用 GPU 加速 PQC 方案:Multi-precision Montgomery、SHA3
参考文献:
- [Mont85] Montgomery P L. Modular multiplication without trial division[J]. Mathematics of computation, 1985, 44(170): 519-521.
- [DK91] Dussé S R, Kaliski B S. A cryptographic library for the Motorola DSP56000[C]//Advances in Cryptology—EUROCRYPT’90: Workshop on the Theory and Application of Cryptographic Techniques Aarhus, Denmark, May 21–24, 1990 Proceedings 9. Springer Berlin Heidelberg, 1991: 230-244.
- [KAK96] Koc C K, Acar T, Kaliski B S. Analyzing and comparing Montgomery multiplication algorithms[J]. IEEE micro, 1996, 16(3): 26-33.
- [CHS11] P. Cayrel, G. Hoffmann, M. Schneider, GPU Implementation of the Keccak Hash Function Family, The 5th International Conference on Information Security and Assurance, 2011.
- [SHA3] Dworkin M J. SHA-3 standard: Permutation-based hash and extendable-output functions[J]. 2015.
- [LWGP17] Lee W K, Wong X F, Goi B M, et al. CUDA-SSL: SSL/TLS accelerated by GPU[C]//2017 International Carnahan Conference on Security Technology (ICCST). IEEE, 2017: 1-6.
- [OBS21] Ono T, Bian S, Sato T. Automatic parallelism tuning for module learning with errors based post-quantum key exchanges on GPUs[C]//2021 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 2021: 1-5.
- [SYD+22] Shen S, Yang H, Dai W, et al. High-Throughput GPU Implementation of Dilithium Post-Quantum Digital Signature[J]. arXiv preprint arXiv:2211.12265, 2022.
- Secure Hash Algorithm-3 (SHA-3) family_-CSDN博客
- CUDA 编程简介(上),CUDA 编程简介(下)
- CUDA之Warp Shuffle详解-CSDN博客
- 【CUDA 基础】5.6 线程束洗牌指令 - 知乎 (zhihu.com)
文章目录
- Multi-precision Montgomery
-
- SOS
- CIOS
- Complexity
- GPU-SSL
-
- SHA3
- CTR mode
- Montgomery
- GPU-PQC
-
- Kyber
- Dilithium
Multi-precision Montgomery
[Mont85] 提出了 Montgomery Modular Multiplication 算法。[KAK96] 考虑了不同的 Montgomery 的算法实现,并比较了其中的 5 5 5 种高精度整数的实现效率。
模数 n n n,选取任意的 r r r 使得 g c d ( n , r ) = 1 gcd(n,r)=1 gcd(n,r)=1,那么存在如下的同构:
Z n ≅ { a ˉ : = a ⋅ r ( m o d n ) ∣ a ∈ Z n } \mathbb Z_n \cong \{\bar a:=a \cdot r \pmod{n} \mid a \in \mathbb Z_n\} Zn≅{aˉ:=a⋅r(modn)∣a∈Zn}
后者是一个完备剩余系(complete residue system),称为 Montgomery 域,
- 加法: a + b ‾ : = a ˉ + b ˉ ≡ ( a + b ) ⋅ r ( m o d n ) \overline{a+b} := \bar a + \bar b \equiv (a+b) \cdot r \pmod{n} a+b:=aˉ+bˉ≡(a+b)⋅r(modn)
- 负数: − a ‾ : = − a ˉ ≡ ( − a ) ⋅ r ( m o d n ) \overline{-a} := -\bar a \equiv (-a) \cdot r \pmod{n} −a:=−aˉ≡(−a)⋅r(modn)
- 乘法: a ⋅ b ‾ : = a ˉ ⋅ b ˉ ⋅ r − 1 ≡ ( a ⋅ b ) ⋅ r ( m o d n ) \overline{a \cdot b} := \bar a \cdot \bar b \cdot r^{-1} \equiv (a \cdot b) \cdot r \pmod{n} a⋅b:=aˉ⋅bˉ⋅r−1≡(a⋅b)⋅r(modn)
- 逆元: a − 1 ‾ : = r 2 ⋅ ( a ˉ ) − 1 ≡ ( a − 1 ) ⋅ r ( m o d n ) \overline{a^{-1}} := r^2\cdot (\bar a)^{-1} \equiv (a^{-1}) \cdot r \pmod{n} a−1:=r2⋅(aˉ)−1≡(a−1)⋅r(modn)
- 数乘: k a ‾ : = k ⋅ a ˉ ≡ ( k a ) ⋅ r ( m o d n ) \overline{ka} := k \cdot \bar a \equiv (ka) \cdot r \pmod{n} ka:=k⋅aˉ≡(ka)⋅r(modn)
- 判等: [ a ˉ ≡ b ˉ ( m o d n ) ] = [ a ⋅ r ≡ b ⋅ r ( m o d n ) ] = [ a ≡ b ( m o d n ) ] [\bar a \equiv \bar b \pmod{n}] = [a\cdot r \equiv b\cdot r \pmod{n}] = [a \equiv b \pmod{n}] [aˉ≡bˉ(modn)]=[a⋅r≡b⋅r(modn)]=[a≡b(modn)]
Montgomery 域上的加法是容易的,它的取模运算可以使用 Barret 算法。
对于乘法运算,也存在快速的 Montgomery 算法:
- 利用扩展欧几里得算法,计算出 r − 1 , n ′ r^{-1},n' r−1,n′,满足 r ⋅ r − 1 − n ⋅ n ′ = 1 r\cdot r^{-1} - n \cdot n'=1 r⋅r−1−n⋅n′=1
- 这里 n ′ = − n − 1 ( m o d r ) n' = - n^{-1} \pmod{r} n′=−n−1(modr),利用预计算的 n ′ n' n′
算法基本流程:

这个算法对于任意的 g c d ( r , n ) gcd(r,n) gcd(r,n) 都工作,但是仅当 r = 2 k r=2^k r=2k 是二的幂次时,其中的 ⋯ ( m o d r ) \cdots\pmod{r} ⋯(modr) 以及 ⋯ / r \cdots/r ⋯/r 可以快速计算。易知, M o n P r o ( x , r 2 ) = x MonPro(x,r^2) = x MonPro(x,r2)=x 就是映射,而 M o n P r o ( x ˉ , 1 ) = x MonPro(\bar x,1) = x MonPro(xˉ,1)=x 就是逆映射。
计算机的运算单元是 words,假设 W = 2 w W=2^w W=2w,一般设置 w = 32 w=32 w=32(单精度 int,双精度 long)。假设 t , a , b , c ∈ [ 0 , 2 w ) t,a,b,c \in [0,2^w) t,a,b,c∈[0,2w) 都是单精度整数,那么 ( C , S ) : = t + a b + c (C,S) := t+ab+c (C,S):=t+ab+c 不会发生溢出,可以存储在两个 words 内
( W − 1 ) 2 + 2 ⋅ ( W − 1 ) = W 2 − 1 = 2 2 w − 1 (W-1)^2 + 2 \cdot (W-1) = W^2-1 =2^{2w}-1 (W−1)2+2⋅(W−1)=W2−1=22w−1
对于多精度整数 a ∈ [ 0 , 2 s w ) a \in [0,2^{sw}) a∈[0,2sw),将它存储为 s s s 个 words。假定 r = 2 s w r=2^{sw} r=2sw,奇模数 n < r n
[KAK96] 考虑了以下因素:
- 计算 multiplication 和 reduction 是完全分离的、还是交错的,交错的是外层循环、还是内层循环。
- 计算 multiplication 和 reduction 的外层循环,是扫描某个操作数、还是扫描计算结果。
根据上述因素的组合,[KSK96] 讨论了多种实现:
- Separated Operand Scanning (SOS)
- Coarsely Integrated Operand Scanning (CIOS)
- Finely Integrated Operand Scanning (FIOS)
- Finely Integrated Product Scanning (FIPS)
- Coarsely Integrated Hybrid Scanning (CIHS)
我们下面仅学习下最基本的 SOS 以及效率最高的 CIOS,读者可以自行阅读其他的实现思路。
SOS
SOS 按顺序,先计算 step 1 的高精度乘法,再计算 step 2 的模约简,最后计算 step 3 的后处理。多精度整数 a a a 的存储格式形如 a [ s − 1 ] ⋯ a [ 1 ] a [ 0 ] a[s-1]\cdots a[1]a[0] a[s−1]⋯a[1]a[0],其中 a [ 0 ] a[0] a[0] 是最低位, a [ s − 1 ] a[s-1] a[s−1] 是最高位。
首先执行 step 1:乘法结果 t = a b t=ab t=ab 存储在 2 s 2s 2s 个 words 内,

接着执行 step 2:先计算 m = t ⋅ n ′ m o d r m=t \cdot n' \mod r m=t⋅n′modr,然后计算 u = t + m ⋅ n u=t+m\cdot n u=t+m⋅n,最后做除法 u / r u/r u/r

临时变量 t t t 的长度为 2 s + 1 2s+1 2s+1,而 u u u 的长度为 s + 1 s+1 s+1,函数 A D D ( t [ i + s ] , C ) ADD(t[i+s],C) ADD(t[i+s],C) 的功能是:将单精度整数 C C C 加到 t [ 2 s ] ⋯ t [ i + s ] t[2s] \cdots t[i+s] t[2s]⋯t[i+s] 上,期望的连续进位链的长度为 1 1 1(两次单精度加法)。
[DK91] 给出了一个重要的观察:不再整体计算 m = t ⋅ n ′ ( m o d r ) m=t \cdot n' \pmod{r} m=t⋅n′(modr) 和 t = t + m n t=t+mn t=t+mn,而是分别计算 m i = t i n ′ ( m o d W ) m_i=t_in' \pmod W mi=tin′(modW) 然后再迭代 t = t + m i n W i t=t+m_inW^i t=t+minWi。虽然两者的计算结果并不一样(忽略了 t ⋅ n ′ t \cdot n' t⋅n′ 的进位),但是后者依旧使得最终的 t t t 成为 r r r 的整数倍。
- 此时 n ′ n' n′ 可以替换为 n 0 ′ = n ′ ( m o d W ) n_0'=n' \pmod W n0′=n′(modW),所以 m i = t ⋅ n ′ m_i=t \cdot n' mi=t⋅n′ 的乘法计算更加简单
- 容易计算 n 0 ′ = − ( n 0 ) − 1 ( m o d W ) n_0' = -(n_0)^{-1} \pmod W n0′=−(n0)−1(modW),不需要预计算大数 n n n 的逆 n − 1 ( m o d r ) n^{-1} \pmod r n−1(modr)
最后执行 step 3:利用大数减法来比较 u > n u>n u>n,顺带执行了后处理步骤

CIOS
CIOS 交错执行 mult 和 reduce:在模约简的第 i i i 轮循环中, m i = t i ⋅ n 0 ′ ( m o d W ) m_i=t_i \cdot n_0' \pmod{W} mi=ti⋅n0′(modW) 仅仅和 t i t_i ti 有关,并且 t i t_i ti 在乘法的第 i i i 轮循环中就被计算完毕了,因此两者可以放在同一个外部循环内。每轮迭代中,模约简过程使得最低的 word 变成零,于是可以立即右移,可以大幅减少内存开销。
step 1 以及 step 2 的交错执行:

最后,利用 SOS 的 step 3 的相同算法,做后处理。
Complexity
文中还给出了其他三种 Montgomery 算法,这里我就不再描述了。它们的复杂度分析结果:

当然,复杂度分析仅仅是一阶近似,忽略了计算机的 register, cache miss 等等细节。实机测试结果:

最后 [KAK96] 总结:对于通用计算机,五种算法中 CIOS 效率最高的。
疑问:C 为何会比 ASM 慢这么多?文中说 C 的 word 是 16 比特的(用两个 16-bits words 模拟一个 32-bits word),而 ASM 的 word 是 32 比特的。现代的计算机应该没这个限制吧?
GPU-SSL
[LWGP17] 提出了 CUDA-SSL,他们在 CUDA 上实现了一些原语,不过没找到他们的实现代码。
SHA3
对于粗粒度的并行,可以让每个 thread 执行单独的 SHA3 任务,各个任务完全独立。但是,GPU 的 core 是很慢的,这么做虽然使得吞吐率很高,但是计算延迟也会非常大。并且,每个 warp 占据的资源是有限的,其中的 32 个线程相互抢占 register, bank 资源。
因为 SHA3 的状态是 { 0 , 1 } 5 × 5 × b \{0,1\}^{5 \times 5 \times b} {0,1}5×5×b 的立方体,并且每轮迭代的置换 θ , ρ , π , χ , ι \theta,\rho,\pi,\chi,\iota θ,ρ,π,χ,ι 都是针对 25 25 25 个 lanes 的,[CHS11] 提出可以使用一个 warp 中的 25 25 25 个线程(空闲 7 7 7 个)细粒度的并行计算。

但是,由于中间变量 C [ 25 ] , D [ 25 ] C[25],D[25] C[25],D[25] 存储在 shared memory 中,线程访问内存时会发生 bank conflict(原本 warp 中的 32 32 32 个线程可以对 32 32 32 个 bank 并行读写),于是 I/O 延迟巨大。[LWGP17] 将数组 C , D C,D C,D 拆分到 25 25 25 个线程的 register 上,然后使用 warp shuffle 交换数据,避免了 bank conflict 的问题。
在版本 CC3.0 以上的 CUDA 支持了 warp shuffle 指令,允许同一个 warp 内的 thread 直接读其他 thread 的寄存器值,包括:__shfl, __shfl_up, __shfl_down, __shfl_xor
修改后的 GPU-SHA3 算法为:

CTR mode
对称密码有多种 mode,其中 CBC mode 是串行的,而 CTR mode 适合并行计算。特别地,CTR mode 的明文/密文仅仅参与最后的异或运算,因此明文/密文不需要执行 host memory 和 device memory 之间的内存交换。

Montgomery
[LWGP17] 使用 Montgomery 实现 RSA 的模幂运算。使用 GPU 实现 CIOS 版本的算法,

GPU-PQC
Kyber
[OBS21] 给出了 Kyber 的 GPU 实现:GitHub - Automatic Tuning for PQC on CUDA
假设 MLWE 的环是 R q = Z q [ x ] / ( x n + 1 ) R_q=\mathbb Z_q[x]/(x^n+1) Rq=Zq[x]/(xn+1),密文是 ( A , b = A s + e ) ∈ R q k × k × R q k (A,b=As+e) \in R_q^{k \times k} \times R_q^k (A,b=As+e)∈Rqk×k×Rqk
- SHA3 的实现:使用 [LWGP17] 的 warp shuffle 版本,每个 warp 计算一个 SHA3 任务。
- Random Matrice 的实现:使用 k × k k \times k k×k 个 warp 分别计算 Shake128 任务。
- Noise Sample 的实现:使用 k k k 个 warp 分别计算 Shake256 任务。
- NTT/InvNTT 的实现:使用 n / 2 n/2 n/2 个线程,并行计算每层的蝴蝶。
- 矩阵运算的实现:使用 O ( k n ) O(kn) O(kn) 个线程。
[OBS21] 综合考虑了延迟 l l l 和吞吐率 c c c,使用比值 l / c l/c l/c 作为性能指标(越小越好)。他们还使用程序遍历参数取值,自动挑选出使得 l / c l/c l/c 最优的 GPU 参数。
不同 GPU 环境下的结果:

Dilithium
[SYD+22] 给出了 Dilithium 的 GPU 实现。实际上 GPU 更适合要求高吞吐率的服务器环境,不太适合要求低延迟的个人环境。本文分别对两种环境提出了一些优化,但是我没找到他们的代码。
Dilithium 使用的是 n = 256 n=256 n=256 的 NTT/INTT,本文使用两种并行方式,
- QWarp 模式:每个 block 包含 4 4 4 个 warp,这个 SM 中运行着 128 128 128 个线程,各个 warp 轮番执行可以完全隐藏 I/O 延迟,其 SM 占用率可以达到 100 % 100\% 100%,但是不同 warp 的线程的状态需要通过 shared memory 来共享。
- SWarp 模式:每个 block 包含 1 1 1 个 warp,这个 SM 中仅运行着 32 32 32 个线程,由于 I/O 延迟难以隐藏,其 SM 占用率约为 33 % 33\% 33%,好处是同一个 warp 内的线程可以利用 warp shuffle 直接共享寄存器的值。为了平衡 register 数量和 I/O 延迟,[SYD+22] 采取了层融合技术,每个线程读取 3 3 3 层所需的 8 8 8 个数据存放在寄存器中(减少 I/O 访问次数), 32 32 32 个线程并行读取 32 32 32 个 bank 顺序读 8 8 8 次(SPMD范式,同一个 warp 同时执行同一条语句,即使 if-else 也是)。
无论 QWarp 还是 SWarp,都会存在 bank conflict,可采取 padding 技术来规避,
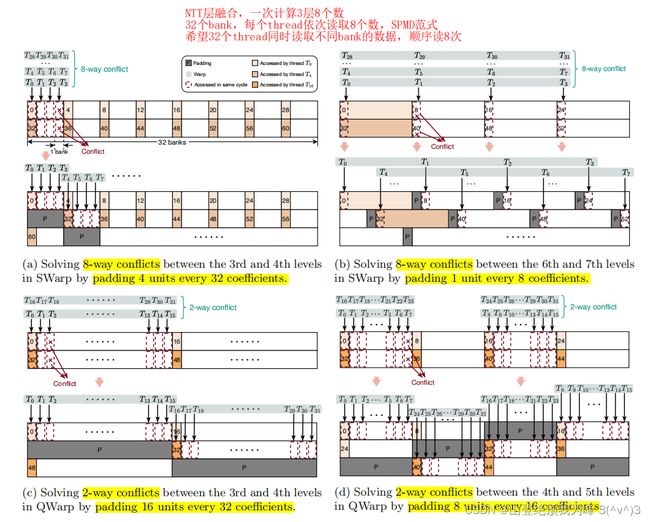
这篇文章也对于 SHA3 给出了优化。相较于 CUDA-SSL 的实现,它将一些预计算数据存放在 constent cache 中而不是 register 中,并且把数据排列为适合连续读写(global memory 的访存合并、cache 的单元是 4 4 4 words 的 line),大幅减少了访存需求,效率也更高。最后,[SYD+22] 给出的 SHA3 实现,吞吐率更高、延迟更小、资源消耗更少,

不同 GPU 环境下,与官方 ref/avx2 实现的比较结果:
