Docker-compose快速搭建 Prometheus+Grafana监控系统
一、说明
Prometheus负责收集数据,Grafana负责展示数据。其中采用Prometheus 中的 Exporter含:
1)Node Exporter,负责收集 host 硬件和操作系统数据。它将以容器方式运行在所有 host 上。
2)cAdvisor,负责收集容器数据。它将以容器方式运行在所有 host 上。
3)Alertmanager,负责告警。它将以容器方式运行在所有 host 上。
完整Exporter列表请参考:https://prometheus.io/docs/instrumenting/exporters/
repo所有文件下载地址
https://young1.lanzouf.com/b036xjdkf
密码:9ure
默认grafana登录地址:
http://ip:33000/login
admin/admin
二、安装docker,docker-compose
2.1 安装docker
先安装一个64位的Linux主机,其内核必须高于3.10,内存不低于1GB。在该主机上安装Docker。
# 卸载旧版本
yum -y remove docker docker-common docker-selinux docker-engine
# 安装依赖包
yum install -y yum-utils device-mapper-persistent-data lvm2
# 添加Docker软件包源
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 更新yum软件包索引
yum makecache fast
# 安装免费版的docker-ce
yum -y install docker-ce
# 启动
systemctl start docker
# 查看docker版本
docker version
# 开机启动
systemctl enable docker
# 查看Docker信息
docker info
配置阿里云镜像加速
登录 -》 控制台 -》 容器镜像服务 -》镜像加速器
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors" : [
"https://jkfdsf2u.mirror.aliyuncs.com",
"https://registry.docker-cn.com"
],
"insecure-registries" : [
"docker-registry.zjq.com"
],
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "10"
}
}
EOF
cat /etc/docker/daemon.json
sudo systemctl daemon-reload
sudo systemctl restart docker
2.2 安装docker-compose
curl -L "https://github.com/docker/compose/releases/download/1.29.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
解决报错 WARNING: IPv4 forwarding is disabled. Networking will not work.
1.解决方式:
第一步:在宿主机上执行echo "net.ipv4.ip_forward=1" >>/usr/lib/sysctl.d/00-system.conf
2.第二步:重启network和docker服务
[root@localhost /]# systemctl restart network && systemctl restart docker
3.第三步:验证是否成功
三、添加配置文件
mkdir -p /opt/prometheus/config
cd /opt/prometheus/config
2.1 添加prometheus.yml配置文件
vim prometheus.yml
sudo tee /opt/prometheus/config/prometheus.yml <<-'EOF'
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_timeout: 10s # scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ['192.168.8.110:9093']
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "node_down.yml"
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
- job_name: 'prometheus'
static_configs:
- targets: ['192.168.8.110:9090']
- job_name: 'cadvisor'
static_configs:
- targets: ['192.168.8.110:8080']
- job_name: 'node'
scrape_interval: 8s
static_configs:
- targets: ['192.168.8.110:9100']
EOF
prometheus.yml 配置文件参数详解
# global是一些常规的全局配置,这里只列出了两个参数:
global:
scrape_interval: 15s #每15s采集一次数据
evaluation_interval: 30s #每15s做一次告警检测
scrape_timeout: 10s # 每次 收集数据的 超时时间
# 当Prometheus和外部系统(联邦, 远程存储, Alertmanager)通信的时候,添加标签到任意的时间序列或者报警
external_labels:
monitor: codelab
foo: bar
# rule_files指定加载的告警规则文件,告警规则放到下面来介绍。
rule_files:
- "first.rules"
- "my/*.rules"
# 远程写入功能相关的设置
remote_write:
- url: http://remote1/push
write_relabel_configs:
- source_labels: [__name__]
regex: expensive.*
action: drop
- url: http://remote2/push
# 远程读取相关功能的设置
remote_read:
- url: http://remote1/read
read_recent: true
- url: http://remote3/read
read_recent: false
required_matchers:
job: special
# scrape_configs指定prometheus要监控的目标,这部分是最复杂的。在scrape_config中每个监控目标是一个job,但job的类型有很多种。可以是最简单的static_config,即静态地指定每一个目标。
scrape_configs:
- job_name: prometheus # 必须配置, 自动附加的job labels, 必须唯一
honor_labels: true # 标签冲突, true 为以抓取的数据为准 并 忽略 服务器中的, false 为 通过重命名来解决冲突
# scrape_interval is defined by the configured global (15s).
# scrape_timeout is defined by the global default (10s).
metrics_path: '/metrics'
# scheme defaults to 'http'.
# 文件服务发现配置 列表
file_sd_configs:
- files: # 从这些文件中提取目标
- foo/*.slow.json
- foo/*.slow.yml
- single/file.yml
refresh_interval: 10m # 刷新文件的 时间间隔
- files:
- bar/*.yaml
# 使用job名作为label的 静态配置目录 的 列表
static_configs:
- targets: ['localhost:9090', 'localhost:9191']
labels:
my: label
your: label
# 目标节点 重新打标签 的配置 列表. 重新标记是一个功能强大的工具,可以在抓取目标之前动态重写目标的标签集。 可以配置多个,按照先后顺序应用
relabel_configs:
- source_labels: [job, __meta_dns_name] # 从现有的标签中选择源标签, 最后会被 替换, 保持, 丢弃
regex: (.*)some-[regex] # 正则表达式, 将会提取source_labels中匹配的值
target_label: job # 在替换动作中将结果值写入的标签.
