Path-Level Network Transformation for Efficient Architecture Search
Path-Level Network Transformation for Efficient Architecture Search
Abstract
我们引入了一种新的函数保持转换,用于有效的神经架构搜索。这种网络转换允许重用先前训练的网络和现有的成功架构,从而提高样本效率。我们的目标是解决当前网络转换操作只能执行层级的限制架构修改,例如添加(修剪)筛选器或插入(删除)层,无法更改连接路径的拓扑。我们提出的路径级转换操作使得元控制器能够在保留权重重用优点的同时修改给定网络的路径拓扑,从而能够有效地设计具有复杂路径拓扑的有效结构,如初始模型。我们进一步提出了一个双向树状结构强化学习元控制器,以探索一个简单但具有高度表现力的树状结构空间,可以看作是多分支结构的推广。我们在计算资源有限的图像分类数据集(约200 GPU小时)上进行了实验,观察到参数效率提高,测试结果更好(在移动环境中,CIFAR-10的14.3M参数测试精度为97.70%,ImageNet的top-1精度为74.6%),展示我们设计的架构的有效性和可移植性。
- Introduction
或者,通过网络转换,从一个针对目标任务训练的现有网络开始,并重用其权重,来探索体系结构空间。例如,蔡等人。(2018)利用Net2Net(Chen et al.,2016)操作(一类保留功能的转换操作)进一步找到基于给定网络的高性能架构,而Ashok et al.(2018)利用网络压缩操作压缩训练有素的网络。这些方法允许从先前训练的网络转移知识,并利用目标任务中现有的成功架构,因此显示出改进的效率,并且需要的计算资源显著减少(例如,Cai中的5gpu等)。(2018年)实现竞争性成果。
然而,在Cai等人的网络改造操作中。(2018)和Ashok等人。(2018)仍然仅限于执行层级架构修改,例如添加(修剪)过滤器或插入(移除)层,这不会改变神经网络中连接路径的拓扑。因此,它们将搜索空间限制为具有与起始网络相同的路径拓扑,即当给定链结构起始点时,它们总是导致链结构网络。由于最先进的卷积神经网络(CNN)结构已经超越了简单的链式结构布局,并证明了多路径结构的有效性,如初始模型(Szegedy et al.,2015)、ResNets(He et al.,2016)和DenseNets(Huang et al.,2017b),我们希望这些方法能够在保持权重重用优点的同时,探索具有不同和复杂路径拓扑的搜索空间。
在本文中,我们提出了一种新的神经网络转换操作,称为路径级网络转换操作,它允许修改给定网络中的路径拓扑,同时允许权重重用以保留Net2Net操作等功能(Chen et al.,2016)。基于所提出的路径级操作,我们引入了一个简单但具有高度表现力的树状结构空间,它可以看作是多分支结构的广义形式。为了有效地探索引入的树结构体系结构空间,我们进一步提出了一种双向树结构(Tai等人,2015)强化学习元控制器,该控制器可以自然地对输入树进行编码,而不是简单地使用链结构递归神经网络(Zoph等人,2017)。
2. Related Work and Background
2.1. Architecture Search
旨在自动发现给定架构空间中有效模型架构的架构搜索已使用多种方法进行了研究,这些方法可分为神经进化(Real et al.,2017;Liu et al.,2018)、贝叶斯优化(Domhan et al.,2015;Mendoza et al.,2016)、蒙特卡罗树搜索(Negrinho&Gordon,2017)和强化学习(RL)(Zoph&Le,2017;Baker等人,2017;Zhong等人,2017;Zoph等人,2017)。
由于对每个设计的体系结构进行评估需要对真实数据进行培训,这使得直接在大型数据集(如ImageNet(Deng等人,2009))上应用体系结构搜索方法的计算成本高昂,Zoph等人。(2017)建议搜索可以稍后堆叠的CNN单元,而不是搜索整个架构。具体来说,单元结构的学习是在小数据集(例如,CIFAR-10)上进行的,而学习的单元结构则被转移到大数据集(例如,ImageNet)。此方案也被纳入了Zhong等人的研究中。(2017)和Liu等人。(2018年)。
