mysql 讲解(1)
文章目录
- 前言
- 一、基本的命令行操作
- 二、操作数据库语句
-
- 2.1、创建数据库
- 2.2、删除数据库
- 2.3、使用数据库
- 2.4 查看所有数据库
- 三、列的数据类型
-
- 3.1 字符串
- 3.2 数值
- 3.3 时间日期
- 3.4 空
- 3.5 int 和 varchar问题总结:
- 四、字段属性
-
- 4.1 UnSigned
- 4.2 ZEROFILL
- 4.3 Auto_InCrement
- 4.4 NULL 和 NOT NULL
- 4.5 DEFAULT
- 4.6 测试
- 4.7 补充
- 4.8 linux 查看表文件 补充
-
- 表类型:引擎
- 4.9 修改和删除表字段
-
- 4.9.1 ==修改表 ( ALTER TABLE )==
- 4.9.2**删除数据表**
- 4.9.3 其它
- 4.10 数据库级别的外键
-
- 4.10.1 建表时指定外键约束
- 4.10.2 建表后修改
- 4.10.3 删除外键
- 五、MYSQL数据管理(重点)
-
- 5.1 DML语言
-
- 5.1.1 Insert
- 5.1.2 update
- 5.1.3 DELETE
-
- delete与truncate 的区分
- 5.2 DQL(重点,查询语句)
-
- 5.2.1 SELECT语法:
- 5.2.2 指定查询字段
- 5.2.3 DISTINCT 去重
- 5.2.4 使用表达式的列
- 5.2.5 where 字句
-
- 5.2.5.1 逻辑操作符
- 5.2.2.1 模糊查询
- 5.2.6 连接查询
-
- 5.2.6.1 JOIN对比
- 5.2.6.2 自连接
- 5.2.7 排序
- 5.2.8 分页
- 5.2.9 子查询 嵌套查询
- 5.2.10 MYSQL常用函数
- 5.2.11 聚合函数以及分组过滤
- 5.2.12 补充知识 MD5加密
- 5.2.13 select 执行顺序
前言
数据库无非三个大类:
①操作数据库 ②操作数据库中的表 ③操作数据库表中的信息
一、基本的命令行操作
查看有哪写数据库
show databases;
使用那个数据库
use databasename
显示所有的表
show tables;
显示具体表的结构
desc tablename
describe tablename
二、操作数据库语句
SQL语句不区分大小写,SQL语句记得以分号结尾;
2.1、创建数据库
例:创建一个school数据库
CREATE DATABASE [IF NOT EXISTS] school;
2.2、删除数据库
例:删除school 数据库
DROP DATABASE [IF EXISTS] school;
2.3、使用数据库
使用school 数据库
USE school;
2.4 查看所有数据库
show DATABASES;
三、列的数据类型
3.1 字符串
| char | 字符串固定大小 0-255 |
|---|---|
| varchar | 可变字符串 0-65535 常用的变量 String |
| tinytext | 最大长度为255个字符,占用1个字节的存储空间 |
| text | 保存文本 最大长度为65,535个字符,占用2个字节的存储空间 |
3.2 数值
| tinyint | 1个字节 |
|---|---|
| smallint | 2个字节 |
| mediumint | 3个字节 |
| int | 4个字节 |
| float | 单精度浮点类型 4个字节 |
| double | 双精度浮点类型 8个字节 |
| decimal | 字符串的浮点类型,可以精准计算 |
3.3 时间日期
| data | YYYY-MM-DD |
|---|---|
| time | HH:mm:ss |
| datatime | YYYY-MM-DD HH:mm:ss |
| timestamp | 时间戳,从1970.1.1到现在的毫秒数 |
3.4 空
NULL 未知,注意:不要使用null进行运算
3.5 int 和 varchar问题总结:
在mysql中 int(M) M这里是宽度,并不是说int(1)就是只能写一位数字。这里是为了填充的,比如int(3),你写了一个1,最后就是001.
而varchar(3),那确实就是3个,不论你是3个字母还是3个汉字。
四、字段属性
4.1 UnSigned
无符号的
声明该数据列不允许负数 .
