂寻道,排序正是为了减少寻道时间。
deadline算法 最终期限算法,工作原理跟CFQ一样,同样并不适合于SSD固态硬盘
Noop空操作算法,专为随机访问的块设备而生的调度算法,工作原理是只做IO合并不做排序,适合于SSD固态硬盘
修改磁盘调度算法,把下面命令写入/etc/rc.local永久生效
echo "noop" > /sys/block/vdc/queue/scheduler
腾讯云
cat /sys/block/vdc/queue/scheduler
noop anticipatory deadline [cfq]
ll /sys/block/
total 0
lrwxrwxrwx 1 root root 0 Aug 31 22:02 loop0 -> ../devices/virtual/block/loop0
lrwxrwxrwx 1 root root 0 Aug 31 22:02 loop1 -> ../devices/virtual/block/loop1
lrwxrwxrwx 1 root root 0 Aug 31 22:02 loop2 -> ../devices/virtual/block/loop2
lrwxrwxrwx 1 root root 0 Aug 31 22:02 loop3 -> ../devices/virtual/block/loop3
lrwxrwxrwx 1 root root 0 Aug 31 22:02 loop4 -> ../devices/virtual/block/loop4
lrwxrwxrwx 1 root root 0 Aug 31 22:02 loop5 -> ../devices/virtual/block/loop5
lrwxrwxrwx 1 root root 0 Aug 31 22:02 loop6 -> ../devices/virtual/block/loop6
lrwxrwxrwx 1 root root 0 Aug 31 22:02 loop7 -> ../devices/virtual/block/loop7
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram0 -> ../devices/virtual/block/ram0
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram1 -> ../devices/virtual/block/ram1
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram10 -> ../devices/virtual/block/ram10
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram11 -> ../devices/virtual/block/ram11
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram12 -> ../devices/virtual/block/ram12
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram13 -> ../devices/virtual/block/ram13
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram14 -> ../devices/virtual/block/ram14
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram15 -> ../devices/virtual/block/ram15
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram2 -> ../devices/virtual/block/ram2
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram3 -> ../devices/virtual/block/ram3
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram4 -> ../devices/virtual/block/ram4
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram5 -> ../devices/virtual/block/ram5
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram6 -> ../devices/virtual/block/ram6
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram7 -> ../devices/virtual/block/ram7
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram8 -> ../devices/virtual/block/ram8
lrwxrwxrwx 1 root root 0 Aug 31 22:02 ram9 -> ../devices/virtual/block/ram9
lrwxrwxrwx 1 root root 0 Aug 31 22:02 vda -> ../devices/pci0000:00/0000:00:04.0/virtio1/block/vda
lrwxrwxrwx 1 root root 0 Aug 31 22:02 vdb -> ../devices/pci0000:00/0000:00:05.0/virtio2/block/vdb
lrwxrwxrwx 1 root root 0 Aug 31 22:02 vdc -> ../devices/pci0000:00/0000:00:06.0/virtio3/block/vdc
第10章 Ceph在kvm虚拟化中的应用和故障处理
centos6自带的内核都是2.6.32-xxx版本 P222
btrfs为Ceph特别设计的文件系统,btrfs对内核有要求,推荐使用3.x的内核版本
升级系统内核
方法一
从Linux官网下载内核自己动手编译安装
方法二
安装编译好的Linux内核,例如ELRepo(Linux企业版的一个增强yum源,有编译好的最新Linux内核)
http://elrepo.org/tiki/tiki-index.php
ELRepo提供两种kernel版本,一个是kernel-lt,长期支持版,目前是3.10.60
另一个是kernel-ml,ml=main line,主线稳定是3.17.3
#To install ELRepo for RHEL-6, SL-6 or CentOS-6:
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
rpm -Uvh http://www.elrepo.org/elrepo-release-6-6.el6.elrepo.noarch.rpm
yum --enablerepo=elrepo-kernel -y install kernel-lt
