面向对象的设计原则最终篇
关于面向对象的设计原则我之前已经解释过四种了,分别是单一职责原则,开放关闭原则,里式替换原则,依赖倒置原则而接下来我们要解释的就是最后的三种原则了,分别是接口隔离原则, 迪米特法则, 组合复用原则
前言
在面向对象的软件设计中,只有尽量降低各个模块之间的耦合度,才能提高代码的复用率,系统的可维护性、可扩展性才能提高。面向对象的软件设计中,有23种经典的设计模式,是一套前人代码设计经验的总结,如果把设计模式比作武功招式,那么设计原则就好比是内功心法。常用的设计原则有七个,下文将具体介绍。
设计原则简介
-
单一职责原则:专注降低类的复杂度,实现类要职责单一;
-
开放关闭原则:所有面向对象原则的核心,设计要对扩展开发,对修改关闭;
-
里式替换原则:实现开放关闭原则的重要方式之一,设计不要破坏继承关系;
-
依赖倒置原则:系统抽象化的具体实现,要求面向接口编程,是面向对象设计的主要实现机制之一;
-
接口隔离原则:要求接口的方法尽量少,接口尽量细化;
-
迪米特法则:降低系统的耦合度,使一个模块的修改尽量少的影响其他模块,扩展会相对容易;
-
组合复用原则:在软件设计中,尽量使用组合/聚合而不是继承达到代码复用的目的。
这些设计原则并不说我们一定要遵循他们来进行设计,而是根据我们的实际情况去怎么去选择使用他们,来让我们的程序做的更加的完善。
接口隔离原则
定义:
接口隔离原则经常略写为ISP,讲的是使用多个专门的接口比使用单一的接口要好。
换句话来说从一个客户类的角度来说,一个类对另外一个类的依赖性应当是建立在最小的接口上的。
那么到底该怎么去理解这个接口隔离原则呢?
我觉得可以从三个方面去理解这个事情。
1. 角色的合理划分
将“接口”理解为一个类所提供的所有的方法的特征集合,也就是一种在逻辑上才存在的概念,这样的话,接口的划分其实就是直接在类型上的划分。
其实可以这么想,一个接口就相当于剧本中的一个角色,而这个角色在表演的过程中,决定由哪一个演员来进行表演就相当于是接口的实现,因此,一个接口代表的应当是一个角色而不是多个角色,如果系统涉及到多个角色的话,那么每一个角色都应当由一个特定的接口代表才对。
而为了避免我们产山混淆的想法,这时候我们就可以把接口隔离原则理解成角色隔离原则。
2. 定制服务
将接口理解成我们开发中狭义的JAVA接口的话,这样子,接口隔离原则讲的就是为同一个角色提供宽窄不同的接口,来应对不同的客户端内容,我画一个简单的图示,大家就完全能明白了。

上面这个办法其实就可以称之为定制服务,在上面的图中有一个角色service以及三个不同的客户端,这三个Client需要的服务是不一样的,所以我给他分成了是三个接口,也就是Service1,Service2和Service3,显而易见,每一个JAVA接口,都仅仅是将Cilent需要的行为暴露给Client,而没有将不需要的方法暴露出去。
其实了解设计模式的很容易就想到这是适配器模式的一个应用场景,我不细聊适配器模式,设计模式我们在知识星球中会进行讲解。
3. 接口污染
这句话的意思就是过于臃肿的接口就是对接口的污染。
由于每一个接口都代表一个角色,实现一个接口对象,在他的整个生命周期中,都扮演着这个角色,因此将角色分清就是系统设计的一个重要的工作。因此一个符合逻辑的判断,不应该是将几个不同的角色都交给一个接口,而是应该交给不同的接口来进行处理。
准确而恰当的划分角色以及角色所对应的接口,就是我们面向对象设计中的一个重要的组成部分,如果将没有关系或者关系不大的接口整合到一起去的话,那就是对角色和接口的污染。
我们来写代码来举个例子论证一下:
public interface TestInterface {
public void method1();
public void method2();
public void method3();
public void method4();
public void method5();
}
class Test1 {
public void mm1(TestInterface i) {
i.method1();
}
public void mm2(TestInterface i) {
i.method2();
}
public void mm3(TestInterface i) {
i.method3();
}
}
class Test2 implements TestInterface{
@Override
public void method1() {
System.out.println("类Test2实现接口TestInterface的方法1");
}
@Override
public void method2() {
System.out.println("类Test2实现接口TestInterface的方法2");
}
@Override
public void method3() {
System.out.println("类Test2实现接口TestInterface的方法3");
}
@Override
