C++学习章节要点总结
第三章 处理数据
3.1.1 变量名
变量名的起名一般表示该变量有什么作用即一定含义的变量名。关于变量名,必须遵循以下C++的命名规则。
- 在名称中,只能使用字母字符、数字和下划线。
- 变量名的第一个字符不能是数字。
- 变量名区分大小写。
- 不能将C++关键字用作名称。
- 以两个下划线或下划线和大写字母打头的名称被保留给实现(编译器及其使用的资源)使用。以一个下划线开头的名称将被保留给实现,用作全局标识符。(这样命名可能会导致行为的不确定性。即不知道会出现什么结果。编译器不报错的原因为这样命名并不是非法的,但要留给实现使用。)
-
在有一些平台中,对名称的长度有所限制。但C++对名称的长度是没有限制的。
3.1.2 整型
整数就是没有小数部分的数字。
3.1.3 整型short、int、long和long long
C++的short、int、long和long long类型通过不同数目的位来存储值,最多能够表示4种不同的整数宽度。
计算机内存的基本单位是位(bit)。可以将位看作是电子开关,可以开,也可以关。关表示的值为0,开表示的值为1。4位的内存块可以设置出64种不同的组合,因为每一位都有两种情况即2x2x2x2=64种。
字节(byte)通常是指8位的内存单元。字节就是描述计算机的度量单位,1KB=1024字节,1MB=1024KB。
下面一段代码为各种类型的长度。
#include
#include
using namespace std;
int main()
{
int n_int = INT_MAX;
short n_short = SHRT_MAX;
long n_long = LONG_MAX;
long long n_llong = LLONG_MAX;
//sizeof operator yields size of type or of variable
cout << "int is " << sizeof(int) << "bytes." << endl;
cout << "short is " << sizeof n_short << "bytes" << endl;
cout << "longlong is" << sizeof n_llong << "bytes" << endl;
cout << "long is" << sizeof n_long << "bytes" << endl;
cout << "Maximum values:" << endl;
cout << "int: " << n_int << endl;
cout << "short: " << n_short << endl;
cout << "long: " << n_long << endl;
cout << "long long: " << n_llong << endl<< endl;
cout << "Minimum int value=" << INT_MIN << endl;
cout << "Bits per byte =" << CHAR_BIT << endl;
return 0;
} 关于sizeof使用的一个小tip:对类型名使用sizeof运算符的时候要带括号,但对变量名使用sizeof的时候括号可以不带
关于初始化,一般都是初始化将赋值与声明合并在一起。有一种初始化方式为C++11初始化方式,这种方式用于数组和结构。(int owl={3};//将3赋值给owl int owl={}//将owl初始化值为0)
3.1.4 无符号类型
例,short表示的范围为-32768到+32768,则无符号版本表示的范围为0到+65535。要创建无符号版本的基本整型,只需要使用关键字unsigned来创建。
下面有一段代码关于无符号类型与有符号类型的区别。
#include
#include
using namespace std;
int main()
{
short sam = SHRT_MAX;
unsigned short sue = sam;
cout << "Sam has " << sam << "dollars and Sue has " << endl;
cout << " dollars deposited .\nPoor Sam!" << endl;
sam = 0;
sue = 0;
cout << "Sam has " << sam << " dollars and Sue has" << sue;
cout << "dollars deposited." << endl;
cout << "take 1 dollar from each account." << endl << "Now";
sam = sam - 1;
sue = sue - 1;
cout << "sam has" << sam << "dollars and sue has" << sue;
cout << " dollars deposited." << endl << "Lucky sue!" << endl;
return 0;
} short变量最大值为32767,而在最大值上加一,则值将会变成-32768。而对于无符号类型,则值变为32768。
3.1.5 选择整型类型
