【操作系统内核】进程
【操作系统内核】进程
进程的组成
进程的运行,需要考虑 磁盘 => 内存 => CPU => 内核 => 进程切换 这个过程
- 首先,程序运行要将可执行文件加载到内存,所以进程要读取可执行文件(运行后可能还需要读取其他文件的数据),需要知道:
① 文件系统的信息,fs_struct
② 打开的文件的信息,files_struct
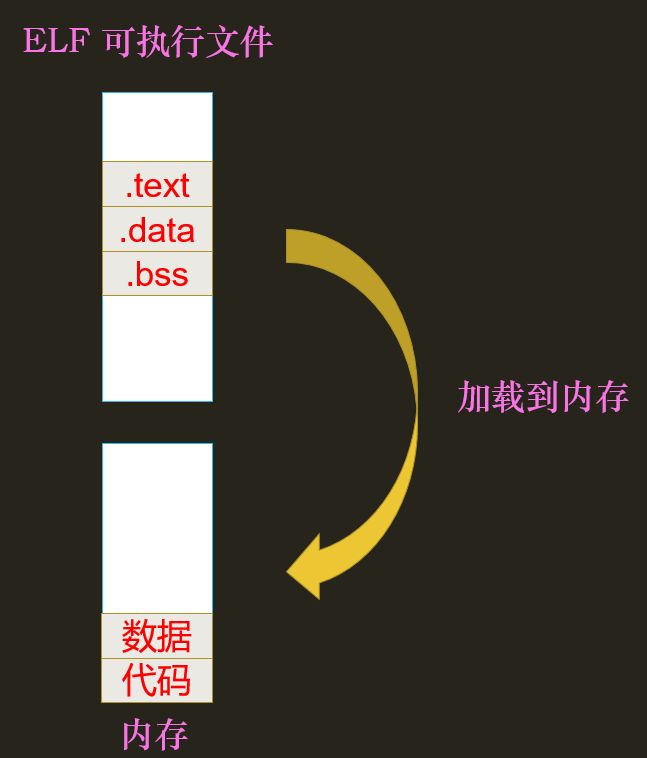
- 其次,进程要访问内存,Linux要求它有一块自己的虚拟地址空间,所以进程中需要有一个
mm_struct实例:
① vm_area_struct:内存映射,如mmp
② 页表:pgd存储页表目录的地址
- 程序加载到内存后,CPU需要知道下一条执行指令的内存地址,这个内存地址存储在CPU的程序计数器中; 此外,进程还需要其他,CPU寄存器的值,也就是
CPU上下文(也称为CPU的硬件上下文),包括:
① 指令指针寄存器 (eip/rip): 存储进程的下一条指令
② 通用寄存器
eax、ebx、ecx、edx、esp、ebp、esi、edi(32位)
rax、rbx、rcx、rdx、rsp、rbp、rsi、rdi(64位)
③ 段寄存器
cs、ds、ss、es、fs、gs
④ 标志寄存器

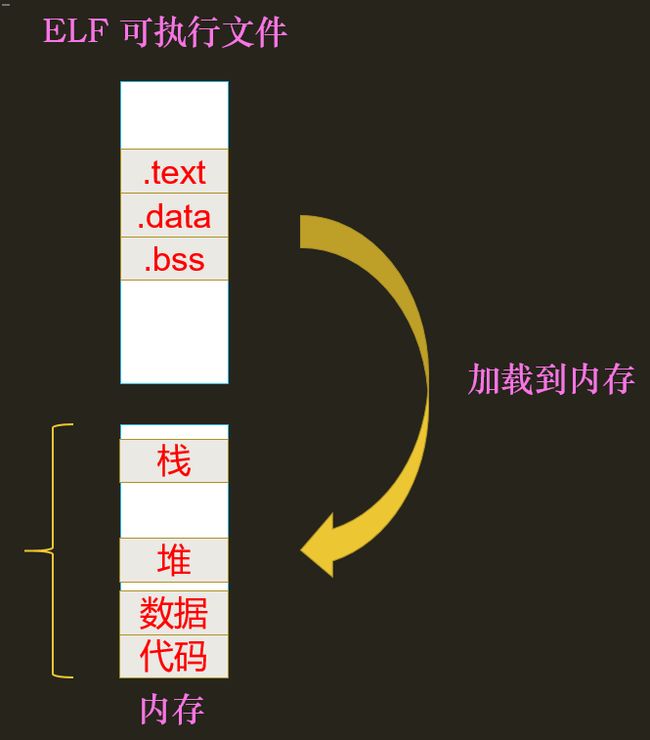
- 每个进程都在运行在用户态和内核态,为实现CPU的上下文切换,每个进程都应该有:
① 一个用户栈
② 一个内核栈
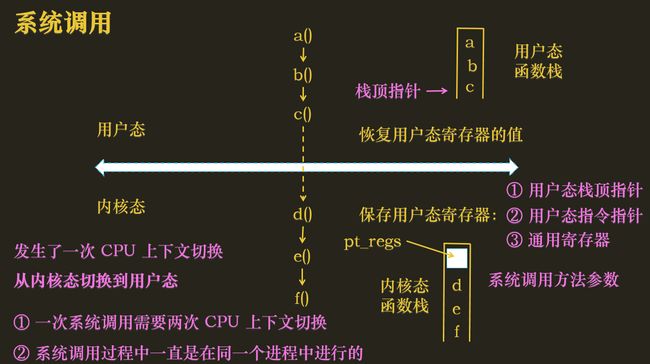
进程的运行流程,无非就是函数链的调用,每调用一次函数,就把函数压栈;但是有一个特殊情况,就是用户态的函数调内核态的函数,如用户态函数c()调用内核态函数d(),将发生第一次CPU上下文切换
此时,内核需要将用户态的信息(通过pt_regs这个结构保存)保存到内核态的函数栈的底端,包含:
① 用户态栈顶指针、系统调用方法参数:调用系统函数的函数
② 用户态栈顶指令指针: 用户态执行的下一个指令
③ 通用寄存器
然后,将函数d()压入内核态函数栈
当内核函数调用完成后,将恢复用户态信息,发生第二次CPU上下文切换
- 调度信息
一个CPU核只能运行一个进程,但如果我要运行的程序多于CPU核,将采用
时分共享的方式:一个进程运行一段时间后,切换到另一个进程运行,使得每个进程都觉得自己拥有一个CPU
而要实现进程切换,就需要内核决定切换的策略,假设只有一个CPU并在运行某一个进程,首先,在进程切换时,内核的调度程序需要拿到CPU的执行权限。
时分共享策略通过产生一个时钟中断,使得内核态能去调度其他进程

