excel记录wFm数值(推理过程)
1 导入计算wfm库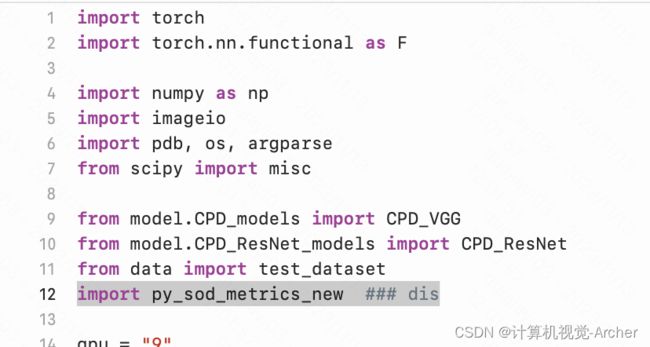 2 实例化具体的指标
2 实例化具体的指标
3 列表循环之前,设置空list

4 单图评测-将图号、图片名、数值记录
列表里面存储dict
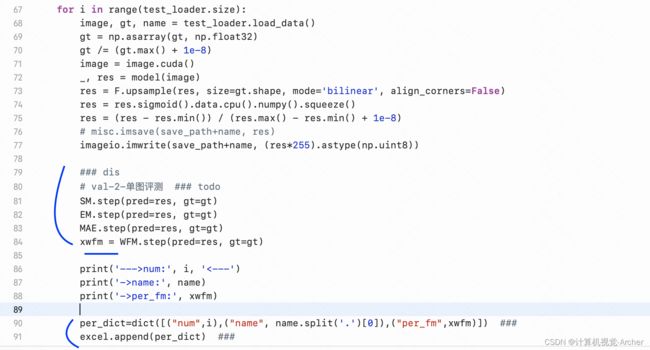
5 将excel列表结果逐个存入excel.xlsx文件

完整代码
test_CPD.py
### test_CPD.py ###
import torch
import torch.nn.functional as F
import numpy as np
import imageio
import pdb, os, argparse
from scipy import misc
from model.CPD_models import CPD_VGG
from model.CPD_ResNet_models import CPD_ResNet
from data import test_dataset
import py_sod_metrics_new ### dis
gpu = "9"
print('\n', '===> GPU num: ', gpu)
os.environ["CUDA_VISIBLE_DEVICES"] = gpu # todo 用于评测
parser = argparse.ArgumentParser()
parser.add_argument('--testsize', type=int, default=352, help='testing size')
parser.add_argument('--is_ResNet', type=bool, default=False, help='VGG or ResNet backbone')
opt = parser.parse_args()
dataset_path = '/cluster/home3/zjc/Dataset/COD/COD-TE/'
# val-1-读入
WFM = py_sod_metrics_new.WeightedFmeasure() ### dis todo 1实例化
SM = py_sod_metrics_new.Smeasure()
EM = py_sod_metrics_new.Emeasure()
MAE = py_sod_metrics_new.MAE()
# SOD
# 'official_cpd/CPD-R.pth'
# 'official_cpd/CPD.pth'
# COD
# 'CPD_ResNet/CPD-99.pth'
# 'CPD_VGG/CPD-99.pth'
model_name_res = 'CPD_Resnet/'
model_name_vgg = 'CPD_VGG/'
if opt.is_ResNet:
model = CPD_ResNet()
model.load_state_dict(torch.load('/cluster/home3/zjc/Code/COD/CPD_My/CPD-master/models/'+ model_name_res + 'CPD-99.pth'))
else:
model = CPD_VGG()
model.load_state_dict(torch.load('/cluster/home3/zjc/Code/COD/CPD_My/CPD-master/models/'+ model_name_vgg + 'CPD-99.pth'))
model.cuda()
model.eval()
# test_datasets = ['PASCAL', 'ECSSD', 'DUT-OMRON', 'DUTS-TEST', 'HKUIS']
test_datasets = ['COD10K-TE'] # 'COD10K-TE' 'Less'
for dataset in test_datasets:
if opt.is_ResNet:
save_path = './results/'+model_name_res + dataset + '/'
else:
save_path = './results/'+model_name_vgg + dataset + '/'
if not os.path.exists(save_path):
os.makedirs(save_path)
image_root = dataset_path + dataset + '/image/'
gt_root = dataset_path + dataset + '/mask/'
test_loader = test_dataset(image_root, gt_root, opt.testsize)
excel = [] ### dis
for i in range(test_loader.size):
image, gt, name = test_loader.load_data()
gt = np.asarray(gt, np.float32)
gt /= (gt.max() + 1e-8)
image = image.cuda()
_, res = model(image)
res = F.upsample(res, size=gt.shape, mode='bilinear', align_corners=False)
res = res.sigmoid().data.cpu().numpy().squeeze()
res = (res - res.min()) / (res.max() - res.min() + 1e-8)
# misc.imsave(save_path+name, res)
imageio.imwrite(save_path+name, (res*255).astype(np.uint8))
### dis
# val-2-单图评测 ### todo
SM.step(pred=res, gt=gt)
EM.step(pred=res, gt=gt)
MAE.step(pred=res, gt=gt)
xwfm = WFM.step(pred=res, gt=gt)
print('--->num:', i, '<---')
print('->name:', name)
print('->per_fm:', xwfm)
per_dict=dict([("num",i),("name", name.split('.')[0]),("per_fm",xwfm)]) ###
excel.append(per_dict) ###
###生成表格### ### dis
from openpyxl import Workbook # 读取excel库
workbook = Workbook() # 实例化
if opt.is_ResNet: # 自动切换res
# 默认sheet
sheet = workbook.active # 激活sheet
sheet.title = "openpyxl_CPD_" + model_name_res # 命名sheet
sheet.append(["num", "name", "wfm"]) # 插入标题
for data in excel: # 列表循环读取dict
sheet.append(list(data.values()))
workbook.save("openpyxl_CPD_" + model_name_res + ".xlsx")
else: # 自动切换vgg
# 默认sheet
sheet = workbook.active # 激活sheet
sheet.title = "openpyxl_CPD_" + model_name_vgg # 命名sheet
sheet.append(["num", "name", "wfm"]) # 插入标题
for data in excel: # 列表循环读取dict
sheet.append(list(data.values()))
workbook.save("openpyxl_CPD_" + model_name_vgg + ".xlsx")
### val-3-数据集求均值
wfm = WFM.get_results()["wfm"] # todo
sm = SM.get_results()["sm"]
em = EM.get_results()["em"]
mae = MAE.get_results()["mae"]
# maelist = MAE.get_results()[1]
# print("mae:{}".format(mae)) # todo
print("wfm:{} sm:{} mae:{}".format(wfm, sm, mae)) # todo
# print("wfm:{} sm:{} em:{} mae:{}".format(wfm, sm,em,mae)) # todo