跟李沐学AI——动手学深度学习 PyTorch版——学习笔记pycharm版本(第二天——04-08)2023.2.27
一、基本数据操作知识
数据结构:标量、向量、矩阵
访问(记数是从0开始的):
[1,2]:单个元素
[1,:]:单行
[:,2]:单列
[1:3,1:]:1到3行,第1列及后面的所有列
[::3,::2]:行跳3提取,列跳2提取
[-1]:最后一行
1、生成tensor数据
import torch # pytorch在导入的时候就是torch
x=torch.arange(0,12) # [0,12)
print(x) # tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
print(x.shape) # torch.Size([12]) 一维的数据,共12个
print(x.numel()) #元素数量 12
torch.norm(x) # 二范数
x1=x.reshape(3,4) # 重塑为三行四列的数据
print(x1)
print(x1.shape) # torch.Size([3, 4])
print(x1.numel()) # 12
print(torch.ones(2,3,4))
print(torch.zeros(2,3,4))
print(torch.tensor([[1,2,3],[3,4,5]]))
x3=torch.arange(12,dtype=torch.float32).reshape(3,4)
x4=torch.arange(1,13,1,dtype=torch.float32).reshape(3,4)
print(x3,x4)
print(torch.cat((x3,x4),dim=0)) # dim=0是按照行拼接,行数变多
print(torch.cat((x3,x4),dim=1)) # dim=1是按照列拼接,列数变多
print(x3.sum(0)) # 行相加,行没有了,就剩列了,维度会下降
print(x3.sum(1)) # 列相加,列没有了,就剩行了,维度会下降
print(x9.sum(axis=1,keepdims=True)) # 维度保持不变
x5=x4.T # 转置
2、numpy、pandas、torch相互转变
numpy中的数据就是刺果果的数据
pandas中的数据就是有标签的数据,所以转换的时候需要用到values
torch中的数据tensor就是张量,可以进行梯度计算的一种数据
x3=torch.arange(12,dtype=torch.float32).reshape(3,4)
A=x3.numpy()
print(A)
B=torch.tensor(A) # 由numpy转为tensor
print(B)
C=B.numpy() # 由tensor转为numpy
在pandas转到其他时候,需要用到values,例如:torch.tensor(inputs.values)
3、pandas中的数据处理
读数据:
data = pd.read_csv(data_file)
分割数据
inputs = data.iloc[:,0:2]
均值填充
inputs = inputs.fillna(inputs.mean())
编码
inputs = pd.get_dummies(inputs,dummy_na=True) # 把不是数值的东西进行独热编码,维度会变大
4、复制的一些事情
x7=torch.arange(12,dtype=torch.float32).reshape(3,4)
x8=x7.T
print(x7,x8)
x9=x7.clone()
x7[:]=0
print(x7,x8,x9) # clone 是开辟内存,深度copy,而等号只是个地址指向一样的,所以,当x7=0的时候,x8也等于0,但是x9不变
二、求导
求导的数学形式
这里直接上沐神提供的图,很简单
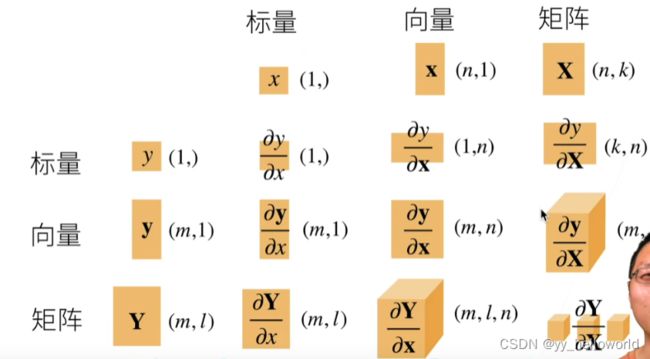
求导
x1=torch.arange(4.0,requires_grad=True) # requires_grad=True这个的意思需要保存梯度
print(x1)
print(x1.grad)
x2=2*torch.dot(x1,x1)
print(x2)
print(x2.backward()) # 这个是反向传播
print(x1.grad) # 这个是求梯度,也就是在求梯度之前需要反向传播
x1.grad.zero_() # x1的梯度清零 如果不清零,梯度就一直的累加