客户端面试笔记
一、下自我介绍
二、说一下一次https的请求过程
- DNS解析得到IP地址
- 与服务器进行TCP连接
- 建立SSL会话
- 发送与收取数据
- TCP连接断开
HTTPS协议发生在端口443,HTTP发生在80
HTTPS协议 = HTTP协议 + SSL协议
HTTPS协议 = HTTP协议 + 认证 + 加密 + 完整性保护
HTTP1.0和HTTP1.1和HTTP2.0的区别
HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较为简单的网页上和网络请求上,而HTTP1.1则在1999年才开始广泛应用于现在的各大浏览器网络请求中,同时HTTP1.1也是当前使用最为广泛的HTTP协议。 主要区别主要体现在:
-
缓存处理,在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
-
带宽优化及网络连接的使用,HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
-
错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
-
Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
-
长连接,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。
HTTP1.1和HTTP2.0的区别
-
新的二进制格式(Binary Format),HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
-
多路复用(MultiPlexing),即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。
-
header压缩,如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
-
服务端推送(server push),同SPDY一样,HTTP2.0也具有server push功能。
HTTP 3.0 (QUIC)
QUIC (Quick UDP Internet Connections), 快速 UDP 互联网连接。
QUIC是基于UDP协议的。
两个主要特性:
(1)线头阻塞(HOL)问题的解决更为彻底:
基于TCP的HTTP/2,尽管从逻辑上来说,不同的流之间相互独立,不会相互影响,但在实际传输方面,数据还是要一帧一帧的发送和接收,一旦某一个流的数据有丢包,则同样会阻塞在它之后传输的流数据传输。而基于UDP的QUIC协议则可以更为彻底地解决这样的问题,让不同的流之间真正的实现相互独立传输,互不干扰。
(2)切换网络时的连接保持:
当前移动端的应用环境,用户的网络可能会经常切换,比如从办公室或家里出门,WiFi断开,网络切换为3G或4G。基于TCP的协议,由于切换网络之后,IP会改变,因而之前的连接不可能继续保持。而基于UDP的QUIC协议,则可以内建与TCP中不同的连接标识方法,从而在网络完成切换之后,恢复之前与服务器的连接。
http请求头
1) accept
表示当前浏览器可以接受的文件类型,假设这里有 image/webp,表示当前浏览器可以支持 webp 格式的图片,那么当服务器给当前浏览器下发 webp 的图片时,可以更省流量。
2) accept-encoding
表示当前浏览器可以接受的数据编码,如果服务器吐出的数据不是浏览器可接受的编码,就会产生乱码。
3) accept-language
表示当前使用的浏览语言。
4) Cookie
很多和用户相关的信息都存在 Cookie 里,用户在向服务器发送请求数据时会带上。例如,用户在一个网站上登录了一次之后,下次访问时就不用再登录了,就是因为登录成功的 token 放在了 Cookie 中,而且随着每次请求发送给服务器,服务器就知道当前用户已登录。
5) user-agent
表示浏览器的版本信息。当服务器收到浏览器的这个请求后,会经过一系列处理,返回一个数据包给浏览器,而响应头里就会描述这个数据包的基本信息。
- 200 - 请求成功
- 301 - 资源(网页等)被永久转移到其它URL
- 404 - 请求的资源(网页等)不存在
- 500 - 内部服务器错误
2、DNS解析
访问目标地址的方式:
- 使用目标IP,这个时候是不需要使用DNS解析的
- 使用域名,需要使用DNS解析为IP
DNS解析使用的是UDP协议,端口53
3、SSL会话建立
三、设计模式了解吗?手写一个懒汉式的单例 为什么加volatile 还了解其他的设计模式吗 说一下
1. 软件设计模式的概念
软件设计模式(Software Design Pattern),又称设计模式,是一套被反复使用、多数人知晓的、经过分类编目的、代码设计经验的总结。它描述了在软件设计过程中的一些不断重复发生的问题,以及该问题的解决方案。也就是说,它是解决特定问题的一系列套路,是前辈们的代码设计经验的总结,具有一定的普遍性,可以反复使用。其目的是为了提高代码的可重用性、代码的可读性和代码的可靠性。
2. 学习设计模式的意义
设计模式的本质是面向对象设计原则的实际运用,是对类的封装性、继承性和多态性以及类的关联关系和组合关系的充分理解。正确使用设计模式具有以下优点。
- 可以提高程序员的思维能力、编程能力和设计能力。
- 使程序设计更加标准化、代码编制更加工程化,使软件开发效率大大提高,从而缩短软件的开发周期。
- 使设计的代码可重用性高、可读性强、可靠性高、灵活性好、可维护性强。
3、软件设计模式的基本要素
1. 模式名称
每一个模式都有自己的名字,通常用一两个词来描述,可以根据模式的问题、特点、解决方案、功能和效果来命名。模式名称(PatternName)有助于我们理解和记忆该模式,也方便我们来讨论自己的设计。
2. 问题
问题(Problem)描述了该模式的应用环境,即何时使用该模式。它解释了设计问题和问题存在的前因后果,以及必须满足的一系列先决条件。
3. 解决方案
模式问题的解决方案(Solution)包括设计的组成成分、它们之间的相互关系及各自的职责和协作方式。因为模式就像一个模板,可应用于多种不同场合,所以解决方案并不描述一个特定而具体的设计或实现,而是提供设计问题的抽象描述和怎样用一个具有一般意义的元素组合(类或对象的 组合)来解决这个问题。
4. 效果
描述了模式的应用效果以及使用该模式应该权衡的问题,即模式的优缺点。主要是对时间和空间的衡量,以及该模式对系统的灵活性、扩充性、可移植性的影响,也考虑其实现问题。显式地列出这些效果(Consequence)对理解和评价这些模式有很大的帮助。
GoF的23种设计模式的功能
根据模式是用来完成什么工作来划分,这种方式可分为创建型模式、结构型模式和行为型模式 3 种。
- 创建型模式:用于描述“怎样创建对象”,它的主要特点是“将对象的创建与使用分离”。GoF 中提供了单例、原型、工厂方法、抽象工厂、建造者等 5 种创建型模式。
- 结构型模式:用于描述如何将类或对象按某种布局组成更大的结构,GoF 中提供了代理、适配器、桥接、装饰、外观、享元、组合等 7 种结构型模式。
- 行为型模式:用于描述类或对象之间怎样相互协作共同完成单个对象都无法单独完成的任务,以及怎样分配职责。GoF 中提供了模板方法、策略、命令、职责链、状态、观察者、中介者、迭代器、访问者、备忘录、解释器等 11 种行为型模式。
前面说明了 GoF 的 23 种设计模式的分类,现在对各个模式的功能进行介绍。
- 单例(Singleton)模式:某个类只能生成一个实例,该类提供了一个全局访问点供外部获取该实例,其拓展是有限多例模式。
- 原型(Prototype)模式:将一个对象作为原型,通过对其进行复制而克隆出多个和原型类似的新实例。
- 工厂方法(Factory Method)模式:定义一个用于创建产品的接口,由子类决定生产什么产品。
- 抽象工厂(AbstractFactory)模式:提供一个创建产品族的接口,其每个子类可以生产一系列相关的产品。
- 建造者(Builder)模式:将一个复杂对象分解成多个相对简单的部分,然后根据不同需要分别创建它们,最后构建成该复杂对象。
- 代理(Proxy)模式:为某对象提供一种代理以控制对该对象的访问。即客户端通过代理间接地访问该对象,从而限制、增强或修改该对象的一些特性。
- 适配器(Adapter)模式:将一个类的接口转换成客户希望的另外一个接口,使得原本由于接口不兼容而不能一起工作的那些类能一起工作。
- 桥接(Bridge)模式:将抽象与实现分离,使它们可以独立变化。它是用组合关系代替继承关系来实现,从而降低了抽象和实现这两个可变维度的耦合度。
- 装饰(Decorator)模式:动态的给对象增加一些职责,即增加其额外的功能。
- 外观(Facade)模式:为多个复杂的子系统提供一个一致的接口,使这些子系统更加容易被访问。
- 享元(Flyweight)模式:运用共享技术来有效地支持大量细粒度对象的复用。
- 组合(Composite)模式:将对象组合成树状层次结构,使用户对单个对象和组合对象具有一致的访问性。
- 模板方法(TemplateMethod)模式:定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该算法结构的情况下重定义该算法的某些特定步骤。
- 策略(Strategy)模式:定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,且算法的改变不会影响使用算法的客户。
- 命令(Command)模式:将一个请求封装为一个对象,使发出请求的责任和执行请求的责任分割开。
- 职责链(Chain of Responsibility)模式:把请求从链中的一个对象传到下一个对象,直到请求被响应为止。通过这种方式去除对象之间的耦合。
- 状态(State)模式:允许一个对象在其内部状态发生改变时改变其行为能力。
- 观察者(Observer)模式:多个对象间存在一对多关系,当一个对象发生改变时,把这种改变通知给其他多个对象,从而影响其他对象的行为。
- 中介者(Mediator)模式:定义一个中介对象来简化原有对象之间的交互关系,降低系统中对象间的耦合度,使原有对象之间不必相互了解。
- 迭代器(Iterator)模式:提供一种方法来顺序访问聚合对象中的一系列数据,而不暴露聚合对象的内部表示。
- 访问者(Visitor)模式:在不改变集合元素的前提下,为一个集合中的每个元素提供多种访问方式,即每个元素有多个访问者对象访问。
- 备忘录(Memento)模式:在不破坏封装性的前提下,获取并保存一个对象的内部状态,以便以后恢复它。
- 解释器(Interpreter)模式:提供如何定义语言的文法,以及对语言句子的解释方法,即解释器。
2. 单例模式的实现
Singleton 模式通常有两种实现形式。
第 1 种:懒汉式单例
该模式的特点是类加载时没有生成单例,只有当第一次调用 getlnstance 方法时才去创建这个单例。代码如下:
class Singleton{
private static volatile Singleton singleton;//第二层锁,volatile关键字,保证了不同线程对于这个变量进行操作时的可见性,禁止指令重排
private Singleton(){
}
public static Singleton getInstance(){
if(singleton==null){//第一层检查,检查是否有引用指向对象,高并发情况下会有多个线程同时进入
synchronized (Singleton.class){//第一层锁,保证只有一个线程进入
//双重检查,防止多个线程同时进入第一层检查(因单例模式只允许存在一个对象,故在创建对象之前无引用指向对象,所有线程均可进入第一层检查)
//当某一线程获得锁创建一个Singleton对象时,即已有引用指向对象,singleton不为空,从而保证只会创建一个对象
//假设没有第二层检查,那么第一个线程创建完对象释放锁后,后面进入对象也会创建对象,会产生多个对象
if(singleton==null){//第二层检查
//volatile关键字作用为禁止指令重排,保证返回Singleton对象一定在创建对象后
singleton=new Singleton();
//singleton=new Singleton语句为非原子性,实际上会执行以下内容:
//(1)在堆上开辟空间;(2)属性初始化;(3)引用指向对象
//假设以上三个内容为三条单独指令,因指令重排可能会导致执行顺序为1->3->2(正常为1->2->3),当单例模式中存在普通变量需要在构造方法中进行初始化操作时,单线程情况下,顺序重排没有影响;但在多线程情况下,假如线程1执行singleton=new Singleton()语句时先1再3,由于系统调度线程2的原因没来得及执行步骤2,但此时已有引用指向对象也就是singleton!=null,故线程2在第一次检查时不满足条件直接返回singleton,此时singleton为null(即str值为null)
//volatile关键字可保证singleton=new Singleton()语句执行顺序为123,因其为非原子性依旧可能存在系统调度问题(即执行步骤时被打断),但能确保的是只要singleton!=0,就表明一定执行了属性初始化操作;而若在步骤3之前被打断,此时singleton依旧为null,其他线程可进入第一层检查向下执行创建对象
}
}
}
return singleton;
}
}
public class ThreadTest{
public static void main(String[] args) {
Singleton singleton=Singleton.getInstance();
System.out.println(singleton);
}
}
注意:如果编写的是多线程程序,则不要删除上例代码中的关键字 volatile 和 synchronized,否则将存在线程非安全的问题。如果不删除这两个关键字就能保证线程安全,但是每次访问时都要同步,会影响性能,且消耗更多的资源,这是懒汉式单例的缺点。
第 2 种:饿汉式单例
该模式的特点是类一旦加载就创建一个单例,保证在调用 getInstance 方法之前单例已经存在了。
public class HungrySingleton {
private static final HungrySingleton instance = new HungrySingleton();
private HungrySingleton() {
}
public static HungrySingleton getInstance() {
return instance;
}
}四、 进程和线程区别说一下
进程(Process) 是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。
线程(thread) 是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。
1.进程要分配一大部分的内存,而线程只需要分配一部分栈就可以了.
2.一个程序至少有一个进程,一个进程至少有一个线程.
