neo4j 社区版主从集群
由于neo4j企业版太贵了,想研究一下通过neo4j社区版搭建主从集群的方案。
分布式、主从、集群的一些解释:https://blog.csdn.net/weixin_47600479/article/details/121315105
0. neo4j企业版集群体验
为了先对neo4j的集群模式有初步的印象,此处,搭建了企业版的集群。
0.1. 节点免密互信
企业版要求至少1主2从。在每台服务器上都要配置两两免密互信,否则启动neo4j服务时会报错。

修改主机名
hostnamectl set-hostname new-name
vim /etc/hosts
10.30.239.202 node01
10.30.239.203 node02
10.30.239.204 node03
ssh-keygen -t dsa -f ~/.ssh/id_dsa -N "" -q
ssh-copy-id node01
ssh-copy-id node02
ssh-copy-id node03
0.2 安装neo4j
cd /opt/
wget http://dist.neo4j.org/neo4j-enterprise-3.4.0-unix.tar.gz
tar -zxvf neo4j-enterprise-3.4.0-unix.tar.gz
配置三个节点上的conf文件
# 配置之后机子才可以互联
dbms.connectors.default_listen_address=0.0.0.0
# ha集群
dbms.mode=HA
# id为1表示主节点,从节点依次为2、3、4....
ha.server_id=1
# 集群的三个节点
ha.initial_hosts=10.30.239.202:5001,10.30.239.203:5001,10.30.239.204:5001
在主节点上导入测试数据,会自动广播到从节点,启动3个节点的neo4j服务
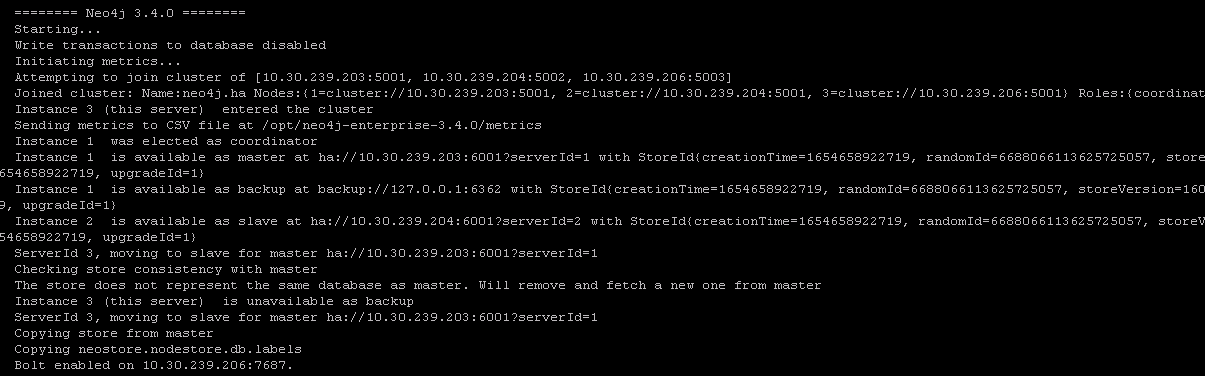
0.3 使用
进入neo4j的可视化节点,查看集群状态。
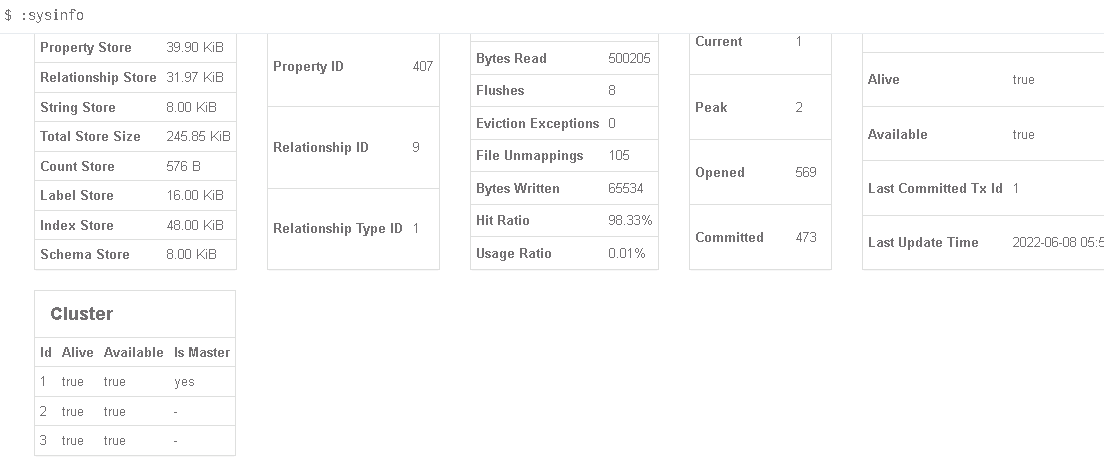
在node03上创建一个节点后,集群自动广播了这个新节点,在3台服务器上节点总数都从6变成了7,neo4j企业版的集群允许从—>写入主,主—>写入从。
conn = my_neo.conn_neo("bolt://10.30.239.205:7687", 'neo4j', '123456')
sql = "CREATE (n:Person{name:'朱允炆',works:'',gender:'男',birth_dead_day:'1377年12⽉5-不详'}) RETURN n"
conn = my_neo.conn_neo("bolt://10.30.239.203:7687", 'neo4j', '123456')
sql = "match (n) return count(n)"
