LINUX网络基础
网络排查工具
常用的 ping,tracert,nslookup 一般用来判断主机的网络连通性,其实 Linux 下有一个更好用的网络联通性判断工具,它可以结合ping nslookup tracert 来判断网络的相关特性,这个命令就是 mtr。mtr 全称 my traceroute,是一个把 ping 和 traceroute 合并到一个程序的网络诊断工具。
traceroute默认使用UDP数据包探测,而mtr默认使用ICMP报文探测,ICMP在某些路由节点的优先级要比其他数据包低,所以测试得到的数据可能低于实际情况。
window版本下载
Linux可以直接运行命令进行安装。
[root@network ~]#yum install mtr -y
使用
[root@network ~]#mtr -h
usage: mtr [-BfhvrwctglxspQomniuT46] [--help] [--version] [--report]
[--report-wide] [--report-cycles=COUNT] [--curses] [--gtk]
[--csv|-C] [--raw] [--xml] [--split] [--mpls] [--no-dns] [--show-ips]
[--address interface] [--filename=FILE|-F]
[--ipinfo=item_no|-y item_no]
[--aslookup|-z]
[--psize=bytes/-s bytes] [--order fields]
[--report-wide|-w] [--inet] [--inet6] [--max-ttl=NUM] [--first-ttl=NUM]
[--bitpattern=NUM] [--tos=NUM] [--udp] [--tcp] [--port=PORT] [--timeout=SECONDS]
[--interval=SECONDS] HOSTNAME
mtr常用的几个参数:
-v:查看当前版本号;
-r:–report 以报告模式显示,不加-r会动态的显示;
-c:设置每秒发送数据包的数量,默认值是10;
-s: --packetsize 指定ping数据包的大小;如果设置为负数,则每一次发送的数据包的大小都会是一个随机数。
-n:相当于–no-dns 不解析dns;使用 -n 选项来让 mtr 只输出 IP,而不对主机 host name 进行解释
-a 或 -address:设置发送数据包的IP地址。用于主机有多个IP时。
[root@network ~]#mtr -v
mtr 0.85
对通用的dns服务器114.114.114.114发送15个包,不做dns解析,并以报告的形式显示,测试数据如下:
[root@network ~]#mtr -r -n -c 15 114.114.114.114
Start: Fri Aug 7 10:49:29 2020
HOST: network Loss% Snt Last Avg Best Wrst StDev
1.|-- 9.124.63.130 0.0% 15 0.6 0.6 0.5 0.7 0.0
2.|-- 9.124.123.12 0.0% 15 0.6 0.7 0.6 1.5 0.0
3.|-- 10.196.86.221 40.0% 15 5.2 2.9 2.0 5.6 1.2
4.|-- 10.196.91.33 0.0% 15 1.9 1.8 1.7 1.9 0.0
5.|-- 58.213.96.217 0.0% 15 2.4 2.6 2.1 4.1 0.5
6.|-- 58.213.94.105 0.0% 15 2.6 2.8 2.6 4.4 0.3
7.|-- 222.190.59.154 0.0% 15 8.1 6.5 2.8 9.8 2.6
8.|-- 58.217.249.94 0.0% 15 4.2 4.5 4.0 8.5 1.1
9.|-- 114.114.114.114 0.0% 15 5.2 5.2 5.1 5.4 0.0
查看本机到 qq.com 的路由以及连接情况直接运行如下命令:
[root@network ~]#mtr qq.com