3.进程是资源分配的最小单位,线程是程序执行的最小单位。
4.一个线程可以创建和撤销另一个线程,同一个进程中的多个线程之间可以并发执行.
threadlocal
是一个线程内部的存储类,可以在指定线程内存储数据,数据存储以后,只有指定线程可以得到存储数据。
五、线程间切换怎么做
进程:
在中断描述符表(IDT)中,除中断门、陷阱门和调用门外,还有一种“任务们”。任务门中包含有TSS段的选择符。当CPU因中断而穿过一个任务门时,就会将任务门中的段选择符自动装入TR寄存器,使指向新的TSS,并完成任务切换。CPU可以通过JMP或CALL指令实现任务切换,当跳转或调用的目标段(代码段)实际上指向GDT表中的一个TSS描述符项时,就会引起一次任务切换.
进程调度算法的优缺点
1、时间片轮转调度算法(RR):给每个进程固定的执行时间,根据进程到达的先后顺序让进程在单位时间片内执行,执行完成后便调度下一个进程执行,时间片轮转调度不考虑进程等待时间和执行时间,属于抢占式调度。优点是兼顾长短作业;缺点是平均等待时间较长,上下文切换较费时。适用于分时系统。
2、先来先服务调度算法(FCFS):根据进程到达的先后顺序执行进程,不考虑等待时间和执行时间,会产生饥饿现象。属于非抢占式调度,优点是公平,实现简单;缺点是不利于短作业。
3、优先级调度算法(HPF):在进程等待队列中选择优先级最高的来执行。常被用于批处理系统中,还可用于实时系统中。
4、多级反馈队列调度算法:将时间片轮转与优先级调度相结合,把进程按优先级分成不同的队列,先按优先级调度,优先级相同的,按时间片轮转。优点是兼顾长短作业,有较好的响应时间,可行性强,适用于各种作业环境。
5、高响应比优先调度算法:根据“响应比=(进程执行时间+进程等待时间)/ 进程执行时间”这个公式得到的响应比来进行调度。高响应比优先算法在等待时间相同的情况下,作业执行的时间越短,响应比越高,满足段任务优先,同时响应比会随着等待时间增加而变大,优先级会提高,能够避免饥饿现象。优点是兼顾长短作业,缺点是计算响应比开销大,适用于批处理系统。
线程:
1.时间片:时钟中断处理例程从PCR中取得当前线程对象指针并更新线程时间,如果超出了时间片,则将当前线程从放入ready列表中,然后从standby列表中取出最高优先级的线程,然后保存当前线程上下文数据,并转到新的线程上下文.
2.主动等待:线程调用等待函数,则将当前线程放到wait列表中,然后从standby列表中取一个线程,切换上下文,当主动等待的事件完成时,线程被调度到ready列表中等待再次被调度运行.
3.抢先:时钟中断发现standby列表中有比当前线程更高的线程,则挂起当前线程,切换线程上下文,运行最需要运行的线程.
所以,线程间切换就是"线程挂起自己,让出CPU"
public enum State {
//线程刚创建
NEW,
//在JVM中正在运行的线程
RUNNABLE,
//线程处于阻塞状态,等待监视锁,可以重新进行同步代码块中执行
BLOCKED,
//等待状态
WAITING,
//调用sleep() join() wait()方法可能导致线程处于等待状态
TIMED_WAITING,
//线程执行完毕,已经退出
TERMINATED;
}指令重排,就是为了尽量少的中断流水线。
注意:指令重排可以保证串行语义一致,但是没有义务保证多进程间的语义也一致。
哪些指令不能重排:Happen-Before规则
1)程序顺序原则:一个线程内保证语义的串行性
2)volatile规则:volatile变量的写,先发生于读,这保证了volatile变量的可见性
3)锁规则:解锁(unlock)必然发生在随后的加锁(lock)前
4)传递性:A先于B,B先于C,那么A必然先于C
5)线程的start()方法先于它的每一个动作
6)线程的所有操作先于线程的终结(Thread.join())
7)线程的中断(interrupt())先于被中断线程的代码
8)对象的构造函数执行、结束先于finalize()方法
六、写一个例子跑一个线程出来
Handler myHandler = new Handler() {
public void handleMessage(Message msg) {
updateUIHere();
}
}
new Thread() {
public void run() {
doStuff(); // 执行耗时操作
Message msg = myHandler.obtainMessage();
Bundle bundle = new Bundle();
bundle.putString("key", "value");
msg.setData(bundle); // 向消息中添加数据
myHandler.sendMessage(msg); // 向Handler发送消息,更新UI
}
}.start();哈希表(Hash Table)
散列表,又叫哈希表(Hash Table),是能够通过给定的关键字的值直接访问到具体对应的值的一个数据结构。也就是说,把关键字映射到一个表中的位置来直接访问记录,以加快访问速度。
冲突的处理方式也有很多,下面介绍几种。
- 开放地址法(也叫开放寻址法):实际上就是当需要存储值时,对Key哈希之后,发现这个地址已经有值了,这时该怎么办?不能放在这个地址,不然之前的映射会被覆盖。这时对计算出来的地址进行一个探测再哈希,比如往后移动一个地址,如果没人占用,就用这个地址。如果超过最大长度,则可以对总长度取余。这里移动的地址是产生冲突时的增列序量。
- 再哈希法:在产生冲突之后,使用关键字的其他部分继续计算地址,如果还是有冲突,则继续使用其他部分再计算地址。这种方式的缺点是时间增加了。
- 链地址法:链地址法其实就是对Key通过哈希之后落在同一个地址上的值,做一个链表。其实在很多高级语言的实现当中,也是使用这种方式处理冲突的,我们会在后面着重学习这种方式。
- 建立一个公共溢出区:这种方式是建立一个公共溢出区,当地址存在冲突时,把新的地址放在公共溢出区里。
八、linkedhashmap底层了解吗
https://www.cnblogs.com/baolingye/p/11667717.html
HashMap的数据结构:数组+链表+红黑树;Java7中的HashMap只由数组+链表构成;Java8引入了红黑树,提高了HashMap的性能;
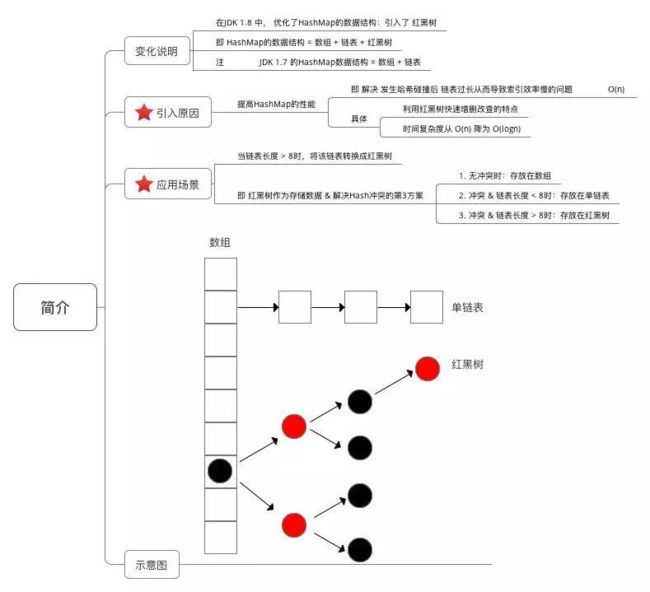
下面简单说一下存储过程:
1.接受传入的参数,通过key计算hash值,得到数组下标位置;未发生hash碰撞,直接插入结束;发生hash碰撞,走第2步;
2.判断当前数据节点是红黑树还是链表,如果是链表,将数据放入链表头节点(在Java 8之前是将Entry插入到链表头部,在Java 8开始是插入链表尾部(Java 8用Node对象替代了Entry对象)),原数据往后移;如果是红黑树,走第3步;
3.直接在红黑树插入数据结束;
扩容机制
如果node1下面没有其他节点,那么直接用"hash&tab.length-1"来定位node1的新位置即可。如果node1下有节点,那么需要遍历这个链表,逐个确定节点的新位置。(与运算代替取模)
线程安全的HashMap替代方案
HashTable
和HashMap原理相同,但是是线程安全的,与HashMap的最大区别是HashMap的Key和Value可以为null,但是HashTable的Key和Value都不能为null。
但是HashTable是遗留类,最好不要使用。
ConcurrentHashMap
并发包下的类,采用了分段锁,是线程安全的,每个分段锁维护着几个桶,多个线程可以同时访问不同分段锁上的桶,使并发度更高。默认并发级别为16。
Collections.synchronizeMap()
使用Collections.synchronizeMap(map) 方法可以返回一个线程安全的Map。
LinkedHashMap 继承自 HashMap,在 HashMap 基础上,通过维护一条双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题。除此之外,LinkedHashMap 对访问顺序也提供了相关支持。在一些场景下,该特性很有用,比如缓存。在实现上,LinkedHashMap 很多方法直接继承自 HashMap,仅为维护双向链表覆写了部分方法。
九、DNS解析了解吗?说一下细节
DNS( Domain Name System)是“域名系统”的英文缩写,是一种组织成域层次结构的计算机和网络服务命名系统,它用于TCP/IP网络,它所提供的服务是用来将主机名和域名转换为IP地址的工作。
DNS服务器一般分三种,根DNS服务器,顶级DNS服务器,权威DNS服务器。
①用户主机上运行着DNS的客户端,就是我们的PC机或者手机客户端运行着DNS客户端了
②浏览器将接收到的url中抽取出域名字段,就是访问的主机名,比如
http://www.baidu.com/
, 并将这个主机名传送给DNS应用的客户端
③DNS客户机端向DNS服务器端发送一份查询报文,报文中包含着要访问的主机名字段(中间包括一些列缓存查询以及分布式DNS集群的工作)
④该DNS客户机最终会收到一份回答报文,其中包含有该主机名对应的IP地址
⑤一旦该浏览器收到来自DNS的IP地址,就可以向该IP地址定位的HTTP服务器发起TCP连接
十、线程池了解吗?说一下 你说漏了一个
handler的拒绝策略:
有四种:第一种AbortPolicy:不执行新任务,直接抛出异常,提示线程池已满
第二种DisCardPolicy:不执行新任务,也不抛出异常
第三种DisCardOldSetPolicy:将消息队列中的第一个任务替换为当前新进来的任务执行
第四种CallerRunsPolicy:直接调用execute来执行当前任务
四种常见的线程池:
CachedThreadPool:可缓存的线程池,该线程池中没有核心线程,非核心线程的数量为Integer.max_value,就是无限大,当有需要时创建线程来执行任务,没有需要时回收线程,适用于耗时少,任务量大的情况。
SecudleThreadPool:周期性执行任务的线程池,按照某种特定的计划执行线程中的任务,有核心线程,但也有非核心线程,非核心线程的大小也为无限大。适用于执行周期性的任务。
SingleThreadPool:只有一条线程来执行任务,适用于有顺序的任务的应用场景。
FixedThreadPool:定长的线程池,有核心线程,核心线程的即为最大的线程数量,没有非核心线程
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
十一、JVM内存模型了解吗?简单说一下
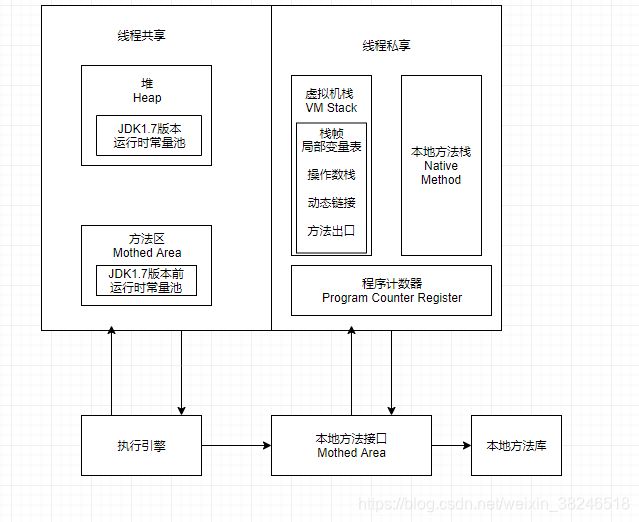
方法区:
各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。主要目的是为了与堆(Heap)区分开来,方便GC(垃圾收集器)。
运行时常量池:
是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有常量池信息(用于存放编译期生成的各种字面量和符号引用)
JDK1.7版本及其以后, JVM 已经将运行时常量池从方法区中移了出来,在 Java 堆(Heap)中开辟了一块区域存放运行时常量池。
字面量:
字符串(final类);final修饰常量值;基本数据类型;其他
符号引用:
类和结构的完全限定名(访问限定修饰符);字段名称和描述符;方法名称与描述符。
十二、 方法区里面可以做垃圾回收吗
方法区和堆一样,都是线程共享的内存区域,被用于存储已被虚拟机加载的类信息、即时编译后的代码、静态变量和常量等数据。
根据Java虚拟机规范的规定,方法区无法满足内存分配需求时,也会抛出OutOfMemoryError异常,虽然规范规定虚拟机可以不实现垃圾收集,因为和堆的垃圾回收效率相比,方法区的回收效率实在太低,但是此部分内存区域也是可以被回收的。
方法区的垃圾回收主要有两种,分别是对废弃常量的回收和对无用类的回收。
当一个常量对象不再任何地方被引用的时候,则被标记为废弃常量,这个常量可以被回收。