内核升级完毕后,不会立即生效,还需要我们修改grub.conf文件,我们修改内核的启动顺序,默认启动的顺序应该为1,升级以后内核是往前面插入为0,如下:
vim /etc/grub.conf
default=0

重启系统
reboot
查看当前内核版本
uname -r
https://www.kernel.org/

第13章 其他管理平台介绍
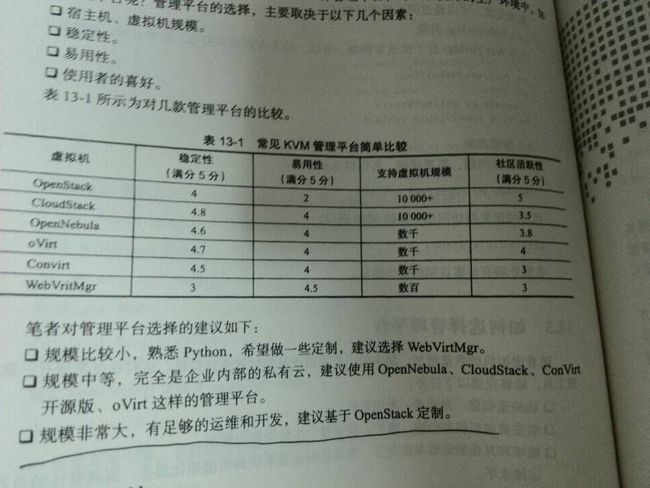
WebVirtMgr介绍
WebVirtMgr就是将VirtManager页面化
WebVirtMgr几乎是纯python开发,前端基于python的django,后端基于Libvirt的python接口,风格也是python风格
使用了wsgi 模块和gunicorn模块
/usr/bin/python /var/www/webvirtmgr/manage.py run_gunicorn -c /var/www/webvirtmgr/conf/gunicorn.conf.py
特点
基于Libvirt的连接
宿主机管理支持功能
虚拟机镜像
虚拟机克隆
快照管理
日志管理
虚拟机管理支持功能
关闭虚拟机
安装虚拟机
VNC网页连接
创建快照

常见kvm管理平台简单比较
openstack,cloudstack,opennebula,ovirt,convirt,webvirtmgr
稳定性,易用性,支持虚拟机规模,社区活跃性
第14章 业务性能评估和压力模型建立
#通过判断iostat文件是否存在来安装sysstat包 P310
if [ ! -e /usr/bin/iostat ] ;then yum install -y sysstat else echo 0 fi
%iowait值过高,可以磁盘存在IO瓶颈,如果%idle值高但系统响应慢,可能CPU等待分配内存,可以尝试添加内存 P311
如果idle值持续低于10,则系统CPU处理能力相对较低,说明系统最需要解决CPU资源
windows虚拟机,由于驱动的关系,运行在kvm平台上的windows虚拟机网卡发包率远远不如Linux虚拟机,通过测试,大概是Linux虚拟机网卡发包率的1/3的性能 P317
第15章 宿主机选型和基础性能测试
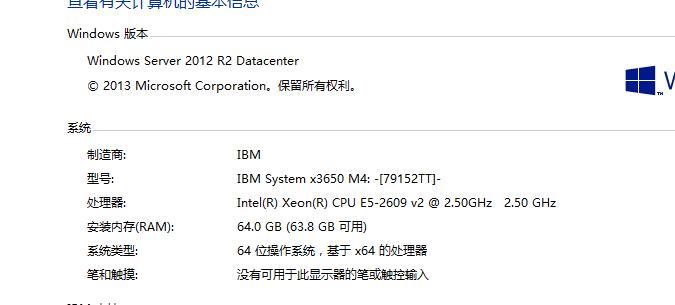
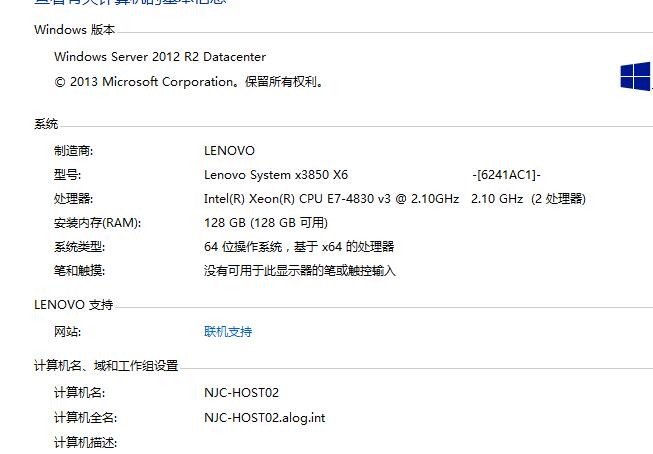
英特尔CPU产品线 P321
PC 酷睿:i3,i5,i7
SERVER 志强xeon:E3,E5,E7
平板:凌动
服务器志强CPU支持睿频技术,可以理解为自动超频,根据当前CPU任务量自动调整CPU主频,睿频技术可以细分到每个具体的CPU核上
比如E5-2640V2标称主频为2.0GHz,有8个核,可能有的核工作在1.2GHz,有的核工作在2.5GHz
intel志强CPU编号含义


E5-2640V2:E5产品线,最多两颗CPU共同工作,CPU接口代号是6,CPU编号是40,V2是版本号
服务器内存类型和CPU平台是绑定的,一旦选择了CPU,就只能选择配套的内存类型 P322
目前最新的服务器上使用的是DDR4内存
一些厂商的入门级服务器使用的一般是普通PC的内存,不带ECC功能,需要注意 P323


硬盘的接口
ATA:并口
SATA:串口
SCSI:小型机系统接口,使用较为先进的技术,转速一般为15K转
SAS:新一代SCSI技术,和sata硬盘相同,sas盘和sata盘共享相同的背板,但有更高的传输速度,比sata性能高3-5倍
FC:光纤通道接口
sas接口硬盘需要配置sas卡,超越桌面级硬盘并且寿命更长

raid卡选型 P326
支持的raid级别
缓存大小
是否带电池
1、入门级raid卡,只支持raid1,raid0,raid10,不支持raid5,没有缓存,没有电池
2、支持raid5甚至raid6,有缓存和电池
有些新出的服务器的raid卡在硬件级别支持SSD做缓存
网卡选型 P327
目前常见服务器一般配置4个网口或8个网口,支持1GB/s,10GB/s,40GB/s的带宽
千兆网卡建议选择intel的I350网卡
万兆网卡建议选择intel的x520或x540网卡
因为这些网卡都支持SRIVO,SRIVO是非常好的虚拟化性能解决方案,hyper-v虚拟机默认已经支持SRIVO
选择intel网卡,还因为intel有DPDK技术,DPDK技术是一套开发包,在内核,虚拟化层,Virtio接口都针对intel硬件做了有优化
内存测试 P331
虚拟机的内存占用和释放需要在虚拟机上操作一次,还需要在宿主机上操作一次,即虚拟机的内存实际是被映射了两次
一个虚拟机的IO性能收到很多层cache的影响
虚拟机 os的buffer cache
宿主机 os的buffer cache
raid卡的cache大小和模式
物理硬盘的cache
磁盘测试IO建议使用如下用例 P336
大块连续读 1MB ,顺序读
大块连续写 1MB ,顺序写
小块随机读 4KB ,随机读
小块随机写 4KB,随机写
磁盘IO测试工具
dd命令 P344
dd是系统自带的命令,不需要单独安装,使用很方便,但是只能测试顺序IO性能
使用oflag或iflag可以指定direct/sync/dsync模式,例如下面命令
测试4K块大小文件的顺序写性能directio模式
dd if=/dev/zero of=/tmp/test.file bs=4k count=10000 oflag=direct 10000+0 records in 10000+0 records out 40960000 bytes (41 MB) copied, 35.2022 s, 1.2 MB/s
测试1m块大小文件的顺序写性能directio模式
dd if=/dev/zero of=/mydata/test.file bs=1024k count=10000 oflag=direct 10000+0 records in 10000+0 records out 10485760000 bytes (10 GB) copied, 154.136 s, 68.0 MB/s
测试1m块大小文件的顺序读性能directio模式
dd if=/mydata/test.file of=/dev/zero bs=1024k count=10000 iflag=direct 10000+0 records in 10000+0 records out 10485760000 bytes (10 GB) copied, 140.699 s, 74.5 MB/s
第16章 虚拟机镜像制作、配置和测试
preallocation=metadata 作用 P347
qemu-img create -f qcow2 preallocation=metadata /images/vm1/redhat6.qcow2 100G
要加上preallocation=metadata 或者在virt-install命令参数中指明是qcow2格式,否则使用virt-install命令
安装完成后虚拟机磁盘镜像会变为raw格式
windows虚拟机配置建议表
win2008:cpu 2线程,内存2g,磁盘100g,virtio网卡
win2012r2:cpu 4线程,内存2g,磁盘100g,virtio网卡

第17章 单机虚拟化技术和生产环境实践
对于网络压力大的业务,可以通过开启网卡的SR-IOV(single-root IO virtuallization)
