SoftwareTest6 - 用 Selenium 怎么点点点
用 Selenium 来点点点
- 一 . 什么是自动化 ?
-
- 1.1 自动化测试的分类
-
- 接口自动化测试
- UI 自动化测试 (界面测试)
- 1.2 实现自动化测试的工具 : selenium
-
- 环境部署
- 驱动
- 二 . selenium 的使用
-
- 2.1 一个简单的示例 : 让谷歌浏览器在百度首页搜索蔡徐坤
-
- 准备工作
- 编写代码
- 2.2 打开谷歌浏览器的开发者工具
- 2.3 selenium 常用方法
-
- 查找页面元素
-
- findElement()
- findElements()
- 元素的定位
-
- selector
- xpath
- 2.4 常见的元素操作
-
- 输入文本 : sendKeys
- 点击按钮 : click()
- 提交 (不点击 , 通过回车键提交) : submit
- 清除 : clear
- 获取文本 : getText()
- 获取属性对应的值 : getAttribute()
- 获取标题 : getTitle() 获取 URL : getCurrentUrl()
- 2.5 窗口
-
- 窗口大小的设置
- 窗口的切换
- 2.6 屏幕截图
- 2.7 等待操作
-
- 强制等待 Thread.sleep()
- 隐式等待
- 显式等待
- 流畅等待
- 2.8 浏览器导航
- 2.9 弹窗
- 2.10 选择框
- 2.11 执行脚本
- 2.12 非常特殊场景 : 上传文件
- 2.13 浏览器的参数设置
Hello , 大家好 , 又给大家带来新的专栏喽 ~
这个专栏是专门为零基础小白从 0 到 1 了解软件测试基础理论设计的 , 虽然还不足以让你成为软件测试行业的佼佼者 , 但是可以让你了解一下软件测试行业的相关知识 , 具有一定的竞争实力 .
那这篇文章 , 就开始 Selenium 实战了 , 我们可以通过代码来操控浏览器来去做一些操作了 , 这个过程非常有趣 , 敬请期待
那也欢迎大家订阅此专栏 : https://blog.csdn.net/m0_53117341/category_12427509.html
希望大家都能够拿到好的 Offer

一 . 什么是自动化 ?
提到自动化 , 我们都能想到什么 ?
- 智能扫地机器人 ?
- 智能家居 ?
- 自动驾驶 ?
- …
那自动化就是有效的减少人力消耗 , 同时提高测试质量的一种说法
针对于我们的测试来说 , 有时候会重复点来点去的操作许多次 , 非常无聊 .
我们就可以通过自动化测试来帮我们有效的解决这种问题 , 解放人力资源 .
通过自动化测试就可以有效减少人力的投入 , 同时也提高了测试的质量和效率
我们之前讲过 : 可以通过自动化测试来完成回归测试 . 这是因为产品的不断迭代 , 版本肯定是越来越多的 , 而且每一个版本都会有人去使用
, 我们不能放弃每一个用户 . 但是针对每一个版本进行测试 , 版本回归的测试压力就会非常的大 , 仅仅通过人工测试来回归所有的版本肯定
是不现实的 , 所以我们就需要借助自动化测试来分担压力
比如 : 我们的一个外卖软件 , 本身就有 A B C 这三个功能 , 现在增加了 D E 两个功能 , 那么我们肯定要对 D E 进行测试 , 而且要进行非常详
细的测试 .
那难不成 A B C 就不测试了 , 就那么地了 ?
当然不行 , 还是需要对 A B C 进行测试的 , 有可能你新增加的 D E 就导致 A B C 不能正常工作了 , 所以也需要对 A B C 进行测试 , 也就是对
历史在线功能(还有用户在使用)需要进行回归测试 .
那我们新更新了一个版本 , 之前的版本就不需要进行测试了吗 ?
那肯定不行 , 我们还需要对历史在线版本(还有用户在使用的功能)进行回归测试 .
如果对所有版本进行人工手动测试 , 那么这个工作量是非常巨大的 , 所以自动化测试是非常必要的 !
1.1 自动化测试的分类
接口自动化测试
接口测试就是 API 测试
比如说我们访问百度 , 打开开发者工具观察返回给我们的接口信息 , 我们通过请求接口的方式 , 检查接口的返回值是否符合我们的预期

UI 自动化测试 (界面测试)
分为 : 移动端自动化测试和 web 自动化测试
我们学习的 , 是 web 自动化测试 , 测试的是一个 web 页面 , 不能用于测试软件
selenium 是一个 web 自动化测试的工具
1.2 实现自动化测试的工具 : selenium
我们市场上实现自动化测试的工具有很多

那么我们为什么要选择使用 selenium 呢 ?
- 开源免费
- 支持多浏览器 , 比如 : Google、Edge、FireFox、IE、Safara

- 支持多系统 , 如 : Windows、Mac、Linux
- 支持多语言编程
- selenium 提供了许多可供测试使用的 API
环境部署
如果我们想要用 selenium 进行 Web 自动化测试 , 我们都需要什么环境
- Chrome 浏览器
- (或其他浏览器) : 因为我们想实施 Web 端自动化测试
- Chrome 浏览器驱动包 (ChromeDriver)
- selenium 工具包
- 版本最低为 JDK 1.8 的 Java 环境
那么这里面的驱动指的是什么 ?
驱动
一辆汽车 , 有他的动力驱动 , 能够让一辆车跑起来
计算机也有驱动程序 , 可以驱动计算机和软件正常工作
那么 , 驱动实际上就是动力
我们在浏览器中点点点的时候 , 驱动实际上就是我们的鼠标
但是实现自动化测试 , 代码是不能够直接打开浏览器的 , 我们需要让代码具有动力 . 那这个动力从哪来 ? 就需要我们去下载额外的驱动程序才能控制浏览器进行一些操作 .
驱动程序的作用就是将代码转换成浏览器可识别的原生语言
那这个驱动是怎样让 selenium 编写的自动化脚本打开浏览器并且工作的呢 ? ( Selenium Driver 浏览器 三者之间的关系)
selenium 编写的自动化脚本会在运行的时候主动向驱动服务器发送请求 , 然后再由驱动服务器解析脚本发送过来的请求 , 转换成浏览器可识别的语言 , 让浏览器执行响应的命令
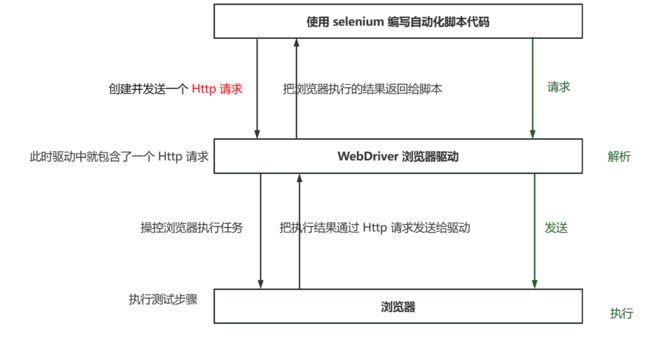
驱动要接受 selenium 脚本发送过来的 Http 请求 , 并且解析请求 ? 那么 , 驱动充当什么样的角色呢 ?
驱动实际上就是一个服务器 , 我们既然想接收 Http 请求 , 就需要有 IP 地址 + 端口号 , 这样才能准确无误定位到驱动 , 那驱动程序的 IP 地址 和 端口号都是什么呢 ?
打开我们之前配置在 JDK 安装目录的 bin 文件夹下 , 打开 chromedriver.exe
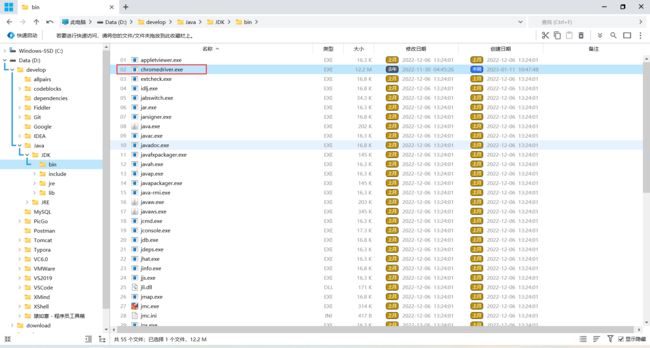

