第三十章 FPN算法及其变种(车道线感知)
目标检测算法:FPN
论文基本信息
- 标题:Feature Pyramid Networks for Object Detection
- 链接:https://arxiv.org/abs/1612.03144
- 代码:https://paperswithcode.com/paper/feature-pyramid-networks-for-object-detection
已有方法
feature pyramid是用来检测不同scale的object的1种基本方法。
如图1和图2所示,基于feature pyrimid来检测不同scale的object,共有5种思路:4种已有思路(分别缩写为ABCD)和本文思路(FPN)

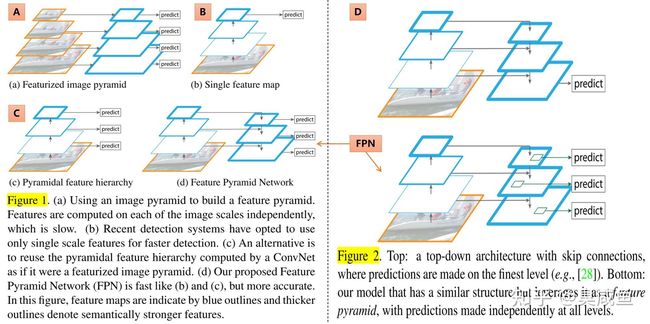
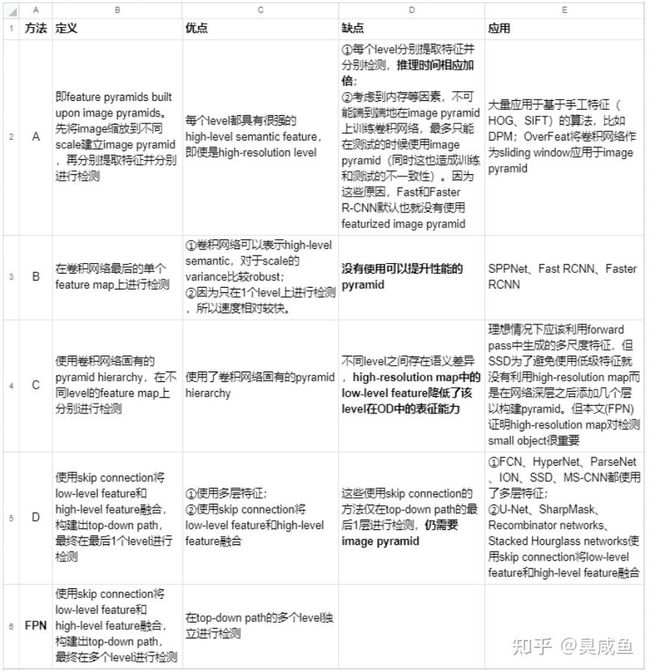
问题
feature pyramid是用来检测不同scale的object的1种基本方法,但最近的deep learning detector(RCNN、SPPNet、Fast RCNN、Faster RCNN)却都没有使用pyramid representation(在多个尺度不同的feature map上进行检测),其中部分原因是它们计算量大、需要大量memory
方法/研究内容
FPN:基于CNN固有的pyramid hierarchy,通过skip connection构建top-down path,仅需少量成本生成feature pyramid,并且feature pyramid的每个scale都具有high-level semantic feature,最终在feature pyramid的各个level上进行目标检测
创新点/优点
- 在deep learning detector中构建pyramid(而最近的RCNN、SPPNet、Fast RCNN、Faster RCNN都没有使用pyramid representation),仅需少量成本并且feature pyramid中每个level都具有high-level semantic feature
- 速度快、精度高
- generic:FPN独立于骨干网络,可以用于改进多种算法,本文将其用于Faster RCNN(RPN+Fast RCNN)、instance segmentation proposals
性能/效果
- 准确度:SOTA,将FPN应用于Faster RCNN,在COCO detection上超过所有single-model
- 速度:GPU上达6FPS
不足
- PoolNet指出top-down路径中高级语义信息会逐渐稀释
- Libra RCNN指出FPN采取的sequential manner使得integrated features更多地关注于相邻层,而较少关注其它层,每次fusion时非相邻层中的semantic information就会稀释1次
FPN算法流程
- 输入:任意scale的单张图片
- 输出:在多个level输出对应size的feature map
FPN的构建包括1个bottom-up path、1个top-down path和skip connection
bottom-up path
-
backbone:bottom-up path就是backbone的feedforward
-
stage:
-
- 定义:将backbone分为多个stage,将每个stage定义为1个pyramid level
- 输出:每个stage中,所有layer输出特征图的size是相同的,取其中最后1层的输出作为该stage的输出,因为每个stage中最深的层应该具有最强的特征
- 下采样:相邻stage之间的下采样比例为2
-
FPN for ResNet:本文将ResNet的后4个stage{C_2,C_3,C_4,C_5}(相对于输入的下采样比例分别为4、8、16、32)的输出定义为4个pyramid level,并不将第1个stage的输出包含到FPN中因为其内存占用量比较大。