使虚拟机网络性能得到非常高的提升,而SR-IOV目前的特性是不支持迁移的,非常适合单机虚拟化
虚拟机故障的两种方案
1、将虚拟机镜像文件复制到健康的宿主机上,迁移过程中虚拟机不可用
2、将宿主机硬盘拆下来换到备机上
冷迁移虚拟机需要注意新、老宿主机的网卡和网络关系,需要一致,否则,网络不同,虚拟机开机后网络会不通
热迁移:centos6.5之后支持无共享存储的虚拟机热迁移,无共享存储需要先迁移磁盘,再迁移虚拟机内存,消耗时间更长
虚拟机备份:
1、虚拟机关机,然后将xml文件和镜像文件复制到别的地方,然后虚拟机开机
virsh shutdown xx
virsh dumpxml gzxtest01 > ~/gzxtest01.xml
cp /data/kvmimg/gzxtest03.qcow2 /data/backup/
virsh start xx
2、使用libvirt提供的在线块复制和在线外部快照
第18章 KVM虚拟化集群技术和应用场景
笔者在生产环境使用的集群有两种存储方式,即基于商业存储和基于分布式开源文件系统 P386
在虚拟机系统里面,也可以配置应用层的高可用,做这样配置的时候,注意主、备节点要放置到不同的宿主机上 P387
在线迁移不是灾备手段 P388
在线迁移实际迁移的虚拟机的内存,当宿主机发生故障的时候,虚拟机的内存信息已经丢失,这时候是不能再去做虚拟机的在线迁移的,所以
在线迁移解决的是有计划的维护问题,如要升级宿主机内存,可以将宿主机上的虚拟机在线迁移到其他宿主机上,内存升级完成后,再将虚拟机在线迁移回来
商业存储为双控制器,分布式文件系统镜像写多份,网络设备冗余 P388
IP SAN共享存储 P39
SAN即区域存储网络,计算节点通过发送block io请求到存储设备,最常见的就是用iscsi技术,计算节点通过scsi协议发出读取数据的请求,并用
tcp/ip包封装scsi包,就可以在tcp/ip网络中进行传输,即scsi over tcp/ip
FC SAN共享存储 心怡就是用FC SAN
计算节点需要安装光纤接口的HBA卡 host bus adapter提供服务器内部的io通道和存储系统的io通道之间的物理连接,为了冗余hba卡
一般有两块,分别接两个光纤交换机,存储一般有双控制器,也分别接两个光纤交换机,达到全冗余目标。FC SAN计算节点直接将io请求通过
fc网络发送到存储设备,性能非常高
关闭virbr0 P393
安装和开启libvirt的服务后会自动生成virbr0,宿主机上所有的虚拟机都通过virbr0连接起来,默认情况下virbr0使用的是NAT模式,所以,这种情况下
虚拟机通过宿主机才能访问外网,生产环境一般虚拟机使用的是bridge方式(网桥),所以virbr0不是必须的,通过以下方式关闭virbr0:
virsh net-autostart default --disable
virsh net-destroy default
virsh net-undefine default
ifconfig -a
eth0 Link encap:Ethernet HWaddr 52:54:00:DE:ED:8B
inet addr:10.105.45.133 Bcast:10.105.63.255 Mask:255.255.192.0
inet6 addr: fe80::5054:ff:fede:ed8b/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:38865079 errors:0 dropped:0 overruns:0 frame:0
TX packets:34128883 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:15055246737 (14.0 GiB) TX bytes:15988887722 (14.8 GiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:14592846 errors:0 dropped:0 overruns:0 frame:0
TX packets:14592846 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:922681363 (879.9 MiB) TX bytes:922681363 (879.9 MiB)
virbr0 Link encap:Ethernet HWaddr 52:54:00:A4:D8:58
inet addr:192.168.122.1 Bcast:192.168.122.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
virbr0-nic Link encap:Ethernet HWaddr 52:54:00:A4:D8:58
BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:500
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
-----------------------------------------------------------------
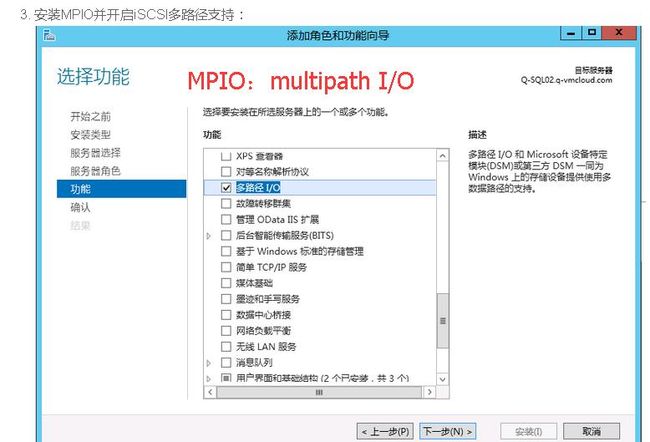
多路径multipath P395
配置multipath实现LUN设备名称的持久化,为了提供冗余,服务器会通过多条线路和存储连接,那么在系统中就会发现
多个存储设备,实际上是一块存储设备,mulitpath多路径服务主要解决这个问题,通过multipath服务,可以将特征相同
的多块存储设备聚合成一块设备,然后给系统使用
#安装multipath所需的安装包
yum install -y device-mapper-multipath iscsi-initiator-utils
#加载multipath模块
modprobe dm-multipath
modprobe dm-round-robin
modprobe dm-service-time
#新建访问接口文件,接口文件保存在/var/lib/iscsi/ifaces目录中
iscsiadm -m iface -I eth2 -o new
iscsiadm -m iface -I eth3 -o new
#配置iface ,通过 eth2,eth3两个接口访问
iscsiadm -m iface -I eth2 --op=update -n iface.net_ifacename -v eth2
iscsiadm -m iface -I eth3 --op=update -n iface.net_ifacename -v eth3
略。。。
Windows2012R2下的multipath MPIO
---------------------------------------------------------------------------------------
管理节点的配置 P398
默认情况下,每个PV中保存一份元数据,元数据以ASCII格式存储,元数据在系统上会保持备份
在/etc/lvm/ 目录下保持最新版本,在/etc/lvm/archive目录下保存旧版本
在/etc/lvm/cache目录下保存lvm文件缓存
