杂乱知识点记录
杂乱知识点记录
- 1 目标检测评估指标
- 2 visual grounding
- 3 分割
- 4 VLM经典框架
- 5 RCNN系列
-
- RCNN
- Fast RCNN
- Faster RCNN
- Mask RCNN
- 6 GIOU
- 7 DETR系列
-
- DETR
- Deformable DETR
- DAB-DETR
- DN-DETR
- DINO
- 8 COCO2014
- 9 COCO评价指标 maxDets=[1,10,100]
- 10 FCOS:anchor-free
- 11 ATSS
1 目标检测评估指标
目标检测和实例分割:box mAP 和 mask mAP。
precision:预测的正例中,真实正例的比例。
recall:预测出的真实正例占所有真实正例的比例。
IoU:交并比,预测框与gt的交集/并集。
目标检测的评估:设置一个置信度阈值和一个交并比阈值,后者一般取50%,然后大于置信度阈值和交并比阈值的框则认为是检测出某类别物体。
PR曲线:设置不同的置信度阈值,得到对于的precision-recall,画出折线图。
平均精度AP:对于某个类别,计算出PR曲线下方的面积,即积分。通常需要将锯齿状曲线做平滑处理,即对于某个recall值的precision,取其右侧(>该recall值)中最大的precision,这样得到的PR曲线是单调递减的。进一步的,用插值AP简化积分计算。例如,在0~1取平均的11个点,然后算出平均的precision值(经过平滑的值)。但是这么处理的AP不精确。
更精确的AP计算方法:设数据集中正例的数量为m,则应该可以得到m+1个不同的召回率值,然后在这些位置进行采样,对于每个pi,权重为ri-1-ri。
mAP:mean average precision,对所有类别的AP求平均。
论文中的AP一般是IoU0.5到0.95的均值:
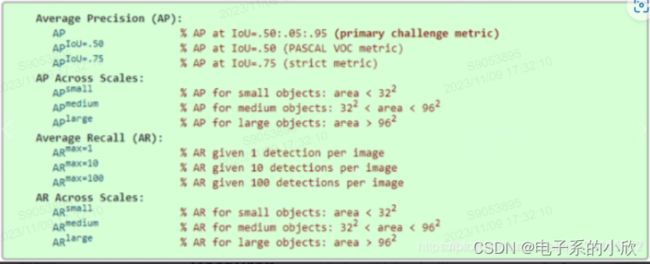
R@k:

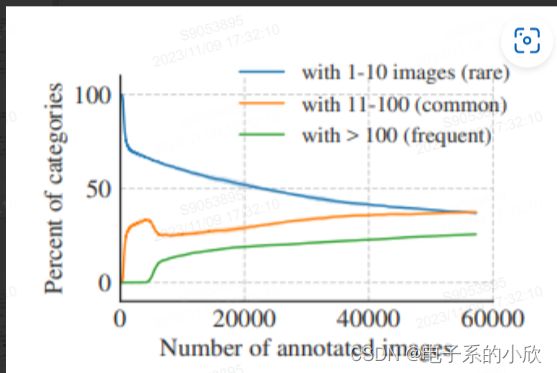
LVIS的类别分为3种,论文实验表对应的AP:APr APc APf
2 visual grounding
visual grounding的输入是图片和描述,输出是物体的box。分两类,一类是phrase localization,他需要检测出描述中提到的所有物体;一类是REC(Referring Expression Comprehension),每一句描述只指示一个物体。
3 分割