replacement: foo-${1} # 如果正则表达匹配, 那么替换值. 可以使用正则表达中的 捕获组
# action defaults to 'replace'
- source_labels: [abc] # 将abc标签的内容复制到cde标签中
target_label: cde
- replacement: static
target_label: abc
- regex:
replacement: static
target_label: abc
bearer_token_file: valid_token_file # 可选的, bearer token 文件的信息
- job_name: service-x
# HTTP basic 认证信息
basic_auth:
username: admin_name
password: "multiline\nmysecret\ntest"
scrape_interval: 50s # 对于该job, 多久收集一次数据
scrape_timeout: 5s
sample_limit: 1000 # 每次 收集 样本数据的限制. 0 为不限制
metrics_path: /my_path # 从目标 获取数据的 HTTP 路径
scheme: https # 配置用于请求的协议方案
# DNS 服务发现 配置列表
dns_sd_configs:
- refresh_interval: 15s
names: # 要查询的DNS域名列表
- first.dns.address.domain.com
- second.dns.address.domain.com
- names:
- first.dns.address.domain.com
# refresh_interval defaults to 30s.
# 目标节点 重新打标签 的配置 列表
relabel_configs:
- source_labels: [job]
regex: (.*)some-[regex]
action: drop
- source_labels: [__address__]
modulus: 8
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: 1
action: keep
- action: labelmap
regex: 1
- action: labeldrop
regex: d
- action: labelkeep
regex: k
# metric 重新打标签的 配置列表
metric_relabel_configs:
- source_labels: [__name__]
regex: expensive_metric.*
action: drop
- job_name: service-y
# consul 服务发现 配置列表
consul_sd_configs:
- server: 'localhost:1234' # consul API 地址
token: mysecret
services: ['nginx', 'cache', 'mysql'] # 被检索目标的 服务 列表. 如果不定义那么 所有 服务 都会被 收集
scheme: https
tls_config:
ca_file: valid_ca_file
cert_file: valid_cert_file
key_file: valid_key_file
insecure_skip_verify: false
relabel_configs:
- source_labels: [__meta_sd_consul_tags]
separator: ','
regex: label:([^=]+)=([^,]+)
target_label: ${1}
replacement: ${2}
- job_name: service-z
# 收集 数据的 TLS 设置
tls_config:
cert_file: valid_cert_file
key_file: valid_key_file
bearer_token: mysecret
- job_name: service-kubernetes
# kubernetes 服务 发现 列表
kubernetes_sd_configs:
- role: endpoints # 必须写, 必须是endpoints, service, pod, node, 或者 ingress
api_server: 'https://localhost:1234'
basic_auth: # HTTP basic 认证信息
username: 'myusername'
password: 'mysecret'
- job_name: service-kubernetes-namespaces
kubernetes_sd_configs:
- role: endpoints # 应该被发现的 kubernetes 对象 实体
api_server: 'https://localhost:1234' # API Server的地址
namespaces: # 可选的命名空间发现, 如果省略 那么所有的命名空间都会被使用
names:
- default
- job_name: service-marathon
# Marathon 服务发现 列表
marathon_sd_configs:
- servers:
- 'https://marathon.example.com:443'
tls_config:
cert_file: valid_cert_file
key_file: valid_key_file
- job_name: service-ec2
ec2_sd_configs:
- region: us-east-1
access_key: access
secret_key: mysecret
profile: profile
- job_name: service-azure
azure_sd_configs:
- subscription_id: 11AAAA11-A11A-111A-A111-1111A1111A11
tenant_id: BBBB222B-B2B2-2B22-B222-2BB2222BB2B2
client_id: 333333CC-3C33-3333-CCC3-33C3CCCCC33C
client_secret: mysecret
port: 9100
- job_name: service-nerve
nerve_sd_configs:
- servers:
- localhost
paths:
- /monitoring
- job_name: 0123service-xxx
metrics_path: /metrics
static_configs:
- targets:
- localhost:9090
- job_name: 測試
metrics_path: /metrics
static_configs:
- targets:
- localhost:9090
- job_name: service-triton
triton_sd_configs:
- account: 'testAccount'
dns_suffix: 'triton.example.com'
endpoint: 'triton.example.com'
port: 9163
refresh_interval: 1m
version: 1
tls_config:
cert_file: testdata/valid_cert_file