ResNet50网络结构图及结构详解 - 知乎 (zhihu.com)
top-down path
- motivation:high-level semantic information有助于识别目标但有害于定位目标,low-level spatial information有害于识别目标但有助于定位目标(由于下采样次数较少,所以可以更准确地定位)
- 构建:通过skip connection来构建top-down path
- 注:在开始top-down path之前,会在bottom-up path顶层使用1×1卷积生成the coarsest resolution map
skip connection

- 将来自top-down path的coarser-resolution feature map上采样。上采样比例为2,简单起见就使用nearest neighbor upsampling
- 使用1×1卷积减少来自bottom-up path的对应feature map的通道数
- 对上2步得到的2个feature map(size和channel数量都相同)进行element-wise addition
输出
top-down path得到的输出{P_2,P_3,P_4,P_5}就是FPN的输出,其和bottom-up path中的{C_2,C_3,C_4,C_5}相对应,其中C_i和P_i的spatial size相同、C_i,P_i表示其分辨率比输入低2^i
-
3×3卷积:对每个element-wise addition得到的feature map分别进行3×3卷积,即得到FPN的输出,这样可以减少上采样带来的aliasing effect
-
More about 3×3卷积
-
- 作用:这样可以减少上采样带来的aliasing effect**(TODO:明确下aliasing effect是什么?那加上3×3卷积为什么能解决aliasing effect?)**
- 激活函数:3×3卷积后没有非线性激活函数,作者通过实验发现其影响很小(注:我在做毕设时尝试将3×3卷积换为1×1卷积,也发现影响不大)
- 通道数:FPN和传统的featurized image pyramid一样,各个pyramid level共享classifier/regressor,所以将这些3×3卷积层的输出通道数设置为256。
FPN for Faster RCNN
FPN for RPN
如未特别指出,则其余设置与Faster RCNN相同
-
FPN输出:{P_2, P_3, P_4, P_5, P_6},其中P_6只是1个步长为2的下采样,引入它是为了覆盖更大的anchor scale 512^2
-
RPN结构:1个3×3卷积 + 2个并行1×1卷积
-
RPN输入:在5个pyramid level上,分别运行同1个RPN
-
anchor:5个level共有5×3=15种anchor
-
- scale:引入FPN后,每个pyrimid level上的anchor就不需要是multi-scale的了。每个pyramid level上的anchor各只有1种scale,{P_2, P_3, P_4, P_5, P_6}上anchor的scale分别为{322,642,1282,2562,512^2}
- aspect ratio:每个level上都有3个aspect ratio的anchor(1:2, 1:1, 2:1)
-
training label assignment:
-
- 正样本:和GT BBox的IoU最大的anchor、和GT BBox的IoU大于0.7的anchor
- 负样本:和所有GT BBox的IoU都小于0.3的anchor
-
GT BBox assignment:并不根据GT BBox的scale将GT BBox分配到某个pyramid level。而是不同scale的anchor已对应到某个pyramid level、GT会根据IoU和anchor对应
-