4.2 ZEROFILL
0填充的
不足位数的用0来填充 , 如int(3),5则为005
4.3 Auto_InCrement
自动增长的 , 每添加一条数据 , 自动在上一个记录数上加 1(默认)
通常用于设置主键 , 且为整数类型
可定义起始值和步长
当前表设置步长(AUTO_INCREMENT=100) : 只影响当前表
SET @@auto_increment_increment=5 ; 影响所有使用自增的表(全局)
4.4 NULL 和 NOT NULL
默认为NULL , 即没有插入该列的数值
如果设置为NOT NULL , 则该列必须有值
4.5 DEFAULT
默认的
用于设置默认值
例如,性别字段,默认为"男" , 否则为 “女” ; 若无指定该列的值 , 则默认值为"男"的值
4.6 测试
创建一个student表
id为主键
注意:
对于表的字段和表名尽量使用``引起来,这个符号是电脑tab上边的点,而不是单引号。
对于字符串,可以用单引号,也可以用双引号,()括号要使用英文的括号。
注释要使用英文的单引号,不同的属性要用空格符隔开。
每一行最后要加英文逗号,
CREATE TABLE IF NOT EXISTS `student`(
`id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号',
`name` VARCHAR(30) NOT NULL DEFAULT '匿名' COMMENT '姓名',
`pwd` VARCHAR(10) NOT NULL DEFAULT '123456' COMMENT '密码',
`birthday` DATETIME DEFAULT NULL COMMENT '生日',
`address` VARCHAR(100) DEFAULT NULL COMMENT '住址',
`email` VARCHAR(20) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
格式:
CREATE TABLE [IF NOT EXISTS] 表名(
列名 列数据类型 [属性] [索引] [注释],
列名 列数据类型 [属性] [索引] [注释],
列名 列数据类型 [属性] [索引] [注释],
primary key(主键列名)
)[表类型] [字符集类型] [注释]
4.7 补充
SHOW CREATE TABLE student --逆向查看构建表 student的过程(语句)
SHOW CREATE DATABASE mytext --逆向查看构建数据库 mytext的过程(语句)
DESC student --查看表结构
4.8 linux 查看表文件 补充
mysql的数据都在 data文件夹下
在linux中 我们如何知道data文件夹在哪里呢?
首先 我们可以先查看mysql的配置文件 my.cnf
find / -name “my.cnf”
如果有多个的话 选择其中一个进行查看可以
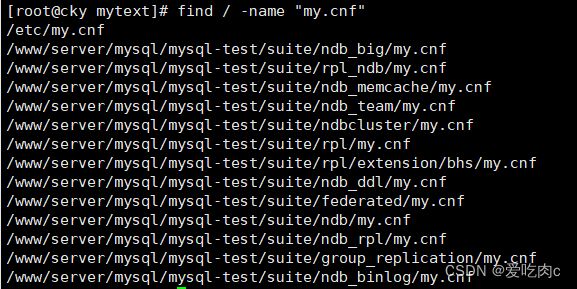
vim /etc/my.cnf
之后在文件夹下 找datadir 关键字
就可以找到 data目录了

表类型:引擎
MySQL的数据表的类型 : MyISAM , InnoDB , HEAP , BOB , CSV等…
常见的 MyISAM 与 InnoDB 类型: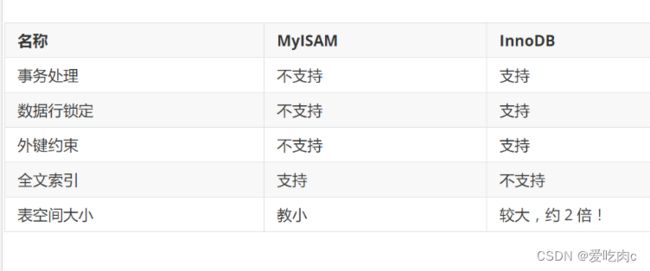
经验 ( 适用场合 ) :
适用 MyISAM : 节约空间及相应速度
适用 InnoDB : 安全性 , 事务处理及多用户操作数据表
数据表的存储位置
MySQL数据表以文件方式存放在磁盘中
包括表文件 , 数据文件 , 以及数据库的选项文件
位置 : Mysql安装目录\data\下存放数据表 . 目录名对应数据库名 , 该目录下文件名对应数据表 .