key_file: testdata/valid_key_file
# Alertmanager相关的配置
alerting:
alertmanagers:
- scheme: https
static_configs:
- targets:
- "1.2.3.4:9093"
- "1.2.3.5:9093"
- "1.2.3.6:9093"
2.2 添加邮件告警配置文件
添加配置文件alertmanager.yml,配置收发邮件邮箱
sudo tee /opt/prometheus/config/alertmanager.yml <<-'EOF'
#全局配置,比如配置发件人
global:
resolve_timeout: 5m # 处理超时时间,默认为5min
smtp_smarthost: 'smtp.qq.com:465' # 邮箱smtp服务器代理
smtp_from: '[email protected]' # 发送邮箱名称
smtp_auth_username: '[email protected]' # 发邮件的邮箱用户名,也就是你的邮箱
smtp_auth_password: 'cuwsscqllsnhgdjh' # 邮箱密码或授权码
smtp_require_tls: false #不进行tls验证
# 定义模板信息,可以自定义html模板,发邮件的时候用自己定义的模板内容发
templates:
- 'template/*.tmpl'
# 定义路由树信息,这个路由可以接收到所有的告警,还可以继续配置路由,比如project: zhidaoAPP(prometheus 告警规则中自定义的lable)发给谁,project: baoxian的发给谁
route:
group_by: ['alertname'] # 报警分组依据
group_wait: 10s # 最初即第一次等待多久时间发送一组警报的通知
group_interval: 60s # 在发送新警报前的等待时间
repeat_interval: 1h # 发送重复警报的周期 对于email配置中,此项不可以设置过低,否则将会由于邮件发送太多频繁,被smtp服务器拒绝
receiver: 'email' # 发送警报的接收者的名称,以下receivers name的名称
# 定义警报接收者信息
receivers:
- name: 'email' # 路由中对应的receiver名称
email_configs: # 邮箱配置
- to: '[email protected]' # 接收警报的email配置
#html: '{{ template "test.html" . }}' # 设定邮箱的内容模板
EOF
cat /opt/prometheus/config/alertmanager.yml
global:
smtp_smarthost: 'smtp.163.com:25' #163服务器
smtp_from: '[email protected]' #发邮件的邮箱
smtp_auth_username: '[email protected]' #发邮件的邮箱用户名,也就是你的邮箱
smtp_auth_password: 'TPP***' #发邮件的邮箱密码
smtp_require_tls: false #不进行tls验证
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 10m
receiver: live-monitoring
receivers:
- name: 'live-monitoring'
email_configs:
- to: '[email protected]' #收邮件的邮箱
2.3 添加报警规则
添加一个node_down.yml为 prometheus targets 监控
vim node_down.yml
sudo tee /opt/prometheus/config/node_down.yml <<-'EOF'
groups:
- name: node_down
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
user: test
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
EOF
cat /opt/prometheus/config/node_down.yml
四、编写docker-compose
vim docker-compose-monitor.yml (node-exporter采集程序不建议采用docker安装)
sudo tee /opt/prometheus/config/docker-compose-monitor.yml <<-'EOF'
version: '3.5'
services:
prometheus:
image: prom/prometheus
container_name: prometheus
hostname: prometheus
restart: always
volumes:
- /opt/prometheus/config/prometheus.yml:/etc/prometheus/prometheus.yml
- /opt/prometheus/config/node_down.yml:/etc/prometheus/node_down.yml
ports:
- "9090:9090"
networks:
- monitor
alertmanager:
image: prom/alertmanager
container_name: alertmanager
hostname: alertmanager
restart: always
volumes:
- /opt/prometheus/config/alertmanager.yml:/etc/alertmanager/alertmanager.yml
ports:
- "9093:9093"
networks:
- monitor
grafana:
image: grafana/grafana
container_name: grafana
hostname: grafana
restart: always
ports:
- "3000:3000"
volumes:
- grafana-data:/var/lib/grafana
networks:
- monitor
cadvisor:
image: google/cadvisor:latest
container_name: cadvisor
privileged: true
hostname: cadvisor
restart: always
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
ports:
- "8080:8080"
networks:
- monitor
node-exporter:
image: quay.io/prometheus/node-exporter
container_name: node-exporter
hostname: node-exporter
restart: always
ports:
- "9100:9100"
networks:
- monitor
networks:
monitor:
driver: bridge
name: monitor
volumes:
grafana-data:
EOF
cat /opt/prometheus/config/docker-compose-monitor.yml
