95% 的算法都是基于这 6 种算法思想
95% 的算法都是基于这 6 种算法思想
算法思想是解决问题的核心,万丈高楼起于平地,在算法中也是如此,95% 的算法都是基于这 6 种算法思想,结下了介绍一下这 6 种算法思想,帮助你理解及解决各种算法问题。
1 递归算法
1.1 算法策略
递归算法是一种直接或者间接调用自身函数或者方法的算法。
递归算法的实质是把问题分解成规模缩小的同类问题的子问题,然后递归调用方法来表示问题的解。递归算法对解决一大类问题很有效,它可以使算法简洁和易于理解。
优缺点:
- 优点:实现简单易上手
- 缺点:递归算法对常用的算法如普通循环等,运行效率较低;并且在递归调用的过程当中系统为每一层的返回点、局部量等开辟了栈来存储,递归太深,容易发生栈溢出
1.2 适用场景
递归算法一般用于解决三类问题:
- 数据的定义是按递归定义的。(斐波那契数列)
- 问题解法按递归算法实现。(回溯)
- 数据的结构形式是按递归定义的。(树的遍历,图的搜索)
递归的解题策略:
- 第一步:明确你这个函数的输入输出,先不管函数里面的代码什么,而是要先明白,你这个函数的输入是什么,输出为何什么,功能是什么,要完成什么样的一件事。
- 第二步:寻找递归结束条件,我们需要找出什么时候递归结束,之后直接把结果返回
- 第三步:明确递归关系式,怎么通过各种递归调用来组合解决当前问题
1.3 使用递归算法求解的一些经典问题
- 斐波那契数列
- 汉诺塔问题
- 树的遍历及相关操作
DOM树为例
下面以以 DOM 为例,实现一个 document.getElementById 功能
由于DOM是一棵树,而树的定义本身就是用的递归定义,所以用递归的方法处理树,会非常地简单自然。
第一步:明确你这个函数的输入输出
从 DOM 根节点一层层往下递归,判断当前节点的 id 是否是我们要寻找的 id='d-cal'
输入:DOM 根节点 document ,我们要寻找的 id='d-cal'
输出:返回满足 id='sisteran' 的子结点
function getElementById(node, id){}
第二步:寻找递归结束条件
从document开始往下找,对所有子结点递归查找他们的子结点,一层一层地往下查找:
- 如果当前结点的 id 符合查找条件,则返回当前结点
- 如果已经到了叶子结点了还没有找到,则返回 null
function getElementById(node, id){
// 当前结点不存在,已经到了叶子结点了还没有找到,返回 null
if(!node) return null
// 当前结点的 id 符合查找条件,返回当前结点
if(node.id === id) return node
}
第三步:明确递归关系式
当前结点的 id 不符合查找条件,递归查找它的每一个子结点
function getElementById(node, id){
// 当前结点不存在,已经到了叶子结点了还没有找到,返回 null
if(!node) return null
// 当前结点的 id 符合查找条件,返回当前结点
if(node.id === id) return node
// 前结点的 id 不符合查找条件,继续查找它的每一个子结点
for(var i = 0; i < node.childNodes.length; i++){
// 递归查找它的每一个子结点
var found = getElementById(node.childNodes[i], id);
if(found) return found;
}
return null;
}
就这样,我们的一个 document.getElementById 功能已经实现了:
function getElementById(node, id){
if(!node) return null;
if(node.id === id) return node;
for(var i = 0; i < node.childNodes.length; i++){
var found = getElementById(node.childNodes[i], id);
if(found) return found;
}
return null;
}
getElementById(document, "d-cal");
最后在控制台验证一下,执行结果如下图所示:
![]()
使用递归的优点是代码简单易懂,缺点是效率比不上非递归的实现。Chrome浏览器的查DOM是使用非递归实现。非递归要怎么实现呢?