手动关闭node02,模拟单点故障,可以看到集群日志的变化,集群在从中重新选举了一个作为主节点。并且,在重新选举期间,集群数据库的写入功能是不可用的。
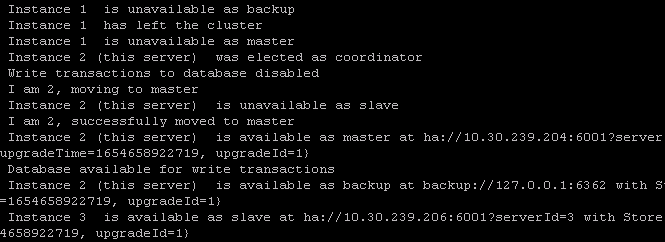
集群状态中,1已经被自动去掉了,主节点也重新选举了。
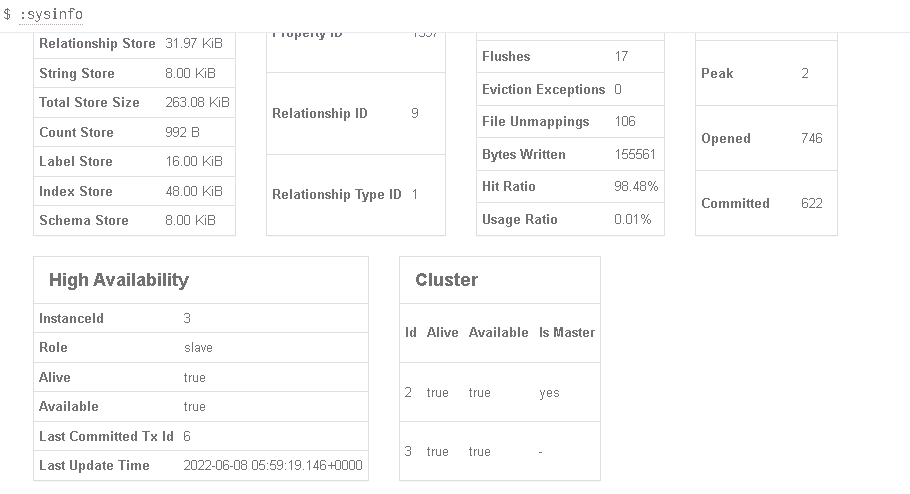
此时,连接203也是失败的,可见neo4j的企业版集群并没有提供统一访问接口,仅实现了单点故障的处理。
由于关闭203是主节点,当主节点挂掉的时候,集群可以重新选举以维持正常工作,但挂掉的主节点无法通过重启再加入集群中。将集群所有节点都关了之后,再重启,是ok的。
![]()
如果挂点的是从节点,可以通过重启的方式再次加入原集群中。
备份命令
bin/neo4j-admin backup --from=<ip> --backup-dir=/opt/db_bak/ --name=graph.db-backup --fallback-to-full=true --pagecache=4G
1. 主从的运行模式
- 每个Neo4J集群都包含一个Master(主)和多个Slave(从)。
- 集群中的Master主要负责数据的写入,接下来Slave则会将Master中的数据更改同步到自身。如果一个写入请求到达了Slave,那么该Slave也将会就该请求与Master通信。此时该写入请求将首先被Master执行,再异步地将数据更新到各个Slave中。数据写入方式的红线有从Master到Slave,也有从Slave到Master,但是并没有从Slave到Slave。
- 当Neo4J集群需要面对持续的大量的写入操作,我们就需要考虑Neo4J集群的纵向扩展了,因为此时横向扩展无益于解决这个问题。
由于neo4j社区版不具备横向扩展的主从热备的集群模式,因此,需要依赖外部组件来实现主从模式,这里考虑使用keepalived+drbd的结构,参考文档:https://blog.csdn.net/qq_40003309/article/details/108298573?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_title~default-1-108298573-blog-82390086.pc_relevant_default&spm=1001.2101.3001.4242.2&utm_relevant_index=4
https://www.freesion.com/article/21511318879/
2. 数据同步(共享存储)
高可用集群既可以使用本地磁盘来构建纯软件的镜像型集群系统,也可以使用专门的共享磁盘装置来构建大规模的共享磁盘型集群系统,共享组件主要有iscsi,drbd,nfs等。
drbd(全称为Distributed Replicated Block Device,简称drbd)分布式块设备复制,是在不同节点上两个相同大小的设备块级别之间的数据同步镜像。
2.1 配置服务器节点间的免密互信