int被设置为对目标计算机而言最为自然的长度。自然长度是指计算机处理起来效率最高的长度。如果没有非常有说服力的理由来选择其他类型,则应使用int。
3.1.6 整型字面值
- 在默认情况下,cout以十进制格式显示整数,而不管这些整数在程序中是如何书写的。
-
如果需要输出八进制或者十六进制可以在输出前打cout<
3.1.7 如何确定常量的类型
除非值太大了,一般情况下C++都将整型常量存储为int类型。
3.1.8 char类型:字符和小数点
char类型是专为存储字符(如字母和数字)而设计的,char最常被用来处理字符,但也可以将它用做比short更小的整型。
对字符使用单引号,对字符串使用双引号。
关于cout.put()函数的使用,代码如下。
#include
using namespace std;
int main()
{
char ch = 'M';
int i = ch;
cout << "The ASCII code for" << ch << "is" << i << endl;
ch = ch + 1;
i = ch;
cout << "The ASCII code for" << ch << "is" << i << endl;
cout << "Displaying char ch using cout.put(ch):";
cout.put(ch);
cout.put('!');
cout << endl << "done" << endl;
return 0;
} tips:cout.put()函数,该函数只显示一个字符。//句点被称为成员运算符,cout.put()的意思是通过类对象cout来使用函数put()。该成员函数提供了另一种显示字符的方法,可以替代<<运算符。
下面是C++转义序列的编码,从网上找的图。
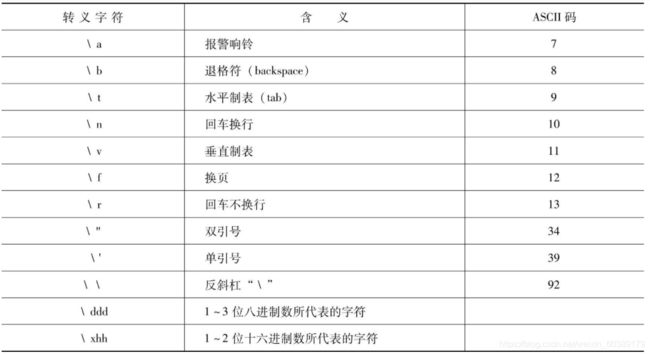
关于Unicode和ISO10646
Unicode提供了一种表示各种字符集的解决方案——为大量字符和符号提供标准数值编码,并根据类型将它们分组。Unicode给每个字符制定一个编号——码点。ISO 10646也是一个对多种语言文本进行编码的标准。
wchar_t类型是一种整数类型,它有足够的空间,可以表示系统使用的最大扩展字符集。这种类型与另一种整型(underlying类型(底层类型))长度和符号属性相同,对底层类型的选择取决于实现。因此在一个系统中,它可能是unsigned short,而在另一个系统中则可能是int。
cin和cout输入和输出看成是char流,因此不适用于处理wchar_t类型。iostream 头文件的最新版提供了作用相似的工具——wcin和wcout,可用于处理wchar_t流。另外,可以通过加上前缀L来指示字符常量和宽字符串。
C++11新增类型:char16_t和char32_t两者皆是无符号类型的。与wchar_t类型一样,都具有底层类型,但底层类型可能会随系统改变而已。
3.1.9 bool类型
布尔变量的值可以是true或false,任何非零值都会被转换为true,零值被转换为false。
3.2 const限定符
如果程序在多个地方需要使用同一个常量,若需修改只需修改一个符号即可。在c语言中用#define来进行定义,在C++中一般使用const。
const相比#define来说更方便。
- const能够明确指定类型。
- const可以使用C++的作用域规则将定义限制在特定的函数或文件中。
- const可以用于更复杂的类型。
3.3 浮点数
浮点类型是C++的第二组基本类型。浮点数能够表示带小数部分的数字。
计算机将带有小数点的数字的值分两部分储存,一部分表示值,另一部分用于对值进行放大或缩小。
C++有两种书写浮点数的方式。
- 第一种是标准小数点表示法。即1.2,5.6798,9231.32等。
- 第二种是E表示法。如3.45E6,表示的事3.45与1000000相乘的结果;E6表示的是10的6次方。6被称为指数,3.45被称为尾数。E表示法最适合于非常大和非常小的数。注意:-3.45E6则表示为3.45x106,3.45E-6则表示3.45÷106。前面的符号用于数值,而指数的符号用于缩放。d.dddE+n指的是小数点向右移动n位,d.dddE-n指的是小数点向左移动n位。
3.3.2 浮点类型
C++有3种浮点类型,分别是:float,double和long double。这些类型是按它们可以表示的有效数位和允许的指数最小范围来描述的。(有效位是数字中有意义的位。如数字14000有效位为2位,12345有效位为5位。)C和C++对于有效位的要求是float至少为32位,double至少为48位,且不少于float,long double,至少和double一样多。double的精度相对于float更高。
下面一段代码演示了float和double类型表示数字的时候在精度方面的差异。
#include
using namespace std;
int main() {
cout.setf(ios_base::fixed, ios_base::floatfield);//这种调用迫使输出使用定点表示法,以便更好地去了解精度,它防止把较大的值切换为E表示法,并将程序显示到小数点后6位。
float tub = 10.0 / 3.0;
double mint = 10.0 / 3.0;
