人工智能极简史:一文读懂ChatGPT的前世今生
2022年11月30日,OpenAI推出的一款人工智能技术驱动的自然语言处理工具——ChatGPT,迅速在社交媒体上走红,短短5天,注册用户数就超过100万。 2023年1月末,ChatGPT的月活用户已突破1亿,一度成为史上增长最快的消费者应用(之后被threads的5天打破)。
微软创始人比尔盖茨在他的博客中畅谈ChatGPT,他说:OpenAI发布的大语言模型ChatGPT是他一生中遇到的两项革命性技术之一。另一个是1980年出现的图形用户界面。
这款具有革命性意义的产品是如何横空出世的?今天我们就来一起来探索一下。
探索
人工智能开始于1940年代末。计算机先驱们开始研究机器是否能够 "思考"。
英国计算机先驱艾伦-图灵的研究取得了突破性的进展。1950年,图灵发表了一篇开创性的论文 "计算机械与智能"。他讨论了如何建造智能机器并测试其智能。提出了“图灵测试”的概念,当你不面对面的时候,跟别人文字聊天,能不能准确判断出来对方是一个人,还是一个机器人。如果你很难分辨,那一定程度可以说这个机器是智能的。

图灵还通过在Bletchley Park时期使用贝叶斯统计方法来解码加密消息,他和他的团队逐字使用统计数据来回答问题,例如:“这个特定的德国单词生成了这些加密字母的概率是多少?”类似的贝叶斯方法现在驱动生成型AI程序,用于生成文章、艺术作品和从未存在的人物形象。“过去70年来,贝叶斯统计领域发生了一整个平行宇宙的活动,完全支持了今天我们所看到的生成型AI,我们可以将其追溯到图灵在加密方面的工作。
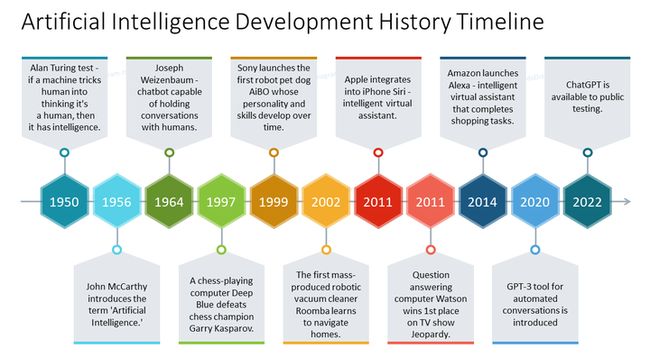
1955年,"人工智能 "这个术语被创造出来。约翰·麦卡锡(John McCarthy),新罕布什尔州达特茅斯学院的计算机科学家,提出了这个短语,对AI的前景充满乐观。他写道:“我们认为,如果一组精选的科学家在夏季一起工作,就可以取得重大进展。”然而,当时的进展很小,1970年代AI泡沫破裂,英国著名数学家詹姆斯·莱特希尔(James Lighthill)撰写了一份严厉的关于AI进展不足的报告,导致立即削减了资金。
1956年--达特茅斯的人工智能夏季研究项目标志着人工智能作为一个研究领域的诞生。

1958年,心理学家弗兰克·罗森布拉特(Frank Rosenblatt)推出了Perceptron,一项令人振奋的创新,被誉为“第一台能够产生原创思想的机器”。Perceptron在一台当时尖端的IBM大型计算机上运行,它模拟人类神经元,学会区分标有左边和右边的穿孔卡片。《纽约客》称其为 "非凡的机器,能够相当于思考"。
尽管在早期显示出了潜力,但Perceptron仅仅是一个基础的神经网络,远未达到推动现代AI的复杂“深度”神经网络的水平。

1961年,Unimation公司推出了第一个为工业用途设计的机器人。
1963年,麻省理工学院开发出第一台神经网络学习机。
模式匹配
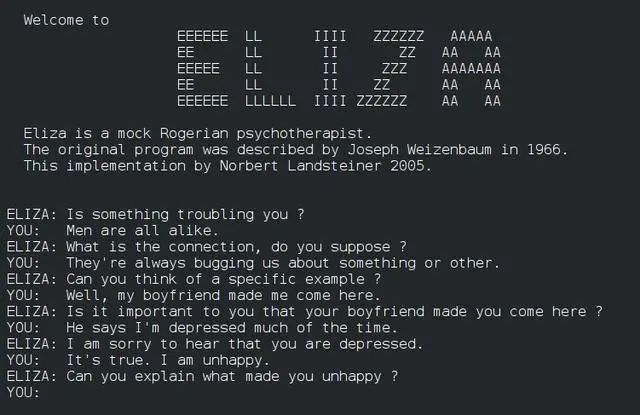
1966年,MIT实验室发明了聊天机器人Eliza。它可以模仿治疗师,用英语交谈。
1970年,第一个拟人机器人WABOT-1在日本早稻田大学建成。它由一个肢体控制系统、一个视觉系统和一个对话系统组成。