五、启动docker-compose
#启动容器:
docker-compose -f /opt/prometheus/config/docker-compose-monitor.yml up -d
#删除容器:
docker-compose -f /opt/prometheus/config/docker-compose-monitor.yml down
#重启容器:
docker restart id
容器启动如下:

查看日志
docker logs prometheus
docker logs node-exporter
docker logs cadvisor
docker logs grafana
docker logs alertmanager
#检查端口是否开启
ss -ntlp | grep -E '9090|9100|8080|3000|9093'
可以在内网通过 [http://192.168.8.110:9100/metrics]查看客户端数据:
**备注:**出现上面信息,证明已经收集到数据。
http://192.168.8.110:9090/targets
prometheus targets界面如下:

**备注:**如果State为Down,应该是防火墙问题,参考下面防火墙配置。
http://192.168.8.110:9090/graph?g0.expr=container_cpu_load_average_10s&g0.tab=0&g0.stacked=0&g0.show_exemplars=0&g0.range_input=1h&g1.expr=&g1.tab=1&g1.stacked=0&g1.show_exemplars=0&g1.range_input=1h
prometheus graph界面如下:
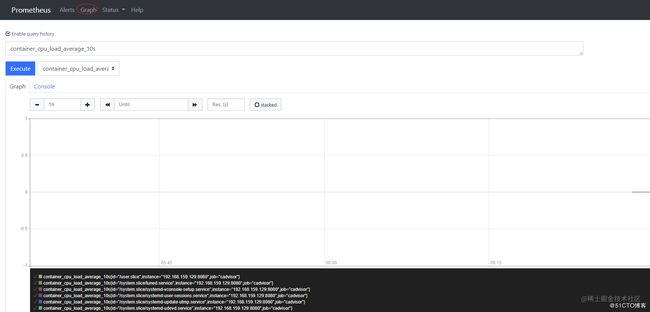
**备注:**如果没有数据,同步下时间。
六、防火墙配置
6.1 关闭selinux
setenforce 0
systemctl is-enabled firewalld.service
systemctl stop firewalld
systemctl disable firewalld.service
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config &> /dev/null
systemctl stop NetworkManager &> /dev/null
systemctl disable NetworkManager &> /dev/null
cat /etc/selinux/config | grep SELINUX=disabled
iptables -F
6.2 配置iptables
#删除自带防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
#安装iptables
yum install -y iptables-services
#配置
vim /etc/sysconfig/iptables
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [24:11326]
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 9090 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 8080 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 3000 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 9093 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 9100 -j ACCEPT
-A INPUT -j REJECT --reject-with icmp-host-prohibited
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
COMMIT
#启动
systemctl restart iptables.service
systemctl enable iptables.service
七、配置Grafana
登录Grafana首页http://192.168.8.110:3000/login(账号:admin 密码:admin)
grafana初始化密码
#获取权限
~~# su
首先打开数据库
~~# sqlite3 /var/lib/grafana/grafana.db
然后修改user表中admin用户的密码
#查看数据库中包含的表
~~# .tables
#查看user表内容
~~# select * from user;
#重置admin用户的密码为默认admin
~~# update user set password = '59acf18b94d7eb0694c61e60ce44c110c7a683ac6a8f09580d626f90f4a242000746579358d77dd9e570e83fa24faa88a8a6', salt = 'F3FAxVm33R' where login = 'admin';
#退出sqlite3
~~# .exit
最后重启grafana服务
~~#service grafana-server start
进入本地3000端口,账号密码都为admin进入。
7.1 添加Prometheus数据源
http://192.168.8.110:9090/
7.2配置dashboards
说明:可以用自带模板,也可以去https://grafana.com/dashboards,下载对应的模板。
7.3 查看数据
grafana仪表盘下载地址 https://grafana.com/grafana/dashboards
我从网页下载了docker相关的模板:Docker and system monitoring,893,8919

输入893,就会加载出下面的信息

导入后去首页查看数据
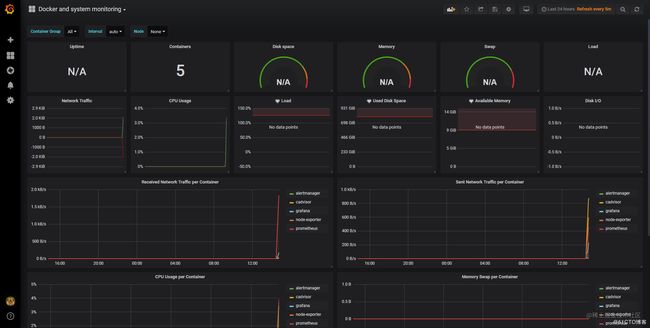
7.4 仪表盘
Dashboards | Grafana Labs
1 Node Exporter for Prometheus Dashboard EN 20201010
Docker monitoring
Docker Swarm & Container Overview
MySQL Overview
NGINX Ingress controller
Grafana Loki Dashboard for NGINX Service Mesh
windows_exporter for Prometheus Dashboard EN
Linux - Zabbix Server
八、附录:单独启动各容器
#启动prometheus
docker run -d -p 9090:9090 --name=prometheus \
-v /opt/prometheus/config/prometheus.yml:/etc/prometheus/prometheus.yml \
-v /opt/prometheus/config/node_down.yml:/etc/prometheus/node_down.yml \
prom/prometheus