注意 :
-
. frm – 表结构定义文件
-
. MYD – 数据文件 ( data )
-
. MYI – 索引文件 ( index )
*InnoDB类型数据表只有一个 .frm文件 , 以及上一级目录的ibdata1文件
MyISAM类型数据表对应三个文件 :

4.9 修改和删除表字段
4.9.1 修改表 ( ALTER TABLE )
修改表名 :ALTER TABLE 旧表名 RENAME AS 新表名
添加字段 : ALTER TABLE 表名 ADD字段名 列属性[属性]
修改字段 :
ALTER TABLE 表名 MODIFY 字段名 列类型[属性] --> 修改列属性
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 列属性[属性] -->重命名
删除字段 : ALTER TABLE 表名 DROP 字段名
4.9.2删除数据表
语法:DROP TABLE [IF EXISTS] 表名
IF EXISTS为可选 , 判断是否存在该数据表
如删除不存在的数据表会抛出错误
4.9.3 其它
-
可用反引号(`)为标识符(库名、表名、字段名、索引、别名)包裹,以避免与关键字重名!中文也可以作为标识符!
-
每个库目录存在一个保存当前数据库的选项文件db.opt。
-
注释:
单行注释 # 注释内容
多行注释 /* 注释内容 */
单行注释 – 注释内容 (标准SQL注释风格,要求双破折号后加一空格符(空格、TAB、换行等)) -
模式通配符:
_ 任意单个字符
% 任意多个字符,甚至包括零字符
单引号需要进行转义 ’ -
CMD命令行内的语句结束符可以为 “;”, “\G”, “\g”,仅影响显示结果。其他地方还是用分号结束。delimiter 可修改当前对话的语句结束符。
-
SQL对大小写不敏感 (关键字)
-
清除已有语句:\c
4.10 数据库级别的外键
对于外键,一般我们都不会去添加物理级别即数据库级别的外键,因为这种会导致耦合性太强,容易出现错误,一般我们如果我们想使用多张表,想使用外键,都会通过程序来实现,而不是这种数据库级别的外键
4.10.1 建表时指定外键约束
-- 创建外键的方式一 : 创建子表同时创建外键
-- 年级表 (id\年级名称)
CREATE TABLE `grade` (
`gradeid` INT(10) NOT NULL AUTO_INCREMENT COMMENT '年级ID',
`gradename` VARCHAR(50) NOT NULL COMMENT '年级名称',
PRIMARY KEY (`gradeid`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
-- 学生信息表 (学号,姓名,性别,年级,手机,地址,出生日期,邮箱,身份证号)
CREATE TABLE `student` (
`studentno` INT(4) NOT NULL COMMENT '学号',
`studentname` VARCHAR(20) NOT NULL DEFAULT '匿名' COMMENT '姓名',
`sex` TINYINT(1) DEFAULT '1' COMMENT '性别',
`gradeid` INT(10) DEFAULT NULL COMMENT '年级',
`phoneNum` VARCHAR(50) NOT NULL COMMENT '手机',
`address` VARCHAR(255) DEFAULT NULL COMMENT '地址',
`borndate` DATETIME DEFAULT NULL COMMENT '生日',
`email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱',
`idCard` VARCHAR(18) DEFAULT NULL COMMENT '身份证号',
PRIMARY KEY (`studentno`),
KEY `FK_gradeid` (`gradeid`),
CONSTRAINT `FK_gradeid` FOREIGN KEY (`gradeid`) REFERENCES `grade` (`gradeid`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
4.10.2 建表后修改
-- 创建外键方式二 : 创建子表完毕后,修改子表添加外键
ALTER TABLE `student`
ADD CONSTRAINT `FK_gradeid` FOREIGN KEY (`gradeid`) REFERENCES `grade` (`gradeid`);
4.10.3 删除外键
注意 : 删除具有主外键关系的表时 , 要先删子表 , 后删主表
– 删除外键
ALTER TABLE student DROP FOREIGN KEY FK_gradeid;
– 发现执行完上面的,索引还在,所以还要删除索引
– 注:这个索引是建立外键的时候默认生成的
ALTER TABLE student DROP INDEX FK_gradeid;
五、MYSQL数据管理(重点)
5.1 DML语言
数据库管理语言
5.1.1 Insert
语法:
可以同时插入多条数据
