Oracle表查询优化思路
一、分页语句优化思路
正确的分页框架:
SELECT *
FROM (SELECT *
FROM (SELECT A.*, ROWNUM AS RN
FROM (需要分页的SQL) A)
WHERE ROWNUM <= 10)
WHERE RN >= 1;
分页语句的优化思路:如果分页语句中有排序(order by ),要利用索引已排序的特征,将order by 的列包含在索引中,同时也要利用rownum的COUNT STOPKEY特性来优化分页SQL。如果分页中没有排序,可以直接利用rownum的COUNT STOPKE特性来优化分页SQL。
实例1:
SELECT *
FROM (SELECT A.*, ROWNUM AS RN
FROM (select * from t_page order by object_id) A) WHERE ROWNUM<=10)
WHERE RN >= 1
该SQL没有过滤条件,只有排序,可以利用索引已经排序这个特性来优化分页语句,也就是说要将分页语句中的SORT ORDER BY消除。
对排序列创建索引,在索引中添加一个常量0,注意0不能放在前面。为什么要再索引中添加一个常量0呢?因为object_id允许为空,如果不加常量(不一定是0,可以是1、2、3,也可以是英文字母),索引中就不能存储空值,然而SQL中并没有写 where object_id is not null。
创建索引:
create index idx_page_ownerid on t_page(object,0)
如果SQL有过滤条件是等值过滤,当然也有order by 。
SELECT * FROM T_PAGE WHERE OWNER='SYS' ORDER BY OBJECT_ID。
这就需要将过滤列(SYS)包含在索引中,排序列是object_id。
创建索引:
create index idx_page_ownerid on t_page(owner,object)
如果有如下分页语句:
SELECT *
FROM (SELECT *
FROM (SELECT A.*, ROWNUM AS RN
FROM (select *
from t_page
order by object_id, object_name desc) A)
WHERE ROWNUM <= 10)
WHERE RN >= 1
那么创建索引的时候,只能是object_id列在前,object_name列在后面,另外object_name是降序显示的,那么在创建索引的时候,还要指定object_name列降序排序。
创建索引:
create index idx_page_ownerid on t_page(object,object_name desc,0)
如果创建索引的时候将object_name放在前面,object_id放在后面,这时,索引中列先后顺序与分页语句中排序先后顺序不一致,强制走索引的时候,执行计划中会出现SORT ORDER BY关键字。如果创建索引的时候没有指定object_name列降序排序,那么执行计划中也会出现SORT ORDER BY。因为索引中排序合分页语句中排序不一致。
如果有如下分页语句:
SELECT *
FROM (SELECT *
FROM (SELECT A.*, ROWNUM AS RN
FROM (select *
from t_page
where owner = 'SYS'
and object_id > 10000
order by object_name) A)
WHERE ROWNUM <= 10)
WHERE RN >= 1
该SQL过滤条件有等值条件,也有非等值条件,当然也有order by 。应该怎么创建索引,从而优化上面的分页语句?因为owner是等值过滤,object_id是非等值过滤,创建索引的时候,优先将等值过滤列和排序组合在一起,然后将非等值过滤列放到后面。
create index idx_page_ownerid on t_page(object,object_name desc,object_id)。
总结:
1、分页语句 看到执行计划有走全表扫描 、走sort order by …就是错误的
2、分页语句没有 order by这种业务逻辑就是错的。分页语句里面必须有 order by 某个列。
3、特殊情况下没有 order by 走全表扫描是对的
4、分页语句如果有 order by 必须走索引 ,而且索引必须是包含了 order by 这个列的索引,只要分页有sort order by就是错的,有sort order by绝对没有走索引。分页语句的优化始终要怎么考虑??? 答:一定要让ORDER BY的列有索引。
5、order by 这个列如果出现在 where条件里面,在创建索引的时候是不是引导列无所谓。并不需要特别注意顺序。不在where条件中的时候必须是引导列。
6、分页语句走索引必须包含什么? 必须包含order by 列,另外分页语句最好不要有回表再过滤,所有最好建组合索引,加where列加进去
7、如果 order by里面的列没有出现在where列里面,也就是说order by 列的值可能为空值,也
不会走索引,所以最好改SQL,在where列上加一个order by 列的值is not null,或者使用
alter table page modify (order by 列) not null;来解决。
8、可能是错的。但实用。落总总结:分页语句 建立索引,不要管选择性了。 以ORDER BY
的列为引导列,其他的过滤条件的列,按照选择性,依次放后面。选择性太低的列就不要放索引里了。
9、遇到分页语句中有order by desc的,写HINT一定要写/*+ index_desc(a indx_1) */
提
10、是不是会把数据都扫描完最终才来distinct,所以会走全表扫描。那分页搞毛啊,你选第一页、二页其他都TM没区别啊。所以分页语句里面同样不能有group by
分页语句里面能否有union? 也不能,有union会排序 union all也是不可以的
总结下来:分页语句里不能用distinct,group by,union ,union all
11、select … from a,b where a.id=b.id order by a.xx;
两个表关联a,b。取第一页可能就十到二十条数据。
像这种返回数据非常少的是走NL对吧?