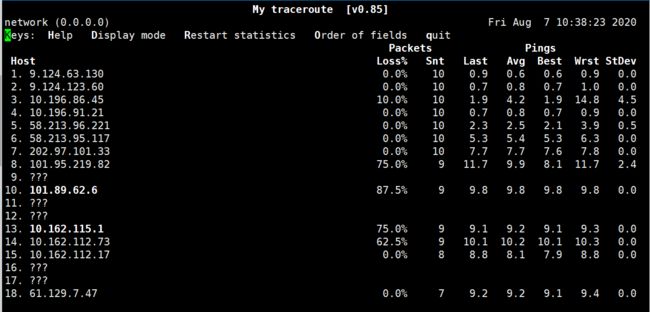
检测一下到自己的博客地址:www.likai.tech
[root@network ~]#mtr www.likai.tech

mtr测试结果的查看
第一列:host显示的是IP地址和本机域名,这点和tracert很像;
第二列:loss%就是对应IP行的丢包率了,需要注意的是有些丢包是由于icmp的保护机制造成的,并不 代表真的丢包;
第三列:snt每秒发送数据包的数量,默认值是10,窝这里通过参数 -c来指定发送15个包;
第四列:Last显示的最近一次的返回时延;
第五列:Avg是平均值 这个应该是发送ping包的平均时延;
第六列:Best是最好或者说时延最短的;
第七列:Wrst是最差或者说时延最常的;
第八列:StDev是标准偏差,统计学名词,一种量度数据分布的分散程度标准,用以衡量数据值偏离算术平均值的程度。标准偏差越小,这些值偏离平均值就越少。
MTR结果分析
当我们分析 MTR 报告时候,最好找出每一跳的任何问题。除了可以查看两个服务器之间的路径之外,MTR 在它的七列数据中提供了很多有价值的数据统计报告。
Loss% 列展示了数据包在每一跳的丢失率。Snt 列记录的多少个数据包被送出。
使用 –report 参数默认会送出10个数据包。如果使用 –report-cycles=[number-of-packets] 选项,MTR 就会按照 [number-of-packets] 指定的数量发出 ICMP 数据包。
Last, Avg, Best 和 Wrst 列都标识数据包往返的时间,使用的是毫秒( ms )单位表示。Last 表示最后一个数据包所用的时间, Avg 表示评价时间, Best 和 Wrst 表示最小和最大时间。在大多数情况下,平均时间( Avg)列需要我们特别注意。
最后一列 StDev 提供了数据包在每个主机的标准偏差。如果标准偏差越高,说明数据包在这个节点的延时越不相同。标准偏差会让您了解到平均延时是否是真的延时时间的中心点,或者测量数据受到某些问题的干扰。
例如,如果标准偏差很大,说明数据包的延迟是不确定的。一些数据包延迟很小(例如:25ms),另一些数据包延迟很大(例如:350ms)。当10个数据包全部发出后,得到的平均延迟可能是正常的,但是平均延迟是不能很好的反应实际情况的。如果标准偏差很高,使用最好和最坏的延迟来确定平均延迟是一个较好的方案。
在大多数情况下,您可以把 MTR 的输出分成三大块。根据配置,第二或第三跳一般都是您的本地 ISP,倒数第二或第三跳一般为您目的主机的ISP。中间的节点是数据包经过的路由器。
网络丢包
如果在任何一跳上看到 loss 的百分比,这就说明这一跳上可能有问题了。当然,很多服务提供商人为限制 ICMP 发送的速率,这也会导致此问题。那么如何才能指定是人为的限制 ICMP 传输 还是确定有丢包的现象?此时需要查看下一跳。如果下一跳没有丢包现象,说明上一条是人为限制的。如下示例:

猜测到100%的丢包率除了网络糟糕的原因之前还有人为限制 ICMP。当我们看到不同的丢包率时,通常要以最后几跳为准。
还有很多时候问题是在数据包返回途中发生的。数据包可以成功的到达目的主机,但是返回过程中遇到“困难”了。所以,当问题发生后,我们通常需要收集反方向的 MTR 报告。
此外,互联网设施的维护或短暂的网络拥挤可能会带来短暂的丢包率,当出现短暂的10%丢包率时候,不必担心,应用层的程序会弥补这点损失。
网络延迟
除了可以通过MTR报告查看丢包率,我们也还可以看到本地到目的之间的时延。因为是不通的位置,延迟通常会随着条数的增加而增加。所以,延迟通常取决于节点之间的物理距离和线路质量。

从上面的MTR报告截图中,我们可以看到从第9跳的延迟猛增,一般有可能是9跳属于不通地域,物理距离导致时延猛增,也有可能是第9条的路由器配置不当,或者是线路拥塞。需要具体问题进行具体的分析。
然而,高延迟并不一定意味着当前路由器有问题。延迟很大的原因也有可能是在返回过程中引发的。从这份报告的截图看不到返回的路径,返回的路径可能是完全不同的线路,所以一般需要进行双向MTR测试。
注:ICMP 速率限制也可能会增加延迟,但是一般可以查看最后一条的时间延迟来判断是否是上述情况。
网络命令相关执行
查看当前系统的连接