const float million = 1.0e6;
cout << "tub =" << tub;
cout << ", a million tubs =" << million * tub;
cout << ",\nand ten million tubs=";
cout << 10 * million * tub << endl;
cout << "mint=" << mint << "and a million mints =";
cout << million * mint << endl;
return 0;
} 通常情况下,cout会删除结尾的零,调用cout.setf会覆盖这种行为。
float类型只能表示数字中的前6位或前7位。double类型确保有15位精确位。
3.3.3 浮点常量
在默认情况下,3.21,3.23E6都被储存为double类型,如果希望常量被储存为浮点类型则需使用f或F后缀。对于long double型,则需使用l或L后缀。
3.3.4 浮点数的优缺点
与整数相比,浮点数有两大优点,首先,它们可以表示整数之间的值,其次,由于有缩放因子,它们可以表示的范围大得多。缺点为,浮点运算的速度通常比整数运算慢,且精度将降低。
下面一段代码表明了浮点数的缺点。
#include
using namespace std;
int main()
{
float a = 2.34E+22f;
float b = a + 1.0f;
cout << "a=" << a << endl;
cout << "b-a=" << b - a << endl;
return 0;
} b-a结果应该为1,但最终显示为0。因为2.34E+22是一个小数点左边有23位的数字,加上1就是在23位上加1。但float类型只能表示数字中的前6位或前7位,因此修改第23位对这个值不会有任何影响。
3.4 C++算术运算符
下面是5种基本的c++算术运算符。
- +运算符对操作数执行加法运算。
- -运算符对操作数执行减法运算。
- *运算符对操作数执行乘法运算。
- /运算符用第一个数除以第二个数。如果两个操作数都是整数,则结果为商的整数部分。
- %运算符,它生成第一个数除以第二个数后的余数。%的操作数只能是整数。
下面一段程序代码是关于运算符的运用。
#include
using namespace std;
int main() {
int hats,heads;
cout << "请输入你想要购买的帽子数:(整数)";
cin >> hats;
cout << "请输入有几个人:(整数)";
cin >> heads;
cout << "hats+heads=" << hats + heads << endl;
cout << "hats-heads=" << hats - heads << endl;
cout << "hats*heads=" << hats * heads << endl;
cout << "hats/heads=" << (double)hats / heads << endl;
cout << "hats%heads=" << hats % heads << endl;
return 0;
} 3.4.1 运算符优先级和结合性
下面这张图展示了运算符的优先级。从网上找到的图。

从左到右意味着先应用左侧运算符,从右到左意味着先运用右侧运算符。
3.4.2 除法分支
如果两个操作数都是整数,C++将执行整数除法,即结果只取整数部分,如2/5=0,3/2=1等。
如果两个操作数中有一个操作数为浮点值,则小数部分将保留,结果为浮点数。(记住:浮点常量在默认情况下为double。)
除法运算符有3种不同的运算:int除法(3/2)、float除法(3f/2f)、double除法(3.0/2.0)。
3.4.3 类型转换
对于不同类型进行运算时,为处理这种潜在的混乱,C++自动执行很多类型转换:
- 将一种算数类型的值赋给另一种算数类型的变量时,C++将对值进行转换。
- 表达式中包含不同的类型时C++将对值进行转换。
- 将参数传递给函数时,C++将对值进行转换。
1.初始化和赋值进行的转换
C++允许将一种类型的值赋给另一种类型的变量。这样做时,值将被转换为接受变量的类型。一般情况下,将一个值赋给取值范围更大的类型时,通常不会导致什么问题,例如short类型的值赋给long类型的值时,只是占用的字节更多而已。但是,将long类型的值赋给float变量的时候,将降低精度。因为float只有六位有效数字。因此,有些转换是安全的,有些转换可能会带来麻烦。下面将列举详情。
- 将较大的浮点类型转换为较小的浮点类型,如将double类型转换为float类型。精度将降低,值可能超出目标类型的取值范围,在这种情况下,结果是不确定的。
- 将浮点型转换为整型,小数部分丢失,值可能超出目标类型的取值范围,在这种情况下,结果是不确定的。
- 将大的整型转换为较小的整型,如将long转换为int,原来的值可能超出目标类型的取值范围,通常只复制右边的字节。
- 将0赋给bool变量的时候,将会转换为false,将非零值赋给bool变量的时候,将会转换为true。
#include
using namespace std;
int main()
{