# 启动grafana
docker run -d -p 3000:3000 --name=grafana grafana/grafana
#启动alertmanager容器
docker run -d -p 9093:9093 -v /opt/prometheus/config/config.yml:/etc/alertmanager/config.yml --name alertmanager prom/alertmanager
#启动node exporter
docker run -d \
-p 9100:9100 \
-v "/:/host:ro,rslave" \
--name=node_exporter \
quay.io/prometheus/node-exporter \
--path.rootfs /host
#启动cadvisor
docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:rw \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
--privileged=true \
google/cadvisor:latest
注意:
在Ret Hat,CentOS, Fedora 等发行版上需要传递如下参数,因为 SELinux 加强了安全策略:
–privileged=true
启动后访问:http://127.0.0.1:8080查看页面,/metric查看指标
centos7上面 docker 启动 cAdvisor 报错问题解决
启动命令:
docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/apps/docker/:/var/lib/docker:ro --volume=/dev/disk/:/dev/disk:ro --publish=9101:8080 --detach=true --name=cadvisor google/cadvisor:latest
报错日志
W0619 08:47:06.754687 1 manager.go:349] Could not configure a source for OOM detection, disabling OOM events: open /dev/kmsg: no such file or directory
F0619 08:47:06.909778 1 cadvisor.go:172] Failed to start container manager: inotify_add_watch /sys/fs/cgroup/cpuacct,cpu: no such file or directory
解决办法:
mount -o remount,rw '/sys/fs/cgroup'
ln -s /sys/fs/cgroup/cpu,cpuacct /sys/fs/cgroup/cpuacct,cpu
原因分析:
系统资源只读
3、metrics指标采集
采集的url:192.168.8.110:8080/metrics
九、node_exporter插件安装
安装 node_exporter 插件
修改配置信息
Prometheus 如果要监控 Linux 系统运行状态,需要安装 node_exporter 插件
#!/bin/bash
# wget https://github.com/prometheus/node_exporter/releases/download/v1.5.0/node_exporter-1.5.0.linux-amd64.tar.gz
tar zxvf node_exporter-1.5.0.linux-amd64.tar.gz
mv node_exporter-1.5.0.linux-amd64 /usr/local/node_exporter
cat > /etc/systemd/system/node_exporter.service << EOF
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl start node_exporter
systemctl status node_exporter
systemctl enable node_exporter
rm -rf node_exporter-1.5.0.linux-amd64.tar.gz
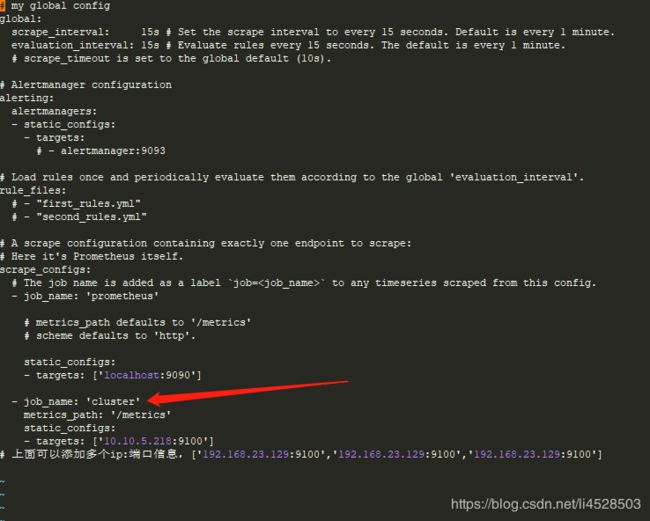
修改 Prometheus 配置文件,添加 node_exporter 监控信息,切换目录
vim /opt/prometheus/configeus.yml
在 scrape_configs: 下面添加内容如下,格式要求严格,需要添加空格达到格式一致
- job_name: "node"
metrics_path: '/metrics'
static_configs:
- targets: ['192.168.8.110:9100','192.168.8.111:9100']
# 上面可以添加多个ip:端口信息,['192.168.8.110:9100','192.168.8.111:9100','192.168.8.112:9100','192.168.8.113:9100']
docker restart prometheus
docker logs prometheus
http://192.168.8.110:3000/d/xfpJB9FGz/1-node-exporter-for-prometheus-dashboard-en-20201010?orgId=1
获取安装包
获取安装包地址:

wget下载安装
wget https://github.com/prometheus/node_exporter/releases/download/v1.0.0/node_exporter-1.0.0.linux-amd64.tar.gz #右键获取链接,wget 方式获取
tar -zxvf node_exporter-1.0.0.linux-amd64.tar.gz #解压文件
mv node_exporter-1.0.0.linux-amd64 /usr/local/node_exporter
cd /usr/local/node_exporter #切换目录
chmod -R 777 /usr/local/node_exporter #赋予启动权限
nohup ./node_exporter >> ./node_exporter.log 2>&1 & #启动
如果要改动端口号 需要添加参数 –web.listen-address=":9999" 例如
nohup ./node_exporter --web.listen-address=":9999" >> /applog/node_exporter/node_exporter.log 2>&1 &
验证
服务器验证方式
curl http://localhost:9100/metrics
默认的端口号是9100,因此要开放9090端口号
sudo firewall-cmd --add-port=9100/tcp --permanent
重载防火墙
sudo firewall-cmd --reload
网页验证方式
http://服务器IP:9100/metrics
ss -ntlp | grep 9100
开机自启动
cat >> /usr/local/node_exporter.sh <<-EOF
#!/bin/bash