如何看当前系统有多少连接呢?可以使用netstat结合awk进行统计。如下脚本,统计了每一种状态的tcp连接数量,其中NR>2 过滤前面前导信息的前2行。
[root@network ~]#netstat -antp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN 18108/php-fpm: mast
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 2448/nginx: worker
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1121/sshd
tcp 0 0 10.206.0.10:41086 169.254.0.55:5574 ESTABLISHED 14418/YDService
tcp 0 36 10.206.0.10:22 221.217.94.106:63459 ESTABLISHED 24282/sshd: root@pt
[root@network ~]#netstat -antp |awk 'NR>2 {count[$6]++}END{for(state in count)print state,count[state]}'
LISTEN 3
ESTABLISHED 2
[root@network ~]#
但如果你在一台有上万连接的服务器上执行这个命令,你可能会等上很长时间。所以,我们有了第二代网络状态统计工具:netstat => ss。
ss命令
[root@network ~]#ss -h
Usage: ss [ OPTIONS ]
ss [ OPTIONS ] [ FILTER ]
-h, --help this message
-V, --version output version information
-n, --numeric don't resolve service names
-r, --resolve resolve host names
-a, --all display all sockets
-l, --listening display listening sockets
-o, --options show timer information
-e, --extended show detailed socket information
-m, --memory show socket memory usage
-p, --processes show process using socket
-i, --info show internal TCP information
-s, --summary show socket usage summary
-b, --bpf show bpf filter socket information
-E, --events continually display sockets as they are destroyed
-Z, --context display process SELinux security contexts
-z, --contexts display process and socket SELinux security contexts
-N, --net switch to the specified network namespace name
-4, --ipv4 display only IP version 4 sockets
-6, --ipv6 display only IP version 6 sockets
-0, --packet display PACKET sockets
-t, --tcp display only TCP sockets
-S, --sctp display only SCTP sockets
-u, --udp display only UDP sockets
-d, --dccp display only DCCP sockets
-w, --raw display only RAW sockets
-x, --unix display only Unix domain sockets
