深度学习细粒度分类综述
https://blog.csdn.net/xys430381_1/article/details/89640699#_2
一.概述
1.什么是图像细粒度分类
细粒度图像分类问题是对大类下的子类进行识别。细粒度图像分析任务相对通用图像(General/GenericImages)任务的区别和难点在于其图像所属类别的粒度更为精细。

2.意义:
细粒度图像分类无论在工业界还是学术界都有着广泛的研究需求与应用场景。
3.挑战:
由于分类的粒度很小,细粒度图像分类非常困难,在某些类别上甚至人眼都难以区分。主要原因有三:
子类之间差异细微:只在某个局部上有细微差异,如狗的眼睛
子类内部差异巨大:如姿态、背景带来的差异
受视角、背景、遮挡等因素影响较大
4.常用方法
目前细粒度图像分类基本上都 采用深度学习的方法,具体来说,大致可以分为以下几类:
使用通用DCNN进行细粒度分类,该方法难以捕获有区别性的局部细节,目前已经不太常用;
基于定位-识别的方法:先找到有区分度的局部,然后进行特征提取和分类,该方法又可分为强监督和弱监督两种;
基于网络集成的方法:使用多个DCNN对细粒度识别中的相似特征进行判别;卷积特征的高阶编码方法:
将cnn特征进行高阶转换然后进行分类,主要有fisher vector、双线性模型、核融合等。
二.基于定位-识别的方法
基于定位-识别的方法将细粒度图像识别分为两个部分:区别性区域定位和区域中的细粒度特征学习。在区别性区域定位时,通常会以强监督或弱监督的方式利用深度神经网络的卷积特征响应;而在细粒度特征学习时,则从定位到的各个区域中分别抽取特征,并将各特征组合到一起最后进行分类。
强监督的方法不仅需要类别标签,而且需要部件标注和关键部位框,该种方法取得了不错的效果,但缺点在于需要昂贵的人工标注,而且人工标注的位置不一定是最佳的区别性区域,这完全依赖于标注者的认知水平。
弱监督的方法利用注意力机制、聚类等手段来自动发现区别性区域,不需要部件标注,仅仅有分类标签即可完成训练。
2.1强监督
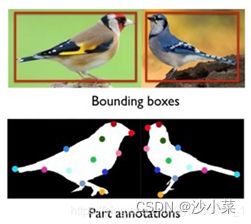
“强监督细粒度图像分类模型”是指:在模型训练时,为了获得更好的分类精度,除了图像的类别标签外,还使用了物体标注框(Object Bounding Box)和部位标注点(Part Annotation)等额外的人工标注信息,如下图所示。
2.1.1 Part-based R-CNN
(1)Part-based R-CNN就是利用R-CNN算法对细粒度图像进行物体级别(例如鸟类)与其局部区域(头、身体等部位)的检测,其总体流程如下图所示。
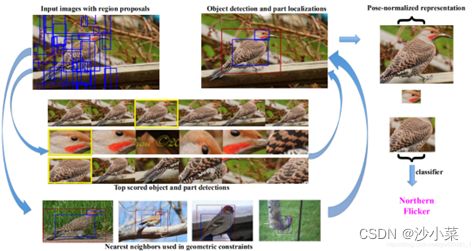
首先利用Selective Search等算法在细粒度图像中产生物体或物体部位可能出现的候选框(Object Proposal)。
用类似于R-CNN做物体检测的流程,借助细粒度图像中的Object Bounding Box和Part Annotation可以训练出三个检测模型(Detection Model),一个对应细粒度物体级别检测;一个对应物体头部检测;另一个则对应躯干部位检测。
对三个检测模型得到的检测框加上位置几何约束,例如,头部和躯干的大体方位,以及位置偏移不能太离谱等。这样便可得到较理想的物体/部位检测结果,如右上。
接下来将得到的图像块(Image Patch)作为输入,分别训练一个CNN,则该CNN可以学习到针对该物体/部位的特征。
最终将三者的全连接层特征级联(Concatenate)作为整张细粒度图像的特征表示,用SVM分类器进行分类训练。显然,这样的特征表示既包含全部特征(即物体级别特征),又包含具有更强判别性的局部特征(即部位特征:头部特征/躯干特征),因此分类精度较理想。
效果:CUB200-2011数据集上取得了73.9%的精度。
缺点:第一是 利用自底向上的区域产生方法, 会产生大量无关区域, 这会在很大程度上影响算法的速度. 第二是不仅在训练时需要借助Bounding Box和Part Annotation,为了取得满意的分类精度,在测试时甚至还要求测试图像提供BoundingBox,这便限制了Part-based R-CNN在实际场景中的应用。第三是该算法本身的创新性十分有限, 既然局部区域对于细粒度图像而言是关键所在, 那么对其进行定位检测则是必要的途径. 只是引入现有的通用定位算法, 似乎并不能很好地解决该问题。
2.1.2Pose Normalized CNN(姿态归一化CNN)
创新:基于Part-based R-CNN做了两点改进
对部位级别图像块做了姿态对齐操作。在原有的局部区域模型的基础上, 进一步考虑了鸟类的不同姿态的干扰, 减轻了类内方差造成的影响, 从而取得了较好的性能表现.