在这里要注意 , 谷歌浏览器一旦自动更新 , 之前的驱动程序就不好使了 , 需要重新配置最新版本的驱动程序
从图片中 , 我们可以看到 , 驱动程序的端口号是 9515
我们可以再确定一下 9515 端口被没被占用 , 被占用了就代表驱动程序真的是个服务器
打开 cmd , 输入 netstat -na | findstr 9515

我们就发现了确实有一个服务占用着 9515 的端口号 , 而且 9515 端口号对应的 IP 地址为 127.0.0.1:9515
二 . selenium 的使用
2.1 一个简单的示例 : 让谷歌浏览器在百度首页搜索蔡徐坤
准备工作
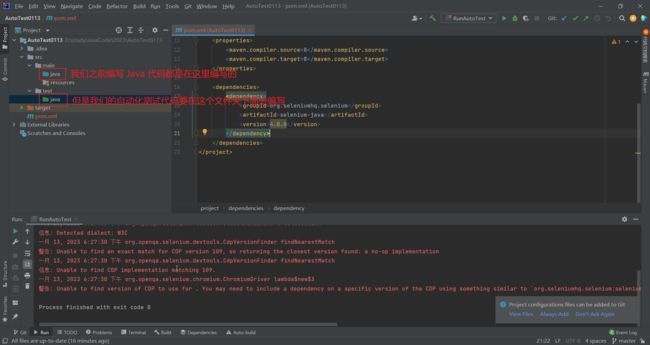
创建一个 Maven 项目
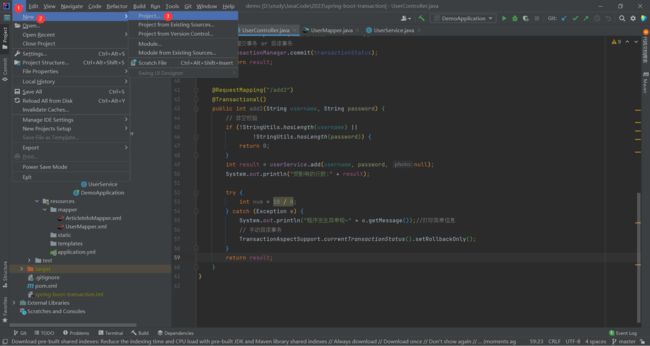
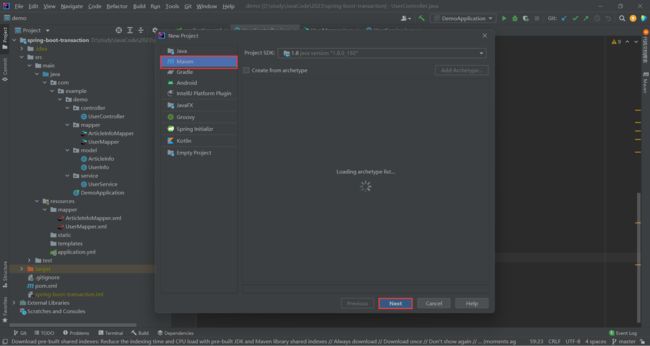
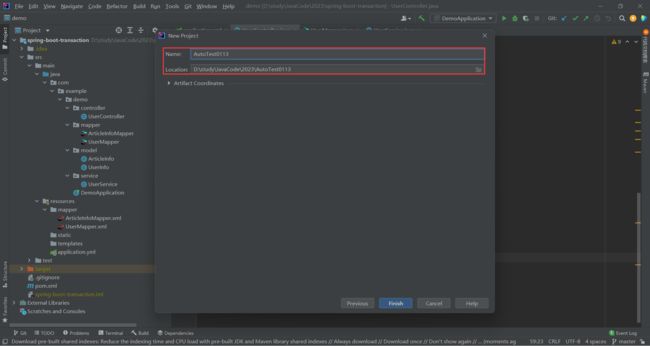
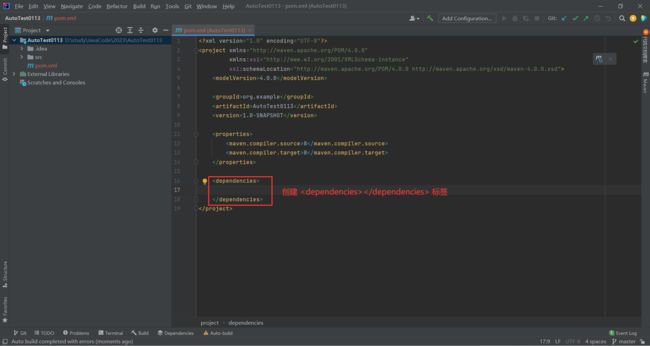
复制这段代码进去
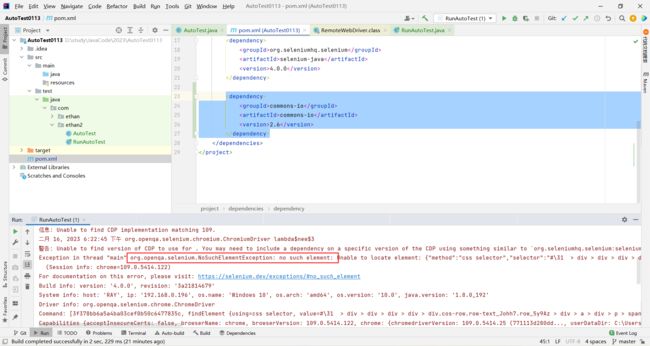
<dependency>
<groupId>org.seleniumhq.seleniumgroupId>
<artifactId>selenium-javaartifactId>
<version>4.0.0version>
dependency>
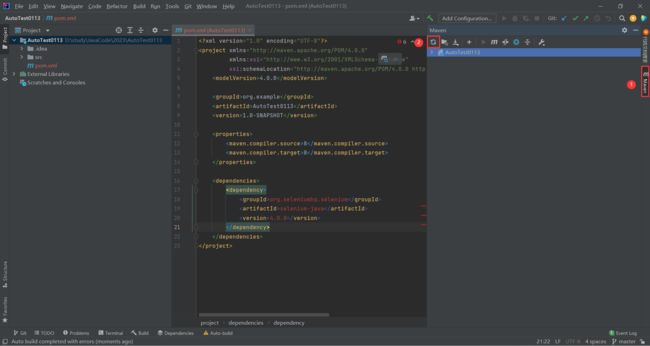
等待不爆红为止
编写代码
我们之前所有学习过的代码 , 都是在上面的蓝色 java 文件夹下创建的 , 我们的自动化测试代码就不是 , 他是在下面的 java 文件夹下创建的
在绿色的 java 目录下创建我们自己的包 , 我这里就创建了 com.ethan


