Java单列集合——List
目录
1. 集合的分类
2. 集合的家族体系
3. 不同集合的特点
4. 集合的通用方法及源码分析
5. 遍历集合的三种方式
5.1 第一种方式,迭代器遍历
5.2 第二种方式,增强for循环
5.3 第三种方式:lambda表达式遍历
6. List集合的特殊方法
7. ArrayList集合详解
8. LinkedList集合详解
Java中的集合是一个庞大的家族,而其中集合主要非为两类
1. 集合的分类
第一类:Collection 单列集合,一次只能存取一个元素。
第二类:Map 双列集合,一次存取两个元素,以 K,V方式存取数据。
2. 集合的家族体系
第一类Collection集合家族图如下图所示: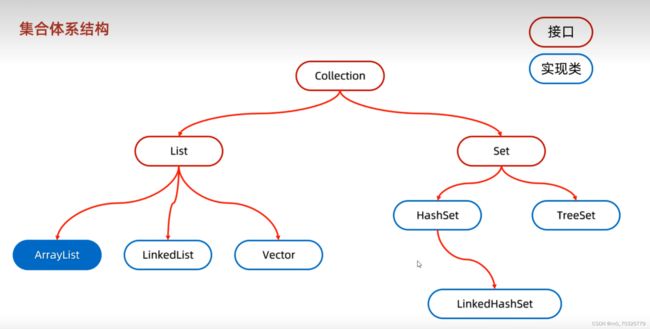
其中红色的是接口,蓝色的是实现类。
从图中可以看出,Collection 又分为两类,分别是List和Set,在这里就需要说一下List集合和Set集合有什么区别了。
3. 不同集合的特点
List集合的特点:添加的元素 有序,可重复,有索引。这里有序是指的是存和取是有序的,而不是指从大到小排序,可重复也很好理解,就是允许有相同元素出现,有索引是指每个元素都有对应的索引,我们可以通过索引获取指定位置的数据。
Set集合的特点:添加的元素 无序,不可重复,无索引。这里的无序是指存入的顺序和取出的顺序有可能是不一样的,不可重复就是指不能有相同的元素出现,如果要添加的元素Set中已经存在的话,会添加失败,无索引就是说不能根据索引找到指定位置的元素。
4. 集合的通用方法及源码分析
我们接下来先说Collection集合,Collection集合是单列集合的祖宗接口,它的功能单列集合都可以继承使用,如下图所示:

在这里有几点要注意:
(1)如果创建的是Collection类型对象,remove()方法只能使用对象的方式进行删除,因为通过索引删除只能使用有序集合List时才可以使用,在无序集合Set时不可使用,添加同理。
(2)contains()方法其实底层调用的是equals()作比较,我们看contains()方法的源码即可得知,如下图所示:

首先contains()方法调用了indexOf()方法

然后indexOf()方法又调用了indexOfRange()方法

从indexOfRange()方法体中可以看出,判断集合中是否包含某个元素,是采用for循环将集合中的所有元素都拿出来,挨个使用equals()作比较。这里也是面试官可能会问到一个小细节要格外注意
在这里我就要多提一句,如果集合中存放的是String类型,无需做什么,如果存放的是自定义类型例如某个类的对象,那么一定要在该类中重写equals()方法,因为如果不在自定义类中重写equals()方法,那么就会采用默认的比较内存地址,我们都知道,每个对象的内存地址都不一样,所以就算我们两个对象存放的内容一样,程序也会认为它们时不相等的;如果我们重写了 equals()方法,我们再去进行 for 循环遍历作比较,比较的就会使内容而不是内存地址,程序就会知道他们是相等,就能得到我们想要的结果。若不重写 equals() 方法,就无法得到我们想要的结果。
(3)判断集合是否为空的方法,其实底层是去判断数组的长度是否为空。
5. 遍历集合的三种方式
此外,Collection集合有三种遍历方式
第一种:迭代器遍历
第二种:增强for遍历
第三种:Lambda表达式遍历
5.1 迭代器遍历
使用迭代器遍历,首先要获取到迭代器,如下代码所示

第一行代码,我们可以理解成创建指针,这个指针默认指向集合0索引的位置。
第二行代码,判断当前位置是否有元素。
第三行代码,创建对应类型的参数变量接受当前元素,这里是string类型。
第四行代码,打印输出获取到的元素。
上述操作只获取到了一个元素,入股我们要获取集合中的所有元素该怎么做呢?
很简单,只要在外边套一层while循环即可,如下图所示:

可以看出while循环,当it.hasNext() = false时,循环结束,当集合中没有元素时,刚好it.hasNext() = false,遍历完成。
这里有几个细节点需要注意:
1. 如果已经遍历结束,让想继续获取,会爆出NoSuchElementException异常。
2. 在遍历结束后,指针不会恢复到默认位置。
3. 循环中只能使用一次next()方法。
4. 迭代器遍历时,不能用集合的方法进行增加或者删除。
5.2 第二种方式,增强for循环
1. 增强for循环底层就是迭代器,为了简化迭代器的代码书写。
2. 所有的单列集合和数组才可以使用增强for进行遍历。
增强for循环书写格式如下:

代码举例如下:

5.3 第三种方式:lambda表达式遍历
lambda表达式利用匿名内部类的形式,他的底层原理其实也是采用了for循环遍历,得到集合中的每一个元素。
lambda表达式的格式为 ()-> {} 其中()中代表的是匿名内部类的形参列表,{}中代表的是内部类的方法体。
书写格式如下:

参数类型可以省略,若参数只有一个,(s)外边的小括号可以省略,若方法体只有一行,外边的大括号{}可以省略,化简之后就可以写成
coll.forEach(s -> System.out.println(s));
6. List集合的特殊方法
OK,上面我们说完了Collection集合之后,我们再来说一说List集合,因为List是Collection的子接口,所以Collection接口中的方法List中都有,此外,因为List集合有索引,所以多了很多关于索引的方法,如下所示:

在这里关于remove()方法有一个点需要注意一下,如下图所示:

可以看到此时集合中有三个元素,分别是1,2,3;这时如果我调用remove(1),会发生什么现象呢?各位认为这个方式是会删除元素为1的元素呢?,还是会删除索引为1的元素呢?
答案是会删除索引为1的元素,这里要知道,在Java中,如果调用方法发生了重载,那么会优先调用实参跟形参类型一样的方法。因为传入的1是int类型,而根据索引删除也是int类型,根据元素内容删除是Object类型,所以会优先调用根据索引删除的方法;如果想根据元素类型删除,那么就需要把1先装箱成Integer类型,这样就会调用根据元素内容删除的方法。
List集合的遍历方式有五种,除了Collection中的三种之外,还有普通for循环遍历和列表迭代器遍历,在这里普通for循环遍历就不再多说,说一下列表迭代器便利,列表迭代器和普通的迭代器差不多,但是多了几个方法,其中比较重要的就是add()和remove(),这两个方法是可以在列表迭代时添加或者删除元素。
7. ArrayList集合详解
在看这篇文章之前,相比一些小伙伴可能对ArrayList集合多多少少有些了解,听说过下面两句话。
(1)ArrayList底层是数据结构,数组默认长度为10.
(2)当数组加满了之后,会自动扩容至原来的1.5倍。
但其实,从严和意义上来讲,这两句话并不完全对,只有ArrayList底层数据结构是数组说对了,为什么是这样呢?且看我给你一一解释。
当我们使用空参的方法创建了一个数组时,在底层其实是创建了一个长度为0的数组,你没有听错,是长度为0,而不是10,底层数组的名字叫“elementData”,而且有一个变量size记录它的长度,初始size也为0。
当我们添加第一个元素的时候,底层就会创建一个新的长度为10的数组,默认初始化值都为null,如下图所示:

当我们向集合中加入第一个元素时,size++,如下

size这里有两层含义,第一,指当前数组中元素的个数;第二,下次要存放元素的位置。
初始时size指向0,当添加了元素 “a” 之后,size++,向后移动一位,后续添加元素同理。
当我们的数组存满了10个元素之后,再想存入元素时,它就要进行扩容了,创建一个新的数组,为原数组长度的1.5倍,再将原数组中的数据拷贝至新数组中去。
这里要注意,还有另外一种情况,如果一次添加多个元素,扩容至1.5倍之后仍然放不下,那么创建的新数组的长度就会以实际的为准。
我们接下来一起看看源码吧!

上图就是Java中ArrayList集合的空参构造方法,只有一行代码,我们点进elementData跟进,

可以看到,这里面可以看到,Java底层中ArrayList的名字就叫elementData,我们再看看是谁赋值给了elementData,如下


还定义了size,初始化值为0。
所以我们可以得出结论,当我们使用空参构造创建ArrayList数组时,底层创建了一个长度为0而且名字为elementData的数组。
我们来看ArrayList数组的 add() 方法的源码,如下:

首先add里面又调用了重载调用了另一个add()方法,如下

这个add()方法里面做了判断,判断是否需要扩容,需要扩容调用了grow()方法,方法源码如下

这个grow()方法又调用了有参grow()方法,源码如下

这个grow()方法里面点用了newLength()方法去创建一个新的数组

经过层层方法,最终会得到新的扩容后的数组的长度并进行返回,以上就是关于ArrayList集合的扩容全过程。
8. LinkedList集合详解
LinkedList集合它的底层数据结构是双向链表,链表最显著的特点就是查询慢,增删快;但是如果查询的是首尾元素,查询效率也很快。

当然了,因为它是链表,所以也添加了特有的API,如下图所示:

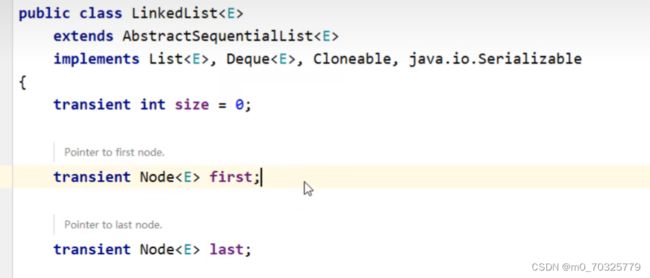
在看LinkenList源码之前,我们先来看一个它的内部类

其中Node表示链表中的一个个节点,item表示要存的元素,next表示下一个结点的位置,prev表示上一个结点的位置。
而且LinkedList类内部还维护了三个变量,
size指链表的长度;
first指链表的头节点;
last指链表的尾节点。
链表添加元素调用方法如下图,当添加第一个元素时,first和last都会指向添加的元素;而当添加第二个元素时,first仍会指向第一个元素,而last会指向第二个元素,然后第一个元素和第二个元素互相指向;后续添加元素同理。