multi RPN:如果每个level上使用不同的RPN,准确度也是类似的,这说明pyramid的各个level共享相似的semantic level,这种优势类似于featurized image pyramid的优势(1个common head classifier可以应用于从任意image scale计算得到的feature map)
FPN for Fast RCNN
可以把FPN输出的feature pyramid当做是1个image pyramid生成的,因此可以使用SPPNet和Fast RCNN应用于image pyramid时的分配策略,将不同scale的RoI分配到对应pyramid level的特征图上
1个size(在input image上的size)为(w,h)的RoI应该被分配到feature pyramid上的level P_k:
![]()
其中224为ImageNet的预训练size,k_0是1个224×224的RoI应该被映射到的target pyramid level。
ResNet原文中的Faster RCNN使用C_4作为RPN的输入,所以本文将k_0设为4。
假如RoI的scale小于224×224(比如112×112,正好是224的一半),则它会被映射到finer-resolution level(比如3)。注:fine-resolution指像素数多,coarse-resolution指像素少。
ResNet中使用conv5作为conv4输出的feature map顶部的head,但本文已经将conv5用于构建FPN。因此本文使用RoI pooling生成7×7的feature,然后用2个1024维的FC层+ReLU,然后再输入到最终的classification layer和BBox regression layer。相比于standard conv5 head,我们的方法参数更少、速度更快
FPN for Segmentation Proposals
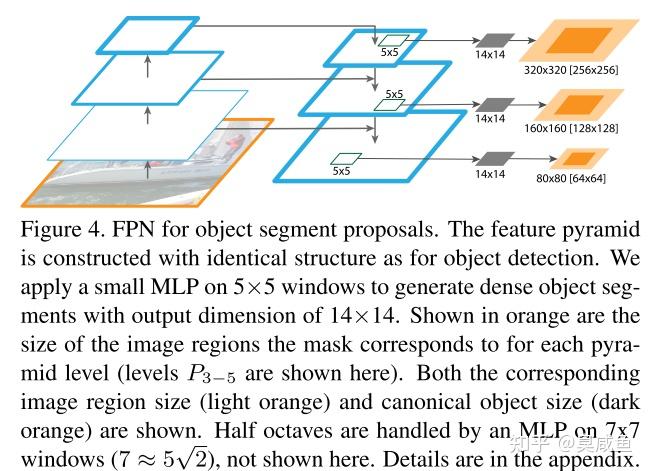
Experiments on RPN
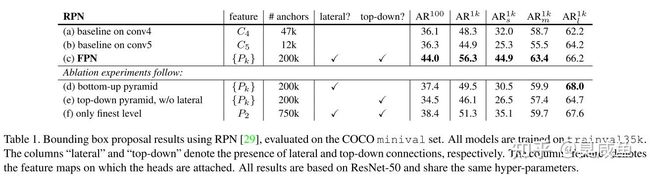
- Implementation details:详见原文
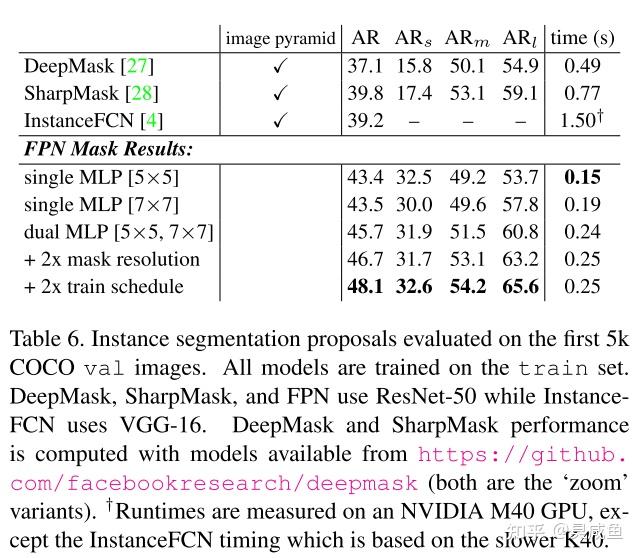
- Comparisons with baselines:表1(a), (b)
- How important is top-down enrichment?:表1(d)
- How important are lateral connections?:表1(e)
- How important are pyramid representations?:表1(f)
Experiments on Fast RCNN

Experiments on Faster RCNN

Comparing with COCO Competition Winners

Experiments on Segmentation Proposal
各种FPN:PANet、ASFF、NAS-FPN、BiFPN、Recursive-FPN…
早期的物体检测算法,无论是一步式的,还是两步式的,通常都是在Backbone的最后一个stage(特征图分辨率相同的所有卷积层归类为一个stage)最后一层的特征图,直接外接检测头做物体检测。此种物体检测算法,可以称之为单stage物体检测算法。
由于单stage物体检测算法中,Backbone的最后一个stage的stride通常是32,导致输出的特征图分辨率是输入图片分辨率的1/32,太小,不利于物体检测,因此单stage的物体检测算法,一般会将最后一个stage的MaxPooling去掉或者将stride为2的conv改为stride为1的conv,以增大最后一个分辨率。
后来研究发现,单stage物体检测算法中,无法用单一stage的特征图同时有效的表征各个尺度的物体,因此,后来物体检测算法,就逐渐发展为利用不同stage的特征图,形成特征金字塔网络(feature parymid network),表征不同scale的物体,然后再基于特征金字塔做物体检测,也就是进入了FPN时代。
物体检测各个阶段
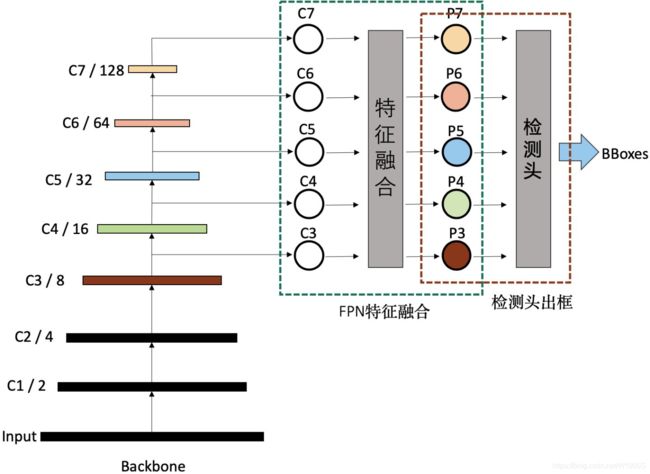