创建好包之后 , 我们先创建我们的启动类 : RunAutoTest.java


编写好了之后 , 我们再去创建任务类 : AutoTask.java

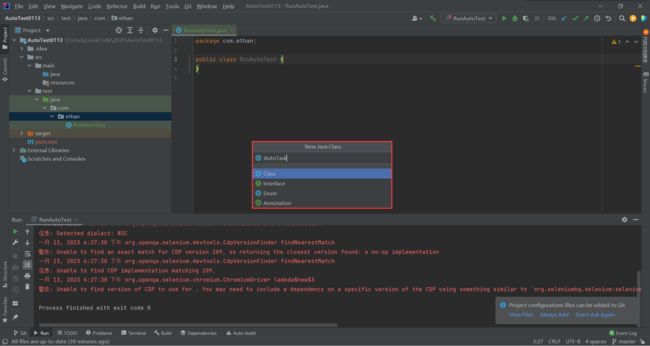
到目前为止我们的准备工作就彻底完成了
RunAutoTest 类主要是作为启动类使用的 , AutoTask 类里面我们写具体的自动化代码 , 然后让 RunAutoTest 类去调用 AutoTask 里面的方法
接下来 , 我们就去完成 AutoTask 类里面的自动化代码
我们人工搜索蔡徐坤需要几个步骤呢 ?
- 打开谷歌浏览器
- 跳转到百度首页
- 输入蔡徐坤
- 点击搜索
- 看到哥哥心满意足了 , 关闭浏览器
我们的自动化测试也需要模拟人的方式来进行测试 , 先创建一个方法 , 里面编写我们的自动化代码
package com.ethan;
public class AutoTask {
public void doAuto() {
}
}
接下来 , 我们就模拟人的思路去编写自动化测试代码
- 打开浏览器
package com.ethan;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTask {
public void doAuto() {
// 1. 打开浏览器 (创建驱动实例)
ChromeDriver driver = new ChromeDriver();
}
}
- 跳转到百度首页
package com.ethan;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTask {
public void doAuto() {
// 1. 打开浏览器 (创建驱动实例)
ChromeDriver driver = new ChromeDriver();
// 2. 跳转到百度首页
driver.get("https://www.baidu.com/");
}
}
- 输入蔡徐坤
输入蔡徐坤关键字的时候 , 就有讲究了 , 我们是随便输入 , 还是要定位到输入框 ? 那肯定是定位到输入框
package com.ethan;
import org.openqa.selenium.By;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTask {
public void doAuto() {
// 1. 打开浏览器 (创建驱动实例)
ChromeDriver driver = new ChromeDriver();
// 2. 跳转到百度首页
driver.get("https://www.baidu.com/");
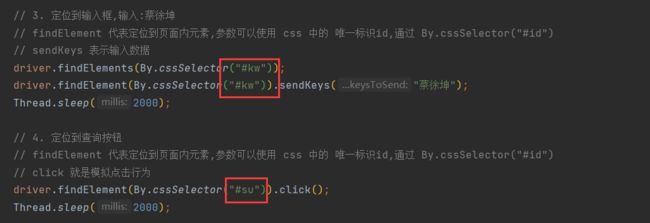
// 3. 定位到输入框,输入:蔡徐坤
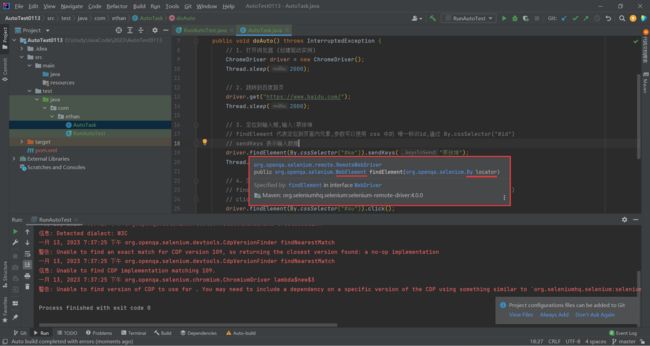
// findElement 代表定位到页面内元素,参数可以使用 css 中的 唯一标识id,通过 By.cssSelector("#id")
// sendKeys 表示输入数据
driver.findElement(By.cssSelector("#kw")).sendKeys("蔡徐坤");
}
}
driver.findElement(By.cssSelector("#kw")).sendKeys("蔡徐坤");这句代码我们可以不知道具体什么含义 , 继续往下看
- 点击搜索
package com.ethan;
import org.openqa.selenium.By;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTask {
public void doAuto() {
// 1. 打开浏览器 (创建驱动实例)
ChromeDriver driver = new ChromeDriver();
// 2. 跳转到百度首页
driver.get("https://www.baidu.com/");
// 3. 定位到输入框,输入:蔡徐坤
// findElement 代表定位到页面内元素,参数可以使用 css 中的 唯一标识id,通过 By.cssSelector("#id")
// sendKeys 表示输入数据
driver.findElement(By.cssSelector("#kw")).sendKeys("蔡徐坤");
// 4. 定位到查询按钮
// findElement 代表定位到页面内元素,参数可以使用 css 中的 唯一标识id,通过 By.cssSelector("#id")
// click 就是模拟点击行为
driver.findElement(By.cssSelector("#su")).click();
}
}
driver.findElement(By.cssSelector("#su")).click();这行代码同样不懂 , 没关系
- 看到我家哥哥了 , 心满意足了 , 退出浏览器
package com.ethan;
import org.openqa.selenium.By;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTask {
public void doAuto() {
// 1. 打开浏览器 (创建驱动实例)
ChromeDriver driver = new ChromeDriver();
// 2. 跳转到百度首页
driver.get("https://www.baidu.com/");
// 3. 定位到输入框,输入:蔡徐坤
// findElement 代表定位到页面内元素,参数可以使用 css 中的 唯一标识id,通过 By.cssSelector("#id")
// sendKeys 表示输入数据
driver.findElement(By.cssSelector("#kw")).sendKeys("蔡徐坤");
// 4. 定位到查询按钮
// findElement 代表定位到页面内元素,参数可以使用 css 中的 唯一标识id,通过 By.cssSelector("#id")
// click 就是模拟点击行为
driver.findElement(By.cssSelector("#su")).click();
// 5. 退出浏览器
driver.quit();
}
}
这样 , 一个自动化代码就完成了 , 我们接下来去启动类中调用这个方法 , 然后就可以启动了
package com.ethan;
public class RunAutoTest {
public static void main(String[] args) {
AutoTask task = new AutoTask();
task.doAuto();
}
}
如果报这个错误的话 , 请在创建浏览器驱动对象之前添加这段代码

System.setProperty("webdriver.chrome.driver", "E:\\develop\\Java\\JDK 8\\JDK\\bin\\chromedriver.exe");
ChromeOptions options = new ChromeOptions();
options.addArguments("--remote-allow-origins=*");
接下来 , 我们就可以运行了 (全程没动鼠标)
但是运行速度很快 , 嗖的一下就一闪而过了
我们可以使用 Thread.sleep();操作减慢运行
我们在每一条指令后面都让代码停止 2 秒
package com.ethan;
import org.openqa.selenium.By;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTask {
public void doAuto() throws InterruptedException {
// 1. 打开浏览器 (创建驱动实例)
ChromeDriver driver = new ChromeDriver();
Thread.sleep(2000);
// 2. 跳转到百度首页
driver.get("https://www.baidu.com/");
Thread.sleep(2000);
// 3. 定位到输入框,输入:蔡徐坤
// findElement 代表定位到页面内元素,参数可以使用 css 中的 唯一标识id,通过 By.cssSelector("#id")
// sendKeys 表示输入数据
driver.findElement(By.cssSelector("#kw")).sendKeys("蔡徐坤");
Thread.sleep(2000);
// 4. 定位到查询按钮
// findElement 代表定位到页面内元素,参数可以使用 css 中的 唯一标识id,通过 By.cssSelector("#id")
// click 就是模拟点击行为
driver.findElement(By.cssSelector("#su")).click();
Thread.sleep(2000);
// 5. 退出浏览器
driver.quit();
}
}
因为 Thread.sleep();方法要抛出异常 , 我们选择抛给上一层的方式 , 所以我们还需要在调用者那一层继续向上抛出异常
package com.ethan;
public class RunAutoTest {
public static void main(String[] args) throws InterruptedException {
AutoTask task = new AutoTask();
task.doAuto();
}
}
接下来再运行代码
这样 , 一个最简单的自动化代码就完成了
主要需要五个步骤 :
- 创建驱动实例 , 创建会话
- 访问网站
- 查找元素
- 操作元素
- 结束会话
2.2 打开谷歌浏览器的开发者工具
- 鼠标右键 , 选择检查
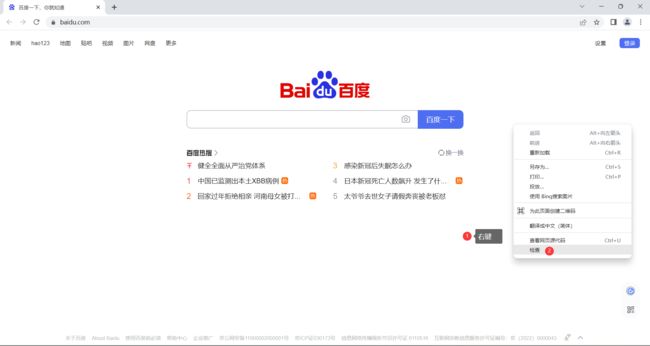
- 快捷键 :
- Ctrl + Shift + I
- F12 (笔记本电脑需要加 Fn)
2.3 selenium 常用方法
查找页面元素
findElement()
参数 : By 类 , 提供通过什么方式来查找元素
返回值 : WebElement
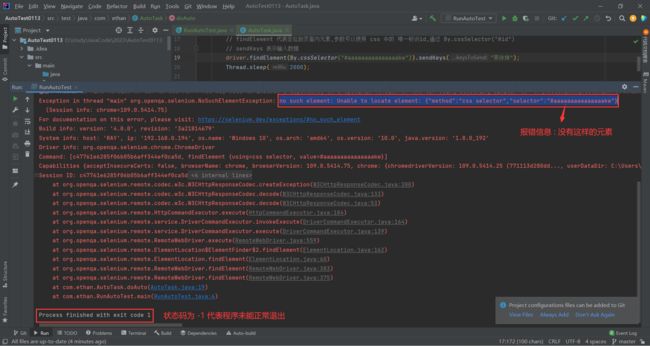
- 当元素可以在页面被找到的情况下 , 程序正确退出
- 当元素在页面找不到的情况下 , 程序执行报错
比如我们把代码中的 id 改错的时候 , 代码就找不到页面中的元素 , 就会发生错误 , 浏览器也不会自动关闭了

