计算机视觉之风格迁移(二)——ECCV2016论文Real-Time Style Transfer复现
一、论文简介
0.论文信息
【ECCV-2016】Perceptual Losses for Real-Time Style Transfer
论文地址:https://arxiv.org/pdf/1603.08155.pdf
1.点睛之处
在上一篇博客中,讲解了Gatys等人是如何分离图片的内容和风格,由此来进行图片的风格转移。但是,他们的方法有一定的缺陷——训练的时间太长,费时比较久。
该论文提出了一种可以实时进行图片风格迁移的方法,首先依赖于预训练的网络(VGG19)提取的高级特征在感知损失函数的作用下来训练图片转换网络,然后将原始图片通过训练好的图像转换网络即可得到风格迁移后的图片。
简单来说,Gatys等人训练的是噪声参数,每更新一次参数都要经过一遍网络,由此导致耗时比较久。这篇论文训练的是网络,将网络训练完成后,即可用训练的好参数处理输入图片,可以很快的得到目标图片。
2.整体结构
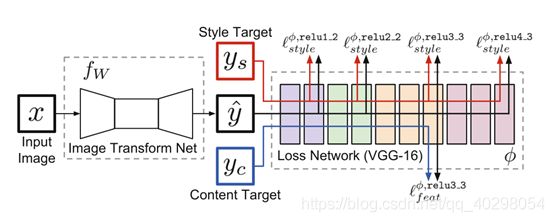
该模型中包含两个网络,一个是左边的图像转换网络(需要我们进行训练),一个是右边的定义了几个损失函数的损失网络(已经提前训练好)。
我们训练一个图像转换网络,将输入图像转换成目标图像,使用VGG19来定义感知损失函数,该函数计算输入图像和目标图像之间内容和风格的差异,然后使用该loss值去优化图像转换网络,损失网络在训练过程中保持不变。
因此,我们的深度卷积变换网络(图像转换网络)是使用也是深度卷积网络(损失网络)的损失函数来训练的。
3.图像转换网络
首先对输入进行下采样,然后是几个剩余块,然后进行上采样。
缩小图像(下采样)的主要目的有两个:1、使得图像符合显示区域的大小;2、生成对应图像的缩略图。
下采样原理:对于一幅图像I尺寸为M*N,对其进行s倍下采样,即得到(M/s)*(N/s)尺寸的得分辨率图像,当然s应该是M和N的公约数才行,如果考虑的是矩阵形式的图像,就是把原始图像s*s窗口内的图像变成一个像素,这个像素点的值就是窗口内所有像素的均值。
放大图像(上采样)的主要目的是放大原图像,从而可以显示在更高分辨率的显示设备上。
上采样原理:图像放大几乎都是采用内插值方法,即在原有图像像素的基础上在像素点之间采用合适的插值算法插入新的元素。
对图像的缩放操作并不能带来更多关于该图像的信息, 因此图像的质量将不可避免地受到影响。然而,确实有一些缩放方法能够增加图像的信息,从而使得缩放后的图像质量超过原图质量的。
先下采样后上采样的好处:
1.节约计算成本
2.更大的有效感受野
4.损失网络
该网络中损失函数包括内容损失函数、特征损失函数、全变分降噪函数
内容损失函数:当我们从更高的层重构时,图像内容和整体空间结构被保留,但是颜色、纹理和精确的形状不被保留
特征损失函数:![]()
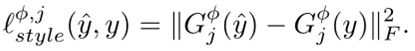
全变分降噪函数:来促进输出图片的空间光滑性![]()
总损失函数:
内容、特征损失在上一篇博客进行了讲解,这里虽然有一些区别,但是原理上相同。
二、代码复现
0.复现环境
scipy==1.2.1
tensorflow_gpu==1.8.0
numpy==1.19.2
1.图像转换网络
一共是由3个卷积层、5个残差块、3个卷积层构成。这里没有用到池化等操作进行采用,在开始卷积层中(第二层、第三层)进行了下采样,在最后的3个卷积层中进行了上采样。5个残差块都是使用相同个数的(128)滤镜核,每个残差块中都有2个卷积层(3*3核),这里的卷积层中都进行了标准的0填充(padding),所以会导致生成出的图像的边界出现伪影。
除了输出层之外,所有非并行卷积层之后都是批量归一化和ReLU,输出层使用缩放的tanh来确保输出具有范围[0,255]内的像素。第一层和最后一层使用9×9核,所有其他卷积层使用3×3核。
def net(image):
#归一化
image = image / 255.0
conv1 = _conv_layer(image, 32, 9, 1)
conv2 = _conv_layer(conv1, 64, 3, 2)
conv3 = _conv_layer(conv2, 128, 3, 2)
resid1 = _residual_block(conv3, 3)
resid2 = _residual_block(resid1, 3)
resid3 = _residual_block(resid2, 3)
resid4 = _residual_block(resid3, 3)
resid5 = _residual_block(resid4, 3)
conv_t1 = _conv_tranpose_layer(resid5, 64, 3, 2)
conv_t2 = _conv_tranpose_layer(conv_t1, 32, 3, 2)
conv_t3 = _conv_layer(conv_t2, 3, 9, 1, relu=False)
preds = tf.nn.tanh(conv_t3)
output = image + preds
return tf.nn.tanh(output) * 127.5 + 255. / 2| Layer |
Size |
| Input |
1×332×500×3 |
| 32×9×9 conv,strides 1 |
1×332×500×32 |
| 64×3×3 conv,strides 2 |
1×166×250×64 |
| 128×3×3 conv,strides 2 |
1×83×125×128 |
| Residual block,128 filters |
