c语言-数据结构-单链表的实现与解析
目录
1、链表的概念
2、链表的结构
3、链表节点的创建
4、链表的打印
5、链表的头插
6、链表的尾插
7、链表的头删与尾删
8、查找数据
9、中间插入数据
9.1 在pos后面插入数据
9.2 在pos前面插入数据
10、删除中间位置的数据
10.1 删除pos当前位置的数据
10.2 删除pos后一个数据
11、释放内存
结语:
1、链表的概念
链表在数据结构中是一种基本的存储数据的方式,链表由多个结构体构成,通常把这些结构体称为链表的节点。他的物理性质其实一种非连续、非顺序的结构形式,只是通过了节点中的指针将各个节点在逻辑上连接了起来,从而达到了“链式”效果。
2、链表的结构
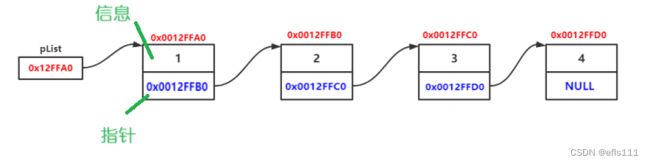
其中pList为头指针,其作用是定位链表,可以把他理解成数组中的数组名,我们都知道数组名就是首元素的地址,有了数组名就能够遍历整个数组,那么pList效果也是如此,pList保存的就算首个节点的地址,有了pList就能遍历整个链表。
每个节点中的1、2、3、4表示该节点所携带的信息,下方的空间表示该结构体里的成员->指针变量,保存的是下一个节点的地址,目的就是将他们“连起来”,这里注意最后一个节点规定指向空。
3、链表节点的创建
从链表的结构得知,链表的节点是由信息、指针构成的(实际上就节点就是一个结构体),直接上代码:
typedef int SLDataType;
typedef struct SList
{
SLDataType data;//信息
struct SList* next;//指针
}SL;那么有了节点的结构体成员,如何将这些成员进行创建和初始化?这里我们在堆上申请空间以便于存放节点成员的数据,因为如果在栈上创建则受生命周期的影响,即每次出函数后,该节点就会被系统回收。在堆上申请则不会被回收,因此需要用到动态内存开辟函数。
节点初始化及创建代码如下:
SLDataType* SetUpNewnode(SLDataType x)//创建节点
{
SL* newnode = (SL*)malloc(sizeof(SL));//动态开辟内存
if (newnode == NULL)//判断是否开辟成功
{
perror("SetUpNewnode");
return;
}
newnode->data = x;//初始化数值
newnode->next = NULL;//节点内的指针要置空,因为该节点可能是最后一个节点
return newnode;//返回节点的地址
}4、链表的打印
链表的打印实质上就是遍历整个链表,涉及到结构体指针的传参,在使用该打印函数之前,得调用该函数,因此主函数中的写法可以是这样:
int main()
{
SL* plist = NULL;//头指针的创建
Print(plist);//传参,因为是只需要遍历链表,因此传一级指针就行
return 0;
}这里注意一点是plist是一个结构体指针,初始化时将他置为空,他的作用就跟上文说的一样,目的是能定位链表。打印链表无需更改plist的值,因此传一级指针即可,但是后续有涉及到更改pilst的值的情况,那时候就需要传plist的地址了,而那时候函数的形参需要用二级指针接收。
打印函数代码如下:
void Print(SL* phead)//打印链表,phead是plist的形参,他的值就是plist的值
{
//assert(phead);//不断言的原因在于空链表一样可以打印
SL* cur = phead;//把phead的值赋给cur,让cur去遍历整个链表
while (cur)//cur为空则遍历完成
{
printf("%d ", cur->data);//打印节点中的信息
cur = cur->next;//把cur指向的下一个节点的地址给到cur,让cur“走”起来
}
printf("NULL");//表示如果链表为空则只打印NULL
}这里的phead与plist都是一个指针变量,并不是一个节点,只是他们保存的是头节点的地址,因此指向头节点,可以对头节点进行一系列的操作。包括cur也是创建出了的一个指针变量,他用于指向链表中的各个节点,从而能够间接操作链表中的节点,但是他本身并不是一个节点。