接下来 , 再去运行一下
我们浏览器并未能在输入框输入蔡徐坤 , 还没等到退出浏览器那一步 , 代码就报错了 .
findElements()

参数 : By 类 , 提供通过什么方式来查找元素
返回值 : List
这个返回值是什么意思呢 ?
我们来看一个案例
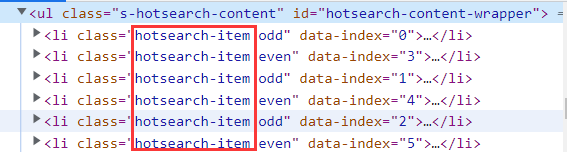
这个页面有 6 条热搜 , 我们想把这 6 条热搜导出来 , 就可以使用 findElements

我们可以发现 , 这六条热搜是以表格的形式展示的 , 我们就可以通过这六个 li 里面的 class 名称来获取到这个元素
package com.ethan;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.List;
public class AutoTask {
// 测试 findElements 方法的返回值
public void doFindElements() throws InterruptedException {
// 1. 打开浏览器 (创建驱动实例)
ChromeDriver driver = new ChromeDriver();
Thread.sleep(2000);
// 2. 跳转到百度首页
driver.get("https://www.baidu.com/");
Thread.sleep(2000);
// 3. 定位到百度热搜
List<WebElement> list = driver.findElements(By.className("hotsearch-item"));
for (WebElement e : list) {
System.out.println(e.getText());// 使用 getText() 可以打印信息
}
// 4. 关闭浏览器
driver.quit();
}
}
运行一下程序
热搜信息就被我们导出到了控制台上
如果单纯使用 findElement 的话 , 就只能获取到一个元素
元素的定位
By 类
我们之前的代码当中 , #后面的那个特别代码我们一直都不知道是怎么来的 , 这回就给大家介绍了
我们可以使用 By.的方式调用不同的定位元素方法
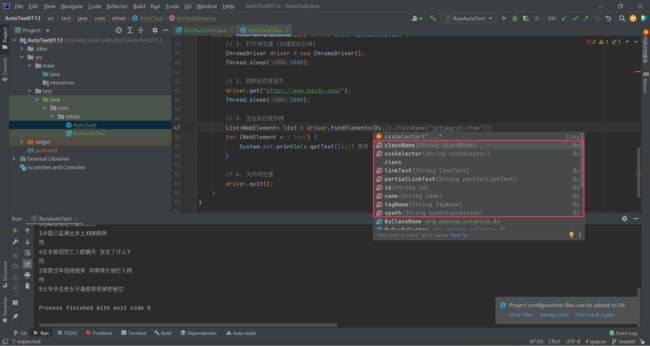
其中我们最常用的就是两种定位方式
selector
selector 分为基础选择器和复合选择器
他的功能就是选中页面中指定的标签元素
比如我们之前搜索蔡徐坤的样例
这个 #kw 和 # su 是从哪里来的呢 ?
打开开发者工具 , 定位到具体元素

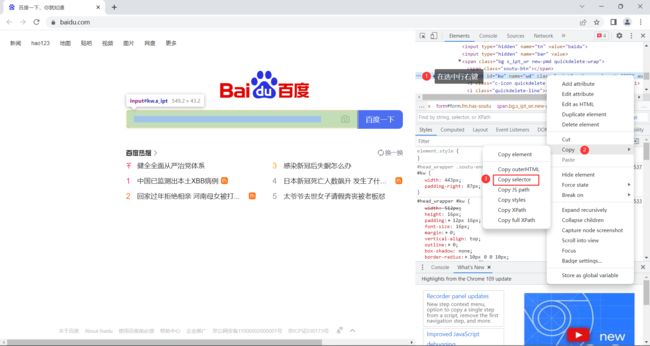
这样 #kw 就被找到了 , 我们就可以通过代码唯一确定一个元素了
xpath
我们先来看 xpath 是什么东西
![]()
它的功能也是定位页面元素位置的
语法 :
- 层级 :
- 子级 : /
- 跳级 : //
- 属性 : @
- 函数 : contains()
那他跟 selector 有什么不同呢 ?
我们先来看一看搜索框的 xpath 是什么 ?

/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input
这其实就跟我们 html 的 DOM 树类似
接下来 , 通过 XPath 的方式定位元素
package com.ethan;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.List;
public class AutoTask {
public void doAuto() throws InterruptedException {
// 1. 打开浏览器 (创建驱动实例)
ChromeDriver driver = new ChromeDriver();
Thread.sleep(2000);
// 2. 跳转到百度首页
driver.get("https://www.baidu.com/");
Thread.sleep(2000);
// 3. 定位到输入框,输入:蔡徐坤
// findElement 代表定位到页面内元素,参数可以使用 css 中的 唯一标识id,通过 By.cssSelector("#id")
// sendKeys 表示输入数据
driver.findElement(By.xpath("/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input")).sendKeys("蔡徐坤");
// driver.findElement(By.cssSelector("#kw")).sendKeys("蔡徐坤");
Thread.sleep(2000);
// 4. 定位到查询按钮
// findElement 代表定位到页面内元素,参数可以使用 css 中的 唯一标识id,通过 By.cssSelector("#id")
// click 就是模拟点击行为
driver.findElement(By.cssSelector("#su")).click();
Thread.sleep(2000);
// 5. 退出浏览器
driver.quit();
}
}
但是你发没发现 , 我们刚才选择的是 Copy Full XPath
那直接复制 XPath 呢 ?

//*[@id="kw"]
这就是跳级 , 意思就是我们不需要再页面上一层一层往下找 , 我们只需要跳过去查找固定元素
其中我们还使用了 @ 符号 , 他代表属性 id 能够定位到我们的 kw(输入框元素按钮)
当然 , 子级和跳级也可以进行嵌套
那么既然 selector 和 xpath 都能定位到页面元素 , 那他们有什么区别呢 ?
自动化测试中 , 要求元素的定位必须要唯一
比如我们页面中 , 有这样的元素
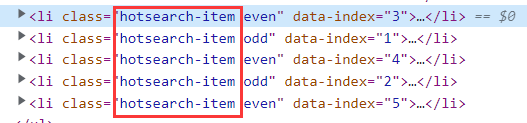
如果我们在代码中定位到这个元素 , 虽然程序能够正常执行 , 但是不知道定位到哪个 li 上面去了 , 所以我们需要唯一确定一个元素路径
但是手动在页面上赋值 selector 或者 xpath 元素不一定是唯一的 , 需要我们进行手动修改到唯一
比如 :
/html/body/div[1]/div[1]/div[5]/div/div/div[3]/ul/

我们现在定位到的是最外层的 ul
如果我们要定位到编号为 4 的新闻呢 ?
我们就可以添加内容到 xpath 中
/html/body/div[1]/div[1]/div[5]/div/div/div[3]/ul/li[4]

再举个例子 :
我们定位到页面当中的新闻元素 , 复制他的 XPath , 然后 Ctrl + F 打开搜索 , 输入刚才复制的 XPath , 就可以发现这是一个唯一定位的元素了
但是有可能 XPath 并不是唯一定位的 , 就需要我们手动调整
我们先来看这条 XPath 的意思吧
//*[@id="hotsearch-content-wrapper"]/li[2]/a/span[2]
2.4 常见的元素操作
对元素的操作前提 : 能够找到元素
输入文本 : sendKeys
输入文本的大前提是获取到输入框元素 , 使用 driver.findElement(By.cssSelector(“”)); 就可以定位到元素 , 他的返回值是 WebElement