另一方面,与从头开始构建和评估体系结构不同,最近的一些工作提出了在目标任务中利用网络转换操作来探索给定训练网络的体系结构空间,并重用权重。蔡等人。(2018)提出了一种递归神经网络来迭代生成 基于当前网络结构执行转换操作,并使用增强算法训练递归网络(Williams,1992)。Ashok等人也纳入了类似的框架。(2018)在Cai等中,转换操作从Net2Net操作改变。(2018)压缩操作。
与上述工作相比,本文将现有的网络转换操作从层级扩展到路径级,类似于Zoph等。(2017)和Zhong等人。(2017),我们专注于学习CNN细胞,同时我们的方法可以很容易地与任何现有的精心设计的架构相结合,以利用它们的成功,并允许重用权重以保留功能。
2.2. Multi-Branch Neural Networks
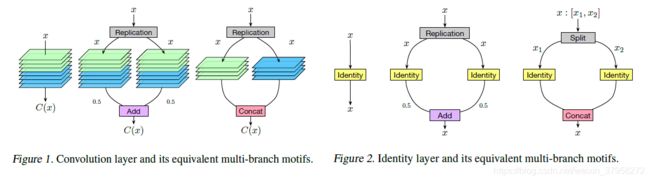
多分支结构(或主题)是许多现代最先进的CNN架构的重要组成部分。Inception模型系列(Szegedy等人,2015;2017;2016)是成功的多分支架构,具有精心定制的分支。ResNets(He et al.,2016)和DenseNets(Huang et al.,2017b)可以看作是两个分支架构,其中一个分支是身份映射。这些多分支体系结构中的一个常见策略是,输入特征映射x首先基于特定的分配方案(在初始模型中拆分或在resnet和densenet中复制)分布到每个分支,然后通过每个分支上的基本操作(例如卷积、池等)进行转换,最后进行聚合,根据特定的合并方案(在Inception模型和densenet中添加ResNets或连接)生成输出。
根据Veit等人的研究。(2016),ResNets可以被认为是许多不同长度路径集合的集合。类似的解释也可以应用于初始模型和densenet,因为初始模型已经证明了精心定制的分支的优点,在每个分支中使用不同的原始操作,因此,研究CNN单元内更复杂、设计更完善的路径拓扑是否能使集合视图中的路径集合更丰富、更多样,是一个非常有意义的问题。
在这项工作中,我们探索了一个树状结构的架构空间,在每个节点上,输入特征映射被分配给每个分支,经过一些基本操作和相应的子节点,然后合并为节点的输出。它可以看作是当前多分支结构(深度为1的树)的一种推广,并且能够在CNN单元中嵌入大量的路径。
2.3. Function-Preserving Network Transformation
功能保持网络转换是指初始化学生网络以保持给定教师网络功能的一类网络转换操作。Net2Net技术(Chen et al.,2016)引入了两种特定的功能保持转换操作,即Net2WiderNet操作,它用更宽的等效层(例如 用于卷积层的滤波器)和Net2DeeperNet操作,该操作用可初始化为identity的层替换标识映射,包括具有各种滤波器的正常卷积层(例如,3×3、7×1、1×7等)、可分离卷积层(Chollet,2016)等。此外,网络压缩操作(Han等人,2015年)在不降低性能的情况下剪除不太重要的连接(例如,低权重连接)以缩小给定模型的大小,也可以被视为一种保留函数的转换操作。我们的方法建立在现有的保留功能的转换操作之上,并进一步扩展到路径级的架构修改。
3. Method
3.1. Path-Level Network Transformation
我们介绍一种操作允许把一层网络替换为多分支结构,他的合并分支方案为add 或者concatenation.为了说明这些操作,我们使用了两种特定类型的层,即identity层和正常卷积层作为示例,同时它们也可以类似地应用于其他类似类型的层,例如深度可分离卷积层。