# 设置hostname
sudo hostnamectl set-hostname node01
sudo hostnamectl set-hostname node02
vim /etc/hosts
10.30.239.201 node01
10.30.239.202 node02
ssh-keygen -t dsa -f ~/.ssh/id_dsa -N "" -q
ssh-copy-id node01
ssh-copy-id node02
2.2 安装drbd
- 配置epel源
vim /etc/yum.repos.d/elrepo.repo
[elrepo]
name=ELRepo.org Community Enterprise Linux Repository - el7 baseurl=https://mirrors.tuna.tsinghua.edu.cn/elrepo/elrepo/el7/x86_64/
enabled=1
gpgcheck=0
- 安装drbd
yum install -y drbd84-utils kmod-drbd84
- 加载模块,报错:modprobe: FATAL: Module drbd not found,更新内核,重启
modprobe drbd
yum -y install kernel-devel kernel kernel-headers
reboot
2.3 配置global_common.conf文件
cd /etc/drbd.d
# DRBD is the result of over a decade of development by LINBIT.
# In case you need professional services for DRBD or have
# feature requests visit http://www.linbit.com
global {
# 改为不统计
usage-count no;
# Decide what kind of udev symlinks you want for "implicit" volumes
# (those without explicit volume {} block, implied vnr=0):
# /dev/drbd/by-resource// (explicit volumes)
# /dev/drbd/by-resource/ (default for implict)
# 这行注释掉
# udev-always-use-vnr; # treat implicit the same as explicit volumes
# minor-count dialog-refresh disable-ip-verification
# cmd-timeout-short 5; cmd-timeout-medium 121; cmd-timeout-long 600;
}
common {
# 使用DRBD的同步协议,添加这行
protocol C;
