【大数据实训】基于当当网图书信息的数据分析与可视化(八)
温馨提示:文末有 CSDN 平台官方提供的博主 的联系方式,有偿帮忙部署
基于当当网图书信息的数据分析与可视化
一、实验环境
(1)Linux: Ubuntu 16.04
(2)Python: 3.5
(3)Hadoop:3.1.3(4)Spark: 2.4.0(5)Web框架:flask 1.0.3
(6)可视化工具:Echarts
(7)开发工具:Visual Studio Code
二、小组成员及分工
(1)成员:林海滢,王惠玲,陈嘉怡,郭诗念
(2)分工:xxx负责xxxx部分,xxx负责xxxx部分,xxx负责xxxx部分。
三、数据采集
3.1数据集说明
爬取网站:http://search.dangdang.com/?key=java,是当当网的java图书的信息网站。数据文件:java_books.xlsx。其中包含了1661条与java图书信息有关的数据。
数据格式为:

图 3. 1 采集数据格式
数据中包含的内容如下:
(1)book_name: 图书的标题
(2)introduction:图书的简介
(3)author: 图书的作者
(4)price: 图书的价格(元/本)
(5)press: 图书出版社
(6)comment: 图书的评论
3.2.爬取数据集以及将其保存到本地D盘文件中的流程
(1)选取所需要爬取的页面进行遍历爬取
(2)通过正则表达式抓取所需要的数据
(3)将爬取出的数据转化为dataframe格式并保存为xlsx文件存放在D盘
四、数据清洗与预处理
4.1预处理中提取的数据


图 4.1 数据处理前的数据格式及存在问题的特征列
4.2 清洗预处理后的数据格式

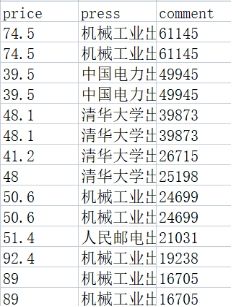
图 4.2 数据处理后的数据格式及特征列
4.3 清洗与预处理的流程
(1)首先检查数据的结构以及是否有数据缺失。
(2)发现book_name特征列的数据格式不对,于是处理转换为了整数类型。
(3)发现price特征列的数据格式不对,于是处理转换为了浮点类型。
(4)内容简介列数据清洗 删除异常值。
(5)保存清洗与预处理后的数据集。
五、spark数据分析
5.1 数据分析目标
(1)图书的售价分布情况(观察图书价格大体集中在哪个分段得出图书价格趋势)

(2)部分图书出版社的出书数量统计

(3)图书的作者出书(观察哪个作者出的书最多)
(4)图书的评论分布情况(观察图书评论大体集中在哪个分段得出图书评论趋势)

(5)图书的部分作者数量统计
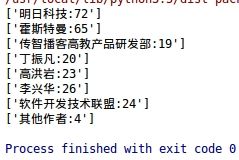
(6)分析价格的最大值、最小值、均值、方差和中位数

六、数据可视化
本实验的可视化基于mutplotlib实现。
6.1.可视化环境
利用和anaconda里面的jubiter和vscode进行可视化操作,最后的代码结构如下。
6.2 图表展示与结论分析
(1)图书的售价分布情况(观察图书价格大体集中在哪个分段得出图书价格趋势)
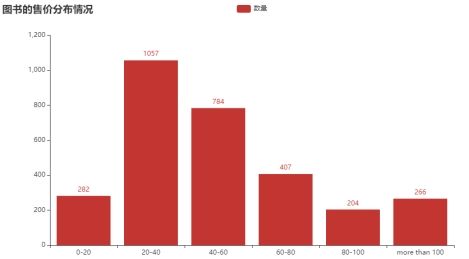
图6.2.1图书的售价分布情况
分析结论:通过这个柱状图可以看出图书售卖价格集中在2060这里。说明了大多数人购书倾向于中端价格。比如2040这里,售价比较便宜图书的销量就会多。而6080这里的价格上升了购买的人就相对少了,销量也随之减少。我们也可以从中得出2060的销量有1841,而20一下和60以上的销量有1159。所以大胆推测出我国中层收入人数是低高层收入人数的1.6倍左右。
(2)部分图书出版社的出书数量统计

图6.2.2部分图书出版社的出书数量统计
(3)图书的作者出书(观察哪个作者出的书最多)
(4)图书的评论分布情况(观察图书评论大体集中在哪个分段得出图书评论趋势)

图6.2.4图书的评论分布情况
分析结论:通过这个图我们可以看出92%的图书评论都是在0~100之间。也就是说92%的人不爱对图书做出评论,其余少部分人会对图书做出评论。所以我们可以大胆推测现在大多数人都不爱对看过的书发布之间的看法。
(5)图书的部分作者数量统计进行数据可视化图表分析
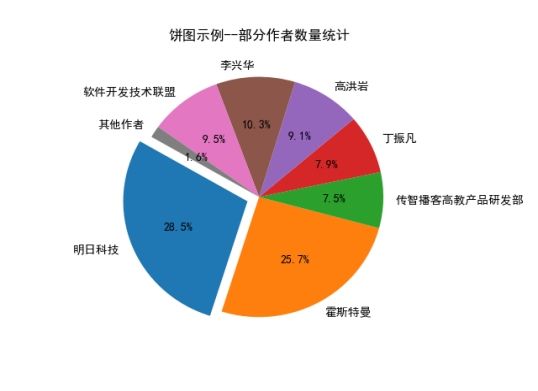
图6.2.5部分作者数量统计
分析结论:通过这个图我们可以看出我们找出来的部分作者54%左右的作者写的书都在65本以下(这就与第五部分的数据分析相对应),也侧面说明了这个数据里面50%左右的作者写的java的书不多即50%以下的作者可能不是专门做java这个领域的,可能还包括别的领域,大多数关于java的图书都是专攻这个专业的组织和作者写的。
(5)分析价格的最大值、最小值、均值、方差和中位数

图6.2.6分析价格的最大值、最小值、均值、方差和中位数
分析结论:通过这个图我们可以看出图书价格的中位数和均值在55块钱左右,方差在50左右,证明了图书的价格波动不是很大,从最大值、最小值中可以看出最便宜的图书是10元左右,最贵的图书是120元左右,所以表明了买一本java图书总体的均价为55元左右。