cout.setf(ios_base::fixed, ios_base::floatfield);
float tree = 3;
int guess(3.9832);
int debt = 7.2E12;
cout << "tree=" << tree << endl;
cout << "guess=" << guess << endl;
cout << "debt=" << debt << endl;
return 0;
} 关于运行结果,最终显示debt=1634811904(每一个系统显示的值都不一样),因为debt无法存储7.2E12。
2.以{}方式初始化时进行的转换(C++11)
这种初始化方式,与之前提到的初始化方式相比,它对类型转换的要求更加严格。具体来说,列表初始化不允许缩窄,即变量的类型可能无法表示赋给它的值,例如,不允许将浮点型转换为整型。在不同的整型之间转换或将整型转换为浮点型可能被允许,条件是编译器知道目标变量能够正确存储赋给它的值。
3.表达式中的转换
下面是C++11版本的校验表,编译器将依次查阅该列表。
- 如果有一个操作数的类型是long double,则将另一个操作数转换为long double。
- 否则,如果有一个操作数的类型是double,则将另一个操作数转换为doubel。
- 否则,如果有一个操作数的类型是float,则将另一个操作数转换为float。
- 否则,说明操作数都是整型,因此执行整型提升。
- 在这种情况下,如果两个操作数都是有符号或无符号的,且其中一个操作数的级别比另一个低,则转换为级别高的类型。
- 如果一个操作数为有符号的,另一个操作数为无符号的,且无符号操作数的级别比有符号操作数高,则将有符号操作数转换为无符号操作数所属的类型。
- 否则,如果有符号类型可表示无符号类型的所有可能取值,则将无符号操作数转换为有符号操作数所属的类型。
- 否则,将两个操作数都转换为有符号类型的无符号版本。
简单来说,有符号整型按级别从高到低依次为long long、long、int、short和signed char。无符号整型的排列顺序与有符号整型排列顺序相同。类型bool的级别最低。wchar_t、char16_t和char32_t的级别与底层类型相同。
4.传递参数时的转换
传递参数时的类型转换通常由C++函数原型控制。(事实上,如果函数原型失去参数类型检查,它就没存在的必要,C++之所以提出函数原型这个概念,就是为了严格参数检查的,取消这个检查当然不是明智之举,等于废掉这个语法的初衷。C原先是没有函数原型语法的,后来才从C++那里学了来,实际上后期的C标准大多数是从C++借鉴来的东西,像就近声明语法,也是C++早就有的。)
5.强制类型转换
C语言强制类型转化为(float)hats; C++为:float(hats);
新格式的思想是,要让强制类型转换就像是函数调用。C++还引入了4个强制类型转换运算符,对它们的使用要求更为严格。static_cast<>可用于将值从一种数值类型转换为另一种数值类型。
3.4.5 C++11中的auto声明
在初始化声明中,如果使用关键字auto,而不指定变量的类型,编译器将把变量的类型设置成与初始值相同的类型。
如:auto n=100;n被设置成int类型。 auto x=1.5;x被设置为double类型。
3.5 总结
字符通过其数值编码来表示。I/O系统决定了编码是被解释为字符还是数字。
通过提供各种长度不同、有符号或无符号的类型,C++使程序员能够根据特定的数据要求选择合适的类型。
C++使用运算符来提供对数字类型的算术运算:加、减、乘、除和求模。当两个运算符对同一个操作数进行操作时,C++的优先级和结合性规则可以确定先执行哪个操作。
关于对变量的初始化及赋值的时候,一定要注意其类型,不然就可能出现结果错误。求模运算时候,两个操作数一定要都为整型。对于一些转换,如将浮点型转换为整型,需多加注意范围和值。
关于几个小问题的回答:
为什么C++有多种整型?
答:有多种整型类型,可以根据特定需求选择最适合的类型。例如,可以使用short来存储空格,使用long来确保存储容量,也可以寻找可提高特定计算的速度的类型。
C++提供了什么措施来防止超出整型的范围?
答:C++没有提供自动防止超出整型限制的功能,可以使用头文件climits来确定限制情况。
下面两条C++语句是否等价?
char grade=65; char grade=‘A’;
答:这两条语句并不真正的等价,但对于某些系统来说,它们是等效的。最重要的是,只有在使用ASCII码的系统上,第一条语句才将得分设置为字母A,第二条语句还可用于使用其他编码的系统。其次,65是一个int常量,而‘A’是一个char常量。
如何使用C++来找出编码88表示的字符?指出至少两种方法。
char c=88;第一种
cout< cout.put(char(88));第二种 cout< cout<<(char)88< 将long值赋给float变量会导致舍入误差,将long值赋给double变量呢?将 long long值赋给double变量呢? 答:这个问题的答案取决于这两个类型的长度,如果long为4个字节,则没有损失。因为最大的long值将是20亿,即有10位数,由于double提供了至少13位有效数字,因而不需要进行任何舍入。long long类型可提供19位有效数字,超过了double保证的13位有效数字。