数据结构与算法(java):线性表(链表-单向链表)
线性表
链表
链表是一种物理存储单元上非连续、非顺序的存储结构,是一种链式存储结构。其物理结构不能直观的表示数据元素的逻辑顺序,数据元素的逻辑顺序通过链表中的指针连接次序实现,链表由一系列的结点组成,链表可以在运行时动态生成。
特点是查询慢,增删块。如图,可以很明显的看到链表增删是比较简单方便的,只要将结点的指向改变就可以进行增删操作;而之所以查找慢是因为链表没有数组那样的下标,每次从查找都是从头结点开始一个一个的一次往后找,特别费时。
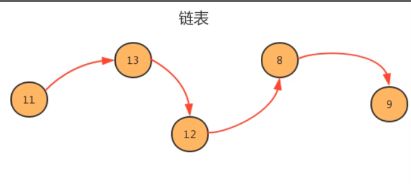
链表由结点组成
按照java中面向对象的思想,设计一个类用来描述节点这个事物,这个类叫结点类,用结点类中的属性来描述这个结点存储的元素和下一个结点。
代码演示
结点类实现
public class Node<T>{
//存储元素
public T item;
//指向的下一个结点
public Node next;
public Node(T item, Node next){
this.item = item;
this.next = next;
}
}
构建结点和生成链表
public static void main(String[] args) throws Exception{
//构建结点:此时结点之间还没有任何指向关系
Node<Integer> first = new Node<Integer>(11,null);
Node<Integer> second = new Node<Integer>(12,null);
Node<Integer> third = new Node<Integer>(13,null);
//生成链表:将前一个结点的末尾指针指向下一个结点
first.next = second;
second.next = third;
}
分类
1、单向链表
2、双向链表
单向链表
定义
单向链表是由多个结点组成,每一个结点都由一个数据域和一个指针域组成,数据域用来存储数据,指针域用来指向其后继结点。链表的头结点的数据域不存储数据,指针域指向第一个真正存储数据的结点。

