k8s 相关笔记
01|初识容器
- 容器技术起源于 Docker,它目前有两个产品:Docker Desktop 和 Docker Engine,我们的课程里推荐使用免费的 Docker Engine,它可以在 Ubuntu 系统里直接用 apt 命令安装。
- Docker Engine 需要使用命令行操作,主命令是 docker,后面再接各种子命令。
- 查看 Docker 的基本信息的命令是 docker version 和 docker info ,其他常用的命令有 docker ps、docker pull、docker images、docker run。
- Docker Engine 是典型的客户端 / 服务器(C/S)架构,命令行工具 Docker 直接面对用户,后面的 Docker daemon 和 Registry 协作完成各种功能。
02|被隔离的进程:一起来看看容器的本质
- 容器技术是动态的容器、静态的镜像和远端的仓库这三者的组合
- 容器就是操作系统里一个特殊的“沙盒”环境,里面运行的进程只能看到受限的信息,与外部系统实现了隔离。
为什么要隔离
使用容器技术,我们就可以让应用程序运行在一个有严密防护的“沙盒”, 容器隔离的目的是为了系统安全,限制了进程能够访问的各种资源。
容器技术的另一个本领就是为应用程序加上资源隔离,在系统里切分出一部分资源,让它只能使用指定的配额
与虚拟机的区别是什么

相比虚拟机技术,容器更加轻巧、更加高效,消耗的系统资源非常少,在云计算时代极具优势。
隔离是怎么实现的
容器的基本实现技术是 Linux 系统里的 namespace、cgroup、chroot。
03|容器化的应用:会了这些你就是Docker高手
容器就是被隔离的进程。
什么是容器化的应用

它里面不仅有基本的可执行文件,还有应用运行时的整个系统环境。这就让镜像具有了非常好的跨平台便携性和兼容性
所谓的“容器化的应用”,或者“应用的容器化”,就是指应用程序不再直接和操作系统打交道,而是封装成镜像,再交给容器环境去运行。
常用的镜像操作有哪些
镜像的完整名字由两个部分组成,名字和标签,中间用 : 连接起来。
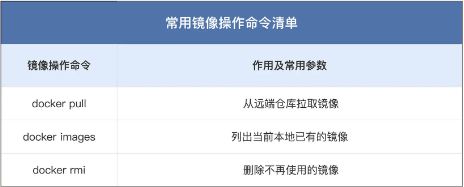
常用的容器操作有哪些

镜像是容器的静态形式,它打包了应用程序的所有运行依赖项,方便保存和传输。使用容器技术运行镜像,就形成了动态的容器,由于镜像只读不可修改,所以应用程序的运行环境总是一致的。
而容器化的应用就是指以镜像的形式打包应用程序,然后在容器环境里从镜像启动容器。
04|创建容器镜像:如何编写正确、高效的Dockerfile
镜像的内部机制是什么
容器镜像内部并不是一个平坦的结构,而是由许多的镜像层组成的,每层都是只读不可修改的一组文件,相同的层可以在镜像之间共享,然后多个层像搭积木一样堆叠起来,再使用一种叫“Union FS 联合文件系统”的技术把它们合并在一起,就形成了容器最终看到的文件系统

可以用命令 docker inspect 来查看镜像的分层信息,比如 nginx:alpine 镜像:
docker inspect nginx:alpine

通过这张截图就可以看到,nginx:alpine 镜像里一共有 6 个 Layer。
Docker 会检查是否有重复的层,如果本地已经存在就不会重复下载,如果层被其他镜像共享就不会删除,这样就可以节约磁盘和网络成本。
Dockerfile 是什么
比起容器、镜像来说,Dockerfile 非常普通,它就是一个纯文本,里面记录了一系列的构建指令,比如选择基础镜像、拷贝文件、运行脚本等等,每个指令都会生成一个 Layer,而 Docker 顺序执行这个文件里的所有步骤,最后就会创建出一个新的镜像出来。
一个最简单的 Dockerfile 实例
# Dockerfile.busybox
FROM busybox # 选择基础镜像
CMD echo "hello world" # 启动容器时默认运行的命令#
--------
# 开始构建镜像
docker build -f Dockerfile.busybox .
Sending build context to Docker daemon 7.68kB
Step 1/2 : FROM busybox
---> d38589532d97
Step 2/2 : CMD echo "hello world"
---> Running in c5a762edd1c8
Removing intermediate container c5a762edd1c8
---> b61882f42db7
Successfully built b61882f42db7
怎样编写正确、高效的 Dockerfile
我们在本机上开发测试时会产生一些源码、配置等文件,需要打包进镜像里,这时可以使用 COPY 命令,它的用法和 Linux 的 cp 差不多,不过拷贝的源文件必须是“构建上下文”路径里的,不能随意指定文件。也就是说,如果要从本机向镜像拷贝文件,就必须把这些文件放到一个专门的目录,然后在 docker build 里指定“构建上下文”到这个目录才行。
COPY ./a.txt /tmp/a.txt # 把构建上下文里的a.txt拷贝到镜像的/tmp目录
COPY /etc/hosts /tmp # 错误!不能使用构建上下文之外的文件
接下来要说的就是 Dockerfile 里最重要的一个指令 RUN ,它可以执行任意的 Shell 命令,比如更新系统、安装应用、下载文件、创建目录、编译程序等等,实现任意的镜像构建步骤,非常灵活。
RUN 通常会是 Dockerfile 里最复杂的指令,会包含很多的 Shell 命令,但 Dockerfile 里一条指令只能是一行,所以有的 RUN 指令会在每行的末尾使用续行符 \,命令之间也会用 && 来连接,这样保证在逻辑上是一行,就像下面这样:
RUN apt-get update \
&& apt-get install -y \
build-essential \
curl \
make \
unzip \
&& cd /tmp \
&& curl -fSL xxx.tar.gz -o xxx.tar.gz\
&& tar xzf xxx.tar.gz \
&& cd xxx \
&& ./config \
&& make \
&& make clean
有的时候在 Dockerfile 里写这种超长的 RUN 指令很不美观,而且一旦写错了,每次调试都要重新构建也很麻烦,所以你可以采用一种变通的技巧:把这些 Shell 命令集中到一个脚本文件里,用 COPY 命令拷贝进去再用 RUN 来执行:
COPY setup.sh /tmp/ # 拷贝脚本到/tmp目录
RUN cd /tmp && chmod +x setup.sh \ # 添加执行权限
&& ./setup.sh && rm setup.sh # 运行脚本然后再删除
RUN 指令实际上就是 Shell 编程,如果你对它有所了解,就应该知道它有变量的概念,可以实现参数化运行,这在 Dockerfile 里也可以做到,需要使用两个指令 ARG 和 ENV。
它们区别在于 ARG 创建的变量只在镜像构建过程中可见,容器运行时不可见,而 ENV 创建的变量不仅能够在构建镜像的过程中使用,在容器运行时也能够以环境变量的形式被应用程序使用。
下面是一个简单的例子,使用 ARG 定义了基础镜像的名字(可以用在“FROM”指令里),使用 ENV 定义了两个环境变量:
ARG IMAGE_BASE="node"
ARG IMAGE_TAG="alpine"
ENV PATH=$PATH:/tmp
ENV DEBUG=OFF
还有一个重要的指令是 EXPOSE,它用来声明容器对外服务的端口号,对现在基于 Node.js、Tomcat、Nginx、Go 等开发的微服务系统来说非常有用:
EXPOSE 443 # 默认是tcp协议
EXPOSE 53/udp # 可以指定udp协议
特别强调一下,因为每个指令都会生成一个镜像层,所以 Dockerfile 里最好不要滥用指令,尽量精简合并,否则太多的层会导致镜像臃肿不堪。
docker build 是怎么工作的
因为命令行“docker”是一个简单的客户端,真正的镜像构建工作是由服务器端的“Docker daemon”来完成的,所以“docker”客户端就只能把“构建上下文”目录打包上传(显示信息 Sending build context to Docker daemon ),这样服务器才能够获取本地的这些文件。
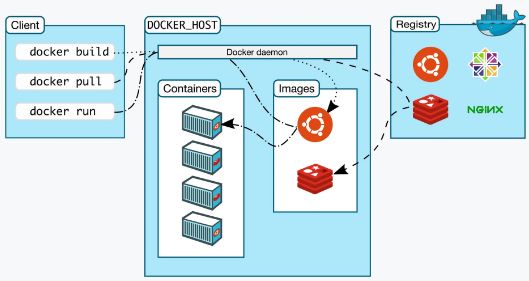
明白了这一点,你就会知道,“构建上下文”其实与 Dockerfile 并没有直接的关系,它其实指定了要打包进镜像的一些依赖文件。而 COPY 命令也只能使用基于“构建上下文”的相对路径,因为“Docker daemon”看不到本地环境,只能看到打包上传的那些文件。
但这个机制也会导致一些麻烦,如果目录里有的文件(例如 readme/.git/.svn 等)不需要拷贝进镜像,docker 也会一股脑地打包上传,效率很低。
为了避免这种问题,你可以在“构建上下文”目录里再建立一个 .dockerignore 文件,语法与 .gitignore 类似,排除那些不需要的文件。
下面是一个简单的示例,表示不打包上传后缀是“swp”“sh”的文件:
# docker ignore
*.swp
*.sh
容器镜像是由多个只读的 Layer 构成的,同一个 Layer 可以被不同的镜像共享
总结:
- 创建镜像需要编写 Dockerfile,写清楚创建镜像的步骤,每个指令都会生成一个 Layer。
- Dockerfile 里,第一个指令必须是 FROM,用来选择基础镜像,常用的有 Alpine、Ubuntu 等。其他常用的指令有:COPY、RUN、EXPOSE,分别是拷贝文件,运行 Shell 命令,声明服务端口号。
- docker build 需要用 -f 来指定 Dockerfile,如果不指定就使用当前目录下名字是“Dockerfile”的文件。
- docker build 需要指定“构建上下文”,其中的文件会打包上传到 Docker daemon,所以尽量不要在“构建上下文”中存放多余的文件。
- 创建镜像的时候应当尽量使用 -t 参数,为镜像起一个有意义的名字,方便管理。
- 可以使用 docker history 回放完整的镜像构建过程, 可以用来排错。
05|镜像仓库:该怎样用好Docker Hub这个宝藏
什么是镜像仓库(Registry)
镜像仓库,术语叫 Registry,直译就是“注册中心”,意思是所有镜像的 Repository 都在这里登记保管,就像是一个巨大的档案馆。
什么是 Docker Hub
在使用 docker pull 获取镜像的时候,我们并没有明确地指定镜像仓库。在这种情况下,Docker 就会使用一个默认的镜像仓库,也就是大名鼎鼎的“Docker Hub”(https://hub.docker.com/); Docker Hub 是 Docker 公司搭建的官方 Registry 服务, Docker Hub 里面不仅有 Docker 自己打包的镜像,而且还对公众免费开放,任何人都可以上传自己的作品。
如何在 Docker Hub 上挑选镜像
在 Docker Hub 上有官方镜像、认证镜像和非官方镜像的区别。
官方镜像是指 Docker 公司官方提供的高质量镜像(https://github.com/docker-library/official-images)
第二类是认证镜像,标记是“Verified publisher”,也就是认证发行商,比如 Bitnami、Rancher、Ubuntu 等。它们都是颇具规模的大公司,具有不逊于 Docker 公司的实力,所以就在 Docker Hub 上开了个认证账号,发布自己打包的镜像
主要还是看下载量、星数、还有更新历史,简单来说就是“好评”数量。
Docker Hub 上镜像命名的规则是什么
镜像标签的格式是应用的版本号加上操作系统。
有的标签还会加上 slim、fat,来进一步表示这个镜像的内容是经过精简的,还是包含了较多的辅助工具。通常 slim 镜像会比较小,运行效率高,而 fat 镜像会比较大,适合用来开发调试。
nginx:1.21.6-alpine,表示版本号是 1.21.6,基础镜像是最新的 Alpine。
redis:7.0-rc-bullseye,表示版本号是 7.0 候选版,基础镜像是 Debian 11。
node:17-buster-slim,表示版本号是 17,基础镜像是精简的 Debian 10。
该怎么上传自己的镜像
第一步,你需要在 Docker Hub 上注册一个用户
第二步,你需要在本机上使用 docker login 命令,用刚才注册的用户名和密码认证身份登录,像这里就用了我的用户名“chronolaw”:
第三步很关键,需要使用 docker tag 命令,给镜像改成带用户名的完整名字,表示镜像是属于这个用户的。或者简单一点,直接用 docker build -t 在创建镜像的时候就起好名字。
docker tag ngx-app chronolaw/ngx-app:1.0
第四步,用 docker push 把这个镜像推上去,我们的镜像发布工作就大功告成了
docker push chronolaw/ngx-app:1.0
离线环境该怎么办
最佳的方法就是在内网环境里仿造 Docker Hub,创建一个自己的私有 Registry 服务,由它来管理我们的镜像,就像我们自己搭建 GitLab 做版本管理一样。
修改镜像仓库配置, 更换下载仓库
/etc/docker/daemon.json
Docker 提供了 save 和 load 这两个镜像归档命令,可以把镜像导出成压缩包,或者从压缩包导入 Docker,而压缩包是非常容易保管和传输的,可以联机拷贝,FTP 共享,甚至存在 U 盘上随身携带。
docker save ngx-app:latest -o ngx.tardocker load -i ngx.tar
06|打破次元壁:容器该如何与外界互联互通
如何拷贝容器内的数据
# 将当前目录下“a.txt”文件拷贝至 062 容器的 /tmp 中
docker cp a.txt 062:/tmp
# 将 062 容器的 /tmp 下“a.txt”文件拷贝至当前目录下并改名为 b.
docker cp 062:/tmp/a.txt ./b.txt
如何共享主机上的文件
# 以 Redis 为例,启动容器,使用 -v 参数把本机的“/tmp”目录挂载到容器里的“/tmp”目录,也就是说让容器共享宿主机的“/tmp”目录:# 宿主机路径: 容器内路径
docker run -d --rm -v /tmp:/tmp redis
如何实现网络互通
Docker 提供了三种网络模式,分别是 null、host 和 bridge
null 是最简单的模式,也就是没有网络,但允许其他的网络插件来自定义网络连接,这里就不多做介绍了。
host 的意思是直接使用宿主机网络,相当于去掉了容器的网络隔离(其他隔离依然保留),所有的容器会共享宿主机的 IP 地址和网卡。这种模式没有中间层,自然通信效率高,但缺少了隔离,运行太多的容器也容易导致端口冲突。
host 模式需要在 docker run 时使用 --net=host 参数,下面我就用这个参数启动 Nginx:
docker run -d --rm --net=host nginx:alpine
第三种 bridge,也就是桥接模式,它有点类似现实世界里的交换机、路由器,只不过是由软件虚拟出来的,容器和宿主机再通过虚拟网卡接入这个网桥(图中的 docker0),那么它们之间也就可以正常的收发网络数据包了。不过和 host 模式相比,bridge 模式多了虚拟网桥和网卡,通信效率会低一些。

没有特殊指定就会使用 bridge 模式:
docker run -d --rm nginx:alpine # 默认使用桥接模式
docker run -d --rm redis # 默认使用桥接模式
可以用 docker inspect 直接查看容器的 ip 地址
docker inspect xxx |grep IPAddress
如何分配服务端口号
端口号映射需要使用 bridge 模式,并且在 docker run 启动容器时使用 -p 参数,形式和共享目录的 -v 参数很类似,用: 分隔本机端口:容器端口。比如,如果要启动两个 Nginx 容器,分别跑在 80 和 8080 端口上
docker run -d -p 80:80 --rm nginx:alpinedocker run -d -p 8080:80 --rm nginx:alpine
使用 docker ps 命令能够在“PORTS”栏里更直观地看到端口的映射情况
07|实战演练:玩转Docker
容器技术要点回顾
- 容器技术是后端应用领域的一项重大创新,它彻底变革了应用的开发、交付与部署方式,是“云原生”的根本
- 容器基于 Linux 底层的 namespace、cgroup、chroot 等功能,虽然它们很早就出现了,但直到 Docker“横空出世”,把它们整合在一起,容器才真正走近了大众的视野,逐渐为广大开发者所熟知
- 容器技术中有三个核心概念:容器(Container)、镜像(Image),以及镜像仓库(Registry)

- 从本质上来说,容器属于虚拟化技术的一种,和虚拟机(Virtual Machine)很类似,都能够分拆系统资源,隔离应用进程,但容器更加轻量级,运行效率更高,比虚拟机更适合云计算的需求。
- 镜像是容器的静态形式,它把应用程序连同依赖的操作系统、配置文件、环境变量等等都打包到了一起,因而能够在任何系统上运行,免除了很多部署运维和平台迁移的麻烦。
- 镜像内部由多个层(Layer)组成,每一层都是一组文件,多个层会使用 Union FS 技术合并成一个文件系统供容器使用。这种细粒度结构的好处是相同的层可以共享、复用,节约磁盘存储和网络传输的成本,也让构建镜像的工作变得更加容易
- 为了方便管理镜像,就出现了镜像仓库,它集中存放各种容器化的应用,用户可以任意上传下载,是分发镜像的最佳方式
- 目前最知名的公开镜像仓库是 Docker Hub,其他的还有 quay.io、gcr.io,我们可以在这些网站上找到许多高质量镜像,集成到我们自己的应用系统中。
- 容器技术有很多具体的实现,Docker 是最初也是最流行的容器技术,它的主要形态是运行在 Linux 上的“Docker Engine”。我们日常使用的 docker 命令其实只是一个前端工具,它必须与后台服务“Docker daemon”通信才能实现各种功能。
- 操作容器的常用命令有 docker ps、docker run、docker exec、docker stop 等;操作镜像的常用命令有 docker images、docker rmi、docker build、docker tag 等;操作镜像仓库的常用命令有 docker pull、docker push 等。
搭建私有镜像仓库
以简单的 Docker Registry 为例
# 使用 docker pull 命令拉取镜像
docker pull registry
# 做一个端口映射,对外暴露端口,这样 Docker Registry 才能提供服务, 它的容器内端口是 5000,简单起见,我们在外面也使用同样的 5000 端口
docker run -d -p 5000:5000 registry
# 检查状态
docker ps
# 使用命令上传镜像
# 先将镜像 tag 一个标签
docker tag nginx:alpine 127.0.0.1:5000/nginx:alpine
# 将镜像上传至 registry 库
docker push 127.0.0.1:5000/nginx:alpine
# Docker Registry 虽然没有图形界面,但提供了 RESTful API,也可以发送 HTTP 请求来查看仓库里的镜像,具体的端点信息可以参考官方文档
curl 127.1:5000/v2/_catalogcurl 127.1:5000/v2/nginx/tags/list

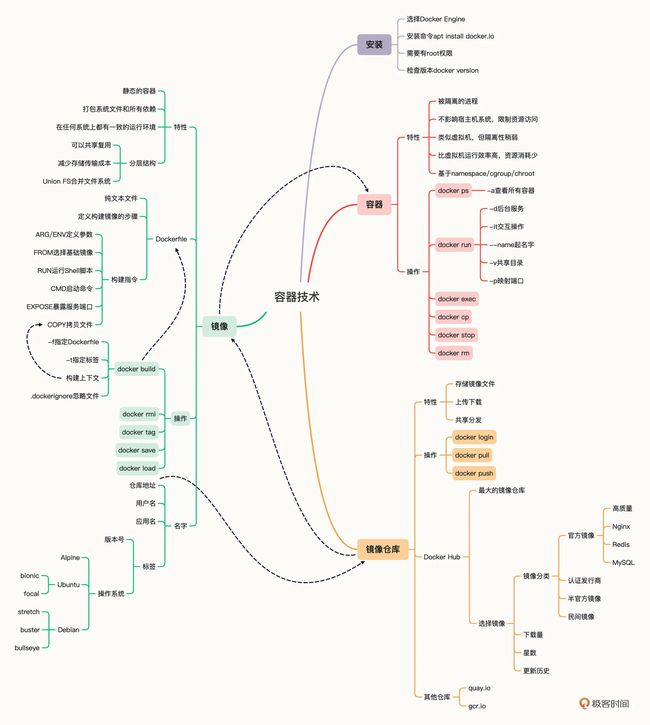
容器思维导图
09|走近云原生:如何在本机搭建小巧完备的Kubernetes环境
什么是容器编排
当我们熟练地掌握了容器技术,信心满满地要在服务器集群里大规模实施的时候,却会发现容器技术的创新只是解决了运维部署工作中一个很小的问题。现实生产环境的复杂程度实在是太高了,除了最基本的安装,还会有各式各样的需求,比如服务发现、负载均衡、状态监控、健康检查、扩容缩容、应用迁移、高可用等等。
容器技术开启了云原生时代,但它也只走出了一小步,再继续前进就无能为力了,因为这已经不再是隔离一两个进程的普通问题,而是要隔离数不清的进程,还有它们之间互相通信、互相协作的超级问题,困难程度可以说是指数级别的上升。
这些容器之上的管理、调度工作,就是这些年最流行的词汇:“容器编排”
什么是 Kubernetes
简单来说,Kubernetes 就是一个生产级别的容器编排平台和集群管理系统,不仅能够创建、调度容器,还能够监控、管理服务器,它凝聚了 Google 等大公司和开源社区的集体智慧,从而让中小型公司也可以具备轻松运维海量计算节点——也就是“云计算”的能力。
什么是 minikube
在官网(https://kubernetes.io/zh/docs/tasks/tools/)上推荐的有两个:kind 和 minikube,它们都可以在本机上运行完整的 Kubernetes 环境。
minikube 最大特点就是“小而美”,可执行文件仅有不到 100MB,运行镜像也不过 1GB,但就在这么小的空间里却集成了 Kubernetes 的绝大多数功能特性,不仅有核心的容器编排功能,还有丰富的插件,例如 Dashboard、GPU、Ingress、Istio、Kong、Registry 等等,综合来看非常完善。
如何搭建 minikube 环境
minikube 支持 Mac、Windows、Linux 这三种主流平台,可以在它的官网(https://minikube.sigs.k8s.io)找到详细的安装说明
minikube 的官网提供了各种系统的安装命令,通常就是下载、拷贝这两步,不过你需要注意一下本机电脑的硬件架构,Intel 芯片要选择带“amd64”后缀,Apple M1 芯片要选择“arm64”后缀,选错了就会因为 CPU 指令集不同而无法运行:
# Intel x86_64
curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
# Apple arm64
curl -Lo minikube https://storage.googleapis.com/minikube/releases/latest/minikube-linux-arm64
sudo install minikube /usr/local/bin/
minikube 只能够搭建 Kubernetes 环境,要操作 Kubernetes,还需要另一个专门的客户端工具“kubectl”
kubectl 是一个与 Kubernetes、minikube 彼此独立的项目,所以不包含在 minikube 里,但 minikube 提供了安装它的简化方式,你只需执行下面的这条命令:
minikube kubectl
minikube 环境示意图

实际验证 minikube 环境
使用命令 minikube start 会从 Docker Hub 上拉取镜像,以当前最新版本的 Kubernetes 启动集群。不过为了保证实验环境的一致性,我们可以在后面再加上一个参数 --kubernetes-version,明确指定要使用 Kubernetes 版本
minikube start --kubernetes-version=v1.23.3

# 查看集群状态
minikube statusminikube node list

从截图里可以看到,Kubernetes 集群里现在只有一个节点,名字就叫“minikube”,类型是“Control Plane”,里面有 host、kubelet、apiserver 三个服务,IP 地址是 192.168.49.2
你还可以用命令 minikube ssh 登录到这个节点上,虽然它是虚拟的,但用起来和实机也没什么区别

# 测试容器编排
kubectl version
在 Kubernetes 里运行一个 Nginx 应用,命令与 Docker 一样,也是 run,不过形式上有点区别,需要用 --image 指定镜像
kubectl run ngx --image=nginx:alpine
小结
-
什么是云原生呢?
所谓的“云”,现在就指的是 Kubernetes,那么“云原生”的意思就是应用的开发、部署、运维等一系列工作都要向 Kubernetes 看齐,使用容器、微服务、声明式 API 等技术,保证应用的整个生命周期都能够在 Kubernetes 环境里顺利实施,不需要附加额外的条件。
换句话说,“云原生”就是 Kubernetes 里的“原住民”,而不是从其他环境迁过来的“移民”。
-
操作 Kubernetes 需要使用命令行工具 kubectl,只有通过它才能与 Kubernetes 集群交互。
-
kubectl 的用法与 docker 类似,也可以拉取镜像运行,但操作的不是简单的容器,而是 Pod。
-
Kubernetes 的官网(https://kubernetes.io/zh/),里面有非常详细的文档,包括概念解释、入门教程、参考手册等等,最难得的是它有全中文版本,我们阅读起来完全不会有语言障碍。
10|自动化的运维管理:探究Kubernetes工作机制的奥秘
云计算时代的操作系统
Kubernetes 是一个生产级别的容器编排平台和集群管理系统,能够创建、调度容器,监控、管理服务器。
Linux 的用户通常是两类人:Dev 和 Ops,而在 Kubernetes 里则只有一类人:DevOps。
Kubernetes 的基本架构

控制面的节点在 Kubernetes 里叫做 Master Node,一般简称为 Master,它是整个集群里最重要的部分,可以说是 Kubernetes 的大脑和心脏。
数据面的节点叫做 Worker Node,一般就简称为 Worker 或者 Node,相当于 Kubernetes 的手和脚,在 Master 的指挥下干活。
# 查看 k8s 节点状态
kubectl get node

可以看到当前的 minikube 集群里只有一个 Master,那 Node 怎么不见了?
这是因为 Master 和 Node 的划分不是绝对的。当集群的规模较小,工作负载较少的时候,Master 也可以承担 Node 的工作,就像我们搭建的 minikube 环境,它就只有一个节点,这个节点既是 Master 又是 Node。
节点内部的结构
Kubernetes 的节点内部也具有复杂的结构,是由很多的模块构成的,这些模块又可以分成组件(Component)和插件(Addon)两类。
组件实现了 Kubernetes 的核心功能特性,没有这些组件 Kubernetes 就无法启动,而插件则是 Kubernetes 的一些附加功能,属于“锦上添花”,不安装也不会影响 Kubernetes 的正常运行。
Master 里的组件有哪些
Master 里有 4 个组件,分别是 apiserver、etcd、scheduler、controller-manager。

- apiserver 是 Master 节点——同时也是整个 Kubernetes 系统的唯一入口,它对外公开了一系列的 RESTful API,并且加上了验证、授权等功能,所有其他组件都只能和它直接通信,可以说是 Kubernetes 里的联络员。
- etcd 是一个高可用的分布式 Key-Value 数据库,用来持久化存储系统里的各种资源对象和状态,相当于 Kubernetes 里的配置管理员。注意它只与 apiserver 有直接联系,也就是说任何其他组件想要读写 etcd 里的数据都必须经过 apiserver。
- scheduler 负责容器的编排工作,检查节点的资源状态,把 Pod 调度到最适合的节点上运行,相当于部署人员。因为节点状态和 Pod 信息都存储在 etcd 里,所以 scheduler 必须通过 apiserver 才能获得。
- controller-manager 负责维护容器和节点等资源的状态,实现故障检测、服务迁移、应用伸缩等功能,相当于监控运维人员。同样地,它也必须通过 apiserver 获得存储在 etcd 里的信息,才能够实现对资源的各种操作。
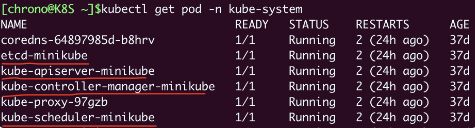
这 4 个组件也都被容器化了,运行在集群的 Pod 里,我们可以用 kubectl 来查看它们的状态,使用命令:
# 检查“kube-system”名字空间里的 Pod
kubectl get pod -n kube-system
Node 里的组件有哪些
Node 里的 3 个组件了,分别是 kubelet、kube-proxy、container-runtime
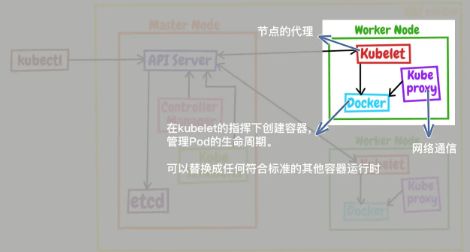
- kubelet 是 Node 的代理,负责管理 Node 相关的绝大部分操作,Node 上只有它能够与 apiserver 通信,实现状态报告、命令下发、启停容器等功能,相当于是 Node 上的一个“小管家”。
- kube-proxy 的作用有点特别,它是 Node 的网络代理,只负责管理容器的网络通信,简单来说就是为 Pod 转发 TCP/UDP 数据包,相当于是专职的“小邮差”。
- container-runtime 我们就比较熟悉了,它是容器和镜像的实际使用者,在 kubelet 的指挥下创建容器,管理 Pod 的生命周期,是真正干活的“苦力”(可以是 docker, 完全可以替换成任何符合标准的其他容器运行时)。
这 3 个组件中只有 kube-proxy 被容器化了,而 kubelet 因为必须要管理整个节点,容器化会限制它的能力,所以它必须在 container-runtime 之外运行。
使用 minikube ssh 命令登录到节点后,可以用 docker ps 看到 kube-proxy:
minikube sshdocker ps |grep kube-proxy
而 kubelet 用 docker ps 是找不到的,需要用操作系统的 ps 命令:
ps -ef|grep kubelet
把 Node 里的组件和 Master 里的组件放在一起来看,就能够明白 Kubernetes 的大致工作流程了:
- 每个 Node 上的 kubelet 会定期向 apiserver 上报节点状态,apiserver 再存到 etcd 里。
- 每个 Node 上的 kube-proxy 实现了 TCP/UDP 反向代理,让容器对外提供稳定的服务。
- scheduler 通过 apiserver 得到当前的节点状态,调度 Pod,然后 apiserver 下发命令给某个 Node 的 kubelet,kubelet 调用 container-runtime 启动容器。
- controller-manager 也通过 apiserver 得到实时的节点状态,监控可能的异常情况,再使用相应的手段去调节恢复。

