JVM基本常识
目录
内存区域划分
类加载
何时触发类加载?
双亲委派模型
GC
GC回收那部分内存?
怎么回收?
怎么找垃圾(判定某个对象是否是垃圾)
具体怎么回收?
我的GitHub:Powerveil · GitHub
我的Gitee:Powercs12 (powercs12) - Gitee.com
皮卡丘每天学Java
内存区域划分
JVM内存区域大致分为四块:堆、栈(虚拟机栈,本地方法栈)、程序计数器、方法区。
public class Test {
// 成员变量
public int c = 11;
public Test d = new Test();
// 静态变量
public static int e = 12;
public static Test f = new Test();
public static void main(String[] args) {
// 局部变量
int a = 10;
Test b = new Test();
}
}
a,b为局部变量,在栈中存储;c,d为成员变量,在堆中存储;e,f为静态变量,在方法区中存储。
| 变量位置 | JVM位置 |
|---|---|
| 局部变量 | 栈上 |
| 成员变量 | 堆上 |
| 静态变量 | 方法区上 |
类加载
类加载大致分为五个过程:加载、连接、初始化,其中连接又分为:验证、准备、解析三个过程。
以字符串为例
1.加载:找到.class文件,读取文件内容,并且按照.class规范的格式来解析
2.验证:检查当前的.class里的内容格式是否符合要求
下图为.class文件的定义,类似C语言的结构体,左侧是类型,右侧是变量名。

u2代表两个字节的无符号整数,u4代表四个字节的无符号整数,cp_info,field_info,method_info,attribute_info为类似.class文件类型的其他类型。
| 属性 | 含义 |
|---|---|
| magic | 魔数 |
| minor_version | 最小版本号 |
| major_version | 最大版本号 |
| constant_pool_count | 常量池个数 |
| constant_pool[constant_pool_count-1] | 常量池 |
| access_flags | 类的访问权限和属性 |
| this_class | 表示此文件定义的类 |
| super_class | 表示其父类 |
| interfaces_count | 当前类实现的接口数量 |
| interfaces[interfaces_count] | 当前类具体实现哪些接口 |
| fields_count | 当前类拥有的属性个数 |
| fields[fields_count] | 当前类具体拥有的属性 |
| methods_count | 当前类拥有的方法个数 |
| methods[methods_count] | 当前类具体拥有的方法 |
| attributes_count | 当前类的其他属性个数 |
| attributes[attributes_count] | 当前类的其他其他属性 |
这里着重说一下魔数
在计算机领域,魔数有两个含义,一指用来判断文件类型的魔数;二指程序代码中的魔数,也称魔法值。
这里主要说第一种含义,不仅Java的.class文件有魔数,其他文件也有魔数,一个文件的类型不是取决于文件后缀名,本质上却决于该文件的魔数值。
3.准备:给类里的静态变量分配空间(并设置默认值)
4.解析,初始化字符串常量,把符号引用替换成直接引用。
5.初始化,针对类进行初始化,初始化静态成员,执行静态代码块,并且加载父类...
何时触发类加载?
第一次使用到一个类的时候就会触发加载(类似懒汉模式)。
1.创建这个类的实例
2.使用了类的静态方法/静态属性
3.使用类的子类(加载子类会触发加载父类)
注意第二条
访问类中的static final 成员时,JVM会在编译阶段对类执行编译优化,当类中有static final修饰的基本数据类型和字符串类型时,就会在编译阶段执行初始化.
双亲委派模型
JVM加载类,是由类加载器(class loader)这样的模块来负责的
JVM自带了多个类加载器(程序员也可以自己实现)
主要分为三类加载器
1.Bootstrap ClassLoader(负责加载标准库中的类)
2.Extension ClassLoader(负责加载JVM扩展的库的类,Java规范里没有写的,但是JVM实现出来了)
3.Application ClassLoader(负责加载自己的项目里的自定义类)
这三类加载器各自负责各自的片区(负责各自的一组目录)
1.上述三个类加载器存在父子关系
2.进行类加载的时候,输入的内容 全限定类名 java.util.Arrays
3.加载的时候,从Application ClassLoader开始
4.某个类加载器开始加载的时候,不会立即扫描自己负责的路径,而是先把任务委托给 父 “类加载器” 先来进行处理
5.找到最上面的Bootstrap ClassLoader 在往上,没有父 类加载器了,自己加载
6.如果自己没找到类,就交给自己的儿子,继续加载。
7.如果一直找到最下面Application ClassLoader也没有找到类,就会抛出一个"类没找到"异常,类加载就失败了,类似下图