INSERT INTO
表名(字段1,字段2,...) VALUES(值1,‘值2’,...),(值1,...),…
表名后边也可以不加字段名,但是如果不加字段名,就注意要一一匹配了,包括自增主键,自己也要写上。
例如:
往student 表中添加name和password两个字段,且同时添加上了两条数据
INSERT INTO
student(name,password) VALUES(‘jiang’,‘123456’),(‘long’,‘123456’);
注意:这种只增加几个字段,而不是全部字段的,其它字段要么设置允许为空,要么有默认值,或者是主键可以自增,否则会报错。
5.1.2 update
语法:
UPDATE
表名SET column_name1=‘value’[,column_name2=‘value’] [WHERE 条件]
例如:
UPDATE
studentSET NAME=‘崔’,password=‘123’ WHERE PASSWORD=‘123456’ AND id=5
注意
修改的属性可以有多个,但是要用英文逗号隔开。
如果不加条件 就会修改全部行。
条件也可以有多个 用 and 或者 or连接。
5.1.3 DELETE
语法:
delete from table_name [where 条件]
delete from table_name 不加条件的话 就是删除所有表内容 但不会删除表结构
TRUNCATE TABLE 表名
delete与truncate 的区分
1、相同点:都会删除表内容,但不会删除表结构
2、不同点:
delete:删除表内容之后,对于自增序列,不会清零,仍从上次自增序列开始。
truncate:对于自增序列,计数器会清零,从1开始。
以下关于delete的了解即可:
- 同样使用DELETE清空不同引擎的数据库表数据.重启数据库服务后
– InnoDB : 自增列从初始值重新开始 (因为是存储在内存中,断电即失)
– MyISAM : 自增列依然从上一个自增数据基础上开始 (存在文件中,不会丢失)
5.2 DQL(重点,查询语句)
5.2.1 SELECT语法:
SELECT [ALL | DISTINCT]
{* | table.* | [table.field1[as alias1][,table.field2[as alias2]][,…]]}
FROM table_name [as table_alias]
[left | right | inner join table_name2] – 联合查询
[WHERE …] – 指定结果需满足的条件
[GROUP BY …] – 指定结果按照哪几个字段来分组
[HAVING] – 过滤分组的记录必须满足的次要条件
[ORDER BY …] – 指定查询记录按一个或多个条件排序
[LIMIT {[offset,]row_count | row_countOFFSET offset}];
– 指定查询的记录从哪条至哪条
SELECT * FROMstudent
SELECTloginpwd,studentnameFROMstudent
注意 : [ ] 括号代表可选的 , { }括号代表必选得
5.2.2 指定查询字段
查询所有学生
SELECT * fromstudent
查询特定字段 并作别名 AS 可以省略 同时也可以给表做别名
SELECTloginpwdAS 登录密码1,studentnameAS ‘姓名2’ FROMstudentAS s
AS 别名
AS 子句作为别名
作用:
可给数据列取一个新别名
可给表取一个新别名
可把经计算或总结的结果用另一个新名称来代替
concat拼接
在每个学生姓名前都加上姓名两个字 并起了别名
SELECT CONCAT(‘姓名:’,studentname) AS 新名字 FROMstudent

5.2.3 DISTINCT 去重
作用 : 去掉SELECT查询返回的记录结果中重复的记录 ( 返回所有列的值都相同 ) , 只返回一条
– # 查看哪些同学参加了考试(学号) 去除重复项
SELECT * FROM result; – 查看考试成绩
SELECT studentno FROM result; – 查看哪些同学参加了考试
SELECT DISTINCT studentno FROM result; – 了解:DISTINCT 去除重复项 , (默认是ALL)
5.2.4 使用表达式的列
数据库中的表达式: 一般由文本值 , 列值 , NULL , 函数和操作符等组成
应用场景 :
①SELECT语句返回结果列中使用
②SELECT语句中的ORDER BY , HAVING等子句中使用
③DML语句中的 where 条件语句中使用表达式
– selcet查询中可以使用表达式
SELECT @@auto_increment_increment; – 查询自增步长
SELECT VERSION(); – 查询版本号
SELECT 100*3-1 AS 计算结果; – 表达式
– 学员考试成绩集体提分一分查看
SELECT studentno,StudentResult+1 AS ‘提分后’ FROM result;
这个加一分并不会修改原始数据库中的成绩 与update set不同
避免SQL返回结果中包含 ’ . ’ , ’ * ’ 和括号等干扰开发语言程序.