--vsock display only vsock sockets
-f, --family=FAMILY display sockets of type FAMILY
FAMILY := {inet|inet6|link|unix|netlink|vsock|help}
查看系统正在监听的tcp连接
可以看出PORT端的服务名称
[root@network ~]#ss -atr
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 VM_0_10_centos:cslistener *:*
LISTEN 0 128 *:rpc.portmapper *:*
LISTEN 0 128 *:http *:*
SYN-RECV 0 0 network:http 197.232.1.182:42981
LISTEN 0 128 *:ssh *:*
ESTAB 0 0 network:41086 169.254.0.55:lsi-bobcat
ESTAB 0 36 network:ssh 221.217.94.106:63459
LISTEN 0 128 [::]:rpc.portmapper [::]:*
[root@network ~]#ss -atn
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 127.0.0.1:9000 *:*
LISTEN 0 128 *:80 *:*
LISTEN 0 128 *:22 *:*
ESTAB 0 0 10.206.0.10:41086 169.254.0.55:5574
ESTAB 0 36 10.206.0.10:22 221.217.94.106:63459
查看系统中所有连接
[root@network ~]#ss -alt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 127.0.0.1:cslistener *:*
LISTEN 0 128 *:sunrpc *:*
LISTEN 0 128 *:http *:*
LISTEN 0 128 *:ssh *:*
LISTEN 0 128 [::]:sunrpc [::]:*
[root@network ~]#ss -altn
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 127.0.0.1:9000 *:*
LISTEN 0 128 *:111 *:*
LISTEN 0 128 *:80 *:*
LISTEN 0 128 *:22 *:*
LISTEN 0 128 [::]:111 [::]:*
查看监听80端口的进程 pid
[root@network ~]#ss -ntlp|grep 80
LISTEN 0 128 *:80 *:* users:(("nginx",pid=12549,fd=6),("nginx",pid=2448,fd=6))
查看进程rpcbind服务占用了哪些端口
[root@network ~]#ss -nltp|grep rpcbind
LISTEN 0 128 *:111 *:* users:(("rpcbind",pid=619,fd=8))
LISTEN 0 128 [::]:111 [::]:* users:(("rpcbind",pid=619,fd=11))
显示所有 UDP 连接
[root@network ~]#ss -ua
State Recv-Q Send-Q Local Address:Port Peer Address:Port
UNCONN 0 0 *:794 *:*
UNCONN 0 0 *:bootpc *:*
UNCONN 0 0 *:sunrpc *:*
UNCONN 0 0 10.206.0.10:ntp *:*
UNCONN 0 0 127.0.0.1:ntp *:*
UNCONN 0 0 [::]:794 [::]:*
UNCONN 0 0 [::]:sunrpc [::]:*
UNCONN 0 0 [fe80::5054:ff:fe38:5e00]%eth0:ntp [::]:*
UNCONN 0 0 [::1]:ntp [::]:*