首先去页面获取输入框元素 , 然后填写到 driver.findElement(By.cssSelector(“”)); 的括号中
接下来就是输入数据 , 使用 sendKeys 输入元素
package com.ethan2;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void baseControl() throws InterruptedException {
driver.get("https://www.baidu.com");
Thread.sleep(2000);// 为了避免页面过快,让页面操作的慢一点
// 具体的操作
WebElement webElement = driver.findElement(By.cssSelector("#kw"));
webElement.sendKeys("蔡徐坤");
Thread.sleep(2000);
// 退出浏览器
driver.quit();
}
}
接下来 , 我们调用 AutoTest 中的 baseController 方法
package com.ethan2;
public class RunAutoTest {
public static void main(String[] args) throws InterruptedException {
AutoTest autoTest = new AutoTest();
autoTest.baseControl();
}
}
运行一下
这样文本就输入进去了
其实我们还可以简写
package com.ethan2;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void baseControl() throws InterruptedException {
driver.get("https://www.baidu.com");
Thread.sleep(2000);
// 具体的操作
driver.findElement(By.cssSelector("#kw")).sendKeys("蔡徐坤");
Thread.sleep(2000);
// 退出浏览器
driver.quit();
}
}
注意 : sendKeys 仅适用于文本字段和内容可编辑的元素
比如 : 我们定位到百度一下的按钮 , 然后尝试输入呢 ? 虽然这是个离谱的行为 , 但是咱们试一下
虽然他也没报错 , 但是他也没成功
我们定位到 #su的时候 , Ctrl + F 看一下
他定位到了 4 个

但是其实这四个只有 1 个是有用的
其余三个都是 css 代码 , 前端代码里面可能存在其他的代码命令导致关键词重复 , 但是不要担心 . 复制出来的 css id 一定是唯一的
点击按钮 : click()
点击按钮的前提还是要定位到元素
package com.ethan2;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void baseControl() throws InterruptedException {
driver.get("https://www.baidu.com");
Thread.sleep(2000);
// 具体的操作
driver.findElement(By.cssSelector("#kw")).sendKeys("蔡徐坤");
driver.findElement(By.cssSelector("#su")).click();
Thread.sleep(2000);
// 退出浏览器
driver.quit();
}
}
提交 (不点击 , 通过回车键提交) : submit
package com.test;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.edge.EdgeDriver;
import org.openqa.selenium.edge.EdgeOptions;
import java.util.List;
public class AutoTask {
// 创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void doAuto() throws InterruptedException {
// 1. 打开百度首页
driver.get("https://www.baidu.com/");
// 2. 获取输入框对象
driver.findElement(By.cssSelector("#kw")).sendKeys("徐佳莹");
// 3. 获取搜索按钮
driver.findElement(By.cssSelector("#su")).submit();
// 4. 让页面停驻 3s
Thread.sleep(3000);
// 5. 退出浏览器
driver.quit();
}
}
submit 能使用的场景非常少 , 仅适用于表单元素 , selenium 官方也不推荐使用 submit() 方法 , 可以使用 click() 替代
能用回车的就能用点击代替 , 但是使用点击的就不一定能用回车代替
比如这个按钮 :
清除 : clear
假如输入框本身就有文本 , 而且还是错误的 , 我们就可以使用 clear 清除掉当前文本重新输入
package com.ethan2;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
/**
* 输入文本 + 点击按钮
* @throws InterruptedException
*/
public void baseControl() throws InterruptedException {
driver.get("https://www.baidu.com");
Thread.sleep(2000);
// 具体的操作
driver.findElement(By.cssSelector("#kw")).sendKeys("鸡哥");
Thread.sleep(2000);
driver.findElement(By.cssSelector("#kw")).clear();
Thread.sleep(2000);
driver.findElement(By.cssSelector("#kw")).sendKeys("蔡徐坤");
Thread.sleep(2000);
// 退出浏览器
driver.quit();
}
}
其实 clear 在自动化中用得不多 , 可能的使用场景就是频繁测试输入框是否可以重复输入
获取文本 : getText()
package com.ethan2;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void baseControl() throws InterruptedException {
// 1. 获取到百度首页
driver.get("https://www.baidu.com");
// 2. 获取到 "更多" 元素
String content = driver.findElement(By.cssSelector("#s-top-left > div > a")).getText();
// 3. 打印一下获取到的值
System.out.println(content);
Thread.sleep(3000);
// 4. 退出浏览器
driver.quit();
}
}
那我们在页面上看到的所有文本 , 都是可以获取到的嘛 ?
我们获取一下 百度一下 按钮上的文字
package com.ethan2;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void baseControl() throws InterruptedException {
driver.get("https://www.baidu.com");
Thread.sleep(2000);
// 具体的操作
String text = driver.findElement(By.cssSelector("#su")).getText();
System.out.println("应该打印的: 百度一下");
System.out.println("实际打印的: " + text);
Thread.sleep(2000);
//
// 退出浏览器
driver.quit();
}
}
并未获取到 , 这是怎么回事 , 我们看一下对应的前端代码
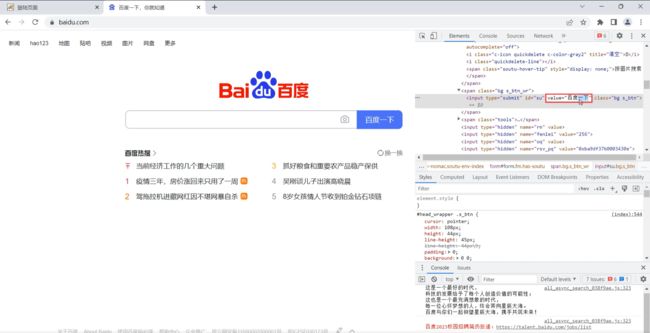
如果我们就想获取到属性里面对应的值怎么办呢 ?
获取属性对应的值 : getAttribute()
使用 getAttribute() 方法 , 获取属性对应的值
package com.ethan2;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
/**
* 输入文本 + 点击按钮
* @throws InterruptedException
*/
public void baseControl() throws InterruptedException {
driver.get("https://www.baidu.com");
Thread.sleep(2000);
// 具体的操作
System.out.println(driver.findElement(By.cssSelector("#su")).getAttribute("value"));
System.out.println(driver.findElement(By.cssSelector("#su")).getAttribute("type"));
System.out.println(driver.findElement(By.cssSelector("#su")).getAttribute("id"));
System.out.println(driver.findElement(By.cssSelector("#su")).getAttribute("class"));
Thread.sleep(2000);
//
// 退出浏览器
driver.quit();
}
}
获取标题 : getTitle() 获取 URL : getCurrentUrl()
访问一个页面 , 肯定会有页面标题和 URL 的 , 我们就可以匹配一下 title 和 URL 中是否相同
或者测试我们的博客系统 , 登陆之后就进入了主页 , 那么我们怎么知道该页面的 URL 和 标题对不对呢
我们就可以通过 getTitle() 获取到页面标题 , 通过 getCurrentUrl() 获取到页面的 URL , 我们来试一下
package com.ethan2;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void baseControl() throws InterruptedException {
// 1. 打开百度首页
driver.get("https://www.baidu.com/");
// 2. 在输入关键词之前先获取一下标题跟 URL
System.out.println("输入关键字之前的标题: " + driver.getTitle());
System.out.println("输入关键字之前的 URL: " + driver.getCurrentUrl());
// 3. 输入关键字
driver.findElement(By.cssSelector("#kw")).sendKeys("徐佳莹");
driver.findElement(By.cssSelector("#su")).click();
// 4. 防止页面太快, Selenium 获取不到最新结果
Thread.sleep(2000);
// 5. 在输入关键词之后获取一下标题跟 URL
System.out.println("输入关键字之后的标题: " + driver.getTitle());
System.out.println("输入关键字之后的 URL: " + driver.getCurrentUrl());
// 6. 退出浏览器
driver.quit();
}
}
实际上这两个操作用的也是不多的
常见的操作就是输入文本 + 点击按钮
2.5 窗口
窗口大小的设置
我们每次打开自动化脚本 , 都显示的是一个正方形的窗口 , 我们可以设置窗口大小
package com.ethan2;
import org.openqa.selenium.By;
import org.openqa.selenium.Dimension;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void windowSize() {
// 1. 打开百度首页
driver.get("https://www.baidu.com");
// 2. 设置窗格大小为最大化
driver.manage().window().maximize();
Thread.sleep(2000);
// 3. 设置窗格大小为最小化
driver.manage().window().minimize();
Thread.sleep(2000);
// 4. 设置窗格大小为全屏
driver.manage().window().fullscreen();
Thread.sleep(2000);
// 5. 设置窗格大小为指定值
driver.manage().window().setSize(new Dimension(1024, 1024));
Thread.sleep(2000);
// 6. 退出浏览器
driver.quit();
}
}
窗口的切换
我们现在有一个这样的案例 , 访问到百度首页 , 然后跳转到图片链接 , 获取到图片链接中的 “百度一下”
我们也看到了 , 程序报错 , 浏览器没退出

