Hadoop伪分布式搭建
Hadoop伪分布式搭建
- 目的
- 准备
-
- 支持的平台
- 需要的软件
- 下载
- 伪分布式配置
- 设置SSH免密登录
- 启动hadoop
- 验证文件分块
-
- 查看上传后的文件
目的
本文档介绍如何设置和配置单节点Hadoop安装,以便您可以使用Hadoop MapReduce和Hadoop分布式文件系统(HDFS)快速执行简单操作。
准备
支持的平台
- 支持GNU/Linux作为开发和生产平台。Hadoop已经在具有2000个节点的GNU/Linux集群上进行了演示。
- Windows也是受支持的平台,但以下步骤仅适用于Linux。要在Windows上设置Hadoop,请参阅维基页面http://wiki.apache.org/hadoop/Hadoop2OnWindows
需要的软件
Linux所需的软件包括:
- 必须安装JAVA™。推荐的Java版本在HadoopJavaVersions中进行了描述https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions。
Apache Hadoop 3.3及更高版本支持Java 8和Java 11(仅限运行时),使用Java 8编译Hadoop。不支持使用Java 11编译Hadoop。所以建议使用Java8
- 如果要使用可选的启动和停止脚本,则必须安装SSH并且必须运行SSHD才能使用管理远程Hadoop守护程序的Hadoop脚本。此外,还建议安装pdsh,以便更好地管理ssh资源。
下载
下载地址:https://dlcdn.apache.org/hadoop/common/
选择稳定版本


选择hadoop-3.3.4.tar.gz下载,现在成功后上传到Linux目录/usr/local/hadoop,解压到当前目录
tar -zxvf hadoop-3.3.4.tar.gz
解压成功,配置hadoop-env.sh
vim /usr/local/hadoop/hadoop-3.3.4/etc/hadoop/hadoop-env.sh
配置JAVA_HOME将下面配置复制到hadoop-env.sh中
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/local/jdk1.8.0_131
注意:
如果启动时报:ERROR: Attempting to operate on hdfs namenode as root
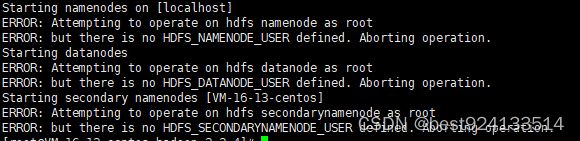
需要在hadoop-env.sh中添加如下配置
export PATH=$PATH:$JAVA_HOME/bin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
伪分布式配置
Hadoop还可以以伪分布式模式在单节点上运行,其中每个Hadoop守护进程都在单独的Java进程中运行。
- 配置core-site.xml
vim /usr/local/hadoop/hadoop-3.3.4/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/hadoop/hadoopdatavalue>
property>
configuration>
此处如果不配置hadoop.tmp.dir,hadoop默认位置是/tmp/hadoop-${username},建议配置自定义的路径,放在tmp中可能会在Linux重启时清除。
注意:如果一次启动时没有在core-site.xml中添加hadoop.tmp.dir自定义的路径,则数据信息会放在/tmp/hadoop-${username},此时如果再想更改为自定义的的路径,启动时就会报错:Directory /usr/local/hadoop/hadoopdata/dfs/name is in an inconsistent state: storage directory does not exist or is not accessible.
2023-02-28 10:37:57,368 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode.
org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /usr/local/hadoop/hadoopdata/dfs/name is in an inconsistent state: storage directory does not exist or is not accessible.
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverStorageDirs(FSImage.java:392)
at org.apache.hadoop.hdfs.server.namenode.FSImage.recoverTransitionRead(FSImage.java:243)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFSImage(FSNamesystem.java:1201)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.loadFromDisk(FSNamesystem.java:779)
at org.apache.hadoop.hdfs.server.namenode.NameNode.loadNamesystem(NameNode.java:681)
at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:768)
at org.apache.hadoop.hdfs.server.namenode.NameNode.(NameNode.java:1020)
at org.apache.hadoop.hdfs.server.namenode.NameNode.(NameNode.java:995)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1769)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1834)
2023-02-28 10:37:57,369 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1: org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /usr/local/hadoop/hadoopdata/dfs/name is in an inconsistent state: storage directory does not exist or is not accessible.
