消息中间件----内存数据库 Redis7(第1章 Redis 概述)
第1章 Redis 概述
1.1 Redis 简介
Redis,Remote Dictionary Server,远程字典服务,由意大利人 Salvatore Sanfilippo(又名Antirez)开发,是一个使用 ANSI C 语言编写、支持网络、可基于内存亦可持久化的日志型、NoSQL 开源内存数据库,其提供多种语言的 API。从 2010 年 3 月 15 日起,Redis 的开发工作由 VMware 主持。从2013 年 5 月开始,Redis 的开发由 Pivotal 赞助。
2008 年时 Salvatore Sanfilippo 自己开发一个叫 LLOOGG 的网站。Redis 之所以称之为字典服务,是因为 Redis 是一个 key-value 存储系统。支持存储的 value类型很多,包括 String(字符串)、List(链表)、Set(集合)、Zset(sorted set --有序集合)和 Hash(哈希类型)等。
Redis 的国际知名用户有,Twitter、GitHub、Facebook 等,国内知名用户有,阿里巴巴、腾讯、百度、搜狐、优酷、美团、小米等。熟练使用和运维 Redis 已经成为开发运维人员的
一个必备技能。
1.1.1 NoSQL
NoSQL(“non-relational”, “Not Only SQL”),泛指非关系型的数据库。随着互联网 web2.0
网站的兴起,传统的关系数据库在处理 web2.0 网站,特别是超大规模和高并发的 SNS 类型的 web2.0 纯动态网站已经显得力不从心,出现了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL 数据库的产生就是为了解决大规模数
据集合多重数据种类带来的挑战,特别是大数据应用难题。
(1) 键值存储数据库
就像 Map 一样的 key-value 对。典型代表就是 Redis。
(2) 列存储数据库
关系型数据库是典型的行存储数据库。其存在的问题是,按行存储的数据在物理层面占
用的是连续存储空间,不适合海量数据存储。而按列存储则可实现分布式存储,适合海量存
储。典型代表是 HBase。
(3) 文档型数据库
其是 NoSQL 与关系型数据的结合,最像关系型数据库的 NoSQL。典型代表是 MongoDB。
(4) 图形(Graph)数据库
用于存放一个节点关系的数据库,例如描述不同人间的关系。典型代表是 Neo4J。
1.2 Redis 的用途
Redis 在生产中使用最多的场景就是做数据缓存。即客户端从 DBMS 中查询出的数据首先写入到 Redis 中,后续无论哪个客户端再需要访问该数据,直接读取 Redis 中的即可,不仅减小了 RT,而且降低了 DBMS 的压力。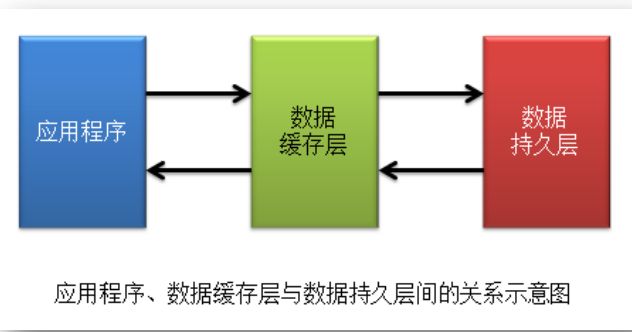
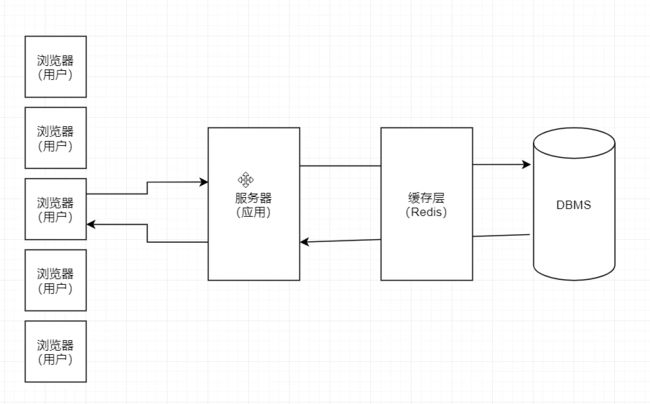
假设有很多用户 这些用户都提交了请求 并且都是在一个时间点提交的 也就是说在高并发的场景中
每一个请求提交给服务器 服务器都要进行处理 服务器都要到数据库里面做查询 这样子, DBMS(数据库)的压力就会很大
解决办法:
在服务器和数据库中间加一层缓存层
生活例子:
假设张三的经理现在要查张三的年龄 我们首先要先到redis里面去查找有没有张三的年龄信息 如果没有 然后在到DBMS里面去查找 找到之后 在找张三的年龄信息给缓存到redis
现在张三的主管也要去查找张三的年龄信息 通过服务器后 达到redis后 发现有张三的年龄信息 这样子的话 就可以从redis返回给服务器 服务器在返回给前端 从而DBMS压力降低
问题1:这样子 redsi压力不是变大了?