public void method4() {}
@Override
public void method5() {}
}
class Test3{
public void mm1(TestInterface i) {
i.method1();
}
public void mm2(TestInterface i) {
i.method4();
}
public void mm3(TestInterface i) {
i.method5();
}
}
class Test4 implements TestInterface{
@Override
public void method1() {
System.out.println("类Test4实现接口TestInterface的方法1");
}
@Override
public void method2() {
}
@Override
public void method3() {
}
@Override
public void method4() {
System.out.println("类Test4实现接口TestInterface的方法4");
}
@Override
public void method5() {
System.out.println("类Test4实现接口TestInterface的方法5");
}
}
然后我们看一下调用方式
public class Client {
public static void main(String[] args) {
Test1 test1 = new Test1();
test1.mm1(new Test2());
test1.mm2(new Test2());
test1.mm3(new Test2());
Test3 test3 = new Test3();
test3.mm1(new Test4());
test3.mm2(new Test4());
test3.mm3(new Test4());
}
}
执行结果如下:
类Test2实现接口TestInterface的方法1
类Test2实现接口TestInterface的方法2
类Test2实现接口TestInterface的方法3
类Test4实现接口TestInterface的方法1
类Test4实现接口TestInterface的方法4
类Test4实现接口TestInterface的方法5
那么我们怎么去设计遵循接口设计原则的代码呢?
public interface TestInterface1 {
public void method1();
}
interface TestInterface2{
public void method2();
public void method3();
}
interface TestInterface3 {
public void method4();
public void method5();
}
class Test1{
public void mm1(TestInterface1 i){
i.method1();
}
public void mm2(TestInterface2 i){
i.method2();
}
public void mm3(TestInterface2 i){
i.method3();
}
}
class Test2 implements TestInterface1,TestInterface2{
@Override
public void method1() {
System.out.println("类Test2实现接口TestInterface1的方法1");
}
@Override
public void method2() {
System.out.println("类Test2实现接口TestInterface2的方法2");
}
@Override
public void method3() {
System.out.println("类Test2实现接口TestInterface2的方法3");
}
}
class Test3{
public void mm1(TestInterface1 i){
i.method1();
}
public void mm2(TestInterface3 i){
i.method4();
}
public void mm3(TestInterface3 i){
i.method5();
}
}
class Test4 implements TestInterface1,TestInterface3{
@Override
public void method1() {
System.out.println("类Test4实现接口TestInterface1的方法1");
}
@Override
public void method4() {
System.out.println("类Test4实现接口TestInterface3的方法4");
}
@Override
public void method5() {