/opt/node_exporter/node_exporter &>> /applog/node_exporter/node_exporter.log
EOF
chmod 755 node_exporter.sh #赋予执行权限
cat >> /usr/lib/systemd/system/node_exporter.service <<-EOF
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/docs/introduction/overview/
Wants=network-online.target
After=network-online.target
[Service]
User=root
Group=root
Type=simple
# 启动脚本
ExecStart=/opt/node_exporter/node_exporter.sh
[Install]
WantedBy=multi-user.target
EOF
验证启动
systemctl daemon-reload
配置开机加载
systemctl enable node_exporter
启动node_exporter
systemctl start node_exporter
查看是启动状态
systemctl status node_exporter
迁移与备份
镜像备份
我们可以通过以下命令将镜像保存为tar 文件
docker save -o node-exporter.tar quay.io/prometheus/node-exporter
docker save -o prometheus.tar prom/prometheus
docker save -o grafana.tar grafana/grafana
docker save -o alertmanager.tar prom/alertmanager
docker save -o cadvisor.tar google/cadvisor
镜像恢复与迁移
docker load -i node-exporter.tar
docker load -i prometheus.tar
docker load -i grafana.tar
docker load -i alertmanager.tar
docker load -i cadvisor.tar
ls | xargs -l docker load -i
监控远程MySQL
在被管理机agent1上安装mysqld_exporter组件
下载地址: https://prometheus.io/download/
安装mysqld_exporter组件
1、下载到被监控端解压压缩包
[root@localhost ~]# tar xf mysqld_exporter-0.12.1.linux-amd64.tar.gz -C /usr/local/
2、改名并移动到指定目录
[root@localhost ~]# mv /usr/local/mysqld_exporter-0.12.1.linux-amd64 /usr/local/mysqld_exporter
[root@localhost ~]# ls /usr/local/mysqld_exporter/
LICENSE mysqld_exporter NOTICE
安装mariadb数据库,并授权
[root@agent1 ~]# yum install mariadb\* -y
[root@agent1 ~]# systemctl restart mariadb
[root@agent1 ~]# systemctl enable mariadb
[root@agent1 ~]# mysql
3、登录mysql为exporter创建账号并授权
grant select,replication client,process ON *.* to 'mysql_monitor'@'localhost' identified by '123456';
flush privileges;
4、创建mysql配置文件、运行时可免密码连接数据库
创建一个mariadb配置文件,写上连接的用户名与密码(和上面的授权的用户名 和密码要对应)
cat > /usr/local/mysqld_exporter/.my.cnf <5、启动mysqld_exporter客户端
[root@agent1 ~]# nohup /usr/local/mysqld_exporter/mysqld_exporter --config.my-cnf=/usr/local/mysqld_exporter/.my.cnf >> /usr/local/mysqld_exporter/mysqld_exporter.out & 确认端口(9104)
[root@localhost ~]# tail -f -n 50 /usr/local/mysqld_exporter/mysqld_exporter.out
[root@localhost ~]# lsof -i:9104
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
mysqld_ex 121342 root 3u IPv6 150935 0t0 TCP *:peerwire (LISTEN)
6、添加系统服务:
vi /usr/lib/systemd/system/mysql_exporter.service
配置服务文件
cat > /usr/lib/systemd/system/mysql_exporter.service <<-EOF
[Unit]
Description=https://prometheus.io
[Service]
User=prometheus
Group=prometheus
ExecStart=/usr/local/mysqld_exporter/mysqld_exporter \
--config.my-cnf=/usr/local/mysqld_exporter/.my.cnf
[Install]
WantedBy=multi-user.target
EOF
7、启动添加后的系统服务
systemctl daemon-reload
systemctl restart mysql_exporter.service
systemctl status mysql_exporter.service
8、网站查看捕获mysql数据
访问:http://192.168.66.31:9104/metrics
9、使用prometheus监控修改监控端配置文件:vim prometheus.yml
cat >> /tmp/prometheus.yml <<-EOF
- job_name: 'MySQL'
static_configs:
- targets: ['192.168.66.31:9104']
EOF
10、检查并重启服务
检查并重新加载配置文件
./bin/promtool check config config/prometheus.yml
重启服务
docker restart prometheus
第一种,向prometheus进行发信号
kill -HUP pid
第二种,向prometheus发送HTTP请求
/-/reload只接收POST请求,并且需要在启动prometheus进程时,指定 --web.enable-lifecycle
curl -XPOST http://prometheus.chenlei.com/-/reload