对于一个卷积层,用 C ( ⋅ ) C(\cdot) C(⋅)表示,为了构造一个具有N个分支的等价多分支motif,我们需要对分支进行设置,以模拟对任意feature map x相对应于原始层的输出。当这些分支通过add合并时,分配方案设置replication,我们将每个分支设置为原始层C(.)的复制,使得每个分支产生相同的输出(即C(x)),再通过add合并后导致一个 N × C ( x ) N\times C(x) N×C(x)的输出。为了消除这个因素,我们进一步将每个分支的输出除以N。因此,多分支的输出与原始卷积层的输出保持相同,如图1(中间)所示。当这些分支通过连接(concatenatio)合并时,分配方案也设置为replication。然后,我们将原始卷积层的滤波器沿输出通道维度分成N部分,并将每个部分分配给相应的分支,然后合并该分支以产生输出C(x),如图1(右)所示。
对于identity层,当通过add合并分支时,转换是相同的,只是在这种情况下,每个分支中的卷积层更改为identity映射(图2(中间))。当通过连接合并分支时,分配方案设置为拆分,每个分支设置为identity映射,如图2(右)所示。

图3。通过路径级转换操作将单层转换为树状结构基序的说明,其中我们在(c)中应用Net2DeeperNet操作用3×3可分离卷积替换identity映射。
注意,简单地应用上述转换并不会导致重要的路径拓扑修改。修改。然而,当与Net2Net操作结合使用时,我们能够极大地更改路径拓扑结构,如图3所示。例如,我们可以通过应用Net2DeeperNet操作在每个分支中插入不同数量和类型的层,这使得每个分支变得本质上不同,就像初始模型一样。此外,由于这种变换可以重复应用于神经网络中的任何适用层,例如分支中的层,因此我们可以任意增加路径拓扑的复杂性。
3.2. Tree-Structured Architecture Space
在本节中,我们将描述树状结构的体系结构空间,如图3所示,这些空间可以通过路径级的网络转换操作进行探索。

树型结构由边和节点组成,在每个节点(叶节点除外)上,我们有分配方案和合并方案的特定组合,节点通过一个定义为卷积、池等基本操作的边连接到其每个子节点。给定一个输入特征图x,拥有m个子节点的输出用 { N i c ( ⋅ ) } \{N_i^c(\cdot)\} {Nic(⋅)}表示,m条相对应的边用 { E i ( ⋅ ) } \{E_i(\cdot)\} {Ei(⋅)}表示,节点的输出 N ( ⋅ ) N(\cdot) N(⋅)根据子节点的输出递归定义:

其中 a l l o c t i o n ( x , i ) alloction(x,i) alloction(x,i)代表的是根据指定的分配策略第i个子节点的分支特征图,merge(.)表示将子节点的输出作为输入并输出聚合结果(也是节点的输出)的合并方案。对于没有子节点的叶节点,它只返回输入特征图作为输出。 如式(1)所定义,对于树结构架构,特征映射首先被馈送到其根节点,然后通过自上而下的方式根据节点和边的分配方案传播到所有后续节点,直到到达叶节点为止,最后以自底向上的方式在镜像中从叶节点聚合到根节点,生成最终的输出特征映射。
请注意,树结构的体系结构空间并不是通过所建议的路径级转换操作可以实现的完整体系结构空间。为了便于实现,我们选择探索树状结构的架构空间,并进一步应用架构搜索方法,如基于RL的方法(Cai et al.,2018),这些方法需要对架构进行编码。选择树型结构空间的另一个原因是它与现有的多分支结构有很强的联系,可以看作深度为1的树型结构,即根节点的所有子节点都是叶子。
为了在树状结构的体系结构空间中应用体系结构搜索方法,需要通过定义可能的分配方案集、合并方案集和基元操作来进一步指定。如第2.2节和第3.1节所述,分配方案为复制或拆分,合并方案为添加或连接。对于原始操作,与之前的工作类似(Zoph et al.,2017;Liu et al.,2018),我们考虑以下7种类型的层:
1 x 1 convolution
Identity
3 x 3 depthwise-separable convolution
5 x 5 depthwise-separable convolution
7 x 7 depthwise-separable convolution
3 x 3 average pooling
3 x 3 max pooling