通过pvcreate等操作将第一份数据覆盖后,可通过第二份数据进行恢复,在集群中将元数据设置保存为两份
命令如下
pvcreate --metadatacopies 2 /dev/mapper/ipsanmp1
vgcreate vmVG $PV
/etc/lvm/lvm.conf
locking_type参数
locking_type=1
1表示对vg有读写权限,4表示只读权限
cd /etc/lvm/
[root@VM_45_133_centos lvm]# ll
total 80
drwx------. 2 root root 4096 Oct 16 2014 archive
drwx------. 2 root root 4096 Oct 16 2014 backup
drwx------. 2 root root 4096 Oct 16 2014 cache
-rw-r--r--. 1 root root 58444 Oct 16 2014 lvm.conf
drwxr-xr-x. 2 root root 4096 Jul 10 2015 profile
整个数据中心采用大二层架构,便于虚拟机主机的漂移和灵活性 P403
什么是VPC P403
vpc 虚拟私有云 virtual private cloud,是公有云上的一个网络概念,相当于公有云里面的一个内网,基于用户划分内网
用户选择公有云最大的顾虑是安全问题,公有云安全包含两个层面
1、数据安全:数据会不会窃取,丢失
2、服务安全:使用公有云,依靠的是公有云的服务支持,用户担心,如果公有云出现大面积问题,是否会对自己服务造成影响
VPC实际上是基于网络的安全解决方案,VPC将同一用户的云主机隔离在一个逻辑网络内部,只有用户自己能访问自己的私有网络
VPC使用场景
大量使用内网IP地址,只需将暴露的服务通过NAT映射出去,云主机无公网IP
将VPC和自己的企业内网或者自己的私有数据中心打通,将公有云变成自己私有云的一部分
通过VPC的使用,可以从网络层面大大提高用户使用公有云的安全性,做到只需暴露的暴露,不需暴露的完全在网络层面关闭
IP地址划分
外网段
内网段
业务内网段
存储段
虚拟机迁移管理 P405
动态迁移、在线迁移、热迁移
热迁移过程中如果断网 可能会导致虚拟机无法启动,最好用开一个网段做迁移
虚拟机在线迁移的认证方式 P399
TCP方式:走TCP通道,没有加密,生产环境一般不用
SSH方式:走SSH通道,已加密,生产环境建议使用,需要宿主机配置免密码SSH认证 (方法: 在迁移命令后面加 qemu+ssh://用户@新宿主机IP:端口/system )
TLS方式:基于证书加密,生产环境建议使用
迁移工具
可以通过qemu层,也可以使用Libvirt工具迁移,Libvirt工具迁移支持加密和认证,安全性更好,一般生产环境使用Libvirt工具迁移
Libvirt工具迁移需要配置认证
基于共享存储
1、迁移命令 virsh migrate ,10.10.10.20为目标宿主机的内网IP
virsh migrate --live --copy-storage-all --unsafe --persistent centos1 qemu+ssh://[email protected]:22/system
2、在源宿主机执行,会显示paused状态
virsh list --all
3、在目标宿主机执行,显示迁移进度
tailf /var/log/libvirt/qemu/gzxtest09.log
4、虚拟机迁移完成后,源宿主机为关机状态,目标宿主机变为running状态
virsh list --all #源宿主机
virsh list --all #目标宿主机
基于本地存储 (存储块动态迁移技术,简称块迁移)
基于本地存储的在线迁移跟基于共享存储的在线迁移方法一样
静态迁移、离线迁移、冷迁移 P407
基于共享存储
基于共享存储的离线迁移跟基于本地存储方法一样,只是不需要拷贝镜像文件
基于本地存储
1. 停用 虚拟机
[root@hkxvmm02 vmserver]# virsh list --all
Id Name State
----------------------------------------------------
9 hkwapp02 running
10 hkwapp03 running
13 hkxrmq01 running
16 hkwrdp01 running
18 hkxzbx01 running
- hkwsql04 shut off
2 .拷贝XML 和 镜像文件 到新服务器
XML位置
/etc/libvirt/qemu/hkwsql04.xml
镜像位置
/data/vmserver/hkwsql04.qcow2
修改xml文件中的镜像位置,找到source file这一项
3.在新服务器上重新定义虚拟机
virsh define /etc/libvirt/qemu/hkwsql04.xml
7.重新启动
# virsh start hkwsql04
Domain hkwsql04 started
[root@hkxvmm02 vmserver]# virsh list
Id Name State
----------------------------------------------------
1 hkwsql04 running
商业存储的备份 P408
1、使用磁带库,成本低,但是备份过程时间长,效率低,虚拟磁带库,容量大
2、使用存储的镜像功能,多台存储使用同步或异步方式进行备份,成本高,开通存储的镜像功能,效率高,容量小
第21章 虚拟化监控,报警与应急响应方案
物理内存的情况 P456
内核把内存页分成以下不同的区(zone)
zone_dma:这个区用来执行dma操作,以便设备用来访问
zone_normal:这个区给应用使用的页
zone_highmem:高端内存,内核通过映射的方式使用,mmap
X86上zone_dma为0~16mb的内存范围,zone_highmem为高于896mb的物理内存,中间的是zone_normal区
使用dmidecode命令可以查看物理内存的详细信息
dmidecode
。。。
Physical Memory Array
Location: System Board Or Motherboard
Use: System Memory
Error Correction Type: Single-bit ECC
Maximum Capacity: 64 GB
Error Information Handle: Not Provided
Number Of Devices: 4
Handle 0x1100, DMI type 17, 40 bytes
Memory Device
Array Handle: 0x1000
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: 8192 MB
Form Factor: DIMM
Set: 1
Locator: A1
Bank Locator: Not Specified
Type: DDR4
Type Detail: Synchronous
Speed: 2133 MHz
Manufacturer: 00AD00000000
Serial Number: 91411655
Asset Tag: 00160200
Part Number: HMA41GU7AFR8N-TF
