计算机毕设 大数据工作岗位数据分析与可视化 - python flask
文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
- 3 项目实现
-
- 3.1 概括
- 3.2 Flask实现
-
- 3.3 HTML页面交互及Jinja2
- 4 **完整代码**
- 5 最后
0 前言
这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
基于大数据的工作岗位数据分析与可视化
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分
1 课题背景
基于python+flask的python岗大数据可视化web系统,可以进行数据交互可视化,主题为python岗位相关大数据分析。
2 实现效果
Web_App动作描述
用户点击导航栏四个选项,跳转到想了解的页面
- 平均月薪
- 岗位数量
- 工作经验
- 最低学历
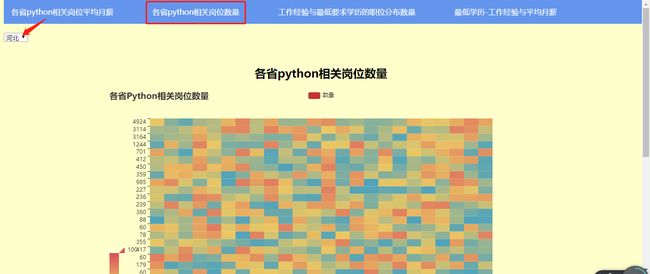
用户通过选择器点击想要了解的城市,可显示该城市的相关岗位数量
鼠标下拉可看文字结论分析

3 项目实现
3.1 概括
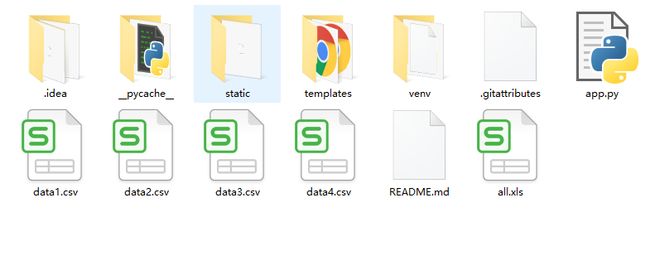
- 主运行文件为 app.py 文件。
- static 文件为网页样式。
- templates 里的map.html系列文件为生成可视化图表的离线文件,作为引用文件。
- data1.csv 等csv文件为引用的数据文档。csv档 为数据源。
- 在flask环境下导入
pandas、pyecharts实现数据图表交互展示。 - 写出四个@route,分别呈现为各省python相关岗位平均月薪、各省python相关岗位数量、工作经验与最低要求学历的职位分布数量、最低学历-工作经验与平 均月薪的相关图表展示。
df = pd.read_csv('xxx.csv',encoding = 'utf8', index_col="xxx")英文采用单字节编码,部分中文采用双字节编码。- 利用
.renter/with open导入和打开文件。 - 调用
pyecharts模块作图传输到HTML页面。 - 使用
list字典循环。 - 使用列表推导式进行取值。
3.2 Flask实现
数据循环

数据嵌套

推导式

条件判断

数据交互
3.3 HTML页面交互及Jinja2
Jinja2介绍
jinja2是Flask作者开发的一个模板系统,起初是仿django模板的一个模板引擎,为Flask提供模板支持,由于其灵活,快速和安全等优点被广泛使用。
jinja2的优点
jinja2之所以被广泛使用是因为它具有以下优点:
- 相对于Template,jinja2更加灵活,它提供了控制结构,表达式和继承等。
- 相对于Mako,jinja2仅有控制结构,不允许在模板中编写太多的业务逻辑。
- 相对于Django模板,jinja2性能更好。
- Jinja2模板的可读性很棒。
项目代码