5.2.5 where 字句
5.2.5.1 逻辑操作符

查询成绩在95-100之间的学生
①SELECTstudentno,studentresultFROMresult
WHEREstudentresult>=95 &&studentresult<=100
②SELECT
studentno,studentresultFROMresult
WHEREstudentresult>=95 ANDstudentresult<=100
③SELECT
studentno,studentresultFROMresult
WHEREstudentresultBETWEEN 95 AND 100
–查询除了1000号学生之外的其他学生的成绩
①SELECT
studentno,studentresultFROMresult
WHEREstudentno!=1000
②SELECT
studentno,studentresultFROMresult
WHERE NOTstudentno=1000
5.2.2.1 模糊查询

in是要求匹配具体数值
测试
-- 模糊查询 between and \ like \ in \ null
-- =============================================
-- LIKE
-- =============================================
-- 查询姓刘的同学的学号及姓名
-- like结合使用的通配符 : % (代表0到任意个字符) _ (一个字符)
SELECT studentno,studentname FROM student
WHERE studentname LIKE '刘%';
-- 查询姓刘的同学,后面只有一个字的
SELECT studentno,studentname FROM student
WHERE studentname LIKE '刘_';
-- 查询姓刘的同学,后面只有两个字的
SELECT studentno,studentname FROM student
WHERE studentname LIKE '刘__';
-- 查询姓名中含有 嘉 字的
SELECT studentno,studentname FROM student
WHERE studentname LIKE '%嘉%';
-- 查询姓名中含有特殊字符的需要使用转义符号 '\'
-- 自定义转义符关键字: ESCAPE ':'
-- =============================================
-- IN(具体数值)
-- =============================================
-- 查询学号为1000,1001,1002的学生姓名
SELECT studentno,studentname FROM student
WHERE studentno IN (1000,1001,1002);
-- 查询地址在北京,南京,河南洛阳的学生
SELECT studentno,studentname,address FROM student
WHERE address IN ('北京','南京','河南洛阳');
-- =============================================
-- NULL 空
-- =============================================
-- 查询出生日期没有填写的同学
-- 不能直接写=NULL , 这是代表错误的 , 用 is null
SELECT studentname FROM student
WHERE BornDate IS NULL;
-- 查询出生日期填写的同学
SELECT studentname FROM student
WHERE BornDate IS NOT NULL;
-- 查询没有写家庭住址的同学(空字符串不等于null)
SELECT studentname FROM student
WHERE Address='' OR Address IS NULL;
5.2.6 连接查询
5.2.6.1 JOIN对比
JOIN 对比
一般常用的是这三种

以左表为基础,就用左连接,以右表为基础就用右连接,如果要查询两个表中的交集就用内连接。
思路:
①看我们需要的字段来自哪些表
②看这些表中交叉的部分 即我们通过什么来将表连接起来
③判断使用什么连接,看以哪个表为基础。
– 左连接 (查询了所有同学,不考试的也会查出来)
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
LEFT JOIN result r
ON r.studentno = s.studentno
– 查一下缺考的同学(左连接应用场景)
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
LEFT JOIN result r
ON r.studentno = s.studentno
WHERE StudentResult IS NULL
注意:如果这里我们的studetno是result表中的学号的话,那么我们左连接就会导致student表中有学号,但是没有参加考试导致result中没有记录的学生学号为null,因为最后选择的是result表中的学号,即使左连接,这些学号也不会显示。
– 查询参加了考试的同学信息(学号,学生姓名,科目编号,分数)
– 右连接(也可实现)
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
RIGHT JOIN result r
ON r.studentno = s.studentno
– 思考题:查询参加了考试的同学信息(学号,学生姓名,科目名,分数)
首先需要三个表 student,subject,result,我们先两两相连
5.2.6.2 自连接
自连接
数据表与自身进行连接
需求:从一个包含栏目ID , 栏目名称和父栏目ID的表中
查询父栏目名称和其他子栏目名称
– 创建一个表
CREATE TABLEcategory(
categoryidINT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT ‘主题id’,
pidINT(10) NOT NULL COMMENT ‘父id’,
categoryNameVARCHAR(50) NOT NULL COMMENT ‘主题名字’,
PRIMARY KEY (categoryid)
) ENGINE=INNODB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8
