(立下flag)每日10道前端面试题-01
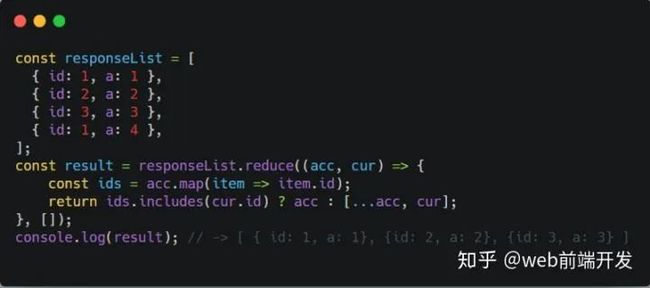
1 对象数组如何去重?
开始的时候一脸懵逼,心里想着每个对象的内存地址本身就不一样,去重的意义何在,非要去重的话,那只能通过JSON.stringify序列化成字符串(这个方法有一定的缺陷)后进行对比,或者递归的方式进行键-值对比,但是对于大型嵌套对象来说还是比较耗时的,所以还是没有答好,后来面试官跟我说是根据每个对象的某一个具体属性来进行去重,因为考虑到服务端返回的数据中可能存在id重复的情况,需要前端进行过滤,如下:
2 (算法题) 如何从10000个数中找到最大的10个数
从10000个整数中找出最大的10个,最好的算法是什么?
算法一:冒泡排序法
千里之行,始于足下。我们先不说最好,甚至不说好。我们只问,如何“从10000个整数中找出最大的10个”?我最先想到的是用冒泡排序的办法:我们从头到尾走10趟,自然会把最大的10个数找到。方法简单,就不再这里写代码了。这个算法的复杂度是10N(N=10000)。
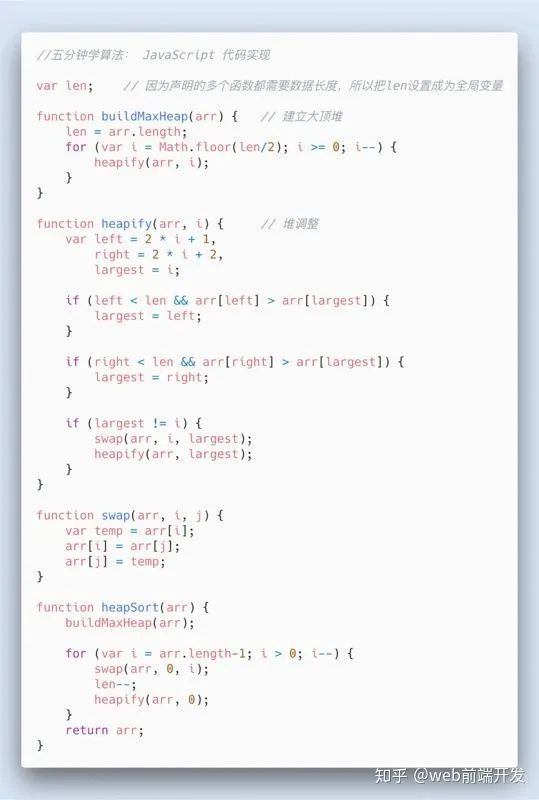
算法二:堆排序
创建一个最小堆结构,初始值为10000个数的前10个,堆顶为10个数里的最小数。然后遍历剩下的9990个数,如果数字小于堆顶的数,则直接丢弃,否则把堆顶的数删除,将遍历的数插入堆中,堆结构进行自动调整,所以可以保证堆顶的数一定是10个数里最小的。遍历完毕后,堆里的10个数就是这10000个数里面最大的10个。
下面为堆排序算法代码,不是上面题的答案:
3 手动封装一个请求函数,可以设置最大请求次数,请求成功则不再请求,请求失败则继续请求直到超过最大次数

4 选择器优先级
important>内联>id>class = 属性 = 伪类 >标签 = 伪元素 > 通配符(*)
important声明 1,0,0,0
ID选择器 0,1,0,0
类选择器 0,0,1,0
伪类选择器 0,0,1,0
属性选择器 0,0,1,0
标签选择器 0,0,0,1
伪元素选择器 0,0,0,1
通配符选择器 0,0,0,0
有人说*外部样式<内部样式,其实不然,其实外部样式=内部样式,*谁在前面定义谁就被覆盖
class = 属性 = 伪类:例如.className的优先级和[class='className']和:hover的优先级是一样的,甚至.className的优先级和[id='idName']和:hover的优先级也是一样
空格和>的优先级是一样的,例如body b和body>b是一样的优先级