handlers {
# These are EXAMPLE handlers only.
# They may have severe implications,
# like hard resetting the node under certain circumstances.
# Be careful when choosing your poison.
# 这三行取消注释
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
# fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
# split-brain "/usr/lib/drbd/notify-split-brain.sh root";
# out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
# after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
# quorum-lost "/usr/lib/drbd/notify-quorum-lost.sh root";
}
startup {
# wfc-timeout degr-wfc-timeout outdated-wfc-timeout wait-after-sb
}
options {
# cpu-mask on-no-data-accessible
# RECOMMENDED for three or more storage nodes with DRBD 9:
# quorum majority;
# on-no-quorum suspend-io | io-error;
}
disk {
# 配置I/O错误处理策略为分离,添加这行
on-io-error detach;
# size on-io-error fencing disk-barrier disk-flushes
# disk-drain md-flushes resync-rate resync-after al-extents
# c-plan-ahead c-delay-target c-fill-target c-max-rate
# c-min-rate disk-timeout
}
net {
# protocol timeout max-epoch-size max-buffers
# connect-int ping-int sndbuf-size rcvbuf-size ko-count
# allow-two-primaries cram-hmac-alg shared-secret after-sb-0pri
# after-sb-1pri after-sb-2pri always-asbp rr-conflict
# ping-timeout data-integrity-alg tcp-cork on-congestion
# congestion-fill congestion-extents csums-alg verify-alg
# use-rle
}
# 添加这个参数
syncer {
rate 1024M; # 设置主备节点同步时的网络速率
}
}
- 新建drbd neo4j.res配置文件
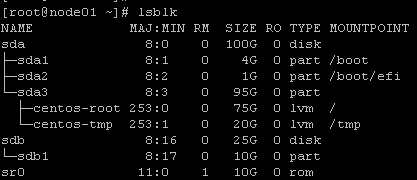
首先查看磁盘状态,然后为sdb磁盘创建一个分区sdb1
lsblk
fdisk /dev/sdb
n
p
+10G
+10G
w # 保存分区,退出
neo4j.res文件内容如下。
cd /etc/drbd.d
resource neo4j { # 资源名
protocol C;
meta-disk internal; # 源数据策略
device /dev/drbd1; # 设备名
syncer {
verify-alg sha1; # 加密算法
}
net {
allow-two-primaries; # 允许双主
}
on node01 { # node01主机节点
disk /dev/sdb1; # 对应的设备:磁盘
address 10.30.239.201:7789; # 地址:默认端口
}
on node02 {
disk /dev/sdb1;
address 10.30.239.202:7789;
}
}
2.4 启动drbd
- 创建并启用资源
# 创建资源
drbdadm create-md neo4j
# 启用资源
drbdadm up neo4j
# 设置node01为主,只在主节点上配置
drbdadm -- --force primary neo4j
# 查看资源状态
cat /proc/drbd
drbdadm status neo4j
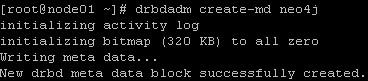
查看neo4j资源状态
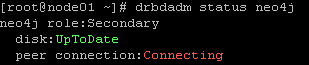
发现节点连接不同,处理方案
- 检查host文件,均已添加两个节点
vim /etc/hosts
- 检查防火墙,关闭防火墙,主要是为了保证7789端口开放
