redis配置集群
目录
一、配置集群所需的环境
1.1 规划网络
1.2 创建 Redis 节点主目录
1.3 创建6个节点目录
1.4 将 redis.conf 拷贝到这六个目录中
1.5 配置5个的redis.conf文件
二、启动集群
2.1 启动6个redis
2.2 创建redis的集群
2.3 使用redis-cli连接redis集群
三、测试集群
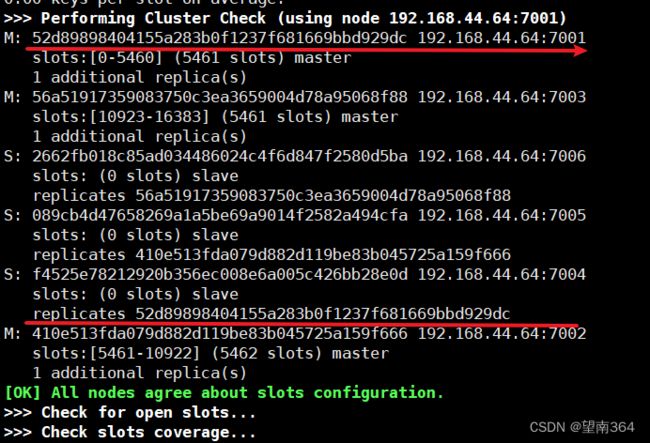
3.1 检查集群的状态
3.2 添加主节点
3.2.1 分配slots
3.3 配置从节点
3.4 删除节点
3.4.1 删除主节点
3.4.2 删除从节点
3.5 故障检测
四、集群录入值
五、什么是slots
六、集群优缺点
集群优点
集群缺点
七、redis相关应用问题
7.1 缓存穿透
7.1.1 缓存穿透问题描述:
7.1.2 缓存穿透解决方案:
7.2 缓存击穿
7.2.1 缓存击穿问题描述:
7.2.2 缓存击穿解决方案:
7.3 缓存雪崩
7.3.1 缓存雪崩问题描述:
7.3.2 缓存雪崩解决方案:
一、配置集群所需的环境
Redis集群至少需要3个节点,因为投票容错机制要求超过半数节点认为某个节点挂了该节点才是挂了,所以2个节点无法构成集群。
要保证集群的高可用,需要每个节点都有从节点,也就是备份节点
1.1 规划网络
规划6个IP地址分别是 7001、7002,7003、7004、7005,7006
1.2 创建 Redis 节点主目录
在redis的文件夹下创建redis_cluster 目录
[root@localhost redis]# mkdir redis_cluster 图:
1.3 创建6个节点目录
[root@localhost redis_cluster]# mkdir 7001 7002 7003 7004 7005 7006图:
1.4 将 redis.conf 拷贝到这六个目录中
先在7001文件写入redistribution.conf文件
创建文件
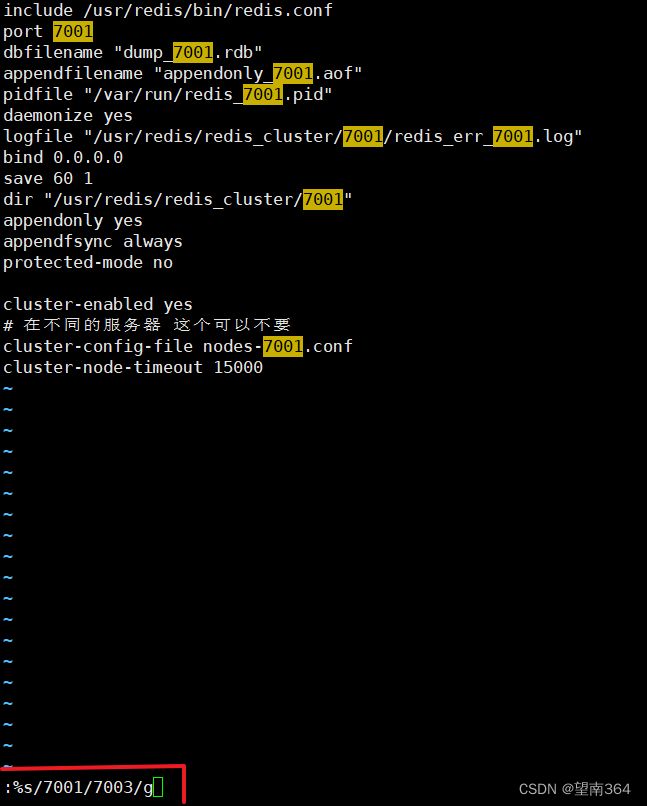
[root@localhost 7001]# touch redis.conf并且写入内容
include /usr/redis/bin/redis.conf
port 7001
dbfilename "dump_7001.rdb"
appendfilename "appendonly_7001.aof"
pidfile "/var/run/redis_7001.pid"
daemonize yes
logfile "/usr/redis/redis_cluster/7001/redis_err_7001.log"
bind 0.0.0.0
save 60 1
dir "/usr/redis/redis_cluster/7001"
appendonly yes
appendfsync always
protected-mode no
cluster-enabled yes
# 在不同的服务器 这个可以不要
cluster-config-file nodes-7001.conf
cluster-node-timeout 15000
在把7001的文件拷贝到7002 7003 7004 7005 7006 文件夹里面
[root@localhost redis_cluster]# echo ./7002 ./7003 ./7004 ./7005 ./7006 | xargs -n 1 cp -v /usr/redis/redis_cluster/7001/redis.conf1.5 配置5个的redis.conf文件