报了没有这样的元素的异常 , 难不成我们刚才复制的 id 不对吗
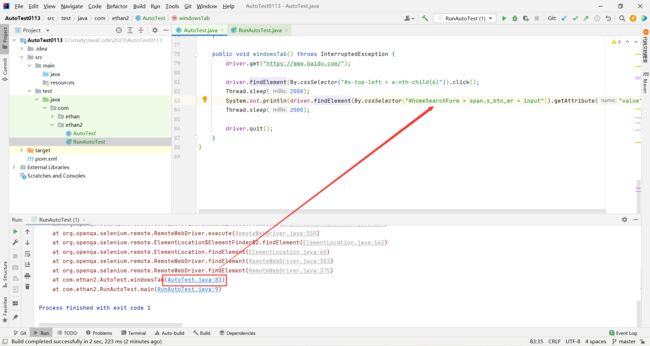

这不也是一对一的吗 , 有啥不对的 ?
实际上原因不在于此 , 是因为我们现在有两个标签页 , 我们虽然知道有两个标签页 , 但是计算机不知道 , 他在之前的页面获取 “图片链接中的百度一下” 当然找不到 , 我们需要告诉脚本我们要查找的是新标签页
当浏览器每次打开一个标签页的时候 , 会自动的给每个标签页进行标识 , 这就是句柄
我们就可以通过每个标签页句柄的不同来切换到不同的标签页
我们首先打印两个标签页的句柄 , 获取句柄使用 getWindowHandles
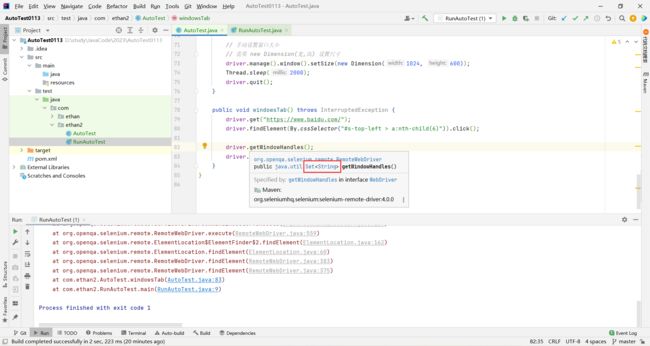
他的返回值是 Set 集合 , 我们也可以用 Set 接收
package com.ethan2;
import org.openqa.selenium.By;
import org.openqa.selenium.Dimension;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.Set;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void windowsTab() throws InterruptedException {
driver.get("https://www.baidu.com/");
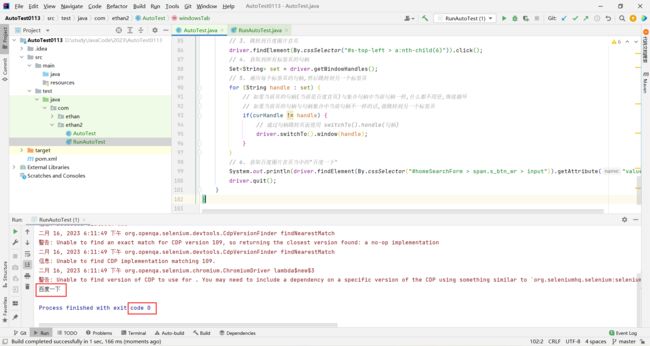
driver.findElement(By.cssSelector("#s-top-left > a:nth-child(6)")).click();
Set<String> set = driver.getWindowHandles();
for(String tmp : set) {
System.out.println(tmp);
}
driver.quit();
}
}
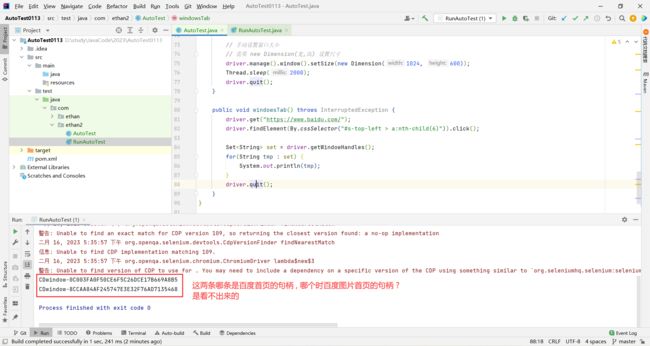
那分不清哪个是谁的句柄 , 我们就可以获取当前页面的句柄 , 使用 getWindowHandle (跟上面的就差一个 s)
package com.ethan2;
import org.openqa.selenium.By;
import org.openqa.selenium.Dimension;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.Set;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void windowsTab() throws InterruptedException {
driver.get("https://www.baidu.com/");
String curHandle1 = driver.getWindowHandle();
System.out.println("百度页面的句柄: " + curHandle1);
driver.findElement(By.cssSelector("#s-top-left > a:nth-child(6)")).click();
String curHandle2 = driver.getWindowHandle();
System.out.println("百度图片页面的句柄: " + curHandle2);
driver.quit();
}
}
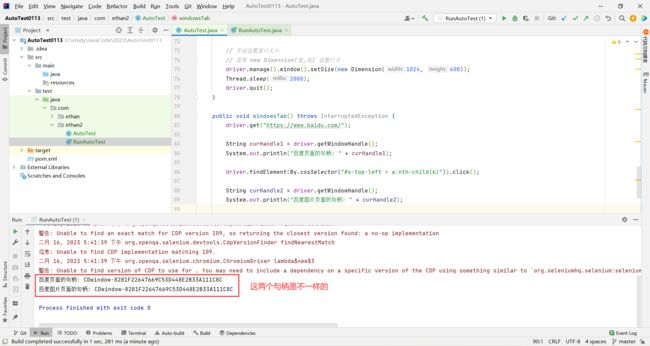
获取到百度图片的句柄了 , 那我接下来怎么跳转到百度图片呢 ?
我们需要先获取到当前页面的句柄 , 再获取所有标签页的句柄
遍历所有句柄 (相当于遍历所有标签页) , 如果当前页面跟目前标签页的句柄一样的时候 , 继续遍历 . 当前页面的句柄与目前标签页的句柄不一样的时候 , 就跳转到新标签页
package com.ethan2;
import org.openqa.selenium.By;
import org.openqa.selenium.Dimension;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.Set;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void windowsTab() throws InterruptedException {
// 1. 跳转到百度首页
driver.get("https://www.baidu.com/");
// 2. 获取百度首页的句柄
String curHandle = driver.getWindowHandle();
// 3. 跳转到百度图片首页
driver.findElement(By.cssSelector("#s-top-left > a:nth-child(6)")).click();
// 4. 获取到所有标签页的句柄
Set<String> set = driver.getWindowHandles();
// 5. 遍历每个标签页的句柄,然后跳转到另一个标签页
for (String handle : set) {
// 如果当前页的句柄(当前是百度首页)与集合句柄中当前句柄一样,什么都不用管,继续循环
// 如果当前页的句柄与句柄集合中当前句柄不一样的话,就跳转到另一个标签页
if(curHandle != handle) {
// 通过句柄跳转页面使用 switchTo().handle(句柄)
driver.switchTo().window(handle);
}
}
// 6. 获取百度图片首页当中的"百度一下"
System.out.println(driver.findElement(By.cssSelector("#homeSearchForm > span.s_btn_wr > input")).getAttribute("value"));
// 7. 退出浏览器
driver.quit();
}
}
2.6 屏幕截图
先举个案例 :
我们可以看到 , 代码报错了
报错的信息是没有对应的元素的异常 , 我们也去控制台搜索了一下 , 确实 1/1 没啥问题 , 那可能不是代码的事 .
我们这个时候就可以截图保存证据了
package com.ethan2;
import org.apache.commons.io.FileUtils;
import org.openqa.selenium.By;
import org.openqa.selenium.Dimension;
import org.openqa.selenium.OutputType;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.io.File;
import java.io.IOException;
import java.util.Set;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void screenShot() throws IOException, InterruptedException {
// 1. 访问百度首页
driver.get("https://www.baidu.com/");
// 2. 输入蔡徐坤
driver.findElement(By.cssSelector("#kw")).sendKeys("蔡徐坤");
// 3. 点击百度一下
driver.findElement(By.cssSelector("#su")).click();
Thread.sleep(3000);
// 4. 这个位置可能有问题,截图看一下是怎么回事
// 获取当前屏幕截图
File curFile = driver.getScreenshotAs(OutputType.FILE);
// 指定保存路径
String fileName = "my.png";
// 将截图保存到指定路径中
FileUtils.copyFile(curFile,new File(fileName));
// 5. 打印蔡徐坤的值
System.out.println(driver.findElement(By.cssSelector("#\\31 > div > div > div > div > div.cos-row.row-text_Johh7.row_5y9Az > div > a > div > p > span > span")).getText());
// 6. 退出浏览器
driver.quit();
}
}
2.7 等待操作
程序执行的速度要比页面渲染的速度要快很多 , 有可能页面还没加载好 , 程序就结束了
实际上 , 在 selenium 中 , 不光只有 Thread.sleep , 有四种等待 : 强制等待 隐式等待 显示等待 流畅等待
强制等待 Thread.sleep()
程序走到阻塞等待的位置 , 直接就往下走不了了 , 必须等到 Thread.sleep 结束之后程序才能继续执行 , 会用到但是不多
这是因为我们写过的每一个自动化代码中 , 每一个自动化方法就是一个自动化测试用例
假如一个用例就需要 10s , 那 200 个用例就需要 2000s , 这等待时间忒长了 , 公司只能忍耐你 10s~几分钟之间 , 所以频繁使用 Thread.sleep 指定不行
隐式等待

