FFmpeg及音频简介
文章目录
- 一、音视频的应用场景
- 二、ffmpeg简介
-
- 1.ffmpeg命令
- 2.ffmpeg编译目录介绍
- 三、音频简介
-
- 1.声音三要素
- 2.音频处理流程
- 3.音频采集
-
- 3.1 PCM和WAV
- 3.2 命令行采集音频
- 3.3 命令行播放PCM
- 4. 音频编码
-
- 4.1 音频编码过程
- 4.2 几种常见的音频编码器比较
- 4.3 AAC音频编码器介绍
- 4.4 音频重采样
- 4.5 音频重采样和编码的ffmpeg编码步骤
一、音视频的应用场景
互动直播系统
娱乐直播系统
音视频特效
音视频剪辑
二、ffmpeg简介
FFmpeg是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序。采用LGPL或GPL许可证。它提供了录制、转换以及流化音视频的完整解决方案。它包含了非常先进的音频/视频编解码库libavcodec,为了保证高可移植性和编解码质量,libavcodec里很多code都是从头开发的。
FFmpeg在Linux平台下开发,但它同样也可以在其它操作系统环境中编译运行,包括Windows、Mac OS X等。前面的"FF"代表"Fast Forward"。 FFmpeg编码库可以使用GPU加速。
1.ffmpeg命令
ffmpeg:编解码,音频处理,特效;可以推流至流媒体服务器;
ffplay:播放器,依赖于ffmpeg;从流媒体服务器拉取音视频流;支持本地流播放;
vlc:依赖域ffmpeg,也支持使用rtmp协议从流媒体服务拉流
2.ffmpeg编译目录介绍
bin文件夹下:
ffmpeg命令:推送,音视频处理
ffplay命令:拉流
ffprole:侦测多媒体文件,文件信息等
include文件夹:
libavcodec:编解码
libavfilter:滤镜 特效
libavutil:基本工具
libswresample:音频重采样
libavdevice:管理设备
libavformat:文件格式处理
libpostproc:
libswscale:视频的缩放等处理
lib文件夹:
包含静态和动态库,与include一样
share文件夹:
文档相关内容,使用手册等
三、音频简介
1.声音三要素
1.音调
音频的快慢 男生->女生->儿童
人类听觉范围
20hz - 20khz, 人声范围85-1100hz。
声音的震动频率即为HZ

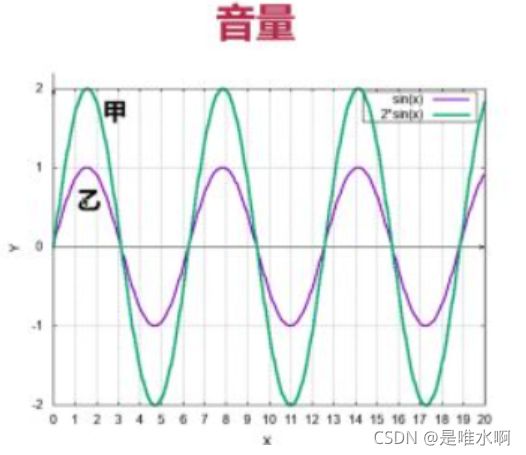
2.音量
震动的幅度
3.音色
谐波:绿色为基频,橙色和蓝色的频率(一次谐波和二次谐波)叠加后,得到粉色的真实频率。粉色频率的小波动端成为称为谐波

2.音频处理流程
音频处理流程: 采集,编码(缩小数据量),解码,播放

音频数据流转:
1)通过各种api采集到音频数据后,格式为PCM,是数字信号
2)通过编码器得到aac/mp3等编码格式的文件
3)数据外层再套一层mp4/flv等格式,得到可识别的多媒体文件
3.音频采集
音频采集的原理就是对声音进行模数转换,对连续的声音进行——量化采样
常见的采样率:48000/s(常用),44.1k,32000/s,16000/s,8000/s(已经非常低了)
3.1 PCM和WAV
采集到的原始音频数据就是PCM格式,WAV是指音频文件格式
WAV格式如下:

chunkSize表示在chunkSize后还有多少字节
其他的子chunksize同理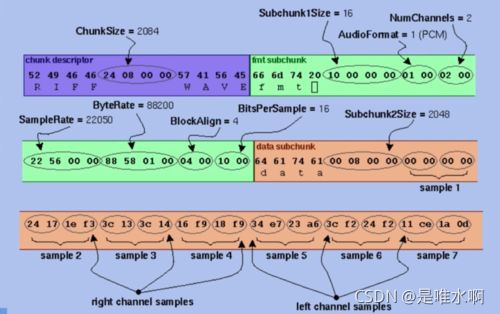
3.2 命令行采集音频
Android端音频采集:
audio recorder(偏底层,采集音频数据,需要调用其他api保存为多媒体文件)
media recorder(偏上层,可以直接将音频数据保存为多媒体文件)
IOS端音频采集:
audio unit:捕获音频,对音频处理(常用于直播)
AV foundation:偏上层
windows端音频采集:
Direct show
Open AL
Audio core(Win7后)
端太多了 但可以统一使用ffmpeg进行音频采集
两种方式
1)命令方式采集音频
采集ffmpeg -f avfoundation -i :0 out.wav
-f avfoundation:采用avfoundation库采集(如果切换操作系统,则依赖库做响应调整)
-i :0表示采集音频,冒号前为视频,冒号后为音频。
采集数据存为out.wav
播放ffplay out.wav
2)API方式
3.3 命令行播放PCM
ffplay -ar 44100 -ac 2 -f f32le audio.pcm
ar为采样率
ac为通道数,2路
f为采样大小,32位
linux下的命令
ffplay -ar 44100 -ac 2 -f s16le audio.pcm
4. 音频编码
4.1 音频编码过程
音频编码实际就是音频压缩技术,如果不进行任何压缩,每秒中的pcm数据就是1M。
希望编码做到最小且最快
音频编码的方法通常通过消除冗余信息和无损压缩,如zip,rar,gz来完成。
消除冗余信息:
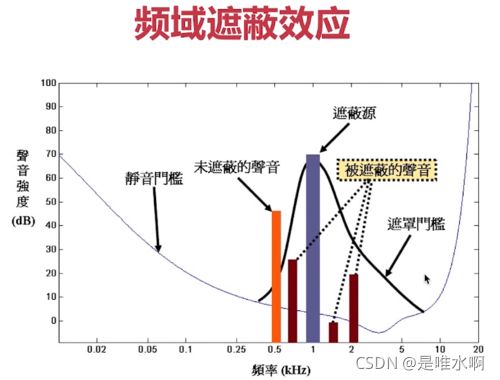
冗余信息包含人耳听觉范围外的音频(20HZ到20000HZ外的数据)以及被掩蔽掉的音频信号(一些被主要音频信号遮蔽的话外音)。
其中音频信号遮蔽分为时域遮蔽和频域遮蔽,如下图所示
频域遮蔽效应是指:高频率高声强的声音会对附近频率的声音产生遮蔽效应。
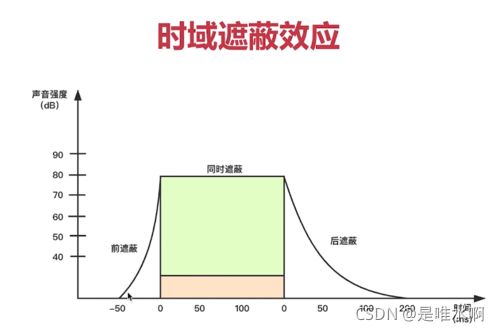
时域遮蔽效应是指:相同频域下,声强高的会屏蔽掉声强低的声音,同时该声音会对前后时域的声音都有一定的遮蔽效应。
无损压缩
无损压缩的原理就是熵编码。
使用的熵编码进行无损编码,其基本原理是将用短的编码替代高频的词汇、句子,用长的句代表低频词。
熵编码常用的三种方法:
(1)哈夫曼编码:使用一串二进制数代替一串特别长的字符。特点是:频率越高的编码越少,频率越低的编码越长。
(2)算术编码:通过二进制小数进行编码。
(3)香农编码
总结来看,音频编码过程如下,包含了冗余信息的消除和无损编码。其中时域转频域变换和心理声学模型属于冗余信息消除,量化编码属于无损压缩技术。
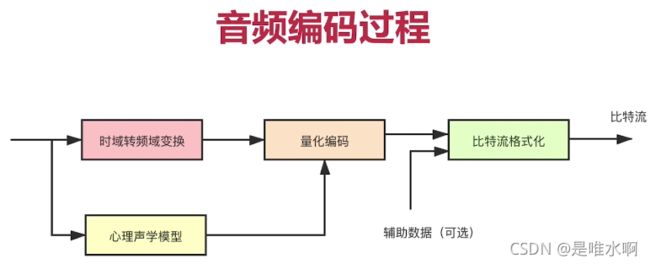
4.2 几种常见的音频编码器比较
一、常见的音频编码器
(1)OPUS:目前较新的音频编码器,WebRTC默认使用OPUS;延迟小,压缩率高。应用在在线教育,视频会议
(2)AAC:在直播系统中应用比较广泛的编码器;(分软件和硬件)不适合实时性要求较高的场景
(3)Ogg:软件收费,应用比较少;
(4)Speex:显著的特点是支持回音消除,是七八年前应用非常广泛的编码器;
(5)G.711:固话、电话使用的窄带音频编码器,但是音损非常严重,不适合实时通信;
(6)其他:iLBC、AMR。
网上评测结果:OPUS>AAC>Ogg
二、不同音频编码器的音频编码质量比较
OPUS对不同的网络质量(窄带、宽带、超宽带、全带)都有对应的码流选择

