25 | 消费者组重平衡全流程解析
文章目录
- Kafka 核心技术与实战
-
- 深入Kafka内核
-
- 25 | 消费者组重平衡全流程解析
-
- 触发与通知
- 消费者组状态机
- 消费者端重平衡流程
- Broker 端重平衡场景剖析
Kafka 核心技术与实战
深入Kafka内核
25 | 消费者组重平衡全流程解析
消费者组的重平衡流程的作用是让组内所有的消费者实例就消费哪些主题分区达成一致。重平衡需要借助 Kafka Broker 端的 Coordinator 组件,在 Coordinator 的帮助下完成整个消费者组的分区重分配。
触发与通知
重平衡的 3 个触发条件:
- 组成员数量发生变化。
- 订阅主题数量发生变化。
- 订阅主题的分区数发生变化。
在实际生产环境中,因命中第 1 个条件而引发的重平衡是最常见。消费者组中的消费者实例依次启动也属于第 1 种情况,也就是说,每次消费者组启动时,必然会触发重平衡过程。
重平衡过程是靠消费者端的心跳线程(Heartbeat Thread)通知到其他消费者实例。
Kafka Java 消费者需要定期地发送心跳请求(Heartbeat Request)到 Broker 端的协调者,以表明它还存活着。
在 Kafka 0.10.1.0 版本之前,发送心跳请求是在消费者主线程完成的,也就是代码调用 KafkaConsumer.poll 方法的那个线程。
消息处理逻辑也是在主线程中完成的。因此,一旦消息处理消耗了过长的时间,心跳请求将无法及时发到协调者那里,导致协调者“错误地”认为该消费者已“死”。
所以,自 0.10.1.0 版本开始,社区引入了一个单独的心跳线程来专门执行心跳请求发送,避免了这个问题。
重平衡的通知机制正是通过心跳线程来完成的。 当协调者决定开启新一轮重平衡后,它会将 REBALANCE_IN_PROGRESS 封装进心跳请求的响应中,发还给消费者实例。当消费者实例发现心跳响应中包含了 REBALANCE_IN_PROGRESS,就能立马知道重平衡又开始了,这就是重平衡的通知机制。
消费者组状态机
重平衡一旦开启,Broker 端的协调者组件就要开始忙了,主要涉及到控制消费者组的状态流转。当前,Kafka 设计了一套消费者组状态机(State Machine),来帮助协调者完成整个重平衡流程。
目前,Kafka 为消费者组定义了 5 种状态,它们分别是:Empty、Dead、PreparingRebalance、CompletingRebalance 和 Stable。
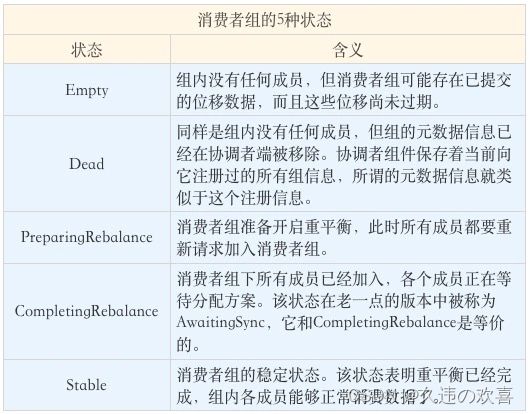
状态机的各个状态流转:
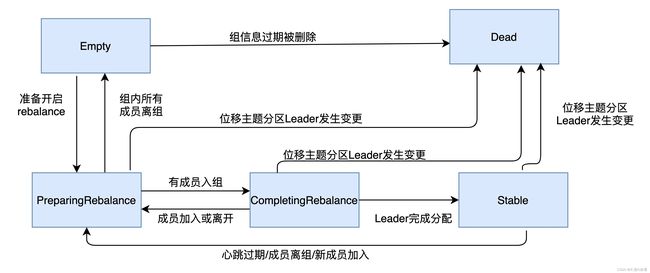
一个消费者组最开始是 Empty 状态,当重平衡过程开启后,它会被置于 PreparingRebalance 状态等待成员加入,之后变更到 CompletingRebalance 状态等待分配方案,最后流转到 Stable 状态完成重平衡。
当有新成员加入或已有成员退出时,消费者组的状态从 Stable / CompletingRebalance 直接跳到 PreparingRebalance 状态,此时,所有现存成员就必须重新申请加入组。当所有成员都退出组后,消费者组状态变更为 Empty。Kafka 定期自动删除过期位移的条件就是,组要处于 Empty 状态。 因此,如果消费者组停掉了很长时间(超过 7 天),那么 Kafka 很可能就把该组的位移数据删除了。
消费者端重平衡流程
重平衡的完整流程需要消费者端和协调者组件共同参与才能完成。
在消费者端,重平衡分为两个步骤:分别是加入组和等待领导者消费者(Leader Consumer)分配方案。这两个步骤分别对应两类特定的请求:JoinGroup 请求和 SyncGroup 请求。
JoinGroup 请求的处理流程:
当组内成员加入组时,它会向协调者发送 JoinGroup 请求。在该请求中,每个成员都要将自己订阅的主题上报,这样协调者就能收集到所有成员的订阅信息。一旦收集了全部成员的 JoinGroup 请求后,协调者会从这些成员中选择一个担任这个消费者组的领导者。
通常情况下,第一个发送 JoinGroup 请求的成员自动成为领导者。领导者消费者的任务是收集所有成员的订阅信息,然后根据这些信息,制定具体的分区消费分配方案。
选出领导者之后,协调者会把消费者组订阅信息封装进 JoinGroup 请求的响应体中,然后发给领导者,由领导者统一做出分配方案后,进入到下一步:发送 SyncGroup 请求。

JoinGroup 请求的主要作用是将组成员订阅信息发送给领导者消费者,待领导者制定好分配方案后,重平衡流程进入到 SyncGroup 请求阶段。
SyncGroup 请求的处理流程:
SyncGroup 请求的主要目的,就是让协调者把领导者制定的分配方案下发给各个组内成员。当所有成员都成功接收到分配方案后,消费者组进入到 Stable 状态,即开始正常的消费工作。
Broker 端重平衡场景剖析
场景一:新成员入组
新成员入组是指组处于 Stable 状态后,有新成员加入。
当协调者收到新的 JoinGroup 请求后,它会通过心跳请求响应的方式通知组内现有的所有成员,强制它们开启新一轮的重平衡。具体的过程如下:
场景二:组成员主动离组
主动离组是指消费者实例所在线程或进程调用 close() 方法主动通知协调者它要退出。
场景三:组成员崩溃离组
崩溃离组是指消费者实例出现严重故障,突然宕机导致的离组。它和主动离组是有区别的,因为后者是主动发起的离组,协调者能马上感知并处理。但崩溃离组是被动的,协调者通常需要等待一段时间才能感知到,这段时间一般是由消费者端参数 session.timeout.ms 控制的。也就是说,Kafka 一般不会超过 session.timeout.ms 就能感知到这个崩溃。
场景四:重平衡时协调者对组内成员提交位移的处理
正常情况下,每个组内成员都会定期汇报位移给协调者。当重平衡开启时,协调者会给予成员一段缓冲时间,要求每个成员必须在这段时间内快速地上报自己的位移信息,然后再开启正常的 JoinGroup/SyncGroup 请求发送。