AI的转折点在1986年到来,当时包括卡耐基梅隆大学的杰弗里·欣顿(Geoffrey Hinton)在内的研究人员开发了“反向传播”作为一种教授网络的方法。这个发展为随后的深度学习革命铺平了道路。2012年,欣顿和其他人推出了AlexNet,这是一个具有约1万个神经元的八层网络,在国际ImageNet挑战中表现出色,凸显了规模和计算的重要性。
反向传播算法是机器学习理论历史上最为重要的一个算法。但直到20世纪80年代中期他才成为了机器学习理论的主流。
反向传播算法最主要的功能是允许一个神经网络在其实际输出和其期待的不一致时,能够主动进行自我调节。更简单的来说,它意味着人们可以通过在每次神经网络犯错误时都及时对其改正来对他们进行训练。之后,反向传播算法就可以修改神经网络的拼接,从而保证它能够在下一次遇到同样问题是不会犯同样的错误。
1988年--朱迪亚-珀尔发表了 "智能系统中的概率推理"。他被认为是贝叶斯网络的发明者。这项工作彻底改变了人工智能领域以及工程和自然科学的许多其他分支。

1988年--罗洛-卡彭特开发了聊天机器人Jabberwacky。其目标是 "以一种有趣、娱乐和幽默的方式模拟人类的自然聊天"。它是通过人类互动创造人工智能的早期尝试。
1991年,互联网的出现使在线连接和数据共享成为可能,无论你是谁,无论你在哪里。由于数据是人工智能的燃料,这在以后将被理解为人工智能的一个关键时刻。
1995年,在Eliza的基础上,聊天机器人A.L.I.C.E(人工语言学互联网计算机实体)被开发。它包括以前所未有的规模收集自然语言样本数据,由互联网促成。
1997年注定是改写AI历史的一年。因为这一年,IBM的深蓝超级计算机赢过了国际象棋冠军Garry Kasparov,使得人们重新评估了人脑与机器大脑的异同。在这场比赛之前,虽然人们都知道深蓝可以比Kasparov更快的处理信息,但是更重要的是,人们并不相信它可以进行战略性的思维。但是这场胜利似乎说明它也可以。
这场胜利虽然仍然无法向研究者表明AI可以在没有明确规则的领域解决问题获得胜利,但已经是整个人工智能领域非常大的飞跃。

2000年,麻省理工学院的辛西娅-布雷泽尔开发了Kismet,一种能够识别和模拟情绪的机器人。

这个阶段的机器人本质上是通过启发式的Pattern Matching(模式匹配)规则来实现与人类的对话程序。就像现在那些客服机器人一样,通过匹配关键词做出相应的回答。但是这样的匹配规则再多再复杂,也不可能穷举出所有答案,所以基本上不可能通过Pattern Matching变成真正的“智能”。
机器学习
2001年,人工智能的新流派出现了:机器学习,顾名思义,就是让机器去学习,人不再给出相应的匹配规则,而是给出相应的例子,由机器主动发现其中规律。
SmartChild机器人就是基于机器学习开发的,他的聊天更加自然。
人工神经网络
2010年机器学习出现了新的领域:人工神经网络。人的大脑是靠超过100亿个神经元,通过网状链接,来判断和传递信息,人工神经网络就是模仿人脑。

