数据结构之散列表(七)
前言
一、什么是散列表
散列表是如何组织数据的呢?
散列表的基本概念
二、Hash算法的设计
什么是Hash算法
Hash算法的应用场景
三、散列表冲突的解决
1. 开放寻址法
2. 链表法
3. 开放寻址法与链表法的对比
四、散列表实际应用场景
1. 拼写检查器
2. LRU缓存淘汰算法
3. 高级语言中对应的容器
五、学习过程中的疑问
前言
散列表笔者一直认为是一种设计特别牛逼的数据结构,一直好奇它的历史由来,奈何网上基本全是有关它的概念,一时半会还没能找到关于散列表比较权威的发展史相关的。
不知你是否跟笔者一样很好奇我们平时经常使用的 Work 文档编辑器中对于英文拼写错误的提示功能是怎么实现的呢?如果让你自己去实现,你会如何去实现呢?
其实,实现 Work 文档编辑器对于英文拼写错误这一功能的底层原理就是运用了散列表。
一、什么是散列表
散列表(Hash table,也叫哈希表),是存储Key-Value映射的集合。可根据键(key)实现近O(1)的时间内对内存中数据进行读写的数据结构。
需要说明的是这里所说的 散列表 或 哈希表 或 Hash Table ,以及对应的函数 散列函数、哈希算法、Hash算法指的都是同一个概念,之所以会有这几个名字,纯属是由于中文翻译的差别。
在Java中常用的HashMap底层对应的数据结构正是散列表(该散列表的组成为:数组+链表或数组+链表+红黑树),在HashMap中可通过 Key 值实现随机读取的功能,该功能其实与数组通过下标实现随机读取是一样的原理。要知道随机读取可是数组杀手锏了,看到这里是不是好奇,散列表跟数组的关系呢?
其实,散列表支持随机访问用的正是数组通过下标来随机访问数据的特性,可以说散列表就是数组的一个扩展,简单地来说是,如果没有数组就没有散列表。
散列表是如何组织数据的呢?
笔者个人总结大概可以概括为以下几点:
- 创建指定长度的数组;
- 当往散列表中插入数据时,通过Hash函数将传入的key值转换成数组下标,并value存入该数组对应下标的内存单元; 注:往散列表插入数据是指插入key-value这类键值对的数据。
- 当通过key对散列表数据进行查找时,再次通过相同的Hash函数将对应的key转换成数组下标,这时查询就可通过数组下标的方式实现近O(1)时间内进行随机读取了;其中删除与修改同理。
下面引用专栏的一个简单例子如下:
假如我们有89名选手参加学校运动会。为了方便记录成绩,每个选手胸前都会贴上自己的参赛号码。这89名选手的编号依次是1到89,现在我们希望编程实现这样一个功能,通过编号快速找到对应的选手信息。你会怎么做呢?
我们可以把这89名选手的信息放在数组里。编号为1的选手,我们放到数组中下标为1的位置;编号为2的选手,我们放到数组中下标为2的位置。以此类推,编号为k的选手放到数组中下标为k的位置。
因为参赛编号跟数组下标一一对应,当我们需要查询参赛编号为x的选手的时候,我们只需要将下标为x的数组元素取出来就可以了,时间复杂度就是O(1)。
这样按照编号查找选手信息,效率是不是很高?
实际上,这个例子已经用到了散列的思想。在这个例子里,参赛编号是自然数,并且与数组的下标形成一映射,所以利用数组支持根据下标随机访问的时候,时间复杂度是O(1) 这一特性,就可以实现快速查找编号对应的选手信息。你可能要说了,这个例子中蕴含的散列思想还不够明显,那我来改造一下这个例子。
假设校长说,参赛编号不能设置得这么简单,要加上年级、班级这些更详细的信息,所以我们把编号的规则稍微修改了一下,用6位数字来表示。比如051167,其中,前两位05表示年级,中间两位11表示班级,最后两位还是原来的编号1到89,这个时候我们该如何存储选手信息,才能够支持通过编号来快速查找选手信息呢?