-
查看TCP sockets,使用-ta选项
-
查看UDP sockets,使用-ua选项
-
查看RAW sockets,使用-wa选项
-
查看UNIX sockets,使用-xa选项
和某个 IP 的所有连接
# ss dst 10.252.68.154
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
tcp ESTAB 0 0 10.252.68.154:50373 10.252.68.154:tmi
tcp ESTAB 0 0 10.252.68.154:tmi 10.252.68.154:50373
# ss dst 10.252.68.154:tmi
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
tcp ESTAB 0 0 10.252.68.154:50373 10.252.68.154:tmi
查看连接本机最多的前2个 IP 地址
# netstat -antp|awk '{print $4}'|cut -d ":" -f1|sort |uniq -c|sort -nr -k1|head -n2
76 10.252.68.154
10 0.0.0.0
Recv-Q 和 Send-Q
这两个值,在LISTEN和ESTAB状态分别代表不同意义。一般,正常的应用程序这两个值都应该为0(backlog除外)。数值越大,说明问题越严重。
- LISTEN 状态
Recv-Q:代表建立的连接还有多少没有被accept,比如Nginx接受新连接变的很慢
Send-Q:代表listen backlog值
- ESTAB 状态
Recv-Q:内核中的数据还有多少(bytes)没有被应用程序读取,发生了一定程度的阻塞
Send-Q:代表内核中发送队列里还有多少(bytes)数据没有收到ack,对端的接收处理能力不强
查看网络流量
dstat linux查看流量
dstat命令是一个用来替换vmstat、iostat、netstat、nfsstat和ifstat这些命令的工具,是一个全能系统信息统计工具。与sysstat相比,dstat拥有一个彩色的界面,在手动观察性能状况时,数据比较显眼容易观察;而且dstat支持即时刷新,譬如输入dstat 3即每三秒收集一次,但最新的数据都会每秒刷新显示。和sysstat相同的是,dstat也可以收集指定的性能资源,譬如dstat -c即显示CPU的使用情况。
[root@network ~]#yum install dstat -y
使用说明
安装完后就可以使用了,dstat非常强大,可以实时的监控cpu、磁盘、网络、IO、内存等使用情况。
直接使用dstat,默认使用的是**-cdngy**参数,分别显示cpu、disk、net、page、system信息,默认是1s显示一条信息。可以在最后指定显示一条信息的时间间隔,如dstat 5是没5s显示一条,dstat 5 10表示没5s显示一条,一共显示10条。
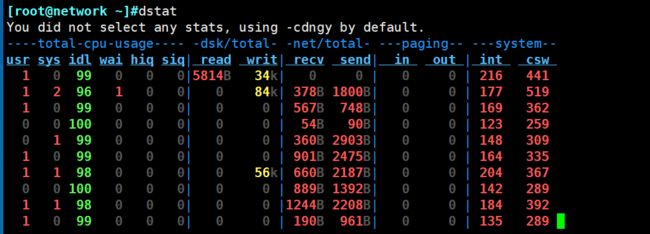
下面对显示出来的部分信息作一些说明:
这是默认输出显示的信息(-cdngy参数):
CPU状态:CPU的使用率。这项报告更有趣的部分是显示了用户,系统和空闲部分,这更好地分析了CPU当前的使用状况。如果你看到"wait"一栏中,CPU的状态是一个高使用率值,那说明系统存在一些其它问题。当CPU的状态处在"waits"时,那是因为它正在等待I/O设备(例如内存,磁盘或者网络)的响应而且还没有收到。
磁盘统计:磁盘的读写操作,这一栏显示磁盘的读、写总数。
网络统计:网络设备发送和接受的数据,这一栏显示的网络收、发数据总数。
分页统计:系统的分页活动。分页指的是一种内存管理技术用于查找系统场景,一个较大的分页表明系统正在使用大量的交换空间,或者说内存非常分散,大多数情况下你都希望看到page in(换入)和page out(换出)的值是0 0。
系统统计:这一项显示的是中断(int)和上下文切换(csw)。这项统计仅在有比较基线时才有意义。这一栏中较高的统计值通常表示大量的进程造成拥塞,需要对CPU进行关注。你的服务器一般情况下都会运行运行一些程序,所以这项总是显示一些数值。