答:redis的里面的数据都是存放在内存里面的 而我们的数据库的数据是在磁盘放着 如果在数据库里面查找 要做大量的检索 但是在redis里面就可以不用 直接通过k就可以定位到这个数据 所以我们的redis查询非常的快 就算是高并发也是不怕的
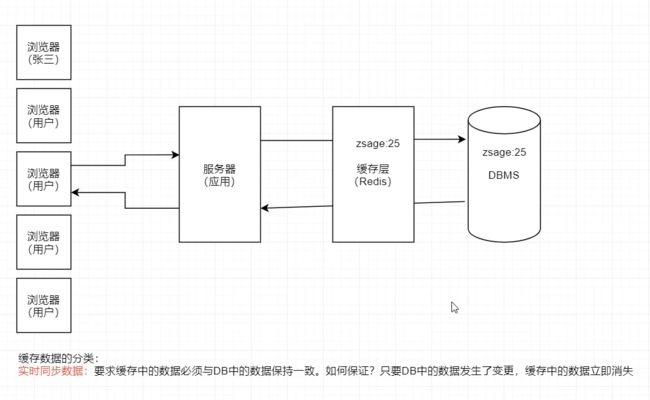
根据 Redis 缓存的数据与 DBMS 中数据的同步性划分,缓存一般可划分为两类:
实时同步缓存,与阶段性同步缓存。实时同步缓存是指,DBMS 中数据更新后,Redis 缓存中的存放的相关数据会被立即清
除,以促使再有对该数据的访问请求到来时,必须先从 DBMS 中查询获取到最新数据,然后
再写入到 Redis。
问题2:假设有一天 张三发现自己填写的年龄不对 然后现在又从新填写一个 发了一个写的请求 因为是写的操作不是读的操作 所以数据直接就到了DBMS里面 原本写的张三年龄是23 现在又进一个实际是25
现在张三的经理过来查询张三的年龄 结果因为redis里面有张三之前的年龄23 直接返回了 可是实际的年龄是25 这就造成redis里面的数据和DBMS里面的数据不一致的情况
答:当DBMS里面的数据发生变化时 redis的数据将会消失 所以这个时候当张三的经理过来查询的时候 先到redis里面查找 发现并没有找到有关于张三年龄的信息 这个时候就只能到DBMS里面去查 这个时候查询到的数据就是25 放到redis里面 以后其他的领导去查询的时候都是25
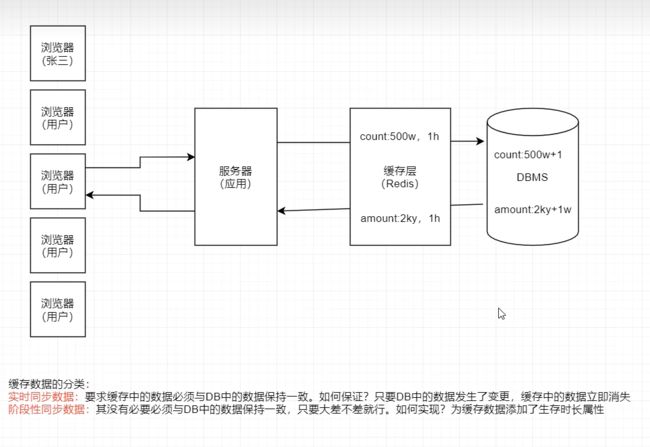
阶段性同步缓存是指,Redis 缓存中的数据允许在一段时间内与 DBMS 中的数据不完全
一致。而这个时间段就是这个缓存数据的过期时间。
问题3:redis的数据和DBMS的数据一定要保持一致吗?