实例分割:检测出特定的物体实例,并进行分割。
语义分割:为图像中每个像素进行类别分类,但是同类别的对象(实例)不区分。
全景分割:对图像中的所有像素进行类别分类和实例区分。
4 VLM经典框架
用大量图像文本训练模型,实现各种视觉任务的zero-shot。
对比:如clip,通过对比学习将正样本对的特征拉进,负样本对拉远。
生成:masked再恢复,然后用生成误差进行网络更新。
5 RCNN系列
RCNN
搜索出region,需要裁剪出region后resize,然后CNN,最后用SVM分类。
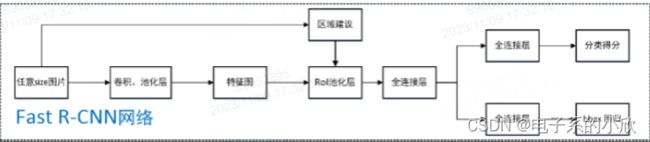
Fast RCNN
不重复CNN而是对原图卷积池化。再根据region proposal将每个region通过RoI池化得到相同size的特征,然后进行分类(改为了softmax)和回归。
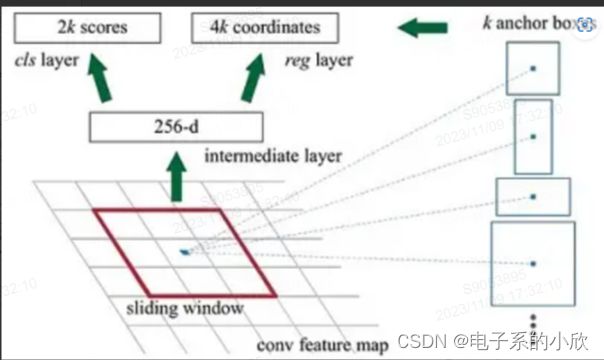
Faster RCNN
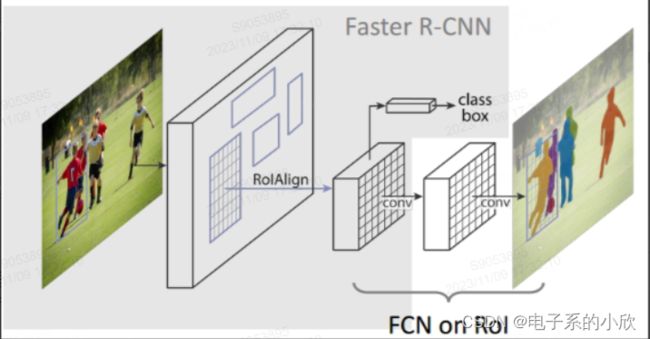
region propoal的提取不再用搜索算法,而是用RPN(下图),使整个模型的特征提取都在同一个网络完成。

Mask RCNN
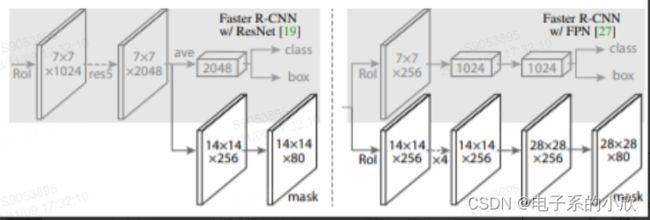
可以进行实例分割。相比Faster RCNN的改动是RoIAlign和FCN。
FCN:输出的mask是80xmxm,80是因为COCO是80类。对于每个RoI,根据预测的类别k,只算第k个mxm的loss,其它79个mask不管。这样就避免了roi重叠导致的类间竞争。
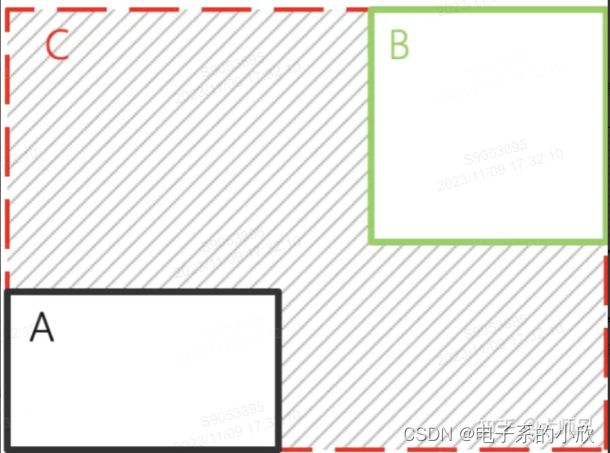
6 GIOU
当框没有重叠时,GIOU还能进行优化,即缩小C-(AUB)的占比。当框有重叠时,与IOU的效果差不多。

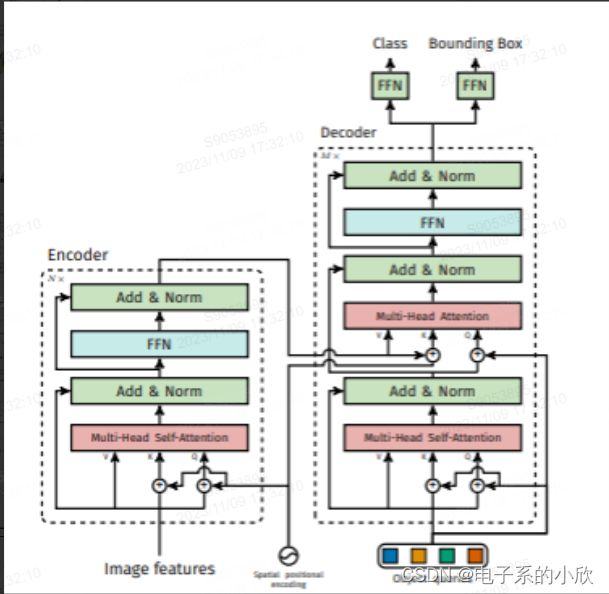
7 DETR系列
DETR
参考自:https://blog.csdn.net/qq_38253797/article/details/127616634
对于decoder中的q的自注意力的作用以及自注意力+交叉注意力作为输出的目的的分析如下:q自注意力可以获得物体信息(物体间的关系)。
损失函数:labels+cardinality+boxes+masks
其中的cardinality是计算个图像中被预测成类别的数量与gt真实数量的数量
损失,不用于训练优化。
masks:用于分割,这里没有用到。