Rank: 2
Configured Clock Speed: 2133 MHz
Minimum Voltage: 1.2 V
Maximum Voltage: 1.2 V
Configured Voltage: 1.2 V
Handle 0x1101, DMI type 17, 40 bytes
Memory Device
Array Handle: 0x1000
Error Information Handle: Not Provided
Total Width: 72 bits
Data Width: 64 bits
Size: 8192 MB
Form Factor: DIMM
Set: 1
Locator: A2
Bank Locator: Not Specified
Type: DDR4
Type Detail: Synchronous
Speed: 2133 MHz
Manufacturer: 00CE00000800
Serial Number: 732AF873
Asset Tag: 00154200
Part Number: M391A1G43DB0-CPB
Rank: 2
Configured Clock Speed: 2133 MHz
Minimum Voltage: 1.2 V
Maximum Voltage: 1.2 V
Configured Voltage: 1.2 V
Handle 0x1102, DMI type 17, 40 bytes
Memory Device
Array Handle: 0x1000
Error Information Handle: Not Provided
Total Width: Unknown
Data Width: Unknown
Size: No Module Installed
Form Factor: Unknown
Set: 2
Locator: A3
Bank Locator: Not Specified
Type: Unknown
Type Detail: None
Speed: Unknown
Manufacturer: Not Specified
Serial Number: Not Specified
Asset Tag: Not Specified
Part Number: Not Specified
Rank: Unknown
Configured Clock Speed: Unknown
Minimum Voltage: Unknown
Maximum Voltage: Unknown
Configured Voltage: Unknown
Handle 0x1103, DMI type 17, 40 bytes
Memory Device
Array Handle: 0x1000
Error Information Handle: Not Provided
Total Width: Unknown
Data Width: Unknown
Size: No Module Installed
Form Factor: Unknown
Set: 2
Locator: A4
Bank Locator: Not Specified
Type: Unknown
Type Detail: None
Speed: Unknown
Manufacturer: Not Specified
Serial Number: Not Specified
Asset Tag: Not Specified
Part Number: Not Specified
Rank: Unknown
Configured Clock Speed: Unknown
Minimum Voltage: Unknown
Maximum Voltage: Unknown
Configured Voltage: Unknown
Handle 0x1300, DMI type 19, 31 bytes
Maximum Capacity: 64 GB 服务器最大支持64g内存
Number Of Devices: 4 有4个内存插槽
Error Correction Type: Single-bit ECC 使用ecc纠错技术
dmidecode |grep "Memory Device" |wc -l 有4个内存插槽
4
Memory Device
Size: 8192 MB 插槽1插了一条8g内存条
Type: DDR4 DDR4内存
Speed: 2133 MHz 频率2G
Size: No Module Installed 表示这个插槽没有插内存条
硬盘吞吐和利用率监控 P477
默认的zabbix监控模板中,对于磁盘只有对空间使用情况的监控,对于IO方面却没有自带的“监控项”,并且每台服务器的磁盘
名称可能不一样(如 sda,hda,vda),所以需要用到zabbix的功能之一 的LLD发现磁盘并监控IO,他可以做到自适应不同的
磁盘名称监控,原理是通过抓取系统文件cat /proc/diskstats 中的内容进行展示
cat /proc/diskstats
1 0 ram0 0 0 0 0 0 0 0 0 0 0 0
1 1 ram1 0 0 0 0 0 0 0 0 0 0 0
1 2 ram2 0 0 0 0 0 0 0 0 0 0 0
1 3 ram3 0 0 0 0 0 0 0 0 0 0 0
1 4 ram4 0 0 0 0 0 0 0 0 0 0 0
1 5 ram5 0 0 0 0 0 0 0 0 0 0 0
1 6 ram6 0 0 0 0 0 0 0 0 0 0 0
1 7 ram7 0 0 0 0 0 0 0 0 0 0 0
1 8 ram8 0 0 0 0 0 0 0 0 0 0 0
1 9 ram9 0 0 0 0 0 0 0 0 0 0 0
1 10 ram10 0 0 0 0 0 0 0 0 0 0 0
1 11 ram11 0 0 0 0 0 0 0 0 0 0 0
1 12 ram12 0 0 0 0 0 0 0 0 0 0 0
1 13 ram13 0 0 0 0 0 0 0 0 0 0 0
1 14 ram14 0 0 0 0 0 0 0 0 0 0 0
1 15 ram15 0 0 0 0 0 0 0 0 0 0 0
7 0 loop0 0 0 0 0 0 0 0 0 0 0 0
7 1 loop1 0 0 0 0 0 0 0 0 0 0 0
7 2 loop2 0 0 0 0 0 0 0 0 0 0 0
7 3 loop3 0 0 0 0 0 0 0 0 0 0 0
7 4 loop4 0 0 0 0 0 0 0 0 0 0 0
7 5 loop5 0 0 0 0 0 0 0 0 0 0 0
7 6 loop6 0 0 0 0 0 0 0 0 0 0 0
7 7 loop7 0 0 0 0 0 0 0 0 0 0 0
252 0 vda 17330 78 455020 183187 202370 189272 3133224 1390072 0 699621 1573131
252 1 vda1 17178 68 453724 183148 202370 189272 3133224 1390072 0 699593 1573092
252 16 vdb 41578 521 671264 245621 2927883 7592724 82924008 15557716 0 6351236 15801097