插件(Addons)有哪些
# 查看插件列表
minikube addons list
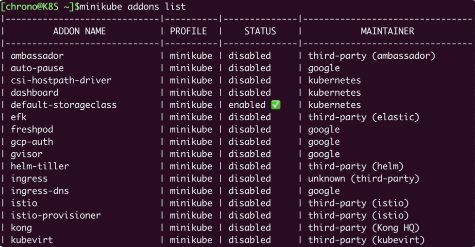
比较重要的有两个:DNS 和 Dashboard
DNS 你应该比较熟悉吧,它在 Kubernetes 集群里实现了域名解析服务,能够让我们以域名而不是 IP 地址的方式来互相通信,是服务发现和负载均衡的基础。由于它对微服务、服务网格等架构至关重要,所以基本上是 Kubernetes 的必备插件。
Dashboard 就是仪表盘,为 Kubernetes 提供了一个图形化的操作界面,非常直观友好,虽然大多数 Kubernetes 工作都是使用命令行 kubectl,但有的时候在 Dashboard 上查看信息也是挺方便的。
你只要在 minikube 环境里执行一条简单的命令,就可以自动用浏览器打开 Dashboard 页面,而且还支持中文:
minikube dashboard

11|YAML:Kubernetes世界里的通用语
声明式与命令式是怎么回事
Kubernetes 使用的 YAML 语言有一个非常关键的特性,叫“声明式”(Declarative),对应的有另外一个词:“命令式”(Imperative)。
命令式理解: 假设你要打车去高铁站,但司机不熟悉路况,你就只好不厌其烦地告诉他该走哪条路、在哪个路口转向、在哪里进出主路、停哪个站口。虽然最后到达了目的地,但这一路上也费了很多口舌,发出了无数的“命令”。很显然,这段路程就属于“命令式”。
声明式理解: 现在我们来换一种方式,同样是去高铁站,但司机经验丰富,他知道哪里有拥堵、哪条路的红绿灯多、哪段路有临时管控、哪里可以抄小道,此时你再多嘴无疑会干扰他的正常驾驶,所以,你只要给他一个“声明”:我要去高铁站,接下来就可以舒舒服服地躺在后座上休息,顺利到达目的地了。
我们需要使用专门的 YAML 语言来给 kubernetes 发出声明式
什么是 YAML
YAML 是 JSON 的超集,支持整数、浮点数、布尔、字符串、数组和对象等数据类型。也就是说,任何合法的 JSON 文档也都是 YAML 文档,如果你了解 JSON,那么学习 YAML 会容易很多。
- 使用空白与缩进表示层次(有点类似 Python),可以不使用花括号和方括号。
- 可以使用 # 书写注释,比起 JSON 是很大的改进。
- 对象(字典)的格式与 JSON 基本相同,但 Key 不需要使用双引号。
- 数组(列表)是使用 - 开头的清单形式(有点类似 MarkDown)。
- 表示对象的 : 和表示数组的 - 后面都必须要有空格。
- 可以使用 — 在一个文件里分隔多个 YAML 对象。
# YAML数组(列表)
OS:
- linux
- macOS
- Windows
# 对应的 json
{
"OS": ["linux", "macOS", "Windows"]
}
----
# YAML对象(字典)
Kubernetes:
master: 1
worker: 3
# 对应的 json
{
"Kubernetes": {
"master": 1,
"worker": 3
}
}
----
# 复杂的例子,组合数组和对象
Kubernetes:
master:
- apiserver: running
- etcd: running
node:
- kubelet: running
- kube-proxy: down
- container-runtime: [docker, containerd, cri-o]

什么是 API 对象
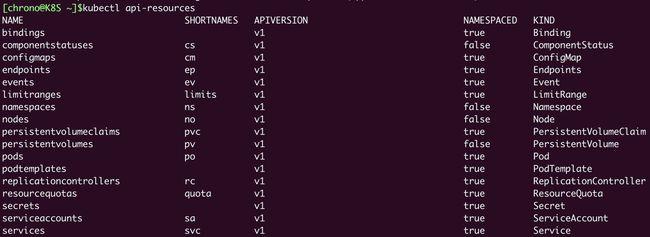
作为一个集群操作系统,Kubernetes 归纳总结了 Google 多年的经验,在理论层面抽象出了很多个概念,用来描述系统的管理运维工作,这些概念就叫做“API 对象”。
# 查看当前 Kubernetes 版本支持的所有对象
kubectl api-resources
# 显示出详细的命令执行过程,清楚地看到发出的 HTTP 请求
kubectl get pod --v=9

从截图里可以看到,kubectl 客户端等价于调用了 curl,向 8443 端口发送了 HTTP GET 请求,URL 是 /api/v1/namespaces/default/pods。
如何描述 API 对象
以 nginx yaml 为例
apiVersion: v1
kind: Pod
metadata:
name: ngx-pod
labels:
env: demo
owner: chrono
spec:
containers:
- image: nginx:alpine
name: ngx
ports:
- containerPort: 80
“header”包含的是 API 对象的基本信息,有三个字段:apiVersion、kind、metadata。
- apiVersion 表示操作这种资源的 API 版本号,由于 Kubernetes 的迭代速度很快,不同的版本创建的对象会有差异,为了区分这些版本就需要使用 apiVersion 这个字段,比如 v1、v1alpha1、v1beta1 等等。
- kind 表示资源对象的类型,这个应该很好理解,比如 Pod、Node、Job、Service 等等。
- metadata 这个字段顾名思义,表示的是资源的一些“元信息”,也就是用来标记对象,方便 Kubernetes 管理的一些信息。
apiVersion、kind、metadata 都被 kubectl 用于生成 HTTP 请求发给 apiserver,你可以用 --v=9 参数在请求的 URL 里看到它们,比如:
https://192.168.49.2:8443/api/v1/namespaces/default/pods/ngx-pod
和 HTTP 协议一样,“header”里的 apiVersion、kind、metadata 这三个字段是任何对象都必须有的,而“body”部分则会与对象特定相关,每种对象会有不同的规格定义,在 YAML 里就表现为 spec 字段(即 specification),表示我们对对象的“期望状态”(desired status)。
还是来看这个 Pod,它的 spec 里就是一个 containers 数组,里面的每个元素又是一个对象,指定了名字、镜像、端口等信息:
spec:
containers:
- image: nginx:alpine
name: ngx
ports:
- containerPort: 80
现在把这些字段综合起来,我们就能够看出,这份 YAML 文档完整地描述了一个类型是 Pod 的 API 对象,要求使用 v1 版本的 API 接口去管理,其他更具体的名称、标签、状态等细节都记录在了 metadata 和 spec 字段等里。
# 创建
kubectl apply -f ngx-pod.yml
# 删除
kubectl delete -f ngx-pod.yml
如何编写 YAML
官方文档 (https://kubernetes.io/docs/reference/kubernetes-api/)
第一个技巧其实前面已经说过了,就是 kubectl api-resources 命令,它会显示出资源对象相应的 API 版本和类型,比如 Pod 的版本是“v1”,Ingress 的版本是“networking.k8s.io/v1”,照着它写绝对不会错。
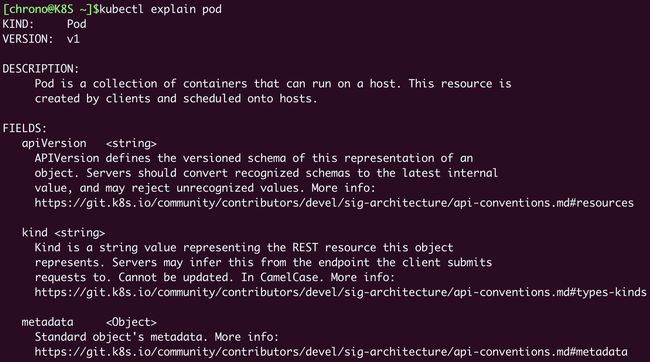
第二个技巧,是命令 kubectl explain,它相当于是 Kubernetes 自带的 API 文档,会给出对象字段的详细说明,这样我们就不必去网上查找了。比如想要看 Pod 里的字段该怎么写,就可以这样:
kubectl explain pod
kubectl explain pod.metadata
kubectl explain pod.spec
kubectl explain pod.spec.containers
第三个技巧就是 kubectl 的两个特殊参数 –dry-run=client 和 -o yaml,前者是空运行,后者是生成 YAML 格式,结合起来使用就会让 kubectl 不会有实际的创建动作,而只生成 YAML 文件。
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: ngx
name: ngx
spec:
containers:
- image: nginx:alpine
name: ngx
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
小结
- “声明式”和“命令式”的区别
- YAML 语言的语法
- 如何用 YAML 来描述 API 对象
12|Pod:如何理解这个Kubernetes里最核心的概念?
为什么要有 Pod
为了解决这样多应用联合运行的问题,同时还要不破坏容器的隔离,就需要在容器外面再建立一个“收纳舱”,让多个容器既保持相对独立,又能够小范围共享网络、存储等资源,而且永远是“绑在一起”的状态。
所以,Pod 的概念也就呼之欲出了,容器正是“豆荚”里那些小小的“豌豆”,你可以在 Pod 的 YAML 里看到,“spec.containers”字段其实是一个数组,里面允许定义多个容器。
为什么 Pod 是 Kubernetes 的核心对象
因为 Pod 是对容器的“打包”,里面的容器是一个整体,总是能够一起调度、一起运行,绝不会出现分离的情况,而且 Pod 属于 Kubernetes,可以在不触碰下层容器的情况下任意定制修改。
Kubernetes 让 Pod 去编排处理容器,然后把 Pod 作为应用调度部署的最小单位,Pod 也因此成为了 Kubernetes 世界里的“原子”(当然这个“原子”内部是有结构的,不是铁板一块),基于 Pod 就可以构建出更多更复杂的业务形态了


所有的 Kubernetes 资源都直接或者间接地依附在 Pod 之上,所有的 Kubernetes 功能都必须通过 Pod 来实现,所以 Pod 理所当然地成为了 Kubernetes 的核心对象。
如何使用 YAML 描述 Pod
Pod 也是 API 对象,所以它也必然具有 apiVersion、kind、metadata、spec 这四个基本组成部分。
“apiVersion”和“kind”这两个字段很简单,对于 Pod 来说分别是固定的值 v1 和 Pod,而一般来说,“metadata”里应该有 name 和 labels 这两个字段。
# 一个简单的 Pod,名字是“busy-pod”,再附加上一些标签:
apiVersion: v1
kind: Pod
metadata:
name: busy-pod
labels:
owner: chrono
env: demo
region: north
tier: back
containers”是一个数组,里面的每一个元素又是一个 container 对象,也就是容器。
和 Pod 一样,container 对象也必须要有一个 name 表示名字,然后当然还要有一个 image 字段来说明它使用的镜像,这两个字段是必须要有的,否则 Kubernetes 会报告数据验证错误。
ports:列出容器对外暴露的端口,和 Docker 的 -p 参数有点像。
imagePullPolicy:指定镜像的拉取策略,可以是 Always/Never/IfNotPresent,一般默认是 IfNotPresent,也就是说只有本地不存在才会远程拉取镜像,可以减少网络消耗。
env:定义 Pod 的环境变量,和 Dockerfile 里的 ENV 指令有点类似,但它是运行时指定的,更加灵活可配置。
command:定义容器启动时要执行的命令,相当于 Dockerfile 里的 ENTRYPOINT 指令。
args:它是 command 运行时的参数,相当于 Dockerfile 里的 CMD 指令,这两个命令和 Docker 的含义不同,要特别注意。
spec:
containers:
- image: busybox:latest
name: busy
imagePullPolicy: IfNotPresent
env:
- name: os
value: "ubuntu"
- name: debug
value: "on"
command:
- /bin/echo
args:
- "$(os), $(debug)"
如何使用 kubectl 操作 Pod
# 删除名称为 busy-pod 的 pod
kubectl delete pod busy-pod
# 查看 pod 日志
kubectl logs busy-pod
# 查看 pod 运行时状态
kubectl get pod
# 查看 pod 的详细编排信息, 常用于排错
kubectl describe pod busy-pod
# 拷贝
kubectl cp a.txt ngx-pod:/tmp
# 交互
kubectl exec -it ngx-pod -- /bin/bash
13|Job/CronJob:为什么不直接用Pod来处理业务?
为什么不直接使用 Pod
Kubernetes 对象设计思路,一个是“单一职责”,另一个是“组合优于继承”。
“单一职责”的意思是对象应该只专注于做好一件事情,不要贪大求全,保持足够小的粒度才更方便复用和管理。
“组合优于继承”的意思是应该尽量让对象在运行时产生联系,保持松耦合,而不要用硬编码的方式固定对象的关系。
因为 Pod 已经是一个相对完善的对象,专门负责管理容器,那么我们就不应该再“画蛇添足”地盲目为它扩充功能,而是要保持它的独立性,容器之外的功能就需要定义其他的对象,把 Pod 作为它的一个成员“组合”进去。
为什么要有 Job/CronJob
Nginx 和 busybox,它们分别代表了 Kubernetes 里的两大类业务。一类是像 Nginx 这样长时间运行的“在线业务”,另一类是像 busybox 这样短时间运行的“离线业务”。
“在线业务”类型的应用有很多,比如 Nginx、Node.js、MySQL、Redis 等等,一旦运行起来基本上不会停,也就是永远在线。
“离线业务”也可以分为两种。一种是“临时任务”,跑完就完事了,下次有需求了说一声再重新安排;另一种是“定时任务”,可以按时按点周期运行,不需要过多干预。
对应到 Kubernetes 里,“临时任务”就是 API 对象 Job,“定时任务”就是 API 对象 CronJob,使用这两个对象你就能够在 Kubernetes 里调度管理任意的离线业务了。
如何使用 YAML 描述 Job
Job 的 YAML“文件头”部分还是那几个必备字段:
- apiVersion 不是 v1,而是 batch/v1。
- kind 是 Job,这个和对象的名字是一致的。
- metadata 里仍然要有 name 标记名字,也可以用 labels 添加任意的标签。
可以使用命令 kubectl explain job 来看字段说明
生成 job 样板
export out="--dry-run=client -o yaml" # 定义Shell变量
kubectl create job echo-job --image=busybox $out
# 生成一个基本的 YAML 文件,保存之后做点修改,就有了一个 Job 对象
apiVersion: batch/v1
kind: Job
metadata:
name: echo-job
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- image: busybox
name: echo-job
imagePullPolicy: IfNotPresent
command: ["/bin/echo"]
args: ["hello", "world"]
# 其实就是在 Job 对象里应用了组合模式,template 字段定义了一个“应用模板”,里面嵌入了一个 Pod,这样 Job 就可以从这个模板来创建出 Pod。
# 而这个 Pod 因为受 Job 的管理控制,不直接和 apiserver 打交道,也就没必要重复 apiVersion 等“头字段”,只需要定义好关键的 spec,描述清楚容器相关的信息就可以了,可以说是一个“无头”的 Pod 对象。
# 因为 Job 业务的特殊性,所以我们还要在 spec 里多加一个字段 restartPolicy,确定 Pod 运行失败时的策略,OnFailure 是失败原地重启容器,而 Never 则是不重启容器,让 Job 去重新调度生成一个新的 Pod。

如何在 Kubernetes 里操作 Job
# 创建一个 job
kubectl apply -f job.yml
# 分别查看 Job 和 Pod 的状态
kubectl get job
kubectl get pod
Kubernetes 的这套 YAML 描述对象的框架提供了非常多的灵活性,可以在 Job 级别、Pod 级别添加任意的字段来定制业务,这种优势是简单的容器技术无法相比的。
这里列出几个控制离线作业的重要字段,其他更详细的信息可以参考 Job 文档:
activeDeadlineSeconds,设置 Pod 运行的超时时间。
backoffLimit,设置 Pod 的失败重试次数。
completions,Job 完成需要运行多少个 Pod,默认是 1 个。
parallelism,它与 completions 相关,表示允许并发运行的 Pod 数量,避免过多占用资源。
要注意这 4 个字段并不在 template 字段下,而是在 spec 字段下,所以它们是属于 Job 级别的,用来控制模板里的 Pod 对象。
# 创建一个 Job 对象,名字叫“sleep-job”,它随机睡眠一段时间再退出,模拟运行时间较长的作业(比如 MapReduce)。Job 的参数设置成 15 秒超时,最多重试 2 次,总共需要运行完 4 个 Pod,但同一时刻最多并发 2 个 Pod:
apiVersion: batch/v1
kind: Job
metadata:
name: sleep-job
spec:
activeDeadlineSeconds: 15
backoffLimit: 2
completions: 4
parallelism: 2
template:
spec:
restartPolicy: OnFailure
containers:
- image: busybox
name: echo-job
imagePullPolicy: IfNotPresent
command:
- sh
- -c
- sleep $(($RANDOM % 10 + 1)) && echo done
# 先创建, 在实时观察 Pod 的状态,看到 Pod 不断被排队、创建、运行的过程
kubectl apply -f sleep-job.yml
kubectl get pod -w

等到 4 个 Pod 都运行完毕,我们再用 kubectl get 来看看 Job 和 Pod 的状态

就会看到 Job 的完成数量如同我们预期的是 4,而 4 个 Pod 也都是完成状态。
如何使用 YAML 描述 CronJob
第一,因为 CronJob 的名字有点长,所以 Kubernetes 提供了简写 cj,这个简写也可以使用命令 kubectl api-resources 看到;第二,CronJob 需要定时运行,所以我们在命令行里还需要指定参数 --schedule。
export out="--dry-run=client -o yaml" # 定义Shell变量
kubectl create cj echo-cj --image=busybox --schedule="" $out
# 编辑这个模板 生成 cronjob
apiVersion: batch/v1
kind: CronJob
metadata:
name: echo-cj
spec:
schedule: '*/1 * * * *'
jobTemplate:
spec:
template:
spec:
restartPolicy: OnFailure
containers:
- image: busybox
name: echo-cj
imagePullPolicy: IfNotPresent
command: ["/bin/echo"]
args: ["hello", "world"]
还是重点关注它的 spec 字段,你会发现它居然连续有三个 spec 嵌套层次:
- 第一个 spec 是 CronJob 自己的对象规格声明
- 第二个 spec 从属于“jobTemplate”,它定义了一个 Job 对象。
- 第三个 spec 从属于“template”,它定义了 Job 里运行的 Pod。
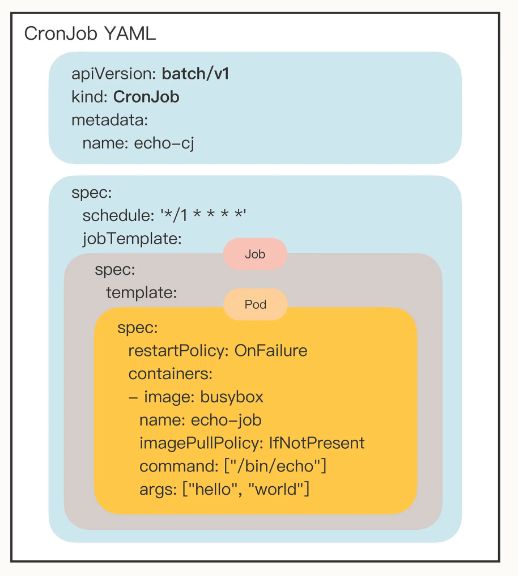
除了定义 Job 对象的“jobTemplate”字段之外,CronJob 还有一个新字段就是“schedule”,用来定义任务周期运行的规则。它使用的是标准的 Cron 语法,指定分钟、小时、天、月、周,和 Linux 上的 crontab 是一样的。
除了名字不同,CronJob 和 Job 的用法几乎是一样的
kubectl apply -f cronjob.yml
kubectl get cj
kubectl get pod
CronJob 使用定时规则控制 Job,Job 使用并发数量控制 Pod,Pod 再定义参数控制容器,容器再隔离控制进程,进程最终实现业务功能,层层递进的形式有点像设计模式里的 Decorator(装饰模式),链条里的每个环节都各司其职,在 Kubernetes 的统一指挥下完成任务。
Job 的关键字段是 spec.template,里面定义了用来运行业务的 Pod 模板,其他的重要字段有 completions、parallelism 等
CronJob 的关键字段是 spec.jobTemplate 和 spec.schedule,分别定义了 Job 模板和定时运行的规则。
14|ConfigMap/Secret:怎样配置、定制我的应用
Kubernetes 里专门用来管理配置信息的两种对象:ConfigMap 和 Secret,使用它们来灵活地配置、定制我们的应用。
ConfigMap/Secret
应用程序有很多类别的配置信息,但从数据安全的角度来看可以分成两类:
- 一类是明文配置,也就是不保密,可以任意查询修改,比如服务端口、运行参数、文件路径等等。
- 另一类则是机密配置,由于涉及敏感信息需要保密,不能随便查看,比如密码、密钥、证书等等。
这两类配置信息本质上都是字符串,只是由于安全性的原因,在存放和使用方面有些差异,所以 Kubernetes 也就定义了两个 API 对象,ConfigMap 用来保存明文配置,Secret 用来保存秘密配置。
什么是 ConfigMap
可以用命令 kubectl create 来创建一个它的 YAML 样板。注意,它有简写名字“cm”,所以命令行里没必要写出它的全称:
export out="--dry-run=client -o yaml" # 定义Shell变量
kubectl create cm info $out
# 得到的样板文件大概是这个样子:
apiVersion: v1
kind: ConfigMap
metadata:
name: info
因为 ConfigMap 存储的是配置数据,是静态的字符串,并不是容器,所以它们就不需要用“spec”字段来说明运行时的“规格”, 就只有 apiVersion, kind 及 metadata
既然 ConfigMap 要存储数据,我们就需要用另一个含义更明确的字段“data”。
# 注意,因为在 ConfigMap 里的数据都是 Key-Value 结构,所以 --from-literal 参数需要使用 k=v 的形式。
kubectl create cm info --from-literal=k=v $out
# 把 YAML 样板文件修改一下,再多增添一些 Key-Value,就得到了一个比较完整的 ConfigMap 对象:
apiVersion: v1
kind: ConfigMap
metadata:
name: info
data:
count: '10'
debug: 'on'
path: '/etc/systemd'
greeting: |
say hello to kubernetes.
# 创建, 查询
kubectl apply -f cm.yml
kubectl get cm
kubectl describe cm info

可以看到,现在 ConfigMap 的 Key-Value 信息就已经存入了 etcd 数据库,后续就可以被其他 API 对象使用。
什么是 Secret
了解了 ConfigMap 对象,我们再来看 Secret 对象就会容易很多,它和 ConfigMap 的结构和用法很类似,不过在 Kubernetes 里 Secret 对象又细分出很多类,比如:
- 访问私有镜像仓库的认证信息
- 身份识别的凭证信息
- HTTPS 通信的证书和私钥
- 一般的机密信息(格式由用户自行解释)
# 创建模板
kubectl create secret generic user --from-literal=name=root $out
# 得到的 Secret 对象大概是这个样子:
apiVersion: v1
kind: Secret
metadata:
name: user
data:
name: cm9vdA==
可以看到 name 是一串乱码, 这串“乱码”就是 Secret 与 ConfigMap 的不同之处,不让用户直接看到原始数据,起到一定的保密作用。不过它的手法非常简单,只是做了 Base64 编码,根本算不上真正的加密,所以我们完全可以绕开 kubectl,自己用 Linux 小工具“base64”来对数据编码,然后写入 YAML 文件,比如:
# 注意这条命令里的 echo ,必须要加参数 -n 去掉字符串里隐含的换行符,否则 Base64 编码出来的字符串就是错误的。
echo -n "123456" | base64
MTIzNDU2
# 手动增加键值对后
apiVersion: v1
kind: Secret
metadata:
name: user
data:
name: cm9vdA== # root
pwd: MTIzNDU2 # 123456
db: bXlzcWw= # mysql
# 创建, 查询等与 configmap 相同
kubectl apply -f secret.yml
kubectl get secret
kubectl describe secret user
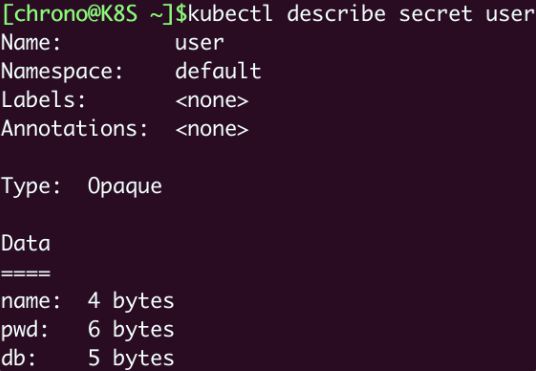
这样一个存储敏感信息的 Secret 对象也就创建好了,而且因为它是保密的,使用 kubectl describe 不能直接看到内容,只能看到数据的大小
如何使用
因为 ConfigMap 和 Secret 只是一些存储在 etcd 里的字符串,所以如果想要在运行时产生效果,就必须要以某种方式“注入”到 Pod 里,让应用去读取。在这方面的处理上 Kubernetes 和 Docker 是一样的,也是两种途径:环境变量和加载文件。
如何以环境变量的方式使用 ConfigMap/Secret
# 查看说明
kubectl explain pod.spec.containers.env.valueFrom
“valueFrom”字段指定了环境变量值的来源,可以是“configMapKeyRef”或者“secretKeyRef”,然后你要再进一步指定应用的 ConfigMap/Secret 的“name”和它里面的“key”,要当心的是这个“name”字段是 API 对象的名字,而不是 Key-Value 的名字。
apiVersion: v1
kind: Pod
metadata:
name: env-pod
spec:
containers:
- env:
- name: COUNT
valueFrom:
configMapKeyRef:
name: info
key: count
- name: GREETING
valueFrom:
configMapKeyRef:
name: info
key: greeting
- name: USERNAME
valueFrom:
secretKeyRef:
name: user
key: name
- name: PASSWORD
valueFrom:
secretKeyRef:
name: user
key: pwd
image: busybox
name: busy
imagePullPolicy: IfNotPresent
command: ["/bin/sleep", "300"]
“env”字段,里面定义了 4 个环境变量,COUNT、GREETING、USERNAME、PASSWORD。
对于明文配置数据, COUNT、GREETING 引用的是 ConfigMap 对象,所以使用字段“configMapKeyRef”,里面的“name”是 ConfigMap 对象的名字,也就是之前我们创建的“info”,而“key”字段分别是“info”对象里的 count 和 greeting。
同样的对于机密配置数据, USERNAME、PASSWORD 引用的是 Secret 对象,要使用字段“secretKeyRef”,再用“name”指定 Secret 对象的名字 user,用“key”字段应用它里面的 name 和 pwd 。
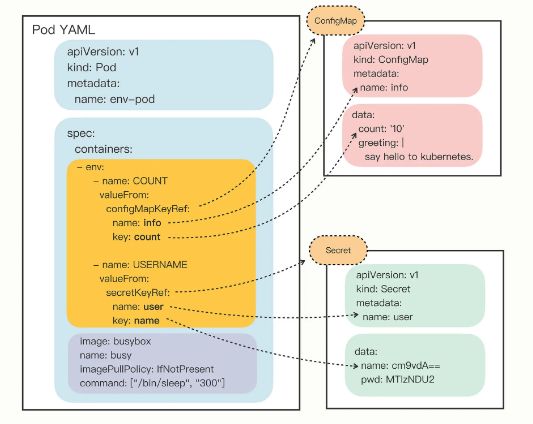
从这张图你就应该能够比较清楚地看出 Pod 与 ConfigMap、Secret 的“松耦合”关系,它们不是直接嵌套包含,而是使用“KeyRef”字段间接引用对象,这样,同一段配置信息就可以在不同的对象之间共享。
弄清楚了环境变量的注入方式之后,让我们用 kubectl apply 创建 Pod,再用 kubectl exec 进入 Pod,验证环境变量是否生效:
kubectl apply -f env-pod.yml
kubectl exec -it env-pod -- sh
echo $COUNT
echo $GREETING
echo $USERNAME $PASSWORD

如何以 Volume 的方式使用 ConfigMap/Secret
Kubernetes 为 Pod 定义了一个“Volume”的概念,可以翻译成是“存储卷”。如果把 Pod 理解成是一个虚拟机,那么 Volume 就相当于是虚拟机里的磁盘。
我们可以为 Pod“挂载(mount)”多个 Volume,里面存放供 Pod 访问的数据,这种方式有点类似 docker run -v,虽然用法复杂了一些,但功能也相应强大一些。
在 Pod 里挂载 Volume 很容易,只需要在“spec”里增加一个“volumes”字段,然后再定义卷的名字和引用的 ConfigMap/Secret 就可以了。要注意的是 Volume 属于 Pod,不属于容器,所以它和字段“containers”是同级的,都属于“spec”。
下面让我们来定义两个 Volume,分别引用 ConfigMap 和 Secret,名字是 cm-vol 和 sec-vol:
spec:
volumes:
- name: cm-vol
configMap:
name: info
- name: sec-vol
secret:
secretName: user
有了 Volume 的定义之后,就可以在容器里挂载了,这要用到“volumeMounts”字段,正如它的字面含义,可以把定义好的 Volume 挂载到容器里的某个路径下,所以需要在里面用“mountPath”“name”明确地指定挂载路径和 Volume 的名字。
containers:
- volumeMounts:
- mountPath: /tmp/cm-items
name: cm-vol
- mountPath: /tmp/sec-items
name: sec-vol
把“volumes”和“volumeMounts”字段都写好之后,配置信息就可以加载成文件了。这里我还是画了图来表示它们的引用关系:
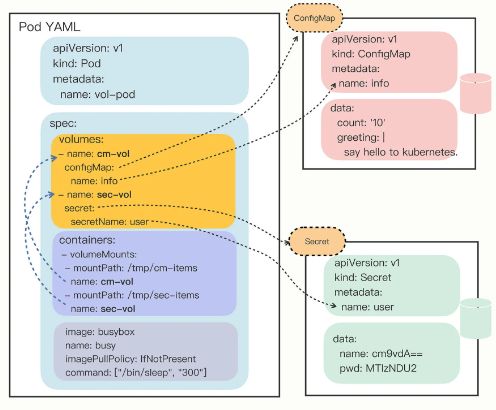
可以看到,挂载 Volume 的方式和环境变量又不太相同。环境变量是直接引用了 ConfigMap/Secret,而 Volume 又多加了一个环节,需要先用 Volume 引用 ConfigMap/Secret,然后在容器里挂载 Volume,有点“兜圈子”“弯弯绕”。
这种方式的好处在于:以 Volume 的概念统一抽象了所有的存储,不仅现在支持 ConfigMap/Secret,以后还能够支持临时卷、持久卷、动态卷、快照卷等许多形式的存储,扩展性非常好。
现在我把 Pod 的完整 YAML 描述列出来,然后使用 kubectl apply 创建它:
apiVersion: v1
kind: Pod
metadata:
name: vol-pod
spec:
volumes:
- name: cm-vol
configMap:
name: info
- name: sec-vol
secret:
secretName: user
containers:
- volumeMounts:
- mountPath: /tmp/cm-items
name: cm-vol
- mountPath: /tmp/sec-items
name: sec-vol
image: busybox
name: busy
imagePullPolicy: IfNotPresent
command: ["/bin/sleep", "300"]
创建之后,我们还是用 kubectl exec 进入 Pod,看看配置信息被加载成了什么形式:
kubectl apply -f vol-pod.yml
kubectl get pod
kubectl exec -it vol-pod -- sh