~和+的优先级是一样的,例如body~b和body+b是一样的优先级
伪元素的优先级和标签选择器的优先级一样
5 forEach,map和filter的区别
forEach遍历数组,参数为一个回调函数,回调函数接收三个参数,当前元素,元素索引,整个数组, forEach 在对 item 进行修改的时候,如果 item 是原始类型的值,item 对应的 的内存地址实际并没有变化,
如果 item 是 引用类型的值,item 对应多的内存地址也没有变化,但是对应的值,已经重写了map与forEach类似,遍历数组,但其回调函数的返回值会组成一个新数组,新数组的索引结构和原数组一致,原数组不变;filter会返回原数组的一个子集,回调函数用于逻辑判断,返回true则将当前元素添加到返回数组中,否则排除当前元素,原数组不变。
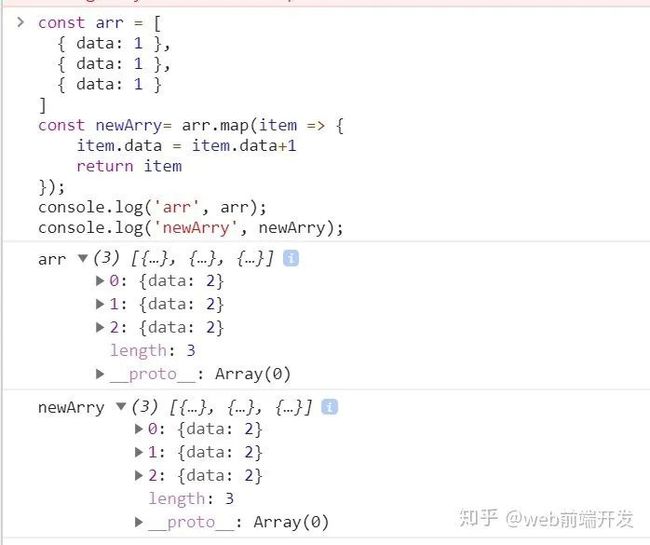
6 如何防止map后的数组修改原数组
这是会被修改的写法
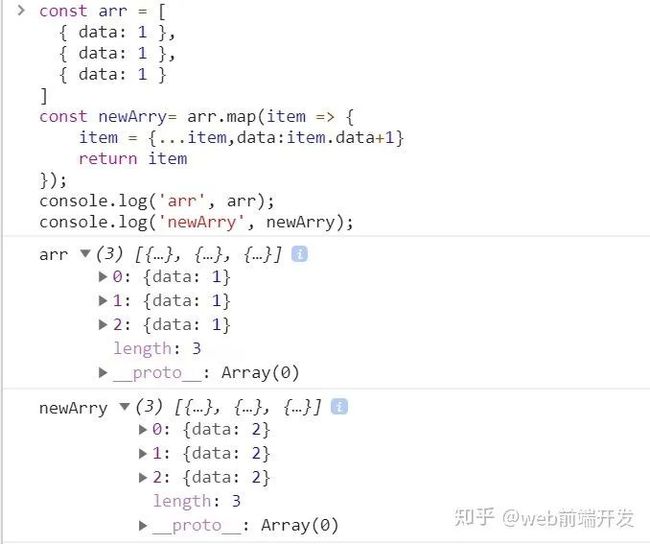
这是防止修改的写法
7 评价一下三种方法实现继承的优缺点,并改进
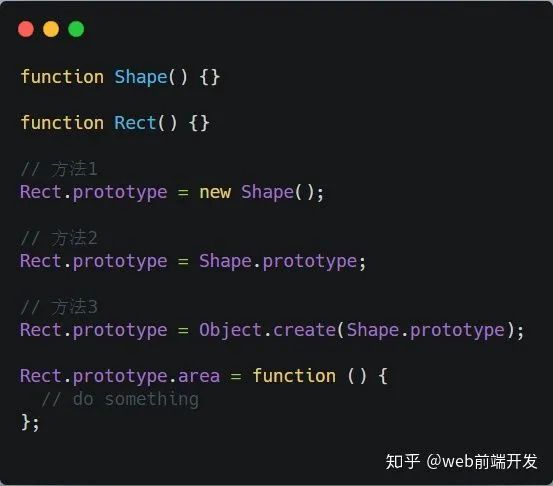
方法 1:
优点:正确设置原型链实现继承
优点:父类实例属性得到继承,原型链查找效率提高,也能为一些属性提供合理的默认值
缺点:父类实例属性为引用类型时,不恰当地修改会导致所有子类被修改
缺点:创建父类实例作为子类原型时,可能无法确定构造函数需要的合理参数,这样提供的参数继承给子类没有实际意义,当子类需要这些参数时应该在构造函数中进行初始化和设置
总结:继承应该是继承方法而不是属性,为子类设置父类实例属性应该是通过在子类构造函数中调用父类构造函数进行初始化
方法 2:
优点:正确设置原型链实现继承
缺点:父类构造函数原型与子类相同。修改子类原型添加方法会修改父类
方法 3:
优点:正确设置原型链且避免方法 1.2 中的缺点
缺点:ES5 方法需要注意兼容性
改进:
所有三种方法应该在子类构造函数中调用父类构造函数实现实例属性初始化

用新创建的对象替代子类默认原型,设置
Rect.prototype.constructor = Rect;保证一致性第三种方法的 polyfill:

8 如何判断一个对象是否为数组
如果浏览器支持 Array.isArray()可以直接判断否则需进行必要判断

这里我有个疑问就是
Object.prototype.toString.call(arg) === '[object Array]';本身就能判断了,为什么外面还要用typeOf,我想应该是typeOf的性能比较好?