按照这个顺序加载,最大的好处在于:如果开发者写了一个类,这这个类的全限定类名和标准库里的类冲突了,(比如自己写一个全限定类名为java.util.Arrays的类),此时仍然保证类加载可以加载到标准库的类,防止代码加载错了带来问题。
演示一下

idea非常智能,没有找到我自己写的Arrays,演示失败

我尝试先让类导入再改包名
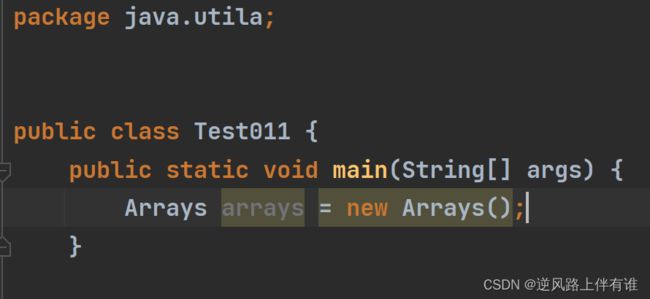
idea还是检测出来了

GC
垃圾回收(Garbage Collection)
写C语言代码的时候,使用malloc申请内存(动态内存申请),务必需要通过free来进行释放,如果不手动free,这个内存会一直持续到程序结束。造成空间上的浪费,而这些只用几次就不使用,直到程序结束还释放的空间就称为垃圾。
手动释放,最大的问题在于容易忘记,造成内存泄漏。内存泄漏短时间内不会出现问题,就像一颗定时炸弹,不确定那个时候会造成程序崩溃。
于是程序员大佬就想出各种方案,其中GC(垃圾回收)就是一种主流的方案。许多语言使用了GC如,Java、Python、JavaScript、Golang、PHP等等。
Java程序员只需要负责申请内存,释放内存的工作交给JVM来完成,JVM会自动判定当前的内存什么时候需要释放,认为这个内存不再使用了,就自动释放了。
GC回收那部分内存?
堆(GC主要就是针对堆来回收)、方法区(类对象,加载之后也不太会卸载)、栈(释放时机确定,不必回收)、程序计数器(固定内存空间,不必回收)。

GC中回收内存,不是以"字节"为单位,而是以“对象”为单位
怎么回收?
1.先找出垃圾(找出是谁垃圾,没错,是我了)

2.再回收垃圾(释放内存)
怎么找垃圾(判定某个对象是否是垃圾)
如果一个对象再也不用了,就说明就是垃圾了。再Java中,对象的使用需要凭借引用,假设有一个对象已经没有任何引用能够指向它了,这个对象自然就无法再被使用了,
最关键的要点,通过引用来判定当前对象是否还能被使用了,没有引用指向就是为是无法被使用。
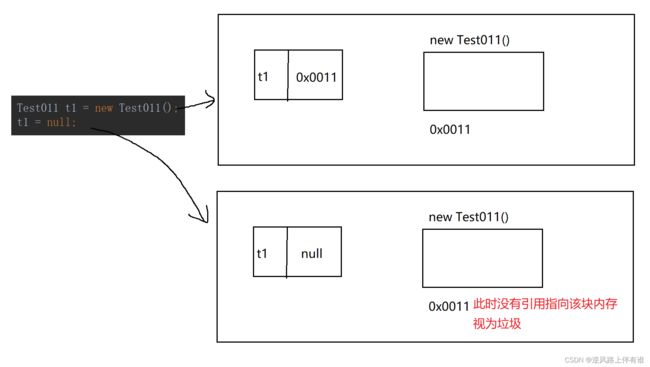
两种典型的判断对象是否存在引用的方法:引用计数[不是JVM采取的方法],可达性分析[是JVM采取的办法]
引用计数
给每个对象都加上一个计数器,这个计数器就表示“当前的对象有几个引用”

每次多一个引用指向该对象,计数器就+1
每次少一个引用指向该对象,计数器就-1
(比如引用是一个局部变量,除了作用域。或者引用是个成员变量,所在的对象被销毁了)
当引用计数器数值为0的时候,就说明当前这个对象已经无人能够使用了,此时就可以进行释放了
引用计数的优点:简单,容易实现,执行效率也比较高
缺点
1.空间利用率比较低,尤其是小对象 比如计数器是个int,如果你的对象本身里面只有一个int成员
2.可能会出现循环引用的情况