语法以及常用选项
语法
Usage: dstat [-afv] [options..] [delay [count]]
常用选项
-c:显示CPU系统占用,用户占用,空闲,等待,中断,软件中断等信息。
-C:当有多个CPU时候,此参数可按需分别显示cpu状态,例:-C 0,1 是显示cpu0和cpu1的信息。
-d:显示磁盘读写数据大小。
-D hda,total:include hda and total。
-n:显示网络状态。
-N eth1,total:有多块网卡时,指定要显示的网卡。
-l:显示系统负载情况。
-m:显示内存使用情况。
-g:显示页面使用情况。
-p:显示进程状态。
-s:显示交换分区使用情况。
-S:类似D/N。
-r:I/O请求情况。
-y:系统状态。
--ipc:显示ipc消息队列,信号等信息。
--socket:用来显示tcp udp端口状态。
-a:此为默认选项,等同于-cdngy。
-v:等同于 -pmgdsc -D total。
--output 文件:此选项也比较有用,可以把状态信息以csv的格式重定向到指定的文件中,以便日后查看。例:dstat --output /root/dstat.csv & 此时让程序默默的在后台运行并把结果输出到/root/dstat.csv文件中。
实例
- 如想监控swap,process,sockets,filesystem并显示监控的时间:
- -tsp t:显示时间 -s:显示交换分区 -p:显示进程
[root@network ~]#dstat -tsp --socket --fs
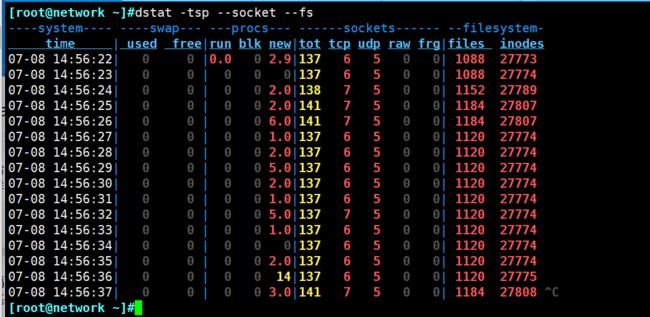
- 若要将结果输出到文件可以加–output filename:
[root@network ~]#dstat -tsp --socket --fs --output /tmp/dstat.csv

这样生成的csv文件可以用excel打开,然后生成图表。
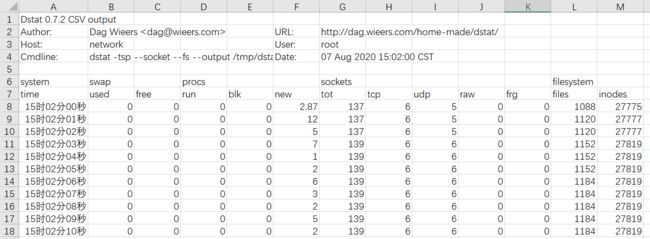
参数查看
通过dstat --list可以查看dstat能使用的所有参数,其中上面internal是dstat本身自带的一些监控参数,下面/usr/share/dstat中是dstat的插件,这些插件可以扩展dstat的功能,如可以监控电源(battery)、mysql等。
下面这些插件并不是都可以直接使用的,有的还依赖其他包,如想监控mysql,必须要装python连接mysql的一些包。
[root@network ~]#dstat --list
internal:
aio, cpu, cpu24, disk, disk24, disk24old, epoch, fs, int, int24, io, ipc, load, lock, mem,
net, page, page24, proc, raw, socket, swap, swapold, sys, tcp, time, udp, unix, vm
/usr/share/dstat:
battery, battery-remain, cpufreq, dbus, disk-tps, disk-util, dstat, dstat-cpu, dstat-ctxt,
dstat-mem, fan, freespace, gpfs, gpfs-ops, helloworld, innodb-buffer, innodb-io, innodb-ops,
lustre, memcache-hits, mysql-io, mysql-keys, mysql5-cmds, mysql5-conn, mysql5-io,
mysql5-keys, net-packets, nfs3, nfs3-ops, nfsd3, nfsd3-ops, ntp, postfix, power, proc-count,
qmail, rpc, rpcd, sendmail, snooze, squid, test, thermal, top-bio, top-bio-adv,
top-childwait, top-cpu, top-cpu-adv, top-cputime, top-cputime-avg, top-int, top-io,