这个神经网络的想法可以追溯到1943年,但是需要两样东西:海量数据+强大算力。而这些在之前都是不具备的,只能纸上谈兵。
2010年,互联网的时代,数据飞速暴涨,算力也在指数级持续提升,人工智能的深度学习时代开始。像英伟达GPU这样的图形处理器开始被用于训练深度学习模型。它们继续成为机器学习的核心,彻底改变了人工智能的发展。在2010年代,有两个因素开始发挥作用,完全改变了人工智能:
- 来自图形处理单元的大量计算能力
- 从互联网上搜刮的大量数据。
2011年,IBM的自然语言答题计算机Watson参加了Jeopardy(美国著名的智力问答竞赛节目,涉及到历史、文学、艺术、流行文化、科技、体育、地理、文字游戏等等各个领域),它击败了两位前冠军。崩溃的Ken Jennings笑称,“我,以自己的名义,欢迎我们的机器人霸主。”
2012年的6月,谷歌的研究人员Jeff Dean和Andrew Ng将他们从Youtube视频上截取下来的一千万张没有标签的图片输入了一个由一万六千台计算机处理器组成的巨型神经网络中。虽然他们并没有给出任何关于这些图片的信息,AI却已经能够通过深度学习的算法分辨出猫科动物的图片。

2016年3月,谷歌的AlphaGo打败了围棋世界冠军李世石。整场比赛有世界各地6千万人围观。而之所以这场比赛有着划时代的意义,是因为围棋选择落子的可能性超过了这世界原子的数量。这估计是AI至今为止最为令人瞠目结舌的一场胜利了。
Transformer
2017年,谷歌出来一篇论文,提出一个新的学习框架叫Transformer,它可以让机器同时学习大量的文字,之前要一个一个学,现在可以同时学。这使得AI的性能有了质的飞跃。
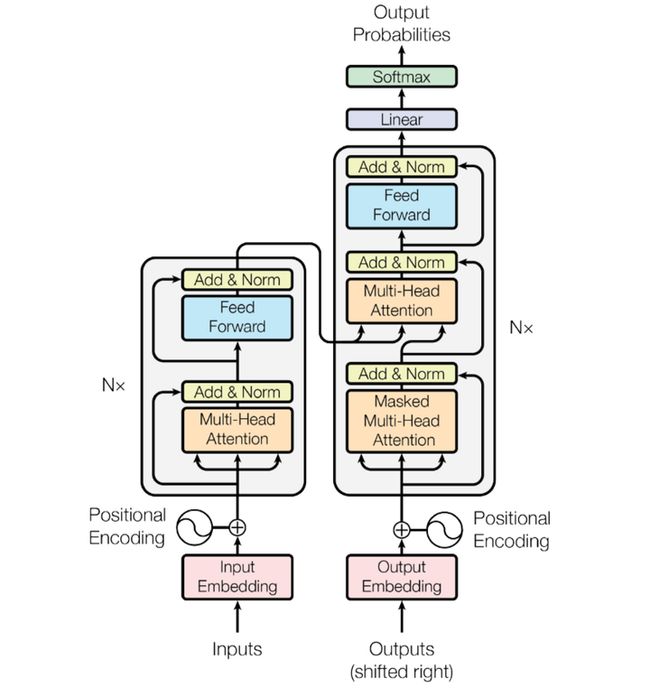
用电路串联,并联类比,学习效率就提高了很多。如今的生成型AI模型都是在这个transformer的基础上的。chatGPT的全称是chat Generative Pre-trained Transformer(生成型预训练变换模型),其中GPT的T就是Transformer。Google的BERT也是Transformer(BERT的全称是Bidirectional Encoder Representation from Transformers,预训练的语言表征模型)。
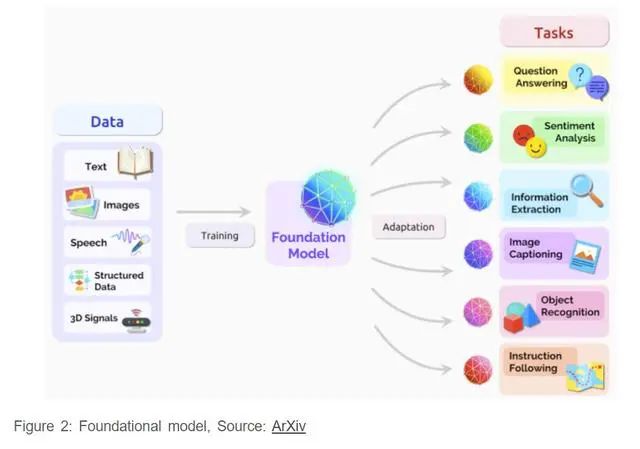