针对不同的级别图像块提取不同网络层的特征, 以试图构造一个更具区分度的特征表示。因为CNN不同层的特征具有不同的表示特性(如浅层特征表示边缘等信息,深层特征更具高层语义)。
先使用DPM预测2D位置及13个语义部位关键点(或者直接使用已提供的物体框及部位标注信息)
对部位级别图像块做姿态对齐操作

针对全局信息,提取FC8的特征;
针对头部信息,提取zu8ihou一层conv特征;
最后景不同级别的特征级联在一起最为整张图像的表示。
效果:在CUB200-2011数据集上取得了75.7%的精度,比Part-based R-CNN高了约2%。
缺点:
该方法依然没有解决训练和测试都需要标注框和局部标注的问题,且检测速度较慢,因此实际应用并不广泛。
2.1.3Mask-CNN
创新:图像分割不同部件+对大图、各部件提取特征+利用定位的位置信息保留前景信息去除背景信息+对三个网络的特征进行融合、分类。
该模型分为两个模块,第一是部分定位 (Part Localization),第二是全局和局部图像块的特征学习。
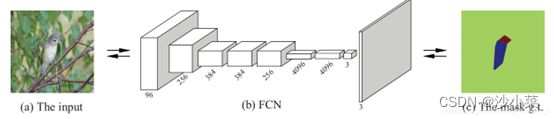
部分定位 (Part Localization):使用全卷积神经网络 (FullyConnected Network, FCN)做部件分割。在FCN的训练中,部分定位这一问题就转化为一个三分类分割问题,分别为头部、躯干和背景。其真实标记是通过Part Annotation得到的头部和躯干部位的最小外接矩形,如下图(c)所示。
分类:
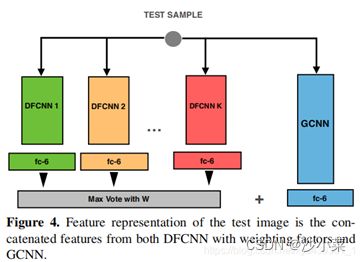
训练分类三个网络:在得到Part Mask后,可以通过Crop获得对应的图像块。同时,两个Part Mask组合起来刚好可组成一个较完整的Object Mask。同样,基于物体/部位图像块,Mask-CNN训练了三个子网络。
使用Selecting UsefulConvolutional Descriptor(“筛选关键卷积特征描述子”)筛选前景信息:其意思是保留表示前景的特征,去除表示背景的特征。在每个子网络中,上一步骤中学到的Part/Object Mask还起到起到了信息筛选的作用,如图( c)-(d)。
筛选后,对保留下来的特征描述子进行全局平均和最大池化(Global Average/Max Pooling)操作,后将二者池化后的特征级联作为子网络的特征表示,最后将三个子网特征再次级联作为整张图像的特征表示。
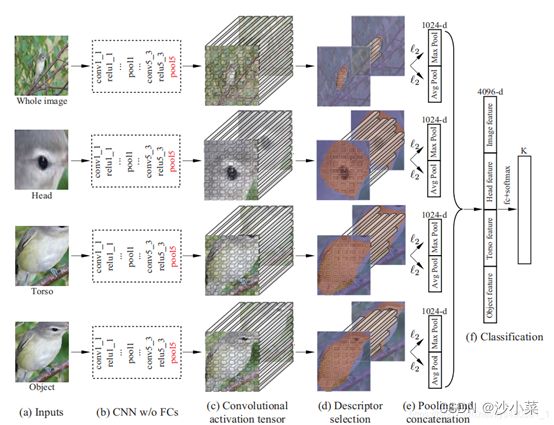
效果:在经典CUB数据上,基于ResNet的模型对200类不同鸟类分类精度可达87.3%。
缺点:该方法的优点在于最先对特征进行选择,利用了更少的特征维数;同时丢弃了全连接层,提高了网络的计算效率。但是,该方法对于一些复杂背景图像部分定位结果还有待提高,同时该方法依然需要标注信息进行训练。
2.2弱监督
弱监督目标定位是一种仅使用图像级标签,而不包含位置注释的目标定位方法。常规WSOL的局限在于仅能定位目标区分性最大的区域,而不是整个目标。