分别修改5个redis.conf的内容
分别进入5个文件夹的redistribution.conf
vim redis.conf使用vim的替换
:%s/被替换的/替换的(7002)/g举例修改7003的redis.conf文件:
二、启动集群
集群配置一般不要设置密码
2.1 启动6个redis
/usr/redis/bin/redis-server /usr/redis/redis_cluster/7001/redis.conf
/usr/redis/bin/redis-server /usr/redis/redis_cluster/7002/redis.conf
/usr/redis/bin/redis-server /usr/redis/redis_cluster/7003/redis.conf
/usr/redis/bin/redis-server /usr/redis/redis_cluster/7004/redis.conf
/usr/redis/bin/redis-server /usr/redis/redis_cluster/7005/redis.conf
/usr/redis/bin/redis-server /usr/redis/redis_cluster/7006/redis.conf查看是否启动成功
[root@localhost redis_cluster]# ps -ef | grep redis
2.2 创建redis的集群
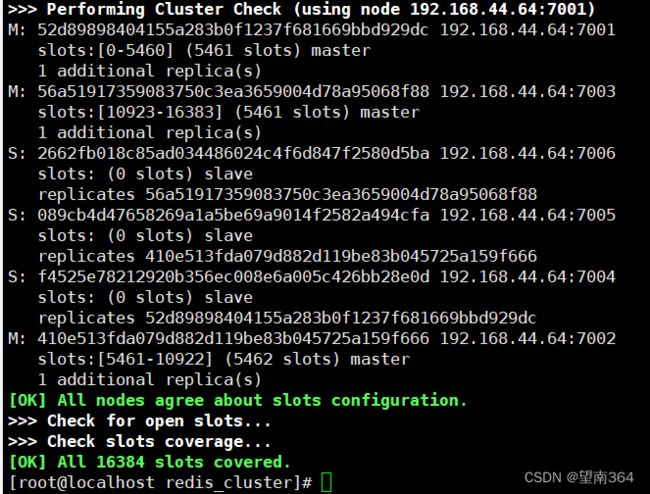
[root@localhost redis_cluster]# /usr/redis/bin/redis-cli --cluster create 192.168.44.64:7001 192.168.44.64:7002 192.168.44.64:7003 192.168.44.64:7004 192.168.44.64:7005 192.168.44.64:7006 --cluster-replicas 1

输入yes
成功
2.3 使用redis-cli连接redis集群
/usr/redis/bin/redis-cli -c -h 192.168.44.64 -p 7002 ![]()
查看集群的节点的信息 :cluster nodes

三、测试集群
3.1 检查集群的状态
/usr/redis/bin/redis-cli --cluster check 192.168.44.64:7002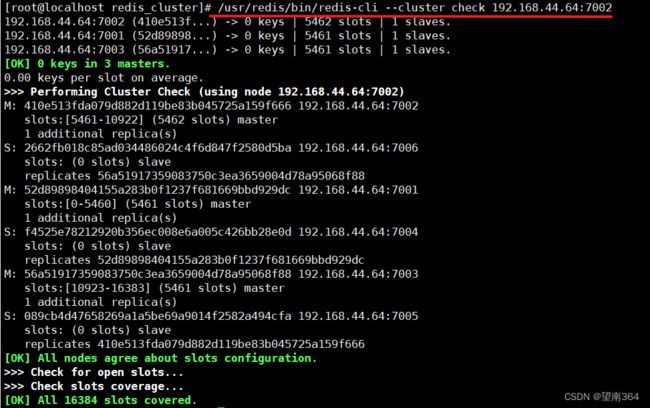
3.2 添加主节点
创建配置文件 7007 /redis.conf
include /usr/redis/bin/redis.conf
port 7007
dbfilename "dump_7007.rdb"
appendfilename "appendonly_7007.aof"
pidfile "/var/run/redis_7007.pid"
daemonize yes
logfile "/usr/redis/redis_cluster/7007/redis_err_7007.log"
bind 0.0.0.0
save 60 1
dir "/usr/redis/redis_cluster/7007"
appendonly yes
