scikit-learn KNN 画图展示
鸢尾花 iris展示
import numpy as np
import matplotlib.pylab as pyb
%matplotlib inline
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
加载数据,数据降维(画图)
X,y = datasets.load_iris(True) #return_X_y=True 返回X,y 之前返回一个字典
# 4个属性,4维空间,4维的数据
# 150代表样本的数量
X.shape
#(150, 4)
# 降维,切片:简单粗暴方式(信息量变少了)
X = X[:,:2]
X.shape
#(150, 2)
pyb.scatter(X[:,0],X[:,1],c = y) #以类别区分颜色
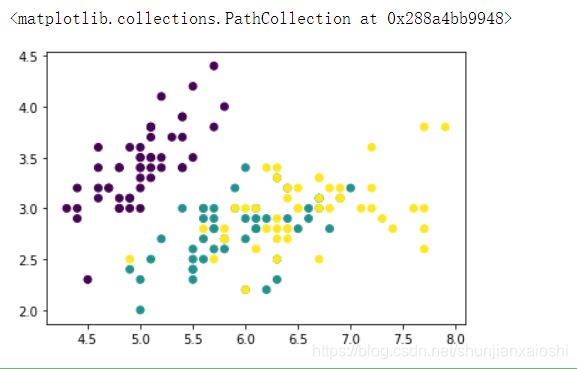
我们以这些点为训练点,以背景点为测试点 最后会形成泾渭分明的图片
KNN算法训练数据
knn = KNeighborsClassifier(n_neighbors=5)
# 使用150个样本点作为训练数据
knn.fit(X,y)
#KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',metric_params=None, n_jobs=None, n_neighbors=5, p=2,weights='uniform')
# 训练数据
X.shape
# 测试数据 shape (?,2)
#(150, 4)
meshgrid提取测试数据(8000个测试样本)
# 获取测试数据
# 横坐标4 ~ 8;纵坐标 2~ 4.5
# 背景点,取出来,meshgrid
x1 = np.linspace(4,8,100)
y1 = np.linspace(2,4.5,80)
X1,Y1 = np.meshgrid(x1,y1) #(80,100)花萼长 (80,100)花瓣长
X1 = X1.reshape(-1,1) #(8000,1)
Y1 = Y1.reshape(-1,1) #(8000,1)
X_test = np.concatenate([X1,Y1],axis = 1)
# X_test.shape #(8000,2)
# 另一种方法,官方案例中使用的 平铺,一维化,reshape(-1)
# X_test = np.c_[X1.ravel(),Y1.ravel()]
X_test

使用算法进行预测,可视化
%%time #一个%只能是一行
y_ = knn.predict(X_test)
#Wall time: 258 ms #一维数据花的时间少,手写数字700多维
from matplotlib.colors import ListedColormap
lc = ListedColormap(['#FFAAAA','#AAFFAA','#AAAAFF']) #颜色
lc2 = ListedColormap(['#FF0000','#00FF00','#0000FF'])
%%time
pyb.scatter(X_test[:,0],X_test[:,1],c = y_,cmap = lc)
pyb.scatter(X[:,0],X[:,1],c = y,cmap = lc2)
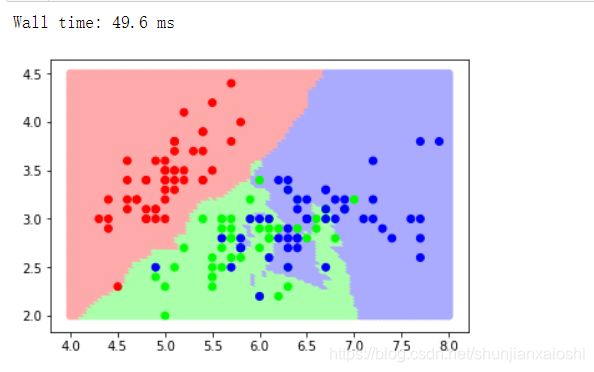
%%time #时间快一点
pyb.contourf(X1,Y1,y_.reshape(80,100),cmap = lc) #轮廓线,等高线
pyb.scatter(X[:,0],X[:,1],c = y,cmap = lc2)