一般步骤
1、定义一个链表的类
2、在链表类中定义相关属性(头结点,链表长度),以及一个结点类的内部类
3、结点类用来创建结点,里面定义两个属性来存储数据和后继结点
4、接下来就是实现各种增删查找插的方法了
5、如果要遍历的话就要将链表类实现Iterable接口,重写里面的Iterator()方法,具体看代码
代码实现
public class LinkList<T> implements Iterable {
//头结点
private Node head;
//链表长度
private int N;
//结点类
private class Node{
//存储数据
T item;
//下一个结点
Node next;
public Node(T item, Node next){
this.item = item;
this.next = next;
}
}
//--------------------------------------------------------------
//构造方法
public LinkList() {
//初始化头结点
this.head = new Node(null,null);
//初始化元素个数
this.N = 0;
}
//--------------------------------------------------------------
//清空链表
public void clear(){
head.next = null;
this.N = 0;
}
//--------------------------------------------------------------
//获取链表长度
public int length(){
return N;
}
//--------------------------------------------------------------
//判断链表是否为空
public boolean isEmpty(){
return N==0;
}
//--------------------------------------------------------------
//获取指定位置i处的元素
public T get(int i){
//通过循环,从头结点开始往后找,找i次
Node n = head.next;
for(int index = 0; index<i; index++){
n = n.next;
}
return n.item;
}
//--------------------------------------------------------------
//添加元素,默认添加到链表末尾
public void add(T t){
//找到最后一个结点
Node n = head;
while(n.next != null){
n = n.next;
//while循环结束后n就是最后一个结点
}
//创建新结点,保存元素t
Node newNode = new Node(t, null);
//让当前最后一个结点指向新结点
n.next = newNode;
//元素实际个数增加
N++;
}
//--------------------------------------------------------------
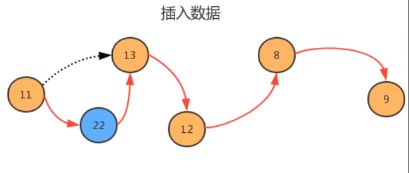
//指定位置i处插入t元素
public void insert(int i, T t){
//找到i位置的前一个结点
Node pre = head;
for(int index = 0; index<=i-1; index++){
pre = pre.next;
}
//找i位置的结点
Node curr = pre.next;
//创建新结点,并且新结点需要指向原来i位置的结点
Node newNode = new Node(t,curr);
//原来的前一个结点指向这个新结点
pre.next = newNode;
//元素个数增加
N++;
}
//--------------------------------------------------------------
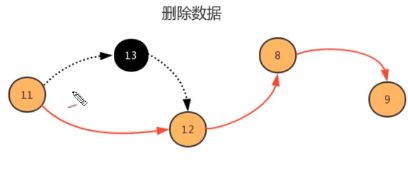
//删除指定位置处元素,且返回被删除元素
public T remove(int i){
//找到i位置的前一个结点
Node pre = head;
for(int index = 0; index<=i-1; index++){
pre = pre.next;
}
//找到i位置的结点
Node curr = pre.next;
//找到i位置的下一个结点
Node newNode = curr.next;
//将前一个结点指向后一个结点
pre.next = newNode;
//元素个数减少
N--;
return curr.item;
}
//--------------------------------------------------------------
//删除与指定元素一样的所有元素
public void remove(LinkList ll,T t){
int n = ll.search(t).size();
for(int i = 0; i<n; i++){
ll.remove(ll.indexOf(t));
}
//下面是我曾有过的错误写法:for循环条件判断语句中每次都会重新计算获取的集合长度
// for(int i = 0; i
// ll.remove(ll.indexOf(t));
// }
}
//--------------------------------------------------------------
//查找元素在链表中第一次出现的位置
public int indexOf(T t){
//从头结点开始找出每一个结点,取出item和t作比较
Node n = head;
for(int index = 0; n.next != null; index++) {
n = n.next;
if(n.item.equals(t)){
return index;
}
}
return -1;
}
//--------------------------------------------------------------
//查找元素,返回下标
public ArrayList search(T t){
ArrayList list = new ArrayList();
Node n = head;
for(int index = 0; n.next != null; index++){
n = n.next;
if(n.item.equals(t)){
list.add(index);
}
}
return list;
}
//--------------------------------------------------------------
//迭代器的重写
@Override
public Iterator iterator() {
return new LIterator();
}
private class LIterator implements Iterator{
private Node n;
public LIterator(){
this.n = head;
}
@Override
public boolean hasNext() {
return n.next != null;
}
@Override
public Object next() {
n = n.next;
return n.item;
}
}
}
实现类
public class LinkListTest {
public static void main(String[] args) {
//创建链表对象
LinkList ll = new LinkList();
//向链表添加元素
ll.add("姚明");
ll.add("hello");
ll.add(1);
ll.add("麦迪");
//遍历
System.out.println("-------这是遍历---------");
for( Object obj : ll){
System.out.println(obj);
}
//测试插入
System.out.println("-------测试插入---------");
ll.insert(1,"科比");
ll.insert(1,"科比");
ll.insert(3,"科比");
for( Object obj : ll){
System.out.println(obj);
}
//测试查找
System.out.println("-------测试查找---------");
System.out.println(ll.search("科比"));;
//测试删除(根据位置删除元素)
System.out.println("-------根据位置删除一个元素---------");
System.out.println("删除元素:" + ll.remove(1));
for( Object obj : ll){
System.out.println(obj);
}
//下面的方法也可以用来删除与指定元素一样的所有元素
// System.out.println("------删除所有指定元素---------");
// for(int i = 0; i
// ll.remove(ll.indexOf("科比"));
// }
System.out.println("------删除指定元素一样的所有元素---------");
ll.remove(ll,"科比");
for( Object obj : ll){
System.out.println(obj);
}
}
}
运行结果如下
-------这是遍历---------
姚明
hello
1
麦迪
-------测试插入---------
姚明
科比
科比
科比
hello
1
麦迪
-------测试查找---------
[1, 2, 3]
-------根据位置删除一个元素---------
删除元素:科比
姚明
科比
科比
hello
1
麦迪
------删除指定元素一样的所有元素---------
姚明
hello
1
麦迪
注意:

图一

图二
Node n = head.next和Node n = head是有区别的,前者head.next表示已经指向了下一个结点,后者head还没有指向,进入循环后才开始指向下个结点的,结合代码来看,图一找的的是i位置处的结点,图二找的是i位置处的前一个结点