思路还是跟前面类似。尽管我们不能直接把编号作为数组下标,但我们可以截取参赛编号的后两位作为数组下标,来存取选手信息数据。当通过参赛编号查询选手信息的时候,我们用同样的方法,取参赛编号的后两位,作为数组下标,来读取数组中的数据。
上述例子就是典型的散列思想。其中,参赛选手的编号我们叫作键(key)或者关键字。我们用它来标识一个选手。我们把参赛编号转化为数组下标的映射方法就叫作散列函数(或"Hash函数" 、 "哈希函数" ) ,而散列函数计算得到的值就叫作散列值(或"Hash值" 、"哈希值" )。形象图如下:

通过上述的概括,我们知道散列表有几个比较关键的知识点,Hash算法的设计、散列表的扩容、散列表的冲突解决(不同的key有可能对应着同一个hash值)。
散列表的基本概念
散列表跟数组其他数据结构类似,同样支持CURD操作;
装载因子: 散列表的装载因子 = 填入表中的元素个数 / 散列表的长度
动态扩容:当散表表达到装载因子后,就会进行自动扩容,类似数组当进行自动扩容时就会出现数据搬移以及对所有数据进行重新的hash值计算。为啥需要重新进行Hash值的计算呢?
简单的说明如下图所示,当进行扩容后,散列表的大小发生了变化,则意味着原先数据的存储位置也需要发生变化,因此需要重新进行hash值的计算。
为了避免散列表的频繁自动扩容,假如我们事先知道散列表需要存储数据的大小,那么可以将其长度设置在达到装载因子之前的长度。比如,需要存储1000个数值,加载因子为0.75,那么就将散列表长度设置为 1000/0.75。

二、Hash算法的设计
什么是Hash算法
将任意长度的二进制值串映射为固定长度的二进制值串,这个映射的规则就是哈希算法,而通过原始数据映射之后得到的二进制值串就是哈希值。
业界常用的哈希算法有:MD5、SHA、SHA-1、SHA-256、AES等。从通过Hash算法构造散列表以及用哈希算法生成密钥相关的,我们可知Hash算法一般应该符合以下那些特点:
- 正向快速:给定明文和 hash 算法,在有限时间和有限资源内能计算出 hash 值。
- 逆向困难:给定(若干) hash 值,在有限时间内很难(基本不可能)逆推出明文。
- 输入敏感:原始输入信息修改一点信息,产生的 hash 值看起来应该都有很大不同。
- 冲突避免:很难找到两段内容不同的明文,使得它们的 hash 值一致(发生冲突)。即对于任意两个不同的数据块,其hash值相同的可能性极小;对于一个给定的数据块,找到和它hash值相同的数据块极为困难。
如下通过MD5算法计算Hash值,发现只是少了一个感叹号其结果却大相径庭。注:此处为了方便查看已将对应的Hash值转换成16进制了。MD5默认生成的Hash值是128位的二进制字符串。
MD5(" 我今天讲哈希算法!") = 425f0d5a917188d2c3c3dc85b5e4f2cb
MD5(" 我今天讲哈希算法 ") = a1fb91ac128e6aa37fe42c663971ac3d
Hash算法的应用场景
场景一:安全加密
将用户密码通过Hash算法转换成Hash值是我们常用的用户密码入库的方法;这里主要就是运用了Hash算法,逆向解密困难的特点。这里为了方便说明还是用MD5来说明,虽说MD5已号称被我国王小云科研工作者破解了,但总的来说,在有限资源跟有限时间内破解还是有一定难度的。正是基于这一点,有一些网站会建议我们隔一段时间修改一次密码或者是设置更加复杂的密码相关的。
我们通常说的密码解密其实原理很简单,它们并没有通过逆向解密,而是通过穷举的方法或者字典法来一一测试从而进行碰撞得出明文密码。例如,我们需要破解一串如下的暗文密码‘a1fb91ac128e6aa37fe42c663971ac3d’,其可通过一一碰撞数据库中已存在的暗文密码与明文密码,进而找出对应的明文密码。如下图所示一些在线解密的网站正是用了这个原理进行解密。
由于有些用户设置的密码相对比较简单,如果被获取到密文,通过字典比对,相信很容易也就被破解了。
针对上述这类字典查询密码,我们可通过对用户添加一定规则的字段再进行加密存储入数据库,这样也就加强了密码的强度。
当然,无论怎么加强,终究是没有绝对安全的加密算法。安全和攻击是一种博弈关系,不存在绝对的安全。所有的安全措施,只是增加攻击的成本而已。
关于MD5破解的文章可见小灰漫画 漫画:如何破解MD5算法?