虽然当前这两个对象引用计数为1,但实际上是两个对象再互相引用,此时外界的代码仍然是无法访问和使用对象的,但是由于引用计数没有成为0,这俩对象是无法进行释放的。
可达性分析
约定一些特定的变量,成为“GC roots”,每个一段时间,从GC roots出发,进行遍历,看看当前哪些变量是能够被访问到的,能被访问到的变量就称为“可达”,否则就是“不可达”
GC roots
-
栈上的变量
-
常量值应用的对象
-
方法区,引用类型的静态变量
每一组都有一些变量
每个变量都可以视为起点
从这些起点出发,尽可能遍历,能够找到所有访问到的对象
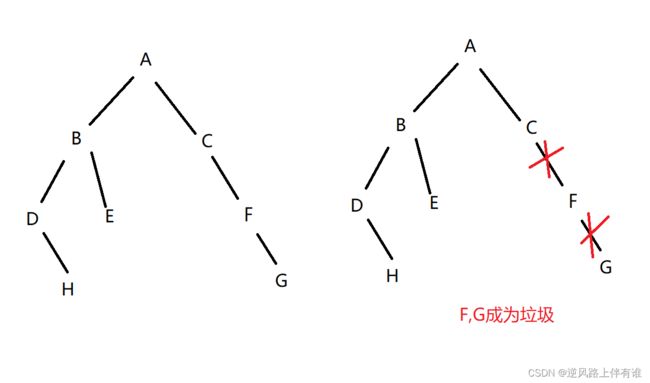
只要是通过上述root的方式访问到的对象,对象都是可达的。
具体怎么回收?
标记-清除法
先从堆首地址开始遍历,判断该对象是垃圾后标记为垃圾,第二次遍历清除被标记为垃圾标志的垃圾
然后把对象对应的内存空间进行释放。

缺点
这种方式有一个最大的问题:内存碎片。导致整个内存“支离破碎”,比如上述每个黑色区域是1Kb,此时整个有4K的空闲空间,但是由于内存是离散的,导致想申请2Kb的内存空间(连续的)都申请不成功
复制算法
针对刚才所说的内存碎片问题来进行引入的方法

使用左侧空间时,右侧不用;使用右侧空间时,左侧不用。
不再是原地释放了,而是把“非垃圾”(可以继续使用的对象)拷贝到另外一侧,然后再把之前这一半整个释放掉,内存碎片就得到了妥善处理。
缺点
1.空间利用率更低了(用一半,丢一半)
2.如果一轮GC下来,大部分对象要保留,只有少数对象要回收,这个时候复制开销就很大了。
标记整理法
类似于顺序表删除元素搬运操作,将后面元素依次搬运到前面垃圾位置。

这种方式相对于上述发复制算法来说,空间利用率上来了,同时也还是能够解决内存碎片问题,但是搬运操作也是比较耗时的。
分代回收策略
上述三个方式,都不是十全十美,所以需要根据实际的场景,因地制宜的解决问题。
根据对象不同的特点,采取不同的回收方式
对象不同的特点:根据对象年龄划分
对象年龄:更具GC的轮次来算,有一组线程,周期性的扫描代码里所有的对象,如果一个对象经历了一次GC而没有被回收,就认为年龄+1.
一个基本的经验规律:如果一个对象寿命比较长了,大概率还会活的更久(要被回收,早就被回收了)
例如许多东西都是短暂美好的,经过时间的洗礼,少数经典的东西才会被留下,哪些短暂的东西很短的时间就消逝了。
基于上述策略,就针对对象的年龄进行了分类,把堆里的对象分成了:新生代(年龄小的对象,GC扫描的频率较高)和老年代(年龄大的对象,GC扫描的频率较低)

刚创建出来的对象进入伊甸区
如果新对象熬过一轮GC,就通过复制算法,复制到生存区中,
生存区的对象也要经历GC的考研,每次熬过一轮GC,就通过复制算法拷贝到另一个生存区中,只要这个对象不消亡,就会在两个生存区中间来回拷贝,每一轮拷贝,每一轮GC都会少选掉一大波对象。即同一时间只用一个生存区。
如果一个对象在生存区中反复坚持了很多轮,还没事,就会进入老年代了。
如果对象来到了老年代,也不是完全的稳定,也会定期进行GC,只是频率更低了,这里采取标记整理的方式来处理老年代对象
上述规则还有个特殊情况!!!
如果对象是一个非常大的对象,则直接进入老年代!!!
解释:大对象进行复制算法开销太大,既然一个很大的对象,好不容易创造出来,看肯定不是立即就销毁的。