如上图,我们常见的物体检测算法,其实可以分解为三个递进的阶段:
1)Backbone生成特征阶段
计算机视觉任务一般都是基于常用预训练的Backbone,生成抽象的语义特征,再进行特定任务微调。物体检测也是如此。
Backbone生成的特征,一般按stage划分,分别记作C1、C2、C3、C4、C5、C6、C7等,其中的数字与stage的编号相同,代表的是分辨率减半的次数,如C2代表stage2输出的特征图,分辨率为输入图片的1/4,C5代表,stage5输出的特征图,分辨率为输入图片的1/32。
2)特征融合阶段
这个是FPN特有的阶段,FPN一般将上一步生成的不同分辨率特征作为输入,输出经过融合后的特征。输出的特征一般以P作为编号标记。如FPN的输入是,C2、C3、C4、C5、C6,经过融合后,输出为P2、P3、P4、P5、P6。
3)检测头输出bounding box
FPN输出融合后的特征后,就可以输入到检测头做具体的物体检测。
FPN的演进
物体检测性能提升,一般主要通过数据增强、改进Backbone、改进FPN、改进检测头、改进loss、改进后处理等6个常用手段。
其中FPN自从被提出来,先后迭代了不少版本。大致迭代路径如下图:

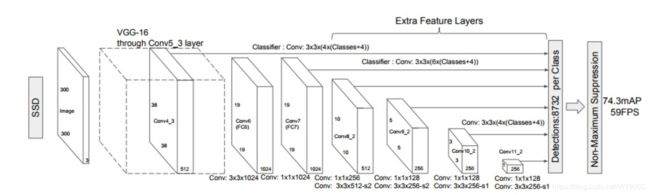
1)无融合
无融合,又利用多尺度特征的典型代表就是2016年的鼎鼎有名的SSD,它直接利用不同stage的特征图分别负责不同scale大小物体的检测。
2)自上而下单向融合
自上而下单向融合的FPN,事实上仍然是当前物体检测模型的主流融合模式。如我们常见的Faster RCNN、Mask RCNN、Yolov3、RetinaNet、Cascade RCNN等,具体各个FPN的内部细节如下图。
a)Faster/Master/Cascade RCNN中的FPN
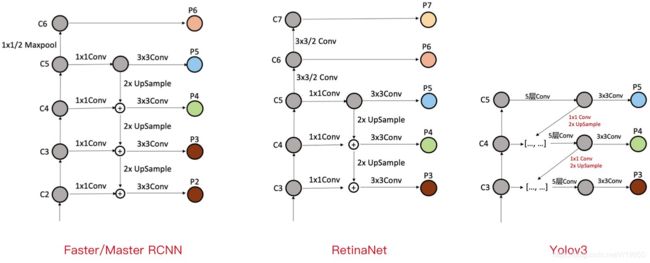
Faster/Master/Cascade RCNN中的FPN,利用了C2-C6五个stage的特征,其中C6是从C5直接施加1x1/2的MaxPooling操作得到。FPN融合后得到P2-P6,其中P6直接等于C6,P5是先经过1x1Conv,再经过3x3Conv得到,P2-P4均是先经过1x1Conv,再融合上一层2xUpsample的特征,再经过3x3Conv得到。具体过程可以看上图。
b)RetinaNet中的FPN
RetinaNet中的FPN,利用了C3-C7五个stage的特征,其中C6是从C5直接施加3x3/2的Conv操作得到,C7是从C6直接施加3x3/2的Conv操作得到。FPN融合后得到P3-P7,其中P6、P7直接等于C6、C7,P5是先经过1x1Conv,再经过3x3Conv得到,P3-P4均是先经过1x1Conv,再融合上一层2xUpsample的特征,再经过3x3Conv得到。具体过程可以看上图。
可以看出,RetinaNet基本与Faster/Master/Cascade RCNN中的FPN一脉相承。只是利用的stage的特征略有差别,Faster/Master/Cascade RCNN利用了高分辨率低语义的C2,RetinaNet利用了更低分辨率更高语义的C7。其他都是细微的差别。
c)Yolov3中的FPN
Yolov3中的FPN与上述两个有比较大的区别。首先,Yolov3中的FPN只利用到了C3-C5三个stage的特征;其次,从C5征到P5特征,会先经过5层Conv,然后再经过一层3x3Conv;最后,C3-C4到P3-P4特征,上一层特征会先经过1x1Conv+2xUpsample,然后先与本层特征concatenate,再经过5层Conv,之后经过一层3x3Conv。看图最清楚。
可以看图仔细对比Yolov3与Faster/Master/Cascade RCNN以及RetinaNet细节上的区别。
3)简单双向融合
FPN自从提出来以后,均是只有从上向下的融合,PANet是第一个提出从下向上二次融合的模型,并且PANet就是在Faster/Master/Cascade RCNN中的FPN的基础上,简单增了从下而上的融合路径。看下图。