答:不一定
假设现在有一个金融平台 交易额 :2k亿 注册用户数量:500w
现在有个用户张三来查 先把数据放在redis
现在张三想买这个产品1w元 注册了账号 这时 交易额2k亿+1 注册用户数量:500w +1w 在DBMS里面 如果按照前面的理论 redis里面的数据应该要消失的 但是我们设想 如果redis里面的数据不消失 还是老数据 对平台的运营有没有受到影响 结果是不受影响 原因是因为查不多
这个时候可以给redis设置一个生存时长 比如设置一小时 在一小时之间 redis的数据还是老数据 到一个小时之后 redis里面的数据才会消化
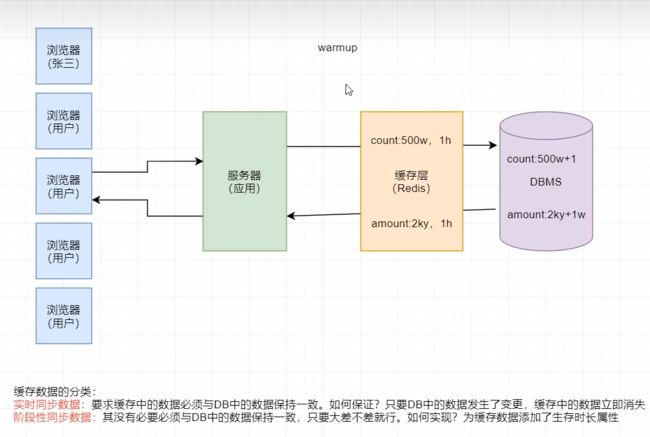
补充知识:其实redis里面的数据并不是在第一个用户过来的时候 进行查询的 当我们的服务器启动之后 要先进行warmup
warmup 的过程就是要先把基础性的信息先写入到redis里面 这样子的话 第一个用户查询的时候 就可以查到redis里面的数据
1.3 Redis 特性
能够做缓存的技术、中间件很多,例如,MyBatis 自带的二级缓存、Memched 等。只所以在生产中做缓存的产品几乎无一例外的会选择 Redis,是因为它有很多其它产品所不具备的特性。
性能极高:
Redis 读的速度可以达到 11w 次/s,写的速度可以达到 8w 次/s。只所以具有这么高的性能,因为以下几点原因:
(1)Redis 的所有操作都是在内存中发生的。
(2)Redis 是用 C 语言开发的。
(3)Redis 源码非常精细(集性能与优雅于一身)。
简单稳定:
Redis 源码很少。早期版本只有 2w 行左右。从 3.0 版本开始,增加了集群功能,代码变为了 5w 行左右。
持久化:
Redis 内存中的数据可以进行持久化,其有两种方式:RDB 与 AOF。
高可用集群:
Redis 提供了高可用的主从集群功能,可以确保系统的安全性。
丰富的数据类型:
Redis 是一个 key-value 存储系统。支持存储的 value 类型很多,包括
String(字符串)、List(链表)、Set(集合)、Zset(sorted set --有序集合)和 Hash(哈希类型)等,还有 BitMap、HyperLogLog、Geospatial 类型。
(1)BitMap:一般用于大数据量的二值性统计。
(2)HyperLogLog:其是 Hyperlog Log,用于对数据量超级庞大的日志做去重统计。
(3)Geospatial:地理空间,其主要用于地理位置相关的计算。
6..强大的功能:
Redis 提供了数据过期功能、发布/订阅功能、简单事务功能,还支持 Lua脚本扩展功能。
7 .客户端语言广泛:
Re7dis提供了简单的 TCP 通信协议,编程语言可以方便地的接入 Redis。所以,有很多的开源社区、大公司等开发出了很多语言的 Redis 客户端。
8 .支持 ACL 权限控制:
之前的权限控制非常笨拙。从 Redis6 开始引入了 ACL 模块,可以为不同用户定制不同的用户权限。
ACL,Access Control List,访问控制列表,是一种细粒度的权限管理策略,可以针对任意