在这里,我们包括不能初始化为identity映射的池化层(we include pooling layers that cannot be initialized as identity mapping.)。为了在选择池层时保持功能,我们进一步重建了学生网络中的权重 (即转换后的网络),使用知识蒸馏的思想模仿给定教师网络的输出logits(Hinton 等人,2015)。由于池化层并没有显著地破坏多径神经网络的功能,我们发现重建过程的成本可以忽略不计。
3.3. Architecture Search with Path-Level Operations
在这一部分中,我们提出了一个RL代理作为元控制器来探索树状结构的体系结构空间。总体框架与Cai等人提出的框架相似。(2018)元控制器迭代采样网络转换动作,生成新的架构,这些架构随后被训练以获得验证性能,作为奖励信号,通过策略梯度算法更新元控制器。为了将输入架构映射到转换动作,元控制器具有学习给定架构的低维表示的编码器网络和生成相应网络转换动作的不同softmax分类器。
在这项工作中,由于输入架构现在有一个树状结构的拓扑结构,无法用一系列令牌轻松指定,因此我们建议使用树状结构的LSTM来编码架构,而不是使用链式结构的长短期内存(LSTM)网络(Hochreiter&Schmidhuber,1997年)(Zoph等人,2017年)。Tai等人。(2015)引入了两种树结构LSTM单元,即子节点无序的树结构的子和树LSTM单元和子节点有序的树结构的N元树LSTM单元。更多详情,请参阅原始文件(Tai等人,2015年)。
训练细节。我们从训练集中随机抽取5000幅图像作为学习架构参数的验证集,这些参数使用Adam优化器进行更新,基于梯度的算法(第3.2.1节)的初始学习率为0.006,基于增强的算法(第3.3.2节)的初始学习率为0.01。在下面的讨论中,我们将这两种算法分别称为Proxyless-G(梯度)和Proxyless-R(加强)。
在过参数化网络的训练过程完成后,根据架构参数导出一个紧凑型网络,如第3.2.1节所述。接下来,我们使用相同的训练设置来训练紧凑型网络,只是训练epoch从200个增加到300个。此外,当采用DropPath正则化(Zoph et al.,2018;Huang et al.,2016)时,我们进一步将训练epoch的数量增加到600个(Zoph et al.,2018)。
结果。我们将所提出的方法应用于B=18和F=400的树状结构建筑空间中的建筑学习。由于我们不重复单元,并且每个单元有12个可学习的边,因此需要总共12 x 18 x 3=648个决策来完全确定体系结构。
表1总结了我们提出的方法和CIFAR-10上其他最新架构的测试错误率结果,其中“c/o”表示使用了Cutout(DeVries&Taylor,2017)。与这些最新架构相比,本文提出的方法不仅可以获得较低的测试误差率,而且可以获得较好的参数效率。具体来说,Proxyless-G的测试错误率为2.08%,略好于AmoebaNet-B(Real等人,2018年)(之前的CIFAR-10最佳架构)。值得注意的是,AmoebaNet-B使用了34.9M的参数,而我们的模型只使用了5.7M的参数,比AmoebaNet-B少了6倍。此外,与探索树状结构空间的路径级EAS(Cai等人,2018b)相比,Proxyless-G和Proxyless-R的测试误差率几乎相同或更低,参数减少了一半。我们的ProxylessNAS的强大的经验结果表明,直接探索一个大的架构空间而不是重复堆叠同一块的好处。

4.2 EXPERIMENTS ON IMAGENET
对于ImageNet实验,我们专注于学习高效的CNN架构(Iandola等人,2016;Howard等人,2017;Sandler等人,2018;Zhu等人,2018),这些架构不仅在特定硬件平台上具有高精度,而且具有低延迟。因此,这是一个多目标NAS任务(Hsu et al.,2018;Dong et al.,2018;Elsken et al.,2018a;He et al.,2018;Wang et al.,2018;Tan et al.,2018),其中一个目标是不可微的(即延迟)。我们在实验中使用了三种不同的硬件平台,包括手机、GPU和CPU。GPU延迟是在批量大小为8的V100 GPU上测量的(单个批量使GPU利用率严重不足)。
此外,在移动电话上,我们在架构搜索期间使用延迟预测模型(附录B)。如图5所示,我们观察到在测试集上预测的延迟和实际测量的延迟之间存在很强的相关性,这表明延迟预测模型可以用来替代昂贵的移动农场基础设施(Tan等人,2018),并且引入的误差很小。
架构空间。我们使用MobileNetV2(Sandler等人,2018)作为构建架构空间的主干。具体来说,我们不重复相同的mobile inverted bottleneck卷积(MBConv),而是允许一组具有不同内核大小{3,5,7}和扩展比率{3,6}的MBConv层。为了在宽度和深度之间进行直接的权衡,我们初始化了一个更深层的over-parameterized network,并通过将零操作添加到其混合操作的候选集来允许一个块有像残差网络那样的跳跃连接。这样,在有限的延迟预算下,网络可以通过跳过更多的块和使用更大的MBConv层来选择更浅和更宽,或者通过保留更多的块和使用更小的MBConv层来选择更深和更薄。
训练细节。在架构搜索期间,我们随机从训练集中抽取50000张图像作为验证集。更新架构参数的设置与CIFAR-10实验相同,只是初始学习率为0.001。过度参数化的网络在批处理大小为256的剩余训练图像上进行训练。

ImageNet分类结果。我们首先应用ProxylessNAS来学习移动电话上的CNN模型。汇总结果见表2。与MobileNetV2相比,我们的模型在保持类似的移动电话延迟的同时,将top-1的准确性提高了2.6%。此外,通过使用乘法器重新调整网络的宽度(Sandler等人,2018;Tan等人,2018),图4显示,在所有延迟设置下,我们的模型始终以显著幅度优于MobileNetV2。具体来说,为了达到同样的顶级精度性能水平(约74.6%),MobileNetV2有143ms的延迟,而我们的模型只需78ms(快1.83倍)。与MnasNet(Tan et al.,2018)相比,我们的模型在移动延迟稍低的情况下,可以达到0.6%的最高精度。更重要的是,我们的资源效率更高:GPU小时比MnasNet少200倍(表2)。

此外,我们还观察到,如果没有延迟正则化损失,Proxyless-G没有动机选择计算便宜的操作。其产生的架构最初在像素1上有158ms的延迟。利用该乘法器对网络进行重定尺度后,其时延降低到83ms,但该模型在ImageNet上只能达到71.8%的top-1精度,比Proxyless-G给出的具有时延正则化损失的结果低2.4%。因此,我们认为在学习有效的神经网络时,必须以潜伏期为直接目标。
除了手机,我们还应用我们的ProxylessNAS在GPU和CPU上学习专门的CNN模型。表3报告了GPU上的结果,我们发现,与人工设计和自动搜索的体系结构相比,我们的ProxylessNAS仍然可以获得优异的性能。具体来说,与MobileNetV2和MnasNet相比,我们的模型在提高1.2倍的速度的同时,将top-1的准确率分别提高了3.1%和1.1%。表4显示了我们在三个不同平台上搜索模型的汇总结果。一个有趣的观察是,为GPU优化的模型在CPU和手机上运行速度并不快,反之亦然。因此,对于不同的硬件结构,学习专门的神经网络是非常必要的,以便在不同的硬件上达到最佳的效率。


不同硬件的专用型号。图6展示了我们在三个硬件平台上搜索的CNN模型的详细架构:GPU/CPU/Mobile。我们注意到,当针对不同的平台时,体系结构显示出不同的偏好:(i)GPU模型更浅更宽,特别是在特征映射具有更高分辨率的早期阶段;(ii)GPU模型更喜欢大型MBConv操作(例如7 x 7 MBConv6),而CPU模型将使用较小的MBConv操作。这是因为GPU具有比CPU高得多的并行性,因此它可以利用大型MBConv操作。另一个有趣的观察是,我们在所有平台上搜索的模型都更喜欢在每个阶段的第一个块中进行更大的MBConv操作,在每个阶段中,特征映射都是下采样的。我们认为这可能是因为较大的MBConv操作有利于网络在下采样时保留更多信息。值得注意的是,这类模式在以前的NAS方法中无法捕获,因为它们迫使块共享相同的结构(Zoph等人,2018;Liu等人,2018a)。