System.out.println("类Test4实现接口TestInterface3的方法5");
}
}
接口隔离原则的含义是:建立单一接口,不要建立庞大臃肿的接口,尽量细化接口,接口中的方法尽量少。也就是说,我们要为各个类建立专用的接口,而不要试图去建立一个很庞大的接口供所有依赖它的类去调用。
我写的这个例子中,将一个庞大的接口变更为3个专用的接口所采用的就是接口隔离原则。
所以其实接口隔离原则其实也算是“看人下菜碟”,它的意思就是要看客人是谁,在提供不同档次的饭菜。
从接口隔离原则的角度出发的话,要根据客户不同的需求,去指定不同的服务,这就是接口隔离原则中推荐的方式。
迪米特法则
定义:
迪米特法则(Law of Demeter)又叫作最少知识原则(Least Knowledge Principle 简写LKP),就是说一个对象应当对其他对象有尽可能少的了解,不和陌生人说话。英文简写为: LoD。
其实他主要是为了解决一个我们最常见的问题,就是类之间的关系,所以类与类之间的关系越密切,耦合度就越大,当一个类放生改变的时间,对另一个类的影响也会越大。
而他最终的解决方案就是降低类和类之间的耦合度,这也是我们所说的高内聚,低耦合。
我们来通过简单的一个系统的代码来理解一下迪米特法则。
不满足迪米特法则的系统
这里的系统有三个类,分别是SomeOne,Friend和Stranger。其中SomeOne与Friend是朋友,而Friend和Stranger是朋友,系统结构图就像下面的。

从上面的类图中,我们可以看到,Friend持有Stranger对象的引用,这就解释了为什么Friend与Stranger是朋友,我们给出一点代码来解释SomeOne和Friend的朋友关系。
public class Someone{
public void operation1(Friend friend){
Stranger stranger = friend.provide();
stranger.operation3();
}
}
可以看出,SomeOne具有一个方法operation1(),这个方法接收friend为参数,显然,根据朋友的定义,Friend和Stranger是朋友关系,其中的Friend的provide()方法会提供自己所创建的Stranger实例,就像下面的代码
public class Friend{
private Stranger stranger = new Stranger();
public void operation2(){
}
public Stranger provide(){
return stranger;
}
}
这其实就很显然了,SomeOne的方法operation1()并不满足迪米特法则,为什么会这么说呢?因为这个方法引用Stranger对象,而Stranger对象不是SomeOne的朋友。
我们下面使用迪米特法则来进行改造一下这个关系和代码。
使用迪米特法则进行改造

从上面的图中我们可以看出,与改造之前相比,在SomeOne与Stranger之间的联系已经没有了,SomeOne不需要知道Stranger的存在就可以做同样的事情,我们看一下SomeOne的代码,
public class Someone{
public void operation1(Friend friend){
friend.forward();
}
}
从源代码中我们可以看出,SomeOne通过调用自己的朋友Friend对象的forward()方法做到了原来需要调用Stranger对象才能够做到的事情,那么我们再来看一下forward()方法是做什么呢?
public class Frend{
private Stranger stranger = new Stranger();
public void operation2(){
System.out.printIn("In Friend.operation2()");
}
public void forward(){
stranger.operation3();
}
}
原来Friend类的forward()方法所做的就是以前SomeOne要做的事情,使用Stranger的operation3()方法,而这种forward()方法叫做转发方法,
由于使用了调用转发,使得调用的具体的细节被隐藏在Friend内部,从而使SomeOne与Stranger之间的直接联系被省略掉了,这样一来,系统内部的耦合度降低了,在系统的某一个类需要修改时,仅仅会影响这个类的“朋友们”,而不会直接影响到其他的部分。
以上就是我对迪米特法则的一些理解,有兴趣的人也可以去深入研究一下,将来对理解设计模式会有很好的见解的。
组合复用原则
定义:
组合复用原则经常又叫做合成复用原则。该原则就是在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分:新的对象通过向这些对象的委派达到复用已有功能的目的。
而在我们的代码中尽可能使用组合而不是用继承是什么原因呢?