日志系统Loki安装部署
一、简 介
Loki是受Prometheus启发由Grafana Labs团队开源的水平可扩展,高度可用的多租户日志聚合系统。 开发语言: Google Go。它的设计具有很高的成本效益,并且易于操作。使用标签来作为索引,而不是对全文进行检索,也就是说,你通过这些标签既可以查询日志的内容也可以查询到监控的数据签,极大地降低了日志索引的存储。系统架构十分简单,由以下3个部分组成 :
- Loki 是主服务器,负责存储日志和处理查询 。
- promtail 是代理,负责收集日志并将其发送给 loki 。
- Grafana 用于 UI 展示。
只要在应用程序服务器上安装promtail来收集日志然后发送给Loki存储,就可以在Grafana UI界面通过添加Loki为数据源进行日志查询(如果Loki服务器性能不够,可以部署多个Loki进行存储及查询)。作为一个日志系统不关只有查询分析日志的能力,还能对日志进行监控和报警
二、系 统 架 构

-
promtail收集并将日志发送给loki的 Distributor 组件
-
Distributor会对接收到的日志流进行正确性校验,并将验证后的日志分批并行发送到Ingester
-
Ingester 接受日志流并构建数据块,压缩后存放到所连接的存储后端
-
Querier 收到HTTP查询请求,并将请求发送至Ingester 用以获取内存数据 ,Ingester 收到请求后返回符合条件的数据 ;
如果 Ingester 没有返回数据,Querier 会从后端存储加载数据并遍历去重执行查询 ,通过HTTP返回查询结果
三、与 ELK 比 较
- ELK虽然功能丰富,但规模复杂,资源占用高,操作苦难,很多功能往往用不上,有点杀鸡用牛刀的感觉。
- 不对日志进行全文索引。通过存储压缩非结构化日志和仅索引元数据,Loki 操作起来会更简单,更省成本。
- 通过使用与 Prometheus 相同的标签记录流对日志进行索引和分组,这使得日志的扩展和操作效率更高。
- 安装部署简单快速,且受 Grafana 原生支持。
四、安 装 示 例
1)下载安装包以及获取默认配置文件
loki、promtail、grafana官网、loki-local-config.yaml、promtail-local-config.yaml
curl -O -L "https://github.com/grafana/loki/releases/download/v1.5.0/loki-linux-amd64.zip"
curl -O -L "https://github.com/grafana/loki/releases/download/v1.5.0/promtail-linux-amd64.zip"
wget https://dl.grafana.com/oss/release/grafana-7.1.1.linux-amd64.tar.gz
wget https://raw.githubusercontent.com/grafana/loki/master/cmd/loki/loki-local-config.yaml
wget https://raw.githubusercontent.com/grafana/loki/master/cmd/promtail/promtail-local-config.yaml
注:配置文件也可自行创建编写
2)解压安装包至指定目录(/data/software/loki/)
unzip -q loki-linux-amd64.zip -d /data/software/loki/
unzip -q promtail-linux-amd64.zip -d /data/software/loki/
3)将配置文件放置在指定目录(/data/software/loki/etc/)
mv loki-local-config.yaml /data/software/loki/etc/
mv promtail-local-config.yaml /data/software/loki/etc/
4)修改配置文件
vim loki-local-config.yaml
auth_enabled: false
server:
http_listen_port: 3100 #监听的端口
ingester:
lifecycler:
address: 127.0.0.1
ring:
kvstore:
store: inmemory
replication_factor: 1
final_sleep: 0s
chunk_idle_period: 5m
chunk_retain_period: 30s
max_transfer_retries: 0
schema_config:
configs:
- from: 2020-07-29
store: boltdb
object_store: filesystem
schema: v11
index:
prefix: index_
period: 168h
storage_config:
boltdb:
directory: /data/loki/index #自定义boltdb目录
filesystem:
directory: /data/loki/chunks #自定义filesystem目录
limits_config:
enforce_metric_name: false
reject_old_samples: true
reject_old_samples_max_age: 168h
chunk_store_config:
max_look_back_period: 0s
table_manager:
retention_deletes_enabled: false
retention_period: 0s
vim promtail-local-config.yaml
# Promtail服务配置
server:
http_listen_port: 9080
grpc_listen_port: 0
# 记录读取日志的位置信息文件,Promtail重新启动时需要它
positions:
filename: /tmp/positions.ymal
# Loki的api服务的地址
clients:
- url: http://192.168.8.110:3100/loki/api/v1/push
scrape_configs:
# ngxin日志收集并打标签
- job_name: nginx # 服务名称
static_configs:
- targets:
- localhost # 目标服务器名称
labels:
job: nginx-error # 作业名称
host: localhost # 服务器地址
__path__: /var/log/*log #服务器日志路径
docker-composer.yml
vim docker-compose-monitor.yml (promtail采集程序不建议采用docker安装)
[root@localhost config]# mkdir -p /opt/loki/index
[root@localhost config]# mkdir -p /opt/loki/chunks
docker-compose -f docker-compose-loki.yml up -d #启动
docker-compose -f docker-compose-loki.yml down #关闭
docker restart loki
docker logs prometheus
docker logs node-exporter