systemctl status firewalld
systemctl stop firewalld
关闭防火墙后,节点间能够正常连通
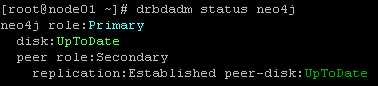
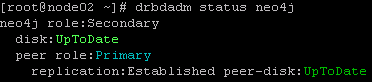
此图表示,主节点在向从节点同步数据,已同步88.52

- 在主节点上挂载
创建脚本目录和数据库目录
mkdir /data
mkdir -p /data/scripts /data/logs data/drbd
mount /dev/drbd1 /data/drbd
报错
![]()
创建ext4文件系统
mkfs.ext4 /dev/drbd1
# 创建xfs在centos7上可能更合适
mkfs.xfs /dev/drbd1
2.5 关闭资源
从节点:
drbdadm down neo4j
主节点,需要先解除挂载,再关闭
fuser -mvk /data/drbd
/bin/umount /data/drbd
drbdadm down neo4j
2.6 一个重点
drbd的主从模式下,从节点无法挂载,不能读也不能写,只能默接收从主节点同步过来的数据,同步数据在服务器上是不可见的。
只有当主节点挂掉时,通过keepalived等组件被重新选举为主节点时,其同步数据才能够挂载出去,进行使用。
这点无法满足我预先期望的从节点可以读不能写的目的,大失败。
drbd可以配置成双主模式,但双主节点无法同步数据,在主1写数据之后,需要对主2重新挂载才会同步。
2.7 nfs
2.7.1 安装
- 在集群所有节点安装nfs
yum -y install nfs-utils rpcbind
- 将主节点上的某一目录共享给从节点使用
vim /etc/exports
# rw:读写
# ro:只读
/data/drbd 10.30.239.202/24(rw,sync,no_root_squash)
- 在主节点启动服务
systemctl start rpcbind
systemctl start nfs
- 在从节点挂载共享的存储目录
mount -t nfs 10.30.239.201:/data/drbd /data/drbd
可以看到,201和202上的/data/drbd的数据是同步的
但是,当我在201上启动neo4j服务后,在202上启动neo4j服务时,报错:数据库已被另外的进程锁定。
![]()
3. neo4j存储探索
由于数据库锁的存在,即使主从的数据共享成功,能够启动服务的也只有主节点,从节点仍处于不可读的状态。
研究了一下mysql的主从机制,在NDB集群存储引擎出来之前,其集群可采用方案如下,也就是通过共享数据库事务的binlog文件来实现数据的同步。
主从同步过程:
- master binlog,主从复制的基础是master所有的变更记录到binlog日志文件
- master binlog dump thread,当binlog有变动时,dump thread读取其内容并发生给slave从节点
- slave IO thread,接受binlog内容,并将其写入到relay log 中继文件中
- slave SQL thread,读取relay log文件内容对数据更新进行重放,最终保证主从数据库的一致性
那么,neo4j作为一个事务数据库是否存在同样的机制呢,查阅资料后发现,neo4j官方集群是通过核心服务器core server 的Raft协议复制所有事务来实现对数据保护的目的,只读副本是通过事务日志传送从Core Servers异步复制的。它定期轮询核心服务器以查找自上次轮询以来已处理的任何新事务,并且核心服务器会将这些事务发送到只读副本。
那么单点neo4j同样也可以考虑通过事务日志的共享来实现数据同步,查询neo4j.conf文件,找到事务日志相关的配置,解析处理这个tx_log或许可以实现数据同步。neo4j会通过Checkpointing来刷新数据库,参考文档:
https://neo4j.com/developer/kb/checkpointing-and-log-pruning-interactions/![]()
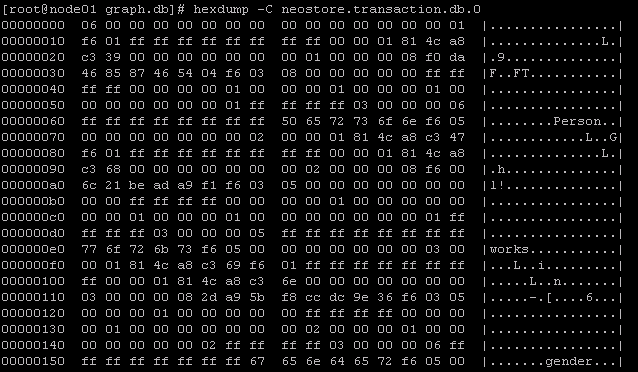
tx_log事务文件在数据库目录下,即图中这个文件。
![]()
在实践中发现,向neo4j写入一个节点数据时,debug.log下会出现checkpoint相关刷新日志

企业版可以通过neo4j-admin backup: https://neo4j.com/docs/operations-manual/4.4/backup-restore/
但是neo4j社区版是没有提供根据事务日志恢复数据的接口的,源代码中涉及:
https://github.com/neo4j/neo4j/blob/3.0/tools/src/main/java/org/neo4j/tools/applytx/DatabaseRebuildTool.java
把源码down下来,初步看了下,由于java文件中引入了很多neo4j自己写的包,内容比较复杂,没看懂,┭┮﹏┭┮