这里的核心在于cur = cur->next;,这句话的逻辑在链表中尤为重要,他的逻辑是让cur指向该节点的下一个节点。后面的所有功能几乎都用到了这个逻辑。

5、链表的头插
链表的头插核心思想是更改了plist的值,因此传参的时候需要传plist的地址,函数的形参需要用二级指针来接收。头插的示意图如下:

头插节点的注意事项:先将头指针plist指向的节点的位置存起来,比如:可以让newnode的next指针指向数据为1的节点,也就是让1节点的地址保存起来,然后在把newnode的值也就是新开辟的节点的地址给到plist,完成插入。
此处不能先把newnode赋予plist,不然plist就无法找到1节点了。
头插代码如下:
void PushFront(SL** phead, SLDataType x)//头插,形参用二级指针接收
{
assert(phead);//断言phead,防止传错。不断言*phead是因为链表为空时可以进行头插
SL* newnode = SetUpNewnode(x);//创建节点,SetUpNewnode是上文节点的初始化的函数
newnode->next = *phead;//(*phead)=plist,将节点的next指针指向头指针原先指向的节点
*phead = newnode;//将节点的地址给到*phead,断开原先指向的节点,让头指针指向新的节点
}
int main()
{
SL* plist = NULL;
PushFront(&plist, 2);//涉及到更改plist的内容,因此传该指针的地址
Print(plist);
return 0;
}这里的*phead就是plist,表示头指针。plist指向哪则*phead就指向哪,对*phead的修改就是对plist的修改。
6、链表的尾插
链表的尾插看似是在链表的最后一个节点的后面插入一个节点即可,实际上要考虑两种情况。
1、当链表中本就存在节点的时候,直接把要插入的节点的地址赋给最后一个节点的next指针即可。无需更改plist的值。
2、当链表为空时,尾插与头插逻辑一样,都是要更改plist的值。
尾插代码如下:
void PushBack(SL** phead, SLDataType x)//尾插
{
assert(phead);//断言phead,防止传错。不断言*phead是因为链表为空时可以进行头插
SL* newnode = SetUpNewnode(x);//创建节点
if (*phead == NULL)//链表为空的情况
{
*phead = newnode;
}
else//链表有节点的情况
{
SL* poi = *phead;
while (poi->next != NULL)//遍历到最后一个节点停下来
{
poi = poi->next;//poi逐个往后走
}
poi->next = newnode;//插入新节点
}
}
int main()
{
//test5();
SL* plist = NULL;
PushFront(&plist, 2);//头插
PushBack(&plist, 20);//尾插,同样传plist的地址,因此存在改变plist的可能性
Print(plist);//打印函数
return 0;
}运行结果:

7、链表的头删与尾删
链表的头删、尾删与头插、尾插的区别在于头删与尾插不能对空链表进行操作,因此要加上对空链表的断言,且头删、尾删有改变plist的可能性,因此要传plist的地址。
头删逻辑示意图如下:
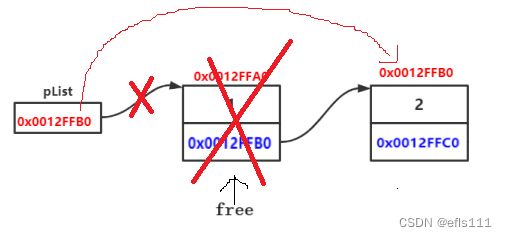
头删代码如下:
void PopFront(SL** phead)//头删
{
assert(phead);
assert(*phead);//防止链表为空也执行下面代码
SL* poi = *phead;*phead的值就是第一个节点的地址
*phead = poi->next;//让*phead指向第二个节点
free(poi);//释放第一个节点
}对于尾删而言,其与头删又有些区别,而且尾删开辟了一个新的思路:用两个指针来维护链表。因为删掉最后一个节点不单单是free最后一个节点,还要将倒数第二个节点的next指向NULL,这时候如果只有一个节点遍历链表是无法找到倒数第二个节点的位置的,因此用两个指针,一前一后的形式来实现尾删。
尾删逻辑示意图:
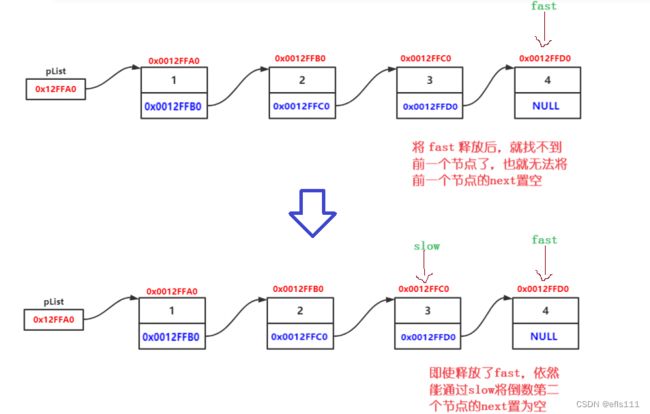
尾删代码实现:
void PopBack(SL** phead)//尾删
{
assert(phead);
assert(*phead);//断言链表不能为空
if ((*phead)->next == NULL)//链表只有一个节点的情况
{
free(*phead);//释放该节点
(*phead) = NULL;//*phead要置空
}
else//当链表多个节点的情况
{
SL* poi = *phead;//定义快指针
SL* prev = *phead;//定义慢指针
while (poi->next != NULL)//遍历快指针到最后一个节点停下来
{
prev = poi;//慢指针在快指针的前一个节点
poi = poi->next;//快指针不断往后走
}
free(poi);
prev->next = NULL;//将慢指针指向的倒数第二个节点的next置空
}
}8、查找数据
查找数据的逻辑相对于较简单,即:输入要查找的数据,然后遍历链表,如果查到了则返回该数据所在节点的地址,如果没查到说明链表没有改数据则返回NULL。查找函数代码如下:
SL* SlSearch(SL* phead, SLDataType x)//查找
{
SL* poi = phead;//用poi遍历链表
while (poi)//poi指向空的时候表示已经遍历完成链表
{
if (poi->data == x)
{
return poi;//找到了返回poi的值,即该节点的地址
}
poi = poi->next;//poi不断往后走
}
return NULL;//没找到返回空
}9、中间插入数据
插入数据的概念是在某个位置的前面或者后面插入,并非是直接插到该位置从而覆盖该位置原先的值。因此在中间位置pos插入分两种情况:1、在pos位置的前面插入。2、在pos位置的后面插入。这里的pos指的是某个节点的地址。
9.1 在pos后面插入数据
在pos后面插入则无需考虑会不会改变plist的值,因为能在pos后面进行插入,说明pos这个位置是一定有一个节点的,因此传一级指针即可。代码如下:
void PushInsertAfter(SL* pos, SLDataType x)//从pos后面插
{
assert(pos);//pos不能为空,若pos为空则插入数据就没有意义了
SL* newnode = SetUpNewnode(x);//创建节点
newnode->next = pos->next;//让新节点指向pos的下一个节点
pos->next = newnode;//让pos指向新节点,完成pos后面插入节点
}9.2 在pos前面插入数据
若从pos的前面插入则有可能会改变plist的值,因此要传二级指针。因为在头节点插入,则会改变头指针的指向。代码如下:
void PushInsertFront(SL** phead, SL* pos, SLDataType x)//从pos前面插
{
assert(phead);
assert(pos);//断言pos不能为空
if (pos == *phead)//从头节点前插入的情况
{
PushFront(phead, x);//即头插的逻辑,因此可以直接调用上文的头插函数
/**phead = newnode;
newnode->next = pos;*///也可以根据逻辑重新写代码
}
else//从其他节点之前插入的情况
{
SL* poi = *phead;
while (poi->next != pos)//遍历找到在pos之前的节点
{
poi = poi->next;
}
SL* newnode = SetUpNewnode(x);//创建节点
newnode->next = pos;//将新节点指向pos节点
poi->next = newnode;//再将pos之前的节点指向新节点,完成在pos之前插入新节点
}