top-io-adv, top-latency, top-latency-avg, top-mem, top-oom, utmp, vm-memctl, vmk-hba,
vmk-int, vmk-nic, vz-cpu, vz-io, vz-ubc, wifi
sar命令
安装命令
[root@network ~]#yum install sysstat -y
网络流量
使用sar -n DEV 2即可每2秒刷新一次网络流量
[root@network ~]#sar -n DEV 2
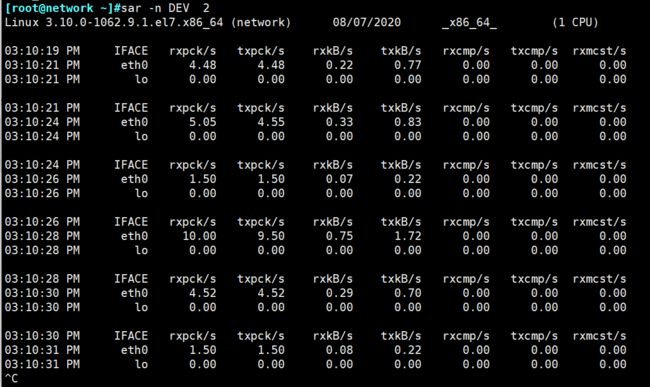
-n参数很有用,他有6个不同的开关:DEV | EDEV | NFS | NFSD | SOCK | ALL 。
DEV显示网络接口信息
EDEV显示关于网络错误的统计数据
NFS统计活动的NFS客户端的信息
NFSD统计NFS服务器的信息,SOCK显示套 接字信息
ALL显示所有5个开关。它们可以单独或者一起使用。
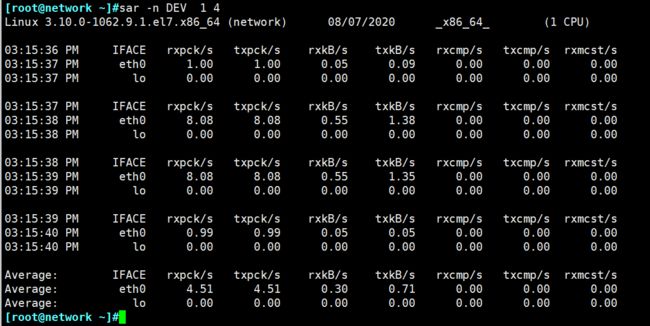
例如:sar -n DEV 1 4 #命令后面 1 4 意思是:每一秒钟取一次值,取四次,如果想长时间监控可以把值设置大些。
参数说明:
IFACE:LAN接口
rxpck/s:每秒钟接收的数据包
txpck/s:每秒钟发送的数据包
rxbyt/s:每秒钟接收的字节数
txbyt/s:每秒钟发送的字节数
rxcmp/s:每秒钟接收的压缩数据包
txcmp/s:每秒钟发送的压缩数据包
rxmcst/s:每秒钟接收的多播数据包
CPU利用率
查看全天CPU利用率
[root@network ~]#sar -p
Linux 3.10.0-1062.9.1.el7.x86_64 (network) 08/07/2020 _x86_64_ (1 CPU)
03:10:01 PM CPU %user %nice %system %iowait %steal %idle
03:20:01 PM all 0.41 0.00 0.36 0.09 0.00 99.13
Average: all 0.41 0.00 0.36 0.09 0.00 99.13
# sar -u 1 10 (1:每隔一秒,10:写入10次)

内存利用率
查看全天内存利用率
[root@network ~]#sar -r
Linux 3.10.0-1062.9.1.el7.x86_64 (network) 08/07/2020 _x86_64_ (1 CPU)
03:10:01 PM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
03:20:01 PM 173152 1708904 90.80 154320 1257040 579040 30.77 858184 662052 672
Average: 173152 1708904 90.80 154320 1257040 579040 30.77 858184 662052 672
# sar -r 1 10 (1:每隔一秒,10:写入10次)


磁盘I/O
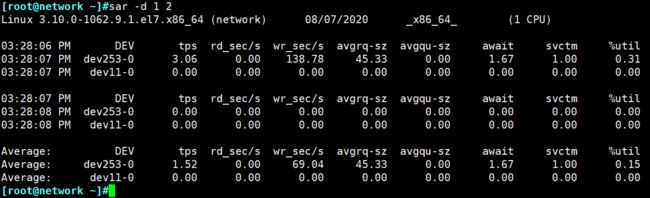
[root@network ~]#sar -d
Linux 3.10.0-1062.9.1.el7.x86_64 (network) 08/07/2020 _x86_64_ (1 CPU)
03:10:01 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
03:20:01 PM dev253-0 3.84 0.01 64.89 16.89 0.01 3.33 0.26 0.10
03:20:01 PM dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: dev253-0 3.84 0.01 64.89 16.89 0.01 3.33 0.26 0.10
Average: dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
# sar -d 1 2 (1:每隔一秒,2:写入2次)