隐式等待作用在自动化的生命周期中 , 每写一条自动化 , 就会检查这个元素对应的模块在不在
比如 : 我们会检查 #kw 对应的输入框在不在 , 输入框加载出来了就立马输入蔡徐坤 , 是一个动态等待的过程
我们还是用上次的例子 :
package com.ethan3;
import org.openqa.selenium.By;
import org.openqa.selenium.chrome.ChromeDriver;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
// 阻塞等待
public void blockingWait() {
// 1. 跳转到百度首页
driver.get("https://www.baidu.com/");
// 2. 定位到输入框,输入 蔡徐坤
driver.findElement(By.cssSelector("#kw")).sendKeys("蔡徐坤");
// 3. 定位到百度一下,模拟点击操作
driver.findElement(By.cssSelector("#kw")).click();
// 4. 获取到 蔡徐坤 这三个字
System.out.println(driver.findElement(By.cssSelector("#\\31 > div > div > div > div > div.cos-row.row-text_Johh7.row_5y9Az > div > a > div > p > span > span")));
// 5. 退出浏览器
driver.quit();
}
}
目前这段代码会因为执行过快产生错误
我们就可以动态调整等待时间 , 就可以使用隐式等待了
语法 : driver.manage().timeouts().implicitlyWait(Duration.of方法());
package com.ethan3;
import org.openqa.selenium.By;
import org.openqa.selenium.chrome.ChromeDriver;
import java.time.Duration;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
// 阻塞等待
public void blockingWait() {
// 1. 设置隐式等待
driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(3));
// 2. 打开百度首页
driver.get("https://www.baidu.com/");
// 3. 获取输入框,搜索徐佳莹
driver.findElement(By.cssSelector("#kw")).sendKeys("徐佳莹");
// 4. 点击搜索按钮
driver.findElement(By.cssSelector("#su")).click();
// 5. 获取页面当中的元素
System.out.println(driver.findElement(By.cssSelector("#\\31 > div > div > div > div > div.cos-row.row-text_Johh7.row_5y9Az > div > a > div > p > span > span")).getText());
// 6. 退出浏览器
driver.quit();
}
}
在代码中 , 隐式等待是会作用于 driver 的整个生命周期 , 只需要在刚开始写上就好
代码每走一步 , 隐式等待都会起到作用
执行的流程就是 : 最刚开始会访问百度 , 找到输入框会立即输入 , 然后去找点击按钮 , 找到会立即点击 …
如果我们代码中的元素并不存在 , 隐式等待会一直轮询判断元素是否存在 , 如果不存在就等待设置好的时间里不断地进行轮询 , 直到元素能够被找到
ofSeconds(3) 就是设置好的等待时间 , 这 3s 期间会一直轮询 , 如果还找不到就直接报错 ~
来运行一下 , 因为我们使用的是隐式等待 , 整体进度就会变得非常快
显式等待

虽然隐式等待速度变快了很多 , 但是在每句话上都需要等待也是需要浪费时间的 , 那么这种情况就需要我们使用显式等待了
显式等待的创建有些许麻烦
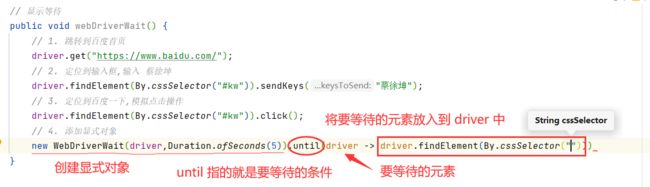
我们首先需要创建显式等待类

目前为止 , 我们就刚刚创建出显式类型的对象

接下来 , 还需要指定等待什么条件位置
package com.ethan3;
import org.openqa.selenium.By;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.time.Duration;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
// 显示等待
public void webDriverWait() {
// 1. 跳转到百度首页
driver.get("https://www.baidu.com/");
// 2. 获取输入框,搜索徐佳莹
driver.findElement(By.cssSelector("#kw")).sendKeys("徐佳莹");
// 3. 点击搜索按钮
driver.findElement(By.cssSelector("#su")).click();
// 4. 设置显式等待
// 其中的 tool 可以随意替换
new WebDriverWait(driver,Duration.ofSeconds(3)).until(tool -> tool.findElement(By.cssSelector("#\\31 > div > div > div > div > div.cos-row.row-text_Johh7.row_5y9Az > div > a > div > p > span > span")));
// 5. 获取页面当中的元素
System.out.println(driver.findElement(By.cssSelector("#\\31 > div > div > div > div > div.cos-row.row-text_Johh7.row_5y9Az > div > a > div > p > span > span")).getText());
// 6. 退出浏览器
driver.quit();
}
}
运行一下 , 因为不像隐式等待每一条语句都在等待 , 所以速度更快了
注意 : 显示等待和隐式等待不能一起使用 , 同时使用可能会出现意想不到的等待结果
有的时候隐式等待和显示等待不生效或者达不到目的的时候我们就可以加上强制等待
流畅等待
流畅等待可以设置更多的参数 , 比如设置多长时间轮询一遍对应的元素是否出现 .
流畅等待使用的不是太多
2.8 浏览器导航
比如我们在百度搜索蔡徐坤

左上角的这个标识 , 指的就是浏览器导航
package com.ethan3;
import org.openqa.selenium.By;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.time.Duration;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
// 浏览器的相关操作
public void browserOper() throws InterruptedException {
// 1. 跳转到百度首页
driver.get("https://www.baidu.com/");
Thread.sleep(3000);
// 2. 回退到浏览器的上一个界面
driver.navigate().back();
Thread.sleep(3000);
// 3. 前进到浏览器的下一个界面
driver.navigate().forward();
Thread.sleep(3000);
// 4. 刷新
driver.navigate().refresh();
Thread.sleep(3000);
// 5. 退出
driver.quit();
}
}
其中 , get 方法其实也算是浏览器的操作 , 因为他也是操控浏览器跳转到新的页面 , 那 get 方法为啥不用 navigate() 调用了呢 ?
实际上是因为 get 方法也是简写的 , 也可以还原回去
package com.ethan3;
import org.openqa.selenium.By;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.time.Duration;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
// 浏览器的相关操作
public void browserOper() throws InterruptedException {
// 1. 跳转到百度首页
// driver.get("https://www.baidu.com/");
driver.navigate().to("https://www.baidu.com/");
Thread.sleep(3000);
// 2. 回退到浏览器的上一个界面
driver.navigate().back();
Thread.sleep(3000);
// 3. 前进到浏览器的下一个界面
driver.navigate().forward();
Thread.sleep(3000);
// 4. 刷新
driver.navigate().refresh();
Thread.sleep(3000);
// 5. 退出
driver.quit();
}
}
2.9 弹窗
弹窗主要分为三种类型 :
- 警告弹窗