appendfsync always
protected-mode no
cluster-enabled yes
# 在不同的服务器 这个可以不要
cluster-config-file nodes-7007.conf
cluster-node-timeout 15000
启动
[root@localhost redis_cluster]# /usr/redis/bin/redis-server /usr/redis/redis_cluster/7007/redis.conf添加节点
前面的IP加端口号是要添加的redis节点,后面的IP和端口号是集群中的任意一个节点。
[root@localhost redis_cluster]# /usr/redis/bin/redis-cli --cluster add-node 192.168.44.64:7007 192.168.44.64:7002 
刚才添加的主节点还没有分配槽,所以无法使用
添加从节点之前需要设置从节点并启动节点
3.2.1 分配slots
/usr/redis/bin/redis-cli --cluster reshard 127.0.0.1:7007输入分配的大小
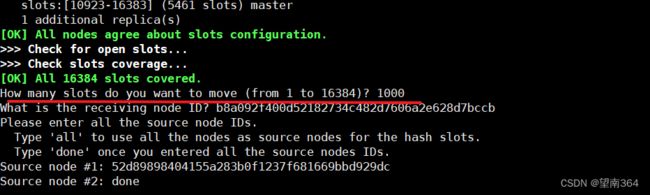
输入接受的id
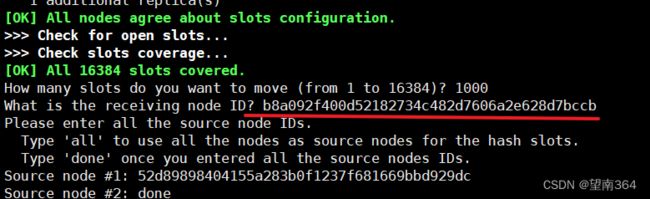
输入从哪里获取的id
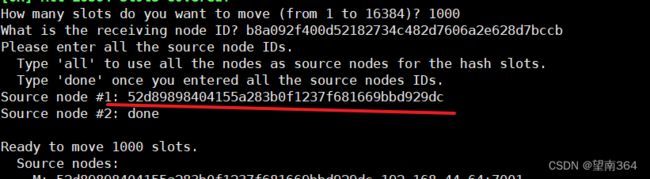
如果不想输入的话就输入done

3.3 配置从节点
创建7008的redis.conf文件
include /usr/redis/bin/redis.conf
port 7008
dbfilename "dump_7008.rdb"
appendfilename "appendonly_7008.aof"
pidfile "/var/run/redis_7008.pid"
daemonize yes
logfile "/usr/redis/redis_cluster/7008/redis_err_7008.log"
bind 0.0.0.0
save 60 1
dir "/usr/redis/redis_cluster/7008"
appendonly yes
appendfsync always
protected-mode no
cluster-enabled yes
# 在不同的服务器 这个可以不要
cluster-config-file nodes-7008.conf
cluster-node-timeout 15000启动
[root@localhost 7008]# /usr/redis/bin/redis-server /usr/redis/redis_cluster/7008/redis.conf添加从节点
redis-cli --cluster add-node 新节点 集群节点 --cluster-slave --cluster-master-id 主节点的id
[root@localhost /]# /usr/redis/bin/redis-cli --cluster add-node 192.168.44.64:7008 192.168.44.64:7007 --cluster-slave --cluster-master-id b8a092f400d52182734c482d7606a2e628d7bccb 192.168.44.64

3.4 删除节点