4)复杂的双向融合
PANet的提出证明了双向融合的有效性,而PANet的双向融合较为简单,因此不少文章在FPN的方向上更进一步,尝试了更复杂的双向融合,如ASFF、NAS-FPN和BiFPN。
ASFF
ASFF(论文:Learning Spatial Fusion for Single-Shot Object Detection)作者在YOLOV3的FPN的基础上,研究了每一个stage再次融合三个stage特征的效果。如下图。其中不同stage特征的融合,采用了注意力机制,这样就可以控制其他stage对本stage特征的贡献度。

NAS-FPN和BiFPN
NAS-FPN(基于搜索结构的FPN )和BiFPN,都是google出品,思路也一脉相承,都是在FPN中寻找一个有效的block,然后重复叠加,这样就可以弹性的控制FPN的大小。
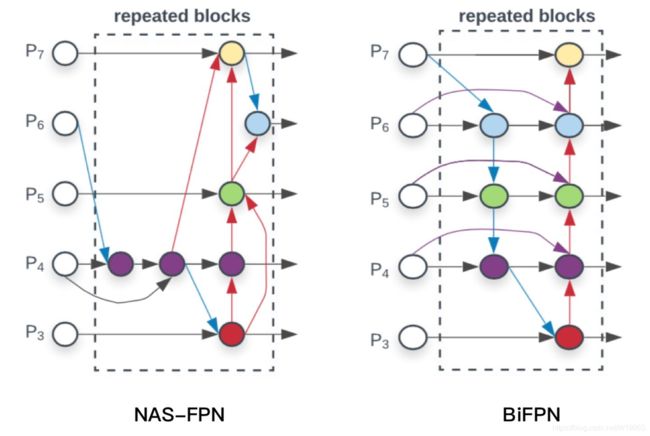
其中BiFPN的具体细节如下图。

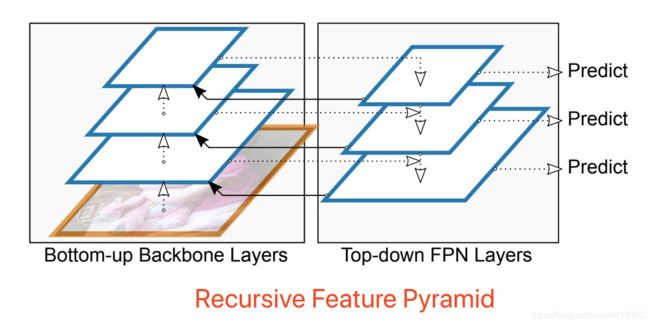
Recursive-FPN
递归FPN是此文写作之时前两周刚刚新出炉的(原论文是DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution),效果之好令人惊讶,使用递归FPN的DetectoRS是目前物体检测(COCO mAP 54.7)、实体分割和全景分割的SOTA,太强悍了。
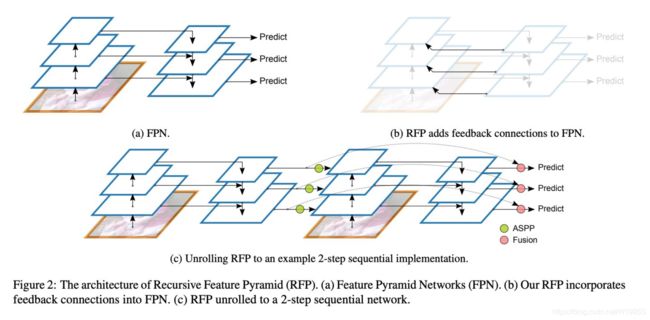
递归FPN理解起来很容易,就是将传统FPN的融合后的输出,再输入给Backbone,进行二次循环,如下图。
下图给出了FPN与Recursive-FPN的区别,并且把一个2层的递归FPN展开了,非常简单明了,不做过多介绍。
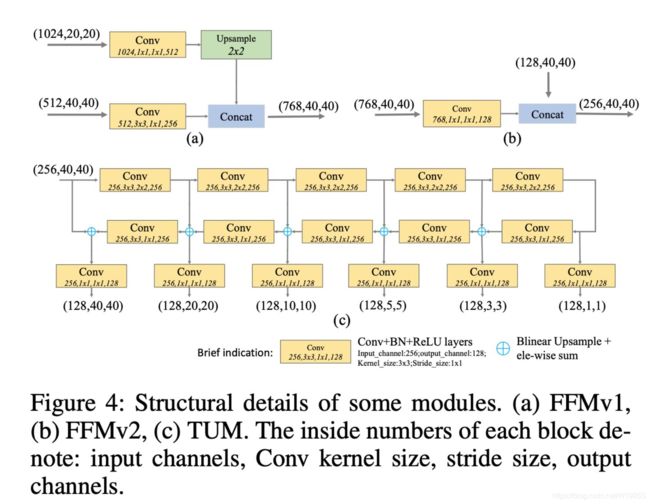
5)M2det中的SFAM
M2det中的SFAM,比较复杂,它是先把C3与C5两个stage的特征融合成一个与C3分辨率相同的特征图(下图中的FFM1模块),然后再在此特征图上叠加多个UNet(下图中的TUM模块),最后将每个UNet生成的多个分辨率中相同分辨率特征一起融合(下图中的SFAM模块),从而生成最终的P3、P4、P5、P6特征,以供检测头使用。具体如下图。

每一个模块的详细细节如下图。
FPT(Transformer)
源论文:FPT
源代码:FPT源码pytorch
其次还有很多FPN变体,可谓数不胜数。。。Fully-FPN,Simple-PAN,Libra R-CNN等等等等
思考
FPN的优化会显著带来物体检测的性能提升,当前最好的FPN是递归FPN,期待将来更有效的FPN出现。
最近Facebook出了一篇文章object detection by transformer,如果transformer与各种强大的FPN结合,效果如何还是值得期待。
改进AugFPN
代码:https://github.com/Gus-Guo/AugFPN
论文:https://arxiv.org/abs/1912.05384
摘要:
- 现有的SOTA检测器都使用了构建特征金字塔(不同尺度的特征组合),来提升对不同尺度(大小)的目标的检测鲁棒性。而FPN是其中的代表性工作
- 本文对FPN进行了分析,找到了其中的一些设计上的缺陷
- 针对缺陷提出了3个改进点,也正是AugFPN的3个组成部分:
- Consistent Supervision:用于降低不同scale之间的语义Gap
- Residual Feature Augmentation:用于在不同尺度的特征融合(fusion, summation)中降低信息损失
- Soft RoI Selection:更好地从图像金字塔中取出ROI Feature用于分类
将FasterRCNN中的FPN结构改成AugFPN,在ResNet50和MobileNet-v2上都有mAP提升