你会看到,ConfigMap 和 Secret 都变成了目录的形式,而它们里面的 Key-Value 变成了一个个的文件,而文件名就是 Key。
因为这种形式上的差异,以 Volume 的方式来使用 ConfigMap/Secret,就和环境变量不太一样。环境变量用法简单,更适合存放简短的字符串,而 Volume 更适合存放大数据量的配置文件,在 Pod 里加载成文件后让应用直接读取使用。
两种在 Kubernetes 里管理配置信息的 API 对象 ConfigMap 和 Secret,它们分别代表了明文信息和机密敏感信息,存储在 etcd 里,在需要的时候可以注入 Pod 供 Pod 使用。
小结
- ConfigMap 记录了一些 Key-Value 格式的字符串数据,描述字段是“data”,不是“spec”。
- Secret 与 ConfigMap 很类似,也使用“data”保存字符串数据,但它要求数据必须是 Base64 编码,起到一定的保密效果。
- 在 Pod 的“env.valueFrom”字段中可以引用 ConfigMap 和 Secret,把它们变成应用可以访问的环境变量。
- 在 Pod 的“spec.volumes”字段中可以引用 ConfigMap 和 Secret,把它们变成存储卷,然后在“spec.containers.volumeMounts”字段中加载成文件的形式。
- ConfigMap 和 Secret 对存储数据的大小没有限制,但小数据用环境变量比较适合,大数据应该用存储卷,可根据具体场景灵活应用。
- ConfigMap 和 Secret 对存储数据的大小是有限制的,限制为 1MiB,官方文档:https://kubernetes.io/zh-cn/docs/concepts/configuration/configmap/#motivation
小贴士:
- 如果已经存在一些配置文件, 可以使用参数 --from-file 从文件中自动创建 configmap 或 secret
- linux 中对环境变量命名有限制, 不能出现 - . 等特殊字符, 所以在创建 configmap 或 secret 时需要注意, 否则无法以环境变量的形式注入 pod
- 可以在 volumes.configMap.items 字段使用 key path 为 configMap 的每个 Key-Value 精确的指定加载的路径名, 也就是给文件改名
15|实战演练:玩转Kubernetes(1)
Kubernetes 技术要点回顾
容器技术开启了云原生的大潮,但成熟的容器技术,到生产环境的应用部署的时候,却显得“步履维艰”。因为容器只是针对单个进程的隔离和封装,而实际的应用场景却是要求许多的应用进程互相协同工作,其中的各种关系和需求非常复杂,在容器这个技术层次很难掌控。
为了解决这个问题,容器编排(Container Orchestration)就出现了,它可以说是以前的运维工作在云原生世界的落地实践,本质上还是在集群里调度管理应用程序,只不过管理的主体由人变成了计算机,管理的目标由原生进程变成了容器和镜像。
而现在,容器编排领域的王者就是——Kubernetes。
Kubernetes 的 Master/Node 架构是它具有自动化运维能力的关键(10 讲)。
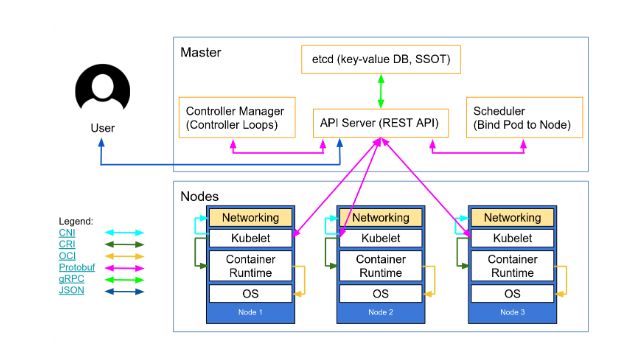
- 控制面是 Master 节点,负责管理集群和运维监控应用,里面的核心组件是 apiserver、etcd、scheduler、controller-manager。
- 数据面是 Worker 节点,受 Master 节点的管控,里面的核心组件是 kubelet、kube-proxy、container-runtime。
为了更好地管理集群和业务应用,Kubernetes 从现实世界中抽象出了许多概念,称为“API 对象”,描述这些对象就需要使用 YAML 语言。
YAML 是 JSON 的超集,但语法更简洁,表现能力更强,更重要的是它以“声明式”来表述对象的状态,不涉及具体的操作细节,这样 Kubernetes 就能够依靠存储在 etcd 里集群的状态信息,不断地“调控”对象,直至实际状态与期望状态相同,这个过程就是 Kubernetes 的自动化运维管理(11 讲)。
Kubernetes 里有很多的 API 对象,其中最核心的对象是“Pod”,它捆绑了一组存在密切协作关系的容器,容器之间共享网络和存储,在集群里必须一起调度一起运行。通过 Pod 这个概念,Kubernetes 就简化了对容器的管理工作,其他的所有任务都是通过对 Pod 这个最小单位的再包装来实现的(12 讲)。
了核心的 Pod 对象,基于“单一职责”和“对象组合”这两个基本原则,我们又学习了 4 个比较简单的 API 对象,分别是 Job/CronJob 和 ConfigMap/Secret。
Job/CronJob 对应的是离线作业,它们逐层包装了 Pod,添加了作业控制和定时规则(13 讲)。
ConfigMap/Secret 对应的是配置信息,需要以环境变量或者存储卷的形式注入进 Pod,然后进程才能在运行时使用(14 讲)。
和 Docker 类似,Kubernetes 也提供一个客户端工具,名字叫“kubectl”,它直接与 Master 节点的 apiserver 通信,把 YAML 文件发送给 RESTful 接口,从而触发 Kubernetes 的对象管理工作流程。
kubectl 的命令很多,查看自带文档可以用 api-resources、explain ,查看对象状态可以用 get、describe、logs ,操作对象可以用 run、apply、exec、delete 等等(09 讲)。
使用 YAML 描述 API 对象也有固定的格式,必须写的“头字段”是“apiVersion”“kind”“metadata”,它们表示对象的版本、种类和名字等元信息。实体对象如 Pod、Job、CronJob 会再有“spec”字段描述对象的期望状态,最基本的就是容器信息,非实体对象如 ConfigMap、Secret 使用的是“data”字段,记录一些静态的字符串信息。
WordPress 网站基本架构
系统的内部逻辑关系

网站的大体架构是没有变化的,毕竟应用还是那三个,它们的调用依赖关系也必然没有变化。
那么 Kubernetes 系统和 Docker 系统的区别又在哪里呢?
关键就在对应用的封装和网络环境这两点上。
现在 WordPress、MariaDB 这两个应用被封装成了 Pod(由于它们都是在线业务,所以 Job/CronJob 在这里派不上用场),运行所需的环境变量也都被改写成 ConfigMap,统一用“声明式”来管理,比起 Shell 脚本更容易阅读和版本化管理。
另外,Kubernetes 集群在内部维护了一个自己的专用网络,这个网络和外界隔离,要用特殊的“端口转发”方式来传递数据,还需要在集群之外用 Nginx 反向代理这个地址,这样才能实现内外沟通,对比 Docker 的直接端口映射,这里略微麻烦了一些。
WordPress 网站搭建步骤
第一步当然是要编排 MariaDB 对象,它的具体运行需求可以参考“入门篇”的实战演练课,这里我就不再重复了。
MariaDB 需要 4 个环境变量,比如数据库名、用户名、密码等,在 Docker 里我们是在命令行里使用参数 --env,而在 Kubernetes 里我们就应该使用 ConfigMap,为此需要定义一个 maria-cm 对象:
apiVersion: v1
kind: ConfigMap
metadata:
name: maria-cm
data:
DATABASE: 'db'
USER: 'wp'
PASSWORD: '123'
ROOT_PASSWORD: '123'
然后我们定义 Pod 对象 maria-pod,把配置信息注入 Pod,让 MariaDB 运行时从环境变量读取这些信息:
apiVersion: v1
kind: Pod
metadata:
name: maria-pod
labels:
app: wordpress
role: database
spec:
containers:
- image: mariadb:10
name: maria
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3306
envFrom:
- prefix: 'MARIADB_'
configMapRef:
name: maria-cm
注意这里我们使用了一个新的字段“envFrom”,这是因为 ConfigMap 里的信息比较多,如果用 env.valueFrom 一个个地写会非常麻烦,容易出错,而 envFrom 可以一次性地把 ConfigMap 里的字段全导入进 Pod,并且能够指定变量名的前缀(即这里的 MARIADB_),非常方便。
使用 kubectl apply 创建这个对象之后,可以用 kubectl get pod 查看它的状态,如果想要获取 IP 地址需要加上参数 -o wide :
kubectl apply -f mariadb-pod.yml
kubectl get pod -o wide

现在数据库就成功地在 Kubernetes 集群里跑起来了,IP 地址是“172.17.0.2”,注意这个地址和 Docker 的不同,是 Kubernetes 里的私有网段。
接着是第二步,编排 WordPress 对象,还是先用 ConfigMap 定义它的环境变量:
apiVersion: v1
kind: ConfigMap
metadata:
name: wp-cm
data:
HOST: '172.17.0.2'
USER: 'wp'
PASSWORD: '123'
NAME: 'db'
在这个 ConfigMap 里要注意的是“HOST”字段,它必须是 MariaDB Pod 的 IP 地址,如果不写正确 WordPress 会无法正常连接数据库。
然后我们再编写 WordPress 的 YAML 文件,为了简化环境变量的设置同样使用了 envFrom:
apiVersion: v1
kind: Pod
metadata:
name: wp-pod
labels:
app: wordpress
role: website
spec:
containers:
- image: wordpress:5
name: wp-pod
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
envFrom:
- prefix: 'WORDPRESS_DB_'
configMapRef:
name: wp-cm
接着还是用 kubectl apply 创建对象,kubectl get pod 查看它的状态:
kubectl apply -f wp-pod.yml
kubectl get pod -o wide

第三步是为 WordPress Pod 映射端口号,让它在集群外可见。
因为 Pod 都是运行在 Kubernetes 内部的私有网段里的,外界无法直接访问,想要对外暴露服务,需要使用一个专门的 kubectl port-forward 命令,它专门负责把本机的端口映射到在目标对象的端口号,有点类似 Docker 的参数 -p,经常用于 Kubernetes 的临时调试和测试。
下面我就把本地的“8080”映射到 WordPress Pod 的“80”,kubectl 会把这个端口的所有数据都转发给集群内部的 Pod:
kubectl port-forward wp-pod 8080:80 &

注意在命令的末尾我使用了一个 & 符号,让端口转发工作在后台进行,这样就不会阻碍我们后续的操作。
如果想关闭端口转发,需要敲命令 fg ,它会把后台的任务带回到前台,然后就可以简单地用“Ctrl + C”来停止转发了。
第四步是创建反向代理的 Nginx,让我们的网站对外提供服务。
这是因为 WordPress 网站使用了 URL 重定向,直接使用“8080”会导致跳转故障,所以为了让网站正常工作,我们还应该在 Kubernetes 之外启动 Nginx 反向代理,保证外界看到的仍然是“80”端口号。(这里的细节和我们的课程关系不大,感兴趣的同学可以留言提问讨论)
Nginx 的配置文件和第 7 讲基本一样,只是目标地址变成了“127.0.0.1:8080”,它就是我们在第三步里用 kubectl port-forward 命令创建的本地地址:
server {
listen 80;
default_type text/html;
location / {
proxy_http_version 1.1;
proxy_set_header Host $host;
proxy_pass http://127.0.0.1:8080;
}
}
然后我们用 docker run -v 命令加载这个配置文件,以容器的方式启动这个 Nginx 代理:
docker run -d --rm \
--net=host \
-v /tmp/proxy.conf:/etc/nginx/conf.d/default.conf \
nginx:alpine
有了 Nginx 的反向代理之后,我们就可以打开浏览器,输入本机的“127.0.0.1”或者是虚拟机的 IP 地址(我这里仍然是“http://192.168.10.208”),看到 WordPress 的界面:

你也可以在 Kubernetes 里使用命令 kubectl logs 查看 WordPress、MariaDB 等 Pod 的运行日志,来验证它们是否已经正确地响应了请求:

使用 Dashboard 管理 Kubernetes
到这里 WordPress 网站就搭建成功了,我们的主要任务也算是完成了,不过我还想再带你看看 Kubernetes 的图形管理界面,也就是 Dashboard,看看不用命令行该怎么管理 Kubernetes。
启动 Dashboard 的命令你还记得吗,在第 10 节课里讲插件的时候曾经说过,需要用 minikube,命令是:
minikube dashboard
它会自动打开浏览器界面,显示出当前 Kubernetes 集群里的工作负载:

点击任意一个 Pod 的名字,就会进入管理界面,可以看到 Pod 的详细信息,而右上角有 4 个很重要的功能,分别可以查看日志、进入 Pod 内部、编辑 Pod 和删除 Pod,相当于执行 logs、exec、edit、delete 命令,但要比命令行要直观友好的多:

比如说,我点击了第二个按钮,就会在浏览器里开启一个 Shell 窗口,直接就是 Pod 的内部 Linux 环境,在里面可以输入任意的命令,无论是查看状态还是调试都很方便:

ConfigMap/Secret 等对象也可以在这里任意查看或编辑:

Dashboard 里的可操作的地方还有很多,这里我只是一个非常简单的介绍。虽然你也许已经习惯了使用键盘和命令行,但偶尔换一换口味,改用鼠标和图形界面来管理 Kubernetes 也是件挺有意思的事情,有机会不妨尝试一下。
Kubernetes 的知识要点思维导图
16|视频:初级篇实操总结
一. minikube 环境
# 查看 minikube 版本号
minikube version
# 查看 minikube 状态
minikube status
# 使用 minikube 启动 minikube 集群
minikube start --kubernetes-version=v1.23.3
# 查看集群节点列表
minikube node list
# 登录节点
minikube ssh xxx.xx.xx.xx
uname -a #显示是Ubuntu操作系统
docker version #这个节点里也跑了一个docker,但其实是复用了宿主机的docker
docker ps #能够看到节点里以容器形式运行的Kubernetes进程,比如pause、scheduler等等
exit
# 查看 k8s 版本
kubectl version
# 运行 nginx pod
kubectl run ngx --image=nginx:alpine
# 查看 kube-system 命名空间下的 pod
kubectl get pod -n kube-system
二. 用 kubectl 操作 API 对象
# 查看当前版本支持的所有 api 对象
kubectl api-resources
# 它的输出信息很多,你可以看到 Pod 的简写是 po、api version 是 v1、CronJob 的简写是 cj、api version 是 batch/v1,这些信息在我们编写 YAML 描述文件的时候非常有用。
# kubectl explain,它能够给出 api 对象字段的详细信息,比如查看 Pod
kubectl explain pod
kubectl explain pod.metadata
kubectl explain pod.spec
kubectl explain pod.spec.containers
# 创建 YAML 样板要用到两个特殊参数“--dry-run=client”和“-o yaml”,我把它定义成一个环境变量:
export out="--dry-run=client -o yaml"
# 创建一个 Pod 的 YAML
kubectl run ngx --image=nginx:alpine $out > pod.yml
三. Pod 对象
四. 离线业务对象 Job、CronJob
# 创建一个 Job 样板文件
kubectl create job echo-job --image=busybox $out
# CronJob 自动生成样板文件
kubectl create cj echo-cj --image=busybox --schedule="" $out
vi cronjob.yml
五. 配置信息对象 ConfigMap 和 Secret
# 创建 cofigMap 模板, 注意 --from-literal=k=v
kubectl create cm info --from-literal=k=v $out
# 创建 Secret 模板, 要用 generic 表示一般的机密信息
kubectl create secret generic user --from-literal=name=root $out
17|更真实的云原生:实际搭建多节点的Kubernetes集群
什么是 kubeadm
kubeadm,原理和 minikube 类似,也是用容器和镜像来封装 Kubernetes 的各种组件,但它的目标不是单机部署,而是要能够轻松地在集群环境里部署 Kubernetes,并且让这个集群接近甚至达到生产级质量。
实验环境的架构是什么样的

Master 节点需要运行 apiserver、etcd、scheduler、controller-manager 等组件,管理整个集群,所以对配置要求比较高,至少是 2 核 CPU、4GB 的内存。

Worker 节点没有管理工作,只运行业务应用,所以配置可以低一些,为了节省资源我给它分配了 1 核 CPU 和 1GB 的内存,可以说是低到不能再低了。
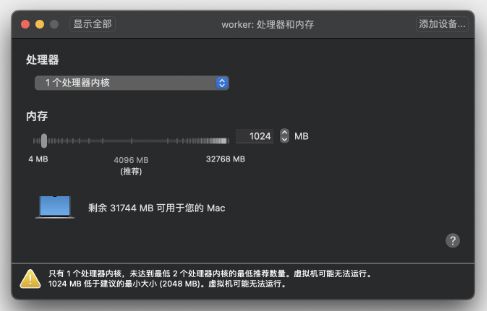
基于模拟生产环境的考虑,在 Kubernetes 集群之外还需要有一台起辅助作用的服务器。
它的名字叫 Console,意思是控制台,我们要在上面安装命令行工具 kubectl,所有对 Kubernetes 集群的管理命令都是从这台主机发出去的。这也比较符合实际情况,因为安全的原因,集群里的主机部署好之后应该尽量少直接登录上去操作。
要提醒你的是,Console 这台主机只是逻辑上的概念,不一定要是独立,你在实际安装部署的时候完全可以复用之前 minikube 的虚拟机,或者直接使用 Master/Worker 节点作为控制台。
这 3 台主机共同组成了我们的实验环境,所以在配置的时候要注意它们的网络选项,必须是在同一个网段,你可以再回顾一下课前准备,保证它们使用的是同一个“Host-Only”(VirtualBox)或者“自定”(VMWare Fusion)网络。
安装前的准备工作
第一,由于 Kubernetes 使用主机名来区分集群里的节点,所以每个节点的 hostname 必须不能重名。你需要修改“/etc/hostname”这个文件,把它改成容易辨识的名字,比如 Master 节点就叫 master,Worker 节点就叫 worker:
sudo vi /etc/hostname
第二,虽然 Kubernetes 目前支持多种容器运行时,但 Docker 还是最方便最易用的一种,所以我们仍然继续使用 Docker 作为 Kubernetes 的底层支持,使用 apt 安装 Docker Engine(可参考第 1 讲)。
安装完成后需要你再对 Docker 的配置做一点修改,在“/etc/docker/daemon.json”里把 cgroup 的驱动程序改成 systemd ,然后重启 Docker 的守护进程,具体的操作我列在了下面:
cat <<EOF | sudo tee /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
sudo systemctl enable docker
sudo systemctl daemon-reload
sudo systemctl restart docker
第三,为了让 Kubernetes 能够检查、转发网络流量,你需要修改 iptables 的配置,启用“br_netfilter”模块:
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward=1 # better than modify /etc/sysctl.conf
EOF
sudo sysctl --system
第四,你需要修改“/etc/fstab”,关闭 Linux 的 swap 分区,提升 Kubernetes 的性能:
sudo swapoff -a
sudo sed -ri '/\sswap\s/s/^#?/#/' /etc/fstab
完成之后,最好记得重启一下系统,然后给虚拟机拍个快照做备份,避免后续的操作失误导致重复劳动。
安装 kubeadm
安装 kubeadm,在 Master 节点和 Worker 节点上都要做这一步。
sudo apt install -y apt-transport-https ca-certificates curl
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
sudo apt update
更新了软件仓库,我们就可以用 apt install 获取 kubeadm、kubelet 和 kubectl 这三个安装必备工具了。apt 默认会下载最新版本,但我们也可以指定版本号,比如使用和 minikube 相同的“1.23.3”:
sudo apt install -y kubeadm=1.23.3-00 kubelet=1.23.3-00 kubectl=1.23.3-00
安装完成之后,你可以用 kubeadm version、kubectl version 来验证版本是否正确:
kubeadm version
kubectl version --client
另外按照 Kubernetes 官网的要求,我们最好再使用命令 apt-mark hold ,锁定这三个软件的版本,避免意外升级导致版本错误:
sudo apt-mark hold kubeadm kubelet kubectl
下载 Kubernetes 组件镜像
Kubeadm 把 apiserver、etcd、scheduler 等组件都打包成了镜像,以容器的方式启动 Kubernetes,但这些镜像不是放在 Docker Hub 上,而是放在 Google 自己的镜像仓库网站 gcr.io,而它在国内的访问很困难,直接拉取镜像几乎是不可能的。所以我们需要采取一些变通措施,提前把镜像下载到本地。
# 使用命令 kubeadm config images list 可以查看安装 Kubernetes 所需的镜像列表,参数 --kubernetes-version 可以指定版本号:
kubeadm config images list --kubernetes-version v1.23.3
k8s.gcr.io/kube-apiserver:v1.23.3
k8s.gcr.io/kube-controller-manager:v1.23.3
k8s.gcr.io/kube-scheduler:v1.23.3
k8s.gcr.io/kube-proxy:v1.23.3
k8s.gcr.io/pause:3.6
k8s.gcr.io/etcd:3.5.1-0
k8s.gcr.io/coredns/coredns:v1.8.6
从国内的镜像网站下载然后再用 docker tag 改名,能够使用 Shell 编程实现自动化:
repo=registry.aliyuncs.com/google_containers
for name in `kubeadm config images list --kubernetes-version v1.23.3`; do
src_name=${name#k8s.gcr.io/}
src_name=${src_name#coredns/}
docker pull $repo/$src_name
docker tag $repo/$src_name $name
docker rmi $repo/$src_name
done

安装 Master 节点
kubeadm 的用法非常简单,只需要一个命令 kubeadm init 就可以把组件在 Master 节点上运行起来,不过它还有很多参数用来调整集群的配置,你可以用 -h 查看。这里我只说一下我们实验环境用到的 3 个参数:
- pod-network-cidr,设置集群里 Pod 的 IP 地址段。
- apiserver-advertise-address,设置 apiserver 的 IP 地址,对于多网卡服务器来说很重要(比如 VirtualBox 虚拟机就用了两块网卡),可以指定 apiserver 在哪个网卡上对外提供服务。
- kubernetes-version,指定 Kubernetes 的版本号。
下面的这个安装命令里,我指定了 Pod 的地址段是“10.10.0.0/16”,apiserver 的服务地址是“192.168.10.210”,Kubernetes 的版本号是“1.23.3”:
sudo kubeadm init \
--pod-network-cidr=10.10.0.0/16 \
--apiserver-advertise-address=192.168.10.210 \
--kubernetes-version=v1.23.3
因为我们已经提前把镜像下载到了本地,所以 kubeadm 的安装过程很快就完成了,它还会提示出接下来要做的工作:
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
意思是要在本地建立一个“.kube”目录,然后拷贝 kubectl 的配置文件,你只要原样拷贝粘贴就行。
另外还有一个很重要的“kubeadm join”提示,其他节点要加入集群必须要用指令里的 token 和 ca 证书,所以这条命令务必拷贝后保存好:
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.10.210:6443 --token tv9mkx.tw7it9vphe158e74 \
--discovery-token-ca-cert-hash sha256:e8721b8630d5b562e23c010c70559a6d3084f629abad6a2920e87855f8fb96f3
安装完成后,你就可以使用 kubectl version、kubectl get node 来检查 Kubernetes 的版本和集群的节点状态了:
kubectl version
kubectl get node
你会注意到 Master 节点的状态是“NotReady”,这是由于还缺少网络插件,集群的内部网络还没有正常运作。
安装 Flannel 网络插件
Kubernetes 定义了 CNI 标准,有很多网络插件,这里我选择最常用的 Flannel,可以在它的 GitHub 仓库里(https://github.com/flannel-io/flannel/)找到相关文档。
它安装也很简单,只需要使用项目的“kube-flannel.yml”在 Kubernetes 里部署一下就好了。不过因为它应用了 Kubernetes 的网段地址,你需要修改文件里的“net-conf.json”字段,把 Network 改成刚才 kubeadm 的参数 --pod-network-cidr 设置的地址段。
比如在这里,就要修改成“10.10.0.0/16”:
net-conf.json: |
{
"Network": "10.10.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
改好后,你就可以用 kubectl apply 来安装 Flannel 网络了:
kubectl apply -f kube-flannel.yml
稍等一小会,等镜像拉取下来并运行之后,你就可以执行 kubectl get node 来看节点状态:
kubectl get node
这时你应该能够看到 Master 节点的状态是“Ready”,表明节点网络也工作正常了。
安装 Worker 节点
如果你成功安装了 Master 节点,那么 Worker 节点的安装就简单多了,只需要用之前拷贝的那条 kubeadm join 命令就可以了,记得要用 sudo 来执行:
sudo \
kubeadm join 192.168.10.210:6443 --token tv9mkx.tw7it9vphe158e74 \
--discovery-token-ca-cert-hash sha256:e8721b8630d5b562e23c010c70559a6d3084f629abad6a2920e87855f8fb96f3
它会连接 Master 节点,然后拉取镜像,安装网络插件,最后把节点加入集群。
当然,这个过程中同样也会遇到拉取镜像的问题,你可以如法炮制,提前把镜像下载到 Worker 节点本地,这样安装过程中就不会再有障碍了。
Worker 节点安装完毕后,执行 kubectl get node ,就会看到两个节点都是“Ready”状态:
现在让我们用 kubectl run ,运行 Nginx 来测试一下:
kubectl run ngx --image=nginx:alpine
kubectl get pod -o wide
会看到 Pod 运行在 Worker 节点上,IP 地址是“10.10.1.2”,表明我们的 Kubernetes 集群部署成功。
后面 Console 节点的部署工作更加简单,它只需要安装一个 kubectl,然后复制“config”文件就行,你可以直接在 Master 节点上用“scp”远程拷贝,例如:
scp `which kubectl` chrono@192.168.10.208:~/
scp ~/.kube/config chrono@192.168.10.208:~/.kube
小结
- kubeadm 是一个方便易用的 Kubernetes 工具,能够部署生产级别的 Kubernetes 集群。
- 安装 Kubernetes 之前需要修改主机的配置,包括主机名、Docker 配置、网络设置、交换分区等。
- Kubernetes 的组件镜像存放在 gcr.io,国内下载比较麻烦,可以考虑从 minikube 或者国内镜像网站获取。
- 安装 Master 节点需要使用命令 kubeadm init,安装 Worker 节点需要使用命令 kubeadm join,还要部署 Flannel 等网络插件才能让集群正常工作。
- 因为这些操作都是各种 Linux 命令,全手动敲下来确实很繁琐,所以我把这些步骤都做成了 Shell 脚本放在了 GitHub 上(https://github.com/chronolaw/k8s_study/tree/master/admin),你可以下载后直接运行。

18|Deployment:让应用永不宕机
为什么要有 Deployment
比如说,有人不小心用 kubectl delete 误删了 Pod,或者 Pod 运行的节点发生了断电故障,那么 Pod 就会在集群里彻底消失,对容器的控制也就无从谈起了。
还有我们也都知道,在线业务远不是单纯启动一个 Pod 这么简单,还有多实例、高可用、版本更新等许多复杂的操作。比如最简单的多实例需求,为了提高系统的服务能力,应对突发的流量和压力,我们需要创建多个应用的副本,还要即时监控它们的状态。如果还是只使用 Pod,那就会又走回手工管理的老路,没有利用好 Kubernetes 自动化运维的优势。
既然 Pod 管理不了自己,那么我们就再创建一个新的对象,由它来管理 Pod,采用和 Job/CronJob 一样的形式——“对象套对象”。这个用来管理 Pod,实现在线业务应用的新 API 对象,就是 Deployment。
如何使用 YAML 描述 Deployment
# 使用 kubectl api-resources 来看看 Deployment 的基本信息
kubectl api-resources
NAME SHORTNAMES APIVERSION NAMESPACED KIND
deployments deploy apps/v1 true Deployment
# 从它的输出信息里可以知道,Deployment 的简称是“deploy”,它的 apiVersion 是“apps/v1”,kind 是“Deployment”。所以, 它的 yaml 文件应该这样写
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: xxx-dep
---
# 亦可以使用 kubectl create 来创建 deployment 的模板
export out="--dry-run=client -o yaml"
kubectl create deploy ngx-dep --image=nginx:alpine $out
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: ngx-dep
name: ngx-dep
spec:
replicas: 2
selector:
matchLabels:
app: ngx-dep
template:
metadata:
labels:
app: ngx-dep
spec:
containers:
- image: nginx:alpine
name: nginx
Deployment 的关键字段
- replicas: 它的含义比较简单明了,就是“副本数量”的意思,也就是说,指定要在 Kubernetes 集群里运行多少个 Pod 实例, 也称为"期望状态"。Deployment 对象就可以扮演运维监控人员的角色,自动地在集群里调整 Pod 的数量。
- selector: 它的作用是“筛选”出要被 Deployment 管理的 Pod 对象,下属字段“matchLabels”定义了 Pod 对象应该携带的 label,它必须和“template”里 Pod 定义的“labels”完全相同,否则 Deployment 就会找不到要控制的 Pod 对象,apiserver 也会告诉你 YAML 格式校验错误无法创建。
这个 selector 字段的用法初看起来好像是有点多余,为了保证 Deployment 成功创建,我们必须在 YAML 里把 label 重复写两次:一次是在“selector.matchLabels”,另一次是在“template.matadata”。像在这里,你就要在这两个地方连续写 app: ngx-dep.
...
spec:
replicas: 2
selector:
matchLabels:
app: ngx-dep
template:
metadata:
labels:
app: ngx-dep
...
这是因为在线业务和离线业务的应用场景差异很大。离线业务中的 Pod 基本上是一次性的,只与这个业务有关,紧紧地绑定在 Job 对象里,一般不会被其他对象所使用。
而在线业务就要复杂得多了,因为 Pod 永远在线,除了要在 Deployment 里部署运行,还可能会被其他的 API 对象引用来管理,比如负责负载均衡的 Service 对象。
所以 Deployment 和 Pod 实际上是一种松散的组合关系,Deployment 实际上并不“持有”Pod 对象,它只是帮助 Pod 对象能够有足够的副本数量运行,仅此而已。如果像 Job 那样,把 Pod 在模板里“写死”,那么其他的对象再想要去管理这些 Pod 就无能为力了。
通过标签这种设计,Kubernetes 就解除了 Deployment 和模板里 Pod 的强绑定,把组合关系变成了“弱引用”。