3.4.1 删除主节点
删除主节点需要先使用 reshard 把主节点的slots移到其他节点才可以
把slots分配完后接着执行命令

slots为空后删除
[root@localhost /]# /usr/redis/bin/redis-cli --cluster del-node 192.168.44.64:7007 b8a092f400d52182734c482d7606a2e628d7bccb 
3.4.2 删除从节点
/usr/redis/bin/redis-cli --cluster del-node 集群节点 节点id
例子:
[root@localhost /]# /usr/redis/bin/redis-cli --cluster del-node 192.168.44.64:7008 d7c90f78d40ca3b7f3c9f0f1aae65dd930219db13.5 故障检测
集群关机之后,集群重启,只需要直接启动各个节点,不需要重新组网,redis会根据node.conf自动组网
验证集群是否生效:
关闭一个主节点查看对应的备用节点是不是能够顶替主节点成为主节点
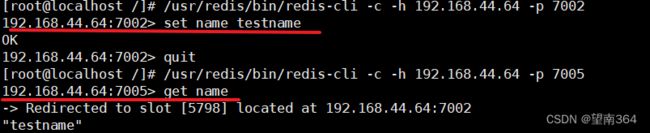
存/取数据的时候查看对应的端口号
(关闭主节点以后需要耐心等待一会儿 让他重新分配一下空间)
关闭的时候一定要使用shutdown命令不要使用kill命令,否则配置会出错
没关闭之前
关闭主节点
/usr/redis/bin/redis-cli -h 192.168.44.64 -p 7001 shutdown查看主从关系

7004变成了主节点 证明集群配置成功
主节点恢复后,主从关系会如何?主节点回来变成从机。
如果所有某一段插槽的主从节点都宕掉,redis服务是否还能继续?
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为yes ,那么 ,整个集群都挂掉
如果某一段插槽的主从都挂掉,而cluster-require-full-coverage 为no ,那么,该插槽数据全都不能使用,也无法存储。
四、集群录入值
集群不支持批量存储
Mset 不支持的 ,key取余之后得到的值可能是不一样的,放到不同的槽里面,没办法更改slots 失败

五、什么是slots
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value时,redis 先对 key(有效值)使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
Redis 集群没有使用一致性hash, 而是引入了哈希槽的概念。
集群中的每个节点负责处理一部分插槽
在redis-cli每次录入、查询键值,redis都会计算出该key应该送往的插槽,如果不是该客户端对应服务器的插槽,redis会报错,并告知应前往的redis实例地址和端口。
redis-cli客户端提供了 –c 参数实现自动重定向。
如 redis-cli -c –p 7000登入后,再录入、查询键值对可以自动重定向。
不在一个slot下的键值,是不能使用mget,mset等多键操作。

可以通过{}来定义组的概念,从而使key中{}内相同内容的键值对放到一个slot中去。(按组分配插槽)
六、集群优缺点
集群优点
1. 高可用性:Redis集群允许将数据分布在多个节点上,当某个节点发生故障时,其他节点仍然可以继续提供服务,保证了系统的高可用性。