如下代码:
function getByElementId(node, id){
//遍历所有的Node
while(node){
if(node.id === id) return node;
node = nextElement(node);
}
return null;
}
还是依次遍历所有的 DOM 结点,只是这一次改成一个 while 循环,函数 nextElement 负责找到下一个结点。所以关键在于这个 nextElement 如何实现非递归查找结点功能:
// 深度遍历
function nextElement(node){
// 先判断是否有子结点
if(node.children.length) {
// 有则返回第一个子结点
return node.children[0];
}
// 再判断是否有相邻结点
if(node.nextElementSibling){
// 有则返回它的下一个相邻结点
return node.nextElementSibling;
}
// 否则,往上返回它的父结点的下一个相邻元素,相当于上面递归实现里面的for循环的i加1
while(node.parentNode){
if(node.parentNode.nextElementSibling) {
return node.parentNode.nextElementSibling;
}
node = node.parentNode;
}
return null;
}
在控制台里面运行这段代码,同样也可以正确地输出结果。不管是非递归还是递归,它们都是深度优先遍历,这个过程如下图所示。
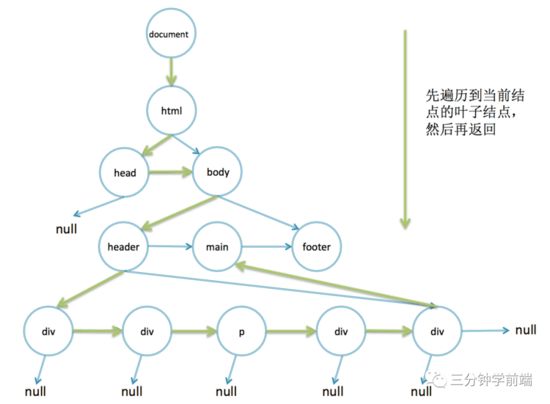
实际上 getElementById 浏览器是用的一个哈希 map 存储的,根据 id 直接映射到 DOM 结点,而 getElementsByClassName 就是用的这样的非递归查找。
参考:我接触过的前端数据结构与算法
2 分治算法
2.1 算法策略
在计算机科学中,分治算法是一个很重要的算法,快速排序、归并排序等都是基于分治策略进行实现的,所以,建议理解掌握它。
分治,顾名思义,就是 分而治之 ,将一个复杂的问题,分成两个或多个相似的子问题,在把子问题分成更小的子问题,直到更小的子问题可以简单求解,求解子问题,则原问题的解则为阿子问题解的合并。
2.2 适用场景
当出现满足以下条件的问题,可以尝试只用分治策略进行求解:
- 原始问题可以分成多个相似的子问题
- 子问题可以很简单的求解
- 原始问题的解是子问题解的合并
- 各个子问题是相互独立的,不包含相同的子问题
分治的解题策略:
- 第一步:分解,将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题
- 第二步:解决,解决各个子问题
- 第三步:合并,将各个子问题的解合并为原问题的解
2.3 使用分治法求解的一些经典问题
- 二分查找
- 归并排序
- 快速排序
- 汉诺塔问题
- React 时间分片
二分查找
也称折半查找算法,它是一种简单易懂的快速查找算法。例如我随机写0-100之间的一个数字,让你猜我写的是什么?你每猜一次,我就会告诉你猜的大了还是小了,直到猜中为止。
第一步:分解
每次猜拳都把上一次的结果分出大的一组和小的一组,两组相互独立
- 选择数组中的中间数
function binarySearch(items, item) {
// low、mid、high将数组分成两组
var low = 0,
high = items.length - 1,
mid = Math.floor((low+high)/2),
elem = items[mid]
// ...
}
第二步:解决子问题
查找数与中间数对比
- 比中间数低,则去中间数左边的子数组中寻找;
- 比中间数高,则去中间数右边的子数组中寻找;
- 相等则返回查找成功
while(low <= high) {
if(elem < item) { // 比中间数高
low = mid + 1
} else if(elem > item) { // 比中间数低
high = mid - 1
} else { // 相等
return mid
}
}
第三步:合并
function binarySearch(items, item) {
var low = 0,
high = items.length - 1,
mid, elem
while(low <= high) {
mid = Math.floor((low+high)/2)
elem = items[mid]
if(elem < item) {
low = mid + 1
} else if(elem > item) {
high = mid - 1
} else {
return mid
}
}
return -1
}
最后,二分法只能应用于数组有序的情况,如果数组无序,二分查找就不能起作用了
function binarySearch(items, item) {
// 快排
quickSort(items)
var low = 0,
high = items.length - 1,
mid, elem
while(low <= high) {
mid = Math.floor((low+high)/2)
elem = items[mid]
if(elem < item) {
low = mid + 1
} else if(elem > item) {
high = mid - 1
} else {
return mid
}
}
return -1
}
// 测试
var arr = [2,3,1,4]
binarySearch(arr, 3)
// 2
binarySearch(arr, 5)
// -1
测试成功
3 贪心算法
3.1 算法策略
贪心算法,故名思义,总是做出当前的最优选择,即期望通过局部的最优选择获得整体的最优选择。
某种意义上说,贪心算法是很贪婪、很目光短浅的,它不从整体考虑,仅仅只关注当前的最大利益,所以说它做出的选择仅仅是某种意义上的局部最优,但是贪心算法在很多问题上还是能够拿到最优解或较优解,所以它的存在还是有意义的。
3.2 适用场景
在日常生活中,我们使用到贪心算法的时候还是挺多的,例如:
从100章面值不等的钞票中,抽出 10 张,怎样才能获得最多的价值?
我们只需要每次都选择剩下的钞票中最大的面值,最后一定拿到的就是最优解,这就是使用的贪心算法,并且最后得到了整体最优解。
但是,我们任然需要明确的是,期望通过局部的最优选择获得整体的最优选择,仅仅是期望而已,也可能最终得到的结果并不一定不能是整体最优解。
例如:求取A到G最短路径:

根据贪心算法总是选择当前最优选择,所以它首先选择的路径是 AB,然后 BE、EG,所得到的路径总长为