如何使用 kubectl 操作 Deployment
# 创建 deployment
kubectl apply -f deploy.yml
# 查询
kubectl get deploy

-
READY 表示运行的 Pod 数量,前面的数字是当前数量,后面的数字是期望数量,所以“2/2”的意思就是要求有两个 Pod 运行,现在已经启动了两个 Pod。
-
UP-TO-DATE 指的是当前已经更新到最新状态的 Pod 数量。因为如果要部署的 Pod 数量很多或者 Pod 启动比较慢,Deployment 完全生效需要一个过程,UP-TO-DATE 就表示现在有多少个 Pod 已经完成了部署,达成了模板里的“期望状态”。
-
AVAILABLE 要比 READY、UP-TO-DATE 更进一步,不仅要求已经运行,还必须是健康状态,能够正常对外提供服务,它才是我们最关心的 Deployment 指标。
-
AGE 表示 Deployment 从创建到现在所经过的时间,也就是运行的时间。
因为 Deployment 管理的是 Pod,我们最终用的也是 Pod,所以还需要用 kubectl get pod 命令来看看 Pod 的状态
kubectl get pod

从截图里你可以看到,被 Deployment 管理的 Pod 自动带上了名字,命名的规则是 Deployment 的名字加上两串随机数(其实是 Pod 模板的 Hash 值)。
# 测试宕机, 随机删除一个 pod
kubectl delete pod ngx-dep-6796688696-jm6tt
# 查询
kubectl get pod
# 发现删除一个 pod 后, 查询的 pod 数量还是 2 个. 这就证明,Deployment 确实实现了它预定的目标,能够让应用“永远在线”“永不宕机
在 Deployment 部署成功之后,你还可以随时调整 Pod 的数量,实现所谓的“应用伸缩”
kubectl scale 是专门用于实现“扩容”和“缩容”的命令,你只要用参数 --replicas 指定需要的副本数量,Kubernetes 就会自动增加或者删除 Pod,让最终的 Pod 数量达到“期望状态”。
# 手动把 Nginx 应用扩容到了 5 个
kubectl scale --replicas=5 deploy ngx-dep
注意, kubectl scale 是命令式操作,扩容和缩容只是临时的措施,如果应用需要长时间保持一个确定的 Pod 数量,最好还是编辑 Deployment 的 YAML 文件,改动“replicas”,再以声明式的 kubectl apply 修改对象的状态。
之前我们通过 labels 为对象“贴”了各种“标签”,在使用 kubectl get 命令的时候,加上参数 -l,使用 ==、!=、in、notin 的表达式,就能够很容易地用“标签”筛选、过滤出所要查找的对象(有点类似社交媒体的 #tag 功能),效果和 Deployment 里的 selector 字段是一样的。
看两个例子,第一条命令找出“app”标签是 nginx 的所有 Pod,第二条命令找出“app”标签是 ngx、nginx、ngx-dep 的所有 Pod:
kubectl get pod -l app=nginx
kubectl get pod -l 'app in (ngx, nginx, ngx-dep)'

小结
- Pod 只能管理容器,不能管理自身,所以就出现了 Deployment,由它来管理 Pod。
- Deployment 里有三个关键字段,其中的 template 和 Job 一样,定义了要运行的 Pod 模板。
- replicas 字段定义了 Pod 的“期望数量”,Kubernetes 会自动维护 Pod 数量到正常水平。
- selector 字段定义了基于 labels 筛选 Pod 的规则,它必须与 template 里 Pod 的 labels 一致。
- 创建 Deployment 使用命令 kubectl apply,应用的扩容、缩容使用命令 kubectl scale。
作为 Kubernetes 里最常用的对象,Deployment 的本事还不止这些,它还支持滚动更新、版本回退,自动伸缩等高级功能

19|Daemonset:忠实可靠的看门狗
另一类代表在线业务 API 对象:DaemonSet,它会在 Kubernetes 集群的每个节点上都运行一个 Pod,就好像是 Linux 系统里的“守护进程”(Daemon)。
为什么要有 DaemonSet
Deployment,它能够创建任意多个的 Pod 实例,并且维护这些 Pod 的正常运行,保证应用始终处于可用状态。
但是,Deployment 并不关心这些 Pod 会在集群的哪些节点上运行,在它看来,Pod 的运行环境与功能是无关的,只要 Pod 的数量足够,应用程序应该会正常工作。
这个假设对于大多数业务来说是没问题的,比如 Nginx、WordPress、MySQL,它们不需要知道集群、节点的细节信息,只要配置好环境变量和存储卷,在哪里“跑”都是一样的。
但是有一些业务比较特殊,它们不是完全独立于系统运行的,而是与主机存在“绑定”关系,必须要依附于节点才能产生价值,比如说:
- 网络应用(如 kube-proxy),必须每个节点都运行一个 Pod,否则节点就无法加入 Kubernetes 网络。
- 监控应用(如 Prometheus),必须每个节点都有一个 Pod 用来监控节点的状态,实时上报信息。
- 日志应用(如 Fluentd),必须在每个节点上运行一个 Pod,才能够搜集容器运行时产生的日志数据。
- 安全应用,同样的,每个节点都要有一个 Pod 来执行安全审计、入侵检查、漏洞扫描等工作。
这些业务如果用 Deployment 来部署就不太合适了,因为 Deployment 所管理的 Pod 数量是固定的,而且可能会在集群里“漂移”,但,实际的需求却是要在集群里的每个节点上都运行 Pod,也就是说 Pod 的数量与节点数量保持同步。
所以,Kubernetes 就定义了新的 API 对象 DaemonSet,它在形式上和 Deployment 类似,都是管理控制 Pod,但管理调度策略却不同。DaemonSet 的目标是在集群的每个节点上运行且仅运行一个 Pod,就好像是为节点配上一只“看门狗”,忠实地“守护”着节点,这就是 DaemonSet 名字的由来。
如何使用 YAML 描述 DaemonSet
DaemonSet 和 Deployment 都属于在线业务,所以它们也都是“apps”组,使用命令 kubectl api-resources 可以知道它的简称是 ds ,YAML 文件头信息应该是:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: xxx-ds
不过非常奇怪,kubectl 不提供自动创建 DaemonSet YAML 样板的功能,也就是说,我们不能用命令 kubectl create 直接创建出一个 DaemonSet 对象。
这个缺点对于我们使用 DaemonSet 的确造成了不小的麻烦,毕竟如果用 kubectl explain 一个个地去查字段再去写 YAML 实在是太辛苦了。
不过,Kubernetes 不给我们生成样板文件的机会,我们也可以自己去“抄”。你可以在 Kubernetes 的官网(https://kubernetes.io/zh/docs/concepts/workloads/controllers/daemonset/)上找到一份 DaemonSet 的 YAML 示例,把它拷贝下来,再去掉多余的部分,就可以做成自己的一份样板文件,大概是下面的这个样子:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: redis-ds
labels:
app: redis-ds
spec:
selector:
matchLabels:
name: redis-ds
template:
metadata:
labels:
name: redis-ds
spec:
containers:
- image: redis:5-alpine
name: redis
ports:
- containerPort: 6379

了解到这些区别,现在,我们就可以用变通的方法来创建 DaemonSet 的 YAML 样板了,你只需要用 kubectl create 先创建出一个 Deployment 对象,然后把 kind 改成 DaemonSet,再删除 spec.replicas 就行了,比如:
export out="--dry-run=client -o yaml"
# change "kind" to DaemonSet
kubectl create deploy redis-ds --image=redis:5-alpine $out
如何在 Kubernetes 里使用 DaemonSet
现在,让我们执行命令 kubectl apply,把 YAML 发送给 Kubernetes,让它创建 DaemonSet 对象,再用 kubectl get 查看对象的状态:

看这张截图,虽然我们没有指定 DaemonSet 里 Pod 要运行的数量,但它自己就会去查找集群里的节点,在节点里创建 Pod。因为我们的实验环境里有一个 Master 一个 Worker,而 Master 默认是不跑应用的,所以 DaemonSet 就只生成了一个 Pod,运行在了“worker”节点上。
暂停一下,你发现这里有什么不对劲了吗?
按照 DaemonSet 的本意,应该在每个节点上都运行一个 Pod 实例才对,但 Master 节点却被排除在外了,这就不符合我们当初的设想了。
显然,DaemonSet 没有尽到“看门”的职责,它的设计与 Kubernetes 集群的工作机制发生了冲突,有没有办法解决呢?
当然,Kubernetes 早就想到了这点,为了应对 Pod 在某些节点的“调度”和“驱逐”问题,它定义了两个新的概念:污点(taint)和容忍度(toleration)。
什么是污点(taint)和容忍度(toleration)
“污点”是 Kubernetes 节点的一个属性,它的作用也是给节点“贴标签”,但为了不和已有的 labels 字段混淆,就改成了 taint。
和“污点”相对的,就是 Pod 的“容忍度”,顾名思义,就是 Pod 能否“容忍”污点。
我们把它俩放在一起就比较好理解了。集群里的节点各式各样,有的节点“纯洁无瑕”,没有“污点”;而有的节点因为某种原因粘上了“泥巴”,也就有了“污点”。Pod 也脾气各异,有的“洁癖”很严重,不能容忍“污点”,只能挑选“干净”的节点;而有的 Pod 则比较“大大咧咧”,要求不那么高,可以适当地容忍一些小“污点”。
这么看来,“污点”和“容忍度”倒是有点像是一个“相亲”的过程。Pod 就是一个挑剔的“甲方”,而“乙方”就是集群里的各个节点,Pod 会根据自己对“污点”的“容忍程度”来选择合适的目标,比如要求“不抽烟不喝酒”,但可以“无车无房”,最终决定在哪个节点上“落户”。
Kubernetes 在创建集群的时候会自动给节点 Node 加上一些“污点”,方便 Pod 的调度和部署。你可以用 kubectl describe node 来查看 Master 和 Worker 的状态:
kubectl describe node master
Name: master
Roles: control-plane,master
...
Taints: node-role.kubernetes.io/master:NoSchedule
...
kubectl describe node worker
Name: worker
Roles: <none>
...
Taints: <none>
...
可以看到,Master 节点默认有一个 taint,名字是 node-role.kubernetes.io/master,它的效果是 NoSchedule,也就是说这个污点会拒绝 Pod 调度到本节点上运行,而 Worker 节点的 taint 字段则是空的。
这正是 Master 和 Worker 在 Pod 调度策略上的区别所在,通常来说 Pod 都不能容忍任何“污点”,所以加上了 taint 属性的 Master 节点也就会无缘 Pod 了。
明白了“污点”和“容忍度”的概念,你就知道该怎么让 DaemonSet 在 Master 节点(或者任意其他节点)上运行了,方法有两种。
第一种方法是去掉 Master 节点上的 taint,让 Master 变得和 Worker 一样“纯洁无瑕”,DaemonSet 自然就不需要再区分 Master/Worker。
操作 Node 上的“污点”属性需要使用命令 kubectl taint,然后指定节点名、污点名和污点的效果,去掉污点要额外加上一个 -。
比如要去掉 Master 节点的“NoSchedule”效果,就要用这条命令:
kubectl taint node master node-role.kubernetes.io/master:NoSchedule-node/master untainted
因为 DaemonSet 一直在监控集群节点的状态,命令执行后 Master 节点已经没有了“污点”,所以它立刻就会发现变化,然后就会在 Master 节点上创建一个“守护”Pod。你可以用 kubectl get 来查看这个变动情况:

但是,这种方法修改的是 Node 的状态,影响面会比较大,可能会导致很多 Pod 都跑到这个节点上运行,所以我们可以保留 Node 的“污点”,为需要的 Pod 添加“容忍度”,只让某些 Pod 运行在个别节点上,实现“精细化”调度。
这就是第二种方法,为 Pod 添加字段 tolerations,让它能够“容忍”某些“污点”,就可以在任意的节点上运行了。
tolerations 是一个数组,里面可以列出多个被“容忍”的“污点”,需要写清楚“污点”的名字、效果。比较特别是要用 operator 字段指定如何匹配“污点”,一般我们都使用 Exists,也就是说存在这个名字和效果的“污点”。
如果我们想让 DaemonSet 里的 Pod 能够在 Master 节点上运行,就要写出这样的一个 tolerations,容忍节点的 node-role.kubernetes.io/master:NoSchedule 这个污点:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
operator: Exists
现在我们先用 kubectl taint 命令把 Master 的“污点”加上:
kubectl taint node master node-role.kubernetes.io/master:NoSchedule-node/master tainted
然后我们再重新部署加上了“容忍度”的 DaemonSet:
kubectl apply -f ds.yml

你就会看到 DaemonSet 仍然有两个 Pod,分别运行在 Master 和 Worker 节点上,与第一种方法的效果相同。
需要特别说明一下,“容忍度”并不是 DaemonSet 独有的概念,而是从属于 Pod,所以理解了“污点”和“容忍度”之后,你可以在 Job/CronJob、Deployment 里为它们管理的 Pod 也加上 tolerations,从而能够更灵活地调度应用。
至于都有哪些污点、污点有哪些效果我就不细说了,Kubernetes 官网文档(https://kubernetes.io/zh/docs/concepts/scheduling-eviction/taint-and-toleration/)上都列的非常清楚,在理解了工作原理之后,相信你自己学起来也不会太难。
什么是静态 Pod
DaemonSet 是在 Kubernetes 里运行节点专属 Pod 最常用的方式,但它不是唯一的方式,Kubernetes 还支持另外一种叫“静态 Pod”的应用部署手段。
“静态 Pod”非常特殊,它不受 Kubernetes 系统的管控,不与 apiserver、scheduler 发生关系,所以是“静态”的。
但既然它是 Pod,也必然会“跑”在容器运行时上,也会有 YAML 文件来描述它,而唯一能够管理它的 Kubernetes 组件也就只有在每个节点上运行的 kubelet 了。
“静态 Pod”的 YAML 文件默认都存放在节点的 /etc/kubernetes/manifests 目录下,它是 Kubernetes 的专用目录。
下面的这张截图就是 Master 节点里目录的情况:
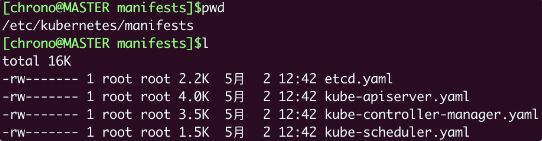
你可以看到,Kubernetes 的 4 个核心组件 apiserver、etcd、scheduler、controller-manager 原来都以静态 Pod 的形式存在的,这也是为什么它们能够先于 Kubernetes 集群启动的原因。
如果你有一些 DaemonSet 无法满足的特殊的需求,可以考虑使用静态 Pod,编写一个 YAML 文件放到这个目录里,节点的 kubelet 会定期检查目录里的文件,发现变化就会调用容器运行时创建或者删除静态 Pod。
小结
-
DaemonSet 的目标是为集群里的每个节点部署唯一的 Pod,常用于监控、日志等业务。
-
DaemonSet 的 YAML 描述与 Deployment 非常接近,只是没有 replicas 字段。
-
“污点”和“容忍度”是与 DaemonSet 相关的两个重要概念,分别从属于 Node 和 Pod,共同决定了 Pod 的调度策略。
-
静态 Pod 也可以实现和 DaemonSet 同样的效果,但它不受 Kubernetes 控制,必须在节点上纯手动部署,应当慎用。

20|Service:微服务架构的应对之道
为什么要有 Service
在应用程序快速版本迭代的同时,另一个问题也逐渐显现出来了,就是“服务发现”。
在 Kubernetes 集群里 Pod 的生命周期是比较“短暂”的,虽然 Deployment 和 DaemonSet 可以维持 Pod 总体数量的稳定,但在运行过程中,难免会有 Pod 销毁又重建,这就会导致 Pod 集合处于动态的变化之中。
这种“动态稳定”对于现在流行的微服务架构来说是非常致命的,试想一下,后台 Pod 的 IP 地址老是变来变去,客户端该怎么访问呢?如果不处理好这个问题,Deployment 和 DaemonSet 把 Pod 管理得再完善也是没有价值的。
这个问题也并不是什么难事,业内早就有解决方案来针对这样“不稳定”的后端服务,那就是“负载均衡”,典型的应用有 LVS、Nginx 等等。它们在前端与后端之间加入了一个“中间层”,屏蔽后端的变化,为前端提供一个稳定的服务。
但 LVS、Nginx 毕竟不是云原生技术,所以 Kubernetes 就按照这个思路,定义了新的 API 对象:Service。
Service 的工作原理和 LVS、Nginx 差不多,Kubernetes 会给它分配一个静态 IP 地址,然后它再去自动管理、维护后面动态变化的 Pod 集合,当客户端访问 Service,它就根据某种策略,把流量转发给后面的某个 Pod。

这里 Service 使用了 iptables 技术,每个节点上的 kube-proxy 组件自动维护 iptables 规则,客户不再关心 Pod 的具体地址,只要访问 Service 的固定 IP 地址,Service 就会根据 iptables 规则转发请求给它管理的多个 Pod,是典型的负载均衡架构。除此之外还有性能更差的 userspace 和性能更好的 ipvs.
如何使用 YAML 描述 Service
照例我们还是可以用命令 kubectl api-resources 查看它的基本信息,可以知道它的简称是svc,apiVersion 是 v1。注意,这说明它与 Pod 一样,属于 Kubernetes 的核心对象,不关联业务应用,与 Job、Deployment 是不同的。
apiVersion: v1
kind: Service
metadata:
name: xxx-svc
同样的,能否让 Kubernetes 为我们自动创建 Service 的 YAML 样板呢?还是使用命令 kubectl create 吗?
这里 Kubernetes 又表现出了行为上的不一致。虽然它可以自动创建 YAML 样板,但不是用命令 kubectl create,而是另外一个命令 kubectl expose,也许 Kubernetes 认为“expose”能够更好地表达 Service“暴露”服务地址的意思吧。
因为在 Kubernetes 里提供服务的是 Pod,而 Pod 又可以用 Deployment/DaemonSet 对象来部署,所以 kubectl expose 支持从多种对象创建服务,Pod、Deployment、DaemonSet 都可以。
exportout="--dry-run=client -o yaml"
kubectl expose deploy ngx-dep --port=80--target-port=80 $out
生成的 Service YAML 大概是这样的:
# Service 的定义非常简单,在“spec”里只有两个关键字段,selector 和 ports。
apiVersion: v1
kind: Service
metadata:
name: ngx-svc
spec:
selector:
app: ngx-dep
ports:
- port: 80 # 外部端口
targetPort: 80 # 内部端口
protocol: TCP
selector 和 Deployment/DaemonSet 里的作用是一样的,用来过滤出要代理的那些 Pod。因为我们指定要代理 Deployment,所以 Kubernetes 就为我们自动填上了 ngx-dep 的标签,会选择这个 Deployment 对象部署的所有 Pod。
ports 就很好理解了,里面的三个字段分别表示外部端口、内部端口和使用的协议,在这里就是内外部都使用 80 端口,协议是 TCP。
当然,你在这里也可以把 ports 改成“8080”等其他的端口,这样外部服务看到的就是 Service 给出的端口,而不会知道 Pod 的真正服务端口。
为了让你看清楚 Service 与它引用的 Pod 的关系,我把这两个 YAML 对象画在了下面的这张图里,需要重点关注的是 selector、targetPort 与 Pod 的关联:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fu0mvp9t-1685935106183)(/Users/songyujian/Library/Application Support/typora-user-images/image-20230605111339716.png)]
如何在 Kubernetes 里使用 Service
首先,我们创建一个 ConfigMap,定义一个 Nginx 的配置片段,它会输出服务器的地址、主机名、请求的 URI 等基本信息:
apiVersion: v1
kind: ConfigMap
metadata:
name: ngx-conf
data:
default.conf: |
server {
listen 80;
location / {
default_type text/plain;
return 200
'srv : $server_addr:$server_port\nhost: $hostname\nuri : $request_method $host $request_uri\ndate: $time_iso8601\n';
}
}
然后我们在 Deployment 的“template.volumes”里定义存储卷,再用“volumeMounts”把配置文件加载进 Nginx 容器里:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ngx-dep
spec:
replicas: 2
selector:
matchLabels:
app: ngx-dep
template:
metadata:
labels:
app: ngx-dep
spec:
volumes:
- name: ngx-conf-vol
configMap:
name: ngx-conf
containers:
- image: nginx:alpine
name: nginx
ports:
- containerPort: 80
volumeMounts:
- mountPath: /etc/nginx/conf.d
name: ngx-conf-vol
部署这个 Deployment 之后,我们就可以创建 Service 对象了,用的还是 kubectl apply:
kubectl apply -f svc.yml
kubectl get svc

你可以看到,Kubernetes 为 Service 对象自动分配了一个 IP 地址“10.96.240.115”,这个地址段是独立于 Pod 地址段的(比如第 17 讲里的 10.10.xx.xx)。而且 Service 对象的 IP 地址还有一个特点,它是一个“*虚地址*”,不存在实体,只能用来转发流量。
想要看 Service 代理了哪些后端的 Pod,你可以用 kubectl describe 命令:
kubectl describe svc ngx-svc

截图里显示 Service 对象管理了两个 endpoint,分别是“10.10.0.232:80”和“10.10.1.86:80”,初步判断与 Service、Deployment 的定义相符,那么这两个 IP 地址是不是 Nginx Pod 的实际地址呢?
我们还是用 kubectl get pod 来看一下,加上参数 -o wide:
kubectl get pod -o wide

把 Pod 的地址与 Service 的信息做个对比,我们就能够验证 Service 确实用一个静态 IP 地址代理了两个 Pod 的动态 IP 地址。
那怎么测试 Service 的负载均衡效果呢?
因为 Service、 Pod 的 IP 地址都是 Kubernetes 集群的内部网段,所以我们需要用 kubectl exec 进入到 Pod 内部(或者 ssh 登录集群节点),再用 curl 等工具来访问 Service:
kubectl exec -it ngx-dep-6796688696-r2j6t --sh

在 Pod 里,用 curl 访问 Service 的 IP 地址,就会看到它把数据转发给后端的 Pod,输出信息会显示具体是哪个 Pod 响应了请求,就表明 Service 确实完成了对 Pod 的负载均衡任务。
我们再试着删除一个 Pod,看看 Service 是否会更新后端 Pod 的信息,实现自动化的服务发现:
kubectl delete pod ngx-dep-6796688696-r2j6t

由于 Pod 被 Deployment 对象管理,删除后会自动重建,而 Service 又会通过 controller-manager 实时监控 Pod 的变化情况,所以就会立即更新它代理的 IP 地址。通过截图你就可以看到有一个 IP 地址“10.10.1.86”消失了,换成了新的“10.10.1.87”,它就是新创建的 Pod。
你也可以再尝试一下使用“ping”来测试 Service 的 IP 地址:

会发现根本 ping 不通,因为 Service 的 IP 地址是“虚”的,只用于转发流量,所以 ping 无法得到回应数据包,也就失败了。
如何以域名的方式使用 Service
Service 高级特性 – DNS 域名
Service 对象的 IP 地址是静态的,保持稳定,这在微服务里确实很重要,不过数字形式的 IP 地址用起来还是不太方便。这个时候 Kubernetes 的 DNS 插件就派上了用处,它可以为 Service 创建易写易记的域名,让 Service 更容易使用。
使用 DNS 域名之前,我们要先了解一个新的概念:名字空间(namespace)。
注意它与我们在第 2 讲里说的用于资源隔离的 Linux namespace 技术完全不同,千万不要弄混了。Kubernetes 只是借用了这个术语,但目标是类似的,用来在集群里实现对 API 对象的隔离和分组。
namespace 的简写是“ns”,你可以使用命令 kubectl get ns 来查看当前集群里都有哪些名字空间,也就是说 API 对象有哪些分组:
kubectl get ns
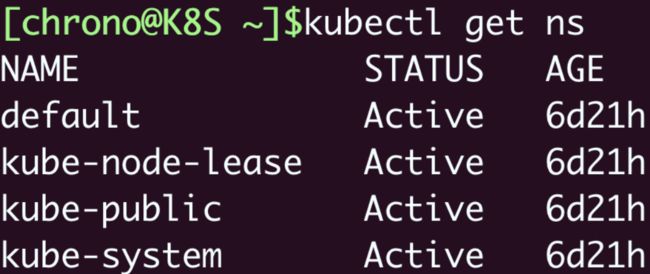
Kubernetes 有一个默认的名字空间,叫“default”,如果不显式指定,API 对象都会在这个“default”名字空间里。而其他的名字空间都有各自的用途,比如“kube-system”就包含了 apiserver、etcd 等核心组件的 Pod。
因为 DNS 是一种层次结构,为了避免太多的域名导致冲突,Kubernetes 就把名字空间作为域名的一部分,减少了重名的可能性。
Service 对象的域名完全形式是“对象. 名字空间.svc.cluster.local”,但很多时候也可以省略后面的部分,直接写“对象. 名字空间”甚至“对象名”就足够了,默认会使用对象所在的名字空间(比如这里就是 default)。
现在我们来试验一下 DNS 域名的用法,还是先 kubectl exec 进入 Pod,然后用 curl 访问 ngx-svc、ngx-svc.default 等域名:

可以看到,现在我们就不再关心 Service 对象的 IP 地址,只需要知道它的名字,就可以用 DNS 的方式去访问后端服务。
比起 Docker,这无疑是一个巨大的进步,而且对比其他微服务框架(如 Dubbo、Spring Cloud),由于服务发现机制被集成在了基础设施里,也会让应用的开发更加便捷。
(顺便说一下,Kubernetes 也为每个 Pod 分配了域名,形式是“*IP 地址. 名字空间.pod.cluster.local*”,但需要把 IP 地址里的 . 改成 - 。比如地址 10.10.1.87,它对应的域名就是 10-10-1-87.default.pod。)
如何让 Service 对外暴露服务
由于 Service 是一种负载均衡技术,所以它不仅能够管理 Kubernetes 集群内部的服务,还能够担当向集群外部暴露服务的重任。
Service 对象有一个关键字段“type”,表示 Service 是哪种类型的负载均衡。前面我们看到的用法都是对集群内部 Pod 的负载均衡,所以这个字段的值就是默认的“ClusterIP”,Service 的静态 IP 地址只能在集群内访问。
除了“ClusterIP”,Service 还支持其他三种类型,分别是“ExternalName”“LoadBalancer”“NodePort”。不过前两种类型一般由云服务商提供,我们的实验环境用不到,所以接下来就重点看“NodePort”这个类型。
如果我们在使用命令 kubectl expose 的时候加上参数 --type=NodePort,或者在 YAML 里添加字段 type:NodePort,那么 Service 除了会对后端的 Pod 做负载均衡之外,还会在集群里的每个节点上创建一个独立的端口,用这个端口对外提供服务,这也正是“NodePort”这个名字的由来。
让我们修改一下 Service 的 YAML 文件,加上字段“type”:
apiVersion: v1
...
spec:
...
type: NodePort
然后创建对象,再查看它的状态:
kubectl get svc

就会看到“TYPE”变成了“NodePort”,而在“PORT”列里的端口信息也不一样,除了集群内部使用的“80”端口,还多出了一个“30651”端口,这就是 Kubernetes 在节点上为 Service 创建的专用映射端口。
因为这个端口号属于节点,外部能够直接访问,所以现在我们就可以不用登录集群节点或者进入 Pod 内部,直接在集群外使用任意一个节点的 IP 地址,就能够访问 Service 和它代理的后端服务了。
比如我现在所在的服务器是“192.168.10.208”,在这台主机上用 curl 访问 Kubernetes 集群的两个节点“192.168.10.210”“192.168.10.220”,就可以得到 Nginx Pod 的响应数据:
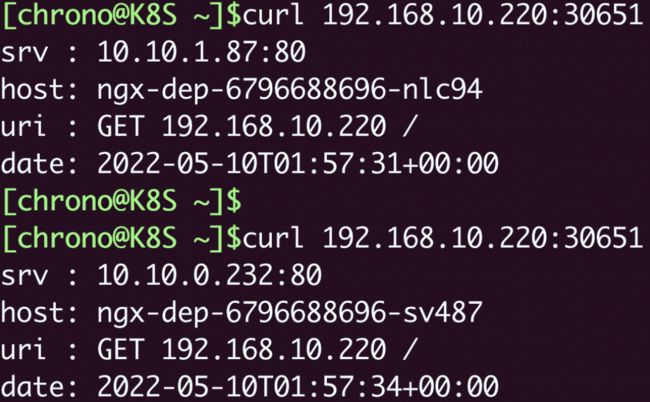
我把 NodePort 与 Service、Deployment 的对应关系画成了图,你看了应该就能更好地明白它的工作原理:

学到这里,你是不是觉得 NodePort 类型的 Service 很方便呢。
不过它也有一些缺点。
第一个缺点是它的端口数量很有限。Kubernetes 为了避免端口冲突,默认只在“30000~32767”这个范围内随机分配,只有 2000 多个,而且都不是标准端口号,这对于具有大量业务应用的系统来说根本不够用。
第二个缺点是它会在每个节点上都开端口,然后使用 kube-proxy 路由到真正的后端 Service,这对于有很多计算节点的大集群来说就带来了一些网络通信成本,不是特别经济。
第三个缺点,它要求向外界暴露节点的 IP 地址,这在很多时候是不可行的,为了安全还需要在集群外再搭一个反向代理,增加了方案的复杂度。
虽然有这些缺点,但 NodePort 仍然是 Kubernetes 对外提供服务的一种简单易行的方式,在其他更好的方式出现之前,我们也只能使用它。
小结
好了,今天我们学习了 Service 对象,它实现了负载均衡和服务发现技术,是 Kubernetes 应对微服务、服务网格等现代流行应用架构的解决方案。
我再小结一下今天的要点:
- Pod 的生命周期很短暂,会不停地创建销毁,所以就需要用 Service 来实现负载均衡,它由 Kubernetes 分配固定的 IP 地址,能够屏蔽后端的 Pod 变化。
- Service 对象使用与 Deployment、DaemonSet 相同的“selector”字段,选择要代理的后端 Pod,是松耦合关系。
- 基于 DNS 插件,我们能够以域名的方式访问 Service,比静态 IP 地址更方便。
- 名字空间是 Kubernetes 用来隔离对象的一种方式,实现了逻辑上的对象分组,Service 的域名里就包含了名字空间限定。
- Service 的默认类型是“ClusterIP”,只能在集群内部访问,如果改成“NodePort”,就会在节点上开启一个随机端口号,让外界也能够访问内部的服务。
21|Ingress:集群进出流量的总管
为什么要有 Ingress
Service 的功能和运行机制,它本质上就是一个由 kube-proxy 控制的四层负载均衡,在 TCP/IP 协议栈上转发流量(Service 工作原理示意图):
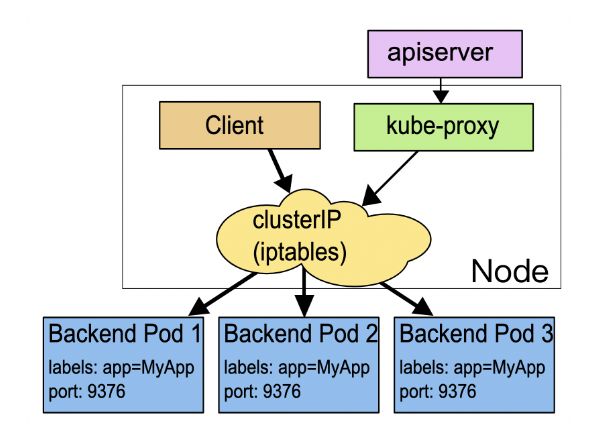
在四层上的负载均衡功能还是太有限了,只能够依据 IP 地址和端口号做一些简单的判断和组合,而我们现在的绝大多数应用都是跑在七层的 HTTP/HTTPS 协议上的,有更多的高级路由条件,比如主机名、URI、请求头、证书等等,而这些在 TCP/IP 网络栈里是根本看不见的。
Service 还有一个缺点,它比较适合代理集群内部的服务。如果想要把服务暴露到集群外部,就只能使用 NodePort 或者 LoadBalancer 这两种方式,而它们都缺乏足够的灵活性,难以管控,这就导致了一种很无奈的局面:我们的服务空有一身本领,却没有合适的机会走出去大展拳脚。
该怎么解决这个问题呢?
Kubernetes 还是沿用了 Service 的思路,既然 Service 是四层的负载均衡,那么我再引入一个新的 API 对象,在七层上做负载均衡是不是就可以了呢?
不过除了七层负载均衡,这个对象还应该承担更多的职责,也就是作为流量的总入口,统管集群的进出口数据,“扇入”“扇出”流量(也就是我们常说的“南北向”),让外部用户能够安全、顺畅、便捷地访问内部服务:

所以,这个 API 对象就顺理成章地被命名为 Ingress,意思就是集群内外边界上的入口。
为什么要有 Ingress Controller
Ingress 可以说是在七层上另一种形式的 Service,它同样会代理一些后端的 Pod,也有一些路由规则来定义流量应该如何分配、转发,只不过这些规则都使用的是 HTTP/HTTPS 协议。
你应该知道,Service 本身是没有服务能力的,它只是一些 iptables 规则,真正配置、应用这些规则的实际上是节点里的 kube-proxy 组件。如果没有 kube-proxy,Service 定义得再完善也没有用。
同样的,Ingress 也只是一些 HTTP 路由规则的集合,相当于一份静态的描述文件,真正要把这些规则在集群里实施运行,还需要有另外一个东西,这就是 Ingress Controller,它的作用就相当于 Service 的 kube-proxy,能够读取、应用 Ingress 规则,处理、调度流量。
按理来说,Kubernetes 应该把 Ingress Controller 内置实现,作为基础设施的一部分,就像 kube-proxy 一样。
不过 Ingress Controller 要做的事情太多,与上层业务联系太密切,所以 Kubernetes 把 Ingress Controller 的实现交给了社区,任何人都可以开发 Ingress Controller,只要遵守 Ingress 规则就好。
由于 Ingress Controller 把守了集群流量的关键入口,掌握了它就拥有了控制集群应用的“话语权”,所以众多公司纷纷入场,精心打造自己的 Ingress Controller,意图在 Kubernetes 流量进出管理这个领域占有一席之地。
这些实现中最著名的,就是老牌的反向代理和负载均衡软件 Nginx 了。从 Ingress Controller 的描述上我们也可以看到,HTTP 层面的流量管理、安全控制等功能其实就是经典的反向代理,而 Nginx 则是其中稳定性最好、性能最高的产品,所以它也理所当然成为了 Kubernetes 里应用得最广泛的 Ingress Controller。
不过,因为 Nginx 是开源的,谁都可以基于源码做二次开发,所以它又有很多的变种,比如社区的 Kubernetes Ingress Controller(https://github.com/kubernetes/ingress-nginx)、Nginx 公司自己的 Nginx Ingress Controller(https://github.com/nginxinc/kubernetes-ingress)、还有基于 OpenResty 的 Kong Ingress Controller(https://github.com/Kong/kubernetes-ingress-controller)等等。
根据 Docker Hub 上的统计,Nginx 公司的开发实现是下载量最多的 Ingress Controller,所以我将以它为例,讲解 Ingress 和 Ingress Controller 的用法。
下面的这张图就来自 Nginx 官网,比较清楚地展示了 Ingress Controller 在 Kubernetes 集群里的地位:

为什么要有 IngressClass
那么到现在,有了 Ingress 和 Ingress Controller,我们是不是就可以完美地管理集群的进出流量了呢?
最初 Kubernetes 也是这么想的,一个集群里有一个 Ingress Controller,再给它配上许多不同的 Ingress 规则,应该就可以解决请求的路由和分发问题了。
但随着 Ingress 在实践中的大量应用,很多用户发现这种用法会带来一些问题,比如:
- 由于某些原因,项目组需要引入不同的 Ingress Controller,但 Kubernetes 不允许这样做;
- Ingress 规则太多,都交给一个 Ingress Controller 处理会让它不堪重负;
- 多个 Ingress 对象没有很好的逻辑分组方式,管理和维护成本很高;
- 集群里有不同的租户,他们对 Ingress 的需求差异很大甚至有冲突,无法部署在同一个 Ingress Controller 上。
所以,Kubernetes 就又提出了一个 Ingress Class 的概念,让它插在 Ingress 和 Ingress Controller 中间,作为流量规则和控制器的协调人,解除了 Ingress 和 Ingress Controller 的强绑定关系。
现在,Kubernetes 用户可以转向管理 Ingress Class,用它来定义不同的业务逻辑分组,简化 Ingress 规则的复杂度。比如说,我们可以用 Class A 处理博客流量、Class B 处理短视频流量、Class C 处理购物流量。

这些 Ingress 和 Ingress Controller 彼此独立,不会发生冲突,所以上面的那些问题也就随着 Ingress Class 的引入迎刃而解了。
如何使用 YAML 描述 Ingress/Ingress Class
和之前学习 Deployment、Service 对象一样,首先应当用命令 kubectl api-resources 查看它们的基本信息,输出列在这里了:
kubectl api-resources
NAME SHORTNAMES APIVERSION NAMESPACED KIND
ingresses ing networking.k8s.io/v1 true Ingress
ingressclasses networking.k8s.io/v1 false IngressClass
你可以看到,Ingress 和 Ingress Class 的 apiVersion 都是“networking.k8s.io/v1”,而且 Ingress 有一个简写“ing”,但 Ingress Controller 怎么找不到呢?
这是因为 Ingress Controller 和其他两个对象不太一样,它不只是描述文件,是一个要实际干活、处理流量的应用程序,而应用程序在 Kubernetes 里早就有对象来管理了,那就是 Deployment 和 DaemonSet,所以我们只需要再学习 Ingress 和 Ingress Class 的的用法就可以了。
先看 Ingress。
Ingress 也是可以使用 kubectl create 来创建样板文件的,和 Service 类似,它也需要用两个附加参数:
- class,指定 Ingress 从属的 Ingress Class 对象。
- rule,指定路由规则,基本形式是“URI=Service”,也就是说是访问 HTTP 路径就转发到对应的 Service 对象,再由 Service 对象转发给后端的 Pod。
好,现在我们就执行命令,看看 Ingress 到底长什么样:
export out="--dry-run=client -o yaml"
kubectl create ing ngx-ing --rule="ngx.test/=ngx-svc:80" --class=ngx-ink $out
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ngx-ing
spec:
ingressClassName: ngx-ink
rules:
- host: ngx.test
http:
paths:
- path: /
pathType: Exact
backend:
service:
name: ngx-svc
port:
number: 80
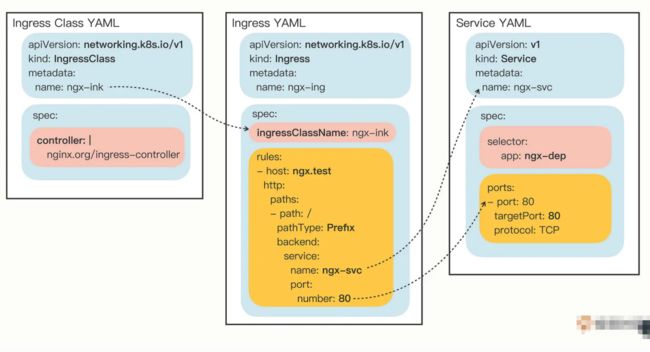
在这份 Ingress 的 YAML 里,有两个关键字段:“ingressClassName”和“rules”,分别对应了命令行参数,含义还是比较好理解的。
只是“rules”的格式比较复杂,嵌套层次很深。不过仔细点看就会发现它是把路由规则拆散了,有 host 和 http path,在 path 里又指定了路径的匹配方式,可以是精确匹配(Exact)或者是前缀匹配(Prefix),再用 backend 来指定转发的目标 Service 对象。
不过我个人觉得,Ingress YAML 里的描述还不如 kubectl create 命令行里的 --rule 参数来得直观易懂,而且 YAML 里的字段太多也很容易弄错,建议你还是让 kubectl 来自动生成规则,然后再略作修改比较好。
有了 Ingress 对象,那么与它关联的 Ingress Class 是什么样的呢?
其实 Ingress Class 本身并没有什么实际的功能,只是起到联系 Ingress 和 Ingress Controller 的作用,所以它的定义非常简单,在“spec”里只有一个必需的字段“controller”,表示要使用哪个 Ingress Controller,具体的名字就要看实现文档了。
比如,如果我要用 Nginx 开发的 Ingress Controller,那么就要用名字“nginx.org/ingress-controller”:
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: ngx-ink
spec:
controller: nginx.org/ingress-controller
Ingress 和 Service、Ingress Class 的关系图
如何在 Kubernetes 里使用 Ingress/Ingress Class
因为 Ingress Class 很小,所以我把它与 Ingress 合成了一个 YAML 文件,让我们用 kubectl apply 创建这两个对象:
kubectl apply -f ingress.yml
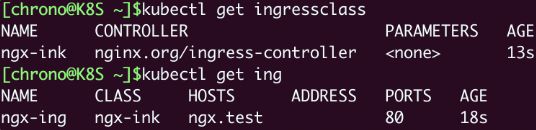
然后我们用 kubectl get 来查看对象的状态:
kubectl get ingressclass
kubectl get ing
命令 kubectl describe 可以看到更详细的 Ingress 信息:
kubectl describe ing ngx-ing
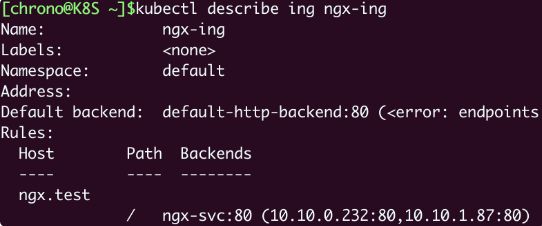
可以看到,Ingress 对象的路由规则 Host/Path 就是在 YAML 里设置的域名“ngx.test/”,而且已经关联了第 20 讲里创建的 Service 对象,还有 Service 后面的两个 Pod。
另外,不要对 Ingress 里“Default backend”的错误提示感到惊讶,在找不到路由的时候,它被设计用来提供一个默认的后端服务,但不设置也不会有什么问题,所以大多数时候我们都忽略它。
如何在 Kubernetes 里使用 Ingress Controller
准备好了 Ingress 和 Ingress Class,接下来我们就需要部署真正处理路由规则的 Ingress Controller。
你可以在 GitHub 上找到 Nginx Ingress Controller 的项目(https://github.com/nginxinc/kubernetes-ingress),因为它以 Pod 的形式运行在 Kubernetes 里,所以同时支持 Deployment 和 DaemonSet 两种部署方式。这里我选择的是 Deployment,相关的 YAML 也都在我们课程的项目(https://github.com/chronolaw/k8s_study/tree/master/ingress)里复制了一份。
Nginx Ingress Controller 的安装略微麻烦一些,有很多个 YAML 需要执行,但如果只是做简单的试验,就只需要用到 4 个 YAML:
kubectl apply -f common/ns-and-sa.yaml
kubectl apply -f rbac/rbac.yaml
kubectl apply -f common/nginx-config.yaml
kubectl apply -f common/default-server-secret.yaml
前两条命令为 Ingress Controller 创建了一个独立的名字空间“nginx-ingress”,还有相应的账号和权限,这是为了访问 apiserver 获取 Service、Endpoint 信息用的;后两条则是创建了一个 ConfigMap 和 Secret,用来配置 HTTP/HTTPS 服务。
部署 Ingress Controller 不需要我们自己从头编写 Deployment,Nginx 已经为我们提供了示例 YAML,但创建之前为了适配我们自己的应用还必须要做几处小改动:
- metadata 里的 name 要改成自己的名字,比如 ngx-kic-dep。
- spec.selector 和 template.metadata.labels 也要修改成自己的名字,比如还是用 ngx-kic-dep。
- containers.image 可以改用 apline 版本,加快下载速度,比如 nginx/nginx-ingress:2.2-alpine。
- 最下面的 args 要加上 -ingress-class=ngx-ink,也就是前面创建的 Ingress Class 的名字,这是让 Ingress Controller 管理 Ingress 的关键。
修改完之后,Ingress Controller 的 YAML 大概是这个样子:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ngx-kic-dep
namespace: nginx-ingress
spec:
replicas: 1
selector:
matchLabels:
app: ngx-kic-dep
template:
metadata:
labels:
app: ngx-kic-dep
...
spec:
containers:
- image: nginx/nginx-ingress:2.2-alpine
...
args:
- -ingress-class=ngx-ink
有了 Ingress Controller,这些 API 对象的关联就更复杂了,你可以用下面的这张图来看出它们是如何使用对象名字联系起来的:

确认 Ingress Controller 的 YAML 修改完毕之后,就可以用 kubectl apply 创建对象:
kubectl apply -f kic.yml
注意 Ingress Controller 位于名字空间“nginx-ingress”,所以查看状态需要用“-n”参数显式指定,否则我们只能看到“default”名字空间里的 Pod:
kubectl get deploy -n nginx-ingress
kubectl get pod -n nginx-ingress

现在 Ingress Controller 就算是运行起来了。
不过还有最后一道工序,因为 Ingress Controller 本身也是一个 Pod,想要向外提供服务还是要依赖于 Service 对象。所以你至少还要再为它定义一个 Service,使用 NodePort 或者 LoadBalancer 暴露端口,才能真正把集群的内外流量打通。这个工作就交给你课下自己去完成了。
这里,我就用第 15 讲里提到的命令kubectl port-forward**,它可以直接把本地的端口映射到 Kubernetes 集群的某个 Pod 里**,在测试验证的时候非常方便。
下面这条命令就把本地的 8080 端口映射到了 Ingress Controller Pod 的 80 端口:
kubectl port-forward -n nginx-ingress ngx-kic-dep-8859b7b86-cplgp 8080:80 &

我们在 curl 发测试请求的时候需要注意,因为 Ingress 的路由规则是 HTTP 协议,所以就不能用 IP 地址的方式访问,必须要用域名、URI。
你可以修改 /etc/hosts 来手工添加域名解析,也可以使用 --resolve 参数,指定域名的解析规则,比如在这里我就把“ngx.test”强制解析到“127.0.0.1”,也就是被 kubectl port-forward 转发的本地地址:
curl --resolve ngx.test:8080:127.0.0.1 http://ngx.test:8080

把这个访问结果和上一节课里的 Service 对比一下,你会发现最终效果是一样的,都是把请求转发到了集群内部的 Pod,但 Ingress 的路由规则不再是 IP 地址,而是 HTTP 协议里的域名、URI 等要素。
小结
好了,今天就讲到这里,我们学习了 Kubernetes 里七层的反向代理和负载均衡对象,包括 Ingress、Ingress Controller、Ingress Class,它们联合起来管理了集群的进出流量,是集群入口的总管。
小结一下今天的主要内容:
- Service 是四层负载均衡,能力有限,所以就出现了 Ingress,它基于 HTTP/HTTPS 协议定义路由规则。
- Ingress 只是规则的集合,自身不具备流量管理能力,需要 Ingress Controller 应用 Ingress 规则才能真正发挥作用。
- Ingress Class 解耦了 Ingress 和 Ingress Controller,我们应当使用 Ingress Class 来管理 Ingress 资源。
- 最流行的 Ingress Controller 是 Nginx Ingress Controller,它基于经典反向代理软件 Nginx。
再补充一点,目前的 Kubernetes 流量管理功能主要集中在 Ingress Controller 上,已经远不止于管理“入口流量”了,它还能管理“出口流量”,也就是 egress,甚至还可以管理集群内部服务之间的“东西向流量”。
此外,Ingress Controller 通常还有很多的其他功能,比如 TLS 终止、网络应用防火墙、限流限速、流量拆分、身份认证、访问控制等等,完全可以认为它是一个全功能的反向代理或者网关,感兴趣的话你可以找找这方面的资料。
22|实战演练:玩转Kubernetes(2)
Kubernetes 技术要点回顾
-
Kubernetes 是云原生时代的操作系统,它能够管理大量节点构成的集群,让计算资源“池化”,从而能够自动地调度运维各种形式的应用。
-
搭建多节点的 Kubernetes 集群是一件颇具挑战性的工作,好在社区里及时出现了 kubeadm 这样的工具,可以“一键操作”,使用 kubeadm init、kubeadm join 等命令从无到有地搭建出生产级别的集群(17 讲)。
-
kubeadm 使用容器技术封装了 Kubernetes 组件,所以只要节点上安装了容器运行时(Docker、containerd 等),它就可以自动从网上拉取镜像,然后以容器的方式运行组件,非常简单方便。
-
在这个更接近实际生产环境的 Kubernetes 集群里,我们学习了 Deployment、DaemonSet、Service、Ingress、Ingress Controller 等 API 对象。
-
(18 讲)Deployment 是用来管理 Pod 的一种对象,它代表了运维工作中最常见的一类在线业务,在集群中部署应用的多个实例,而且可以很容易地增加或者减少实例数量,从容应对流量压力。
-
Deployment 的定义里有两个关键字段:一个是 replicas,它指定了实例的数量;另一个是 selector,它的作用是使用标签“筛选”出被 Deployment 管理的 Pod,这是一种非常灵活的关联机制,实现了 API 对象之间的松耦合。
-
(19 讲)DaemonSet 是另一种部署在线业务的方式,它很类似 Deployment,但会在集群里的每一个节点上运行一个 Pod 实例,类似 Linux 系统里的“守护进程”,适合日志、监控等类型的应用。
-
DaemonSet 能够任意部署 Pod 的关键概念是“污点”(taint)和“容忍度”(toleration)。Node 会有各种“污点”,而 Pod 可以使用“容忍度”来忽略“污点”,合理使用这两个概念就可以调整 Pod 在集群里的部署策略。
-
(20 讲)由 Deployment 和 DaemonSet 部署的 Pod,在集群中处于“动态平衡”的状态,总数量保持恒定,但也有临时销毁重建的可能,所以 IP 地址是变化的,这就为微服务等应用架构带来了麻烦。
-
Service 是对 Pod IP 地址的抽象,它拥有一个固定的 IP 地址,再使用 iptables 规则把流量负载均衡到后面的 Pod,节点上的 kube-proxy 组件会实时维护被代理的 Pod 状态,保证 Service 只会转发给健康的 Pod。
-
Service 还基于 DNS 插件支持域名,所以客户端就不再需要关心 Pod 的具体情况,只要通过 Service 这个稳定的中间层,就能够访问到 Pod 提供的服务。
-
(21 讲)Service 是四层的负载均衡,但现在的绝大多数应用都是 HTTP/HTTPS 协议,要实现七层的负载均衡就要使用 Ingress 对象。
-
Ingress 定义了基于 HTTP 协议的路由规则,但要让规则生效,还需要 Ingress Controller 和 Ingress Class 来配合工作。
-
Ingress Controller 是真正的集群入口,应用 Ingress 规则调度、分发流量,此外还能够扮演反向代理的角色,提供安全防护、TLS 卸载等更多功能。
-
Ingress Class 是用来管理 Ingress 和 Ingress Controller 的概念,方便我们分组路由规则,降低维护成本。
-
不过 Ingress Controller 本身也是一个 Pod,想要把服务暴露到集群外部还是要依靠 Service。Service 支持 NodePort、LoadBalancer 等方式,但 NodePort 的端口范围有限,LoadBalancer 又依赖于云服务厂商,都不是很灵活。
-
折中的办法是用少量 NodePort 暴露 Ingress Controller,用 Ingress 路由到内部服务,外部再用反向代理或者 LoadBalancer 把流量引进来。
WordPress 网站基本架构
简略回顾了 Kubernetes 里这些 API 对象,下面我们就来使用它们再搭建出 WordPress 网站,实践加深理解。
既然我们已经掌握了 Deployment、Service、Ingress 这些 Pod 之上的概念,网站自然会有新变化,架构图我放在了这里:

这次的部署形式比起 Docker、minikube 又有了一些细微的差别,重点是我们已经完全舍弃了 Docker,把所有的应用都放在 Kubernetes 集群里运行,部署方式也不再是裸 Pod,而是使用 Deployment,稳定性大幅度提升。
原来的 Nginx 的作用是反向代理,那么在 Kubernetes 里它就升级成了具有相同功能的 Ingress Controller。WordPress 原来只有一个实例,现在变成了两个实例(你也可以任意横向扩容),可用性也就因此提高了不少。而 MariaDB 数据库因为要保证数据的一致性,暂时还是一个实例。
还有,因为 Kubernetes 内置了服务发现机制 Service,我们再也不需要去手动查看 Pod 的 IP 地址了,只要为它们定义 Service 对象,然后使用域名就可以访问 MariaDB、WordPress 这些服务。
网站对外提供服务我选择了两种方式。
一种是让 WordPress 的 Service 对象以 NodePort 的方式直接对外暴露端口 30088,方便测试;另一种是给 Nginx Ingress Controller 添加“hostNetwork”属性,直接使用节点上的端口号,类似 Docker 的 host 网络模式,好处是可以避开 NodePort 的端口范围限制。
下面我们就按照这个基本架构来逐步搭建出新版本的 WordPress 网站,编写 YAML 声明。
这里有个小技巧,在实际操作的时候你一定要记得善用 kubectl create、kubectl expose 创建样板文件,节约时间的同时,也能避免低级的格式错误。
1. WordPress 网站部署 MariaDB
首先我们还是要部署 MariaDB,这个步骤和在第 15 讲里做的也差不多。
先要用 ConfigMap 定义数据库的环境变量,有 DATABASE、USER、PASSWORD、ROOT_PASSWORD:
apiVersion: v1
kind: ConfigMap
metadata:
name: maria-cm
data:
DATABASE: 'db'
USER: 'wp'
PASSWORD: '123'
ROOT_PASSWORD: '123'
然后我们需要把 MariaDB 由 Pod 改成 Deployment 的方式,replicas 设置成 1 个,template 里面的 Pod 部分没有任何变化,还是要用 envFrom把配置信息以环境变量的形式注入 Pod,相当于把 Pod 套了一个 Deployment 的“外壳”:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: maria-dep
name: maria-dep
spec:
replicas: 1
selector:
matchLabels:
app: maria-dep
template:
metadata:
labels:
app: maria-dep
spec:
containers:
- image: mariadb:10
name: mariadb
ports:
- containerPort: 3306
envFrom:
- prefix: 'MARIADB_'
configMapRef:
name: maria-cm
我们还需要再为 MariaDB 定义一个 Service 对象,映射端口 3306,让其他应用不再关心 IP 地址,直接用 Service 对象的名字来访问数据库服务:
apiVersion: v1
kind: Service
metadata:
labels:
app: maria-dep
name: maria-svc
spec:
ports:
- port: 3306
protocol: TCP
targetPort: 3306
selector:
app: maria-dep
因为这三个对象都是数据库相关的,所以可以在一个 YAML 文件里书写,对象之间用 — 分开,这样用 kubectl apply 就可以一次性创建好:
kubectl apply -f wp-maria.yml
执行命令后,你应该用 kubectl get 查看对象是否创建成功,是否正常运行:

2. WordPress 网站部署 WordPress
第二步是部署 WordPress 应用。
因为刚才创建了 MariaDB 的 Service,所以在写 ConfigMap 配置的时候“HOST”就不应该是 IP 地址了,而应该是 DNS 域名,也就是 Service 的名字maria-svc**,这点需要特别注意**:
apiVersion: v1
kind: ConfigMap
metadata:
name: wp-cm
data:
HOST: 'maria-svc'
USER: 'wp'
PASSWORD: '123'
NAME: 'db'
WordPress 的 Deployment 写法和 MariaDB 也是一样的,给 Pod 套一个 Deployment 的“外壳”,replicas 设置成 2 个,用字段“envFrom”配置环境变量:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: wp-dep
name: wp-dep
spec:
replicas: 2
selector:
matchLabels:
app: wp-dep
template:
metadata:
labels:
app: wp-dep
spec:
containers:
- image: wordpress:5
name: wordpress
ports:
- containerPort: 80
envFrom:
- prefix: 'WORDPRESS_DB_'
configMapRef:
name: wp-cm
然后我们仍然要为 WordPress 创建 Service 对象,这里我使用了“NodePort”类型,并且手工指定了端口号“30088”(必须在 30000~32767 之间):
apiVersion: v1
kind: Service
metadata:
labels:
app: wp-dep
name: wp-svc
spec:
ports:
- name: http80
port: 80
protocol: TCP
targetPort: 80
nodePort: 30088
selector:
app: wp-dep
type: NodePort
现在让我们用 kubectl apply 部署 WordPress:
kubectl apply -f wp-dep.yml

因为 WordPress 的 Service 对象是 NodePort 类型的,我们可以在集群的每个节点上访问 WordPress 服务。
比如一个节点的 IP 地址是“192.168.10.210”,那么你就在浏览器的地址栏里输入“http://192.168.10.210:30088”,其中的“30088”就是在 Service 里指定的节点端口号,然后就能够看到 WordPress 的安装界面了:

3. WordPress 网站部署 Nginx Ingress Controller
现在 MariaDB,WordPress 都已经部署成功了,第三步就是部署 Nginx Ingress Controller。
首先我们需要定义 Ingress Class,名字就叫“wp-ink”,非常简单:
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: wp-ink
spec:
controller: nginx.org/ingress-controller
然后用 kubectl create 命令生成 Ingress 的样板文件,指定域名是“wp.test”,后端 Service 是“wp-svc:80”,Ingress Class 就是刚定义的“wp-ink”:
kubectl create ing wp-ing --rule="wp.test/=wp-svc:80" --class=wp-ink $out
得到的 Ingress YAML 就是这样,注意路径类型我还是用的前缀匹配“Prefix”:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: wp-ing
spec:
ingressClassName: wp-ink
rules:
- host: wp.test
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: wp-svc
port:
number: 80
接下来就是最关键的 Ingress Controller 对象了,它仍然需要从 Nginx 项目的示例 YAML 修改而来,要改动名字、标签,还有参数里的 Ingress Class。
在之前讲基本架构的时候我说过了,这个 Ingress Controller 不使用 Service,而是给它的 Pod 加上一个特殊字段 hostNetwork,让 Pod 能够使用宿主机的网络,相当于另一种形式的 NodePort:
apiVersion: apps/v1
kind: Deployment
metadata:
name: wp-kic-dep
namespace: nginx-ingress
spec:
replicas: 1
selector:
matchLabels:
app: wp-kic-dep
template:
metadata:
labels:
app: wp-kic-dep
spec:
serviceAccountName: nginx-ingress
# use host network
hostNetwork: true
containers:
...
准备好 Ingress 资源后,我们创建这些对象:
kubectl apply -f wp-ing.yml -f wp-kic.yml
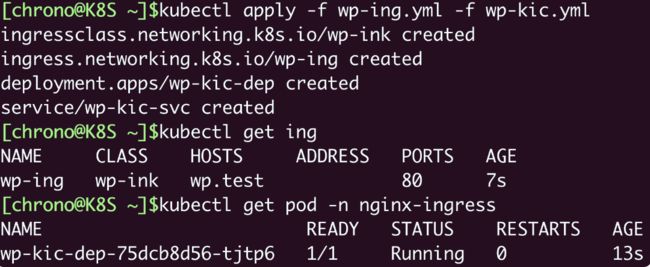
现在所有的应用都已经部署完毕,可以在集群外面访问网站来验证结果了。
不过你要注意,Ingress 使用的是 HTTP 路由规则,用 IP 地址访问是无效的,所以在集群外的主机上必须能够识别我们的“wp.test”域名,也就是说要把域名“wp.test”解析到 Ingress Controller 所在的节点上。
如果你用的是 Mac,那就修改 /etc/hosts;如果你用的是 Windows,就修改 C:\Windows\System32\Drivers\etc\hosts,添加一条解析规则就行:
cat /etc/hosts
192.168.10.210 wp.test
有了域名解析,在浏览器里你就不必使用 IP 地址,直接用域名“wp.test”走 Ingress Controller 就能访问我们的 WordPress 网站了:

23|视频:中级篇实操总结
一. 安装 kubeadm
二. 安装 Kubernetes
三. Kubernetes 集群部署
四. Deployment 的使用
# kubectl api-resources 来查看 Deployment 的基本信息
kubectl api-resources | grep deploy
可以看到 Deployment 的简称是“deploy”,它的 apiVersion 是“apps/v1”,kind 是“Deployment”。
然后我们执行 kubectl create,让 Kubernetes 为我们自动生成 Deployment 的样板文件。
# 先要定义一个环境变量 out:
export out="--dry-run=client -o yaml"
# 然后创建名字叫“ngx-dep”的对象,使用的镜像是“nginx:alpine”:
kubectl create deploy ngx-dep --image=nginx:alpine $out
# 把这个样板存入一个文件 ngx.yml
kubectl create deploy ngx-dep --image=nginx:alpine $out > deploy.yml
# 这里可以删除一些不需要的字段,让 YAML 看起来更干净,然后把 replicas 改成 2,意思是启动两个 Nginx Pod。
# 把 Deployment 的 YAML 写好之后,我们就可以用 kubectl apply 来创建对象了:
kubectl apply -f deploy.yml
# 用 kubectl get 命令查看 Deployment 的状态:
kubectl get deploy
kubectl get pod
# 来试验一下 Deployment 的应用伸缩功能,使用命令 kubectl scale,把 Pod 数量改成 5 个:
kubectl scale --replicas=5 deploy ngx-dep
五. DaemonSet 的使用
因为 DaemonSet 不能使用 kubectl create 直接生成样板文件,但大体结构和 Deployment 是一样的,所以我们可以先生成一个 Deployment,然后再修改几个字段就行了。
这里我使用了 Linux 系统里常用的小工具 sed,直接替换 Deployment 里的名字,再删除 replicas 字段,这样就自动生成了 DaemonSet 的样板文件:
kubectl create deploy redis-ds --image=redis:5-alpine $out \
| sed 's/Deployment/DaemonSet/g' - \
| sed -e '/replicas/d' -
这个样板文件因为是从 Deployment 改来的,所以不会有 tolerations 字段,不能在 Master 节点上运行,需要手工添加。
注意看里面的 tolerations 字段,它能够容忍节点的 node-role.kubernetes.io/master:NoSchedule 这个污点,也就是说能够运行在 Master 节点上。
六. Service 的使用
# 使用 kubectl expose 创建 Service 样板文件
kubectl expose deploy ngx-dep --port=80 --target-port=80 $out
# 修改之后就是 svc.yml,再用 kubectl apply 创建 Service 对象
kubectl apply -f svc.yml
# 用 kubectl get svc 可以列出 Service 对象,可以看到它的虚 IP 地址
kubectl get svc
# 要看 Service 代理了哪些后端的 Pod,要用 kubectl describe 命令
kubectl describe svc ngx-svc
# 用 kubectl get pod 可以对比验证 Service 是否正确代理了 Nginx Pod
kubectl get pod -o wide
# 现在让我们用 kubectl exec 进入 Pod,验证 Service 的域名功能
kubectl exec -it ngx-dep-6796688696-4h6lb -- sh
# 使用 curl,加上域名“ngx-svc”,也就是 Service 对象的名字
curl ngx-svc
# 多执行几次,就会看到通过这个域名,Service 对象实现了对后端 Pod 的负载均衡,把流量分发到不同的 Pod。
# 我们还可以再尝试 Service 的其他域名形式,比如加上名字空间:
curl ngx-svc.default
curl ngx-svc.default.svc.cluster.local
七. Ingress 的使用
24|PersistentVolume:怎么解决数据持久化的难题?
什么是 PersistentVolume
我们在 Kubernetes 集群里搭建了 WordPress 网站,但其中存在一个很严重的问题:Pod 没有持久化功能,导致 MariaDB 无法“永久”存储数据。
因为 Pod 里的容器是由镜像产生的,而镜像文件本身是只读的,进程要读写磁盘只能用一个临时的存储空间,一旦 Pod 销毁,临时存储也就会立即回收释放,数据也就丢失了。
为了保证即使 Pod 销毁后重建数据依然存在,我们就需要找出一个解决方案,让 Pod 用上真正的“虚拟盘”。怎么办呢?
其实,Kubernetes 的 Volume 对数据存储已经给出了一个很好的抽象,它只是定义了有这么一个“存储卷”,而这个“存储卷”是什么类型、有多大容量、怎么存储,我们都可以自由发挥。Pod 不需要关心那些专业、复杂的细节,只要设置好 volumeMounts,就可以把 Volume 加载进容器里使用。
所以,Kubernetes 就顺着 Volume 的概念,延伸出了 PersistentVolume 对象,它专门用来表示持久存储设备,但隐藏了存储的底层实现,我们只需要知道它能安全可靠地保管数据就可以了(由于 PersistentVolume 这个词很长,一般都把它简称为 PV)。
那么,集群里的 PV 都从哪里来呢?
作为存储的抽象,PV 实际上就是一些存储设备、文件系统,比如 Ceph、GlusterFS、NFS,甚至是本地磁盘,管理它们已经超出了 Kubernetes 的能力范围,所以,一般会由系统管理员单独维护,然后再在 Kubernetes 里创建对应的 PV。
要注意的是,PV 属于集群的系统资源,是和 Node 平级的一种对象,Pod 对它没有管理权,只有使用权。
什么是 PersistentVolumeClaim/StorageClass
现在有了 PV,我们是不是可以直接在 Pod 里挂载使用了呢?
还不行。因为不同存储设备的差异实在是太大了:有的速度快,有的速度慢;有的可以共享读写,有的只能独占读写;有的容量小,只有几百 MB,有的容量大到 TB、PB 级别……
这么多种存储设备,只用一个 PV 对象来管理还是有点太勉强了,不符合“单一职责”的原则,让 Pod 直接去选择 PV 也很不灵活。于是 Kubernetes 就又增加了两个新对象,PersistentVolumeClaim 和 StorageClass,用的还是“中间层”的思想,把存储卷的分配管理过程再次细化。
我们看这两个新对象。
PersistentVolumeClaim,简称 PVC,从名字上看比较好理解,就是用来向 Kubernetes 申请存储资源的。PVC 是给 Pod 使用的对象,它相当于是 Pod 的代理,代表 Pod 向系统申请 PV。一旦资源申请成功,Kubernetes 就会把 PV 和 PVC 关联在一起,这个动作叫做“绑定”(bind)。
但是,系统里的存储资源非常多,如果要 PVC 去直接遍历查找合适的 PV 也很麻烦,所以就要用到 StorageClass。
StorageClass 的作用有点像第 21 讲里的 IngressClass,它抽象了特定类型的存储系统(比如 Ceph、NFS),在 PVC 和 PV 之间充当“协调人”的角色,帮助 PVC 找到合适的 PV。也就是说它可以简化 Pod 挂载“虚拟盘”的过程,让 Pod 看不到 PV 的实现细节。

如果看到这里,你觉得还是差点理解也不要着急,我们找个生活中的例子来类比一下。毕竟和常用的 CPU、内存比起来,我们对存储系统的认识还是比较少的,所以 Kubernetes 里,PV、PVC 和 StorageClass 这三个新概念也不是特别好掌握。
看例子,假设你在公司里想要 10 张纸打印资料,于是你给前台打电话讲清楚了需求。
- “打电话”这个动作,就相当于 PVC,向 Kubernetes 申请存储资源。
- 前台里有各种牌子的办公用纸,大小、规格也不一样,这就相当于 StorageClass。
- 前台根据你的需要,挑选了一个品牌,再从库存里拿出一包 A4 纸,可能不止 10 张,但也能够满足要求,就在登记表上新添了一条记录,写上你在某天申领了办公用品。这个过程就是 PVC 到 PV 的绑定。
- 而最后到你手里的 A4 纸包,就是 PV 存储对象。
好,大概了解了这些 API 对象,我们接下来可以结合 YAML 描述和实际操作再慢慢体会。
如何使用 YAML 描述 PersistentVolume
Kubernetes 里有很多种类型的 PV,我们先看看最容易的本机存储“HostPath”,它和 Docker 里挂载本地目录的 -v 参数非常类似,可以用它来初步认识一下 PV 的用法。
因为 Pod 会在集群的任意节点上运行,所以首先,我们要作为系统管理员在每个节点上创建一个目录,它将会作为本地存储卷挂载到 Pod 里。
为了省事,我就在 /tmp 里建立名字是 host-10m-pv 的目录,表示一个只有 10MB 容量的存储设备。
有了存储,我们就可以使用 YAML 来描述这个 PV 对象了。
不过很遗憾,你不能用 kubectl create 直接创建 PV 对象,只能用 kubectl api-resources、kubectl explain 查看 PV 的字段说明,手动编写 PV 的 YAML 描述文件。
下面我给出一个 YAML 示例,你可以把它作为样板,编辑出自己的 PV:
apiVersion: v1
kind: PersistentVolume
metadata:
name: host-10m-pv
spec:
storageClassName: host-test
accessModes:
- ReadWriteOnce
capacity:
storage: 10Mi
hostPath:
path: /tmp/host-10m-pv/
PV 对象的文件头部分很简单,还是 API 对象的“老一套”,我就不再详细解释了,重点看它的 spec 部分,每个字段都很重要,描述了存储的详细信息。
“storageClassName”就是刚才说过的,对存储类型的抽象 StorageClass。这个 PV 是我们手动管理的,名字可以任意起,这里我写的是 host-test,你也可以把它改成 manual、hand-work 之类的词汇。
“accessModes”定义了存储设备的访问模式,简单来说就是虚拟盘的读写权限,和 Linux 的文件访问模式差不多,目前 Kubernetes 里有 3 种:
- ReadWriteOnce:存储卷可读可写,但只能被一个节点上的 Pod 挂载。
- ReadOnlyMany:存储卷只读不可写,可以被任意节点上的 Pod 多次挂载。
- ReadWriteMany:存储卷可读可写,也可以被任意节点上的 Pod 多次挂载。
你要注意,这 3 种访问模式限制的对象是节点而不是 Pod,因为存储是系统级别的概念,不属于 Pod 里的进程。
显然,本地目录只能是在本机使用,所以这个 PV 使用了 ReadWriteOnce。
第三个字段“capacity”就很好理解了,表示存储设备的容量,这里我设置为 10MB。
再次提醒你注意,Kubernetes 里定义存储容量使用的是国际标准,我们日常习惯使用的 KB/MB/GB 的基数是 1024,要写成 Ki/Mi/Gi,一定要小心不要写错了,否则单位不一致实际容量就会对不上。
最后一个字段“hostPath”最简单,它指定了存储卷的本地路径,也就是我们在节点上创建的目录。
用这些字段把 PV 的类型、访问模式、容量、存储位置都描述清楚,一个存储设备就创建好了。
如何使用 YAML 描述 PersistentVolumeClaim
有了 PV,就表示集群里有了这么一个持久化存储可以供 Pod 使用,我们需要再定义 PVC 对象,向 Kubernetes 申请存储。
下面这份 YAML 就是一个 PVC,要求使用一个 5MB 的存储设备,访问模式是 ReadWriteOnce:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: host-5m-pvc
spec:
storageClassName: host-test
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Mi
PVC 的内容与 PV 很像,但它不表示实际的存储,而是一个“申请”或者“声明”,spec 里的字段描述的是对存储的“期望状态”。
所以 PVC 里的 storageClassName、accessModes 和 PV 是一样的,但不会有字段 capacity**,而是要用** resources.request 表示希望要有多大的容量。
这样,Kubernetes 就会根据 PVC 里的描述,去找能够匹配 StorageClass 和容量的 PV,然后把 PV 和 PVC“绑定”在一起,实现存储的分配,和前面打电话要 A4 纸的过程差不多。
如何在 Kubernetes 里使用 PersistentVolume
现在我们已经准备好了 PV 和 PVC,就可以让 Pod 实现持久化存储了。
首先需要用 kubectl apply 创建 PV 对象:
kubectl apply -f host-path-pv.yml
# 然后用 kubectl get 查看它的状态:
kubectl get pv
![]()
从截图里我们可以看到,这个 PV 的容量是 10MB,访问模式是 RWO(ReadWriteOnce),StorageClass 是我们自己定义的 host-test,状态显示的是 Available,也就是处于可用状态,可以随时分配给 Pod 使用。
接下来我们创建 PVC,申请存储资源:
kubectl apply -f host-path-pvc.yml
kubectl get pvc

一旦 PVC 对象创建成功,Kubernetes 就会立即通过 StorageClass、resources 等条件在集群里查找符合要求的 PV,如果找到合适的存储对象就会把它俩“绑定”在一起。
PVC 对象申请的是 5MB,但现在系统里只有一个 10MB 的 PV,没有更合适的对象,所以 Kubernetes 也只能把这个 PV 分配出去,多出的容量就算是“福利”了。
你会看到这两个对象的状态都是 Bound,也就是说存储申请成功,PVC 的实际容量就是 PV 的容量 10MB,而不是最初申请的容量 5MB。
那么,如果我们把 PVC 的申请容量改大一些会怎么样呢?比如改成 100MB:

你会看到 PVC 会一直处于 Pending 状态,这意味着 Kubernetes 在系统里没有找到符合要求的存储,无法分配资源,只能等有满足要求的 PV 才能完成绑定。
如何为 Pod 挂载 PersistentVolume
PV 和 PVC 绑定好了,有了持久化存储,现在我们就可以为 Pod 挂载存储卷。用法和第 14 讲里差不多,先要在 spec.volumes 定义存储卷,然后在 containers.volumeMounts 挂载进容器。
不过因为我们用的是 PVC,所以要在 volumes 里用字段 persistentVolumeClaim 指定 PVC 的名字。
下面就是 Pod 的 YAML 描述文件,把存储卷挂载到了 Nginx 容器的 /tmp 目录:
apiVersion: v1
kind: Pod
metadata:
name: host-pvc-pod
spec:
volumes:
- name: host-pvc-vol
persistentVolumeClaim:
claimName: host-5m-pvc
containers:
- name: ngx-pvc-pod
image: nginx:alpine
ports:
- containerPort: 80
volumeMounts:
- name: host-pvc-vol
mountPath: /tmp
我把 Pod 和 PVC/PV 的关系画成了图(省略了字段 accessModes),你可以从图里看出它们是如何联系起来的:
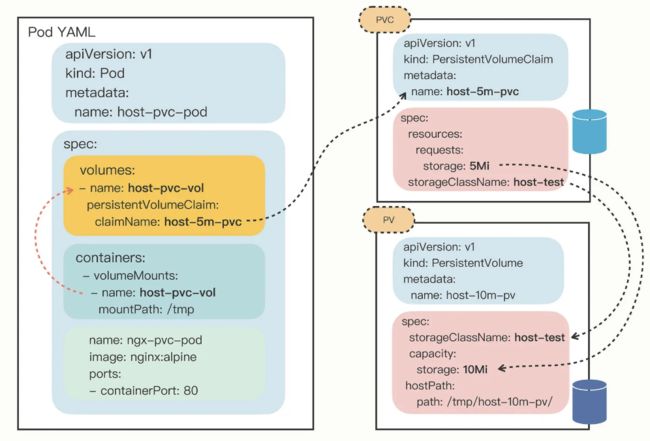
现在我们创建这个 Pod,查看它的状态:
kubectl apply -f host-path-pod.yml
kubectl get pod -o wide

它被 Kubernetes 调到了 worker 节点上,那么 PV 是否确实挂载成功了呢?让我们用 kubectl exec 进入容器,执行一些命令看看:
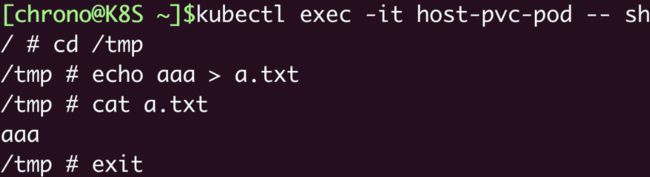
容器的 /tmp 目录里生成了一个 a.txt 的文件,根据 PV 的定义,它就应该落在 worker 节点的磁盘上,所以我们就登录 worker 节点检查一下:
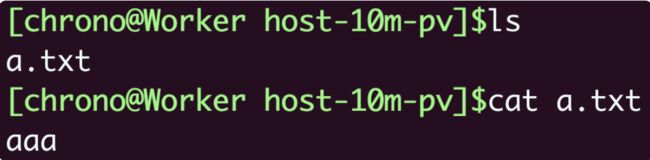
你会看到确实在 worker 节点的本地目录有一个 a.txt 的文件,再对一下时间,就可以确认是刚才在 Pod 里生成的文件。
因为 Pod 产生的数据已经通过 PV 存在了磁盘上,所以如果 Pod 删除后再重新创建,挂载存储卷时会依然使用这个目录,数据保持不变,也就实现了持久化存储。
不过还有一点小问题,因为这个 PV 是 HostPath 类型,只在本节点存储,如果 Pod 重建时被调度到了其他节点上,那么即使加载了本地目录,也不会是之前的存储位置,持久化功能也就失效了。
所以,HostPath 类型的 PV 一般用来做测试,或者是用于 DaemonSet 这样与节点关系比较密切的应用,我们下节课再讲实现真正任意的数据持久化。
小结
好了,今天我们一起学习了 Kubernetes 里应对持久化存储的解决方案,一共有三个 API 对象,分别是 PersistentVolume、PersistentVolumeClaim、StorageClass。它们管理的是集群里的存储资源,简单来说就是磁盘,Pod 必须通过它们才能够实现数据持久化。
再小结一下今天的主要内容:
PersistentVolume 简称为 PV,是 Kubernetes 对存储设备的抽象,由系统管理员维护,需要描述清楚存储设备的类型、访问模式、容量等信息。
PersistentVolumeClaim 简称为 PVC,代表 Pod 向系统申请存储资源,它声明对存储的要求,Kubernetes 会查找最合适的 PV 然后绑定。
StorageClass 抽象特定类型的存储系统,归类分组 PV 对象,用来简化 PV/PVC 的绑定过程。
HostPath 是最简单的一种 PV,数据存储在节点本地,速度快但不能跟随 Pod 迁移。