4 完整代码
import random
from calendar import c
from tkinter import Grid
from flask import Flask,render_template,request
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Map, EffectScatter, HeatMap, Line,Grid
from pyecharts.faker import Faker
from pyecharts.globals import SymbolType
from pyecharts.charts import Pie,Bar
df = pd.read_csv('data1.csv')
app = Flask(__name__)
@app.route('/')
def map() -> 'html':
a = (
Map()
.add("平均月薪", list(zip(df.省, df.平均月薪)), "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="各省python相关岗位平均月薪"),
visualmap_opts=opts.VisualMapOpts(min_=7164.08, max_=17096.07),
)
)
a.render("./templates/map.html")
with open("./templates/map.html", encoding="utf8", mode="r") as f:
map = "".join(f.readlines())
the_select_province = {'北京':'4924',
'上海':'3114',
'广东':'3164',
'浙江':'1244',
'南京':'701',
'湖北':'412',
'江苏':'450',
'福建':'359',
'四川':'985',
'辽宁':'227',
'安徽':'236',
'湖南':'239',
'山东':'360',
'吉林':'88',
'江西':'60',
'天津':'355',
'山西':'417',
'陕西':'60',
'重庆':'179',
'黑龙江':'60',
'河南':'477',
'贵州':'60',
'河北':'60',}
return render_template('python_map.html',
the_map=map,
the_province=the_select_province
)
element = list(set(most['分类']))
@app.route('/effectscatter_symbol')
def effectscattere_symbol() -> 'html':
df = pd.read_csv('data2.csv',encoding = 'utf8', index_col="名称")
省 = list(df.loc["省"].values)[-24:]
数量 = list(df.loc["数量"].values)[-24:]
value = [[i, j, random.randint(0, 80)] for i in range(24) for j in range(24)]
c = (
HeatMap()
.add_xaxis(省)
.add_yaxis("数量", 数量, value)
.set_global_opts(
title_opts=opts.TitleOpts(title="各省Python相关岗位数量"),
visualmap_opts=opts.VisualMapOpts(),
)
)
c.render("./templates/effectscatter_symbol.html")
with open("./templates/effectscatter_symbol.html", encoding="utf8", mode="r") as f:
sym = "".join(f.readlines())
return render_template('python_effectscatter_symbol.html',
the_sym=sym,
)
1
data_pie1 = data_pie.T.to_html()
pie1_list = [num for num in data_pie['分类']]
labels = [index for index in data_pie.index]
@app.route('/pie_base')
def pie_base() -> 'html':
df = pd.read_csv('data3.csv', encoding='utf8')
bar = (
Bar()
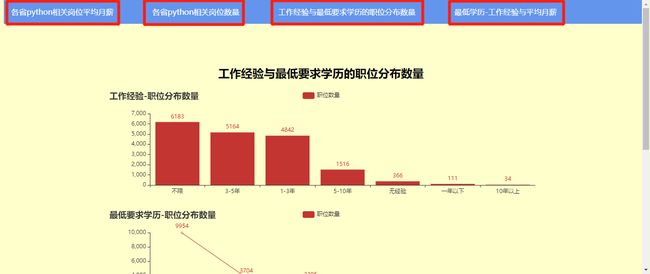
.add_xaxis(['不限', '3-5年', '1-3年', '5-10年', '无经验', '一年以下', '10年以上'])
.add_yaxis("职位数量", [6183, 5164, 4842, 1516, 366, 111, 34])
.set_global_opts(title_opts=opts.TitleOpts(title="工作经验-职位分布数量"))
)
line = (
Line()
.add_xaxis(['本科', '大专', '不限', '硕士', '博士', '中专'])
.add_yaxis("职位数量", [9954, 3704, 3205, 1137, 88, 31])
.set_global_opts(
title_opts=opts.TitleOpts(title="最低要求学历-职位分布数量", pos_top="50%"),
legend_opts=opts.LegendOpts(pos_top="50%"),
)
)
grid = (
Grid()
.add(bar, grid_opts=opts.GridOpts(pos_bottom="60%", pos_right="0", height="30%"))
.add(line, grid_opts=opts.GridOpts(pos_top="60%", pos_right="0", height="30%"))
)
bar,line,grid.render("./templates/pie_base.html")
with open("./templates/pie_base.html", encoding="utf8", mode="r") as f:
pie_base = "".join(f.readlines())
return render_template('python_pie_base.html',
the_pie_base=pie_base,
)
the_element3 = request.form['the_element3_selected']
print(the_element3)
element3_available = element3
if the_element3 =='广州':
the_level = 广州
elif the_element3 =='上海':
the_level = 上海
elif the_element3 =='北京':
the_level = 北京
else:
the_level = 其它
def python_most():
title1 = "最低学历"
data_pie = pd.DataFrame(pressure2.loc['最低学历与工作经验的关系']['分类'].value_counts())
data_pie1 = data_pie.T.to_html()
pie1_list = [num for num in data_pie['分类']]
labels = [index for index in data_pie.index]
@app.route('/Bar/')
def bar_base() -> Bar:
df = pd.read_csv('data4.csv', encoding='utf8', index_col="学历")
最低学历 = list(df.loc["最低学历"].values)[-6:]
无经验 = list(df.loc["无经验"].values)[-6:]
一年以下 = list(df.loc["一年以下"].values)[-6:]
不限 = list(df.loc["不限"].values)[-24:]
一至三年 = list(df.loc["一至三年"].values)[-24:]
三至五年 = list(df.loc["三至五年"].values)[-24:]
五至十年 = list(df.loc["五至十年"].values)[-24:]
十年以上 = list(df.loc["十年以上"].values)[-24:]
c = (
Line()
.add_xaxis(最低学历)
.add_yaxis("无经验", 无经验)
.add_yaxis("一年以下", 一年以下)
.add_yaxis("不限", 不限)
.add_yaxis("一至三年", 一至三年)
.add_yaxis("三至五年", 三至五年)
.add_yaxis("五至十年", 五至十年)
.add_yaxis("十年以上", 十年以上)
.set_global_opts(title_opts=opts.TitleOpts(title="最低学历-工作经验与平均月薪",
subtitle="平均月薪(元)"))
)
c.render("./templates/Bar.html")
with open("./templates/Bar.html", encoding="utf8", mode="r") as f:
bar_base= "".join(f.readlines())
return render_template('python_bar.html',
the_bar_base=bar_base,
)
return render_template('first.html',
the_title1 = title1,
the_select_element1 = element1_available,
the_data_pie1 = data_pie1,
the_pyecharts_all = plot_all,
the_pyecharts_all1 = plot_all1,
the_pyecharts_all3 = plot_all3,