KNN参数的筛选
导包,加载数据
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets
# model_selection:模型选择
# cross_val_score cross:交叉,validation:验证(测试)
# 交叉验证分数
from sklearn.model_selection import cross_val_score
X,y = datasets.load_iris(True)
X.shape
#(150, 4)
# 参考
150**0.5
# K 选择 1 ~ 13
#12.24744871391589
什么是交叉验证?
就是假设有一堆数据,将它分成5份1,2,3,4,5。先将第一份取出作为测试数据,2,3,4,5则为训练数据,会得到一个测试分数,再将第二份取出作为测试数据,1,3,4,5则为训练数据,依次类推直到全都测完,得到5个分数。之后我们可以取平均值。平均值更具有说服性。
cross_val_score交叉验证筛选最合适参数
# 演示了交叉验证,如何使用
knn = KNeighborsClassifier()
score = cross_val_score(knn,X,y,scoring='accuracy',cv = 10) #评分标准 分类标准 cv就是分成几份
score.mean()
#0.9666666666666668
分类标准:scikit-learn.org/state/modules/model_evaluation.html
应用cross_val_score筛选最合适的邻居数量
erros = []
for k in range(1,14):
knn = KNeighborsClassifier(n_neighbors=k)
score = cross_val_score(knn,X,y,scoring='accuracy',cv = 6).mean()
# 误差越小,说明k选择越合适,越好
erros.append(1 - score)
import matplotlib.pyplot as plt
%matplotlib inline
# k = 11时,误差最小,说明k = 11对鸢尾花来说,最合适的k值
plt.plot(np.arange(1,14),erros)

多参数组合使用cross_val_score筛选最合适的参数组合
模型如何调参的,参数调节
weights=['uniform',distance']
result = {}
for k in range(1,14):
for w in weights:
knn = KNeighborsClassifier(n_neighbors=k,weights=w)
sm = cross_val_score(knn,X,y,scoring='accuracy',cv = 6).mean()
result[w + str(k)] = sm
result
#{'uniform1': 0.9591049382716049,
#'distance1': 0.9591049382716049,
#'uniform2': 0.9390432098765431,
#'distance2': 0.9591049382716049,...}
np.array(list(result.values())).argmax()
#20
list(result)[20]
#'uniform11' #最合适参数组合
KNN癌症诊断
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
# grid网格,search搜索,cv:cross_validation
# 搜索算法最合适的参数
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score

加载数据和提取数据和目标值
cancer = pd.read_csv('./cancer.csv',sep = '\t') #569个数据 32个特征
cancer.drop('ID',axis = 1,inplace=True) #ID没用对于数据分析
X = cancer.iloc[:,1:]
y = cancer['Diagnosis']
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2)
网格搜索GridSearchCV进行最佳参数的查找
knn = KNeighborsClassifier()
params = {'n_neighbors':[i for i in range(1,30)],
'weights':['distance','uniform'],
'p':[1,2]}
# cross_val_score类似
gcv = GridSearchCV(knn,params,scoring='accuracy',cv = 6)
gcv.fit(X_train,y_train)