21|Ingress:集群进出流量的总管
为什么要有 Ingress
Service 的功能和运行机制,它本质上就是一个由 kube-proxy 控制的四层负载均衡,在 TCP/IP 协议栈上转发流量(Service 工作原理示意图):
在四层上的负载均衡功能还是太有限了,只能够依据 IP 地址和端口号做一些简单的判断和组合,而我们现在的绝大多数应用都是跑在七层的 HTTP/HTTPS 协议上的,有更多的高级路由条件,比如主机名、URI、请求头、证书等等,而这些在 TCP/IP 网络栈里是根本看不见的。
Service 还有一个缺点,它比较适合代理集群内部的服务。如果想要把服务暴露到集群外部,就只能使用 NodePort 或者 LoadBalancer 这两种方式,而它们都缺乏足够的灵活性,难以管控,这就导致了一种很无奈的局面:我们的服务空有一身本领,却没有合适的机会走出去大展拳脚。
该怎么解决这个问题呢?
Kubernetes 还是沿用了 Service 的思路,既然 Service 是四层的负载均衡,那么我再引入一个新的 API 对象,在七层上做负载均衡是不是就可以了呢?
不过除了七层负载均衡,这个对象还应该承担更多的职责,也就是作为流量的总入口,统管集群的进出口数据,“扇入”“扇出”流量(也就是我们常说的“南北向”),让外部用户能够安全、顺畅、便捷地访问内部服务:
所以,这个 API 对象就顺理成章地被命名为 Ingress,意思就是集群内外边界上的入口。
为什么要有 Ingress Controller
Ingress 可以说是在七层上另一种形式的 Service,它同样会代理一些后端的 Pod,也有一些路由规则来定义流量应该如何分配、转发,只不过这些规则都使用的是 HTTP/HTTPS 协议。
你应该知道,Service 本身是没有服务能力的,它只是一些 iptables 规则,真正配置、应用这些规则的实际上是节点里的 kube-proxy 组件。如果没有 kube-proxy,Service 定义得再完善也没有用。
同样的,Ingress 也只是一些 HTTP 路由规则的集合,相当于一份静态的描述文件,真正要把这些规则在集群里实施运行,还需要有另外一个东西,这就是 Ingress Controller,它的作用就相当于 Service 的 kube-proxy,能够读取、应用 Ingress 规则,处理、调度流量。
按理来说,Kubernetes 应该把 Ingress Controller 内置实现,作为基础设施的一部分,就像 kube-proxy 一样。
不过 Ingress Controller 要做的事情太多,与上层业务联系太密切,所以 Kubernetes 把 Ingress Controller 的实现交给了社区,任何人都可以开发 Ingress Controller,只要遵守 Ingress 规则就好。
由于 Ingress Controller 把守了集群流量的关键入口,掌握了它就拥有了控制集群应用的“话语权”,所以众多公司纷纷入场,精心打造自己的 Ingress Controller,意图在 Kubernetes 流量进出管理这个领域占有一席之地。
这些实现中最著名的,就是老牌的反向代理和负载均衡软件 Nginx 了。从 Ingress Controller 的描述上我们也可以看到,HTTP 层面的流量管理、安全控制等功能其实就是经典的反向代理,而 Nginx 则是其中稳定性最好、性能最高的产品,所以它也理所当然成为了 Kubernetes 里应用得最广泛的 Ingress Controller。
不过,因为 Nginx 是开源的,谁都可以基于源码做二次开发,所以它又有很多的变种,比如社区的 Kubernetes Ingress Controller(https://github.com/kubernetes/ingress-nginx)、Nginx 公司自己的 Nginx Ingress Controller(https://github.com/nginxinc/kubernetes-ingress)、还有基于 OpenResty 的 Kong Ingress Controller(https://github.com/Kong/kubernetes-ingress-controller)等等。
根据 Docker Hub 上的统计,Nginx 公司的开发实现是下载量最多的 Ingress Controller,所以我将以它为例,讲解 Ingress 和 Ingress Controller 的用法。
下面的这张图就来自 Nginx 官网,比较清楚地展示了 Ingress Controller 在 Kubernetes 集群里的地位:
为什么要有 IngressClass
那么到现在,有了 Ingress 和 Ingress Controller,我们是不是就可以完美地管理集群的进出流量了呢?
最初 Kubernetes 也是这么想的,一个集群里有一个 Ingress Controller,再给它配上许多不同的 Ingress 规则,应该就可以解决请求的路由和分发问题了。
但随着 Ingress 在实践中的大量应用,很多用户发现这种用法会带来一些问题,比如:
- 由于某些原因,项目组需要引入不同的 Ingress Controller,但 Kubernetes 不允许这样做;
- Ingress 规则太多,都交给一个 Ingress Controller 处理会让它不堪重负;
- 多个 Ingress 对象没有很好的逻辑分组方式,管理和维护成本很高;
- 集群里有不同的租户,他们对 Ingress 的需求差异很大甚至有冲突,无法部署在同一个 Ingress Controller 上。
所以,Kubernetes 就又提出了一个 Ingress Class 的概念,让它插在 Ingress 和 Ingress Controller 中间,作为流量规则和控制器的协调人,解除了 Ingress 和 Ingress Controller 的强绑定关系。
现在,Kubernetes 用户可以转向管理 Ingress Class,用它来定义不同的业务逻辑分组,简化 Ingress 规则的复杂度。比如说,我们可以用 Class A 处理博客流量、Class B 处理短视频流量、Class C 处理购物流量。
这些 Ingress 和 Ingress Controller 彼此独立,不会发生冲突,所以上面的那些问题也就随着 Ingress Class 的引入迎刃而解了。
如何使用 YAML 描述 Ingress/Ingress Class
和之前学习 Deployment、Service 对象一样,首先应当用命令 kubectl api-resources 查看它们的基本信息,输出列在这里了:
kubectl api-resources
NAME SHORTNAMES APIVERSION NAMESPACED KIND
ingresses ing networking.k8s.io/v1 true Ingress
ingressclasses networking.k8s.io/v1 false IngressClass
你可以看到,Ingress 和 Ingress Class 的 apiVersion 都是“networking.k8s.io/v1”,而且 Ingress 有一个简写“ing”,但 Ingress Controller 怎么找不到呢?
这是因为 Ingress Controller 和其他两个对象不太一样,它不只是描述文件,是一个要实际干活、处理流量的应用程序,而应用程序在 Kubernetes 里早就有对象来管理了,那就是 Deployment 和 DaemonSet,所以我们只需要再学习 Ingress 和 Ingress Class 的的用法就可以了。
先看 Ingress。
Ingress 也是可以使用 kubectl create 来创建样板文件的,和 Service 类似,它也需要用两个附加参数:
- class,指定 Ingress 从属的 Ingress Class 对象。
- rule,指定路由规则,基本形式是“URI=Service”,也就是说是访问 HTTP 路径就转发到对应的 Service 对象,再由 Service 对象转发给后端的 Pod。
好,现在我们就执行命令,看看 Ingress 到底长什么样:
export out="--dry-run=client -o yaml"
kubectl create ing ngx-ing --rule="ngx.test/=ngx-svc:80" --class=ngx-ink $out
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ngx-ing
spec:
ingressClassName: ngx-ink
rules:
- host: ngx.test
http:
paths:
- path: /
pathType: Exact
backend:
service:
name: ngx-svc
port:
number: 80
在这份 Ingress 的 YAML 里,有两个关键字段:“ingressClassName”和“rules”,分别对应了命令行参数,含义还是比较好理解的。
只是“rules”的格式比较复杂,嵌套层次很深。不过仔细点看就会发现它是把路由规则拆散了,有 host 和 http path,在 path 里又指定了路径的匹配方式,可以是精确匹配(Exact)或者是前缀匹配(Prefix),再用 backend 来指定转发的目标 Service 对象。
不过我个人觉得,Ingress YAML 里的描述还不如 kubectl create 命令行里的 --rule 参数来得直观易懂,而且 YAML 里的字段太多也很容易弄错,建议你还是让 kubectl 来自动生成规则,然后再略作修改比较好。
有了 Ingress 对象,那么与它关联的 Ingress Class 是什么样的呢?
其实 Ingress Class 本身并没有什么实际的功能,只是起到联系 Ingress 和 Ingress Controller 的作用,所以它的定义非常简单,在“spec”里只有一个必需的字段“controller”,表示要使用哪个 Ingress Controller,具体的名字就要看实现文档了。
比如,如果我要用 Nginx 开发的 Ingress Controller,那么就要用名字“nginx.org/ingress-controller”:
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: ngx-ink
spec:
controller: nginx.org/ingress-controller
Ingress 和 Service、Ingress Class 的关系图
如何在 Kubernetes 里使用 Ingress/Ingress Class
因为 Ingress Class 很小,所以我把它与 Ingress 合成了一个 YAML 文件,让我们用 kubectl apply 创建这两个对象:
kubectl apply -f ingress.yml
然后我们用 kubectl get 来查看对象的状态:
kubectl get ingressclass
kubectl get ing
命令 kubectl describe 可以看到更详细的 Ingress 信息:
kubectl describe ing ngx-ing
可以看到,Ingress 对象的路由规则 Host/Path 就是在 YAML 里设置的域名“ngx.test/”,而且已经关联了第 20 讲里创建的 Service 对象,还有 Service 后面的两个 Pod。
另外,不要对 Ingress 里“Default backend”的错误提示感到惊讶,在找不到路由的时候,它被设计用来提供一个默认的后端服务,但不设置也不会有什么问题,所以大多数时候我们都忽略它。
如何在 Kubernetes 里使用 Ingress Controller
准备好了 Ingress 和 Ingress Class,接下来我们就需要部署真正处理路由规则的 Ingress Controller。
你可以在 GitHub 上找到 Nginx Ingress Controller 的项目(https://github.com/nginxinc/kubernetes-ingress),因为它以 Pod 的形式运行在 Kubernetes 里,所以同时支持 Deployment 和 DaemonSet 两种部署方式。这里我选择的是 Deployment,相关的 YAML 也都在我们课程的项目(https://github.com/chronolaw/k8s_study/tree/master/ingress)里复制了一份。
Nginx Ingress Controller 的安装略微麻烦一些,有很多个 YAML 需要执行,但如果只是做简单的试验,就只需要用到 4 个 YAML:
kubectl apply -f common/ns-and-sa.yaml
kubectl apply -f rbac/rbac.yaml
kubectl apply -f common/nginx-config.yaml
kubectl apply -f common/default-server-secret.yaml
前两条命令为 Ingress Controller 创建了一个独立的名字空间“nginx-ingress”,还有相应的账号和权限,这是为了访问 apiserver 获取 Service、Endpoint 信息用的;后两条则是创建了一个 ConfigMap 和 Secret,用来配置 HTTP/HTTPS 服务。
部署 Ingress Controller 不需要我们自己从头编写 Deployment,Nginx 已经为我们提供了示例 YAML,但创建之前为了适配我们自己的应用还必须要做几处小改动:
- metadata 里的 name 要改成自己的名字,比如 ngx-kic-dep。
- spec.selector 和 template.metadata.labels 也要修改成自己的名字,比如还是用 ngx-kic-dep。
- containers.image 可以改用 apline 版本,加快下载速度,比如 nginx/nginx-ingress:2.2-alpine。
- 最下面的 args 要加上 -ingress-class=ngx-ink,也就是前面创建的 Ingress Class 的名字,这是让 Ingress Controller 管理 Ingress 的关键。
修改完之后,Ingress Controller 的 YAML 大概是这个样子:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ngx-kic-dep
namespace: nginx-ingress
spec:
replicas: 1
selector:
matchLabels:
app: ngx-kic-dep
template:
metadata:
labels:
app: ngx-kic-dep
...
spec:
containers:
- image: nginx/nginx-ingress:2.2-alpine
...
args:
- -ingress-class=ngx-ink
有了 Ingress Controller,这些 API 对象的关联就更复杂了,你可以用下面的这张图来看出它们是如何使用对象名字联系起来的:
确认 Ingress Controller 的 YAML 修改完毕之后,就可以用 kubectl apply 创建对象:
kubectl apply -f kic.yml
注意 Ingress Controller 位于名字空间“nginx-ingress”,所以查看状态需要用“-n”参数显式指定,否则我们只能看到“default”名字空间里的 Pod:
kubectl get deploy -n nginx-ingress
kubectl get pod -n nginx-ingress
现在 Ingress Controller 就算是运行起来了。
不过还有最后一道工序,因为 Ingress Controller 本身也是一个 Pod,想要向外提供服务还是要依赖于 Service 对象。所以你至少还要再为它定义一个 Service,使用 NodePort 或者 LoadBalancer 暴露端口,才能真正把集群的内外流量打通。这个工作就交给你课下自己去完成了。
这里,我就用第 15 讲里提到的命令kubectl port-forward**,它可以直接把本地的端口映射到 Kubernetes 集群的某个 Pod 里**,在测试验证的时候非常方便。
下面这条命令就把本地的 8080 端口映射到了 Ingress Controller Pod 的 80 端口:
kubectl port-forward -n nginx-ingress ngx-kic-dep-8859b7b86-cplgp 8080:80 &
我们在 curl 发测试请求的时候需要注意,因为 Ingress 的路由规则是 HTTP 协议,所以就不能用 IP 地址的方式访问,必须要用域名、URI。
你可以修改 /etc/hosts 来手工添加域名解析,也可以使用 --resolve 参数,指定域名的解析规则,比如在这里我就把“ngx.test”强制解析到“127.0.0.1”,也就是被 kubectl port-forward 转发的本地地址:
curl --resolve ngx.test:8080:127.0.0.1 http://ngx.test:8080
把这个访问结果和上一节课里的 Service 对比一下,你会发现最终效果是一样的,都是把请求转发到了集群内部的 Pod,但 Ingress 的路由规则不再是 IP 地址,而是 HTTP 协议里的域名、URI 等要素。
小结
好了,今天就讲到这里,我们学习了 Kubernetes 里七层的反向代理和负载均衡对象,包括 Ingress、Ingress Controller、Ingress Class,它们联合起来管理了集群的进出流量,是集群入口的总管。
小结一下今天的主要内容:
- Service 是四层负载均衡,能力有限,所以就出现了 Ingress,它基于 HTTP/HTTPS 协议定义路由规则。
- Ingress 只是规则的集合,自身不具备流量管理能力,需要 Ingress Controller 应用 Ingress 规则才能真正发挥作用。
- Ingress Class 解耦了 Ingress 和 Ingress Controller,我们应当使用 Ingress Class 来管理 Ingress 资源。
- 最流行的 Ingress Controller 是 Nginx Ingress Controller,它基于经典反向代理软件 Nginx。
再补充一点,目前的 Kubernetes 流量管理功能主要集中在 Ingress Controller 上,已经远不止于管理“入口流量”了,它还能管理“出口流量”,也就是 egress,甚至还可以管理集群内部服务之间的“东西向流量”。
此外,Ingress Controller 通常还有很多的其他功能,比如 TLS 终止、网络应用防火墙、限流限速、流量拆分、身份认证、访问控制等等,完全可以认为它是一个全功能的反向代理或者网关,感兴趣的话你可以找找这方面的资料。
22|实战演练:玩转Kubernetes(2)
Kubernetes 技术要点回顾
-
Kubernetes 是云原生时代的操作系统,它能够管理大量节点构成的集群,让计算资源“池化”,从而能够自动地调度运维各种形式的应用。
-
搭建多节点的 Kubernetes 集群是一件颇具挑战性的工作,好在社区里及时出现了 kubeadm 这样的工具,可以“一键操作”,使用 kubeadm init、kubeadm join 等命令从无到有地搭建出生产级别的集群(17 讲)。
-
kubeadm 使用容器技术封装了 Kubernetes 组件,所以只要节点上安装了容器运行时(Docker、containerd 等),它就可以自动从网上拉取镜像,然后以容器的方式运行组件,非常简单方便。
-
在这个更接近实际生产环境的 Kubernetes 集群里,我们学习了 Deployment、DaemonSet、Service、Ingress、Ingress Controller 等 API 对象。
-
(18 讲)Deployment 是用来管理 Pod 的一种对象,它代表了运维工作中最常见的一类在线业务,在集群中部署应用的多个实例,而且可以很容易地增加或者减少实例数量,从容应对流量压力。
-
Deployment 的定义里有两个关键字段:一个是 replicas,它指定了实例的数量;另一个是 selector,它的作用是使用标签“筛选”出被 Deployment 管理的 Pod,这是一种非常灵活的关联机制,实现了 API 对象之间的松耦合。
-
(19 讲)DaemonSet 是另一种部署在线业务的方式,它很类似 Deployment,但会在集群里的每一个节点上运行一个 Pod 实例,类似 Linux 系统里的“守护进程”,适合日志、监控等类型的应用。
-
DaemonSet 能够任意部署 Pod 的关键概念是“污点”(taint)和“容忍度”(toleration)。Node 会有各种“污点”,而 Pod 可以使用“容忍度”来忽略“污点”,合理使用这两个概念就可以调整 Pod 在集群里的部署策略。
-
(20 讲)由 Deployment 和 DaemonSet 部署的 Pod,在集群中处于“动态平衡”的状态,总数量保持恒定,但也有临时销毁重建的可能,所以 IP 地址是变化的,这就为微服务等应用架构带来了麻烦。
-
Service 是对 Pod IP 地址的抽象,它拥有一个固定的 IP 地址,再使用 iptables 规则把流量负载均衡到后面的 Pod,节点上的 kube-proxy 组件会实时维护被代理的 Pod 状态,保证 Service 只会转发给健康的 Pod。
-
Service 还基于 DNS 插件支持域名,所以客户端就不再需要关心 Pod 的具体情况,只要通过 Service 这个稳定的中间层,就能够访问到 Pod 提供的服务。
-
(21 讲)Service 是四层的负载均衡,但现在的绝大多数应用都是 HTTP/HTTPS 协议,要实现七层的负载均衡就要使用 Ingress 对象。
-
Ingress 定义了基于 HTTP 协议的路由规则,但要让规则生效,还需要 Ingress Controller 和 Ingress Class 来配合工作。
-
Ingress Controller 是真正的集群入口,应用 Ingress 规则调度、分发流量,此外还能够扮演反向代理的角色,提供安全防护、TLS 卸载等更多功能。
-
Ingress Class 是用来管理 Ingress 和 Ingress Controller 的概念,方便我们分组路由规则,降低维护成本。
-
不过 Ingress Controller 本身也是一个 Pod,想要把服务暴露到集群外部还是要依靠 Service。Service 支持 NodePort、LoadBalancer 等方式,但 NodePort 的端口范围有限,LoadBalancer 又依赖于云服务厂商,都不是很灵活。
-
折中的办法是用少量 NodePort 暴露 Ingress Controller,用 Ingress 路由到内部服务,外部再用反向代理或者 LoadBalancer 把流量引进来。
WordPress 网站基本架构
简略回顾了 Kubernetes 里这些 API 对象,下面我们就来使用它们再搭建出 WordPress 网站,实践加深理解。
既然我们已经掌握了 Deployment、Service、Ingress 这些 Pod 之上的概念,网站自然会有新变化,架构图我放在了这里:
这次的部署形式比起 Docker、minikube 又有了一些细微的差别,重点是我们已经完全舍弃了 Docker,把所有的应用都放在 Kubernetes 集群里运行,部署方式也不再是裸 Pod,而是使用 Deployment,稳定性大幅度提升。
原来的 Nginx 的作用是反向代理,那么在 Kubernetes 里它就升级成了具有相同功能的 Ingress Controller。WordPress 原来只有一个实例,现在变成了两个实例(你也可以任意横向扩容),可用性也就因此提高了不少。而 MariaDB 数据库因为要保证数据的一致性,暂时还是一个实例。
还有,因为 Kubernetes 内置了服务发现机制 Service,我们再也不需要去手动查看 Pod 的 IP 地址了,只要为它们定义 Service 对象,然后使用域名就可以访问 MariaDB、WordPress 这些服务。
网站对外提供服务我选择了两种方式。
一种是让 WordPress 的 Service 对象以 NodePort 的方式直接对外暴露端口 30088,方便测试;另一种是给 Nginx Ingress Controller 添加“hostNetwork”属性,直接使用节点上的端口号,类似 Docker 的 host 网络模式,好处是可以避开 NodePort 的端口范围限制。
下面我们就按照这个基本架构来逐步搭建出新版本的 WordPress 网站,编写 YAML 声明。
这里有个小技巧,在实际操作的时候你一定要记得善用 kubectl create、kubectl expose 创建样板文件,节约时间的同时,也能避免低级的格式错误。
1. WordPress 网站部署 MariaDB
首先我们还是要部署 MariaDB,这个步骤和在第 15 讲里做的也差不多。
先要用 ConfigMap 定义数据库的环境变量,有 DATABASE、USER、PASSWORD、ROOT_PASSWORD:
apiVersion: v1
kind: ConfigMap
metadata:
name: maria-cm
data:
DATABASE: 'db'
USER: 'wp'
PASSWORD: '123'
ROOT_PASSWORD: '123'
然后我们需要把 MariaDB 由 Pod 改成 Deployment 的方式,replicas 设置成 1 个,template 里面的 Pod 部分没有任何变化,还是要用 envFrom把配置信息以环境变量的形式注入 Pod,相当于把 Pod 套了一个 Deployment 的“外壳”:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: maria-dep
name: maria-dep
spec:
replicas: 1
selector:
matchLabels:
app: maria-dep
template:
metadata:
labels:
app: maria-dep
spec:
containers:
- image: mariadb:10
name: mariadb
ports:
- containerPort: 3306
envFrom:
- prefix: 'MARIADB_'
configMapRef:
name: maria-cm
我们还需要再为 MariaDB 定义一个 Service 对象,映射端口 3306,让其他应用不再关心 IP 地址,直接用 Service 对象的名字来访问数据库服务:
apiVersion: v1
kind: Service
metadata:
labels:
app: maria-dep
name: maria-svc
spec:
ports:
- port: 3306
protocol: TCP
targetPort: 3306
selector:
app: maria-dep
因为这三个对象都是数据库相关的,所以可以在一个 YAML 文件里书写,对象之间用 — 分开,这样用 kubectl apply 就可以一次性创建好:
kubectl apply -f wp-maria.yml
执行命令后,你应该用 kubectl get 查看对象是否创建成功,是否正常运行:
2. WordPress 网站部署 WordPress
第二步是部署 WordPress 应用。
因为刚才创建了 MariaDB 的 Service,所以在写 ConfigMap 配置的时候“HOST”就不应该是 IP 地址了,而应该是 DNS 域名,也就是 Service 的名字maria-svc**,这点需要特别注意**:
apiVersion: v1
kind: ConfigMap
metadata:
name: wp-cm
data:
HOST: 'maria-svc'
USER: 'wp'
PASSWORD: '123'
NAME: 'db'
WordPress 的 Deployment 写法和 MariaDB 也是一样的,给 Pod 套一个 Deployment 的“外壳”,replicas 设置成 2 个,用字段“envFrom”配置环境变量:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: wp-dep
name: wp-dep
spec:
replicas: 2
selector:
matchLabels:
app: wp-dep
template:
metadata:
labels:
app: wp-dep
spec:
containers:
- image: wordpress:5
name: wordpress
ports:
- containerPort: 80
envFrom:
- prefix: 'WORDPRESS_DB_'
configMapRef:
name: wp-cm
然后我们仍然要为 WordPress 创建 Service 对象,这里我使用了“NodePort”类型,并且手工指定了端口号“30088”(必须在 30000~32767 之间):
apiVersion: v1
kind: Service
metadata:
labels:
app: wp-dep
name: wp-svc
spec:
ports:
- name: http80
port: 80
protocol: TCP
targetPort: 80
nodePort: 30088
selector:
app: wp-dep
type: NodePort
现在让我们用 kubectl apply 部署 WordPress:
kubectl apply -f wp-dep.yml
因为 WordPress 的 Service 对象是 NodePort 类型的,我们可以在集群的每个节点上访问 WordPress 服务。
比如一个节点的 IP 地址是“192.168.10.210”,那么你就在浏览器的地址栏里输入“http://192.168.10.210:30088”,其中的“30088”就是在 Service 里指定的节点端口号,然后就能够看到 WordPress 的安装界面了
3. WordPress 网站部署 Nginx Ingress Controller
现在 MariaDB,WordPress 都已经部署成功了,第三步就是部署 Nginx Ingress Controller。
首先我们需要定义 Ingress Class,名字就叫“wp-ink”,非常简单:
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: wp-ink
spec:
controller: nginx.org/ingress-controller
然后用 kubectl create 命令生成 Ingress 的样板文件,指定域名是“wp.test”,后端 Service 是“wp-svc:80”,Ingress Class 就是刚定义的“wp-ink”:
kubectl create ing wp-ing --rule="wp.test/=wp-svc:80" --class=wp-ink $out
得到的 Ingress YAML 就是这样,注意路径类型我还是用的前缀匹配“Prefix”:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: wp-ing
spec:
ingressClassName: wp-ink
rules:
- host: wp.test
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: wp-svc
port:
number: 80
接下来就是最关键的 Ingress Controller 对象了,它仍然需要从 Nginx 项目的示例 YAML 修改而来,要改动名字、标签,还有参数里的 Ingress Class。
在之前讲基本架构的时候我说过了,这个 Ingress Controller 不使用 Service,而是给它的 Pod 加上一个特殊字段 hostNetwork,让 Pod 能够使用宿主机的网络,相当于另一种形式的 NodePort:
apiVersion: apps/v1
kind: Deployment
metadata:
name: wp-kic-dep
namespace: nginx-ingress
spec:
replicas: 1
selector:
matchLabels:
app: wp-kic-dep
template:
metadata:
labels:
app: wp-kic-dep
spec:
serviceAccountName: nginx-ingress
# use host network
hostNetwork: true
containers:
...
准备好 Ingress 资源后,我们创建这些对象:
kubectl apply -f wp-ing.yml -f wp-kic.yml
现在所有的应用都已经部署完毕,可以在集群外面访问网站来验证结果了。
不过你要注意,Ingress 使用的是 HTTP 路由规则,用 IP 地址访问是无效的,所以在集群外的主机上必须能够识别我们的“wp.test”域名,也就是说要把域名“wp.test”解析到 Ingress Controller 所在的节点上。
如果你用的是 Mac,那就修改 /etc/hosts;如果你用的是 Windows,就修改 C:\Windows\System32\Drivers\etc\hosts,添加一条解析规则就行:
cat /etc/hosts
192.168.10.210 wp.test
有了域名解析,在浏览器里你就不必使用 IP 地址,直接用域名“wp.test”走 Ingress Controller 就能访问我们的 WordPress 网站了:
23|视频:中级篇实操总结
一. 安装 kubeadm
二. 安装 Kubernetes
三. Kubernetes 集群部署
四. Deployment 的使用
# kubectl api-resources 来查看 Deployment 的基本信息
kubectl api-resources | grep deploy
可以看到 Deployment 的简称是“deploy”,它的 apiVersion 是“apps/v1”,kind 是“Deployment”。
然后我们执行 kubectl create,让 Kubernetes 为我们自动生成 Deployment 的样板文件。
# 先要定义一个环境变量 out:
export out="--dry-run=client -o yaml"
# 然后创建名字叫“ngx-dep”的对象,使用的镜像是“nginx:alpine”:
kubectl create deploy ngx-dep --image=nginx:alpine $out
# 把这个样板存入一个文件 ngx.yml
kubectl create deploy ngx-dep --image=nginx:alpine $out > deploy.yml
# 这里可以删除一些不需要的字段,让 YAML 看起来更干净,然后把 replicas 改成 2,意思是启动两个 Nginx Pod。
# 把 Deployment 的 YAML 写好之后,我们就可以用 kubectl apply 来创建对象了:
kubectl apply -f deploy.yml
# 用 kubectl get 命令查看 Deployment 的状态:
kubectl get deploy
kubectl get pod
# 来试验一下 Deployment 的应用伸缩功能,使用命令 kubectl scale,把 Pod 数量改成 5 个:
kubectl scale --replicas=5 deploy ngx-dep
五. DaemonSet 的使用
因为 DaemonSet 不能使用 kubectl create 直接生成样板文件,但大体结构和 Deployment 是一样的,所以我们可以先生成一个 Deployment,然后再修改几个字段就行了。
这里我使用了 Linux 系统里常用的小工具 sed,直接替换 Deployment 里的名字,再删除 replicas 字段,这样就自动生成了 DaemonSet 的样板文件:
kubectl create deploy redis-ds --image=redis:5-alpine $out \
| sed 's/Deployment/DaemonSet/g' - \
| sed -e '/replicas/d' -
这个样板文件因为是从 Deployment 改来的,所以不会有 tolerations 字段,不能在 Master 节点上运行,需要手工添加。
注意看里面的 tolerations 字段,它能够容忍节点的 node-role.kubernetes.io/master:NoSchedule 这个污点,也就是说能够运行在 Master 节点上。
六. Service 的使用
# 使用 kubectl expose 创建 Service 样板文件
kubectl expose deploy ngx-dep --port=80 --target-port=80 $out
# 修改之后就是 svc.yml,再用 kubectl apply 创建 Service 对象
kubectl apply -f svc.yml
# 用 kubectl get svc 可以列出 Service 对象,可以看到它的虚 IP 地址
kubectl get svc
# 要看 Service 代理了哪些后端的 Pod,要用 kubectl describe 命令
kubectl describe svc ngx-svc
# 用 kubectl get pod 可以对比验证 Service 是否正确代理了 Nginx Pod
kubectl get pod -o wide
# 现在让我们用 kubectl exec 进入 Pod,验证 Service 的域名功能
kubectl exec -it ngx-dep-6796688696-4h6lb -- sh
# 使用 curl,加上域名“ngx-svc”,也就是 Service 对象的名字
curl ngx-svc
# 多执行几次,就会看到通过这个域名,Service 对象实现了对后端 Pod 的负载均衡,把流量分发到不同的 Pod。
# 我们还可以再尝试 Service 的其他域名形式,比如加上名字空间:
curl ngx-svc.default
curl ngx-svc.default.svc.cluster.local
七. Ingress 的使用
24|PersistentVolume:怎么解决数据持久化的难题?
什么是 PersistentVolume
我们在 Kubernetes 集群里搭建了 WordPress 网站,但其中存在一个很严重的问题:Pod 没有持久化功能,导致 MariaDB 无法“永久”存储数据。
因为 Pod 里的容器是由镜像产生的,而镜像文件本身是只读的,进程要读写磁盘只能用一个临时的存储空间,一旦 Pod 销毁,临时存储也就会立即回收释放,数据也就丢失了。
为了保证即使 Pod 销毁后重建数据依然存在,我们就需要找出一个解决方案,让 Pod 用上真正的“虚拟盘”。怎么办呢?
其实,Kubernetes 的 Volume 对数据存储已经给出了一个很好的抽象,它只是定义了有这么一个“存储卷”,而这个“存储卷”是什么类型、有多大容量、怎么存储,我们都可以自由发挥。Pod 不需要关心那些专业、复杂的细节,只要设置好 volumeMounts,就可以把 Volume 加载进容器里使用。
所以,Kubernetes 就顺着 Volume 的概念,延伸出了 PersistentVolume 对象,它专门用来表示持久存储设备,但隐藏了存储的底层实现,我们只需要知道它能安全可靠地保管数据就可以了(由于 PersistentVolume 这个词很长,一般都把它简称为 PV)。
那么,集群里的 PV 都从哪里来呢?
作为存储的抽象,PV 实际上就是一些存储设备、文件系统,比如 Ceph、GlusterFS、NFS,甚至是本地磁盘,管理它们已经超出了 Kubernetes 的能力范围,所以,一般会由系统管理员单独维护,然后再在 Kubernetes 里创建对应的 PV。
要注意的是,PV 属于集群的系统资源,是和 Node 平级的一种对象,Pod 对它没有管理权,只有使用权。
什么是 PersistentVolumeClaim/StorageClass
现在有了 PV,我们是不是可以直接在 Pod 里挂载使用了呢?
还不行。因为不同存储设备的差异实在是太大了:有的速度快,有的速度慢;有的可以共享读写,有的只能独占读写;有的容量小,只有几百 MB,有的容量大到 TB、PB 级别……
这么多种存储设备,只用一个 PV 对象来管理还是有点太勉强了,不符合“单一职责”的原则,让 Pod 直接去选择 PV 也很不灵活。于是 Kubernetes 就又增加了两个新对象,PersistentVolumeClaim 和 StorageClass,用的还是“中间层”的思想,把存储卷的分配管理过程再次细化。
我们看这两个新对象。
PersistentVolumeClaim,简称 PVC,从名字上看比较好理解,就是用来向 Kubernetes 申请存储资源的。PVC 是给 Pod 使用的对象,它相当于是 Pod 的代理,代表 Pod 向系统申请 PV。一旦资源申请成功,Kubernetes 就会把 PV 和 PVC 关联在一起,这个动作叫做“绑定”(bind)。
但是,系统里的存储资源非常多,如果要 PVC 去直接遍历查找合适的 PV 也很麻烦,所以就要用到 StorageClass。
StorageClass 的作用有点像第 21 讲里的 IngressClass,它抽象了特定类型的存储系统(比如 Ceph、NFS),在 PVC 和 PV 之间充当“协调人”的角色,帮助 PVC 找到合适的 PV。也就是说它可以简化 Pod 挂载“虚拟盘”的过程,让 Pod 看不到 PV 的实现细节。
如果看到这里,你觉得还是差点理解也不要着急,我们找个生活中的例子来类比一下。毕竟和常用的 CPU、内存比起来,我们对存储系统的认识还是比较少的,所以 Kubernetes 里,PV、PVC 和 StorageClass 这三个新概念也不是特别好掌握。
看例子,假设你在公司里想要 10 张纸打印资料,于是你给前台打电话讲清楚了需求。
- “打电话”这个动作,就相当于 PVC,向 Kubernetes 申请存储资源。
- 前台里有各种牌子的办公用纸,大小、规格也不一样,这就相当于 StorageClass。
- 前台根据你的需要,挑选了一个品牌,再从库存里拿出一包 A4 纸,可能不止 10 张,但也能够满足要求,就在登记表上新添了一条记录,写上你在某天申领了办公用品。这个过程就是 PVC 到 PV 的绑定。
- 而最后到你手里的 A4 纸包,就是 PV 存储对象。
好,大概了解了这些 API 对象,我们接下来可以结合 YAML 描述和实际操作再慢慢体会。
如何使用 YAML 描述 PersistentVolume
Kubernetes 里有很多种类型的 PV,我们先看看最容易的本机存储“HostPath”,它和 Docker 里挂载本地目录的 -v 参数非常类似,可以用它来初步认识一下 PV 的用法。
因为 Pod 会在集群的任意节点上运行,所以首先,我们要作为系统管理员在每个节点上创建一个目录,它将会作为本地存储卷挂载到 Pod 里。
为了省事,我就在 /tmp 里建立名字是 host-10m-pv 的目录,表示一个只有 10MB 容量的存储设备。
有了存储,我们就可以使用 YAML 来描述这个 PV 对象了。
不过很遗憾,你不能用 kubectl create 直接创建 PV 对象,只能用 kubectl api-resources、kubectl explain 查看 PV 的字段说明,手动编写 PV 的 YAML 描述文件。
下面我给出一个 YAML 示例,你可以把它作为样板,编辑出自己的 PV:
apiVersion: v1
kind: PersistentVolume
metadata:
name: host-10m-pv
spec:
storageClassName: host-test
accessModes:
- ReadWriteOnce
capacity:
storage: 10Mi
hostPath:
path: /tmp/host-10m-pv/
PV 对象的文件头部分很简单,还是 API 对象的“老一套”,我就不再详细解释了,重点看它的 spec 部分,每个字段都很重要,描述了存储的详细信息。
“storageClassName”就是刚才说过的,对存储类型的抽象 StorageClass。这个 PV 是我们手动管理的,名字可以任意起,这里我写的是 host-test,你也可以把它改成 manual、hand-work 之类的词汇。
“accessModes”定义了存储设备的访问模式,简单来说就是虚拟盘的读写权限,和 Linux 的文件访问模式差不多,目前 Kubernetes 里有 3 种:
- ReadWriteOnce:存储卷可读可写,但只能被一个节点上的 Pod 挂载。
- ReadOnlyMany:存储卷只读不可写,可以被任意节点上的 Pod 多次挂载。
- ReadWriteMany:存储卷可读可写,也可以被任意节点上的 Pod 多次挂载。
你要注意,这 3 种访问模式限制的对象是节点而不是 Pod,因为存储是系统级别的概念,不属于 Pod 里的进程。
显然,本地目录只能是在本机使用,所以这个 PV 使用了 ReadWriteOnce。
第三个字段“capacity”就很好理解了,表示存储设备的容量,这里我设置为 10MB。
再次提醒你注意,Kubernetes 里定义存储容量使用的是国际标准,我们日常习惯使用的 KB/MB/GB 的基数是 1024,要写成 Ki/Mi/Gi,一定要小心不要写错了,否则单位不一致实际容量就会对不上。
最后一个字段“hostPath”最简单,它指定了存储卷的本地路径,也就是我们在节点上创建的目录。
用这些字段把 PV 的类型、访问模式、容量、存储位置都描述清楚,一个存储设备就创建好了。
如何使用 YAML 描述 PersistentVolumeClaim
有了 PV,就表示集群里有了这么一个持久化存储可以供 Pod 使用,我们需要再定义 PVC 对象,向 Kubernetes 申请存储。
下面这份 YAML 就是一个 PVC,要求使用一个 5MB 的存储设备,访问模式是 ReadWriteOnce:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: host-5m-pvc
spec:
storageClassName: host-test
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Mi
PVC 的内容与 PV 很像,但它不表示实际的存储,而是一个“申请”或者“声明”,spec 里的字段描述的是对存储的“期望状态”。
所以 PVC 里的 storageClassName、accessModes 和 PV 是一样的,但不会有字段 capacity**,而是要用** resources.request 表示希望要有多大的容量。
这样,Kubernetes 就会根据 PVC 里的描述,去找能够匹配 StorageClass 和容量的 PV,然后把 PV 和 PVC“绑定”在一起,实现存储的分配,和前面打电话要 A4 纸的过程差不多。
如何在 Kubernetes 里使用 PersistentVolume
现在我们已经准备好了 PV 和 PVC,就可以让 Pod 实现持久化存储了。
首先需要用 kubectl apply 创建 PV 对象:
kubectl apply -f host-path-pv.yml
# 然后用 kubectl get 查看它的状态:
kubectl get pv
![]()
从截图里我们可以看到,这个 PV 的容量是 10MB,访问模式是 RWO(ReadWriteOnce),StorageClass 是我们自己定义的 host-test,状态显示的是 Available,也就是处于可用状态,可以随时分配给 Pod 使用。
接下来我们创建 PVC,申请存储资源:
kubectl apply -f host-path-pvc.yml
kubectl get pvc
一旦 PVC 对象创建成功,Kubernetes 就会立即通过 StorageClass、resources 等条件在集群里查找符合要求的 PV,如果找到合适的存储对象就会把它俩“绑定”在一起。
PVC 对象申请的是 5MB,但现在系统里只有一个 10MB 的 PV,没有更合适的对象,所以 Kubernetes 也只能把这个 PV 分配出去,多出的容量就算是“福利”了。
你会看到这两个对象的状态都是 Bound,也就是说存储申请成功,PVC 的实际容量就是 PV 的容量 10MB,而不是最初申请的容量 5MB。
那么,如果我们把 PVC 的申请容量改大一些会怎么样呢?比如改成 100MB:
你会看到 PVC 会一直处于 Pending 状态,这意味着 Kubernetes 在系统里没有找到符合要求的存储,无法分配资源,只能等有满足要求的 PV 才能完成绑定。
如何为 Pod 挂载 PersistentVolume
PV 和 PVC 绑定好了,有了持久化存储,现在我们就可以为 Pod 挂载存储卷。用法和第 14 讲里差不多,先要在 spec.volumes 定义存储卷,然后在 containers.volumeMounts 挂载进容器。
不过因为我们用的是 PVC,所以要在 volumes 里用字段 persistentVolumeClaim 指定 PVC 的名字。
下面就是 Pod 的 YAML 描述文件,把存储卷挂载到了 Nginx 容器的 /tmp 目录:
apiVersion: v1
kind: Pod
metadata:
name: host-pvc-pod
spec:
volumes:
- name: host-pvc-vol
persistentVolumeClaim:
claimName: host-5m-pvc
containers:
- name: ngx-pvc-pod
image: nginx:alpine
ports:
- containerPort: 80
volumeMounts:
- name: host-pvc-vol
mountPath: /tmp
我把 Pod 和 PVC/PV 的关系画成了图(省略了字段 accessModes),你可以从图里看出它们是如何联系起来的:
现在我们创建这个 Pod,查看它的状态:
kubectl apply -f host-path-pod.yml
kubectl get pod -o wide
它被 Kubernetes 调到了 worker 节点上,那么 PV 是否确实挂载成功了呢?让我们用 kubectl exec 进入容器,执行一些命令看看:
容器的 /tmp 目录里生成了一个 a.txt 的文件,根据 PV 的定义,它就应该落在 worker 节点的磁盘上,所以我们就登录 worker 节点检查一下:
你会看到确实在 worker 节点的本地目录有一个 a.txt 的文件,再对一下时间,就可以确认是刚才在 Pod 里生成的文件。
因为 Pod 产生的数据已经通过 PV 存在了磁盘上,所以如果 Pod 删除后再重新创建,挂载存储卷时会依然使用这个目录,数据保持不变,也就实现了持久化存储。
不过还有一点小问题,因为这个 PV 是 HostPath 类型,只在本节点存储,如果 Pod 重建时被调度到了其他节点上,那么即使加载了本地目录,也不会是之前的存储位置,持久化功能也就失效了。
所以,HostPath 类型的 PV 一般用来做测试,或者是用于 DaemonSet 这样与节点关系比较密切的应用,我们下节课再讲实现真正任意的数据持久化。
小结
好了,今天我们一起学习了 Kubernetes 里应对持久化存储的解决方案,一共有三个 API 对象,分别是 PersistentVolume、PersistentVolumeClaim、StorageClass。它们管理的是集群里的存储资源,简单来说就是磁盘,Pod 必须通过它们才能够实现数据持久化。
再小结一下今天的主要内容:
PersistentVolume 简称为 PV,是 Kubernetes 对存储设备的抽象,由系统管理员维护,需要描述清楚存储设备的类型、访问模式、容量等信息。
PersistentVolumeClaim 简称为 PVC,代表 Pod 向系统申请存储资源,它声明对存储的要求,Kubernetes 会查找最合适的 PV 然后绑定。
StorageClass 抽象特定类型的存储系统,归类分组 PV 对象,用来简化 PV/PVC 的绑定过程。
HostPath 是最简单的一种 PV,数据存储在节点本地,速度快但不能跟随 Pod 迁移。
22|实战演练:玩转Kubernetes(2)
Kubernetes 技术要点回顾
-
Kubernetes 是云原生时代的操作系统,它能够管理大量节点构成的集群,让计算资源“池化”,从而能够自动地调度运维各种形式的应用。
-
搭建多节点的 Kubernetes 集群是一件颇具挑战性的工作,好在社区里及时出现了 kubeadm 这样的工具,可以“一键操作”,使用 kubeadm init、kubeadm join 等命令从无到有地搭建出生产级别的集群(17 讲)。
-
kubeadm 使用容器技术封装了 Kubernetes 组件,所以只要节点上安装了容器运行时(Docker、containerd 等),它就可以自动从网上拉取镜像,然后以容器的方式运行组件,非常简单方便。
-
在这个更接近实际生产环境的 Kubernetes 集群里,我们学习了 Deployment、DaemonSet、Service、Ingress、Ingress Controller 等 API 对象。
-
(18 讲)Deployment 是用来管理 Pod 的一种对象,它代表了运维工作中最常见的一类在线业务,在集群中部署应用的多个实例,而且可以很容易地增加或者减少实例数量,从容应对流量压力。
-
Deployment 的定义里有两个关键字段:一个是 replicas,它指定了实例的数量;另一个是 selector,它的作用是使用标签“筛选”出被 Deployment 管理的 Pod,这是一种非常灵活的关联机制,实现了 API 对象之间的松耦合。
-
(19 讲)DaemonSet 是另一种部署在线业务的方式,它很类似 Deployment,但会在集群里的每一个节点上运行一个 Pod 实例,类似 Linux 系统里的“守护进程”,适合日志、监控等类型的应用。
-
DaemonSet 能够任意部署 Pod 的关键概念是“污点”(taint)和“容忍度”(toleration)。Node 会有各种“污点”,而 Pod 可以使用“容忍度”来忽略“污点”,合理使用这两个概念就可以调整 Pod 在集群里的部署策略。
-
(20 讲)由 Deployment 和 DaemonSet 部署的 Pod,在集群中处于“动态平衡”的状态,总数量保持恒定,但也有临时销毁重建的可能,所以 IP 地址是变化的,这就为微服务等应用架构带来了麻烦。
-
Service 是对 Pod IP 地址的抽象,它拥有一个固定的 IP 地址,再使用 iptables 规则把流量负载均衡到后面的 Pod,节点上的 kube-proxy 组件会实时维护被代理的 Pod 状态,保证 Service 只会转发给健康的 Pod。
-
Service 还基于 DNS 插件支持域名,所以客户端就不再需要关心 Pod 的具体情况,只要通过 Service 这个稳定的中间层,就能够访问到 Pod 提供的服务。
-
(21 讲)Service 是四层的负载均衡,但现在的绝大多数应用都是 HTTP/HTTPS 协议,要实现七层的负载均衡就要使用 Ingress 对象。
-
Ingress 定义了基于 HTTP 协议的路由规则,但要让规则生效,还需要 Ingress Controller 和 Ingress Class 来配合工作。
-
Ingress Controller 是真正的集群入口,应用 Ingress 规则调度、分发流量,此外还能够扮演反向代理的角色,提供安全防护、TLS 卸载等更多功能。
-
Ingress Class 是用来管理 Ingress 和 Ingress Controller 的概念,方便我们分组路由规则,降低维护成本。
-
不过 Ingress Controller 本身也是一个 Pod,想要把服务暴露到集群外部还是要依靠 Service。Service 支持 NodePort、LoadBalancer 等方式,但 NodePort 的端口范围有限,LoadBalancer 又依赖于云服务厂商,都不是很灵活。
-
折中的办法是用少量 NodePort 暴露 Ingress Controller,用 Ingress 路由到内部服务,外部再用反向代理或者 LoadBalancer 把流量引进来。
WordPress 网站基本架构
简略回顾了 Kubernetes 里这些 API 对象,下面我们就来使用它们再搭建出 WordPress 网站,实践加深理解。
既然我们已经掌握了 Deployment、Service、Ingress 这些 Pod 之上的概念,网站自然会有新变化,架构图我放在了这里:
这次的部署形式比起 Docker、minikube 又有了一些细微的差别,重点是我们已经完全舍弃了 Docker,把所有的应用都放在 Kubernetes 集群里运行,部署方式也不再是裸 Pod,而是使用 Deployment,稳定性大幅度提升。
原来的 Nginx 的作用是反向代理,那么在 Kubernetes 里它就升级成了具有相同功能的 Ingress Controller。WordPress 原来只有一个实例,现在变成了两个实例(你也可以任意横向扩容),可用性也就因此提高了不少。而 MariaDB 数据库因为要保证数据的一致性,暂时还是一个实例。
还有,因为 Kubernetes 内置了服务发现机制 Service,我们再也不需要去手动查看 Pod 的 IP 地址了,只要为它们定义 Service 对象,然后使用域名就可以访问 MariaDB、WordPress 这些服务。
网站对外提供服务我选择了两种方式。
一种是让 WordPress 的 Service 对象以 NodePort 的方式直接对外暴露端口 30088,方便测试;另一种是给 Nginx Ingress Controller 添加“hostNetwork”属性,直接使用节点上的端口号,类似 Docker 的 host 网络模式,好处是可以避开 NodePort 的端口范围限制。
下面我们就按照这个基本架构来逐步搭建出新版本的 WordPress 网站,编写 YAML 声明。
这里有个小技巧,在实际操作的时候你一定要记得善用 kubectl create、kubectl expose 创建样板文件,节约时间的同时,也能避免低级的格式错误。
1. WordPress 网站部署 MariaDB
首先我们还是要部署 MariaDB,这个步骤和在第 15 讲里做的也差不多。
先要用 ConfigMap 定义数据库的环境变量,有 DATABASE、USER、PASSWORD、ROOT_PASSWORD:
apiVersion: v1
kind: ConfigMap
metadata:
name: maria-cm
data:
DATABASE: 'db'
USER: 'wp'
PASSWORD: '123'
ROOT_PASSWORD: '123'
然后我们需要把 MariaDB 由 Pod 改成 Deployment 的方式,replicas 设置成 1 个,template 里面的 Pod 部分没有任何变化,还是要用 envFrom把配置信息以环境变量的形式注入 Pod,相当于把 Pod 套了一个 Deployment 的“外壳”:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: maria-dep
name: maria-dep
spec:
replicas: 1
selector:
matchLabels:
app: maria-dep
template:
metadata:
labels:
app: maria-dep
spec:
containers:
- image: mariadb:10
name: mariadb
ports:
- containerPort: 3306
envFrom:
- prefix: 'MARIADB_'
configMapRef:
name: maria-cm
我们还需要再为 MariaDB 定义一个 Service 对象,映射端口 3306,让其他应用不再关心 IP 地址,直接用 Service 对象的名字来访问数据库服务:
apiVersion: v1
kind: Service
metadata:
labels:
app: maria-dep
name: maria-svc
spec:
ports:
- port: 3306
protocol: TCP
targetPort: 3306
selector:
app: maria-dep
因为这三个对象都是数据库相关的,所以可以在一个 YAML 文件里书写,对象之间用 — 分开,这样用 kubectl apply 就可以一次性创建好:
kubectl apply -f wp-maria.yml
执行命令后,你应该用 kubectl get 查看对象是否创建成功,是否正常运行:

2. WordPress 网站部署 WordPress
第二步是部署 WordPress 应用。
因为刚才创建了 MariaDB 的 Service,所以在写 ConfigMap 配置的时候“HOST”就不应该是 IP 地址了,而应该是 DNS 域名,也就是 Service 的名字maria-svc**,这点需要特别注意**:
apiVersion: v1
kind: ConfigMap
metadata:
name: wp-cm
data:
HOST: 'maria-svc'
USER: 'wp'
PASSWORD: '123'
NAME: 'db'
WordPress 的 Deployment 写法和 MariaDB 也是一样的,给 Pod 套一个 Deployment 的“外壳”,replicas 设置成 2 个,用字段“envFrom”配置环境变量:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: wp-dep
name: wp-dep
spec:
replicas: 2
selector:
matchLabels:
app: wp-dep
template:
metadata:
labels:
app: wp-dep
spec:
containers:
- image: wordpress:5
name: wordpress
ports:
- containerPort: 80
envFrom:
- prefix: 'WORDPRESS_DB_'
configMapRef:
name: wp-cm
然后我们仍然要为 WordPress 创建 Service 对象,这里我使用了“NodePort”类型,并且手工指定了端口号“30088”(必须在 30000~32767 之间):
apiVersion: v1
kind: Service
metadata:
labels:
app: wp-dep
name: wp-svc
spec:
ports:
- name: http80
port: 80
protocol: TCP
targetPort: 80
nodePort: 30088
selector:
app: wp-dep
type: NodePort
现在让我们用 kubectl apply 部署 WordPress:
kubectl apply -f wp-dep.yml
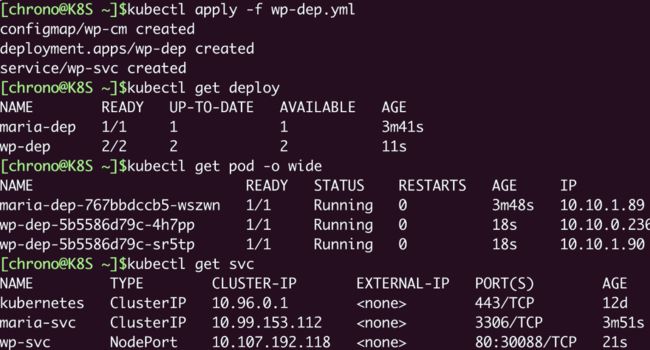
因为 WordPress 的 Service 对象是 NodePort 类型的,我们可以在集群的每个节点上访问 WordPress 服务。
比如一个节点的 IP 地址是“192.168.10.210”,那么你就在浏览器的地址栏里输入“http://192.168.10.210:30088”,其中的“30088”就是在 Service 里指定的节点端口号,然后就能够看到 WordPress 的安装界面了:

3. WordPress 网站部署 Nginx Ingress Controller
现在 MariaDB,WordPress 都已经部署成功了,第三步就是部署 Nginx Ingress Controller。
首先我们需要定义 Ingress Class,名字就叫“wp-ink”,非常简单:
apiVersion: networking.k8s.io/v1
kind: IngressClass
metadata:
name: wp-ink
spec:
controller: nginx.org/ingress-controller
然后用 kubectl create 命令生成 Ingress 的样板文件,指定域名是“wp.test”,后端 Service 是“wp-svc:80”,Ingress Class 就是刚定义的“wp-ink”:
kubectl create ing wp-ing --rule="wp.test/=wp-svc:80" --class=wp-ink $out
得到的 Ingress YAML 就是这样,注意路径类型我还是用的前缀匹配“Prefix”:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: wp-ing
spec:
ingressClassName: wp-ink
rules:
- host: wp.test
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: wp-svc
port:
number: 80
接下来就是最关键的 Ingress Controller 对象了,它仍然需要从 Nginx 项目的示例 YAML 修改而来,要改动名字、标签,还有参数里的 Ingress Class。
在之前讲基本架构的时候我说过了,这个 Ingress Controller 不使用 Service,而是给它的 Pod 加上一个特殊字段 hostNetwork,让 Pod 能够使用宿主机的网络,相当于另一种形式的 NodePort:
apiVersion: apps/v1
kind: Deployment
metadata:
name: wp-kic-dep
namespace: nginx-ingress
spec:
replicas: 1
selector:
matchLabels:
app: wp-kic-dep
template:
metadata:
labels:
app: wp-kic-dep
spec:
serviceAccountName: nginx-ingress
# use host network
hostNetwork: true
containers:
...
准备好 Ingress 资源后,我们创建这些对象:
kubectl apply -f wp-ing.yml -f wp-kic.yml
现在所有的应用都已经部署完毕,可以在集群外面访问网站来验证结果了。
不过你要注意,Ingress 使用的是 HTTP 路由规则,用 IP 地址访问是无效的,所以在集群外的主机上必须能够识别我们的“wp.test”域名,也就是说要把域名“wp.test”解析到 Ingress Controller 所在的节点上。
如果你用的是 Mac,那就修改 /etc/hosts;如果你用的是 Windows,就修改 C:\Windows\System32\Drivers\etc\hosts,添加一条解析规则就行:
cat /etc/hosts
192.168.10.210 wp.test
有了域名解析,在浏览器里你就不必使用 IP 地址,直接用域名“wp.test”走 Ingress Controller 就能访问我们的 WordPress 网站了:

23|视频:中级篇实操总结
一. 安装 kubeadm
二. 安装 Kubernetes
三. Kubernetes 集群部署
四. Deployment 的使用
# kubectl api-resources 来查看 Deployment 的基本信息
kubectl api-resources | grep deploy
可以看到 Deployment 的简称是“deploy”,它的 apiVersion 是“apps/v1”,kind 是“Deployment”。
然后我们执行 kubectl create,让 Kubernetes 为我们自动生成 Deployment 的样板文件。
# 先要定义一个环境变量 out:
export out="--dry-run=client -o yaml"
# 然后创建名字叫“ngx-dep”的对象,使用的镜像是“nginx:alpine”:
kubectl create deploy ngx-dep --image=nginx:alpine $out
# 把这个样板存入一个文件 ngx.yml
kubectl create deploy ngx-dep --image=nginx:alpine $out > deploy.yml
# 这里可以删除一些不需要的字段,让 YAML 看起来更干净,然后把 replicas 改成 2,意思是启动两个 Nginx Pod。
# 把 Deployment 的 YAML 写好之后,我们就可以用 kubectl apply 来创建对象了:
kubectl apply -f deploy.yml
# 用 kubectl get 命令查看 Deployment 的状态:
kubectl get deploy
kubectl get pod
# 来试验一下 Deployment 的应用伸缩功能,使用命令 kubectl scale,把 Pod 数量改成 5 个:
kubectl scale --replicas=5 deploy ngx-dep
五. DaemonSet 的使用
因为 DaemonSet 不能使用 kubectl create 直接生成样板文件,但大体结构和 Deployment 是一样的,所以我们可以先生成一个 Deployment,然后再修改几个字段就行了。
这里我使用了 Linux 系统里常用的小工具 sed,直接替换 Deployment 里的名字,再删除 replicas 字段,这样就自动生成了 DaemonSet 的样板文件:
kubectl create deploy redis-ds --image=redis:5-alpine $out \
| sed 's/Deployment/DaemonSet/g' - \
| sed -e '/replicas/d' -
这个样板文件因为是从 Deployment 改来的,所以不会有 tolerations 字段,不能在 Master 节点上运行,需要手工添加。
注意看里面的 tolerations 字段,它能够容忍节点的 node-role.kubernetes.io/master:NoSchedule 这个污点,也就是说能够运行在 Master 节点上。
六. Service 的使用
# 使用 kubectl expose 创建 Service 样板文件
kubectl expose deploy ngx-dep --port=80 --target-port=80 $out
# 修改之后就是 svc.yml,再用 kubectl apply 创建 Service 对象
kubectl apply -f svc.yml
# 用 kubectl get svc 可以列出 Service 对象,可以看到它的虚 IP 地址
kubectl get svc
# 要看 Service 代理了哪些后端的 Pod,要用 kubectl describe 命令
kubectl describe svc ngx-svc
# 用 kubectl get pod 可以对比验证 Service 是否正确代理了 Nginx Pod
kubectl get pod -o wide
# 现在让我们用 kubectl exec 进入 Pod,验证 Service 的域名功能
kubectl exec -it ngx-dep-6796688696-4h6lb -- sh
# 使用 curl,加上域名“ngx-svc”,也就是 Service 对象的名字
curl ngx-svc
# 多执行几次,就会看到通过这个域名,Service 对象实现了对后端 Pod 的负载均衡,把流量分发到不同的 Pod。
# 我们还可以再尝试 Service 的其他域名形式,比如加上名字空间:
curl ngx-svc.default
curl ngx-svc.default.svc.cluster.local
七. Ingress 的使用
24|PersistentVolume:怎么解决数据持久化的难题?
什么是 PersistentVolume
我们在 Kubernetes 集群里搭建了 WordPress 网站,但其中存在一个很严重的问题:Pod 没有持久化功能,导致 MariaDB 无法“永久”存储数据。
因为 Pod 里的容器是由镜像产生的,而镜像文件本身是只读的,进程要读写磁盘只能用一个临时的存储空间,一旦 Pod 销毁,临时存储也就会立即回收释放,数据也就丢失了。
为了保证即使 Pod 销毁后重建数据依然存在,我们就需要找出一个解决方案,让 Pod 用上真正的“虚拟盘”。怎么办呢?
其实,Kubernetes 的 Volume 对数据存储已经给出了一个很好的抽象,它只是定义了有这么一个“存储卷”,而这个“存储卷”是什么类型、有多大容量、怎么存储,我们都可以自由发挥。Pod 不需要关心那些专业、复杂的细节,只要设置好 volumeMounts,就可以把 Volume 加载进容器里使用。
所以,Kubernetes 就顺着 Volume 的概念,延伸出了 PersistentVolume 对象,它专门用来表示持久存储设备,但隐藏了存储的底层实现,我们只需要知道它能安全可靠地保管数据就可以了(由于 PersistentVolume 这个词很长,一般都把它简称为 PV)。
那么,集群里的 PV 都从哪里来呢?
作为存储的抽象,PV 实际上就是一些存储设备、文件系统,比如 Ceph、GlusterFS、NFS,甚至是本地磁盘,管理它们已经超出了 Kubernetes 的能力范围,所以,一般会由系统管理员单独维护,然后再在 Kubernetes 里创建对应的 PV。
要注意的是,PV 属于集群的系统资源,是和 Node 平级的一种对象,Pod 对它没有管理权,只有使用权。
什么是 PersistentVolumeClaim/StorageClass
现在有了 PV,我们是不是可以直接在 Pod 里挂载使用了呢?
还不行。因为不同存储设备的差异实在是太大了:有的速度快,有的速度慢;有的可以共享读写,有的只能独占读写;有的容量小,只有几百 MB,有的容量大到 TB、PB 级别……
这么多种存储设备,只用一个 PV 对象来管理还是有点太勉强了,不符合“单一职责”的原则,让 Pod 直接去选择 PV 也很不灵活。于是 Kubernetes 就又增加了两个新对象,PersistentVolumeClaim 和 StorageClass,用的还是“中间层”的思想,把存储卷的分配管理过程再次细化。
我们看这两个新对象。
PersistentVolumeClaim,简称 PVC,从名字上看比较好理解,就是用来向 Kubernetes 申请存储资源的。PVC 是给 Pod 使用的对象,它相当于是 Pod 的代理,代表 Pod 向系统申请 PV。一旦资源申请成功,Kubernetes 就会把 PV 和 PVC 关联在一起,这个动作叫做“绑定”(bind)。
但是,系统里的存储资源非常多,如果要 PVC 去直接遍历查找合适的 PV 也很麻烦,所以就要用到 StorageClass。
StorageClass 的作用有点像第 21 讲里的 IngressClass,它抽象了特定类型的存储系统(比如 Ceph、NFS),在 PVC 和 PV 之间充当“协调人”的角色,帮助 PVC 找到合适的 PV。也就是说它可以简化 Pod 挂载“虚拟盘”的过程,让 Pod 看不到 PV 的实现细节。

如果看到这里,你觉得还是差点理解也不要着急,我们找个生活中的例子来类比一下。毕竟和常用的 CPU、内存比起来,我们对存储系统的认识还是比较少的,所以 Kubernetes 里,PV、PVC 和 StorageClass 这三个新概念也不是特别好掌握。
看例子,假设你在公司里想要 10 张纸打印资料,于是你给前台打电话讲清楚了需求。
- “打电话”这个动作,就相当于 PVC,向 Kubernetes 申请存储资源。
- 前台里有各种牌子的办公用纸,大小、规格也不一样,这就相当于 StorageClass。
- 前台根据你的需要,挑选了一个品牌,再从库存里拿出一包 A4 纸,可能不止 10 张,但也能够满足要求,就在登记表上新添了一条记录,写上你在某天申领了办公用品。这个过程就是 PVC 到 PV 的绑定。
- 而最后到你手里的 A4 纸包,就是 PV 存储对象。
好,大概了解了这些 API 对象,我们接下来可以结合 YAML 描述和实际操作再慢慢体会。
如何使用 YAML 描述 PersistentVolume
Kubernetes 里有很多种类型的 PV,我们先看看最容易的本机存储“HostPath”,它和 Docker 里挂载本地目录的 -v 参数非常类似,可以用它来初步认识一下 PV 的用法。
因为 Pod 会在集群的任意节点上运行,所以首先,我们要作为系统管理员在每个节点上创建一个目录,它将会作为本地存储卷挂载到 Pod 里。
为了省事,我就在 /tmp 里建立名字是 host-10m-pv 的目录,表示一个只有 10MB 容量的存储设备。
有了存储,我们就可以使用 YAML 来描述这个 PV 对象了。
不过很遗憾,你不能用 kubectl create 直接创建 PV 对象,只能用 kubectl api-resources、kubectl explain 查看 PV 的字段说明,手动编写 PV 的 YAML 描述文件。
下面我给出一个 YAML 示例,你可以把它作为样板,编辑出自己的 PV:
apiVersion: v1
kind: PersistentVolume
metadata:
name: host-10m-pv
spec:
storageClassName: host-test
accessModes:
- ReadWriteOnce
capacity:
storage: 10Mi
hostPath:
path: /tmp/host-10m-pv/
PV 对象的文件头部分很简单,还是 API 对象的“老一套”,我就不再详细解释了,重点看它的 spec 部分,每个字段都很重要,描述了存储的详细信息。
“storageClassName”就是刚才说过的,对存储类型的抽象 StorageClass。这个 PV 是我们手动管理的,名字可以任意起,这里我写的是 host-test,你也可以把它改成 manual、hand-work 之类的词汇。
“accessModes”定义了存储设备的访问模式,简单来说就是虚拟盘的读写权限,和 Linux 的文件访问模式差不多,目前 Kubernetes 里有 3 种:
- ReadWriteOnce:存储卷可读可写,但只能被一个节点上的 Pod 挂载。
- ReadOnlyMany:存储卷只读不可写,可以被任意节点上的 Pod 多次挂载。
- ReadWriteMany:存储卷可读可写,也可以被任意节点上的 Pod 多次挂载。
你要注意,这 3 种访问模式限制的对象是节点而不是 Pod,因为存储是系统级别的概念,不属于 Pod 里的进程。
显然,本地目录只能是在本机使用,所以这个 PV 使用了 ReadWriteOnce。
第三个字段“capacity”就很好理解了,表示存储设备的容量,这里我设置为 10MB。
再次提醒你注意,Kubernetes 里定义存储容量使用的是国际标准,我们日常习惯使用的 KB/MB/GB 的基数是 1024,要写成 Ki/Mi/Gi,一定要小心不要写错了,否则单位不一致实际容量就会对不上。
最后一个字段“hostPath”最简单,它指定了存储卷的本地路径,也就是我们在节点上创建的目录。
用这些字段把 PV 的类型、访问模式、容量、存储位置都描述清楚,一个存储设备就创建好了。
如何使用 YAML 描述 PersistentVolumeClaim
有了 PV,就表示集群里有了这么一个持久化存储可以供 Pod 使用,我们需要再定义 PVC 对象,向 Kubernetes 申请存储。
下面这份 YAML 就是一个 PVC,要求使用一个 5MB 的存储设备,访问模式是 ReadWriteOnce:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: host-5m-pvc
spec:
storageClassName: host-test
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Mi
PVC 的内容与 PV 很像,但它不表示实际的存储,而是一个“申请”或者“声明”,spec 里的字段描述的是对存储的“期望状态”。
所以 PVC 里的 storageClassName、accessModes 和 PV 是一样的,但不会有字段 capacity**,而是要用** resources.request 表示希望要有多大的容量。
这样,Kubernetes 就会根据 PVC 里的描述,去找能够匹配 StorageClass 和容量的 PV,然后把 PV 和 PVC“绑定”在一起,实现存储的分配,和前面打电话要 A4 纸的过程差不多。
如何在 Kubernetes 里使用 PersistentVolume
现在我们已经准备好了 PV 和 PVC,就可以让 Pod 实现持久化存储了。
首先需要用 kubectl apply 创建 PV 对象:
kubectl apply -f host-path-pv.yml
# 然后用 kubectl get 查看它的状态:
kubectl get pv
![]()
从截图里我们可以看到,这个 PV 的容量是 10MB,访问模式是 RWO(ReadWriteOnce),StorageClass 是我们自己定义的 host-test,状态显示的是 Available,也就是处于可用状态,可以随时分配给 Pod 使用。
接下来我们创建 PVC,申请存储资源:
kubectl apply -f host-path-pvc.yml
kubectl get pvc
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sDWCj2fg-1685935106186)(/Users/songyujian/Library/Application Support/typora-user-images/image-20230319183133053.png)]
一旦 PVC 对象创建成功,Kubernetes 就会立即通过 StorageClass、resources 等条件在集群里查找符合要求的 PV,如果找到合适的存储对象就会把它俩“绑定”在一起。
PVC 对象申请的是 5MB,但现在系统里只有一个 10MB 的 PV,没有更合适的对象,所以 Kubernetes 也只能把这个 PV 分配出去,多出的容量就算是“福利”了。
你会看到这两个对象的状态都是 Bound,也就是说存储申请成功,PVC 的实际容量就是 PV 的容量 10MB,而不是最初申请的容量 5MB。
那么,如果我们把 PVC 的申请容量改大一些会怎么样呢?比如改成 100MB:

你会看到 PVC 会一直处于 Pending 状态,这意味着 Kubernetes 在系统里没有找到符合要求的存储,无法分配资源,只能等有满足要求的 PV 才能完成绑定。
如何为 Pod 挂载 PersistentVolume
PV 和 PVC 绑定好了,有了持久化存储,现在我们就可以为 Pod 挂载存储卷。用法和第 14 讲里差不多,先要在 spec.volumes 定义存储卷,然后在 containers.volumeMounts 挂载进容器。
不过因为我们用的是 PVC,所以要在 volumes 里用字段 persistentVolumeClaim 指定 PVC 的名字。
下面就是 Pod 的 YAML 描述文件,把存储卷挂载到了 Nginx 容器的 /tmp 目录:
apiVersion: v1
kind: Pod
metadata:
name: host-pvc-pod
spec:
volumes:
- name: host-pvc-vol
persistentVolumeClaim:
claimName: host-5m-pvc
containers:
- name: ngx-pvc-pod
image: nginx:alpine
ports:
- containerPort: 80
volumeMounts:
- name: host-pvc-vol
mountPath: /tmp
我把 Pod 和 PVC/PV 的关系画成了图(省略了字段 accessModes),你可以从图里看出它们是如何联系起来的:

现在我们创建这个 Pod,查看它的状态:
kubectl apply -f host-path-pod.yml
kubectl get pod -o wide

它被 Kubernetes 调到了 worker 节点上,那么 PV 是否确实挂载成功了呢?让我们用 kubectl exec 进入容器,执行一些命令看看:
容器的 /tmp 目录里生成了一个 a.txt 的文件,根据 PV 的定义,它就应该落在 worker 节点的磁盘上,所以我们就登录 worker 节点检查一下:
你会看到确实在 worker 节点的本地目录有一个 a.txt 的文件,再对一下时间,就可以确认是刚才在 Pod 里生成的文件。
因为 Pod 产生的数据已经通过 PV 存在了磁盘上,所以如果 Pod 删除后再重新创建,挂载存储卷时会依然使用这个目录,数据保持不变,也就实现了持久化存储。
不过还有一点小问题,因为这个 PV 是 HostPath 类型,只在本节点存储,如果 Pod 重建时被调度到了其他节点上,那么即使加载了本地目录,也不会是之前的存储位置,持久化功能也就失效了。
所以,HostPath 类型的 PV 一般用来做测试,或者是用于 DaemonSet 这样与节点关系比较密切的应用,我们下节课再讲实现真正任意的数据持久化。
小结
好了,今天我们一起学习了 Kubernetes 里应对持久化存储的解决方案,一共有三个 API 对象,分别是 PersistentVolume、PersistentVolumeClaim、StorageClass。它们管理的是集群里的存储资源,简单来说就是磁盘,Pod 必须通过它们才能够实现数据持久化。
再小结一下今天的主要内容:
PersistentVolume 简称为 PV,是 Kubernetes 对存储设备的抽象,由系统管理员维护,需要描述清楚存储设备的类型、访问模式、容量等信息。
PersistentVolumeClaim 简称为 PVC,代表 Pod 向系统申请存储资源,它声明对存储的要求,Kubernetes 会查找最合适的 PV 然后绑定。
StorageClass 抽象特定类型的存储系统,归类分组 PV 对象,用来简化 PV/PVC 的绑定过程。
HostPath 是最简单的一种 PV,数据存储在节点本地,速度快但不能跟随 Pod 迁移。