编写一个函数将列表子元素顺序反转
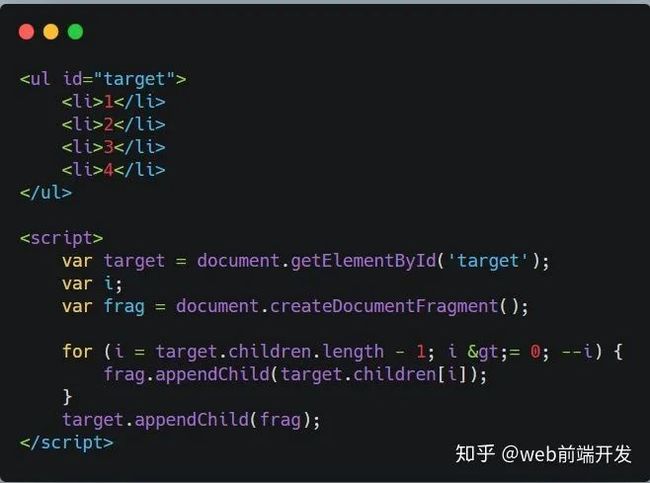
createdocumentfragment()方法创建了一虚拟的节点对象,节点对象包含所有属性和方法。
当你想提取文档的一部分,改变,增加,或删除某些内容及插入到文档末尾可以使用createDocumentFragment() 方法。
你也可以使用文档的文档对象来执行这些变化,但要防止文件结构被破坏,createDocumentFragment() 方法可以更安全改变文档的结构及节点。
10 link和@import的区别
本质上,这两种方式都是为了加载css文件,但还是存在细微的差别。
差别1:老祖宗的差别,link属于XHTML标签,而@import完全是css提供的一种方式。
link标签除了可以加载css外,还可以做很多其他的事情,比如定义RSS,定义rel连接属性等,@import只能加载CSS。
差别2:加载顺序的差别:当一个页面被夹在的时候(就是被浏览者浏览的时候),link引用的CSS会同时被加载,而@import引用的CSS会等到页面全部被下载完再加载。所以有时候浏览@import加载CSS的页面时会没有样式(就是闪烁),网速慢的时候还挺明显。
差别3:兼容性的差别。由于@import是CSS2.1提出的所以老的浏览器不支持,@import只有在IE5以上的才能识别,而link标签无此问题,完全兼容。
差别4:使用dom控制样式时的差别。当时用JavaScript控制dom去改变样式的时候,只能使用link标签,因为@import不是dom可以控制的(不支持)。
差别5(不推荐):@import可以在css中再次引入其他样式表,比如创建一个主样式表,在主样式表中再引入其他的样式表,如:
@import “sub1.css”;
@import “sub2.css”;
sub1.css
———————-
p {color:red;}
sub2.css
———————-
.myclass {color:blue}
这样有利于修改和扩展。
但是:这样做有一个缺点,会对网站服务器产生过多的HTTP请求,以前是一个文件,而现在确实两个或更多的文件了,服务器压力增大,浏览量大的网站还是谨慎使用。
@import的书写方式
@import 'style.css' //Windows IE4/ NS4, Mac OS X IE5, Macintosh IE4/IE5/NS4不识别
@import "style.css" //Windows IE4/ NS4, Macintosh IE4/NS4不识别
@import url(style.css) //Windows NS4, Macintosh NS4不识别
@import url('style.css') //Windows NS4, Mac OS X IE5, Macintosh IE4/IE5/NS4不识别
@import url("style.css") //Windows NS4, Macintosh NS4不识别
由上分析知道,@import url(style.css)和@import url("style.css")是最优的选择,兼容的浏览器最多。从字节优化的角度来看@import url(style.css)最值得推荐。