对于二分图匹配,他是先不区分patch地计算出损失矩阵:
分类 + L1 box + GIOU box,然后再取出不同图片的矩阵,再调用scipy的函数。
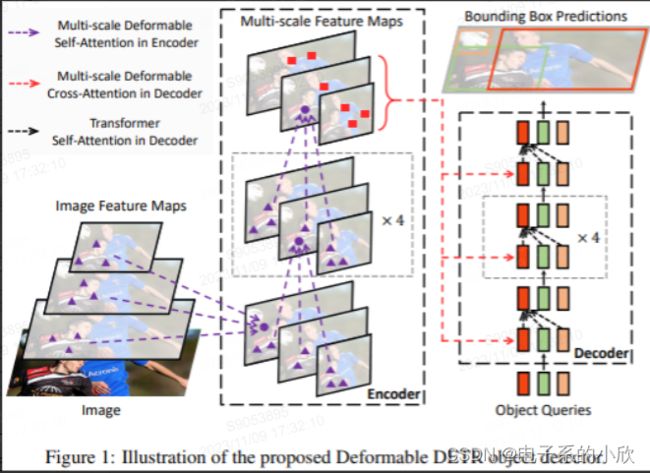
Deformable DETR
改进DETR收敛慢的问题(计算复杂度高),同时引入了多尺度。
做法:提出了可变形DETR,即把encoder的attention、encoder与decoder的cross-attention换成了稀疏的可变形注意力模块。且无需FPN即可实现多尺度。
分析1:下图公式是attention的计算,初始化时
Amqk得到的注意力权重是平均的,k的维度数量Nk越
多,则平均之后权重越小,对input特征的梯度不明
确,需要长时间的训练来调整权重。
分析2:一般通道数小于q和k的token数量,所以
复杂度的关键是Amqk的计算以及Amqk与V相乘项的
复杂度(第三项)。

对DETR中长宽分别为H、W的特征图的attention复杂度:
encoder :O(HWHWC)
decoder-crossattention:O(NHWC+HWCC),这里因为q是N个,它不一定远大于C,所以保留两项。
encoder-selfattention:O(2NCC+NNC),感觉该文的这些计算有些常数系数遗漏。
上述3个中,前两个的计算复杂度较高,所以应用了可变形 attention。
多尺度可变形attention:
有l个尺度。这些尺度是从backbone提炼来的。
对于encoder,从 backbone提取多尺度特征,然后用可变形attention计算。
对于coder-crossattention,也用可变形attention,要注意,由于此时的注意力计算是采样HW中的k个,所以最后预测box的位置是相对于参考点的,参考点的坐标是通过将q进行映射=sigmoid实现的。
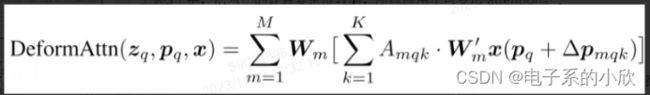
DAB-DETR
参考自:https://zhuanlan.zhihu.com/p/560513044
优化DETR收敛慢的问题:decoder的可学习q没有提供位置先验。
做法:将decoder的q改为4d的anchor,同时在计算交叉注意力时,引入w和h的信息,使得注意力跟尺度相关。此外,q是可以在每一层都通过MLP得到矫正的,这样更新更快。
DN-DETR
参考自:https://www.zhihu.com/question/517340666/answer/2381304399
在DAB-DETR基础上的改进。