方法区中的类需要同时满足以下三个条件才能被标记为无用的类:
1.Java堆中不存在该类的任何实例对象;
2.加载该类的类加载器已经被回收;
3.该类对应的java.lang.Class对象不在任何地方被引用,且无法在任何地方通过反射访问该类的方法。
当满足上述三个条件的类才可以被回收,但是并不是一定会被回收,需要参数进行控制,例如HotSpot虚拟机提供了-Xnoclassgc参数进行控制是否回收。
十三、线程栈里面可以回收垃圾吗
十四、说一下强引用 弱引用 虚引用 软引用 (https://blog.csdn.net/baidu_22254181/article/details/82555485)
Java执行GC判断对象是否存活有两种方式其中一种是引用计数。
引用计数:Java堆中每一个对象都有一个引用计数属性,引用每新增1次计数加1,引用每释放1次计数减1。
在JDK 1.2以前的版本中,若一个对象不被任何变量引用,那么程序就无法再使用这个对象。也就是说,只有对象处于(reachable)可达状态,程序才能使用它。
从JDK 1.2版本开始,对象的引用被划分为4种级别,从而使程序能更加灵活地控制对象的生命周期。这4种级别由高到低依次为:强引用、软引用、弱引用和虚引用。
(一) 强引用(StrongReference)
强引用是使用最普遍的引用。如果一个对象具有强引用,那垃圾回收器绝不会回收它。
(二) 软引用(SoftReference)
如果一个对象只具有软引用,则内存空间充足时,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。
(三) 弱引用(WeakReference)
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
(四) 虚引用(PhantomReference)
虚引用顾名思义,就是形同虚设。与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。能在这个对象被收集器回收时收到一个系统通知。
-
重要对象回收监听 进行日志统计
-
系统gc监听 因为虚引用每次GC都会被回收,那么我们就可以通过虚引用来判断gc的频率,如果频率过大,内存使用可能存在问题,才导致了系统gc频繁调用
字节流和字符流的区别:
每次读写的字节数不同;
字符流是块读写,字节流是字节读写;
字符流带有缓存,字节流没有。
java流在处理上分为字符流和字节流。字符流处理的单元为2个字节的Unicode字符,分别操作字符、字符数组或字符串,而字节流处理单元为1个字节,操作字节和字节数组。
字符流和字节流,一个属性范围小,一个属性范围大,字符流只能是字符这一种类型,但是字节流中可以是字符,可以是二进制文件,可以是音频,可以是各种各样的类型,只要符合字节形式存储的都可以接字节流,而字符流只能接字符。
TCP 和 UDP 的区别
- TCP 是面向连接的,UDP 是面向无连接的
- UDP程序结构较简单
- TCP 是面向字节流的,UDP 是基于数据报的
- TCP 保证数据正确性,UDP 可能丢包
- TCP 保证数据顺序,UDP 不保证
TCP建立连接和释放连接过程
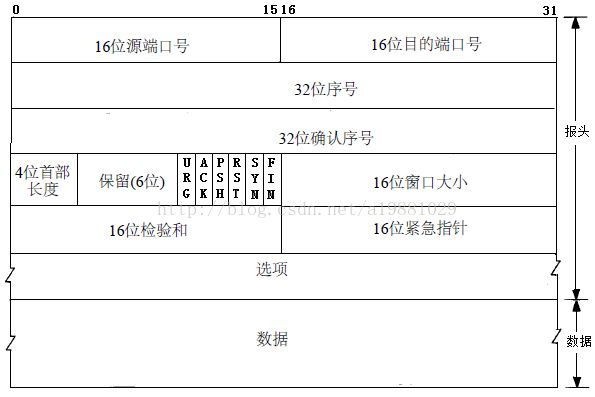
TCP(Transmission Control Protocol 传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议。TCP建立连接需要三次握手,释放连接需要四次握手。
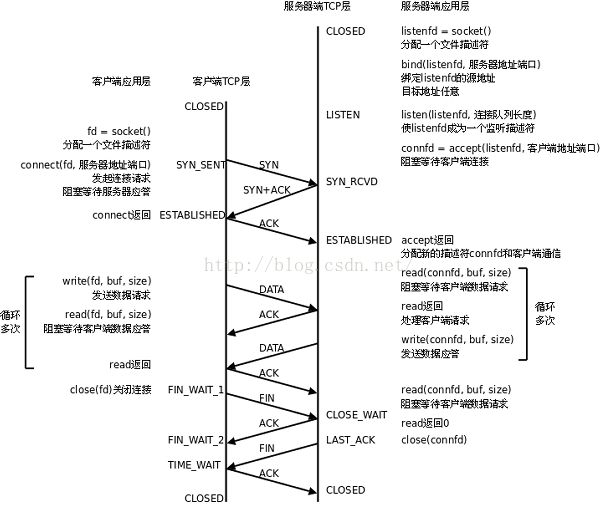
TCP连接过程:
(1) 服务端通过socket,bind和listen准备好接受外来的连接,此时服务端状态为Listen
(2)客户端通过调用connect来发起主动连接,导致客户端TCP发送一个SYN(同步)字节,告诉服务器客户将在(待建立的)连接中发送的数据的初始序列号,客户端状态为SYN_SENT。
(3)服务器确认(ACK)客户的SYN,并自己也发送一个SYN,它包含服务器将在同一连接中发送数据的初始序列号。
(4)客户端确认服务的ACK和SYN,向服务器发送ACK,客户端状态ESTABLISHED
(5)服务器接收ACK,服务器状态ESABLISHED。
TCP连接中止过程:
(1)某端首先调用close,成为主动关闭端,向另一端发送FIN分节,表示数据发送完毕,此时主动关闭端状态FIN_WAIT_1;
(2)接收到FIN的是被动关闭端,FIN由TCP确认,先向主动关闭端发送ACK,作为一个文件结束符传递给接收端应用进程(放在已排队等候该应用进程接收到的任何其他数据之后),因为FIN的接收意味着接收端应用进程在相应连接无额外数据可接收,接收端状态CLOSE_WAIT;主动关闭端接收到ACK状态变为FIN_WAIT_2;
(3)一段时间后,接收端接收到这个文件结束符的应用进程调用close关闭套接字,向主动关闭端发送FIN,接收端状态为LAST_ACK;
(4)主动关闭端确认FIN,状态变为TIME_WAIT,并向接收端发送ACK,接收端接收到ACK关闭TCP,而主动关闭端一段时间后也关闭TCP;
ACK:这里出现的ACK即为上面所说的TCP报文段首部中的“ACK字段”,置1时该报文段为确认报文段。
ack:而ack则为TCP报文段首部中“确认号字段”的具体数值。ack=x+1说明B希望A下次发来的报文段的第一个数据字节为序号=x+1的字节;ack=y+1说明A希望B下次发来的报文段的第一个数据字节为序号=y+1的字节。
2. 为什么需要TIME_WAIT状态?
假设最后的ACK丢失,server将重发FIN,client必须维护TCP状态信息以便可以重发最后的ACK,否则将会发送RST,结果server认为发生错误。TCP实现必须可靠地终止连接的两个方向,所以client必须进入TIME_WAIT状态。
此外,考虑一种情况,TCP实现可能面临着先后两个相同的五元组。如果前一个连接处于TIME_WAIT状态,而允许另一个拥有相同五元组连接出现,可能处理TCP报文时,两个连接互相干扰。所以使用SO_REUSEADDR选项就需要考虑这种情况。
3. 什么是2MSL
MSL是Maximum Segment Lifetime,译为“报文最大生存时间”,他是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
因为TCP报文(segment)是IP数据报(datagram)的数据部分,而IP头中有一个TTL域,TTL是time to live的缩写,中文可以译为“生存时间”,这个生存时间是由源主机设置初始值但不是存的具体时间,而是存储了一个IP数据报可以经过的最大路由数,每经过一个处理他的路由器此值就减1,当此值为0则数据报将被丢弃,同时发送ICMP报文通知源主机。
TCP的四种拥塞控制算法
1.慢开始
2.拥塞避免
3.快重传
4.快恢复
流量控制:如果发送方把数据发送得过快,接收方可能会来不及接收,这就会造成数据的丢失。
TCP的流量控制是利用滑动窗口机制实现的,接收方在返回的数据中会包含自己的接收窗口的大小,以控制发送方的数据发送。
拥塞控制:拥塞控制就是防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。
TCP粘包
什么是TCP粘包问题?
TCP粘包就是指发送方发送的若干包数据到达接收方时粘成了一包,从接收缓冲区来看,后一包数据的头紧接着前一包数据的尾,出现粘包的原因是多方面的,可能是来自发送方,也可能是来自接收方。
造成TCP粘包的原因
(1)发送方原因
TCP默认使用Nagle算法(主要作用:减少网络中报文段的数量),而Nagle算法主要做两件事:
只有上一个分组得到确认,才会发送下一个分组
收集多个小分组,在一个确认到来时一起发送
Nagle算法造成了发送方可能会出现粘包问题
(2)接收方原因
TCP接收到数据包时,并不会马上交到应用层进行处理,或者说应用层并不会立即处理。实际上,TCP将接收到的数据包保存在接收缓存里,然后应用程序主动从缓存读取收到的分组。这样一来,如果TCP接收数据包到缓存的速度大于应用程序从缓存中读取数据包的速度,多个包就会被缓存,应用程序就有可能读取到多个首尾相接粘到一起的包。
什么是 TCP 半连接队列和全连接队列?
在 TCP 三次握手的时候,Linux 内核会维护两个队列,分别是:
-
半连接队列,也称 SYN 队列;
-
全连接队列,也称 accepet 队列;
服务端收到客户端发起的 SYN 请求后,内核会把该连接存储到半连接队列,并向客户端响应 SYN+ACK,接着客户端会返回 ACK,服务端收到第三次握手的 ACK 后,内核会把连接从半连接队列移除,然后创建新的完全的连接,并将其添加到 accept 队列,等待进程调用 accept 函数时把连接取出来。
www.baidu.com访问过程
1.域名解析成IP
每个主机在网络中都是IP为标识的,IP才是主机在网络中的位置,域名只是为了方便用户记忆而已,这就要求浏览器能够识别域名并且将其转化为对应的IP地址。
所以浏览器会有一个DNS缓存,其中记录了一些域名与IP的对应关系,供浏览器快速查找需要的IP。但是这个DNS缓存不可能存下所有的域名-IP地址,何况IP地址有时候还会变化,因此当在浏览器DNS缓存中没有找到的时候,就要先向DNS服务器请求域名解析,DNS域名解析时用的是UDP协议。
①客户端从浏览器中输入www.baidu.com网站网址后回车,首先浏览器会查询浏览器本身的DNS缓存,一般只有几分钟的缓存,找到了就返回域名对应的IP;如果找不到,系统就会查询本地hosts文件和本地DNS缓存信息,如果找到了,就返回域名对应IP;
②如果没有找到对应的域名解析记录,那么那么系统会把浏览器的解析请求,交给客户端本地设置的DNS服务器地址解析(称为Local DNS,LDNS),如果LDNS服务的本地缓存有对应的解析记录,就会直接返回IP地址;
③如果没有,LDNS会负责继续请求其他DNS服务器;此时就是外网的DNS服务器了,先是根域名服务器,根据浏览器得到的域名,根域名服务器看到.com,会返回.com的顶级域名服务器的ip给LDNS;然后LDNS通过顶级域名服务器的ip,找到了顶级域名服务器,.com顶级域名服务器看到了是找baidu.com一级域名服务器,就将其服务器的ip返回给LDNS;然后一层一层往下找,直到找到了www.baidu.com的DNS记录,并得到对应的IP地址,这时候LDNS会把找到的www.baidu.com的ip发送给客户端浏览器,并记录在缓存中,以便未来再次访问。
④客户端浏览器收到ip之后,就可以通过ip地址找到对应的web服务器了,即服务端主机;接下来就是三次握手建立连接了
2.与目的主机进行TCP连接(三次握手)
得到域名对应的ip地址后,也就表示可以将数据送达到目的主机了,即可以向服务器发送http请求了,但是http是应用层协议,tcp是传输层,所以发送http请求之前,开始我们常说的三次握手。Http请求是使用TCP进行传输的,可以保证可靠传输,并且有序,需要建立连接,才能进行数据传输。
①向目的主机发送TCP连接请求报文
②该TCP报文中SYN标志位为1,产生一个随机数j,表示连接请求
③该TCP报文通过获取的ip(DNS)找到服务器主机,然后获得MAC地址(ARP),通过网关,最终到达目的主机。
④目的主机收到数据帧后,通过ip协议传输帧,再到TCP协议,封装成请求应答报文;
⑤该报文中SYN标志为1,产生一个随机数k,ack标志位j+1,表示连接请求应答
⑥该请求应答报文通过接收到的源ip-》Mac(arp)-》网关,发送到我的主机;
⑦我的主机收到数据帧,通过ip协议传输帧,再到TCP协议,封装成请求确认报文
⑧该请求确认报文通过目标ip-》Mac(arp)-》网关,发送到目的主机
⑨请求确认报文的ack为k +1,表示请求确认;
⑩目的主机接收到数据帧,连接建立完成
3.发送和接收数据
建立连接之后,就可以发送数据了,即发送http请求
知道get/put/delete/post么?