另外,AugFPN中与特征金字塔相关的改进点(也就是Consistent Supervision & Residual Feature Augmentation),在一些Anchor Based/ Anchor Free的One-stage方法中,也能获得提升
原生的FPN中存在的缺陷分析
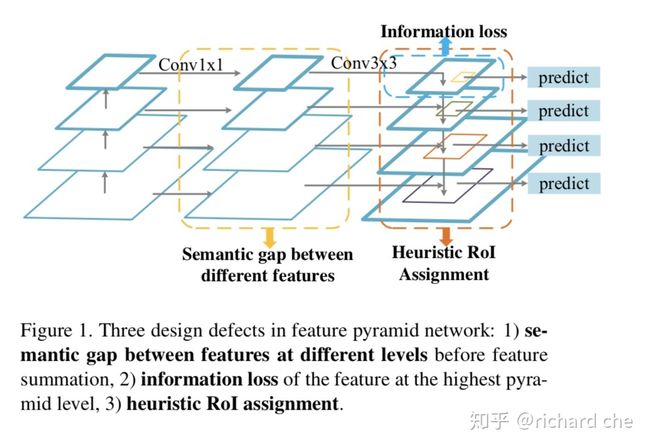
针对FPN中对不同尺度特征的融合&利用,Figure 1对其进行了总结。对于一个Backbone,FPN首先会引出它在不同尺度下的输出,这些输出有这样的特性:
- 底层特征尺度(大小)大,包含的语义信息不够丰富,往往只通过非常有限的卷积核(层),得到一些底层(如边缘,角点)等信息。很多网络的在设计上,为了兼顾算力,底层特征的通常通道数会比较小(因为在这种大小下做卷积的算力会暴增,具体结合卷积的时间复杂度去分析)
- 高层特征尺度小,由于经过了相对比较多的卷积层,会包含比较多的语义信息,而且通道数往往会比较大
相邻两个尺度的特征融合,FPN首先将高层特征通过1x1的卷积进行降维,从而使得它和下面一层特征有同样的通道数(维度/channel数上的适配),然后通过2倍上采样 + 3x3卷积来进行尺度上的适配,最终将维度&尺度上适配后的特征和上一层尺度进行融合(直接相加,因为两个特征的shape已经完全一样
上述的特征融合方式(两个卷积进行适配,直接相加)的问题在于:
- 相邻尺度特征融合过程中的信息损失:在高层 -> 底层适配的过程中,那个1x1的卷积会对丢失信息(这里主要指的是语义(semantic)信息),因为channel数变少了
- 高层特征的损失:在最高层的特征中,因为没有别的特征和它融合,而它又直接经过了一个1x1的卷积进行降维,通道数的减少显然会损失信息。文章指出这种信息可以通过Global Pooling来解决,但是Global Pooling得到的一个一维向量显然丢失了空间信息(e.g. 目标的相对位置没办法通过这样的一维向量表征)
- ROI特征的选择上有问题:FPN认为,融合后的底层信息包含较多与小目标相关的特征,并且尺度大,信息更细腻,对小目标更敏感,因此在底层特征中输出的往往是小目标的ROI特征,反之亦然。但问题是,其他层也包含了对该物体的一些语义信息。本文提到了一个缓解性的方案:PANet通过在每个物体中取出ROI特征,然后通过全链接的方式,从而充分利用每个尺度下的ROI。但这样的问题是:
- 全链接之后接了一个max pooling,同样会丧失一些响应小的网络特征输出,而这些输出也有可能对分类有帮助
- 全连接层的参数量太大了
针对上述3个缺陷的改进
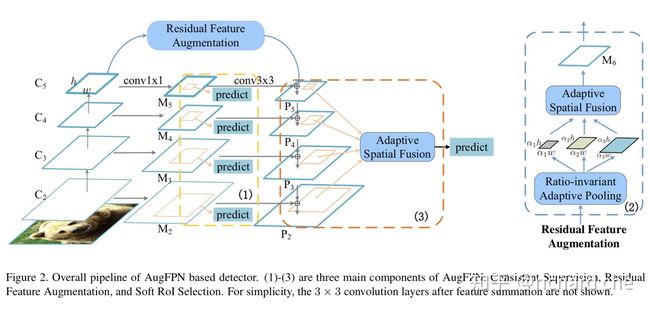
对应地,AugFPN 提出了3个模块来提升性能,分别对应Figure 2的3个部分:
- Consistent Supervision:用于降低不同scale之间的语义Gap
- Residual Feature Augmentation:用于在不同尺度的特征融合(fusion, summation)中降低信息损失
- Soft RoI Selection:更好地从图像金字塔中取出ROI Feature用于分类
Consistent Supervision:
-
- 文章中认为,通过两个卷积进行适配,相邻两个尺度的特征图直接相加的方式,从参数优化的角度来看,会使得最终的特征金字塔陷入次优(简而言之,可以认为融合的过程中缺乏语义信息,网络学不好)
- 因此,一种间接的思路是,直接在每个融合前的特征后面接上检测器&分类器(RPN Head + RCNN),如Figure 2黄色部分。训练时,网络的损失 = lambda * 融合前检测器的Localization Loss + 融合后检测器的Localization Loss + beta * (融合前检测器的Classification Loss + 融合后检测器的Classification Loss) ,实际使用中lambda = 0.25
- 此外,融合前各个尺度的检测器权重是共享的,这样有利于对不同尺度的监督,从而:1)进一步加强各个尺度下的特征联系; 2)反推底层信息能学到更多的语义信息(从高层信息引导过来)
- 在预测时,融合前的共享的这些检测器&分类器都可以去掉
Residual Feature Augmentation
-
- 可以看到在图2中的M5,经过1x1的卷积后channel数减少,显然丢失了信息,并且没有其余的特征与其融合
- 文章中认为,空间上下文信息,能够减少channel数减少带来的语义信息损失,因此可以通过空间信息来补偿,并且提出了Residual Feature Augmentation这一具体举措
-
Residual Feature Augmentation的具体做法:
-
- 将C5降采样成3份。这里的降采样包括2部分:一个是将C5通过adaptive pooling分别降采样成 alpha1, alpha2, alpha3 * C5的宽高;一个是将adaptive pooling后的结果通过1x1的卷积,将每份降采样的Feature Channel变成256,如图3(a)所示。实际使用中,alpha1, alpha2, alpha3分别为0.1, 0.2, 0.3
- adaptive pooling介绍:https://discuss.pytorch.org/t/adaptive-avg-pool2d-vs-avg-pool2d/27011
-
-
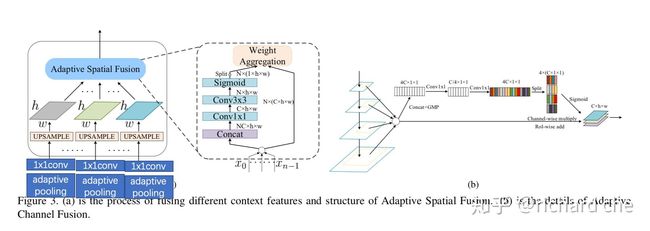
重点在于将采样后的特征如何进行融合,也就是Adaptive Spatial Fusion:
-
- 本文先通过将3个不同尺度的降采样结果统一上采样到C5一样的宽高,保持channel = 256
- 将三者concat,通过conv 1x1 -> conv 3x3的方式进行融合,最终形成3个attention map(因此Sigmoid输入的维度应该是Nx3xhxw,与代码中一致)
- 并将这3个attention map分别应用于3个上采样后的Feature Map
-
Soft ROI Selection
-
-
本文认为对于给定的ROI, 如果是在某层金字塔中取,会
-
对于某个ROI,通过ROI Align取出特征金字塔中所有的ROI Feature(4个尺度会产生4个ROI Feature),默认会在4,8,16,32 4个stride取出4个 7x7x256的ROI feature
-
同样采用ASF的方式:
-
- 将4个ROI Feature Concat起来
- 通过conv 1x1 -> conv 3x3的方式进行融合,形成N个attention map(N=金字塔层数)
- 每个ROI Feature与对应的attention map相乘(加权)
- 将加权后的ROI Feature相加
-
针对One-stage的适配:
-
- 文中指出,这样的理念同样适用于One-stage算法,比如retinanet
- AugFPN中ROIAlign后面的部分,即Soft ROI Selection在训练中没有用上
- Consistent Supervision和Residual Feature Augmentation依然可用
总结
-
-
本文分析出了FPN在特征融合时所暴露的缺陷:核心是融合的过程中产生的各种信息缺失
-
针对信息的缺失提出了一些改进点,主要包含三个方面:
-
- 补偿最顶层由于融合前降维产生的信息损失
- 补偿相邻特征融合后产生的语义信息损失
- 补偿从单层金字塔中取ROI Feature产生的信息损失
-
改进CE-FPN
CEFPN论文链接:https://arxiv.org/abs/2103.10643
CEFPN复现代码:https://github.com/RooKichenn/CEFPN
CEFPN结构
话不多说,先上图:
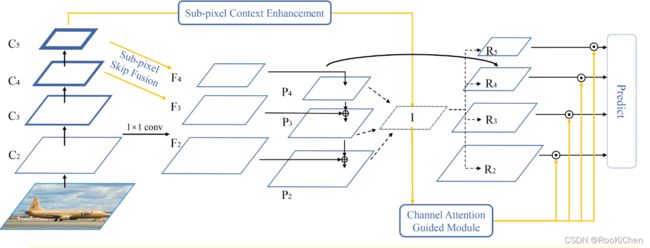
CEFPN中用了不少前辈们的思想,整体框架借鉴了LibraRCNN(https://arxiv.org/abs/1904.02701v1),我认为最大创新就是CEFPN的网络结构,其他模块都是借鉴前辈们的思想,没什么特别大的创新,但是提供了一个改进的思路:去掉F5和P5层,融合P4,P3,P2。下面就具体分析一下CEFPN的结构。
SSF模块
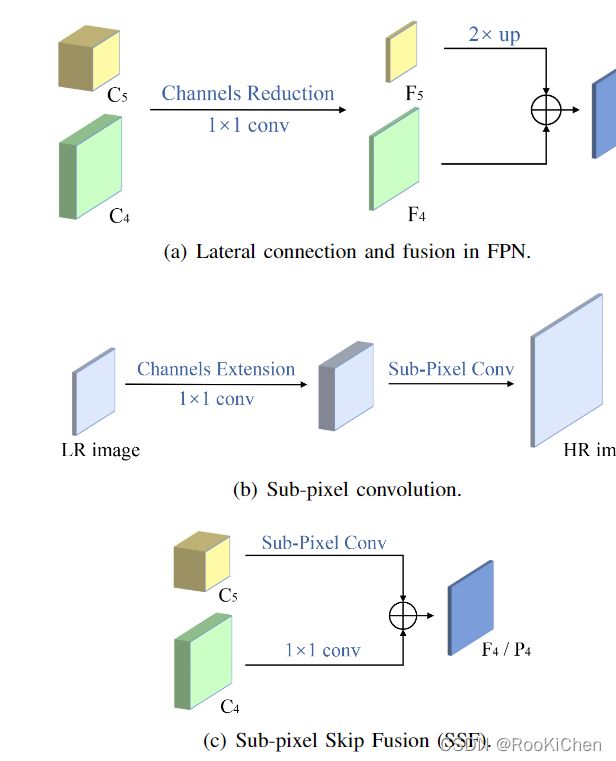