}这里强调一点插入数据的时候要注意上文说到的插入数据时的注意事项。即节点地址的赋值和指向的顺序不能出错。
10、删除中间位置的数据
删除pos位置的数据切记不能删除pos之前的数据,因为若pos指向的节点是第一个节点(头节点),则不存在pos之前的数据。但pos后面的数据是一直都存在的,因此删除中间数据也分两种情况:1、删除pos之后的数据。2、删除pos当前位置的数据。
10.1 删除pos当前位置的数据
删除pos位置的数据也有可能影响plist的值,因此这里的逻辑与尾删的逻辑如出一辙,只不过这里需要找到pos的位置。代码如下:
void PopInsert(SL** phead, SL* pos)//删除pos位置的数据
{
assert(pos);
assert(phead);
if (pos == *phead)//表示pos指向的是第一个节点,要删除第一个节点,即头删逻辑
{
*phead = pos->next;
free(pos);
}
else//pos是其他节点的情况
{
SL* poi = *phead;
while (poi->next != pos)//找到pos的前一个节点
{
poi = poi->next;
}
poi->next = pos->next;//将pos前一个节点与pos后一个节点相连
free(pos);//释放pos
}
}
10.2 删除pos后一个数据
删除pos后一个位置的数据逻辑就简单很多,因为其不影响plist的值,而且也不需要找到pos前一个位置的节点,只要有pos这个位置就能做到删除pos后面位置的数据。但是要注意的是pos后面如果是空,即pos是最后一个节点的时候无法进行删除。代码如下:
void PopInsertAfter(SL* pos)//删除pos后面的数据
{
assert(pos);
assert(pos->next);//pos后面必须有节点,不然无法删除
SL* poi = pos->next;//将pos后一个节点的地址给到poi
pos->next = poi->next;//将pos与poi后面的节点相连
free(poi);//释放poi节点
}一般删除中间位置的数据或者中间插入数据都是与查找数据相结合使用的,因为查找函数会返回节点的地址,以下是删除中间位置函数的用法:
int main()
{
SL* plist = NULL;
PushFront(&plist, 2);
PushFront(&plist, 1);
PushBack(&plist, 3);
PushBack(&plist, 4);
PushBack(&plist, 5);//让链表中存放1,2,3,4,5的数据
SL* pos = SlSearch(plist, 1);//查找数据1的节点位置,并将该节点的地址存到pos中
assert(pos);
if (pos)//如果pos是真则说明该链表中有该节点
{
PopInsertAfter(pos);//删除pos后面一个节点(即2)
PopInsert(&plist, pos);//删除pos当前的节点(即1)
Print(plist);
}
return 0;
}运行结果:

11、释放内存
由于链表中的节点是使用动态内存函数在堆上申请的,因此再使用完之后应该手动释放,防止内存泄漏。因为释放内存会让plist重新置为空,因此会改变plist的值,所以用二级指针来进行操作。释放函数如下:
void Destroy(SL** phead)//释放函数
{
assert(phead);
SL* poi = *phead;
SL* cur = NULL;
while (poi)//poi为空时表示遍历整个链表完成
{
cur = poi->next;//让cur指向poi的下一个节点,目的是标志位置
free(poi);//释放poi指向的节点
poi = cur;//把cur指向的节点给到poi,继续释放
}
*phead = NULL;//最后*phead要置空,意味着plist也置空了
}结语:
以上就是关于链表各个功能的实现与分析,如果本文对你起到了帮助,希望可以点赞+关注+收藏哦!如果有遗漏或者有误的地方欢迎大家在评论区补充~!!谢谢大家!!
( ̄︶ ̄)↗