2.2.1两级注意力(Two-level attention)
< The application of two-level attention models indeep convolutional neural network for fine-grained image classification ,cvpr,2015>
两级注意力(Two Level Attention)算法第一个尝试不依赖额外的标注信息, 而仅仅使用类别标签来完成细粒度图像分类的工作。该结合了三种类型的注意力:(1)生成候选图像块的自底向上注意力、(2)选择相关块形成特定物体的对象级自顶向下注意力、(3)定位判别性部件的部件级自底向上注意力。通过整合这些类型的注意力机制训练特定的DCNN,以提取前景物体及特征较强的部件。该模型容易泛化,不需要边界框及部件标注。
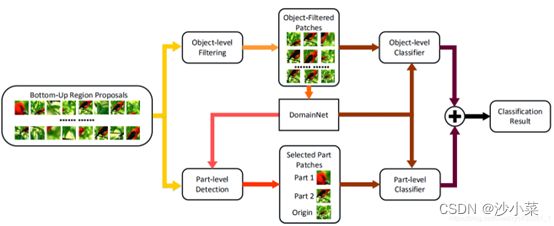
生成候选图像块的自底向上注意力:利用selective research从原始图片中提取大量的patch。
选择相关块形成特定物体的对象级自顶向下注意力:
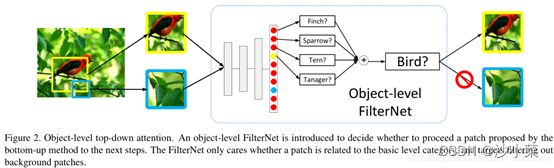
使用FilterNet分类网络对所有的patch进行挑选,识别是不是鸟,将含有鸟的patch挑选出来,背景过滤掉。需要很高的召回率,准确率可以不用很高。
然后,将这些FilterNet挑出来的patchs,用来训练一个新的CNN网络(称为DomainNet),并用来进行细粒度分类,得到相应的分数。
使用谱聚类的方法,对DomainNet的中间层进行聚类,发现这些不同层的神经元对鸟的不同部位(头,身子,翅膀等)反应程度不一样(也就是权重具有聚类模式)。因此将层分为了三类,也就是三个part detector,头部部件、身体部件、腿部件。
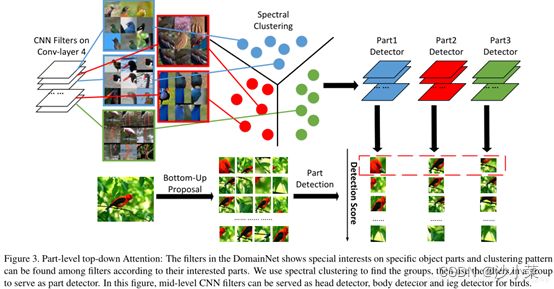
然后将这三个part detector分别用来对FilterNet挑出来的patchs进行细粒度分类,得到一个分数。最后,作者将每幅图片的object-level和part-level的分数连接起来,来训练SVM part-based分类器。
效果:总体上来看, 两级注意力模型较好地解决了在只有类别标签的情况下, 如何对局部区域进行检测的问题. 但是, 利用聚类算法所得到的局部区域, 准确度十分有限. 在同样使用Alex Net的情况下, 其分类精度要低于强监督的Part R-CNN算法。
2.2.2 FCN注意力模型(FCN attention)
3. 基于网络集成的方法
将细粒度数据集划分为几个相似的子集分别进行分类,或直接使用多个神经网络来提高细粒度分类的性能。
3.1子集特征学习网络(Subset feature learning networks)
Subset feature learning forfine-grained category classification—CVPR2015