2023-02-28 10:37:57,371 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at VM-16-13-centos/127.0.0.1
/
2023-02-28 10:41:46,683 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: STARTUP_MSG:
/
解决办法:
1.删除原来的位置数据:/tmp/hadoop-${username}
2.name节点格式化:bin/hdfs namenode -format
设置SSH免密登录
首先检查您是否可以在没有密码的情况下ssh到本地主机:
ssh localhost
如果在没有密码的情况下无法通过ssh连接到本地主机,请执行以下命令:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
启动hadoop
- 格式化文件系统:
bin/hdfs namenode -format
- 启动NameNode守护进程和DataNode守护进程:
sbin/start-dfs.sh
Hadoop守护程序日志输出将写入HADOOP_LOG_DIR目录(默认为HADOOP_HOME/Logs)。
- 浏览NameNode的Web界面:http://localhost:9870/
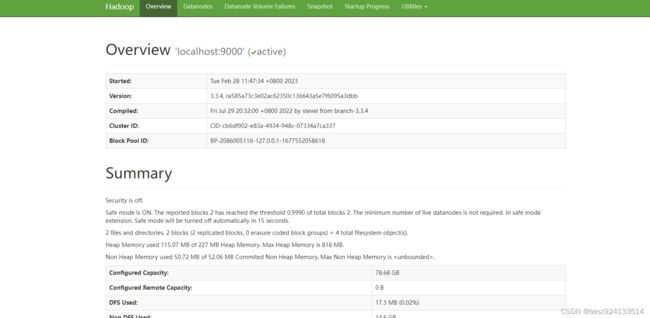
启动成功!!
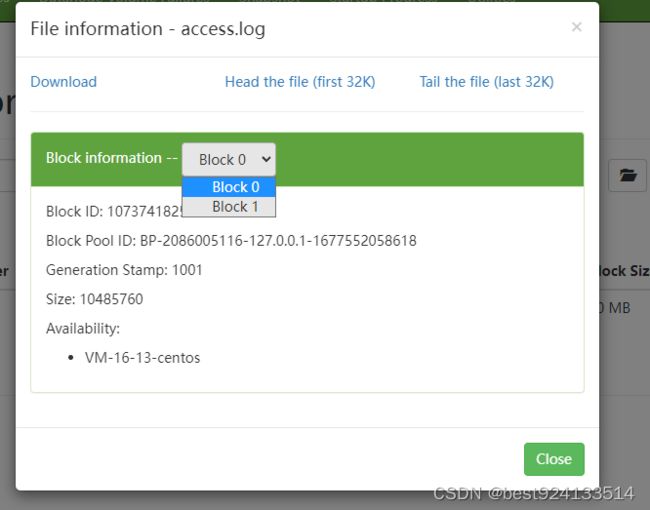
验证文件分块
bin/hdfs dfs -D dfs.blocksize=10485760 -D dfs.replication=1 -put access.log /
access.log为17M的文件
blocksize:分块大小,设置为10M
replication:副本数设置为1
查看上传后的文件
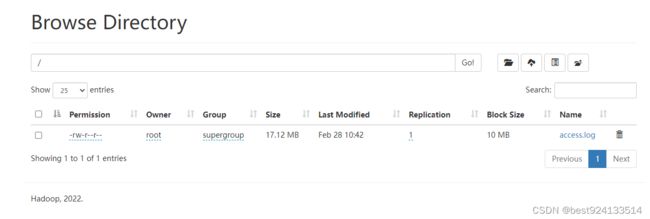
分了两个block
文档存放位置:/usr/local/hadoop/hadoopdata/dfs/data/current/BP-2086005116-127.0.0.1-1677552058618/current/finalized/subdir0/subdir0