- 确认弹窗

- 提示弹窗

那举个栗子 : 针对于提示弹窗来说 , 我们想要定位到弹窗里面的输入框 , 但是这并不是一个 HTML 元素 , 并不能获取到该元素 , 所以按照之前的步骤是不好使的
处理弹窗的步骤 :
-
先将 driver 对象作用到弹窗上 (切换到弹窗) : driver.switchTo.alert()
-
选择 确认/取消/提示弹窗输入文本 :
-
- 确认 : accept()
- 取消 : dismiss()
- 提示弹窗输入文本 : sendKeys()
写个代码看看具体咋回事吧
我们先把测试文件放到这里
selenium-html.rar
package com.ethan3;
import org.openqa.selenium.Alert;
import org.openqa.selenium.By;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.time.Duration;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void alertContro() throws InterruptedException {
// 注意:这里复制的URL是浏览器当中的 URL,不是文件位置
// err:driver.get("D:\\study\\JavaCode\\selenium_demo\\Prompt.html");
driver.get("file:///D:/study/JavaCode/selenium_demo/alert.html");
// 打开弹窗
driver.findElement(By.cssSelector("#tooltip")).click();
Thread.sleep(2000);
// 切换到弹窗
Alert alert = driver.switchTo().alert();
Thread.sleep(2000);
// 3. 输入框输入
// alert.sendKeys("蔡徐坤");
// Thread.sleep(2000);
// 1. 点击确定
// alert.accept();
// Thread.sleep(2000);
// 2. 点击退出
// alert.dismiss();
// Thread.sleep(2000);
driver.quit();
}
}
但是 , 由于网络或页面加载等原因 , 弹出框可能需要一些时间才能完全加载出来 . 因此 , 在尝试切换到弹出框之前 , 可以使用等待机制等待一段时间 , 确保弹出框已经加载完成
我们可以使用 WebDriverWait 类和 ExpectedConditions 类结合来实现等待弹出框的加载
那这里是一个示范代码
import org.openqa.selenium.Alert;
import org.openqa.selenium.NoAlertPresentException;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
public class WaitForAlertExample {
public static void main(String[] args) {
WebDriver driver = new ChromeDriver();
// 等待弹出框加载最多 10 秒
WebDriverWait wait = new WebDriverWait(driver, 10);
try {
// 等待弹出框出现并获取它
Alert alert = wait.until(ExpectedConditions.alertIsPresent());
// 在此处处理弹出框
// ...
// 关闭弹出框
alert.accept();
} catch (NoAlertPresentException e) {
System.out.println("未找到弹出框");
}
driver.quit();
}
}
2.10 选择框
选择框的话 , 想要定位到下拉框里面的元素是定位不到的
选项既然通过前端访问不到 , 那我们就有自己的访问方式
选项的选择方式主要有三种
- 根据文本来选择
- 根据属性值来选择
- 根据序号来选择

我们先模拟一下上面三种方法
package com.ethan3;
import org.openqa.selenium.Alert;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.openqa.selenium.support.ui.Select;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.time.Duration;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void selectionBox() throws InterruptedException {
// 1. 获取页面
// 注意:从浏览器的URL中复制的
driver.get("file:///D:/study/JavaCode/selenium_demo/select.html");
// 2. 点击下拉框
WebElement webElement = driver.findElement(By.cssSelector("#ShippingMethod"));
// 3. 创建选择框对象
Select select = new Select(webElement);
Thread.sleep(1000);
// 根据文本来选择
// select.selectByVisibleText("UPS Next Day Air ==> $12.51");
// 根据属性值来选择
// select.selectByValue("11.61");
// 根据序号来选择
// //*[@id="ShippingMethod"]
select.selectByIndex(0);
Thread.sleep(2000);
driver.quit();
}
}
2.11 执行脚本
我们目前编写的代码是 Java 语言 , 但是浏览器并不认识 Java 语言啊 , 所以需要借助驱动把 Java 语言编译一下发送给浏览器 , 浏览器解析之后就会执行一系列操作了
但是有可能浏览器有些时候就不认识脚本了 , 发生错误了我们也不好排查 , 我们就可以借助 JS 原生脚本帮我们
执行脚本使用 executeScript() , 其中的参数就是 JS 代码
我们可以先在控制台模拟一下 JS 代码

接下来 , 确定这两个 JS 代码没问题之后 , 我们就可以挪到我们的代码中使用了
package com.ethan3;
import org.openqa.selenium.Alert;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.support.ui.Select;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.time.Duration;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void scriptControl() throws InterruptedException {
driver.get("https://image.baidu.com/");
// 置底(值尽量设的大一些)
driver.executeScript("document.documentElement.scrollTop=500");
Thread.sleep(2000);
// 置顶(0就是顶部)
driver.executeScript("document.documentElement.scrollTop=0");
Thread.sleep(2000);
driver.quit();
}
}

package com.ethan3;
import org.openqa.selenium.Alert;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.support.ui.Select;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.time.Duration;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void scriptControl() throws InterruptedException {
driver.get("https://image.baidu.com/");
driver.executeScript("var inputBox = document.querySelector('#kw');inputBox.value = '蔡徐坤'");
Thread.sleep(2000);
driver.quit();
}
}
有些场景下 , sendKeys 或者 click 就是不好使 , 我们就可以借助 executeScript 来使用 JS 原生代码帮我们实现
2.12 非常特殊场景 : 上传文件
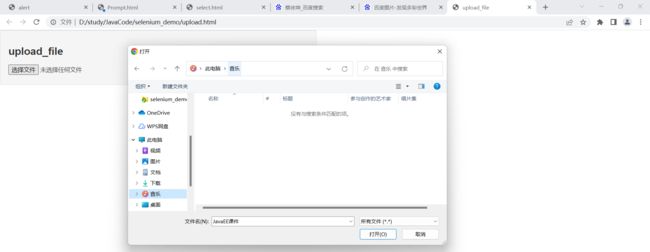
我们 selenium 能操作页面元素 , 但是这个文件资源管理器他肯定是控制不了的
但是我们可以把文件名和文件路径通过 sendKeys 直接定位到该文件
package com.ethan3;
import org.openqa.selenium.Alert;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.support.ui.Select;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.time.Duration;
public class AutoTest {
// 先创建驱动对象
ChromeDriver driver = new ChromeDriver();
public void fileUploadControll() throws InterruptedException {
driver.get("file:///D:/study/JavaCode/selenium_demo/upload.html");
Thread.sleep(1000);
driver.findElement(By.cssSelector("body > div > div > input[type=file]")).sendKeys("D:\\study\\JavaCode\\selenium_demo\\select.html");
Thread.sleep(1000);
driver.quit();
}
}
2.13 浏览器的参数设置
在日常工作过程中 , 测试人员将自动化部署在机器上自动执行 , 并不会去盯着每次跟我们的预期一不一样 , 只会去查看结果
实际上正常情况下我们就给他隐藏在状态栏中 , 该干啥干啥
不像咱们还看一下运行效果
所以真正使用的时候 , 大家都使用无头模式
无头模式 : 程序在自动的执行 , 并不会看到运行过程
package com.ethan3;
import org.openqa.selenium.Alert;
import org.openqa.selenium.By;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.openqa.selenium.support.ui.Select;
import org.openqa.selenium.support.ui.WebDriverWait;
import java.time.Duration;
public class AutoTest {
// 百度搜索蔡徐坤
public void paramsControl() {
// 先创建选项对象
ChromeOptions options = new ChromeOptions();
// 通过选项对象我们就可以设置浏览器的参数
options.addArguments("-headless");
// 创建浏览器对象
ChromeDriver driver = new ChromeDriver(options);
driver.get("https://www.baidu.com/");
driver.findElement(By.cssSelector("#kw")).sendKeys("蔡徐坤");
driver.findElement(By.cssSelector("#su")).click();
driver.quit();
}
}
注意 : 浏览器的参数设置需要在创建浏览器对象之前