查看了GridSearchCV最佳的参数组合
gcv.best_params_
#{'n_neighbors': 12, 'p': 1, 'weights': 'distance'}
gcv.best_estimator_
#KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',metric_params=None, n_jobs=None, n_neighbors=12, p=1,weights='distance')
gcv.best_score_
#0.9494505494505494
使用GridSearchCV进行预测,计算准确率
y_ = gcv.predict(X_test) #自己的方法
(y_ == y_test).mean()
#0.9122807017543859
gcv.score(X_test,y_test) #gcv自带的
#0.9122807017543859
accuracy_score(y_test,y_) #导包导进来的
#0.9122807017543859
# 取出了最好的模型,进行预测
# 也可以直接使用gcv进行预测,结果一样的
knn_best = gcv.best_estimator_ #gcv对模型进行了封装
y_ = knn_best.predict(X_test)
accuracy_score(y_test,y_)
#0.9122807017543859
交叉表
X_test.shape
#(114, 30)
pd.crosstab(index = y_test,columns=y_,rownames=['True'],colnames=['Predict'],
margins=True) #margins边界 加上会出现ALL
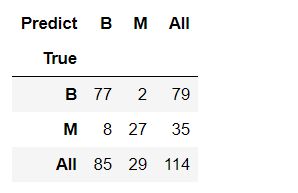
77+2是B正常人真实值,8+27是M病人真实值,预测77对了8个病人预测成好的,将2个好人预测为病人,27个预测正确
from sklearn.metrics import confusion_matrix #混淆矩阵
confusion_matrix(y_test,y_)
#array([[77, 2],
# [ 8, 27]], dtype=int64)
# 真实的
y_test.value_counts()
#B 79
#M 35
#Name: Diagnosis, dtype: int64
# 预测
Series(y_).value_counts()
#B 85
#M 29
#dtype: int64
confusion_matrix(y_test,y_)
#array([[77, 2],
# [ 8, 27]], dtype=int64)
confusion_matrix(y_,y_test)
#array([[77, 8],
# [ 2, 27]], dtype=int64)
#recall 找到正样本的能力
np.round(77/79,2)
#0.97
np.round(27/35,2)
#0.77
# precision 精确度
np.round(77/85,2)
#0.91
np.round(27/29,2)
#0.93
#f1-score 调和平均律
np.round(2*0.97*0.91/(0.97 + 0.91),2)
#0.94
np.round(2*0.93*0.77/(0.77 + 0.93),2)
#0.84
# 精确率、召回率、f1-score调和平均值
from sklearn.metrics import classification_report
print(classification_report(y_test,y_,target_names = ['B','M']))
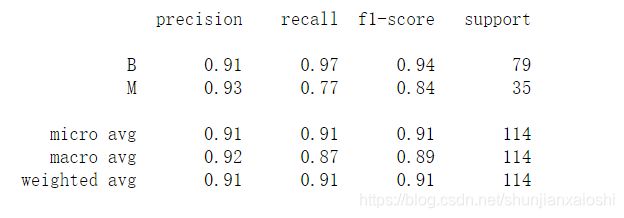
提升准确率,提升精确率,提升召回率
X.head()
#可以发现数据值之间差别太大

# 归一化操作
X_norm1 = (X - X.min())/(X.max() - X.min())
X_norm1.head()

X_train,X_test,y_train,y_test = train_test_split(X_norm1,y,test_size = 0.2)
knn = KNeighborsClassifier()
params = {'n_neighbors':[i for i in range(1,30)],
'weights':['uniform','distance'],
'p':[1,2]}
gcv = GridSearchCV(knn,params,scoring='accuracy',cv = 6)
gcv.fit(X_train,y_train)

y_ = gcv.predict(X_test)
accuracy_score(y_test,y_)
#0.9824561403508771
print(classification_report(y_test,y_,target_names=['B','M']))

# Z-Score归一化,标准化
X_norm2 = (X - X.mean())/X.std()
X_norm2.head()

#平均值整体接近0
X_norm2.mean()
#radius_mean -3.136331e-15
#texture_mean -6.558316e-15
#perimeter_mean -7.012551e-16
#area_mean -8.339355e-16....
#标准差整体接近1
X_norm2.std()
#radius_mean 1.0
#texture_mean 1.0
#perimeter_mean 1.0
#area_mean 1.0...
使用归一化的数据进行预测
X_train,X_test,y_train,y_test = train_test_split(X_norm2,y,test_size = 0.2)
knn = KNeighborsClassifier()
params = {'n_neighbors':[i for i in range(1,30)],
'weights':['uniform','distance'],
'p':[1,2]}
gcv = GridSearchCV(knn,params,scoring='accuracy',cv = 6)
gcv.fit(X_train,y_train)
y_ = gcv.predict(X_test)
accuracy_score(y_test,y_)
#0.9912280701754386
from sklearn.preprocessing import MinMaxScaler,StandardScaler #缩放
# MinMaxScaler 和最大值最小值归一化效果一样
mms = MinMaxScaler()
((X - X.min())/(X.max() - X.min())).head()

mms.fit(X)
X2 = mms.transform(X)
X2.round(6)
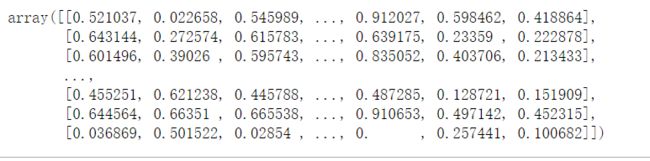
# DataFrame,默认保留6位
# z = (x - u) / s
((X - X.mean())/X.std()).head()

nd = X.get_values()
nd

(nd - nd.mean(axis = 0))/nd.std(axis = 0)

ss = StandardScaler()
X3 = ss.fit_transform(X)
X3