查看了neostore.transaction.db.0事务日志,一个二进制文件,和mysql的Binlog类似,但mysql提供了了对Binlog的处理方法,neo4j企业版才提供neo4j-admin backup的处理方法。
hexdump -C /data/drbd/neo4j-community-3.5.3/data/databases/graph.db/neostore.transaction.db.0
4. 集群管理
集群管理是高可用的一个重要组成部分,集群搭建后,需要对各节点进行检查和维护,常用的组件有:Keepalived,heartbeat、corosync、pacemaker等。
Keepalived是一个基于VRRP协议来实现的服务高可用方案,可以利用其来避免IP单点故障。keepalived本身是没有资源管理层,只有心跳状态层。它实现管理管理是由脚本实现的。参考文档:https://blog.csdn.net/xyang81/article/details/52554398/?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_utm_term~default-0–blog-123023897.pc_relevant_default&spm=1001.2101.3001.4242.1&utm_relevant_index=3
3.1 安装Keepalived
cd /opt/install
wget http://www.keepalived.org/software/keepalived-1.4.2.tar.gz --no-check-certificate
tar zxvf keepalived-1.4.2.tar.gz
cd keepalived-1.4.2
./configure --prefix=/usr/local/keepalived
报错openssl环境不存在
# 安装openssl等依赖后进行编译
yum install -y gcc openssl-devel popt-devel
make && make install

- 拷贝配置文件到系统路径
mkdir /etc/keepalived
cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/
cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
cp /usr/local/keepalived/sbin/keepalived /usr/sbin/
3.2 配置master文件
vim /etc/keepalived/keepalived.conf
主机
vrrp_script的参考文档:http://t.zoukankan.com/paul8339-p-9644821.html
虚拟网卡:
ip a
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL # 标识本节点的字条串,通常为hostname
#vrrp_strict
}
# vrrp_script用于对集群中服务资源进行监控, 定义对服务资源检测的时间间隔、权重等参数,进而实现Keepalived的主、备节点切换
vrrp_script check_neo4j {
script "/data/scripts/check_neo4j.sh"
interval 1
fall 2
}
# vrrp实例
vrrp_instance VI_1 {
state MASTER
# 本机虚拟网卡名字
interface ens192
virtual_router_id 52
priority 100
advert_int 1
# 如果两节点的上联交换机禁用了组播,则采用vrrp单播通告的方式
# 本机ip
unicast_src_ip 10.30.239.201
unicast_peer {
# 其他机器ip
10.30.239.202
}
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟ip,vip,实现高可用,201,202都通过这个vip对外提供服务
virtual_ipaddress {
10.30.239.203
}
# keepalived停止运行前运行notify_stop指定的脚本
notify_stop /data/scripts/notify_stop.sh
# 当前节点成为master时,通知脚本执行任务
notify_master /data/scripts/notify_master.sh
track_script {
check_neo4j
}
}
- check_neo4j.sh的脚本内容如下。
#!/bin/sh
ps_out=`ps -ef | grep neo4j-community | grep -v 'grep' | grep -v check_neo4j.sh`:
result=$(echo $ps_out | grep "neo4j-community")
if [[ "$result" != "" ]];then
echo "Running"
else