2018年,LLMs(大型语言模型)出现了。LLMs是一种在海量文本数据上训练过的人工智能系统。它们可以理解自然语言,并对输入产生类似人类的反应。LLMs使用先进的机器学习算法来理解和分析人类语音。它们被用于聊天机器人、虚拟助手、语言翻译、内容创作和科学研究。作为其中的代表,OpenAI推出了GPT(Generative Pre-trained Transformer)。这成为自然语言处理中最重要的突破之一。
2019年,ChatGPT参加了在伦敦举行的“图灵测试”,并成功通过了这项由英国计算机科学家艾伦·图灵设计的著名测试。在测试中,ChatGPT能够与人类进行自然对话,表现出类似于人类的思考和推理能力,从而成为了第一个通过图灵测试的AI模型。
这一事件对人工智能领域具有重大意义,证明了人工智能在自然语言处理方面的强大能力。ChatGPT的成功也为其背后的公司OpenAI赢得了声誉和大量投资。
2020年,ChatGPT的研究者在《自然》杂志上发表了一篇题为《语言模型ChatGPT在各种自然语言基准测试中的表现》的论文。这篇论文详细介绍了ChatGPT在各种自然语言处理任务中的表现,包括文本生成、文本分类、问答系统等。
论文的发表进一步提高了ChatGPT的知名度,并为自然语言处理领域的研究者提供了宝贵的参考。此外,这一事件也表明了人工智能领域对于高质量数据的重视,以及数据科学在当今研究中的重要地位。
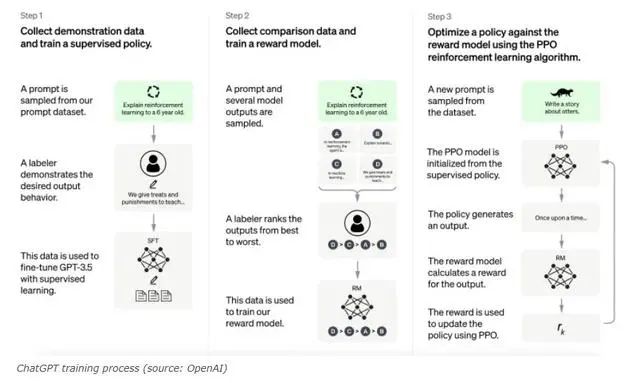
2022年11月30日 - OpenAI推出聊天机器人ChatGPT。它是建立在GPT-3.5和GPT-4大型语言模型之上的。
ChatGPT根据用户的提示,生成类似人类的文本。它根据它在训练过程中从大量数据中学习到的模式,预测给定文本中的下一个词。当你提示ChatGPT时,它使用 "转化器架构 "来回应。这是一种深度学习技术,通过包含数十亿字的TB级数据来创造一个答案。
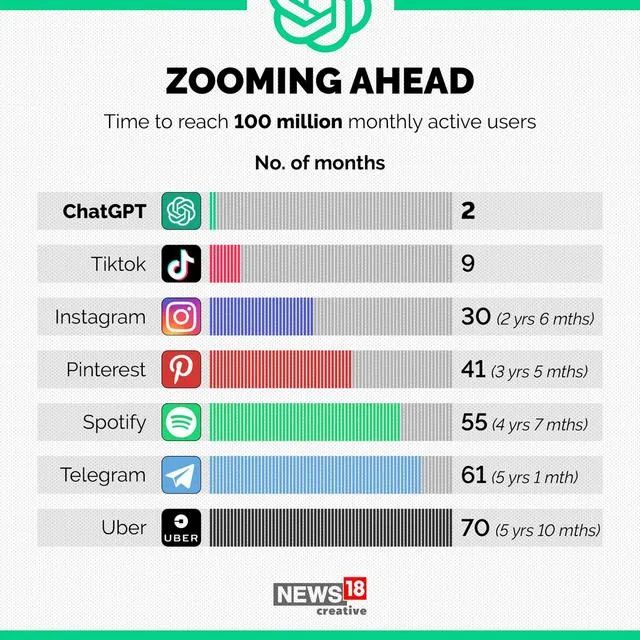
2022年12月4日,ChatGPT达到100万用户,2023年1月,ChatGPT的月度活跃用户就达到了1亿人。它是 "历史上增长最快的消费者应用程序"。
ChatGPT
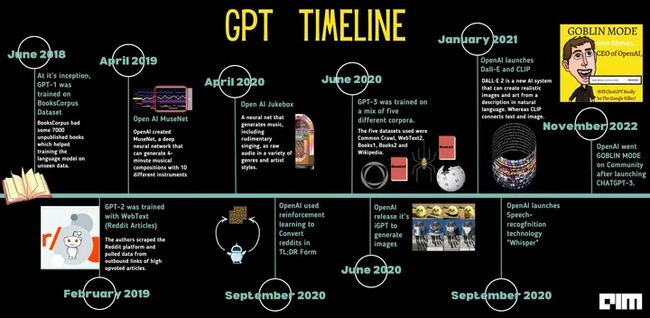
2015年,OpenAI由Elon Musk、Sam Altman、Reid Hoffman、Jessica Livingston等人创立,是一个非营利组织。他们的任务是花费10亿美元来保护人类免受邪恶人工智能的伤害。但因为特斯拉的自动驾驶也需要ai方面的研究,为了避免和OpenAI的利益冲突。马斯克后来退出了这项交易,OpenAI开始接受企业的资助。