– 插入数据
INSERT INTOcategory(categoryid,pid,categoryName)
VALUES(‘2’,‘1’,‘信息技术’),
(‘3’,‘1’,‘软件开发’),
(‘4’,‘3’,‘数据库’),
(‘5’,‘1’,‘美术设计’),
(‘6’,‘3’,‘web开发’),
(‘7’,‘5’,‘ps技术’),
(‘8’,‘2’,‘办公信息’);
– 编写SQL语句,将栏目的父子关系呈现出来 (父栏目名称,子栏目名称)
– 核心思想:把一张表看成两张一模一样的表,然后将这两张表连接查询(自连接)
SELECT a.categoryName AS ‘父栏目’,b.categoryName AS ‘子栏目’
FROM category AS a,category AS b
WHERE a.categoryid=b.pid
– 思考题:查询参加了考试的同学信息(学号,学生姓名,科目名,分数)
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOINsubjectsub
ON sub.subjectno = r.subjectno
– 查询学员及所属的年级(学号,学生姓名,年级名)
SELECT studentno AS 学号,studentname AS 学生姓名,gradename AS 年级名称
FROM student s
INNER JOIN grade g
ON s.GradeId= g.GradeID
– 查询科目及所属的年级(科目名称,年级名称)
SELECT subjectname AS 科目名称,gradename AS 年级名称
FROM SUBJECT sub
INNER JOIN grade g
ON sub.gradeid = g.gradeid
– 查询 数据库结构-1 的所有考试结果(学号 学生姓名 科目名称 成绩)
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOINsubjectsub
ON r.subjectno = sub.subjectno
WHERE subjectname=‘数据库结构-1’
5.2.7 排序
语法 : ORDER BY
ORDER BY 语句用于根据指定的列对结果集进行排序。
ORDER BY 语句默认按照ASC升序对记录进行排序。
如果您希望按照降序对记录进行排序,可以使用 DESC 关键字。
– 查询 数据库结构-1 的所有考试结果(学号 学生姓名 科目名称 成绩)
– 按成绩降序排序
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOINsubjectsub
ON r.subjectno = sub.subjectno
WHERE subjectname=‘数据库结构-1’
ORDER BY StudentResult DESC
5.2.8 分页
语法 : SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offset
好处 : (用户体验,网络传输,查询压力)
推导:
第一页 : limit 0,5
第二页 : limit 5,5
第三页 : limit 10,5
…
第N页 : limit (pageNo-1)*pageSzie,pageSzie
[pageNo:页码,pageSize:单页面显示条数]
– 每页显示5条数据
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOINsubjectsub
ON r.subjectno = sub.subjectno
WHERE subjectname=‘数据库结构-1’
ORDER BY StudentResult DESC , studentno
LIMIT 0,5
– 查询 JAVA第一学年 课程成绩前10名并且分数大于80的学生信息(学号,姓名,课程名,分数)
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOINsubjectsub
ON r.subjectno = sub.subjectno
WHERE subjectname=‘JAVA第一学年’
ORDER BY StudentResult DESC
LIMIT 0,10
5.2.9 子查询 嵌套查询
什么是子查询?
在查询语句中的WHERE条件子句中,又嵌套了另一个查询语句
嵌套查询可由多个子查询组成,求解的方式是由里及外;
子查询返回的结果一般都是集合,故而建议使用IN关键字;
– 查询 高等数学-1 的所有考试结果(学号,科目编号,成绩),并且成绩降序排列
– 方法一:使用连接查询
SELECT r.studentno,r.subjectno,studentresult
FROMresultr
INNER JOINsubjectsub
ON sub.subjectno=r.subjectno
WHEREsubjectname=‘高等数学-1’
ORDER BYstudentresultDESC
–使用子查询
SELECTstudentno,subjectno,studentresult
FROMresult
WHEREsubjectnoIN(
SELECTsubjectno
FROMsubject
WHEREsubjectname=‘高等数学-1’
)
ORDER BYstudentresultDESC
– 查询课程为 高等数学-2 且分数不小于80分的学生的学号和姓名
– 方法一:使用连接查询
SELECT s.studentno,studentname
FROM student s
INNER JOINresultr
ON s.studentno=r.studentno
INNER JOINsubjectsub
ON sub.subjectno=r.subjectno
WHEREsubjectname=‘高等数学-2’ ANDstudentresult>=80
– 方法二:使用子查询
SELECTstudentno,studentname
FROM student
WHEREstudentnoIN(
SELECTstudentnoFROM result
WHEREstudentresult>=80 ANDsubjectno=(
SELECTsubjectnoFROMsubjectWHEREsubjectname=‘高等数学-2’
)
)
/*
练习题目:
查 C语言-1 的前5名学生的成绩信息(学号,姓名,分数)
使用子查询,查询cui同学所在的年级名称
*/
SELECT s.