原因如下
- 第一,继承复用破坏包装,它把父类的实现细节直接暴露给了子类,这违背了信息隐藏的原则;
- 第二:如果父类发生了改变,那么子类也要发生相应的改变,这就直接导致了类与类之间的高耦合,不利于类的扩展、复用、维护等,也带来了系统僵硬和脆弱的设计。而用合成和聚合的时候新对象和已有对象的交互往往是通过接口或者抽象类进行的,就可以很好的避免上面的不足,而且这也可以让每一个新的类专注于实现自己的任务,符合单一职责原则。
其实这个组合复用原则最好的理解就是我们各种系统中的后台系统里面的权利和角色的分配,我相信很多公司的项目中都会有,我来阐述一下这个问题。
“Has-A”和“Is-A”
“Is-A”是严格的分类学意义上的定义,意思是一个类是另外一个类的“一种”。而“Has-A”则不同,他表示某一个角色具有某一项责任。
我们看一个图解
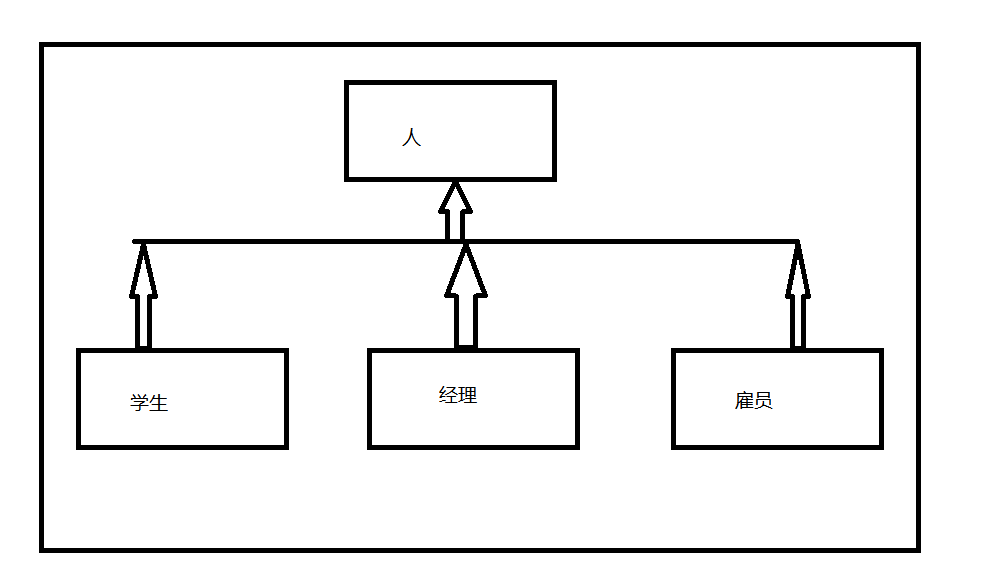
人被继承到“雇员”,“经理”,“学生”等子类,而实际上,“雇员”,“经理”,“学生”分别描述一种角色,而“人”可以同时有几种不同的角色,比如,一个“人”即使“经理”,就必然是“雇员”,而有可能这个“人”还是一个“学生”。如果说使用继承来说,那么如果这个人是“学生”,那么它一定不能再是经理,这个大家可以思考一下为什么,很简单,这显然就是不合理的。
图中的这种就是把“角色”的等级结构和“人”的等级结构混淆了,把“Has-A”角色误解成为了“Is-A”角色,而下面这幅图就成功的解释了这一点

而在这个图中,就不存在之前混淆的问题了,每个人都可以拥有一个以上的“角色”了。
组合/聚合复用原则使用总结:
合成和聚合均是关联的特殊情况。聚合用来表示“拥有”关系或者整体与部分的关系;而合成则用来表示一种强得多的“拥有”关系。在一个合成关系里面,部分和整体的生命周期是一样的。一个合成的新的对象完全拥有对其组成部分的支配权,包括它们的创建和销毁等。使用程序语言的术语来说,组合而成的新对象对组成部分的内存分配、内存释放有绝对的责任。要正确的选择合成/复用和继承,必须透彻地理解里氏替换原则和Coad法则。(Coad法则由Peter Coad提出,总结了一些什么时候使用继承作为复用工具的条件。Coad法则:只有当以下Coad条件全部被满足时,才应当使用继承关系)
-
子类是基类的一个特殊种类,而不是基类的一个角色。区分“Has-A”和“Is-A”。只有“Is-A”关系才符合继承关系,“Has-A”关系应当用聚合来描述。
-
永远不会出现需要将子类换成另外一个类的子类的情况。如果不能肯定将来是否会变成另外一个子类的话,就不要使用继承。
-
子类具有扩展基类的责任,而不是具有置换掉(override)或注销掉(Nullify)基类的责任。如果一个子类需要大量的置换掉基类的行为,那么这个类就不应该是这个基类的子类。
-
只有在分类学角度上有意义时,才可以使用继承。不要从工具类继承。
以上就是我最后介绍的关于设计模式之前的设计原则的所有了,三篇文章,你学会了么?
我是懿,一个正在被打击还在努力前进的码农。欢迎大家关注我们的公众号,加入我们的知识星球,我们在知识星球中等着你的加入。