而order by a返回的数据是不是根据a表来排序,那根据a来排序,也就是取完a的数据再去驱动b。分页语句里面order by谁,谁就是驱动表
二、DBLINK优化
现在有两个表,a表是远端表(1800万),b表是本地表(100行)。
SQL:select * from a@dblink,b where a.id =b.id
1、优化方案(一)
默认情况下会将远端表a的数据传输到本地,然后再进行关联,远端表b很大,对数据进行传输会耗费大量时间,本地表b表很小,而且a和b关联之后返回数据量很少,可以将本地表b传输到远端,在远端进行关联,然后再将结果集传回本地,这时需要使用hint:driving_site。
select /*+driving_site(a)*/ * from a@dblink,b where a.id =b.id
2、优化方案(二)
现在在远端表a的连接列创建索引idx_id。因为b表只有100行数据,a表有1800万行数据,两表关联返回2.5万行数据,现在可以让a表与b表走嵌套循环,b表作为驱动表,a表作为被驱动表,而且走连接索引。
select /*+index(a) leading(b) use_nl(a,b)*/ * from a@dblink,b where a.id =b.id
强制a表走索引之后,只需将索引过滤之后的数据传输到本地,性能得到极大的提升。
3、优化方案(三)
如果远端表a很大,本地表b也很大,两表关联返回数据量多,这既不能将远端表a传到本地,也不能将本地表b传输到远端,,因此无论采用哪种方式,SQL都很慢。可以在本地创建一个带有DBLINK的物化视图,将远端的数据刷到本地。如果SQL语句中有多个DBLINK源,最好在本地针对每个DBLINK源建立带有DBLINK的物化视图,因为多个DBLINK之间进行数据传输,网络信息交换会导致严重性能问题。
4、DBLINK永远不能作为NL的被驱动表
三、超大表与超小表关联优化方法
SELECT * FROM A, B WHERE A.OBJECT_ID = B.OBJECT_ID
表a有30MB,b有30GB,两表关联后返回大量数据,应该走HASH连接,因为a是小表所有a应该作为HASH JOIN的驱动表,大表b作为HASH JOIN的被驱动表。在进行HASH的时候,驱动表会被放在PGA中,因为驱动表a只有30MB,PGA能够完全容纳下驱动表。因为被驱动表b特别大,想要加快SQL查询速度,必须开启并行查询。超大表与超小表在进行并行HASH连接的时候,可以将小表(驱动表)广播到所有的查询进程,然后对大表进行并行随机扫描,每个查询进程查询部分b表数据,然后再进行关联。假设对以上SQL启用6个并行进程对a表的并行广播,对b表进行随机并行扫描。怎么让a表进行广播?需要添加hint:pq_distribute(驱动表 none, broadcast)。具体查询语句如下:
SELECT /*+parallel(6) use_hash(a,b) pq_distribute(a none,broadcast)*/
* FROM A, B
WHERE A.OBJECT_ID = B.OBJECT_ID
注意:如果是两个大表关联,千万不能让大表广播。
四、对表进行ROWID切片
对于一个很大的非分区表进行update、delete,如果只在一个会话里面运行,很容易引发UNDO不够,如果会话连接中断,会导致大量数据从UNDO回滚,这将是一场灾难。
对于非分区表,可以对表按照ROWID切片,然后开启多个窗口同时执行SQL,这样既能加快执行速度,还能减少对HUNDO的占用。
Oracle提供了一个内置函数DBMS_ROWID.ROWID_CREATE()用于生成ROWID。对于一个非分区表,一个表就是一个段(segment),段是由多个区组成,每个区里面的块物理是是连续的。于是,可以根据数据字典DBA_EXTENTS,DBA_OBJECTS关联,然后再利用生成ROWID的内置函数人工生成ROWID。
查询SQL脚本:
SELECT DBMS_ROWID.ROWID_CREATE(1,
B.DATA_OBJECT_ID,
A.RELATIVE_FNO,
A.BLOCK_ID,
0),
DBMS_ROWID.ROWID_CREATE(1,
B.DATA_OBJECT_ID,
A.RELATIVE_FNO,
A.BLOCK_ID + A.BLOCKS - 1,
999)
FROM DBA_EXTENTS A
INNER JOIN DBA_OBJECTS B
ON A.OWNER = B.OWNER
AND A.SEGMENT_NAME = B.OBJECT_NAME
WHERE B.OWNER = 'SCOTT'