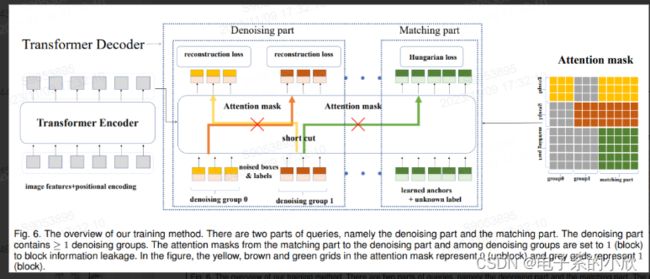
动机:DETR的二分图匹配前期是不稳定的,导致anchor的偏移预测不稳定。
做法:训练时,在匹配任务中加入去噪任务,加快模型前期的收敛
DINO
参考自:https://zhuanlan.zhihu.com/p/540786844
基于DAB-DETR和DN-DETR,继续提高模型性能和收敛效率。
改进1:去噪任务中,引入负样本的去噪任务。当输入的框的噪声太大时,其与真实框接近,但不是真实框、此时不进行真实框的去噪,而是进行类别的判别(是否为object)。
改进2:deformable detr中的decoder的query的初始化是用从encoder的输出进行选择的,包括anchors和content queries,其中的content queries是未优化的可能有歧义,因此将其改为可学习参数。
改进3:box的更新做了优化,无特别,具体看论文。
8 COCO2014
类别:80类,id值是1~90,其中有一些id没有。
3种标注:目标实例(box和分割都有)、caption、关键点。
9 COCO评价指标 maxDets=[1,10,100]
该指标的意思是分别保留测试集的每张图上置信度排名第1、前10、前100个预测框,根据这些预测框和真实框进行比对,来计算AP、AR等值
10 FCOS:anchor-free
直接预测每个位置对应的物体的上下左右边界。
如果一个物体被多个位置预测,则选择离中心近的;如果一个位置有多个物体,则选择框小的。
11 ATSS
参考自:https://zhuanlan.zhihu.com/p/358125611
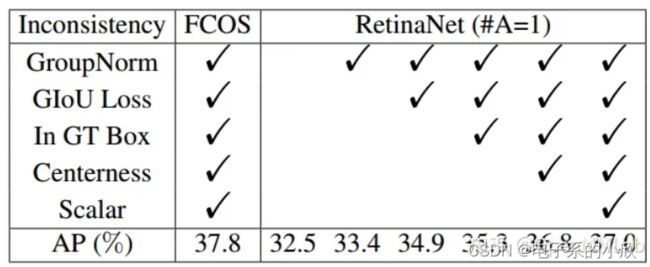
优化FCOS的超参难调问题,使得正样本分配机制更灵活。
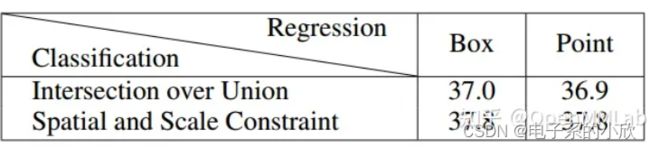
RetinaNet和FCOS的对比:trick一样的情况下,前者仍然效果较差,说明有差距的原因不是trick,而是正负样本划分方法或bbox回归方式。表2 对比可知原因是正负样本划分方式。
ATSS的backbone、neck、head:
backbone和RetinaNet相同
neck加了add_extra_convs=‘on_output’,其余和
RetinaNet相同
head和FCOS相同
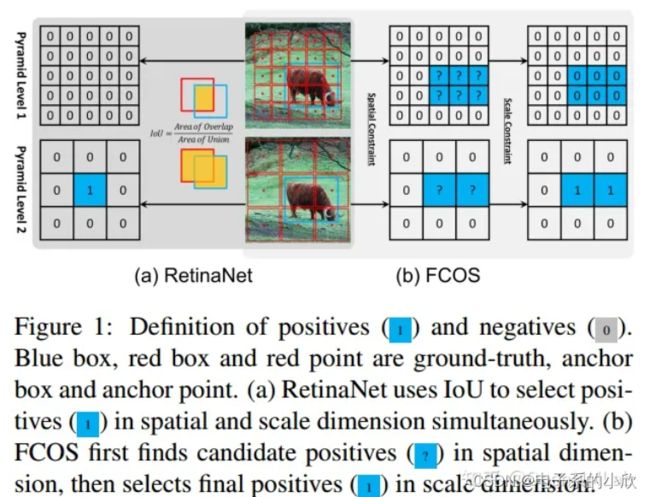
图1说明了2种正负样本划分方式的简要情况。前者根据一个统一的IoU阈值进行划分,最终只有1个正样本。后者先得到候选正样本点(是否落在某个gt里),然后再根据回归scale选择正样本点(落在几个gt,需要回归的框有多大),最终有2个正样本点。这说明FCOS的正负样本划分策略能够得到更多的正样本。
其简要流程为(原话):
计算每个 gt bbox 和多尺度输出层的所有 anchor 之间的 IoU
计算每个 gt bbox 中心坐标和多尺度输出层的所有 anchor 中心坐标的 l2 距离
遍历每个输出层,遍历每个 gt bbox,找出当前层中 topk (超参,默认是 9 )个最小 l2 距离的 anchor 。假设一共有 l 个输出层,那么对于任何一个 gt bbox,都会挑选出 topk×l 个候选位置
对于每个 gt bbox,计算所有候选位置 IoU 的均值和标准差,两者相加得到该 gt bbox 的自适应阈值
遍历每个 gt bbox,选择出候选位置中 IoU 大于阈值的位置,该位置认为是正样本,负责预测该 gt bbox
如果 topk 参数设置过大,可能会导致某些正样本位置不在 gt bbox 内部,故需要过滤掉这部分正样本,设置为背景样本
某种手段是指计算每个 gt bbox 和所有 anchor 之间的 IoU topk 操作;每个 gt bbox 和 anchor 计算得到的 IoU 值即为适应度值,值越大越可能是正样本;计算 gt bbox 和候选 anchor 的 IoU 均值和标准差即为对适应度值计算统计值得到全局阈值;然后采用每个 gt bbox 各自的全局预测进行切分即可得到正样本。
举个例子简要概述:假设当前图片中,一共 2 个 gt bbox,一共 5 个输出层,每层都是 100 个 anchor
遍历每个 gt bbox,和 500 个 anchor 都计算 IoU 和中心坐标的 L2 距离值
遍历 5 个输出层,对于每个 gt bbox,都选择 topk=9 个 l2 距离最小的 anchor,此步骤完成后每个 gt bbox,一共挑选出 9x5=45 个候选 anchor
遍历每个 gt bbox,将挑选出来的 45 个 anchor 所对应的 IoU 计算均值和标准差,然后相加,此时 2 个 gt bbox,都可以得到各自的全局预测
最后遍历每个 gt bbox,在候选 anchor 中将 IoU 值低于阈值的 anchor 设置为负样本,其余为正样
正负样本划分策略的分析:选择均值和标准差来作为阈值,是因为高均值体现了anchor的质量越好,高标准差体现了不同层的区分度很大。
鲁棒性:即使一开始anchor的设置不太好,也能得到均值和方差较低的正样本。