1×83×125×128 |
| Residual block,128 filters |
1×83×125×128 |
| Residual block,128 filters |
1×83×125×128 |
| Residual block,128 filters |
1×83×125×128 |
| Residual block,128 filters |
1×83×125×128 |
| 64×3×3 conv_tranpose,strides 2 |
1×166×250×64 |
| 32×3×3 conv_tranpose,strides 2 |
1×332×500×32 |
| 3×9×9 conv_tranpose,strides 1 |
1×332×500×3 |
2. 训练过程
def train(self, content_training_images, learning_rate, epochs, checkpoint_iterations):
train_step = tf.contrib.opt.ScipyOptimizerInterface(self.loss,
method='L-BFGS-B', options={'maxiter': epochs,'disp': 0})
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
iterations = 0
for epoch in range(epochs):
for i in range(0, len(content_training_images), self.batch_size):
stdout.write('Iteration %d\n' % (iterations + 1))
batch = self._load_batch(content_training_images[i: i + self.batch_size])
train_step.minimize(sess, feed_dict={self.input_batch: batch})
if iterations % checkpoint_iterations == 0:
# 生成器,返回一个元组,下次从断点处继续执行
yield (
iterations,
sess,
self.target_image.eval(feed_dict={self.input_batch: batch})[0],
self._current_loss({self.input_batch: batch})
)
iterations += 1使用L-BFGS-B优化方法,每经过100轮会返回主函数打印loss值和保存模型,然后从断点处继续执行训练过程。
def _load_batch(self, image_paths):
batch_imgs = []
for batch_file in image_paths:
img = utils.load_image(batch_file, (256, 256))
batch_imgs.append(img)
return np.asarray(batch_imgs)喂入数据为batch_size大小
def _instance_norm(net, train=True):
batch, rows, cols, channels = [i.value for i in net.get_shape()]
var_shape = [channels]
#对1,2维度求均值和方差
mean, variance = tf.nn.moments(net, [1, 2], keep_dims=True)
shift = tf.Variable(tf.zeros(var_shape))
scale = tf.Variable(tf.ones(var_shape))
epsilon = 1e-3
normalized = (net - mean) / (variance + epsilon) ** (.5)
#对标准化后的数据进行缩放(scale)和平移(shift)
return scale * normalized + shift这里使用实例归一化而不是批量归一化,可以显著提高生成图像的质量。
3.代码文件明细

4.复现结果
训练网络的训练集选择COCO2017数据集,下载地址http://images.cocodataset.org/zips/train2017.zip,由于训练网络时的batch_size为4,所以我增加了一张图片,数据集达到118288张图片。
epochs选择5,在1080显卡上进行训练,训练时间貌似近乎两天。
i.图像转换
| 特征图片 | 原始图片 | 目标图片 |
|
|
|
|
|
|
|
|






ii.视频转换
我在项目中放了一段重庆风景的视频,真的好怀念在重庆的那段时光,我愿意用一切换我回到那段时光。
读者可运行程序转换视频,同时也可以运行程序打开电脑自带摄像头,进行实时在线转换(这两者只是运行时参数不同),如何运行代码请看github中README。
5.资源地址
VGG网络参数文件:https://download.csdn.net/download/qq_40298054/13082438
风格图为梵高的星空的网络参数文件:https://download.csdn.net/download/qq_40298054/13113600
github代码地址:https://github.com/Lonely79/Style_Transfer_2.git
三、结语
该论文通过训练网络,速度比Gatys等人快了三个数量级,并且能够做到实时转换图像,效果令人振奋。