studentno,studentname,studentresult
FROMstudents
INNER JOINresultr
ON r.studentno=s.studentno
WHEREsubjectnoIN(
SELECTsubjectnoFROMsubject
WHEREsubjectname=‘C语言-1’
)
ORDER BYstudentresultDESC
LIMIT 0,5
SELECT
gradename
FROM grade
WHEREgradeid=(
SELECTgradeidFROMstudent
WHEREstudentname=‘cui’
)
5.2.10 MYSQL常用函数
数据函数
SELECT ABS(-8); /绝对值/
SELECT CEILING(9.4); /向上取整/
SELECT FLOOR(9.4); /向下取整/
SELECT RAND(); /随机数,返回一个0-1之间的随机数/
SELECT SIGN(0); /符号函数: 负数返回-1,正数返回1,0返回0/
字符串函数
SELECT CHAR_LENGTH(‘狂神说坚持就能成功’); /返回字符串包含的字符数/
SELECT CONCAT(‘我’,‘爱’,‘程序’); /合并字符串,参数可以有多个/
SELECT INSERT(‘我爱编程helloworld’,1,2,‘超级热爱’); /替换字符串,从某个位置开始替换某个长度/
index从1开始
insert(str,pos,len,new_str) 如果len为0就是插入
上述例子是 从1开始 替换2个 所以就把我爱这两个变为了超级热爱
SELECT LOWER(‘KuangShen’); /小写/
SELECT UPPER(‘KuangShen’); /大写/
SELECT LEFT(‘hello,world’,5); /从左边截取/
SELECT RIGHT(‘hello,world’,5); /从右边截取/
SELECT REPLACE(‘狂神说坚持就能成功’,‘坚持’,‘努力’); /替换字符串/
SELECT SUBSTR(‘狂神说坚持就能成功’,4,6); /截取字符串,开始和长度/
SELECT REVERSE(‘狂神说坚持就能成功’); /*反转
– 查询姓周的同学,改成邹
SELECT REPLACE(studentname,‘周’,‘邹’) AS 新名字
FROM student WHERE studentname LIKE ‘周%’;
日期和函数
SELECT CURRENT_DATE(); /获取当前日期/
SELECT CURDATE(); /获取当前日期/
SELECT NOW(); /获取当前日期和时间/
SELECT LOCALTIME(); /获取当前日期和时间/
SELECT SYSDATE(); /获取当前日期和时间/
– 获取年月日,时分秒
SELECT YEAR(NOW());
SELECT MONTH(NOW());
SELECT DAY(NOW());
SELECT HOUR(NOW());
SELECT MINUTE(NOW());
SELECT SECOND(NOW());
系统信息函数
SELECT VERSION(); /版本/
SELECT USER(); /用户/
5.2.11 聚合函数以及分组过滤
函数名称 描述
COUNT() 返回满足Select条件的记录总和数,如 select count(*) 【不建议使用 ,效率低】
SUM() 返回数字字段或表达式列作统计,返回一列的总和。
AVG() 通常为数值字段或表达列作统计,返回一列的平均值
MAX() 可以为数值字段,字符字段或表达式列作统计,返回最大的值。
MIN() 可以为数值字段,字符字段或表达式列作统计,返回最小的值。
– 聚合函数
/COUNT:非空的/
SELECT COUNT(studentname) FROM student;
SELECT COUNT() FROM student;
SELECT COUNT(1) FROM student; /推荐/
– 从含义上讲,count(1) 与 count() 都表示对全部数据行的查询。
– count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。
– count() 包括了所有的列,相当于行数,在统计结果的时候,包含字段为null 的记录;
– count(1) 用1代表代码行,在统计结果的时候,包含字段为null 的记录 。
/*
很多人认为count(1)执行的效率会比count()高,原因是count()会存在全表扫描,而count(1)可以针对一个字段进行查询。其实不然,count(1)和count(*)都会对全表进行扫描,统计所有记录的条数,包括那些为null的记录,因此,它们的效率可以说是相差无几。而count(字段)则与前两者不同,它会统计该字段不为null的记录条数。
下面它们之间的一些对比:
1)在表没有主键时,count(1)比count()快
2)有主键时,主键作为计算条件,count(主键)效率最高;
3)若表格只有一个字段,则count()效率较高。
*/
SELECT SUM(StudentResult) AS 总和 FROM result;
SELECT AVG(StudentResult) AS 平均分 FROM result;
SELECT MAX(StudentResult) AS 最高分 FROM result;
SELECT MIN(StudentResult) AS 最低分 FROM result;
题目:
– 查询不同课程的平均分,最高分,最低分
– 前提:根据不同的课程进行分组
SELECT subjectname,AVG(studentresult) AS 平均分,MAX(StudentResult) AS 最高分,MIN(StudentResult) AS 最低分
FROM result AS r
INNER JOINsubjectAS s
ON r.subjectno = s.subjectno
GROUP BY r.subjectno
HAVING 平均分>80;
注意:
where写在group by前面.