1、GET请求会向数据库发索取数据的请求,从而来获取信息,该请求就像数据库的select操作一样,只是用来查询一下数据,不会修改、增加数据,不会影响资源的内容,即该请求不会产生副作用。无论进行多少次操作,结果都是一样的。
2、与GET不同的是,PUT请求是向服务器端发送数据的,从而改变信息,该请求就像数据库的update操作一样,用来修改数据的内容,但是不会增加数据的种类等,也就是说无论进行多少次PUT操作,其结果并没有不同。
3、POST请求同PUT请求类似,都是向服务器端发送数据的,但是该请求会改变数据的种类等资源,就像数据库的insert操作一样,会创建新的内容。几乎目前所有的提交操作都是用POST请求的。
4、DELETE请求顾名思义,就是用来删除某一个资源的,该请求就像数据库的delete操作。
就像前面所讲的一样,既然PUT和POST操作都是向服务器端发送数据的,那么两者有什么区别呢。。。POST主要作用在一个集合资源之上的(url),而PUT主要作用在一个具体资源之上的(url/xxx),通俗一下讲就是,如URL可以在客户端确定,那么可使用PUT,否则用POST。
cookies和session区别 存储的内容有何不同?
(1)、cookie数据存放在客户的浏览器上,session数据放在服务器上 ;
(2)、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,如果主要考虑到安全应当使用session ;
(3)、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,如果主要考虑到减轻服务器性能方面,应当使用COOKIE ;
(4)、单个cookie在客户端的限制是3K,就是说一个站点在客户端存放的COOKIE不能3K;
(5)、所以将登陆信息等重要信息存放为SESSION;其他信息如果需要保留,可以放在COOKIE中。
服务器只能向客户端发送html文件么?css等文件又是怎么在客户端转换的呢
进程同步的方式:
a)管道(Pipe):即有名管道(named pipe):管道可用于具有亲缘关系进程间的通信,有名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信;
b)信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数);
c)Message(消息队列):消息队列是消息的链接表,包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。
d)共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
e)信号量(semaphore):主要作为进程间以及同一进程不同线程之间的同步手段。
f)套接口(Socket):更为一般的进程间通信机制,与其他通信机制不同的是,它可用于不同主机间的进程通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它类Unix系统上:Linux和System V的变种都支持套接字。
线程通信的方式
线程通信主要可以分为三种方式,分别为共享内存、消息传递和管道流。每种方式有不同的方法来实现
- 共享内存:线程之间共享程序的公共状态,线程之间通过读-写内存中的公共状态来隐式通信。
volatile共享内存
- 消息传递:线程之间没有公共的状态,线程之间必须通过明确的发送信息来显示的进行通信。
wait/notify等待通知方式
join方式
- 管道流
管道输入/输出流的形式
四、线程同步互斥的4种方式
1. 临界区(Critical Section):适合一个进程内的多线程访问公共区域或代码段时使用
2. 互斥量 (Mutex):适合不同进程内多线程访问公共区域或代码段时使用,与临界区相似。
3. 信号量(Semaphore):与临界区和互斥量不同,可以实现多个线程同时访问公共区域数据,原理与操作系统中PV操作类似,先设置一个访问公共区域的线程最大连接数,每有一个线程访问共享区资源数就减一,直到资源数小于等于零。
4. 事件(Event):通过线程间触发事件实现同步互斥
如果一组进程中的每一个进程都在等待仅由该组进程中的其他进程才能引发的事件,那么该组进程是死锁的(Deadlock)。
产生死锁的必要条件:
互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
不可剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
环路等待条件:在发生死锁时,必然存在一个进程--资源的环形链。
内存管理:页表查询,
1.MMU/TLB/Cache概述
MMU:完成的工作就是虚拟地址到物理地址的转换,可以让系统中的多个程序跑在自己独立的虚拟地址空间中,相互不会影响。程序可以对底层的物理内存一无所知,物理地址可以是不连续的,但是不妨碍映射连续的虚拟地址空间。
TLB:MMU工作的过程就是查询页表的过程,页表放置在内存中时查询开销太大,因此专门有一小片访问更快的区域用于存放地址转换条目,用于提高查找效率。当页表内容有变化的时候,需要清除TLB,以防止地址映射出错。
Cache:处理器和存储器之间的缓存机制,用于提高访问速率,在ARMv8上会存在多级Cache,其中L1 Cache分为指令Cache和数据Cache,在CPU Core的内部,支持虚拟地址寻址;L2 Cache容量更大,同时存储指令和数据,为多个CPU Core共用,这多个CPU Core也就组成了一个Cluster。
分页和分段式内存管理有什么区别
1、页是信息的物理单位,分页是为实现离散分配方式,以消减内存的外零头,提高内存的利用率;或者说,分页仅仅是由于系统管理的需要,而不是用户的需要。段是信息的逻辑单位,它含有一组其意义相对完整的信息。分段的目的是为了能更好的满足用户的需要。
2、页的大小固定且由系统确定,把逻辑地址划分为页号和页内地址两部分,是由机器硬件实现的,因而一个系统只能有一种大小的页面。段的长度却不固定,决定于用户所编写的程序,通常由编辑程序在对源程序进行编辑时,根据信息的性质来划分。
3、分页的作业地址空间是维一的,即单一的线性空间,程序员只须利用一个记忆符,即可表示一地址。分段的作业地址空间是二维的,程序员在标识一个地址时,既需给出段名,又需给出段内地址。
页面置换算法
1.最佳置换算法(OPT)(理想置换算法):从主存中移出永远不再需要的页面;如无这样的页面存在,则选择最长时间不需要访问的页面。于所选择的被淘汰页面将是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。
2.先进先出置换算法(FIFO):是最简单的页面置换算法。这种算法的基本思想是:当需要淘汰一个页面时,总是选择驻留主存时间最长的页面进行淘汰,即先进入主存的页面先淘汰。其理由是:最早调入主存的页面不再被使用的可能性最大。
3.最近最久未使用(LRU)算法:这种算法的基本思想是:利用局部性原理,根据一个作业在执行过程中过去的页面访问历史来推测未来的行为。它认为过去一段时间里不曾被访问过的页面,在最近的将来可能也不会再被访问。所以,这种算法的实质是:当需要淘汰一个页面时,总是选择在最近一段时间内最久不用的页面予以淘汰。
4. 时钟(CLOCK)置换算法 :LRU算法的性能接近于OPT,但是实现起来比较困难,且开销大;FIFO算法实现简单,但性能差。所以操作系统的设计者尝试了很多算法,试图用比较小的开销接近LRU的性能,这类算法都是CLOCK算法的变体。简单的CLOCK算法是给每一帧关联一个附加位,称为使用位。当某一页首次装入主存时,该帧的使用位设置为1;当该页随后再被访问到时,它的使用位也被置为1。
实现LRU
利用链表和hashmap。当需要插入新的数据项的时候,如果新数据项在链表中存在(一般称为命中),则把该节点移到链表头部,如果不存在,则新建一个节点,放到链表头部,若缓存满了,则把链表最后一个节点删除即可。在访问数据的时候,如果数据项在链表中存在,则把该节点移到链表头部,否则返回-1。这样一来在链表尾部的节点就是最近最久未访问的数据项。
快表与go to!
快表是一种特殊的高速缓冲存储器,内容是页表中的一部分或全部内容。
在操作系统中引入快表是为了加快地址映射速度。
volatile与synchronized
执行控制的目的是控制代码执行(顺序)及是否可以并发执行。
内存可见控制的是线程执行结果在内存中对其它线程的可见性。根据Java内存模型的实现,线程在具体执行时,会先拷贝主存数据到线程本地(CPU缓存),操作完成后再把结果从线程本地刷到主存。
synchronized关键字解决的是执行控制的问题,它会阻止其它线程获取当前对象的监控锁,这样就使得当前对象中被synchronized关键字保护的代码块无法被其它线程访问,也就无法并发执行。更重要的是,synchronized还会创建一个内存屏障,内存屏障指令保证了所有CPU操作结果都会直接刷到主存中,从而保证了操作的内存可见性,同时也使得先获得这个锁的线程的所有操作,都happens-before于随后获得这个锁的线程的操作。
volatile关键字解决的是内存可见性的问题,会使得所有对volatile变量的读写都会直接刷到主存,即保证了变量的可见性。这样就能满足一些对变量可见性有要求而对读取顺序没有要求的需求。
使用volatile关键字仅能实现对原始变量(如boolen、 short 、int 、long等)操作的原子性,但需要特别注意, volatile不能保证复合操作的原子性,即使只是i++,实际上也是由多个原子操作组成:read i; inc; write i,假如多个线程同时执行i++,volatile只能保证他们操作的i是同一块内存,但依然可能出现写入脏数据的情况。
synchronized优化
到了JDK1.6,发生了变化,对synchronize加入了很多优化措施,有自适应自旋,锁消除,锁粗化,轻量级锁,偏向锁等等。导致在JDK1.6上synchronize的性能并不比Lock差。官方也表示,他们也更支持synchronized,在未来的版本中还有优化余地,所以还是提倡在synchronized能实现需求的情况下,优先考虑使用synchronized来进行同步。
synchronized的实现原理和应用总结
(1)synchronized同步代码块:synchronized关键字经过编译之后,会在同步代码块前后分别形成monitorenter和monitorexit字节码指令,在执行monitorenter指令的时候,首先尝试获取对象的锁,如果这个锁没有被锁定或者当前线程已经拥有了那个对象的锁,锁的计数器就加1,在执行monitorexit指令时会将锁的计数器减1,当减为0的时候就释放锁。如果获取对象锁一直失败,那当前线程就要阻塞等待,直到对象锁被另一个线程释放为止。
(2)同步方法:方法级的同步是隐式的,无须通过字节码指令来控制,JVM可以从方法常量池的方法表结构中的ACC_SYNCHRONIZED访问标志得知一个方法是否声明为同步方法。当方法调用的时,调用指令会检查方法的ACC_SYNCHRONIZED访问标志是否被设置,如果设置了,执行线程就要求先持有monitor对象,然后才能执行方法,最后当方法执行完(无论是正常完成还是非正常完成)时释放monitor对象。在方法执行期间,执行线程持有了管程,其他线程都无法再次获取同一个管程。
/**
* 求二叉树第k层的节点个数
*
* @param root
* @param k
* @return
*/
public int getNodeNumKthLevel(TreeNode root, int k) {
if (root == null || k < 1) {
return 0;
}
if (k == 1) {
return 1;
}
return getNodeNumKthLevel(root.left, k - 1) + getNodeNumKthLevel(root.right, k - 1);
}
数组和链表的区别
数组:
(1)数组在内存中连续; (2)使用数组之前,必须事先固定数组长度,不支持动态改变数组大小;(3) 数组元素增加时,有可能会数组越界;(4) 数组元素减少时,会造成内存浪费;(5)数组增删时需要移动其它元素
场景:数组的存储空间是栈上分配的,存储密度大,当要求存储的大小变化不大时,且可以事先确定大小,宜采用数组存储数据
链表:
(1)链表采用动态内存分配的方式,在内存中不连续 (2)支持动态增加或者删除元素 (3)需要时可以使用malloc或者new来申请内存,不用时使用free或者delete来释放内存
场景:链表的存储空间是堆上动态申请的,当要求存储的长度变化较大时,且事先无法估量数据规模,宜采用链表存储
事务
事务是用户定义的一个数据库操作序列,这些操作要么全不做,要么全做,是一个不可分割的工作单位。
事务具有四个特性:原子性(Atomicity)、持续性(Durability)、一致性(Consistency)和隔离性(Isolation)。这四个特性简称ACID特性(ACID Properties)。
1.读未提交(Read uncommitted):
这种事务隔离级别下,select语句不加锁。
此时,可能读取到不一致的数据,即“读脏 ”。这是并发最高,一致性最差的隔离级别。
2.读已提交(Read committed):
可避免 脏读 的发生。
在互联网大数据量,高并发量的场景下,几乎 不会使用 上述两种隔离级别。
3.可重复读(Repeatable read):
MySql默认隔离级别。
可避免 脏读 、不可重复读 的发生。
4.串行化(Serializable ):
可避免 脏读、不可重复读、幻读 的发生。
数据库三大范式
数据库的设计范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。
1.第一范式(1NF):列不可再分
1.每一列属性都是不可再分的属性值,确保每一列的原子性
2.两列的属性相近或相似或一样,尽量合并属性一样的列,确保不产生冗余数据
2.第二范式(2NF)属性完全依赖于主键
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。这个惟一属性列被称为主键
3.第三范式(3NF)属性不依赖于其它非主属性 属性直接依赖于主键
数据不能存在传递关系,即每个属性都跟主键有直接关系而不是间接关系。像:a-->b-->c 属性之间含有这样的关系,是不符合第三范式的。
sql优化的一般思路:
1)添加适当的索引,索引字段必须要能最大限度的区分全表数据,才能达到比较好的效果。
2)在查询语句中带上where条件,过滤条件最好已经添加了索引,可以避免全表扫描。
3)注意索引失效问题。
- 前置模糊查询会导致索引失效;
- 索引字段参与函数计算会导致索引失效
- 在筛选条件中OR关键字的两端,一个字段有索引,另一字段无索引, 索引失效
- 隐式转换,穿入字段类型和索引字段类型不一样,但是能匹配上,mysql 就会在不改变字段内容的前提下,把出入字段转换成数据库中对应的字段类型进行匹配,此时也不走索引。
4)在使用复合索引的时候要要遵循最左原则,筛选条件中的字段顺序和复合索 引的字段顺序保持一致
5)需要哪些字段就查询哪些字段,不要用*号,避免过多回表操作
6)sql优化的其他思路:
I.对热点数据进行缓存,
II.读写分离主从架构
III.分库分表,应用曾开发难度大,一般不这么玩,常用的分库分表中间件有mycat,sharing-jdbc。
普通索引:仅加速查询
唯一索引:加速查询 + 列值唯一(可以有null)
主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个
组合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
全文索引:对文本的内容进行分词,进行搜索
ps.索引合并,使用多个单列索引组合搜索
覆盖索引,select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖
创建索引:
普通索引、UNIQUE索引或PRIMARY KEY索引:
ALTER TABLE table_name ADD INDEX index_name (column_list)
普通索引、UNIQUE索引:
CREATE INDEX index_name ON table_name (column_list)
删除索引:
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY
归结到mysql中innodb索引结构,采用的是B+树,如聚簇索引,是通过主键来聚集数据,采用B+树实现,https://blog.csdn.net/chinabestchina/article/details/80685902
MySQL“慢SQL”定位
https://www.cnblogs.com/jpfss/p/12077222.html
贪心算法与动态递归的区别?