2. 数据分片:Redis集群使用分片技术,将数据分散存储在多个节点上,有效地利用了集群的整体存储容量,提高了单个节点的处理性能。同时,分片技术也降低了单个节点的负载压力,提高了系统的扩展性。
3. 自动故障转移:Redis集群支持主节点的自动故障转移。当主节点发生故障时,集群会自动选举一个从节点成为新的主节点,保证了数据的连续性和可用性。
4. 负载均衡:Redis集群通过对数据进行分片和均衡,实现了负载均衡的效果。当有新的节点加入或者节点发生故障时,集群会自动重新分片并进行负载均衡,提高了系统的整体性能和稳定性。
5. 纵向扩展:Redis集群允许在需要更高性能的情况下,通过增加节点数量来进行纵向扩展。新添加的节点会自动参与到分片中,提供更多的存储容量和处理能力。
需要注意的是,Redis集群也存在一些限制和注意事项,比如不支持跨节点事务和Lua脚本执行,需要应用程序自行处理分片和一致性等问题。因此,在使用Redis集群时需要根据具体的业务需求和场景进行合理的规划和配置。
集群缺点
1. 配置和管理复杂:相比单个Redis实例,Redis集群的配置和管理更加复杂。需要考虑集群的拓扑结构、数据分片规则、节点的故障转移等方面,需要花费一定的时间和精力进行配置和管理。
2. 数据一致性:由于Redis集群使用的是分片技术,数据被分散存储在多个节点上,这可能导致在数据写入和读取时的一致性问题。例如,当一个键被分片到不同的节点上时,在进行读取时可能需要在多个节点上进行查询,增加了读取数据的复杂性。
3. 无法跨节点事务:Redis集群不支持跨节点的事务操作。在一个事务中,如果涉及到多个键被分片到不同的节点上,就无法保证事务的原子性,需要在应用层进行额外的处理。
4. 内存成本较高:Redis是基于内存的数据库,而Redis集群中的每个节点都要存储一部分数据,意味着集群的总体内存成本会相对增加。如果数据量大,可能需要更多的内存资源来支持集群的运行。
5. 节点间通信开销:Redis集群中的节点之间需要进行频繁的通信以保持数据一致性和集群的正常运行。这种通信会增加网络开销和延迟,对于网络质量不佳的环境可能会影响性能。
尽管存在这些缺点,但Redis集群在大规模高可用性和高扩展性方面仍然是一种常用的解决方案。在使用Redis集群时,需要综合考虑业务需求和系统限制,合理选择和配置集群方案。
七、redis相关应用问题
7.1 缓存穿透
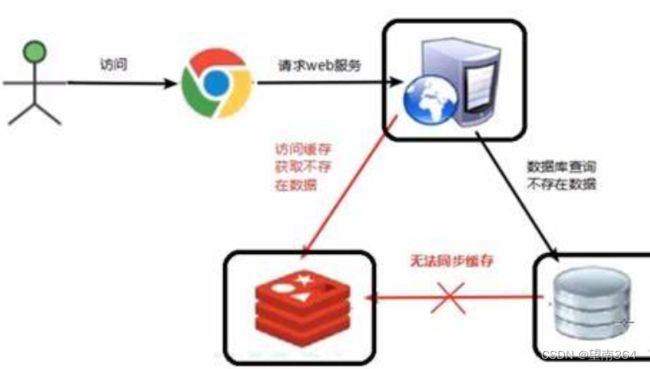
缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
7.1.1 缓存穿透问题描述:
Redis缓存穿透问题通常是指在应用程序中查询一个不存在的键时,查询会直达底层数据存储(比如关系型数据库),而缓存中却没有被预先设置好的值,导致查询变得缓慢,并且会对底层存储造成压力,甚至出现宕机。
Redis缓存穿透问题可能是恶意攻击或者简单的应用程序bug造成的,其中最常见的攻击场景是黑客尝试使用恶意查询来绕过缓存,获取应用程序中的敏感数据。如一个黑客发起一个查询不存在的key: SELECT * FROM user WHERE id=10001 ,如果服务端没有相应的缓存,那么这条查询请求将会直接传递到数据库执行,可能导致服务端出现宕机甚至数据库连接异常。
7.1.2 缓存穿透解决方案:
为了解决Redis缓存穿透问题,可以采取以下几种解决方案:
-