# /data/drbd/neo4j-community-3.5.3/bin/neo4j start >> /data/logs/keepalived/notify_master.log
# sleep 2
echo "干掉keepalived $result" >/tmp/check.log
killall keepalived
fi
- notify_master.sh的脚本内容如下。
#!/bin/bash
time=`date "+%F %H:%M:%S"`
echo -e "$time ------notify_master------\n" >> /data/logs/keepalived/notify_master.log
#ssh root@inte-neo4j-02 "reboot" >> /data/logs/keepalived/notify_master.log
drbdadm primary neo4j >> /data/logs/keepalived/notify_master.log
mount /dev/drbd1 /data/drbd >> /data/logs/keepalived/notify_master.log
/data/drbd/neo4j-community-3.5.3/bin/neo4j start >> /data/logs/keepalived/notify_master.log
echo -e "end \n" >> /data/logs/keepalived/notify_master.log
- notify_stop.sh的脚本内容如下。
#!/bin/bash
time=`date "+%F %H:%M:%S"`
echo -e "$time ------notify_stop------\n" >> /data/logs/keepalived/notify_stop.log
fuser -mvk /data/drbd
/bin/umount /data/drbd >> /data/logs/keepalived/notify_stop.log
echo 'unount success'
/usr/sbin/drbdadm secondary neo4j >> /data/logs/keepalived/notify_stop.log
#/usr/bin/systemctl stop keepalived >> /data/logs/keepalived/notify_stop.log
echo -e " end \n" >> /data/logs/keepalived/notify_stop.log
3.2 配置backup文件
global_defs {
router_id LVS_DEVEL
#vrrp_strict
}
vrrp_instance VI_1 {
state BACKUP
interface ens192
virtual_router_id 52
priority 90
advert_int 1
# 如果两节点的上联交换机禁用了组播,则采用vrrp单播通告的方式
# 本机ip
unicast_src_ip 10.30.239.202
unicast_peer {
# 其他机器ip
10.30.239.201
}
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.30.239.203
}
notify_master /data/scripts/notify_master.sh
notify_backup /data/scripts/notify_backup.sh
}
- notify_backup.sh的脚本内容如下
#!/bin/bash
time=`date "+%F %H:%M:%S"`
echo -e "$time ------notify_backup------\n" >> /data/logs/keepalived/notify_backup.log
/data/drbd/neo4j-community-3.5.3/bin/neo4j stop >> /data/logs/keepalived/notify_backup.log
#fuser -mvk /data/drbd
/bin/umount /data/drbd >> /data/logs/keepalived/notify_backup.log
echo "umount success"
/usr/sbin/drbdadm secondary neo4j >> /data/logs/keepalived/notify_backup.log
echo -e "end \n" >> /data/logs/keepalived/notify_backup.log
3.4 启动服务
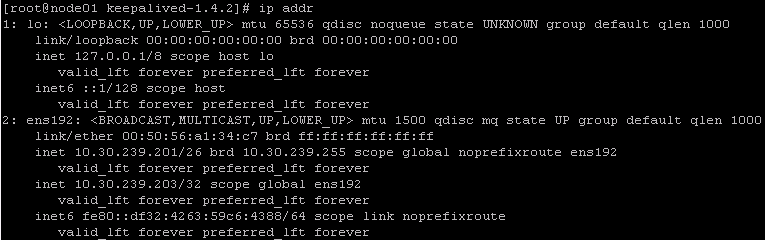
service keepalived start
ip addr
主节点上生成虚拟ip
4. 安装neo4j
https://dist.neo4j.org/neo4j-community-3.5.3-unix.tar.gz
cd /data/drbd
tar -zxvf neo4j-community-3.5.3-unix.tar.gz
cd /data/drbd/neo4j-community-3.5.3/bin
./neo4j start