场景二:唯一标识
通过Hash算法计算出大数据进行信息摘要,通过一个固定长度的简短二进制来标识大数据文件,此特点也就可用于高效检索对比数据。
场景三:数据检验
如客户往我们数据中心同步一个文件,该文件使用MD5校验,那么客户在发送文件的同时会再发一个存有校验码的文件;
我们拿到该文件后做MD5运算,得到的计算结果与客户发送的校验码相比较,如果一致则认为客户发送的文件没有出错,否则认为文件出错需要重新发送。
该场景其实主要是运用了Hash算法对输入数据敏感的特点。
如下引用专栏的例子再进行说明
电驴这样的BT下载软件你肯定用过吧? 我们知道, BT下载的原理是基于P2P协议的。我们从多个机器上并行下载一个2GB的电影,这个电影文件可能会被分割成很多文件块(比如可以分成100块,每块大约20MB) 。等所有的文件块都下载完成之后,再组装成一个完整的电影文件就行了。
我们知道,网络传输是不安全的,下载的文件块有可能是被宿主机器恶意修改过的,又或者下载过程中出现了错误,所以下载的文件块可能不是完整的。如果我们没有能力检测这种恶意修改或者文件下载出错,就会导致最终合并后的电影无法观看,甚至导致电脑中毒。现在的问题是,如何来校验文件块的安全、正确、完整呢?
具体的BT协议很复杂,校验方法也有很多,我来说其中的一种思路。
我们通过哈希算法,对100个文件块分别取哈希值,并且保存在种子文件中。我们在前面讲过,哈希算法有一个特点,对数据很敏感。只要文件块的内容有一丁点儿的改变,最后计算出的哈希值就会完全不同。所以,当文件块下载完成之后,我们可以通过相同的哈希算法,对下载好的文件块逐一求哈希值,然后跟种子文件中保存的哈希值比对。如果不同,说明这个文件块不完整或者被篡改了,需要再重新从其他宿主机器上下载这个文件块。
场景四:散列表对应的散列函数
散列函数中用到的哈希算法更加关注散列后的值能不能平均分布,以及散列函数的正向执行的效率。
三、散列表冲突的解决
1. 开放寻址法
核心思想:当出现散列冲突时,便重新探测一个空闲位置,将其插入。
探测空闲位置的策略:
线性探测:当往散列中插入数据发生散列冲突时,如里待写入的位置被占用,则依次往后探测是否有空闲位置,有则插入。
二次探测:其实二次探测与线性探测很类似,只不过是探测的步长不一样而已。线性探测的步长为每次一步,二次探测步长为‘每次的二次方’,如hash(key)+0, hash(key)+1,hash(key)+4, hash(key)+9。
双重散列:使用一组散列函数 hash1 (key),hash2 (key),hash3(key),我们先用第一个散列函数,如果计算得到的存储位置已经被占用,再用第二个散列函数,依次类推,直到找到空闲的存储位置。
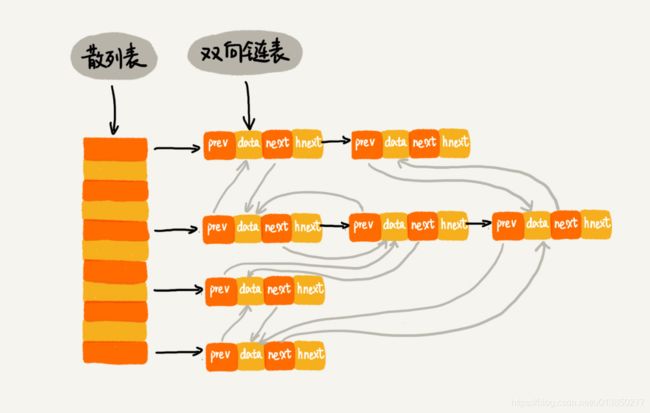
2. 链表法
当出现散列冲突时,则在冲突位置以链表的形式存储Hash值相同的数据。该结构由数组+链表的形式组成,如下图所示:

3. 开放寻址法与链表法的对比