缓存空对象:针对查询结果为空的情况,可以在Redis中存储一个空对象,例如,使用空字符串或者null值占位。这样当应用程序查询不存在的键时,Redis缓存中就会存在一个空对象,而不会对底层数据源造成查询压力。
-
布隆过滤器:布隆过滤器是一种快速判断一个元素是否存在于集合中的数据结构。当用户或黑客请求某个不存在的key时,先通过布隆过滤器快速判断出查询结果不存在,直接返回,避免了对底层数据源的查询。
-
懒加载:对于可能被黑客攻击的接口,可以使用懒加载方式进行处理,只在第一次查询的时候加载缓存,后面的查询直接从缓存中获取即可,避免了重复查询和对底层数据源的压力。
-
设置查询限制:设置最大查询次数或者查询频率限制,当超出限制后直接拒绝服务,避免恶意攻击对服务端造成影响。
综上,Redis缓存穿透问题需要在多个方面探索解决方案,尤其是在可能被恶意攻击的场景中特别需要加强安全防护。
7.2 缓存击穿
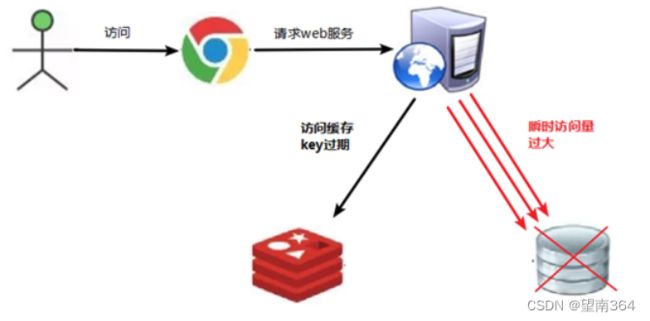
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
7.2.1 缓存击穿问题描述:
key对应的数据存在,但在redis中没有过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
7.2.2 缓存击穿解决方案:
key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。
解决问题:
1. 预先设置热门数据:在redis高峰访问之前,把一些热门数据提前存入到redis里面,加大这些热门数据key的时长
2. 实时调整:现场监控哪些数据热门,实时调整key的过期时长
3. 使用锁:
3.1 就是在缓存失效的时候(判断拿出来的值为空),不是立即去加载数据库。
3.2 先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX)去set一个mutex key
3.3 当操作返回成功时,再进行load db的操作,并回设缓存,最后删除mutex key;
3.4 当操作返回失败,证明有线程在load db,当前线程睡眠一段时间再重试整个get缓存的方法。
7.3 缓存雪崩
缓存雪崩是指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
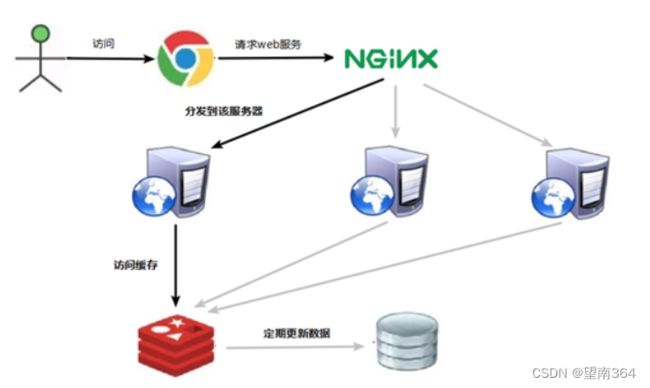
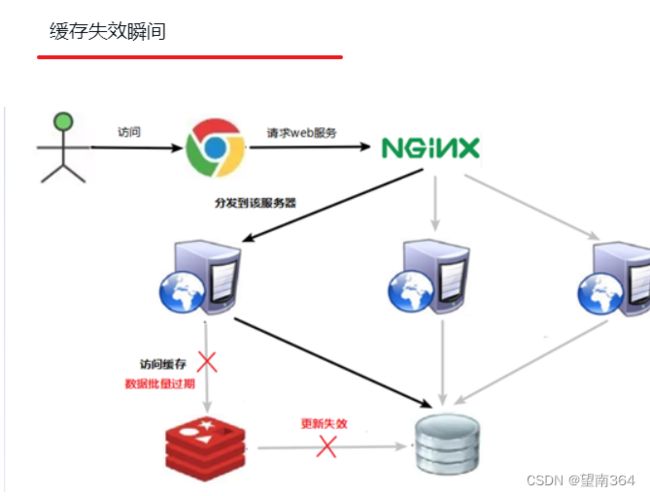
7.3.1 缓存雪崩问题描述:
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存雪崩与缓存击穿的区别在于这里针对很多key缓存,击穿则是某一个key正常访问
7.3.2 缓存雪崩解决方案:
缓存失效时的雪崩效应对底层系统的冲击非常可怕!
解决方案:
(1) 构建多级缓存架构:nginx缓存 + redis缓存 +其他缓存(ehcache等)
(2) 使用锁或队列:
5000 1000
用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。不适用高并发情况
(3) 设置过期标志更新缓存:
记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
(4) 将缓存失效时间分散开:
比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。