docker logs cadvisor
docker logs grafana
docker logs alertmanager
docker logs loki
docker logs promtail
#检查端口是否开启
ss -ntlp | grep -E '9090|9100|8080|3000|9093|3100'
version: '3.1'
networks:
monitor:
driver: bridge
services:
prometheus:
image: prom/prometheus
container_name: prometheus
hostname: prometheus
restart: always
environment:
- TZ=Asia/Shanghai
- LANG=zh_CN.UTF-8
volumes:
- /opt/prometheus/config/prometheus.yml:/etc/prometheus/prometheus.yml
- /opt/prometheus/config/node_down.yml:/etc/prometheus/node_down.yml
ports:
- "9090:9090"
networks:
- monitor
alertmanager:
image: prom/alertmanager
container_name: alertmanager
hostname: alertmanager
restart: always
environment:
- TZ=Asia/Shanghai
- LANG=zh_CN.UTF-8
volumes:
- /opt/prometheus/config/alertmanager.yml:/etc/alertmanager/alertmanager.yml
ports:
- "9093:9093"
networks:
- monitor
grafana:
image: grafana/grafana
container_name: grafana
hostname: grafana
restart: always
environment:
- TZ=Asia/Shanghai
- LANG=zh_CN.UTF-8
ports:
- "3000:3000"
networks:
- monitor
node-exporter:
image: quay.io/prometheus/node-exporter
container_name: node-exporter
hostname: node-exporter
restart: always
environment:
- TZ=Asia/Shanghai
- LANG=zh_CN.UTF-8
ports:
- "9100:9100"
networks:
- monitor
cadvisor:
image: google/cadvisor:latest
container_name: cadvisor
privileged: true
hostname: cadvisor
restart: always
environment:
- TZ=Asia/Shanghai
- LANG=zh_CN.UTF-8
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
ports:
- "8080:8080"
networks:
- monitor
loki:
image: grafana/loki:latest
container_name: loki
hostname: loki
restart: always
environment:
- TZ=Asia/Shanghai
- LANG=zh_CN.UTF-8
volumes:
- /opt/loki/config/loki-local-config.yaml:/etc/loki/loki-local-config.yaml
- /opt/loki/index :/data/loki/index
- /opt/loki/chunks:/data/loki/chunks
ports:
- "3100:3100"
command: -config.file=/etc/loki/loki-local-config.yaml
networks:
- monitor
promtail:
image: grafana/promtail
container_name: promtail
hostname: promtail
restart: always
environment:
- TZ=Asia/Shanghai
- LANG=zh_CN.UTF-8
volumes:
- /opt/prometheus/config/promtail-local-config.yaml:/etc/promtail/promtail-local-config.yaml
command: -config.file=/etc/promtail/promtail-local-config.yaml
networks:
- monitor
5)Grafana安装:
tar -xf grafana-7.1.1.linux-amd64.tar.gz -C /data/software/
6)启动服务(先启loki):
nohup /data/software/loki/loki-linux-amd64 -config.file=/data/software/loki/etc/loki-local-config.yaml &
nohup /data/software/loki/promtail-linux-amd64 -config.file=/data/software/loki/etc/promtail-local-config.yaml &
nohup /data/software/grafana-7.1.1/bin/grafana-server web &
注:每次启动完可以查看所在目录的nohup.out,查看启动情况
五、使 用 示 例
1)浏览器登陆地址:http://127.0.0.1:3000 访问Grafana,首次登陆默认用户名和密码都是 admin,登录后会提示修改密码。http://192.168.8.110:3100
2)进入Data Sources添加数据源,选择Loki,URL为loki的地址: http://127.0.0.1:3100 ,Name自己定义
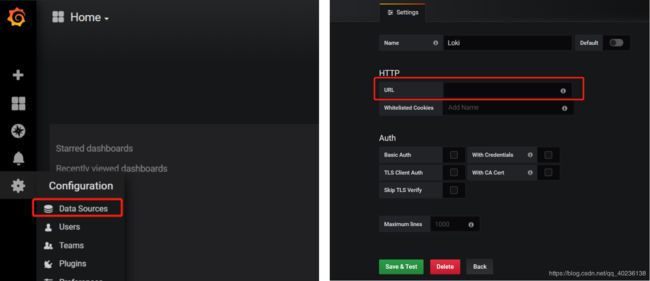
3)然后进入Explore就可以搜索查询日志了,日志查询由两部分组成:日志流选择器和搜索表达式。出于性能原因,需要先通过选择日志标签来选择日志流。查询字段Log labels旁边的按钮显示了可用日志流的标签列表
标签匹配符:
-
=完全相等。 -
!=不相等。 -
=~正则表达式匹配。 -
!~不进行正则表达式匹配。例:{job=“UMG-log”,filename=“/home/zoehuawang/loki/UMG.07.18.15-40-07.log”}

搜索表达式:
-
|=行包含字符串。 -
!=行不包含字符串。 -
|~行匹配正则表达式。 -
!~行与正则表达式不匹配。例:{job=“UMG-log”} |= “07.18” |= “[-973]” != “0xffffffff”

点击了解适用于Loki的logstash插件使用方法https://grafana.com/docs/loki/latest/clients/logstash/)