用户与组进行权限控制。目前大多数 Unix 系统与 Linux 2.6 版本已经支持 ACL 了。
Zookeeper 早已支持 ACL 了。
Unix 与 Linux 系统默认使用是 UGO(User、Group、Other)权限控制策略,其是一种粗
粒度的权限管理策略。9 . 支持多线程 IO 模型:Redis 之前版本采用的是单线程模型,从 6.0 版本开始支持了多线程模型。
1.4 Redis 的 IO 模型
Redis 客户端提交的各种请求是如何最终被 Redis 处理的?Redis 处理客户端请求所采用
的处理架构,称为 Redis 的 IO 模型。不同版本的 Redis 采用的 IO 模型是不同的。
1.4.1 单线程模型
对于 Redis 3.0 及其以前版本,Redis 的 IO 模型采用的是纯粹的单线程模型。即所有客户端的请求全部由一个线程处理。
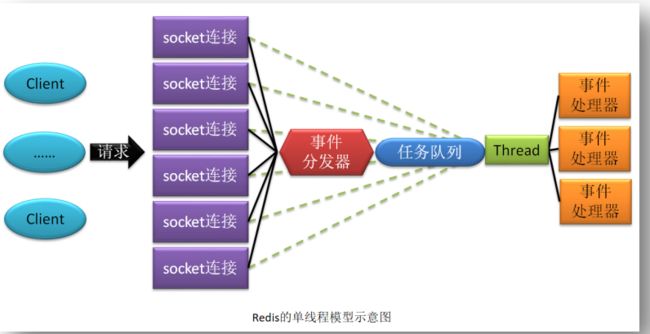
Redis 的单线程模型采用了多路复用技术。
对于多路复用器的多路选择算法常见的有三种:select 模型、poll 模型、epoll 模型。
poll 模型的选择算法:采用的是轮询算法。该模型对客户端的就绪处理是有延迟的。
epoll 模型的选择算法:采用的是回调方式。根据就绪事件发生后的处理方式的不同,
又可分为 LT 模型与 ET 模型。每个客户端若要向 Redis 提交请求,都需要与 Redis 建立一个 socket 连接,并向事件分发器注册一个事件。一旦该事件发生就表明该连接已经就绪。而一旦连接就绪,事件分发器就会感知到,然后获取客户端通过该连接发送的请求,并将由该事件分发器所绑定的这个唯一的线程来处理。如果该线程还在处理多个任务,则将该任务写入到任务队列等待线程处理。
只所以称为事件分发器,是因为它会根据不同的就绪事件,将任务交由不同的事件处理
器去处理。
1.4.2 混合线程模型
从 Redis 4.0 版本开始,Redis 中就开始加入了多线程元素。处理客户端请求的仍是单线程模型,但对于一些比较耗时但又不影响对客户端的响应的操作,就由后台其它线程来处理。
例如,持久化、对 AOF 的 rewrite、对失效连接的清理等。
1.4.3 多线程模型
Redis 6.0 版本,才是真正意义上的多线程模型。因为其对于客户端请求的处理采用的是多线程模型。多线程 IO 模型中的“多线程”仅用于接受、解析客户端的请求,然后将解析出的请求写入到任务队列。而对具体任务(命令)的处理,仍是由主线程处理。这样做使得用户无需考虑线程安全问题,无需考虑事务控制,无需考虑像 LPUSH/LPOP 等命令的执行顺序问题。
1.4.4 优缺点总结
(1) 单线程模型
优点:可维护性高,性能高。不存在并发读写情况,所以也就不存在执行顺序的不确定性,不存在线程切换开销,不存在死锁问题,不存在为了数据安全而进行的加锁/解锁开销。
缺点:性能会受到影响,且由于单线程只能使用一个处理器,所以会形成处理器浪费。
(2) 多线程模型
优点:其结合了多线程与单线程的优点,避开了它们的所有不足
缺点:该模型没有显示不足。如果非要找其不足的话就是,其并非是一个真正意义上的“多线程”,因为真正处理“任务”的线程仍是单线程。所以,其对性能也是有些影响的。