【一】分治算法特征:
1)规模如果很小,则很容易解决。//一般问题都能满足
2)大问题可以分为若干规模小的相同问题。//前提
3)利用子问题的解,可以合并成该问题的解。//关键
4)分解出的各个子问题相互独立,子问题不再包含公共子问题。 //效率高低
【二】动态规划:
依赖:依赖于有待做出的最优选择
实质:就是分治思想和解决冗余。
自底向上(每一步,根据策略得到一个更小规模的问题。最后解决最小规模的问题。得到整个问题最优解)
特征:动态规划任何一个i+1阶段都仅仅依赖 i 阶段做出的选择。而与i之前的选择无关。但是动态规划不仅求出了当前状态最优值,而且同时求出了到中间状态的最优值。
缺点:空间需求大。
【三】贪心算法:
依赖:依赖于当前已经做出的所有选择。
自顶向下(就是每一步,根据策略得到一个当前最优解。传递到下一步,从而保证每一步都是选择当前最优的。最后得到结果)
【四】分治算法:
实质:递归求解
缺点:如果子问题不独立,需要重复求公共子问题
五层模型及各层协议
应用层:HTTP、FTP、POP3、SMTP、DNS...
传输层:TCP(经典三次握手)、UDP。(字节流报文)。主页是用户数据报文。
网络层:IP协议。绑上IP地址和端口。把用户数据准确的发送出去。
数据链路层:连接硬件设备程序。如:网卡驱动!
物理层:就是硬件本身了。
如果不采用分层次分解处理,则会产生由于任何错误或性能修改而影响整体设计的弊端。层次化的网络体系的优点在于每层实现相对独立的功能,层与层之间通过接口来提供服务,每一层都对上层屏蔽如何实现协议的具体细节,使网络体系结构作到与具体物理实现无关。层次结构便于系统的实现和便于系统的维护。
ARP(Address Resolution Protocol,地址解析协议)
是将IP地址解析为以太网MAC地址(或称物理地址)的协议。
在局域网中,当主机或其它网络设备有数据要发送给另一个主机或设备时,它必须知道对方的网络层地址(即IP地址)。但是仅仅有IP地址是不够的,因为IP数据报文必须封装成帧才能通过物理网络发送,因此发送站还必须有接收站的物理地址,所以需要一个从IP地址到物理地址的映射。APR就是实现这个功能的协议。
对称加密和非对称加密
1. 对称加密
对称加密指的就是加密和解密使用同一个秘钥,所以叫做对称加密。对称加密只有一个秘钥,作为私钥。
常见的对称加密算法:DES,AES,3DES等等。
2. 非对称加密
非对称加密指的是:加密和解密使用不同的秘钥,一把作为公开的公钥,另一把作为私钥。公钥加密的信息,只有私钥才能解密。私钥加密的信息,只有公钥才能解密。
常见的非对称加密算法:RSA,ECC
操作系统的基本组成部分
1、进程管理
2、存储管理
3、文件管理
4、设备管理
5、系统调用
进程上下文切换
进程上下文包含了进程执行所需要的所有信息。
用户地址空间:包括程序代码,数据,用户堆栈等;
控制信息:进程描述符,内核栈等;
硬件上下文:进程恢复前,必须装入寄存器的数据统称为硬件上下文。
进程切换分3步
a.切换页目录以使用新的地址空间
b.切换内核栈
c.切换硬件上下文
4、刷新TLB
5、系统调度器的代码执行
对于linux来说,线程和进程的最大区别就在于地址空间。
对于线程切换,第1步是不需要做的,第2和3步是进程和线程切换都要做的。所以明显是进程切换代价大
1. 线程上下文切换和进程上下文切换一个最主要的区别是线程的切换虚拟内存空间依然是相同的,
但是进程切换是不同的。这两种上下文切换的处理都是通过操作系统内核来完成的。
内核的这种切换过程伴随的最显著的性能损耗是将寄存器中的内容切换出。
2. 另外一个隐藏的损耗是上下文的切换会扰乱处理器的缓存机制。
简单的说,一旦去切换上下文,处理器中所有已经缓存的内存地址一瞬间都作废了。
还有一个显著的区别是当你改变虚拟内存空间的时候,
处理的页表缓冲(processor’s Translation Lookaside Buffer (TLB))或者相当的神马东西会被全部刷新,
这将导致内存的访问在一段时间内相当的低效。但是在线程的切换中,不会出现这个问题。
内存管理机制
1、分配机制
操作系统它会为每一个进程分配一个合理的大小,从而他能保证每一个进程能够正常的运行。而不至于内存不够使用或者某个进程占用太多的内存,这就是操作系统里面的分配概念。
2、回收机制(这一块是操作系统特别重要的一块)
在系统内存不足的时候,他会有一个回收再分配内存资源的机制,从而能够保证新的进程能够正常运行。而回收的时候就要杀死那些占有内存的进程,所以操作系统需要提供一套合理的杀死这些进程的机制,从而把副作用将到最低,而对于我们安卓系统来说,它对内存管理也有一套特别的办法,它和PC端是不一样的。我们都知道安卓它是移动操作系统,一般情况下安卓的内存资源会比PC端更少,所以我们就要更加谨慎的管理内存。
优先级它主要分为五个阶段。
第一:前台进程,屏幕当中显示的进程
第二:可见进程,他已经不属于前台进程,用户仍能看见的进程,
第三:服务进程,例如定位、闹钟等。
第四:后台进程,后台进程不同于服务进程,它是在后台处理一些计算的进程.
第五:空进程,没有任何东西在内存运行的进程。内存可以随时回收。
介绍虚拟内存
虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。
什么是页表
页表是一种特殊的数据结构,放在系统空间的页表区,存放逻辑页与物理页帧的对应关系。 每一个进程都拥有一个自己的页表,PCB表中有指针指向页表。
套接口Socket通信原理
socket通信原理是一种“打开—读/写—关闭”模式的实现,服务器和客户端各自维护一个“文件”,在建立连接打开后,可以向文件写入内容供对方读取或者读取对方内容,通讯结束时关闭文件。
Socket在应用层和传输层之间的一个抽象层,它把 TCP/IP 层复杂的操作抽象为几个简单的接口,供应用层调用实现进程在网络中的通信。Socket 起源于 UNIX,在 UNIX 一切皆文件的思想下,进程间通信就被冠名为文件描述符(file descriptor)。
Socket 保证了不同计算机之间的通信,也就是网络通信。对于网站,通信模型是服务器与客户端之间的通信。两端都建立了一个 Socket 对象,然后通过 Socket 对象对数据进行传输。通常服务器处于一个无限循环,等待客户端的连接。
为什么要有包装类
1.声明方式不同:
基本类型不使用new关键字,而包装类型需要使用new关键字来在堆中分配存储空间;
2.存储方式及位置不同:
基本类型是直接将变量值存储在栈中,而包装类型是将对象放在堆中,然后通过引用来使用;
3.初始值不同:
基本类型的初始值如int为0,boolean为false,而包装类型的初始值为null;
4.使用方式不同:
基本类型直接赋值直接使用就好,而包装类型在集合(如:Collection、Map)时会使用到。
ArrayList和linkedlist有什么区别?