2018年,OpenAI公司发布了第一个版本的GPT(Generative Pre-trained Transformer)模型,它是一种基于深度学习的语言模型,可以自动生成自然语言文本。GPT-1采用了Transformer结构,可以对大量的文本数据进行预训练,从而学习到语言的语法和语义特征,并且可以通过fine-tuning的方式进行特定任务的微调。
2019年,OpenAI公司于发布了GPT-2模型,这是一个更加强大的语言模型,具有更多的参数和更高的预测能力。GPT-2模型可以生成更加自然、连贯的文本,其预训练模型也包含了更多的数据和知识。但是,由于担心GPT-2模型被滥用,OpenAI公司只发布了部分模型和数据,并且限制了其访问和使用。
2020年,OpenAI公司推出了GPT-3模型,这是一个非常大型和强大的语言模型,拥有1750亿个参数,可以处理各种复杂的自然语言任务。GPT-3模型可以生成高质量、逼真的自然语言文本,并且可以进行多种类型的语言任务,如问答、翻译、摘要、生成等。GPT-3模型被广泛认为是目前最先进的自然语言处理技术之一,它的应用前景非常广泛。
2022年一月,OpenAI公司发布了ChatGPT-3,这是一个基于GPT-3模型的聊天机器人,可以进行自然、流畅的对话,并且可以回答各种类型的问题。
ChatGPT-3利用GPT-3模型的强大语言处理能力,可以实现更加智能化、人性化的对话体验。它可以应用于多种领域,如智能客服、语音交互、智能家居、金融投资等,具有非常广泛的应用前景。
2023年3月,OpenAI发布了其下一代大型语言模型GPT-4,这是其支持ChatGPT和新必应等应用程序的最新AI大型语言模型。该公司表示,该模型在许多专业测试中的表现超出了“人类水平”。GPT-4, 相较于ChatGPT(GPT-3.5)有了质的飞跃,逻辑推理能力更强,语言能力更强,各种考试已经基本超过90%的人类!
未来
关于AI的未来,最令人兴奋的是它们将不断变得更加善于理解和回应我们人类。很快,它们将变得非常高效。但这还不是全部。AI将能够处理不仅是文本,还包括图像和声音,并且将使用世界各地的语言。此外,人们正在努力确保这些AI模型是公平和负责任的,以使其更加开放和减少偏见。
就在刚刚,11月7日凌晨2点,OpenAI在美国旧金山举行首场开发者大会。OpenAI将GPT大模型更新到GPT-4 Turbo版本,并进一步完善大模型开发的业务架构,包括推出吸引软件开发者的“商店”产品、推出版权盾、提供API开发助手等。AI的发展已经超出了你的想象。
总之,AI将成为我们惊人的伙伴,并以不可思议的方式与速度来改变我们的生活,一起拭目以待吧。
参考资料:
1、陈巍:ChatGPT发展历程、原理、技术架构详解和产业未来 (收录于GPT-4/ChatGPT技术与产业分析) - 知乎
2、https://www.jiemian.com/article/8893975.html
3、https://baike.baidu.com/item/ChatGPT/62446358?fr=ge_ala
4、https://baijiahao.baidu.com/s?id=1756585184519481965&wfr=spider&for=pc
5、https://www.huxiu.com/article/800724.html
6、https://baijiahao.baidu.com/s?id=1762792484134390671&wfr=spider&for=pc
7、https://wandb.ai/mostafaibrahim