252 17 vdb1 41492 520 670568 245464 2772776 7592724 82924008 15478697 0 6272457 15721980
252 32 vdc 820 4446 13382 3917 321 28412 229864 8529 0 5869 12444
252 33 vdc1 797 4437 13126 3793 321 28412 229864 8529 0 5779 12320
json格式是zabbix接受的格式
网络IO监控 P485
zabbix同样可以通过自动发现网卡,原理跟磁盘自动发现一样,不过zabbix本身已经提前写好了发现功能模板,只需要
在功能模板进行简单定制后即可满足需求
他可以做到自适应不同的网卡名称监控,原理是通过抓取系统文件cat /proc/net/dev 中的内容进行展示
cat /proc/net/dev
Inter-| Receive | Transmit
face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed
lo: 428931041 5495077 0 0 0 0 0 0 428931041 5495077 0 0 0 0 0 0
eth0: 11840841339 150603347 0 0 0 0 0 0 17255300403 184305349 0 0 0 0 0 0
zabbix可以监控发包数,丢包数,错误包数都可以使用zabbix自带的监控项来实现 P486
应急方案制定注意要点 P487
虚拟化层灾备就是做虚拟机镜像的多份复制和快照,应用层做灾备就是将虚拟机像物理机一样灾备,原来在
物理机上如何灾备,现在在虚拟机用同样的方法进行灾备。一般建议使用应用层灾备方法,因为在虚拟化层做灾备
要消耗大量磁盘空间,并且做多个快照,会影响虚拟机性能,而在应用层做灾备,消耗的资源比较少,而且可以做到
精准备份,即只需备份必要的部分。如果要做好应用层的灾备,就需要在应用层提升自动化运维的水平,自动化运维
水平越高,越有利于提升灾备和恢复的效率
服务器常用raid卡主要是LSI和HP服务器专用raid卡 P491
LSI低端raid卡使用lsiutil工具,高端raid卡使用MegaCli64工具
使用Lsiutil管理Dell SAS 6i/R
Dell的好多型号(如R410,R610)服务器默认的RAID控制器都是SAS 6i/R ,对于这款控制器MegaCli是不能使用的。在命令行模式下想管理SAS 6i/R,需要使用Lsiutil这个工具。
Lsiutil下载地址:ftp://ftp.lsil.com/HostAdapterDrivers/linux/lsiutil/lsiutil.tar.gz
Lsiutil有两种使用方法: 菜单驱动的交互使用 和 命令行
不带任何参数执行lsiutil,就会进入lsiutil的交互模式。在这个模式下,所有的操作都是通过文本菜单来进行的,举例如下:
[root@Dell1950 ~]# lsiutil
命令行模式举例如下:
lsiutil –p1 –a 21,1,0,0,0 和上边菜单操作一样,只不过不用手动去选择菜单项了
lsiutil -p 1 -i –s 显示端口1的设置和连接的设备
lsiutil –s 显示所有端口上连接的设备
lsiutil -p 2 -l 1 强制HBA卡端口2连接速度为1Gb
HP的raid卡使用HPACUCli工具
DELL 和IBM的pc server都是基于lsi公司的raid卡,都可用MegaCli工具来管理
megacli-8.35.46-2.x86_64 (8.xx 都是最新版本)
MegaCli -h/--help
新版本的可执行文件可能是MegaCli64
惠普
hpacucli
hpacucli(cli端) => hpacu(gui端)
下面是宿主机上使用的一个脚本,通过crontab,每天在凌晨检查一次硬盘,当发现有硬盘故障的时候 P492
就会调用python发邮件的一个脚本,发邮件处理,脚本供读者参考
cat /bin/checkdisk.sh
#!/bin/bash source /etc/profile myip=$(/sbin/ifconfig |grep "inet addr") myname=$(hostname) echo $myip >/tmp/q.txt echo $myname >>/tmp/q.txt yum install -y dmidecode #生成临时文件,把ip,服务器名字写入临时文件 check_mpt() #通过mtp的raid卡管理程序,检查是否有硬盘故障 { find /bin/lsiutil.x86_64 if [ $? = 1 ] ;then bash /opt/sys_scripts/misc/check_disk/install.sh reinstall fi /bin/lsiutil.x86_64 -pl -a 21,2,0,0 |grep offline if [ $? = 0 ] ;then echo $myip>/tmp/errmsg /bin/lsiutil.x86_64 -pl -a 21,2,0,0 >> /tmp/errmsg /usr/bin/python /bin/pymail $myname fi } check_Mega() { find /bin/MegaCli64 if [ $? = 1 ] ;then bash /opt/sys_scripts/misc/check_disk/install.sh reinstall fi /bin/MegaCli64 -PdGetMissing -aALL |grep "No Missing" if [ $? = 0 ] ;then errmsg=$(/bin/MegaCli64 -PdGetMissing -aALL) else echo $myip >/tmp/errmsg /bin/MegaCli64 -PdGetMissing -aALL >> /tmp/errmsg /usr/bin/python /bin/pymail #myname fi critical_disk=$(/bin/MegaCli64 -AdpAllInfo -aALL|grep "Critical Disks|sed 's/^[ ]*//g'|awk -F ":" '{print $2}'|sed 's/^[ ]*//g') failed_disk=$(/bin/MegaCli64 -AdpAllInfo -aALL|grep -i "Failed Disks"|sed 's/^[ ]*//g'|awk -F ":" '{print $2}'|sed 's/^[ ]*//g') if [ $critical_disk -gt 0 -o $failed_disk -gt 0 ] ;then echo $myip >/tmp/errmsg echo -e "\n" >>/tmp/errmsg /bin/MegaCli64 -AdpAllInfo -aALL|grep -i -EA9 "Device Present">>/tmp/errmsg /usr/bin/python /bin/pymail $myname else echo $(/bin/MegaCli64 -AdpAllInfo -aALL|grep -i -EA9 "Device Present") fi } check_hp() #通过HP的raid卡管理程序检查是否有硬盘故障 { find /usr/sbin/hpacucli if [ $? = 1 ];then bash /opt/sys_scripts/misc/check_disk/install.sh reinstall fi /usr/sbin/hpacucli ctrl slot=0 pd all show status |grep Failed if [ $? = 0 ] ;then echo $myip>/tmp/errmsg /usr/sbin/hpacucli ctrl slot=0 pd all show status>>/tmp/errmsg /usr/bin/python /bin/pymail $myname fi } check_RAID_type() #通过lspci命令确定是哪种raid卡 { lspci|grep "MPT"|grep "LSI" >/dev/null if [ $? = 0 ];then RAID_type="MPT" check_mpt fi lspci|grep "MegaRAID"|grep "LSI" >/dev/null if [ $? = 0 ];then RAID_type="Mega" check_Mega fi lspci|grep "Hewlett_packard"|grep "LSI" >/dev/null if [ $? = 0 ];then RAID_type="HP" check_hp fi dmidecode |grep "ProLiant" >/dev/null if [ $? = 0 ];then RAID_type="HP" check_hp fi } check_RAID_type
第22章 生产环境问题案例和分析
宿主机强制关机导致虚拟机无法启动案例 P522
启动虚拟机的时候报错
Unable to read from monitor: Connection reset by peer
宿主机系统为centos6.x
原因:在未完成内存保存的情况下,重启宿主机,会造成虚拟机再次启动的时候,虚拟机状态文件读取错误,从而虚拟机不能启动
虚拟机的状态保存文件路径是/var/lib/libvirt/qemu/save/
解决办法:直接删除状态保存文件,或者执行managedsave-remove 命令,再启动虚拟机,问题解决
# virsh managedsave-remove win7
Removed managedsave image for domain win7
# virsh start win7
域 win7 已启动
建议:宿主机重启的时候,建议先关闭虚拟机,再重启宿主机
windows7虚拟机只能使用2个CPU案例 P524 这个问题应该是肖力或kvm问题,在hyper-v上没有这个问题
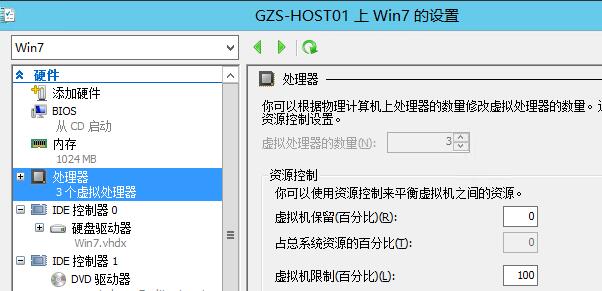

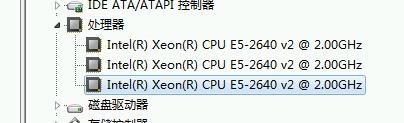
通过微软网站查找资料,发现windows7最多只支持两个cpu socket,即两颗物理机CPU,但是,每个物理CPU内可以有多个core
如果配置给虚拟机的是模拟多颗物理CPU,那么windows7系统就只能使用两个
KVM默认每个CPU模拟一个socket,必须修改虚拟机cpu的拓扑,才能使用超过一个CPU
解决办法是修改为一个socket内有多个core
xml配置文件
kvm 一个物理核 四个逻辑核 一个物理核心四线程
virt-install --name=gzxtest02 --ram 4096 --vcpus=16 虚拟机创建分配的是逻辑线程
cat /proc/cpuinfo |grep processor
processor : 0
processor : 1
processor : 2
processor : 3
cat /proc/cpuinfo |grep 'core id'
core id : 0
core id : 0
core id : 0
core id : 0
hyper-v 四个物理核 四个逻辑核 一个物理核心四个线程 总共16线程
虚拟机创建分配的是物理核心和逻辑线程数,需要进行乘法得出最终线程数
cat /proc/cpuinfo | grep processor
processor : 0
processor : 1
processor : 2
processor : 3
cat /proc/cpuinfo |grep 'core id'
core id : 0
core id : 1
core id : 2
core id : 3
机房断电引起的宿主机重启 P529
修改raid设置,跳过开机因为raid卡BBU无电的错误界面 BE=bypass error
MegaCli -AdpBios -BE –a0
默认是dsply=display
MegaCli -AdpBios -dsply –a0
机房断点引起虚拟机文件系统错误 P530
加载系统盘,编辑虚拟机的xml文件,加载iso光驱
编辑虚拟机的启动方法,在os的标签处添加cdrom,并放在第一项,命令如下
修改为
宿主机使用kvm的好处
生产环境存储故障导致50个虚拟机丢失案例 P532
在宿主机做监控
所有线上存储,磁盘监控SMART信息,有10个以上的坏块就报警
使用存储的镜像功能
全部使用raid10
ubuntu虚拟机内核频繁崩溃问题 P534
默认ubuntu12.04没有配置内核崩溃自动重启及转存,造成发生内核崩溃的时候,
没有core dump文件去分析,并且卡死在内核崩溃界面,为了方便查找内核崩溃原因,需要将内核崩溃自动重启配置及内核转存配置起来,配置步骤如下:
第一步 配置内核崩溃自动重启
添加kernel.panic到内核参数,10为内核崩溃10秒之后,自动重启系统
vi /etc/sysctl.conf
kernel.panic = 10
第二步 验证自动重启机制是否生效,需要配置sysrq
添加kernel.sysrq 到内核参数,1为生效
vi /etc/sysctl.conf
kernel.sysrq = 1
运行命令,使配置的参数生效,或者重启系统
sysctl -p /etc/sysctl.conf
检查配置的参数是否生效
cat /proc/sys/kernel/panic
10
cat /proc/sys/kernel/sysrq
1
模拟系统内核崩溃,同时按alt+sysrq+c三个键,或者运行如下命令
echo c >/proc/sysrq
看以看到内核崩溃,并读秒重启
第三步 配置内核转存
新装的系统需要升级下,否则不能通过apt-get安装软件
apt-get update
安装内核转存
sudo apt-get install linux-crashdump
查看是否生效
cat /proc/cmdline
ro root=UUID=d845dbbd-8e42-4a58-a6ff-90313562f232 rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=129M@0M KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM rhgb quiet
测试,模拟系统内核崩溃,同时按alt+sysrq+c三个键,或者运行如下命令
发现系统崩溃,并卡死住,没有发送转存,也没有重启!