AND B.OBJECT_NAME = 'T_PAGE'
假如要执行DELETE FROM T_PAGE WHERE OBJECT_ID>50000000,T_PAGE表有1亿条数据,要删除其中5000万行数据,可以根据上述办法对表按照ROWID切片删除。
DELETE FROM T_PAGE
WHERE OBJECT_ID > 5000000
AND ROWID BETWEEN 'AABE3nAAEAAAACoAAA' AND 'AABE3nAAEAAAACvAPn';
DELETE FROM T_PAGE
WHERE OBJECT_ID > 5000000
AND ROWID BETWEEN 'AABE3nAAEAAAACwAAA' AND 'AABE3nAAEAAAAC3APn';
…
上述方法需要手动编辑大量SQL脚本,如果表的EXTENT很多,这将会带来很大工作量,因此可以通过存储过程来实现。
CREATE OR REPLACE PROCEDURE P_DEL_ROWID(P_RANGE NUMBER, P_ID NUMBER) AS
CURSOR CUR_ROWID IS
SELECT DBMS_ROWID.ROWID_CREATE(1,
B.DATA_OBJECT_ID,
A.RELATIVE_FNO,
A.BLOCK_ID,
0) AS ROWID1,
DBMS_ROWID.ROWID_CREATE(1,
B.DATA_OBJECT_ID,
A.RELATIVE_FNO,
A.BLOCK_ID + A.BLOCKS - 1,
999) AS ROWID2
FROM DBA_EXTENTS A
INNER JOIN DBA_OBJECTS B
ON A.OWNER = B.OWNER
AND A.SEGMENT_NAME = B.OBJECT_NAME
WHERE B.OWNER = 'SCOTT'
AND B.OBJECT_NAME = 'T_PAGE'
AND MOD(A.EXTENT_ID, P_RANGE) = P_ID;
V_SQL VARCHAR2(4000);
BEGIN
FOR CUR IN CUR_ROWID LOOP
V_SQL := 'DELETE FROM T_PAGE WHERE OBJECT_ID >100 AND ROWID BETWEEN :1 AND :2';
EXECUTE IMMEDIATE V_SQL
USING CUR.ROWID1, CUR.ROWID2;
COMMIT;
END LOOP;
CLOSE CUR_ROWID;
END;
五、固化查询/+MATERIALIZE/
通过对查询语句采用 WITH temp AS select /+MATERIALIZE/ * from 子查询固化查询语句,不让查询语句展开,如果该查询语句返回数据量比较少,该子查询可作为主表,进行嵌套循环连接。
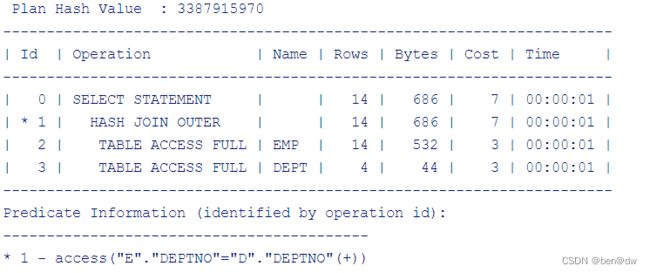
六、外连接有OR关联条件只能走NL
SELECT E.*, D.DEPTNO AS DEPTNO2, D.LOC
FROM EMP E
LEFT JOIN DEPT D
ON E.DEPTNO = D.DEPTNO
AND (D.DEPTNO >= E.SAL AND E.SAL < 1000 OR E.ENAME LIKE '%O')

从执行计划中看到,两表走的是嵌套循环。当两表用外连接关联,关联条件中有OR关联条件,那么这时只能走嵌套循环,而且驱动表固定为主表,此时不能走HASH连接,即使通过HINT:USE_HASH要无法修改执行计划。如果主表数据量很大,那么这时就会出现严重性能问题。可以将外连接的OR关联/过滤条件放到查询中,用CASE WHEN进行过滤,从而让SQL可以走HASH连接。
SELECT E.*,
(case
when (D.DEPTNO >= E.SAL AND E.SAL < 1000 OR E.ENAME LIKE '%O') then
D.DEPTNO
end) AS DEPTNO2,
(case
when (D.DEPTNO >= E.SAL AND E.SAL < 1000 OR E.ENAME LIKE '%O') then
D.LOC
end) as LOC
FROM EMP E
LEFT JOIN DEPT D
ON E.DEPTNO = D.DEPTNO
利用case when改写外连接OR连接条件有个限制:从表(被驱动表)只能是1的关系,不能是N的关系,从表要展示多少个列,就要写多少个case when。
如果主表属于1的关系,从表属于n的关系,就不能用case when进行等价改写。