- 1. 开放寻址数据全部存储于数组中,可以利用CPU的缓存机制加快查询的速度。而链表法由于链表这种结构是随机存储的,因此对于CPU成块加载数据这机制就没法用到了。
- 2. 开放寻址组装的数据序列化比较方便。
- 3. 开放寻址对于删除数据时间复杂度会比较高。
- 4. 在空间的使用情况下,链表的利用用会比较高也比较方便,不需要事先声明固定的大小,这一点基本跟数组与链表的区别一致了。
总结如下:
当数据量比较小、装载因子小的时候,适合采用开放寻址法。这也是Java中的ThreadLocalMap使用开放寻址法解决散列冲突的原因。
基于链表的散列冲突处理方法比较适合存储大对象(存储大对象就使的指针所占的空间可忽视了)、大数据量的散列表,而且,比起开放寻址法,它更加灵活,支持更多的优化策略,比如用红黑树代替链表。
四、散列表实际应用场景
1. 拼写检查器
解决开篇中Word 文档编辑器拼写错误提示这类应用核心思想如下:
常用的英文单词有20万个左右,假设单词的平均长度是10个字母,平均一个单词占用10个字节的内存空间,那20万英文单词大约占2MB的存储空间,就算放大10倍也就是20MB。对于现在的计算机来说,这个大小完全可以放在内存里面。所以我们可以用散列表来存储整个英文单词词典。
当用户输入英文单词时,我们拿其输入的单词与散列表中的数据进行对比,如果能查到便说明输入无误,否则提示错误。
2. LRU缓存淘汰算法
LRU缓存淘汰算法主要操作有哪些?主要包含3个操作:
①往缓存中添加一个数据;
②从缓存中删除一个数据;
③在缓存中查找一个数据;
④总结:上面3个都涉及到查找。
其实 Java 容器中的 LinkedHashMap正好就已经将LRU所需要的功能已经全部包装好了。构造成的散列表如下图所示:
3. 高级语言中对应的容器
这里还是以Java 容器 HashMap来做个简单的举例,这里由于篇幅有限,详细说明见如下链接对应的博文。
HashMap 原理探索
五、学习过程中的疑问
在学习散列表的冲突过程中,笔者一开始的疑问,权当是一个记录吧。
疑问一:
散列函数计算出来的hash值相同的概率可以算是几乎接近为零了,为啥我们在散列表中要特别在意散列冲突的问题呢?
对于这个疑问其实是对散列表的底层原理的理解不够透彻引起的,散列表在存储数据时,其实是将hash值转换成数组下标再进行存储的。转换成下标后,由于采取的转换规则导致其有一定概率的冲突。这一点详细内容可见后文HashMap原理的说明。
疑问二:
通过链表解决冲突问题时,在根据hash(key) 值转换成数组下标查找的时候,当出现多个数据时,如何确定要查找的数据就是我们要查的呢?
对于这个疑问其实也可以说是对散列表的理解不够,散列表中其实每个存储单元存储的数据包含了两个部分,分别是key与value值(类似HashMap底层的数组就存储了键值对);在根据hash(key)进行查询时,如果出现链表,则再将key拿出来跟链表中存储的key直接进行字符串对比,相同则返回。
注:了解更多数据结构知识
该系列博文为笔者学习《数据结构与算法之美》的个人学习笔记小结