要是放在分组后面的筛选
要使用HAVING…
因为having是从前面筛选的字段再筛选,而where是从数据表中的>字段直接进行的筛选的
*/
5.2.12 补充知识 MD5加密
一、MD5简介
MD5即Message-Digest Algorithm 5(信息-摘要算法5),用于确保信息传输完整一致。是计算机广泛使用的杂凑算法之一(又译摘要算法、哈希算法),主流编程语言普遍已有MD5实现。将数据(如汉字)运算为另一固定长度值,是杂凑算法的基础原理,MD5的前身有MD2、MD3和MD4。
二、实现数据加密
新建一个表 testmd5
CREATE TABLE
testmd5(
idINT(4) NOT NULL,
nameVARCHAR(20) NOT NULL,
pwdVARCHAR(50) NOT NULL,
PRIMARY KEY (id)
) ENGINE=INNODB DEFAULT CHARSET=utf8
插入一些数据
INSERT INTO testmd5 VALUES(1,‘kuangshen’,‘123456’),(2,‘qinjiang’,‘456789’)
如果我们要对pwd这一列数据进行加密,语法是:
update testmd5 set pwd = md5(pwd);
如果单独对某个用户(如kuangshen)的密码加密:
INSERT INTO testmd5 VALUES(3,‘kuangshen2’,‘123456’)
update testmd5 set pwd = md5(pwd) where name = ‘kuangshen2’;
插入新的数据自动加密
INSERT INTO testmd5 VALUES(4,‘kuangshen3’,md5(‘123456’));
查询登录用户信息(md5对比使用,查看用户输入加密后的密码进行比对)
SELECT * FROM testmd5 WHERE
name=‘kuangshen’ AND pwd=MD5(‘123456’);
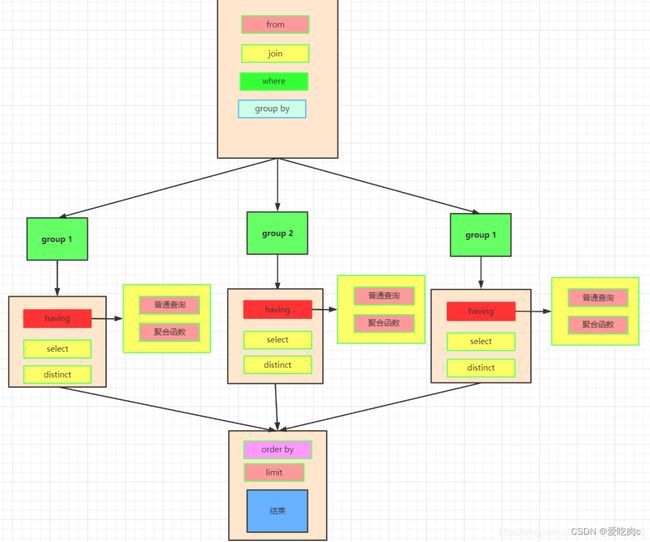
5.2.13 select 执行顺序
我们先执行from,join来确定表之间的连接关系,得到初步的数据
where对数据进行普通的初步的筛选
group by 分组
各组分别执行having中的普通筛选或者聚合函数筛选。
然后把再根据我们要的数据进行select,可以是普通字段查询也可以是获取聚合函数的查询结果,如果是集合函数,select的查询结果会新增一条字段
将查询结果去重distinct
最后合并各组的查询结果,按照order by的条件进行排序