经过查找资料,发送这样的情况,
可能和core dump内存配置不够有关系,
于是修改了core dump内存配置内存配置
cd /etc/grub.d/
vi 10_linux
修改成512M大小
crashkernel=384M-2G:64M,2G-:512M
重新生成grub.cfg
grub-mkconfig -o /boot/grub/grub.cfg
再测试,成功。
问题
遇到virsh命令无反应需要重启libvirtd服务

/etc/init.d/libvirtd restart
用哪个厂家的服务器就注定要用那家的硬盘
戴尔服务器用戴尔原装硬盘


每一个虚拟机都对应每个物理机的vnet虚拟网卡
virsh list --all
Id Name State
----------------------------------------------------
1 gzxtest02 running
2 gzxtest04 running
4 gzxtest03 running
- gzxtest09 shut off
[root@gzxkvm53 ~]# ifconfig -a
br0 Link encap:Ethernet HWaddr 34:17:EB:F0:04:6B
inet addr:10.11.30.53 Bcast:10.11.30.255 Mask:255.255.255.0
inet6 addr: fe80::3617:ebff:fef0:46b/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:5743351 errors:0 dropped:0 overruns:0 frame:0
TX packets:56943 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:692330471 (660.2 MiB) TX bytes:5007556 (4.7 MiB)
em1 Link encap:Ethernet HWaddr 34:17:EB:F0:04:6B
inet6 addr: fe80::3617:ebff:fef0:46b/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:6263348 errors:51 dropped:0 overruns:0 frame:40
TX packets:3195751 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:930033726 (886.9 MiB) TX bytes:1959941318 (1.8 GiB)
Interrupt:16
em2 Link encap:Ethernet HWaddr 34:17:EB:F0:04:6C
BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
Interrupt:17
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:18 errors:0 dropped:0 overruns:0 frame:0
TX packets:18 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1554 (1.5 KiB) TX bytes:1554 (1.5 KiB)
vnet0 Link encap:Ethernet HWaddr FE:54:00:B7:B9:F2
inet6 addr: fe80::fc54:ff:feb7:b9f2/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:3301490 errors:0 dropped:0 overruns:0 frame:0
TX packets:4810193 errors:0 dropped:0 overruns:501 carrier:0
collisions:0 txqueuelen:500
RX bytes:2194463404 (2.0 GiB) TX bytes:681705310 (650.1 MiB)
vnet1 Link encap:Ethernet HWaddr FE:54:00:1B:90:B4
inet6 addr: fe80::fc54:ff:fe1b:90b4/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:2582 errors:0 dropped:0 overruns:0 frame:0
TX packets:3425322 errors:0 dropped:0 overruns:1002 carrier:0
collisions:0 txqueuelen:500
RX bytes:687276 (671.1 KiB) TX bytes:466564653 (444.9 MiB)
vnet2 Link encap:Ethernet HWaddr FE:54:00:58:81:48
inet6 addr: fe80::fc54:ff:fe58:8148/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:56767 errors:0 dropped:0 overruns:0 frame:0
TX packets:3651241 errors:0 dropped:0 overruns:501 carrier:0
collisions:0 txqueuelen:500
RX bytes:5171782 (4.9 MiB) TX bytes:752522079 (717.6 MiB)
qemu版本
centos6.8 下面执行
@符号表示这个软件已经安装了
yum list |grep qemu
gpxe-roms-qemu.noarch 0.9.7-6.15.el6 @base
qemu-img.x86_64 0.12.1.2-2.491.el6_8.3 @updates
qemu-kvm.x86_64 0.12.1.2-2.491.el6_8.3 @updates
qemu-kvm-tools.x86_64 0.12.1.2-2.491.el6_8.3 @updates
qemu-guest-agent.x86_64 0.12.1.2-2.491.el6_8.3 updates
vdsm-hook-faqemu.noarch 4.16.20-1.git3a90f62.el6 epel
vdsm-hook-qemucmdline.noarch 4.16.20-1.git3a90f62.el6 epel
rpm -qf /usr/bin/qemu-img
qemu-img-0.12.1.2-2.491.el6_8.3.x86_64
虚拟机的monitor目录
ll /var/lib/libvirt/qemu
total 12
srwxr-xr-x 1 qemu qemu 0 Nov 13 00:20 CQ-HAPROXY02.monitor
srwxr-xr-x 1 qemu qemu 0 Nov 12 21:15 CQ-MONITOR02.monitor
srwxr-xr-x 1 qemu qemu 0 Nov 12 23:42 CQ-NGINX02.monitor
srwxr-xr-x 1 qemu qemu 0 Nov 15 23:16 CQ-TEST01.monitor
drwxr-xr-x 2 root root 4096 Nov 10 14:03 dump
drwxr-xr-x 2 qemu qemu 4096 Nov 10 14:03 save
drwxr-xr-x 2 qemu qemu 4096 Nov 10 14:03 snapshot
目前2.3.0-31是比较稳定的版本

f