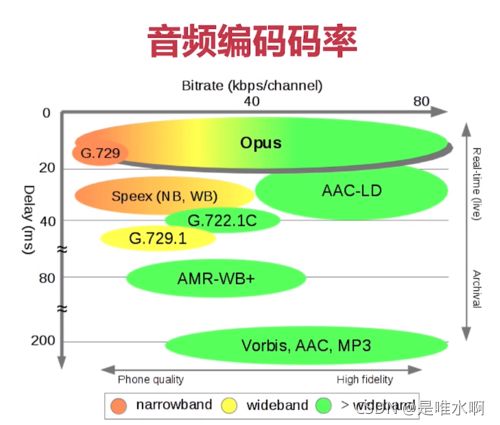
三、不同音频编码器的音频编码码率
不同编码器在不同的延时对码率的支持范围。
4.3 AAC音频编码器介绍
一、产生
AAC全称为Advanced Audio Coding。研发目的:取代MP3格式。与MP3格式的比较:MP3的压缩率比较低,压缩后的文件大;AAC的压缩率比较高,保真性强,即使压缩成很小的数据,还原度仍然很高。
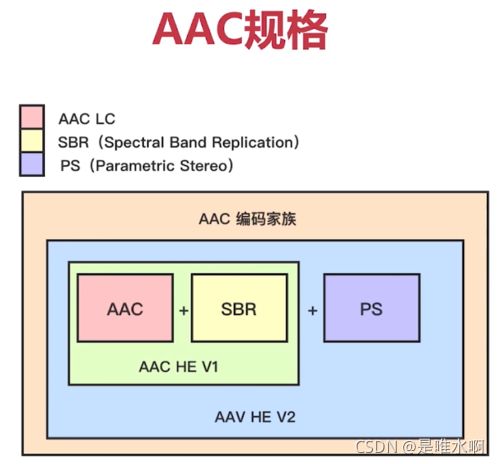
最初是基于MPEG-2的音频编码技术,在MPEG-4标准出现后,AAC加入了SBR技术和PS技术。
二、常用的规格

三、AAC编码家族规格之间的关系
四、AAC格式

因此ADTS的数据比ADIF的数据多,好处是能按流的方式处理,可以从任何位置开始播放,适用于直播系统

A:前12bit表示ADTS头
D:是否进行CRC,7、9字节通过该字段决定
E:判断编码为AAC LC还是AAC HE V1还是AAC HE V2
F:采样率
具体格式的组成可以从官网获取:https://www.p23.nl/projects/aac-header/
在开发的过程当中,FFmpeg提供了相应的API可以填充参数生成ADTS格式的数据,减少了编程的工作量。
五、ffmpeg生成AAC数据
从mp4文件中生成aac数据
ffmpeg -i xxx.mp4 -vn -c:a libfdk_aac -ar 44100 -channels 2 -profile:a aac_he_v2 xxx.aac
-i ***mp4表示输入的多媒体文件,文件中需要包括音频
-vn:no video,过滤视频
-c:a: c表示编码器coder,a表示音频,即音频编码器。指定音频编码器使用fdkaac;也支持libopus
-ar:表示音频采样率
-channels:表示声道数
-profile:a:表示对音频编码的一些参数配置,设置为aac_he_v2
命令行的参数格式见如下:
http://ffmpeg.org/ffmpeg-codecs.html#libfdk_005faac
4.4 音频重采样
什么是重采样?
三元组(采样大小,采样频率,声道数量)中任何一个或多个值发生变化都称为重采样
为什么进行重采样?
从设备采集的音频数据与编码器要求的数据不一致
扬声器要求的音频数据与要播放的音频数据不一致
更方便运算
如何知道是否需要进行重采样
了解音频设备的参数,是为了知道从设备采集的音频数据是什么样的
了解ffmpeg源码,确定编码器要求的数据格式是什么样的(ffmpeg源码支持跨平台,支持多种编码,因此在源码中可以看到需要的三元组参数)
4.5 音频重采样和编码的ffmpeg编码步骤
音频重采样

几个重要的ffmpeg的API
swr_alloc_set_opts:创建上下文,设置重采样的参数
swr_init:初始化上下文
swr_convert:对音频帧的转化
swr_free:释放上下文
音频编码
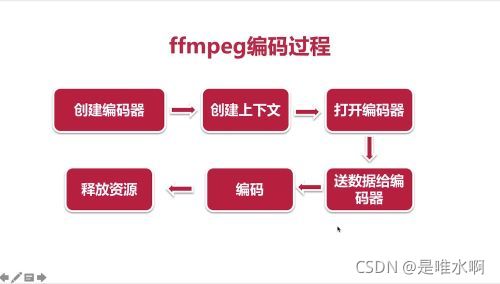
几个重要api
创建编码器 avcodec_find_encoder
创建上下文 avcodec_alloc_context3
打开编码器 avcodec_open2
发送数据给编码器 avcodec_send_frame
从编码器接收数据 avcodec_receive_packet
结构体:AVFrame(大多数为未编码数据)和AVPacket(大多数为编码数据,之前的课程使用find_input_format是把设备当成多媒体文件处理,读出的数据采用AVPacket存储,应该转换为AVFrame,但哪怕转换为AVFrame,其实也没有做解码处理)