两个进程切换过程(详细过程见参考链接):
① 切换CPU上下文,如CPU的rip指针应该指向第二个进程的下一条执行指令
② 切换虚拟地址空间,如切换页表
③ 切换内核栈
而内核调度器去调度进程时,需要根据进程的调度信息(如调度算法、优先级等)去调度
据此,可以将进程抽象为结构体task_struct

当然,这里只讲述一些基础的信息,task_srtrcut的组成不止如此
进程的数据结构
除了上面讲到的组成,信息处理也是进程数据结构中重要的组成:
// 0. 标志信息
pid_t pid;
pid_t tgid;
struct task_struct *group_leader;
// 1. 文件和文件系统
struct fs_struct *fs;
struct files_struct *files;
// 2. 内存管理
struct mm_struct *mm;
// 3. 内核栈
struct thread_info thread_info;
void *stack;
// 4. 调度信息
//调度器类
const struct sched_class *sched_class;
//调度实体
struct sched_entity se;
struct sched_rt_entity rt;
struct sched_dl_entity dl;
//调度策略
unsigned int policy;
//可以使用哪些CPU
int nr_cpus_allowed;
cpumask_t cpus_allowed;
struct sched_info sched_info;
//是否在运行队列上
int on_rq;
//优先级
int prio;
int static_prio;
int normal_prio;
unsigned int rt_priority;
// 5.运行统计信息
u64 utime; //用户态消耗的CPU时间
u64 stime; //内核态消耗的CPU时间
unsigned long nvcsw;//自愿(voluntary)上下文切换计数
unsigned long nivcsw;//非自愿(involuntary)上下文切换计数
u64 start_time; //进程启动时间,不包含睡眠时间
u64 real_start_time; //进程启动时间,包含睡眠时间
// 6. 信号处理
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked;
sigset_t real_blocked;
sigset_t saved_sigmask;
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
unsigned int sas_ss_flags;
// 7.进程状态
volatile long state;
int exit_state;
unsigned int flags;
// 8.亲缘关系
struct task_struct __rcu *real_parent;
struct task_struct __rcu *parent;
struct list_head children;
struct list_head sibling;
// 9.进程权限
const struct cred __rcu *real_cred;
const struct cred __rcu *cred;
...
0、1、2号进程
计算机在启动时,会先运行0号进程(idle进程),建立它的堆栈,并运行它:
① 配置实时时钟
② 挂载根文件系统
③ 创建 1 号进程(init 进程)
④ 创建 2 号进程 (kthreadd进程)
0号进程
内核进程:只运行在内核态,只能用大于PAGE_OFFSET的虚拟地址空间(只使用内核态的虚拟地址空间)
普通进程:可运行在内核态和用户态,可以使用所有虚拟地址空间(在内核态使用内核态地址空间,在用户态使用用户态地址空间)
0号进程是一个内核进程,也只有没有任何可运行的进程时,才会运行0号进程
1号进程
共享0号进程的所有数据结构,一开始是内核进程,先执行init()函数完成内核初始化,然后调用exec()装入可执行程序init,变成一个普通进程
它是所有用户态进程的祖先
2号进程
kswapd: 一直在后台运行,执行物理页面的回收,交换出不用的页帧(将最近不用的内存块移动到磁盘)
pdflush:刷新 “脏” 缓冲区的内容到磁盘以回收内存
是所有内核进程的祖先
进程间的关系
除了 0 号进程,一个进程都是由一个父亲进程创建
如果一个进程创建了多个进程,那么子进程之间是兄弟关系
task_struct中维护节点关系的字段:

- parent:指向其父进程。当它终止时,必须向它的父进程发送信号
- children: 表示链表的头部。链表中的所有元素都是它的子进程。
- sibling: 用于把当前进程插入到兄弟链表中。
- real_parent 和 parent:
- 通常情况下,real_parent 和 parent 是一样的,但是也会有另外的情况存在
- bash 创建一个进程,那进程的 parent 和 real_parent 就都是 bash。
- 如果在 bash 上使用 GDB 来 debug 一个进程,这个时候 GDB 是 parent,bash 是这个进程的 real_parent。
如登录一个linux的shell终端,会先创建一个sshd的进程,sshd进程才创建一个pts进程,pts进程再创建一个bash进程,如果在这个bash去拉起一个进程(如ps -ef、ls这些命令就会拉起一个进程,通过which ls命令可查看ls的可执行文件路径),
那么这个进程的父进程就是这个bash,关闭这个bash后,它的所有子进程都会被kill

内核将task_struct之间通过双向链接的形式组织,后续fork的进程插入链表的表尾:
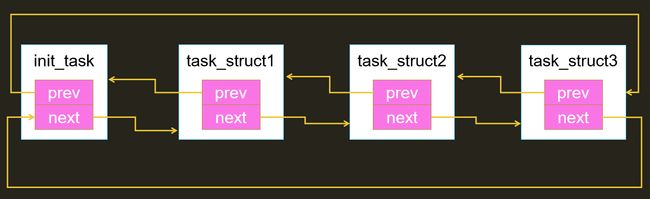
进程的创建
比如我们写一段代码,生成可执行文件,然后在bash上运行,则这个进程属于bash进程的一个子进程:
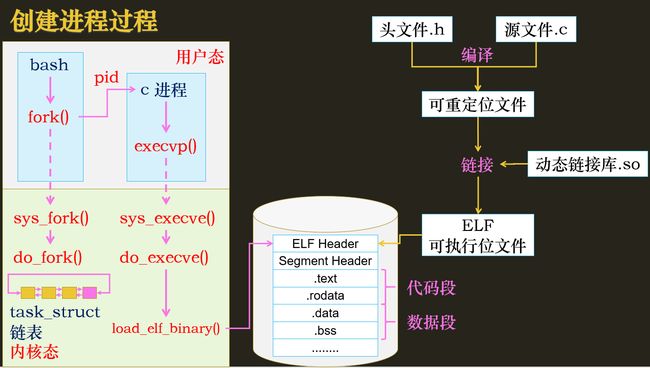
内核调用sys_fork()创建一个进程并加入到双向链表
sys_fork()的本质: 在内核创建一个task_struct实例(拷贝父进程的task_struct),然后将之维护到各种链表队列(用于管理或调度进程)
- 第一次系统调用:
-
bash调用fork()陷入内核态
- 进入父进程保存用户态寄存器、程序计数器的值到内核栈
- 从slab分配器中分配一个task_struct实例,创建子线程内核栈,拷贝父进程内核栈并设置thread_info
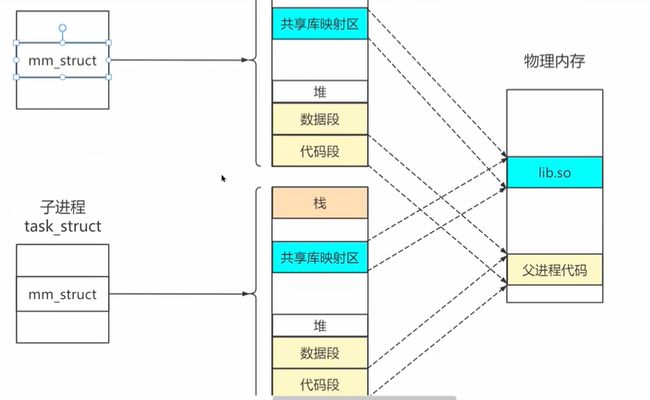
- 拷贝父进程的实例,调度信息,进程运行信息等,创建进程时主要关注
mm_struct
-
拷贝完成后,分配PID,建立进程亲缘关系,将task_struct加入进程链表,
-
创建进程完成,唤醒新线程(task_running)
- 第二次系统调用:
-
子进程被唤醒后,调用execvp()加载磁盘上的可执行文件,由于磁盘IO操作需要内核态完成,所以需要再次陷入内核态
-
内核态调用load_elf_binary()加载代码段和数据段到内存,最主要的是设置子进程的虚拟地址空间
- 修改mmp
- 初始化函数栈(会比父进程的小)
- 将可执行文件的代码部分映射到内存(写时复制,内存映射,因为代码段是进程私有的,不能共享)

- 设置堆的brk以及堆的vm_area_struct(堆也会比较小)
- 将依赖的so映射到内存中的内存映射区域
-
由于内核栈相同,切换会用户态后,子进程的rip指针和父进程的rip指针会指向同一行指令,且执行的代码段也相同,需要根据pid是否等于0区分父进程或子进程
Tip:
exec()函数:
