neo4j与es结合
由于neo4j模糊查询比较慢,所以想研究一下提高查询效率的方法。
1. es插件与容器
es插件下载地址:https://github.com/neo4j-contrib/neo4j-elasticsearch/releases
这里下载3.5.6版本的插件,将插件复制到neo4j的plugins目录下
docker cp neo4j-elasticsearch-3.5.6.jar neo4j_es:/opt/neo4j/plugins
下载es镜像,并创建容器
docker pull elasticsearch:2.3
docker run -p 9200:9200 -d --name es elasticsearch:2.3
2. neo4j配置
启动neo4j容器,此处要将已创建的es容器link到neo4j容器
docker run -d --name neo4j_es_test -p 7445:7474 -p 7648:7687 -h neo4j_server --link es:es -t tfws/neo4j-server:3.5.6
在neo4j增加如下配置
vim /opt/neo4j/conf/neo4j.conf
# 将Movie标签的Node的title属性存入ES的movie索引中
elasticsearch.host_name=http://10.30.239.217:9200
elasticsearch.index_spec=movie:Movie(title)
启动neo4j,查看启动日志,发现es配置已加载

3. 使用方法
3.1 neo4j向es的数据同步
向neo4j中添加一条数据
create(n:Movie{title:'Forrest Gup'}) return n;
进入es查看该数据是否自动同步到es,http://10.30.239.217:9200/movie/_search?pretty=
发现报错,查阅neo4j日志提示错误:Problem Updating ElasticSearch No route to host


查阅资料后,推测是服务器屏蔽从docker内部的访问,可以修改服务器的防火墙设置。由于这里是开发环境所以比较简单粗暴的直接关了服务器防火墙
systemctl stop firewalld
关闭防火墙后先向neo4j中添加一条数据
create(n:Movie{title:'神话'}) return n;
进入neo4j容器执行如下命令
curl -X GET http://10.30.239.217:9200/movie/_search?pretty=

- 问题
es和neo4j的数据同步需要neo4j服务处于开启状态,因此,采用neo4j-admin初始化数据库时的csv数据是无法同步到es的,这个需要单独进行一次同步。
后续采用Cypher、load csv导入时数据可以自动同步到es。
3.2 apoc调用es
apoc插件的安装方法见https://blog.csdn.net/shlhhy/article/details/106356733?spm=1001.2014.3001.5502第6节
常用语法如下
Call调用数据库中已部署的存储过程,YIELD子句用于显式选择将哪些可用结果字段作为新绑定变量从过程调用返回给用户,或者由剩余查询进一步处理
apoc的调用es的官方文档:https://neo4j.com/labs/apoc/4.1/database-integration/elasticsearch/
# 查看es的状态
call apoc.es.stats("10.30.239.217")
# 查询es
CALL apoc.es.getRaw("10.30.239.217",'movie/_search?',null)
YIELD value
UNWIND value.hits.hits as hits
RETURN hits['_source'] LIMIT 100

此处指定查询文本语法是es的dsl query语法,ES的查询语法说明官方文档:https://www.elastic.co/guide/cn/elasticsearch/guide/current/_most_important_queries.html
# 查询es的movie索引, 查询字段为title,查询文本为Reloaded2
CALL apoc.es.getRaw("10.30.239.217","movie/_search?",{
query: {match_phrase:{title: "Reloaded2"}}
})
YIELD value
UNWIND value.hits.hits as hits
RETURN hits['_source'] LIMIT 100

3.3 apoc与match语法结合
首先调用call YIELD语法返回某一变量,存为中间结果,再加上match语法进行使用
CALL db.propertyKeys() YIELD propertyKey AS prop
MATCH (n)
WHERE n[prop] IS NOT NULL RETURN prop, count(n) AS numNodes

# 从es中查找movie索引中title包含神的节点,并返回符合查询的title列表
CALL apoc.es.getRaw("10.30.239.217","movie/_search?",{
query: {match_phrase:{title: "神"}}
})
YIELD value
UNWIND value.hits.hits as hits
UNWIND hits['_source']['title'] as title_list RETURN title_list

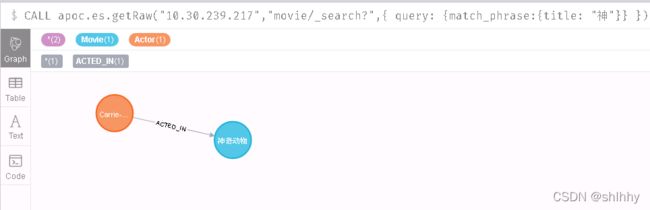
# 从es中查找movie索引中title包含"神"的节点,并返回符合查询的title列表,并查询与包含"神"的Movie节点相连的一度ACTED_IN边
CALL apoc.es.getRaw("10.30.239.217","movie/_search?",{
query: {match_phrase:{title: "神"}}
})
YIELD value
UNWIND value.hits.hits as hits
with collect(hits['_source']['title']) as title_list
MATCH p=(m:Movie)-[r:ACTED_IN]-(n) where m.title in title_list RETURN p
由于常规的es查询的最大返回数量为10000,因此,需要研究一下es的 分页在apoc调用中如何实现。语法如下,通过scrollId反复迭代即可。
# 调用apoc.es.query以获取第一块数据hits1,并获取scroll_id,scroll=5m表示该scroll_id缓存5分钟,size可以指定每次滚动拉取多少数据,这里每次滚动拉取1条
# 接着使用range进行翻页,从2开始,步长为1,直至10,共滚动9次
# 这里有2个问题:1)第一块数据hits1无法return输出;2)如果size设置为10,但是我只想取出33条数据时,最终会返回10的整数倍数据
CALL apoc.es.query("http://10.30.239.211:9200","dianying","_doc","&size=1&scroll=5m",{query: {match_phrase:{name: "执导"}}})
YIELD value
with value._scroll_id as scrollId, value.hits.hits as hits1
WITH range(2,10,1) as list, scrollId
UNWIND list as count
CALL apoc.es.get("http://10.30.239.211:9200","_search","scroll",null,{scroll:"5m",scroll_id:scrollId},null) yield value with value._scoll_id as scrollId, value.hits.hits as nextHits
UNWIND nextHits as hit
return hit

4. 全文索引
由于apoc调用es需要使用unwind、with collect这样的语法去收集结果,当数据量大的时候,还是不太行,这里观察一下全文索引的性能,大约是match语法的1/2
# 创建全文索引
CALL db.index.fulltext.createNodeIndex("电影",["电影"],["name"])
# 使用全文索引进行查询
CALL db.index.fulltext.queryNodes("电影", 'name: "执导"') YIELD node, score RETURN node.name, score limit 10
# 删除全文索引
call db.index.fulltext.drop("电影")
5.超级节点
例如,快递发货省份,”江苏“,作为一个节点的话,每天都有数千万的快递单从江苏寄出,”江苏“这个节点就会是一个超级节点,有N多的边与其相连。
超级节点对于图谱的更新维护、查询、表征模型等都会产生难以处理的问题,我在项目实践中也没找到具体的处理方案。可以采用的方式如下:
- 处理成标签
- 处理成属性
如果不可避免的要出现超级节点,一些优化的参考方案:https://yc-ma.blog.csdn.net/article/details/104906383