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。 (LinkedList是双向链表,有next也有previous)
2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
ArrayList和LinkedList区别及使用场景
1. LinkedList和ArrayList的差别主要来自于Array和LinkedList数据结构的不同。ArrayList是基于数组实现的,LinkedList是基于双链表实现的。另外LinkedList类不仅是List接口的实现类,可以根据索引来随机访问集合中的元素,除此之外,LinkedList还实现了Deque接口,Deque接口是Queue接口的子接口,它代表一个双向队列,因此LinkedList可以作为双向队列 ,栈(可以参见Deque提供的接口方法)和List集合使用,功能强大。
2. 因为Array是基于索引(index)的数据结构,它使用索引在数组中搜索和读取数据是很快的,可以直接返回数组中index位置的元素,因此在随机访问集合元素上有较好的性能。Array获取数据的时间复杂度是O(1),但是要插入、删除数据却是开销很大的,因为这需要移动数组中插入位置之后的的所有元素。
3. 相对于ArrayList,LinkedList的随机访问集合元素时性能较差,因为需要在双向列表中找到要index的位置,再返回;但在插入,删除操作是更快的。因为LinkedList不像ArrayList一样,不需要改变数组的大小,也不需要在数组装满的时候要将所有的数据重新装入一个新的数组,这是ArrayList最坏的一种情况,时间复杂度是O(n),而LinkedList中插入或删除的时间复杂度仅为O(1)。ArrayList在插入数据时还需要更新索引(除了插入数组的尾部)。
4. LinkedList需要更多的内存,因为ArrayList的每个索引的位置是实际的数据,而LinkedList中的每个节点中存储的是实际的数据和前后节点的位置。
使用场景:
(1)如果应用程序对数据有较多的随机访问,ArrayList对象要优于LinkedList对象;
( 2 ) 如果应用程序有更多的插入或者删除操作,较少的随机访问,LinkedList对象要优于ArrayList对象;
(3)不过ArrayList的插入,删除操作也不一定比LinkedList慢,如果在List靠近末尾的地方插入,那么ArrayList只需要移动较少的数据,而LinkedList则需要一直查找到列表尾部,反而耗费较多时间,这时ArrayList就比LinkedList要快。
在一个有序数组里判断指定数字出现的次数
class Solution {
public int search(int[] nums, int target) {
int pivot, left = 0, right = nums.length - 1;
while (left <= right) {
pivot = left + (right - left) / 2;
if (nums[pivot] == target) return pivot;
if (target < nums[pivot]) right = pivot - 1;
else left = pivot + 1;
}
return -1;
}
}wait()和sleep()的区别
1) 原理不同。sleep()方法是Thread类的静态方法,是线程用来控制自身流程的,他会使此线程暂停执行一段时间,而把执行机会让给其他线程,等到计时时间一到,此线程会自动苏醒。例如,当线程执行报时功能时,每一秒钟打印出一个时间,那么此时就需要在打印方法前面加一个sleep()方法,以便让自己每隔一秒执行一次,该过程如同闹钟一样。而wait()方法是object类的方法,用于线程间通信,这个方法会使当前拥有该对象锁的进程等待,直到其他线程调用notify()方法或者notifyAll()时才醒来,不过开发人员也可以给他指定一个时间,自动醒来。
2) 对锁的 处理机制不同。由于sleep()方法的主要作用是让线程暂停执行一段时间,时间一到则自动恢复,不涉及线程间的通信,因此,调用sleep()方法并不会释放锁。而wait()方法则不同,当调用wait()方法后,线程会释放掉他所占用的锁,从而使线程所在对象中的其他synchronized数据可以被其他线程使用。
3) 使用区域不同。wait()方法必须放在同步控制方法和同步代码块中使用,sleep()方法则可以放在任何地方使用。sleep()方法必须捕获异常,而wait()、notify()、notifyAll()不需要捕获异常。在sleep的过程中,有可能被其他对象调用他的interrupt(),产生InterruptedException。由于sleep不会释放锁标志,容易导致死锁问题的发生,因此一般情况下,推荐使用wait()方法。
堆和栈的应用场景
基本类型是保存在栈内存中的简单数据段,它们的值都有固定的大小,每种类型的数据占用的内存空间的大小是确定的,并由系统自动分配和自动释放,通过按值访问。
引用类型是保存在堆内存中的对象,值大小不固定,栈内存中存放的该对象的访问地址指向堆内存中的对象,JavaScript不允许直接访问堆内存中的位置,因此操作对象时,实际操作对象的引用。
栈:栈是一种线性的数据结构,读取规则是先进后出。栈中的数据占用的内存空间的大小是确定的,便于代码执行时的入栈、出栈操作,并由系统自动分配和自动释放内存可以及时得到回收,相对于堆来说,更加容易管理内存空间。
堆:堆是一种树形数据结构,读取相对复杂。堆是动态分配内存,内存大小不一,也不会自动释放。栈中的数据长度不定,且占空间比较大。便于开辟内存空间,更加方便存储。
堆栈内存分配:
程序运行时,每个线程分配一个栈,每个进程分配一个堆。也就是说,栈是线程独占的,堆是线程共用的。此外,栈创建的时候,大小是确定的,数据超过这个大小,就发生stack overflow错误,而堆的大小是不确定的,需要的话可以不断增加。
java的特性
一.简单性:
Java是纯面向对象语言,语法简单明了,易于掌握。
Java使用接口取代了多重继承,并且取消了指针,因为多重继承和指针会使程序变得复杂。
Java还会自动地收集内存垃圾,使得内存管理变得更为简单。
Java还提供了丰富的类库、API文档以及第三方开发包,还有大量Java的开源项目。
二.面向对象性:
面向对象性事Java语言的基础。
java语言提倡“万物皆对象”,语法中不能在类外面定义单独的数据和函数。
Java语言最外部的数据类型是对象,所有的元素都要通过类和对象来访问。
三.分布性:
Java的分布性包括:1.操作分布。2.数据分布
⑴操作分布:即在多个不同的主机上不知相关操作。
⑵数据分布:将数据分别存放在不同的主机上,这些主机是网络中的不同成员。
四.可移植性:
Java程序具有与体系结构无关的特性。
Java的类库也提供了针对不同平台的接口,所有这些类库也可以被移植。
五.安全性
Java语言删除了类C语言的指针和内存释放等语法,有效地避免了用户对内存的非法操作
Java程序代码要经过代码程序校验、指针校验等很多测试步骤才能够运行。所以未经允许的Java程序不能出现损害系统平台的行为。
Java可以编写出防病毒和防修改系统。
六.健壮性
Java会检查程序在编码和运行时的错误,并消除错误。
七.多线程性。
Java应用程序可以在同一时间并行执行多项任务。而且相应的同步机制可以保证不同线程能够正确地共享数据。
八.高性能性
Java编译后的字节码是在解释器中运行的,所以它的速度较多数交互式运用程序提高了很多。
九.动态性
Java可以动态调整库中方法和增加变量,并且客户端不需要任何更改。在Java中进行动态调整是非常简单和直接。
面向对象中多态的概念
根据实际的对象类型决定函数调用的具体目标
同样的调用语句在实际运行时有多种不同的表现形态
继承,封装,多态
封装的意义:
- 封装的意义在于保护或者防止代码(数据)被我们无意中破坏。
- 保护成员属性,不让类以外的程序直接访问和修改;
- 隐藏方法细节
继承的意义:
主要实现重用代码,节省开发时间。
什么是多态
面向对象的三大特性:封装、继承、多态。从一定角度来看,封装和继承几乎都是为多态而准备的。这是我们最后一个概念,也是最重要的知识点。
多态的定义:指允许不同类的对象对同一消息做出响应。即同一消息可以根据发送对象的不同而采用多种不同的行为方式。(发送消息就是函数调用)
实现多态的技术称为:动态绑定(dynamic binding),是指在执行期间判断所引用对象的实际类型,根据其实际的类型调用其相应的方法。
多态的作用:消除类型之间的耦合关系。
多态的三个条件:
1.继承的存在(继承是多态的基础,没有继承就没有多态).
2.子类重写父类的方法(多态下调用子类重写的方法).
3.父类引用变量指向子类对象(子类到父类的类型转换).
实现多态方式:
1.接口多态性。
2.继承多态性。
3.通过抽象类实现的多态性。
多态的好处:
1.可替换性(substitutability)。多态对已存在代码具有可替换性。例如,多态对圆Circle类工作,对其他任何圆形几何体,如圆环,也同样工作。
2.可扩充性(extensibility)。多态对代码具有可扩充性。增加新的子类不影响已存在类的多态性、继承性,以及其他特性的运行和操作。实际上新加子类更容易获得多态功能。例如,在实现了圆锥、半圆锥以及半球体的多态基础上,很容易增添球体类的多态性。
3.接口性(interface-ability)。多态是超类通过方法签名,向子类提供了一个共同接口,由子类来完善或者覆盖它而实现的。如图8.3 所示。图中超类Shape规定了两个实现多态的接口方法,computeArea()以及computeVolume()。子类,如Circle和Sphere为了实现多态,完善或者覆盖这两个接口方法。
4.灵活性(flexibility)。它在应用中体现了灵活多样的操作,提高了使用效率。
5.简化性(simplicity)。多态简化对应用软件的代码编写和修改过程,尤其在处理大量对象的运算和操作时,这个特点尤为突出和重要。
虚函数
那些被virtual关键字修饰的成员函数,就是虚函数。虚函数的作用,用专业术语来解释就是实现多态性(Polymorphism),多态性是将接口与实现进行分离;用形象的语言来解释就是实现以共同的方法,但因个体差异,而采用不同的策略。
Java八种基本数据类型的大小,以及封装类,自动装箱/拆箱的用法?
原始类型-大小-包装类型
char-2B-Character
booelan-1B-Boolean
byte-1B-Byte
short-2B-Short
int-4B-Integer
long-8B-Long
float-4B-Float
double-8B-Double
final可以修饰类、属性、方法。
1、当用final修饰类的时候,此类不可被继承,即final类没有子类。这样可以用final保证用户调用时动作的一致性,可以防止子类覆盖情况的发生。
2、当利用final修饰一个属性(变量)的时候,此时的属性成为常量。
3、对于在构造方法中利用final进行赋值的时候,此时在构造之前系统设置的默认值相对于构造方法失效。
App编译流程
一个Android应用从开始编译到打包大致上会经历三个步骤:编译前检查--> 编译(资源文件和源码)-->打包签名
我们以最熟悉的Android Studio开发应用为例,首先,我们把Gradle构建项目从本文中剖离开,不讨论具体的Gradle构建是怎么回事,只关注于代码是如何通过一系列的Android编译工具最终生成APK的。
编译步骤如下:
- 首先在编译阶段,会对资源文件文件进行检查,包括AndroidManifest.xml 、res目录下的所有文件(文件名是否合理),在检查通过后,对资源文件进行处理,一次编译生成resources.arsc 和 R.java文件,在完成资源编译后,会针对res目录下的xml文件和AndroidManifest.xml分别进行编译,这样处理过的xml文件就被简单的“加密”(如果你解压一个apk,会发现所有的xml布局文件都是乱码),最后处理后的res&AndroidManifest.xml&resources.arsc会打包压缩成resources.ap_文件,在AndroidStudio的项目下
/app/build/intermediates/res目录下可以看到编译打包后生成的资源打包文件。如果项目中使用了NDK来编译native代码,则也会在这个阶段编译并生成.so库文件。在apkbuilder的时候作为三方库文件打包进应用。 - 处理AIDL文件,在编译阶段会将.aidl的文件编译生成相应的java代码供程序调用。
- 编译工程源码,生成相应的class文件,位于项目
/app/build/intermediates/classes目录下。 - 在class文件生成后,如果使用了混淆,则会调用proguard.jar文件对class文件和资源文件进行混淆优化处理,同时生成混淆的mapping文件,位于
/app/,如果没有使用混淆,则直接转换所有的class文件生成classes.dex文件。 - 打包生成APK文件。
1.质量压缩 2.采样率压缩 3.缩放法压缩(martix) 4.RGB_565法
recycleview很长列表如何缓存?
主要进行ViewHolder缓存
RecyclerView的缓存分为四级
- Scrap
- Cache
- ViewCacheExtension
- RecycledViewPool
Scrap对应ListView 的Active View,就是屏幕内的缓存数据,就是相当于换了个名字,可以直接拿来复用。
Cache 刚刚移出屏幕的缓存数据,默认大小是2个,当其容量被充满同时又有新的数据添加的时候,会根据FIFO原则,把优先进入的缓存数据移出并放到下一级缓存中,然后再把新的数据添加进来。Cache里面的数据是干净的,也就是携带了原来的ViewHolder的所有数据信息,数据可以直接来拿来复用。需要注意的是,cache是根据position来寻找数据的,这个postion是根据第一个或者最后一个可见的item的position以及用户操作行为(上拉还是下拉)。
举个栗子:当前屏幕内第一个可见的item的position是1,用户进行了一个下拉操作,那么当前预测的position就相当于(1-1=0),也就是position=0的那个item要被拉回到屏幕,此时RecyclerView就从Cache里面找position=0的数据,如果找到了就直接拿来复用。
ViewCacheExtension是google留给开发者自己来自定义缓存的,这个ViewCacheExtension我个人建议还是要慎用,因为我扒拉扒拉网上其他的博客,没有找到对应的使用场景,而且这个类的api设计的也有些奇怪,只有一个public abstract View getViewForPositionAndType(@NonNull Recycler recycler, int position, int type);让开发者重写通过position和type拿到ViewHolder的方法,却没有提供如何产生ViewHolder或者管理ViewHolder的方法,给人一种只出不进的赶脚,还是那句话慎用。
RecycledViewPool刚才说了Cache默认的缓存数量是2个,当Cache缓存满了以后会根据FIFO(先进先出)的规则把Cache先缓存进去的ViewHolder移出并缓存到RecycledViewPool中,RecycledViewPool默认的缓存数量是5个。RecycledViewPool与Cache相比不同的是,从Cache里面移出的ViewHolder再存入RecycledViewPool之前ViewHolder的数据会被全部重置,相当于一个新的ViewHolder,而且Cache是根据position来获取ViewHolder,而RecycledViewPool是根据itemType获取的,如果没有重写getItemType()方法,itemType就是默认的。因为RecycledViewPool缓存的ViewHolder是全新的,所以取出来的时候需要走onBindViewHolder()方法。
Drawable 和bitmap区别
Bitmap
- 称作位图,一般位图的文件格式后缀为bmp
Drawable
- 作为Android平下通用的图形对象,它可以装载常用格式的图像
比如GIF、PNG、JPG,当然也支持BMP,当然还提供一些高级的可视化对象,比如渐变、图形等。
Bitmap是Drawable . Drawable不一定是Bitmap
Drawable在内存占用和绘制速度这两个非常关键的点上胜过Bitmap
1、Bitmap对象
Resources res = getResources();
Bitmap bmp = BitmapFactory.decodeResource(res, R.drawable.icon);
获取其宽高的方法:
bmp.getHeight()
bmp.getWidth()
2、Drawable对象
Drawable drawable = getResources().getDrawable(R.drawable.icon);
获取其宽高的方法:
drawable.getIntrinsicWidth();
drawable.getIntrinsicHeight();
View整体绘制流程
当一个应用启动时,会启动一个主Activity,Android系统会根据Activity的布局来对它进行绘制。绘制会从根视图ViewRoot的performTraversals()方法开始,是一个树形的递归过程,从上到下遍历整个视图树,每个View控件负责绘制自己,而ViewGroup负责通知自己的子视图进行绘制。View的绘制是从上到下,按树形结构绘制。整个绘制流程分三个步骤,分别是测量(Measure)、布局(Layout)和绘制(Draw)。
View绘制流程
View的绘制基本由measure()、layout()、draw()这个三个函数完成
| 函数 | 作用 | 相关方法 |
|---|---|---|
| measure() | 测量View的宽高 | measure(),setMeasuredDimension(),onMeasure() |
| layout() | 计算当前View以及子View的位置 | layout(),onLayout(),setFrame() |
| draw() | 视图的绘制工作 | draw(),onDraw() |
view?事件分发机制?https://www.cnblogs.com/chengxuyinli/p/9979826.html
被分发的对象
被分发的对象是那些?被分发的对象是用户触摸屏幕而产生的点击事件,事件主要包括:按下、滑动、抬起与取消。这些事件被封装成MotionEvent对象。该对象中的主要事件如下表所示:
| 事件 | 触发场景 | 单次事件流中触发的次数 |
|---|---|---|
| MotionEvent.ACTION_DOWN | 在屏幕按下时 | 1次 |
| MotionEvent.ACTION_MOVE | 在屏幕上滑动时 | 0次或多次 |
| MotionEvent.ACTION_UP | 在屏幕抬起时 | 0次或1次 |
| MotionEvent.ACTION_CANCLE | 滑动超出控件边界时 | 0次或1次 |
按下、滑动、抬起、取消这几种事件组成了一个事件流。事件流以按下为开始,中间可能有若干次滑动,以抬起或取消作为结束。
在安卓对事件分发的处理过程中,主要是对按下事件作分发,进而找到能够处理按下事件的组件。对于事件流中后续的事件(如滑动、抬起等),则直接分发给能够处理按下事件的组件。故本文讨论的内容则是主要针对按下事件的。
3. 分发事件的组件
从上图中可以看出,Activity包括了ViewGroup,ViewGroup又可以包含多个View。
| 组件 | 特点 | 举例 |
|---|---|---|
| Activity | 安卓视图类 | 如MainActivity |
| ViewGroup | View的容器,可以包含若干View | 各种布局类 |
| View | UI类组件的基类 | 如按钮、文本框 |
4. 分发的核心方法
负责对事件进行分发的方法主要有三个,分别是:
- dispatchTouchEvent(
- onTouchEvent()
- onInterceptTouchEvent()。
它们并不存在于所有负责分发的组件中,其具体情况总结于下面的表格中:
| 组件 | dispatchTouchEvent | onTouchEvent | onInterceptTouchEvent |
|---|---|---|---|
| Activity | 存在 | 存在 | 不存在 |
| ViewGroup | 存在 | 存在 | 存在 |
| View | 存在 | 存在 | 不存在 |
从表格中看,dispatchTouchEvent,onTouchEvent方法存在于上文的三个组件中。而onInterceptTouchEvent为ViewGroup独有。这些方法的具体作用在下文作介绍。
ViewGroup类中,实际是没有onTouchEvent方法的,但是由于ViewGroup继承自View,而View拥有onTouchEvent方法,故ViewGroup的对象也是可以调用onTouchEvent方法的。故在表格中表明ViewGroup中存在onTouchEvent方法的。
5、事件分发过程
向下传播:Activity包括Layout,事件从Activity向Layout传播被称作’向下传播‘。Layout包含若干View,事件从Layout向其子View传播,也被称为’向下传播‘。
JNI (Java Native Interface) 和 NDK (Native Development Kit):https://zhuanlan.zhihu.com/p/159028982
jni 是java调用native interface的功能,ndk 是android提供的底层开发包 。
jni 的目的是java调用c、c++写的本地方法;android下是用JNI时需要的.so文件,是通过ndk-build生成的。
Java Native Interface(JNI)是java本地接口,所谓的本地(native)一般是指C/C++语言。当使用Java进行程序设计时,一般主要有三种情况需要C语言协助。
1)调用驱动。由于操作系统所提供的驱动一般都是C接口,java语言本身不具备操作这些驱动的能力。
2)对于某些大量数据处理的模块,java的效率可能远低于C,因此,程序员希望使用C去完成。
3)对于某些功能模块,可能java和C的效率差不多,但是这些模块已经存在已有的C代码,程序员不想再用java重写,而只想重新利用已有的C代码。
从程序的角度来看,JNI接口主要包含两种情况:
1)从java中访问C
2)从C中访问java
只有解决了这两个问题,那么就可以任意进行java和C的应用组合。Framework中大量使用JNI完成本地接口的实现。
触发ANR的原因
-
应用进程自身引起
例如:
1.主线程阻塞、挂起、死循环
2.应用进程的其他线程的CPU占用率高,使得主线程无法抢占到CPU时间片 -
其他进程间接引起(误伤)
例如:
1.当前应用进程进行进程间通信请求其他进程,其他进程的操作长时间没有反馈
2.其他进程的CPU占用率极高,使得当前应用进程无法抢占到CPU时间片
ANR的分类:
- 应用在5秒内未响应用户的输入事件,如按键或触摸事件
- BroadcastReceiver未在10秒内完成相关的处理
- Service的各个生命周期函数时20秒内没有执行完毕
hashcode和equals区别?
1.hashCode是为了提高在散列结构存储中查找的效率,在线性表中没有作用。
2.equals和hashCode需要同时覆盖。
3.若两个对象equals返回true,则hashCode有必要也返回相同的int数。
4.若两个对象equals返回false,则hashCode不一定返回不同的int数,但为不相等的对象生成不同hashCode值可以提高哈希表的性能。
5.若两个对象hashCode返回相同int数,则equals不一定返回true。
6.若两个对象hashCode返回不同int数,则equals一定返回false。
7.同一对象在执行期间若已经存储在集合中,则不能修改影响hashCode值的相关信息,否则会导致内存泄露问题。
string,stringbuilder区别?底层了解吗?
String 是不可变字符串,JDK源码定义String的时候其value是privite final char value[]
StringBuilder 是可变字符串,JDK源码在其父类定义的时候定义其value为 char[] value;
故String是不可变字符串,StringBuilder是可变字符串,从内存分析角度来看
若定义一个String的对象,若改变其值,则其指向的内存地址必定改变,
若定义一个StringBuilder对象,若改变其值,其内存地址未必一定改变,
重写重载
重写方法的规则:
1、参数列表必须完全与被重写的方法相同,否则不能称其为重写而是重载。
2、返回的类型必须一直与被重写的方法的返回类型相同,否则不能称其为重写而是重载。
3、访问修饰符的限制一定要大于被重写方法的访问修饰符(public>protected>default>private)
4、重写方法一定不能抛出新的检查异常或者比被重写方法申明更加宽泛的检查型异常。例如:
父类的一个方法申明了一个检查异常IOException,在重写这个方法是就不能抛出Exception,只能抛出IOException的子类异常,可以抛出非检查异常。
而重载的规则:
- 被重载的方法必须改变参数列表(参数个数或类型不一样);
- 被重载的方法可以改变返回类型;
- 被重载的方法可以改变访问修饰符;
- 被重载的方法可以声明新的或更广的检查异常;
- 方法能够在同一个类中或者在一个子类中被重载。
- 无法以返回值类型作为重载函数的区分标准。
static是一个修饰符,用于修饰类的成员方法、类的成员变量,另外可以编写static代码块来优化程序性能。
抽象类和接口区别
(1) 抽象方法只作声明,而不包含实现,可以看成是没有实现体的虚方法
(2) 抽象类不能被实例化
(3) 抽象类可以但不是必须有抽象属性和抽象方法,但是一旦有了抽象方法,就一定要把这个类声明为抽象类
(4) 具体派生类必须覆盖基类的抽象方法
(5) 抽象派生类可以覆盖基类的抽象方法,也可以不覆盖。如果不覆盖,则其具体派生类必须覆盖它们。
接 口
(1) 接口不能被实例化
(2) 接口只能包含方法声明
(3) 接口的成员包括方法、属性、索引器、事件
(4) 接口中不能包含常量、字段(域)、构造函数、析构函数、静态成员。
“泛型”
意味着编写的代码可以被不同类型的对象所重用。泛型的提出是为了编写重用性更好的代码。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
实际上引入泛型的主要目标有以下几点:
类型安全
-
泛型的主要目标是提高 Java 程序的类型安全
-
编译时期就可以检查出因 Java 类型不正确导致的 ClassCastException 异常
-
符合越早出错代价越小原则
消除强制类型转换
-
泛型的一个附带好处是,使用时直接得到目标类型,消除许多强制类型转换
-
所得即所需,这使得代码更加可读,并且减少了出错机会
潜在的性能收益
-
由于泛型的实现方式,支持泛型(几乎)不需要 JVM 或类文件更改
-
所有工作都在编译器中完成
-
编译器生成的代码跟不使用泛型(和强制类型转换)时所写的代码几乎一致,只是更能确保类型安全而已
悲观锁和乐观锁?
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
JAVA创建对象的四种方式:
有4种显式地创建对象的方式:
1.用new语句创建对象,这是最常用的创建对象的方式。
2.运用反射手段,调用Java.lang.Class或者java.lang.reflect.Constructor类的newInstance()实例方法。
3.调用对象的clone()方法。
4.运用反序列化手段,调用java.io.ObjectInputStream对象的readObject()方法.
类加载过程
从类的生命周期而言,一个类包括如下阶段:
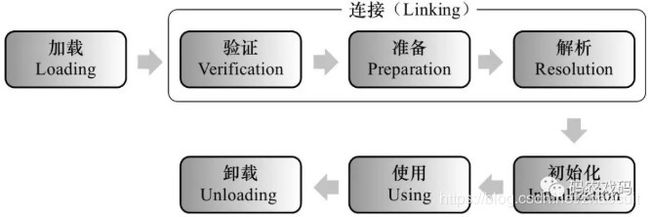
加载、验证、准备、初始化和卸载这5个阶段的顺序是确定的,类的加载过程必须按照这种顺序进行,而解析阶段则不一定,它在某些情况下可能在初始化阶段后在开始,因为java支持运行时绑定。
类加载器的类别
BootstrapClassLoader(启动类加载器)
c++编写,加载java核心库 java.*,构造ExtClassLoader和AppClassLoader。由于引导类加载器涉及到虚拟机本地实现细节,开发者无法直接获取到启动类加载器的引用,所以不允许直接通过引用进行操作
ExtClassLoader (标准扩展类加载器)
java编写,加载扩展库,如classpath中的jre ,javax.*或者java.ext.dir 指定位置中的类,开发者可以直接使用标准扩展类加载器。
AppClassLoader(系统类加载器)
java编写,加载程序所在的目录,如user.dir所在的位置的class
CustomClassLoader(用户自定义类加载器)
java编写,用户自定义的类加载器,可加载指定路径的class文件。
什么是双亲委派机制
当某个类加载器需要加载某个.class文件时,它首先把这个任务委托给他的上级类加载器,递归这个操作,如果上级的类加载器没有加载,自己才会去加载这个类。
双亲委派机制的作用
1、防止重复加载同一个.class。通过委托去向上面问一问,加载过了,就不用再加载一遍。保证数据安全。
2、保证核心.class不能被篡改。通过委托方式,不会去篡改核心.clas,即使篡改也不会去加载,即使加载也不会是同一个.class对象了。不同的加载器加载同一个.class也不是同一个Class对象。这样保证了Class执行安全。
操作系统中,常见的I/O模型包括以下几种:
- 阻塞I/O
- 非阻塞I/O
- I/O多路复用
- 异步I/O
常见的垃圾回收算法
1、Mark-Sweep(标记-清除算法):
(1)思想:标记清除算法分为两个阶段,标记阶段和清除阶段。标记阶段任务是标记出所有需要回收的对象,清除阶段就是清除被标记对象的空间。
(2)优缺点:实现简单,容易产生内存碎片
2、Copying(复制清除算法):
(1)思想:将可用内存划分为大小相等的两块,每次只使用其中的一块。当进行垃圾回收的时候了,把其中存活对象全部复制到另外一块中,然后把已使用的内存空间一次清空掉。
(2)优缺点:不容易产生内存碎片;可用内存空间少;存活对象多的话,效率低下。
3、Mark-Compact(标记-整理算法):
(1)思想:先标记存活对象,然后把存活对象向一边移动,然后清理掉端边界以外的内存。
(2)优缺点:不容易产生内存碎片;内存利用率高;存活对象多并且分散的时候,移动次数多,效率低下
4、分代收集算法:(目前大部分JVM的垃圾收集器所采用的算法):
垃圾回收器,CMS和G1
https://blog.csdn.net/zhao1299002788/article/details/94736238?utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.control
2.1 引用计数法
2.2 标记清除法
2.3 标记压缩算法
2.4 复制算法
2.5 分代算法
4.1CMS垃圾回收器
1.CMS与G1都是并发回收,多线程分阶段回收,只有某阶段会stw;2.CMS只会回收老年代和永久代(1.8开始为元数据区,需要设置CMSClassUnloadingEnabled),不会收集年轻代;年轻带只能配合Parallel New或Serial回收器; CMS是一种预处理垃圾回收器,它不能等到old内存用尽时回收,需要在内存用尽前,完成回收操作,否则会导致并发回收失败;所以CMS垃圾回收器开始执行回收操作,有一个触发阈值,默认是老年代或永久带达到92%;
CMS 处理过程有七个步骤(这也是面试常问的问题,包括哪俩个阶段会STW):
1. 初始标记(CMS-initial-mark) ,会导致STW; 初始标记阶段就是标记老年代中的GC ROOT对象和与GC ROOT对象关联的对象给标记出来。
2. 并发标记(CMS-concurrent-mark),与用户线程同时运行;因 为是并发运行的,在运行期间会发生新生代的对象晋升到老年代、或者是直接在老年代分配对象、或者更新老年代对象的引用关系等等,对于这些对象,都是需要进行重新标记的,否则有些对象就会被遗漏,发生漏标的情况。为了提高重新标记的效率,该阶段会把上述对象所在的Card标识为Dirty,后续只需扫描这些Dirty Card的对象,避免扫描整个老年代;
并发标记阶段只负责将引用发生改变的Card标记为Dirty状态,不负责处理;
3. 预清理(CMS-concurrent-preclean),与用户线程同时运行;
4. 可被终止的预清理(CMS-concurrent-abortable-preclean) 与用户线程同时运行;
5. 重新标记(CMS-remark) ,会导致STW; 这个阶段会导致第二次stop the word,该阶段的任务是完成标记整个年老代的所有的存活对象。
6. 并发清除(CMS-concurrent-sweep),与用户线程同时运行;
7. 并发重置状态等待下次CMS的触发(CMS-concurrent-reset),与用户线程同时运行;
CMS垃圾回收器的优化:
1.减少remark阶段停顿
一般CMS的GC耗时 80%都在remark阶段,如果发现remark阶段停顿时间很长,可以尝试添加该参数:-XX:+CMSScavengeBeforeRemark
在执行remark操作之前先做一次ygc,目的在于减少ygen对oldgen的无效引用,降低remark时的开销。
2.内存碎片
CMS是基于标记-清除算法的,只会将标记为为存活的对象删除,并不会移动对象整理内存空间,会造成内存碎片,这时候我们需要用到这个参数;-XX:CMSFullGCsBeforeCompaction=n
3.promotion failed与解决方法
过早提升与提升失败
在 Minor GC 过程中,Survivor Unused 可能不足以容纳 Eden 和另一个 Survivor 中的存活对象, 那么多余的将被移到老年 代, 称为过早提升(Premature Promotion),这会导致老年代中短期存活对象的增长, 可能会引发严重的性能问题。 再进一 步, 如果老年代满了, Minor GC 后会进行 Full GC, 这将导致遍历整个堆, 称为提升失败(Promotion Failure)。
早提升的原因
1. Survivor空间太小,容纳不下全部的运行时短生命周期的对象,如果是这个原因,可以尝试将Survivor调大,否则端生命周 期的对象提升过快,导致老年代很快就被占满,从而引起频繁的full gc;
2. 对象太大,Survivor和Eden没有足够大的空间来存放这些大象;
提升失败原因
当提升的时候,发现老年代也没有足够的连续空间来容纳该对象。
为什么是没有足够的连续空间而不是空闲空间呢?
老年代容纳不下提升的对象有两种情况:
1. 老年代空闲空间不够用了;
2. 老年代虽然空闲空间很多,但是碎片太多,没有连续的空闲空间存放该对象;
解决方法
1. 如果是因为内存碎片导致的大对象提升失败,cms需要进行空间整理压缩;
2. 如果是因为提升过快导致的,说明Survivor 空闲空间不足,那么可以尝试调大 Survivor;
3. 如果是因为老年代空间不够导致的,尝试将CMS触发的阈值调低;
4.增加线程数
CMS默认启动的回收线程数目是 (ParallelGCThreads + 3)/4) ,这里的ParallelGCThreads是年轻代的并行收集线程数,感觉 有 点怪怪的;
年轻代的并行收集线程数默认是(ncpus <= 8) ? ncpus : 3 + ((ncpus * 5) / 8),可以通过-XX:ParallelGCThreads= N 来调整;
如果要直接设定CMS回收线程数,可以通过-XX:ParallelCMSThreads=n,注意这个n不能超过cpu线程数,需要注意的是增加 gc线程数,就会和应用争抢资源;
G1垃圾收集器
是在jdk1.7中正式使用的全新的垃圾收集器,oracle官方计划在jdk9中将G1变成默认的垃圾
收集器,以替代CMS。
G1的设计原则就是简化JVM性能调优,开发人员只需要简单的三步即可完成调优 :
1. 第一步,开启G1垃圾收集器
2. 第二步,设置堆的最大内存
3. 第三部,设置最大的停顿时间
G1中提供了三种模式垃圾回收模式,Young GC、Mixed GC和Full GC,在不同的条件下被触发。
G1垃圾收集器相对比其他收集器而言,最大的区别在于它取消了年轻代、老年代的物理划分,取而代之的是将堆划分为若
干个区域(Region),这些区域中包含了有逻辑上的年轻代、老年代区域。
这样做的好处就是,我们再也不用单独的空间对每个代进行设置了,不用担心每个代内存是否足够。
JIT编译https://www.jianshu.com/p/ae0d47e770f0
对于 Java 代码,刚开始都是被编译器编译成字节码文件,然后字节码文件会被交由 JVM 解释执行,所以可以说 Java 本身是一种半编译半解释执行的语言。
当JIT编译启用时(默认是启用的),JVM读入.class文件解释后,将其发给JIT编译器。JIT编译器将字节码编译成本机机器代码。
通常Javac将程序源码编译,转换成java字节码,JVM通过解释字节码将其翻译成相应的机器指令,逐条读入,逐条解释翻译。
经过解释运行,其运行速度必定会比可运行的二进制字节码程序慢。为了提高运行速度,引入了JIT技术。
在执行时JIT会把翻译过的机器码保存起来,已备下次使用,因此从理论上来说,采用该JIT技术能够,能够接近曾经纯编译技术。
Android性能优化
https://blog.csdn.net/chuhe1989/article/details/105712898/
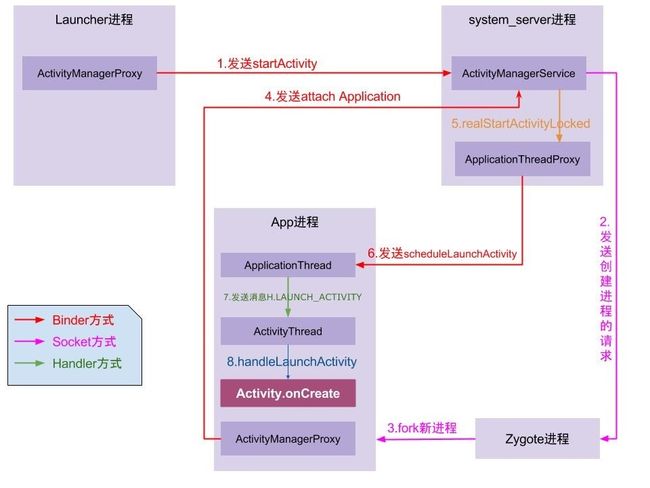
APP启动流程
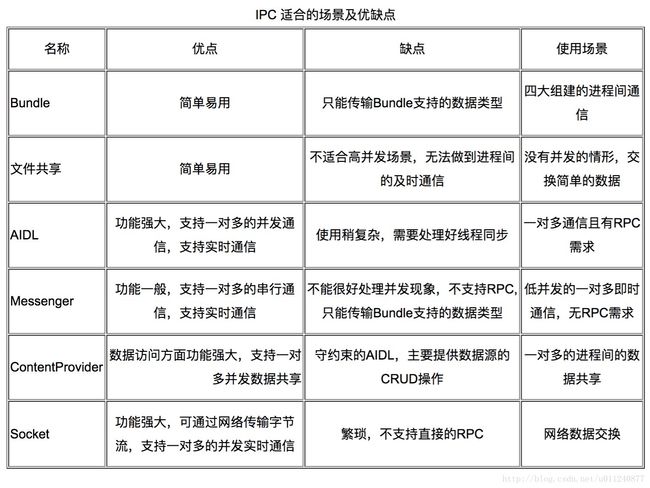
安卓有哪些进程通信的方式?
十大排序算法
https://www.cnblogs.com/onepixel/articles/7674659.html

#include
#include
#include
#include
using namespace std;
void cal_next(char *str, int *next, int len)
{
next[0] = -1;
int k = -1;
for (int q = 1; q <= len-1; q++)
{
while (k > -1 && str[k + 1] != str[q])
{
k = next[k];
}
if (str[k + 1] == str[q])
{
k = k + 1;
}
next[q] = k;
}
}
int KMP(char *str, int slen, char *ptr, int plen)
{
int *next = new int[plen];
cal_next(ptr, next, plen);
int k = -1;
for (int i = 0; i < slen; i++)
{
while (k >-1&& ptr[k + 1] != str[i])
k = next[k];
if (ptr[k + 1] == str[i])
k = k + 1;
if (k == plen-1)
{
//cout << "在位置" << i-plen+1<< endl;
//k = -1;//重新初始化,寻找下一个
//i = i - plen + 1;//i定位到该位置,外层for循环i++可以继续找下一个(这里默认存在两个匹配字符串可以部分重叠)
return i-plen+1;
}
}
return -1;
}
int main()
{
char *str = "bacbababadababacambabacaddababacasdsd";
char *ptr = "ababaca";
int a = KMP(str, 36, ptr, 7);
printf("%d",a);
return 0;
} //文件路径
String filePath="C:/Users/Admin/Desktop/products.txt";
File file=new File(filePath);
BufferedReader reader = null;
String tempString = null;
int line =1;
try {
// System.out.println("以行为单位读取文件内容,一次读一整行:");
reader = new BufferedReader(new InputStreamReader(new FileInputStream(file),"GBK"));
while ((tempString = reader.readLine()) != null) {
System.out.println("Line"+ line + ":" +tempString);
line ++ ;
}
reader.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}finally{
if(reader != null){
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
//10个城市编号0~9,城市之间移动只能前后移动(比如5只能到4或者6),10个城市构成一个环,
//从0可以到9,从9也可以到0。从任意城市X出发,途径N个城市,问有多少途径?
public class Main {
//dp + 递归
static int solution(int X, int N){
int result = recur(X, X + 1, N);
return result * 2;
}
static int recur(int X, int Y, int N) {
if (N == 0) {
if (Y == X) {
return 1;
} else {
return 0;
}
}
//处理循环
int pre = Y - 1;
if (pre < 0) {
pre = 9;
}
int next = Y + 1;
if (next > 9) {
next = 0;
}
return recur(X, pre, N-1) + recur(X, next, N-1);
}
public static void main(String[] args) {
System.out.println(solution(0, 3));
}
}void swap(USERINFO *head,USERINFO *left,USERINFO *right)
{
USERINFO *temp;
if (right->next == NULL) //t结点是否为尾结点
{
if (left->next == right) //p,t结点是否相邻
{
//与尾结点相邻的交换代
right->next = left;
right->pre = left->pre;
left->next = NULL;
left->pre->next = right;
left->pre = right;
}
else
{
//与尾结点不相邻的交换代
right->next = left->next;
right->pre->next = left;
temp = right->pre;
right->pre = left->pre;
left->next->pre = right;
left->next = NULL;
left->pre->next = right;
left->pre = temp;
}
}
else
{
if (left->next == right) //p,t结点是否相邻
{
//相邻的交换代
right->next->pre = left;
temp = right->next;
right->next = left;
right->pre = left->pre;
left->next = temp;
left->pre->next = right;
left->pre = right;
}
else
{
//不相邻的交换代
right->next->pre = left;
temp = right->next;
right->next = left->next;
left->next->pre = right;
left->next = temp;
right->pre->next = left;
temp = right->pre;
right->pre = left->pre;
left->pre->next = right;
left->pre = temp;
}
}
}//多线程交替打印
public class ABC_Synch {
public static class ThreadPrinter implements Runnable {
private String name;
private Object prev;
private Object self;
private ThreadPrinter(String name, Object prev, Object self) {
this.name = name;
this.prev = prev;
this.self = self;
}
@Override
public void run() {
int count = 10;
while (count > 0) {// 多线程并发,不能用if,必须使用whil循环
synchronized (prev) { // 先获取 prev 锁
synchronized (self) {// 再获取 self 锁
System.out.print(name);// 打印
count--;
self.notifyAll();// 唤醒其他线程竞争self锁,注意此时self锁并未立即释放。
}
// 此时执行完self的同步块,这时self锁才释放。
try {
if (count == 0) {// 如果count==0,表示这是最后一次打印操作,通过notifyAll操作释放对象锁。
prev.notifyAll();
} else {
prev.wait(); // 立即释放 prev锁,当前线程休眠,等待唤醒
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}
public static void main(String[] args) throws Exception {
Object a = new Object();
Object b = new Object();
Object c = new Object();
ThreadPrinter pa = new ThreadPrinter("A", c, a);
ThreadPrinter pb = new ThreadPrinter("B", a, b);
ThreadPrinter pc = new ThreadPrinter("C", b, c);
new Thread(pa).start();
Thread.sleep(10);// 保证初始ABC的启动顺序
new Thread(pb).start();
Thread.sleep(10);
new Thread(pc).start();
Thread.sleep(10);
}
}