SSF(Sub-pixel Skip Fusion)是借鉴了CVPR2016年一篇关于超分辨率图像论文中提出的亚像素卷积思想,具体是实现细节我在这里就不赘述了,对这篇论文不了解的话可以先去读一下:https://arxiv.org/abs/1609.05158,在CEFPN中,作者采用了残差融合亚像素卷积的方法对C5和C4进行上采样到C4和C3大小,而没有采用传统的线性插值来进行上采样,同时将C4和C3进行1x1的卷积操作,并将这个结果跟亚像素卷积后的进行特征融合,就得到了F4和F3。
SCE模块
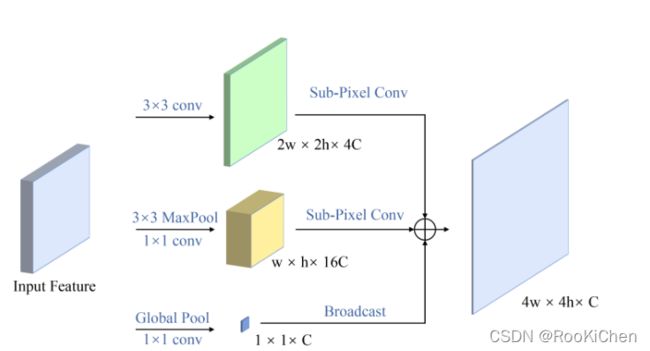
SCE(Sub-pixel Context Enhancement),这个模块的思想也比较简单:将Input Feature分别进行三种处理,最后得到一个通道数为原来的1/8,长宽为原来的2倍的特征图。在论文中,将Input Feature的维度描述为 2h x 2w x 8C,我认为这样描述的原因是第二个分支中,涉及到了长宽减半的操作,也正是在这里,有一个小问题:当Input Feature长宽为 25x25 时,在长宽减半后,长宽为13x13,作者进行了四倍的上采样,得到的特征图为52x52,与第一个分支得到的特征图50x50大小不匹配,而文中作者并没有提到这种情况,所以我在第二个分支输出特征图前又加了一个线性插值的操作,将其缩放到和第一个分支输出的特征图相同大小(如果有复现过的小伙伴可以在评论区说一下你的解决方法,我复现出来的效果并没有作者说的好)。经过SCE模块后得到的特征图和P4,P3,P2进行特征融合,得到特征图I。
CAG模块
CAG

CAM
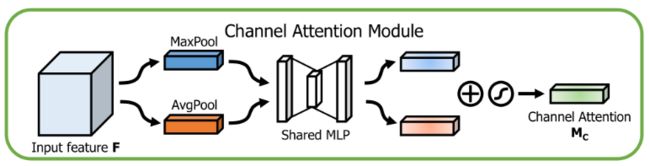
CAG(Channel Attention Guided)模块借鉴了CBAM中通道注意力机制的思想,与CAM不同的是,在CAG中去掉了一个参数共享的全链接层,直接进行了特征融合。
使用线性插值和maxpool得到特征图I
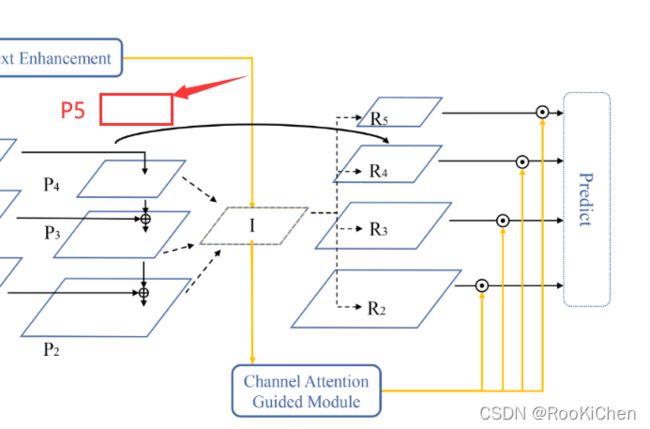
在得到特征图I的这个部分,跟LibraRCNN中FPN特征特征融合是一模一样的,不了解的可以去细看LibraRCNN论文,在这里就简单说一下作者是怎么做的:将经过SCE模块得到的P5,以及P4,P3,P2进行线性插值和maxpool操作,得到特征图I(I的size跟P4是一样的),再除以4(I = I / 4),这里的4代表融合了几个特征层;之后再经过CAG模块得到一个权重α,再通过线性插值和maxpool得到R5, R4, R3, R2,最后将Ri(i=2,3,4,5)乘以权重α,就得到了最后的预测特征图。
训练策略
以ResNet50为例,作者再COCO数据集上训练了12轮,使用了4块16G显存的GPU,每块GPU上2张图片,初始学习率为0.01,并且在第8轮和第11轮下降0.1倍。这里说一下我复现的结果,我只跑了ResNet50,用学校的服务器,四块40G的A100,跟作者参数设置相同,但是map比作者低了接近两个百分点。
复现代码
代码已同步到GitHub,欢迎star:https://github.com/RooKichenn/CEFPN
块得到的P5,以及P4,P3,P2进行线性插值和maxpool操作,得到特征图I(I的size跟P4是一样的),再除以4(I = I / 4),这里的4代表融合了几个特征层;之后再经过CAG模块得到一个权重α,再通过线性插值和maxpool得到R5, R4, R3, R2,最后将Ri(i=2,3,4,5)乘以权重α,就得到了最后的预测特征图。
训练策略
以ResNet50为例,作者再COCO数据集上训练了12轮,使用了4块16G显存的GPU,每块GPU上2张图片,初始学习率为0.01,并且在第8轮和第11轮下降0.1倍。这里说一下我复现的结果,我只跑了ResNet50,用学校的服务器,四块40G的A100,跟作者参数设置相同,但是map比作者低了接近两个百分点。
复现代码
代码已同步到GitHub,欢迎star:https://github.com/RooKichenn/CEFPN